
不平衡數(shù)據(jù)集的建模的技巧和策略

本文介紹了不平衡數(shù)據(jù)集的建模技巧和策略。
不平衡數(shù)據(jù)集是指一個(gè)類中的示例數(shù)量與另一類中的示例數(shù)量顯著不同的情況。例如在一個(gè)二元分類問題中,一個(gè)類只占總樣本的一小部分,這被稱為不平衡數(shù)據(jù)集。類不平衡會(huì)在構(gòu)建機(jī)器學(xué)習(xí)模型時(shí)導(dǎo)致很多問題。
不平衡數(shù)據(jù)集的主要問題之一是模型可能會(huì)偏向多數(shù)類,從而導(dǎo)致預(yù)測(cè)少數(shù)類的性能不佳。這是因?yàn)槟P徒?jīng)過訓(xùn)練以最小化錯(cuò)誤率,并且當(dāng)多數(shù)類被過度代表時(shí),模型傾向于更頻繁地預(yù)測(cè)多數(shù)類。這會(huì)導(dǎo)致更高的準(zhǔn)確率得分,但少數(shù)類別得分較低。
另一個(gè)問題是,當(dāng)模型暴露于新的、看不見的數(shù)據(jù)時(shí),它可能無法很好地泛化。這是因?yàn)樵撃P褪窃趦A斜的數(shù)據(jù)集上訓(xùn)練的,可能無法處理測(cè)試數(shù)據(jù)中的不平衡。
在本文中,我們將討論處理不平衡數(shù)據(jù)集和提高機(jī)器學(xué)習(xí)模型性能的各種技巧和策略。將涵蓋的一些技術(shù)包括重采樣技術(shù)、代價(jià)敏感學(xué)習(xí)、使用適當(dāng)?shù)男阅苤笜?biāo)、集成方法和其他策略。通過這些技巧,可以為不平衡的數(shù)據(jù)集構(gòu)建有效的模型。
處理不平衡數(shù)據(jù)集的技巧
重采樣技術(shù)是處理不平衡數(shù)據(jù)集的最流行方法之一。這些技術(shù)涉及減少多數(shù)類中的示例數(shù)量或增加少數(shù)類中的示例數(shù)量。
欠采樣可以從多數(shù)類中隨機(jī)刪除示例以減小其大小并平衡數(shù)據(jù)集。這種技術(shù)簡(jiǎn)單易行,但會(huì)導(dǎo)致信息丟失,因?yàn)樗鼤?huì)丟棄一些多數(shù)類示例。
過采樣與欠采樣相反,過采樣隨機(jī)復(fù)制少數(shù)類中的示例以增加其大小。這種技術(shù)可能會(huì)導(dǎo)致過度擬合,因?yàn)槟P褪窃谏贁?shù)類的重復(fù)示例上訓(xùn)練的。
SMOTE是一種更高級(jí)的技術(shù),它創(chuàng)建少數(shù)類的合成示例,而不是復(fù)制現(xiàn)有示例。這種技術(shù)有助于在不引入重復(fù)項(xiàng)的情況下平衡數(shù)據(jù)集。
代價(jià)敏感學(xué)習(xí)(Cost-sensitive learning)是另一種可用于處理不平衡數(shù)據(jù)集的技術(shù)。在這種方法中,不同的錯(cuò)誤分類成本被分配給不同的類別。這意味著與錯(cuò)誤分類多數(shù)類示例相比,模型因錯(cuò)誤分類少數(shù)類示例而受到更嚴(yán)重的懲罰。
在處理不平衡的數(shù)據(jù)集時(shí),使用適當(dāng)?shù)男阅苤笜?biāo)也很重要。準(zhǔn)確性并不總是最好的指標(biāo),因?yàn)樵谔幚聿黄胶獾臄?shù)據(jù)集時(shí)它可能會(huì)產(chǎn)生誤導(dǎo)。相反,使用 AUC-ROC等指標(biāo)可以更好地指示模型性能。
集成方法,例如 bagging 和 boosting,也可以有效地對(duì)不平衡數(shù)據(jù)集進(jìn)行建模。這些方法結(jié)合了多個(gè)模型的預(yù)測(cè)以提高整體性能。Bagging 涉及獨(dú)立訓(xùn)練多個(gè)模型并對(duì)它們的預(yù)測(cè)進(jìn)行平均,而 boosting 涉及按順序訓(xùn)練多個(gè)模型,其中每個(gè)模型都試圖糾正前一個(gè)模型的錯(cuò)誤。
重采樣技術(shù)、成本敏感學(xué)習(xí)、使用適當(dāng)?shù)男阅苤笜?biāo)和集成方法是一些技巧和策略,可以幫助處理不平衡的數(shù)據(jù)集并提高機(jī)器學(xué)習(xí)模型的性能。
在不平衡數(shù)據(jù)集上提高模型性能的策略
