
云原生全鏈路追蹤Trace2.0架構(gòu)實踐
導(dǎo)讀:
分布式鏈路追蹤作為解決分布式應(yīng)用可觀測問題的重要技術(shù),得物全鏈路追蹤(簡稱Trace2.0)基于OpenTelemetry提供的可觀測標(biāo)準(zhǔn)方案實現(xiàn)新一代的一站式全鏈路觀測診斷平臺,并通過全量采集Trace幫助業(yè)務(wù)提高故障診斷、性能優(yōu)化、架構(gòu)治理的效率。
全量采集Trace數(shù)據(jù)(日增數(shù)百TB 、數(shù)千億條Span數(shù)據(jù))并以較低的成本保證數(shù)據(jù)的實時處理與高效查詢,對Trace2.0后端整體的可觀測性解決方案提出了極高的要求。本文將詳細(xì)介紹Trace2.0背后的架構(gòu)設(shè)計、尾部采樣和冷熱存儲方案,以及我們是如何通過自建存儲實現(xiàn)進(jìn)一步的降本增效(存儲成本下降66%)。
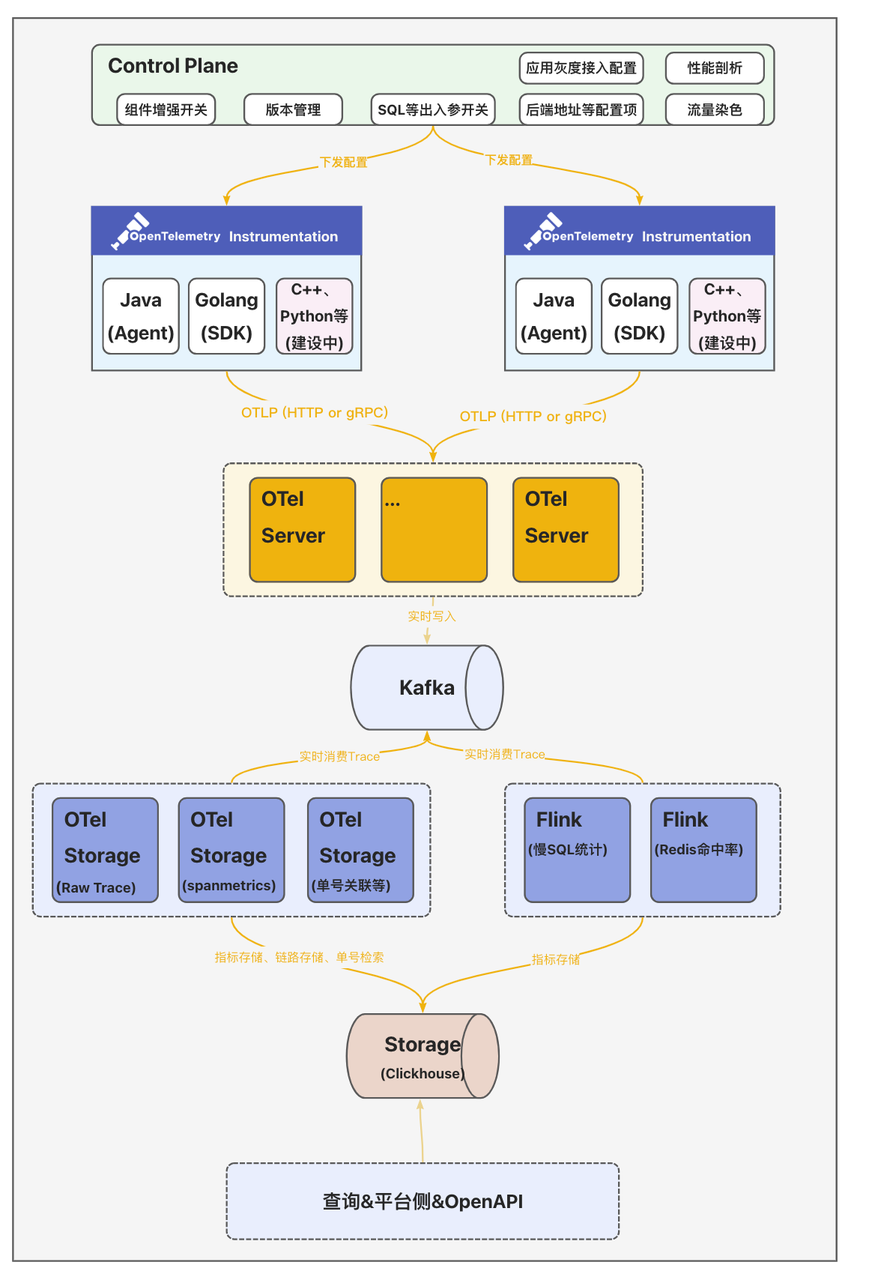
全鏈路追蹤Trace2.0從數(shù)據(jù)接入側(cè)、計算、存儲到查詢整體模塊架構(gòu)如上圖所示。這里說一下各組件的核心能力:
-
客戶端&數(shù)據(jù)采集:集成并定制OpenTelemetry提供的多語言SDK(Agent),生成統(tǒng)一格式的可觀測數(shù)據(jù)。
-
控制平面Control Plane:統(tǒng)一的配置中心向數(shù)據(jù)采集側(cè)下發(fā)各類動態(tài)配置發(fā)并實時生效;支持向各采集器下發(fā)動態(tài)配置并實時生效,支持應(yīng)用按實例數(shù)灰度接入,并提供出入?yún)⑹占瘎討B(tài)開關(guān)、性能剖析動態(tài)開關(guān)、流量染色動態(tài)配置、客戶端版本管理等。
-
數(shù)據(jù)收集服務(wù)OTel Server:數(shù)據(jù)收集器OTel Server兼容OpenTelemetry Protocol(OTLP)協(xié)議,提供gRPC和HTTP兩種方式接收采集器發(fā)送的可觀測數(shù)據(jù)。
-
分析計算&存儲OTel Storage:計算側(cè)除了基礎(chǔ)的實時檢索能力外,還提供了場景化的數(shù)據(jù)分析計算主要包括:
-
存儲Trace數(shù)據(jù):數(shù)據(jù)分為兩段,一段是索引字段,包括TraceID、ServiceName、SpanName、StatusCode、Duration和起止時間等基本信息,用于高級檢索;另一段是明細(xì)數(shù)據(jù)(源數(shù)據(jù),包含所有的Span數(shù)據(jù))
-
計算SpanMetrics數(shù)據(jù):聚合計算Service、SpanName、Host、StatusCode、Env、Region等維度的執(zhí)行總次數(shù)、總耗時、最大耗時、最小耗時、分位線等數(shù)據(jù);
-
業(yè)務(wù)單號關(guān)聯(lián)Trace:電商場景下部分研發(fā)多以訂單號、履約單號、匯金單號作為排障的輸入,因此和業(yè)務(wù)研發(fā)約定特殊埋點規(guī)則后--在Span的Tag里添加一個特殊字段"bizOrderId={實際單號}"--便將這個Tag作為ClickHouse的索引字段;從而實現(xiàn)業(yè)務(wù)鏈路到全鏈路Trace形成一個完整的排障鏈路;
-
Redis熱點數(shù)據(jù)統(tǒng)計:在客戶端側(cè)擴展調(diào)用Redis時入?yún)⒑统鰠panTag埋點,以便統(tǒng)Redis命中率、大Key、高頻寫、慢調(diào)用等指標(biāo)數(shù)據(jù);
-
MySQL熱點數(shù)據(jù)統(tǒng)計:按照SQL指紋統(tǒng)計調(diào)用次數(shù)、慢SQL次數(shù)以及關(guān)聯(lián)的接口名。
-
得物早期的全鏈路追蹤方案出于對存儲成本的考慮,在客戶端設(shè)置了1%的采樣率,導(dǎo)致研發(fā)排查問題時經(jīng)常查詢不到想看的Trace鏈路。那么Trace2.0為了解決這個問題,就不能僅僅只是簡單地將客戶端的采樣率調(diào)整為100%,而是需要在客戶端全量采集Trace數(shù)據(jù)的同時,合理地控制Trace存儲成本。且從實踐經(jīng)驗來看,Trace數(shù)據(jù)的價值分布是不均勻的,隨著時間的推移Trace的數(shù)據(jù)價值是急速降低的。
全量存儲Trace數(shù)據(jù)不僅會造成巨大的成本浪費,還會顯著地影響整條數(shù)據(jù)處理鏈路的性能以及穩(wěn)定性。所以,如果我們能夠只保存那些有價值、大概率會被用戶實際查詢的Trace,就能取得成本與收益的平衡。那什么是有價值的Trace呢?根據(jù)日常排查經(jīng)驗,我們發(fā)現(xiàn)業(yè)務(wù)研發(fā)主要關(guān)心以下四類優(yōu)先級高場景:
-
在調(diào)用鏈上出現(xiàn)了異常ERROR;
-
在調(diào)用鏈上出現(xiàn)了大于「200ms」的數(shù)據(jù)庫調(diào)用;