收集更多數(shù)據(jù)是在不平衡數(shù)據(jù)集上提高模型性能的最直接策略之一。通過增加少數(shù)類中的示例數(shù)量,模型將有更多信息可供學(xué)習(xí),并且不太可能偏向多數(shù)類。當(dāng)少數(shù)類中的示例數(shù)量非常少時(shí),此策略特別有用。
生成合成樣本是另一種可用于提高模型性能的策略。合成樣本是人工創(chuàng)建的樣本,與少數(shù)類中的真實(shí)樣本相似。這些樣本可以使用 SMOTE等技術(shù)生成,該技術(shù)通過在現(xiàn)有示例之間進(jìn)行插值來創(chuàng)建合成示例。生成合成樣本有助于平衡數(shù)據(jù)集并為模型提供更多示例以供學(xué)習(xí)。
使用領(lǐng)域知識(shí)來關(guān)注重要樣本也是一種可行的策略,通過識(shí)別數(shù)據(jù)集中信息量最大的示例來提高模型性能。例如,如果我們正在處理醫(yī)學(xué)數(shù)據(jù)集,可能知道某些癥狀或?qū)嶒?yàn)室結(jié)果更能表明某種疾病。通過關(guān)注這些例子可以提高模型準(zhǔn)確預(yù)測(cè)少數(shù)類的能力。
最后可以使用異常檢測(cè)等高級(jí)技術(shù)來識(shí)別和關(guān)注少數(shù)類示例。這些技術(shù)可用于識(shí)別與多數(shù)類不同且可能是少數(shù)類示例的示例。這可以通過識(shí)別數(shù)據(jù)集中信息量最大的示例來幫助提高模型性能。
在收集更多數(shù)據(jù)、生成合成樣本、使用領(lǐng)域知識(shí)專注于重要樣本以及使用異常檢測(cè)等先進(jìn)技術(shù)是一些可用于提高模型在不平衡數(shù)據(jù)集上的性能的策略。這些策略可以幫助平衡數(shù)據(jù)集,為模型提供更多示例以供學(xué)習(xí),并識(shí)別數(shù)據(jù)集中信息量最大的示例。
不平衡數(shù)據(jù)集的練習(xí)
這里我們使用信用卡欺詐分類的數(shù)據(jù)集演示處理不平衡數(shù)據(jù)的方法:
import pandas as pdimport numpy as npfrom sklearn.preprocessing import RobustScalerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_scorefrom sklearn.metrics import confusion_matrix,classification_report,f1_score,recall_score,roc_auc_score, roc_curveimport matplotlib.pyplot as pltimport seaborn as snsfrom matplotlib import rc,rcParamsimport itertoolsimport warningswarnings.filterwarnings("ignore", category=DeprecationWarning)warnings.filterwarnings("ignore", category=FutureWarning)warnings.filterwarnings("ignore", category=UserWarning)
讀取數(shù)據(jù)
df = pd.read_csv("creditcard.csv")df.head()print("Number of observations : " ,len(df))print("Number of variables : ", len(df.columns))#Number of observations : 284807#Number of variables : 31
查看數(shù)據(jù)集信息
df.info()<class 'pandas.core.frame.DataFrame'>RangeIndex: 284807 entries, 0 to 284806Data columns (total 31 columns):# Column Non-Null Count Dtype--- ------ -------------- -----0 Time 284807 non-null float641 V1 284807 non-null float642 V2 284807 non-null float643 V3 284807 non-null float644 V4 284807 non-null float645 V5 284807 non-null float646 V6 