-
整個調(diào)用鏈耗時超過「1s」;
-
業(yè)務(wù)場景的調(diào)用鏈,比如通過訂單號關(guān)聯(lián)的調(diào)用鏈。
在這個背景下,并結(jié)合業(yè)界的實踐經(jīng)驗,落地Trace2.0的過程中設(shè)計了尾部采樣&冷熱分層存儲方案,方案如下:
-
「3天」內(nèi)的Trace數(shù)據(jù)全量保存,定義為熱數(shù)據(jù)。
-
基于Kafka延遲消費+Bloom Filter尾部采樣的數(shù)據(jù)(錯、慢、自定義采樣規(guī)則、以及默認(rèn)常規(guī)0.1%采樣數(shù)據(jù))保留「30天」,定義為冷數(shù)據(jù)。
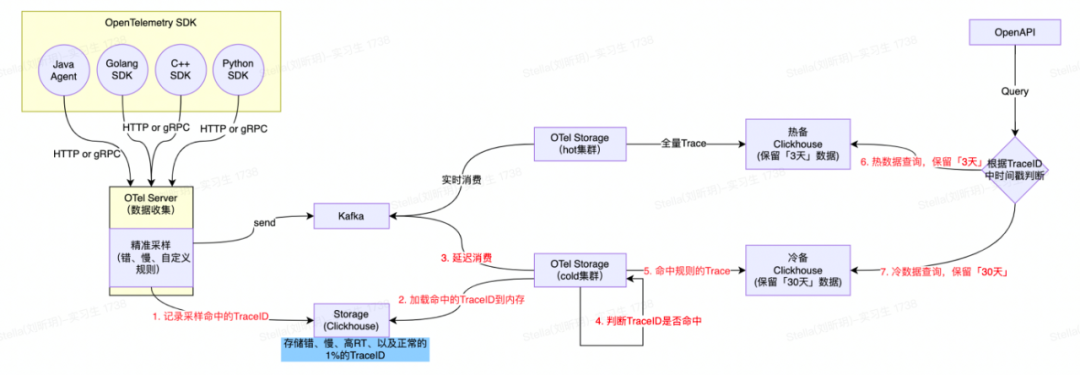
整體處理流程如下:
-
OTel Server數(shù)據(jù)收集&采樣規(guī)則:將客戶端采集器上報的全量Trace數(shù)據(jù)實時寫入Kafka中,并把滿足采樣規(guī)則(上述定義的場景)的Span數(shù)據(jù)對應(yīng)的TraceID記錄到Bloom Filter中;
-
OTel Storage持久化熱數(shù)據(jù):實時消費Kafka中數(shù)據(jù),并全量持久化到ClickHouse熱集群中;
-
OTel Storage持久化冷數(shù)據(jù):訂閱上游OTel Server的Bloom Filter,延遲消費Kafka中的數(shù)據(jù),將TraceID在Bloom Filter中可能存在的Span數(shù)據(jù)持久化到ClickHouse冷集群中;
-
延遲時間配置的30分鐘,盡量保證一個Trace下的Span完整保留。
-
-
TraceID點查: Trace2.0自定義了TraceID的生成規(guī)則;在生成TraceID時,會把當(dāng)前時間戳秒數(shù)的16進(jìn)制編碼結(jié)果(占8個字節(jié))作為TraceID的一部分。查詢時只需要解碼TraceId中的時間戳,即可知道應(yīng)該查詢熱集群還是冷集群。
接下來再介紹一下尾部采樣中Bloom Filter的設(shè)計細(xì)節(jié),如下圖所示:
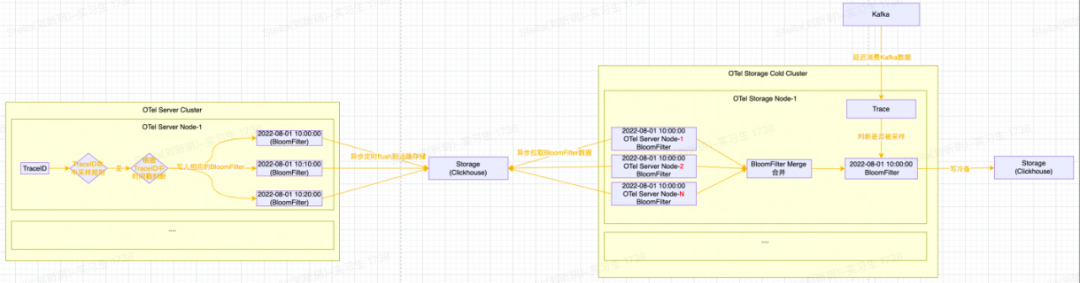
整體處理流程如下:
-
OTel Server會將滿足采樣規(guī)則的Span數(shù)據(jù)對應(yīng)的TraceID,根據(jù)TraceID中的時間戳寫入到對應(yīng)時間戳的Bloom Filter中;