284807 non-null float647 V7 284807 non-null float648 V8 284807 non-null float649 V9 284807 non-null float6410 V10 284807 non-null float6411 V11 284807 non-null float6412 V12 284807 non-null float6413 V13 284807 non-null float6414 V14 284807 non-null float6415 V15 284807 non-null float6416 V16 284807 non-null float6417 V17 284807 non-null float6418 V18 284807 non-null float6419 V19 284807 non-null float6420 V20 284807 non-null float6421 V21 284807 non-null float6422 V22 284807 non-null float6423 V23 284807 non-null float6424 V24 284807 non-null float6425 V25 284807 non-null float6426 V26 284807 non-null float6427 V27 284807 non-null float6428 V28 284807 non-null float6429 Amount 284807 non-null float6430 Class 284807 non-null int64dtypes: float64(30), int64(1)memory usage: 67.4 MB
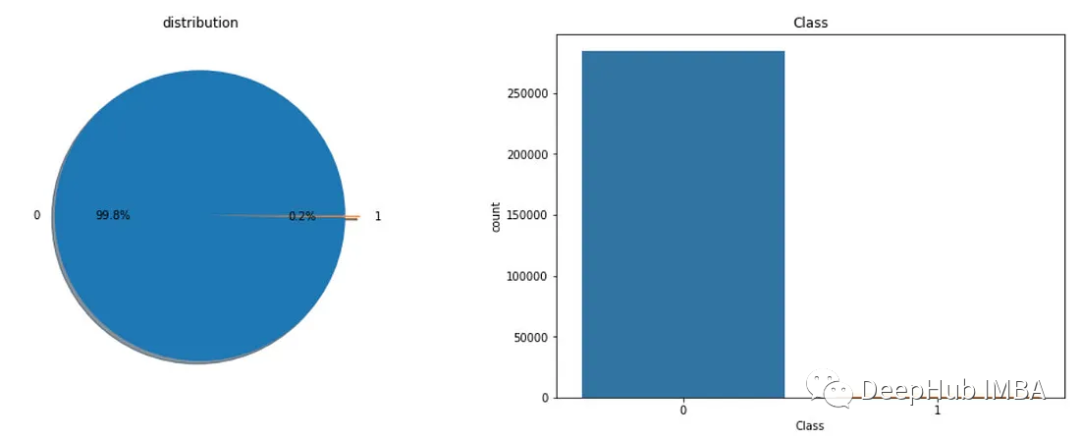
查看分類類別:
f,ax=plt.subplots(1,2,figsize=(18,8))df['Class'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)ax[0].set_title('da??l?m')ax[0].set_ylabel('')sns.countplot('Class',data=df,ax=ax[1])ax[1].set_title('Class')plt.show()
rob_scaler = RobustScaler()df['Amount'] = rob_scaler.fit_transform(df['Amount'].values.reshape(-1,1))df['Time'] = rob_scaler.fit_transform(df['Time'].values.reshape(-1,1))df.head()
創(chuàng)建基類模型
X = df.drop("Class", axis=1)y = df["Class"]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=123456)model = LogisticRegression(random_state=123456)model.fit(X_train, y_train)y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print("Accuracy: %.3f"%(accuracy))
我們創(chuàng)建的模型的準(zhǔn)確率評(píng)分為0.999。我們可以說我們的模型很完美嗎?
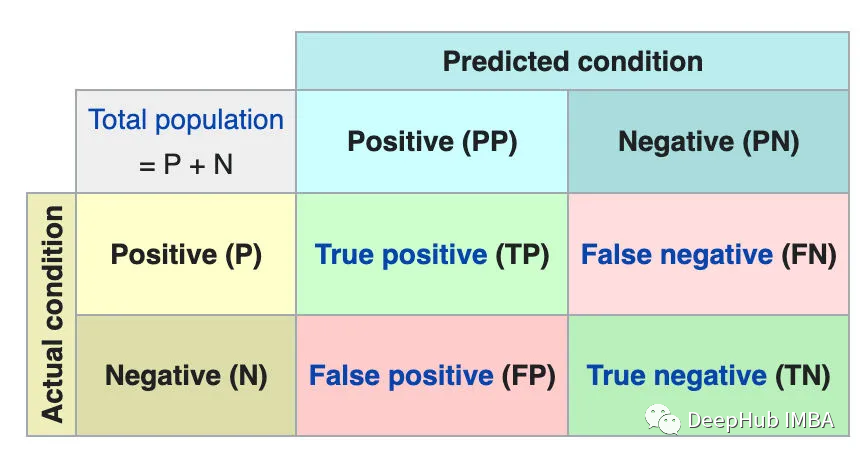
混淆矩陣是一個(gè)用來描述分類模型的真實(shí)值在測(cè)試數(shù)據(jù)上的性能的表。它包含4種不同的估計(jì)值和實(shí)際值的組合。
def plot_confusion_matrix(cm, classes,title='Confusion matrix',cmap=plt.cm.Blues):plt.rcParams.update({'font.size': 19})plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title,fontdict={'size':'16'})plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45,fontsize=12,color="blue")plt.yticks(tick_marks, classes,fontsize=12,color="blue")rc('font', weight='bold')fmt = '.1f'thresh = cm.max()for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, format(cm[i, j], fmt),horizontalalignment="center",color="red")plt.ylabel('True label',fontdict={'size':'16'})plt.xlabel('Predicted label',fontdict={'size':'16'})plt.tight_layout()plot_confusion_matrix(confusion_matrix(y_test, y_pred=y_pred), classes=['Non Fraud','Fraud'],title='Confusion matrix')
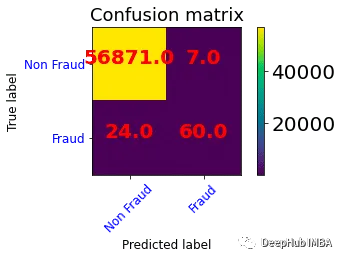
非欺詐類共進(jìn)行了56875次預(yù)測(cè),其中56870次(TP)正確,5次(FP)錯(cuò)誤。
欺詐類共進(jìn)行了87次預(yù)測(cè),其中31次(FN)錯(cuò)誤,56次(TN)正確。
該模型可以預(yù)測(cè)欺詐狀態(tài),準(zhǔn)確率為0.99。但當(dāng)檢查混淆矩陣時(shí),欺詐類的錯(cuò)誤預(yù)測(cè)率相當(dāng)高。也就是說該模型正確地預(yù)測(cè)了非欺詐類的概率為0.99。但是非欺詐類的觀測(cè)值的數(shù)量高于欺詐類的觀測(cè)值的數(shù)量,這拉搞了我們對(duì)準(zhǔn)確率的計(jì)算,并且我們更加關(guān)注的是欺詐類的準(zhǔn)確率,所以我們需要一個(gè)指標(biāo)來衡量它的性能。
選擇正確的指標(biāo)
在處理不平衡數(shù)據(jù)集時(shí),選擇正確的指標(biāo)來評(píng)估模型的性能非常重要。傳統(tǒng)指標(biāo),如準(zhǔn)確性、精確度和召回率,可能不適用于不平衡的數(shù)據(jù)集,因?yàn)樗鼈儧]有考慮數(shù)據(jù)中類別的分布。
經(jīng)常用于不平衡數(shù)據(jù)集的一個(gè)指標(biāo)是 F1 分?jǐn)?shù)。F1 分?jǐn)?shù)是精確率和召回率的調(diào)和平均值,它提供了兩個(gè)指標(biāo)之間的平衡。計(jì)算如下:
F1 = 2 * (precision * recall) / (precision + recall)另一個(gè)經(jīng)常用于不平衡數(shù)據(jù)集的指標(biāo)是 AUC-ROC。AUC-ROC 衡量模型區(qū)分正類和負(fù)類的能力。它是通過繪制不同分類閾值下的TPR與FPR來計(jì)算的。AUC-ROC 值的范圍從 0.5(隨機(jī)猜測(cè))到 1.0(完美分類)。
print(classification_report(y_test, y_pred))precision recall f1-score support0 1.00 1.00 1.00 568751 0.92 0.64 0.76 87accuracy 1.00 56962macro avg 0.96 0.82 0.88 56962weighted avg 1.00 1.00 1.00 56962
返回對(duì)0(非欺詐)類的預(yù)測(cè)有多少是正確的。查看混淆矩陣,56870 + 31 = 56901個(gè)非欺詐類預(yù)測(cè),其中56870個(gè)預(yù)測(cè)正確。0類的精度值接近1 (56870 / 56901)。
返回對(duì)1 (欺詐)類的預(yù)測(cè)有多少是正確的。查看混淆矩陣,5 + 56 = 61個(gè)欺詐類別預(yù)測(cè),其中56個(gè)被正確估計(jì)。0類的精度為0.92 (56 / 61),可以看到差別還是很大的。
過采樣
通過復(fù)制少數(shù)類樣本來穩(wěn)定數(shù)據(jù)集。
隨機(jī)過采樣:通過添加從少數(shù)群體中隨機(jī)選擇的樣本來平衡數(shù)據(jù)集。如果數(shù)據(jù)集很小,可以使用這種技術(shù)。可能會(huì)導(dǎo)致過擬合。randomoverampler方法接受sampling_strategy參數(shù),當(dāng)sampling_strategy = ' minority '被調(diào)用時(shí),它會(huì)增加minority類的數(shù)量,使其與majority類的數(shù)量相等。