-
Bloom Filter會按十分鐘粒度(可根據(jù)實際的數(shù)據(jù)量并結(jié)合BloomFilter的誤算率和樣本大小計算內(nèi)存消耗并調(diào)整)進(jìn)行分片,十分鐘過后將Bloom Filter進(jìn)行序列化并寫入到ClickHouse存儲中;
-
OTel Storage消費側(cè)拉取Bloom Filter數(shù)據(jù)(注意:同一個時間窗口,每一個OTel Server節(jié)點都會生成一個BloomFilter)并進(jìn)行合并Merge(減少Bloom Filter的內(nèi)存占用并提高Bloom Filter的查詢效率)。
綜上所述,Trace2.0僅使用了較少的資源就完成了尾部采樣和冷熱分層存儲。既為公司節(jié)約了成本,又保存了幾乎所有「有價值」Trace,解決了業(yè)務(wù)研發(fā)日常排查時查詢不到想看的Trace的問題。
3. 自建存儲&降本增效
3.1 基于SLS-Trace的解決方案
Trace2.0建設(shè)初期采用了SLS專為OpenTelemetry定制的Trace方案 【1】 ,提供了Trace查詢、調(diào)用分析、拓?fù)浞治龅裙δ埽缦聢D所示:
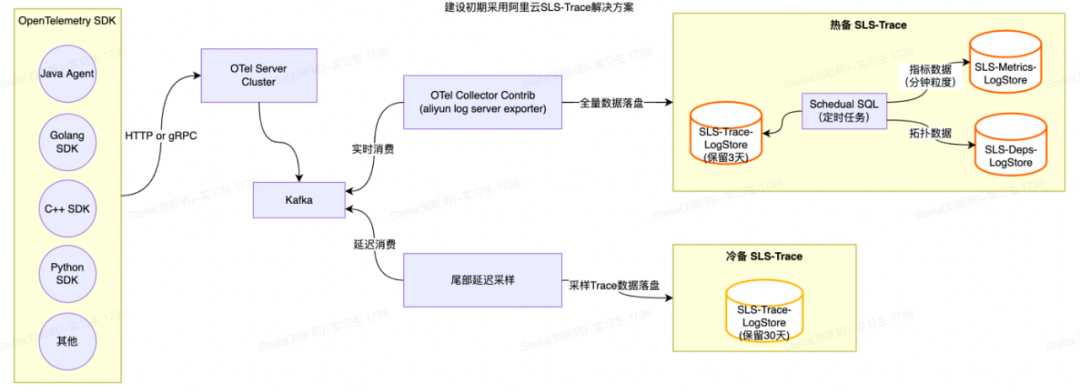
SLS-Trace主要處理流程如下:
-
利用OpenTelemetry Collector aliyunlogserverexporter【2】將Trace數(shù)據(jù)寫入到SLS-Trace Logstore中;
-
SLS-Trace通過默認(rèn)提供的Scheduled SQL任務(wù)定時聚合Trace數(shù)據(jù)并生成相應(yīng)的Span指標(biāo)與應(yīng)用、接口粒度的拓?fù)渲笜?biāo)等數(shù)據(jù)。
隨著Trace2.0在公司內(nèi)部全面鋪開,SLS的存儲成本壓力變得越來越大,為了響應(yīng)公司“利用技術(shù)手段實現(xiàn)降本提效”的號召,我們決定自建存儲。
3.2 基于ClickHouse的解決方案
目前業(yè)內(nèi)比較流行的全鏈路追蹤開源項目(SkyWalking、Pinpoint、Jaeger等)采用的存儲大都是基于ES或者HBase實現(xiàn)的。而近幾年新興的開源全鏈路追蹤開源項目( Uptrace 【3】 、 Signoz 【4】 等)采用的存儲大都是基于ClickHouse實現(xiàn)的,同時將Span數(shù)據(jù)清洗出來的指標(biāo)數(shù)據(jù)也存儲在ClickHouse中。且ClickHouse的物化視圖(很好用)也很好地解決了指標(biāo)數(shù)據(jù)降采樣(DownSampling)的問題。最終經(jīng)過一番調(diào)研,我們決定基于ClickHouse來自建新的存儲解決方案。整體架構(gòu)圖如下:
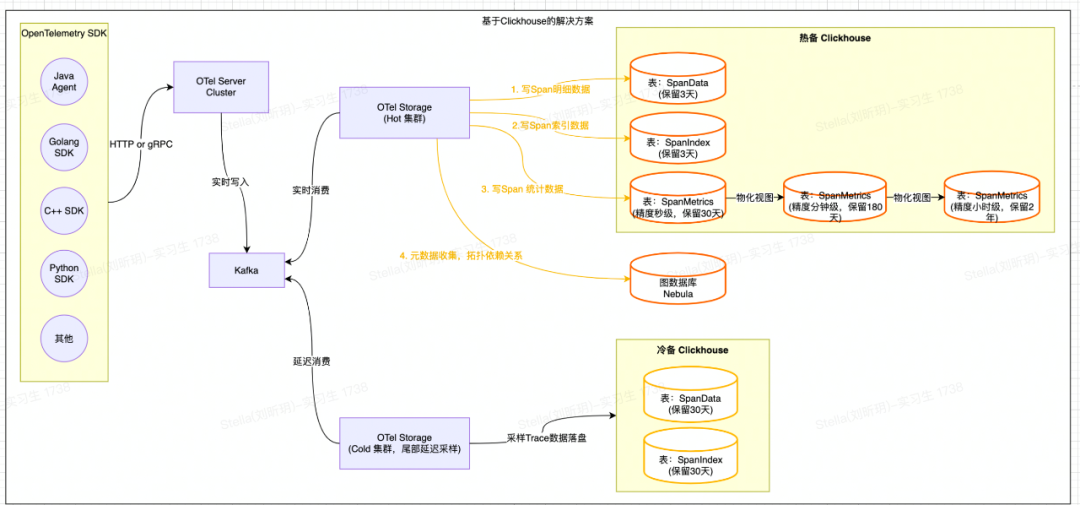
整體處理流程如下:
-
Trace索引&明細(xì)數(shù)據(jù):OTel Storage會將基于Span原始數(shù)據(jù)構(gòu)建的索引數(shù)據(jù)寫入到SpanIndex表中,將Span原始明細(xì)數(shù)據(jù)寫入到SpanData表中(相關(guān)表設(shè)計可以參考 Uptrace 【5】 );
-
計算&持久化SpanMetrics數(shù)據(jù):OTel Storage會根據(jù)Span的Service、SpanName、Host、StatusCode等屬性統(tǒng)計并生成「30秒」粒度的總調(diào)用次數(shù)、總耗時、最大耗時、最小耗時、分位線等指標(biāo)數(shù)據(jù),并寫入到SpanMetrics表;
-
指標(biāo)DownSampling功能:利用ClickHouse的物化視圖將「秒級」指標(biāo)聚合成「分鐘級」指標(biāo),再將「分鐘級」指標(biāo)聚合成「小時級」指標(biāo);從而實現(xiàn)多精度的指標(biāo)以滿足不同時間范圍的查詢需求;
-
-- span_metrics_10m_mvCREATE MATERIALIZED VIEW IF NOT EXISTS '{database}'.span_metrics_10m_mv_localon cluster '{cluster}'TO '{database}'.span_metrics_10m_localASSELECT a.serviceName as serviceName,a.spanName as spanName,a.kind as kind,a.statusCode as statusCode,toStartOfTenMinutes(a.timeBucket) as timeBucket,sum(a.count) as count,sum(a.timeSum) as timeSum,max(a.timeMax) as timeMax,min(a.timeMin) as timeMinFROM '{database}'.span_metrics_30s_local as aGROUP BY a.serviceName, a.spanName, a.kind, a.statusCode,toStartOfTenMinutes(a.timeBucket);