我們可以在這個(gè)參數(shù)中輸入一個(gè)浮點(diǎn)值。例如,假設(shè)我們的少數(shù)群體人數(shù)為1000人,多數(shù)群體人數(shù)為100人。如果我們說sampling_strategy = 0.5,少數(shù)類將被添加到500。
y_train.value_counts()0 2274401 405Name: Class, dtype: int64from imblearn.over_sampling import RandomOverSampleroversample = RandomOverSampler(sampling_strategy='minority')X_randomover, y_randomover = oversample.fit_resample(X_train, y_train)
采樣后訓(xùn)練
model.fit(X_randomover, y_randomover)y_pred = model.predict(X_test)plot_confusion_matrix(confusion_matrix(y_test, y_pred=y_pred), classes=['Non Fraud','Fraud'],title='Confusion matrix')
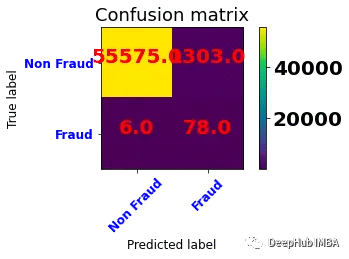
應(yīng)用隨機(jī)過采樣后,訓(xùn)練模型的精度值為0.97,出現(xiàn)了下降。但是從混淆矩陣來看,模型的欺詐類的正確估計(jì)率有所提高。
SMOTE 過采樣:從少數(shù)群體中隨機(jī)選取一個(gè)樣本。然后,為這個(gè)樣本找到k個(gè)最近的鄰居。從k個(gè)最近的鄰居中隨機(jī)選取一個(gè),將其與從少數(shù)類中隨機(jī)選取的樣本組合在特征空間中形成線段,形成合成樣本。
from imblearn.over_sampling import SMOTEoversample = SMOTE()X_smote, y_smote = oversample.fit_resample(X_train, y_train)
使用SMOTE后的數(shù)據(jù)訓(xùn)練
model.fit(X_smote, y_smote)y_pred = model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)plot_confusion_matrix(confusion_matrix(y_test, y_pred=y_pred), classes=['Non Fraud','Fraud'],title='Confusion matrix')
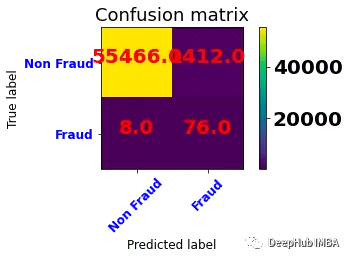
可以看到與基線模型相比,欺詐的準(zhǔn)確率有所提高,但是比隨機(jī)過采樣有所下降,這可能是數(shù)據(jù)集的原因,因?yàn)镾MOTE采樣會(huì)生成心的數(shù)據(jù),所以并不適合所有的數(shù)據(jù)集。
總結(jié)
在這篇文章中,我們討論了處理不平衡數(shù)據(jù)集和提高機(jī)器學(xué)習(xí)模型性能的各種技巧和策略。不平衡的數(shù)據(jù)集可能是機(jī)器學(xué)習(xí)中的一個(gè)常見問題,并可能導(dǎo)致在預(yù)測(cè)少數(shù)類時(shí)表現(xiàn)不佳。
本文介紹了一些可用于平衡數(shù)據(jù)集的重采樣技術(shù),如欠采樣、過采樣和SMOTE。還討論了成本敏感學(xué)習(xí)和使用適當(dāng)?shù)男阅苤笜?biāo),如AUC-ROC,這可以提供更好的模型性能指示。
處理不平衡的數(shù)據(jù)集是具有挑戰(zhàn)性的,但通過遵循本文討論的技巧和策略,可以建立有效的模型準(zhǔn)確預(yù)測(cè)少數(shù)群體。重要的是要記住最佳方法將取決于特定的數(shù)據(jù)集和問題,為了獲得最佳結(jié)果,可能需要結(jié)合各種技術(shù)。因此,試驗(yàn)不同的技術(shù)并使用適當(dāng)?shù)闹笜?biāo)評(píng)估它們的性能是很重要的。
編輯:王菁
校對(duì):林亦霖