-
元數(shù)據(jù)(上下游拓?fù)鋽?shù)據(jù)):OTel Storage根據(jù)Span屬性中的上下游關(guān)系(需要在客戶端埋相關(guān)屬性),將拓?fù)湟蕾囮P(guān)系寫入到圖數(shù)據(jù)庫Nebula中。
-
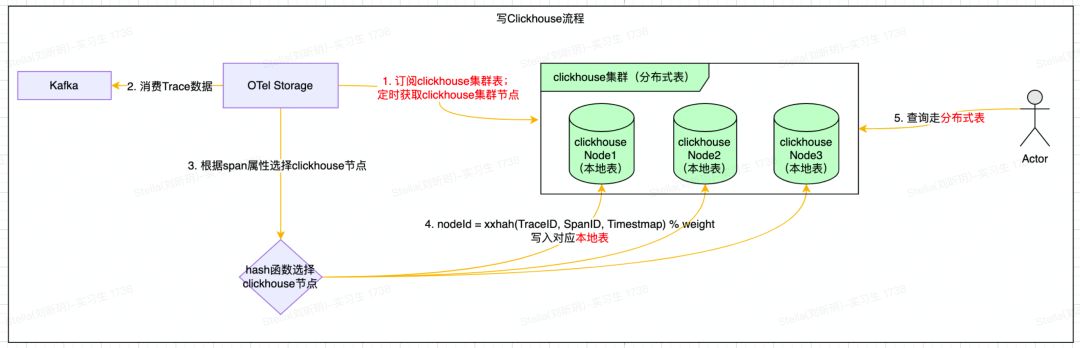
ClickHouse寫入細(xì)節(jié)
ClickHouse使用Distributed引擎實現(xiàn)了Distributed(分布式)表機制,可以在所有分片(本地表)上建立視圖,實現(xiàn)分布式查詢。并且Distributed表自身不會存儲任何數(shù)據(jù),它會通過讀取或?qū)懭肫渌h(yuǎn)端節(jié)點的表來進(jìn)行數(shù)據(jù)處理。SpanData表創(chuàng)建語句如下所示:
-- span_dataCREATE TABLE IF NOT EXISTS '{database}'.span_data_local ON CLUSTER '{cluster}'(traceID FixedString(32),spanID FixedString(16),startTime DateTime64(6 ) Codec (Delta, Default),body String CODEC (ZSTD(3))) ENGINE = MergeTreeORDER BY (traceID,startTime,spanID)PARTITION BY toStartOfTenMinutes(startTime)TTL toDate(startTime) + INTERVAL '{TTL}' HOUR;
-- span_data_distributedCREATE TABLE IF NOT EXISTS '{database}'.span_data_all ON CLUSTER '{cluster}'as '{database}'.span_data_localENGINE = Distributed('{cluster}', '{database}', span_data_local,xxHash64(concat(traceID,spanID,toString(toDateTime(startTime,6)))));
整體寫入流程比較簡單(注意:避免使用分布式表),如下所示:
-
定時獲取ClickHouse集群節(jié)點;
-
通過Hash函數(shù)選擇對應(yīng)的ClickHouse節(jié)點,然后批量寫ClickHouse的本地表。
-
上線效果
全鏈路追蹤是一個典型的寫多讀少的場景,因此我們采用了ClickHouse ZSTD壓縮算法對數(shù)據(jù)進(jìn)行了壓縮,壓縮后的壓縮比高達(dá)12,效果非常好。目前ClickHouse冷熱集群各使用數(shù)十臺16C64G ESSD機器,單機寫入速度25w/s(ClickHouse寫入的行數(shù))。相比于初期的阿里云SLS-Trace方案,存儲成本下降66%,查詢速度也從800+ms下降至490+ms。
-
下一步規(guī)劃
目前Trace2.0將Span的原始明細(xì)數(shù)據(jù)也存儲在了ClickHouse中,導(dǎo)致ClickHouse的磁盤使用率會有些偏高,后續(xù)考慮將Span明細(xì)數(shù)據(jù)先寫入HDFS/OSS等塊存儲設(shè)備中,ClickHouse來記錄每個Span在塊存儲中的offset,從而進(jìn)一步降低ClickHouse的存儲成本。
關(guān)于我們:
得物監(jiān)控團隊提供一站式的可觀測性平臺,負(fù)責(zé)鏈路追蹤、時序數(shù)據(jù)庫、日志系統(tǒng),包括自定義大盤、應(yīng)用大盤、業(yè)務(wù)監(jiān)控、智能告警、AIOPS等排障分析。
歡迎對可觀測性/監(jiān)控/告警/AIOPS 等領(lǐng)域感興趣的同學(xué)加入我們。
引用
【1】 SLS-Trace方案
https://developer.aliyun.com/article/785854
【2】 SLS-Trace Contrib
https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/exporter/alibabacloudlogserviceexporter
【3】Uptrace
https://uptrace.dev/
【4】Signoz
https://signoz.io/
【5】Uptrace Schema設(shè)計
https://github.com/uptrace/uptrace/tree/v0.2.16/pkg/bunapp/migrations
往期推薦
技術(shù)閱讀周刊第十四期:Golang 作者 Rob Pike 在 GopherConAU 上的分享
請注意,你的 Pulsar 集群可能有刪除數(shù)據(jù)的風(fēng)險
 點分享
點分享
 點收藏
點收藏
 點點贊
點點贊
 點在看
點在看