AIGC時(shí)代的視頻擴(kuò)散模型,復(fù)旦等團(tuán)隊(duì)發(fā)布領(lǐng)域首篇綜述
來源:機(jī)器之心
AI 生成內(nèi)容已經(jīng)成為當(dāng)前人工智能領(lǐng)域的最熱門話題之一,也代表著該領(lǐng)域的前沿技術(shù)。近年來,隨著 Stable Diffusion、DALL-E3、ControlNet 等新技術(shù)的發(fā)布,AI 圖像生成和編輯領(lǐng)域?qū)崿F(xiàn)了令人驚艷的視覺效果,并且在學(xué)術(shù)界和工業(yè)界都受到了廣泛關(guān)注和探討。這些方法大多基于擴(kuò)散模型,而這正是它們能夠?qū)崿F(xiàn)強(qiáng)大可控生成、照片級(jí)生成以及多樣性的關(guān)鍵所在。
然而,與簡單的靜態(tài)圖像相比,視頻具有更為豐富的語義信息和動(dòng)態(tài)變化。視頻能夠展示實(shí)物的動(dòng)態(tài)演變過程,因此在視頻生成和編輯領(lǐng)域的需求和挑戰(zhàn)更為復(fù)雜。盡管在這個(gè)領(lǐng)域,受限于標(biāo)注數(shù)據(jù)和計(jì)算資源的限制,視頻生成的研究一直面臨困難,但是一些代表性的研究工作,比如 Make-A-Video、Imagen Video 和 Gen-2 等方法,已經(jīng)開始逐漸占據(jù)主導(dǎo)地位。
這些研究工作引領(lǐng)著視頻生成和編輯技術(shù)的發(fā)展方向。研究數(shù)據(jù)顯示,自從 2022 年以來,關(guān)于擴(kuò)散模型在視頻任務(wù)上的研究工作呈現(xiàn)出爆炸式增長的態(tài)勢。這種趨勢不僅體現(xiàn)了視頻擴(kuò)散模型在學(xué)術(shù)界和工業(yè)界的受歡迎程度,同時(shí)也凸顯了該領(lǐng)域的研究者們對(duì)于視頻生成技術(shù)不斷突破和創(chuàng)新的迫切需求。
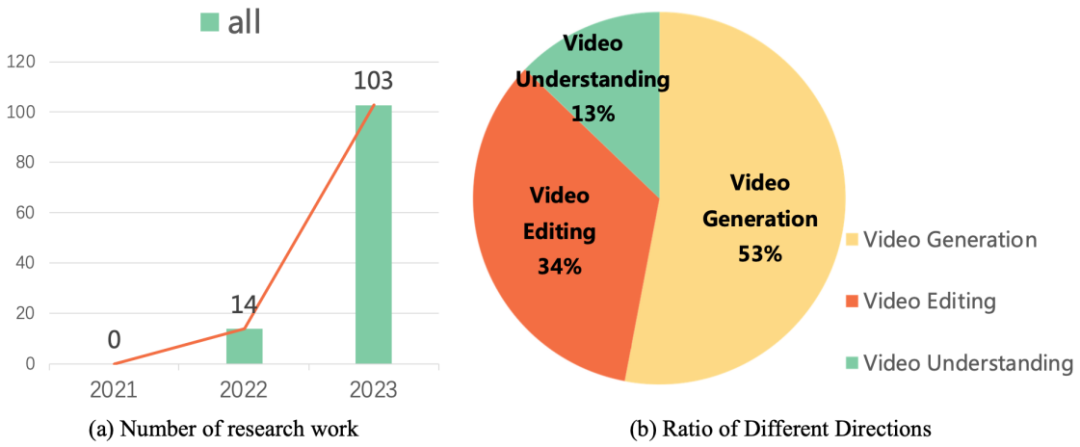
近期,復(fù)旦大學(xué)視覺與學(xué)習(xí)實(shí)驗(yàn)室聯(lián)合微軟、華為等學(xué)術(shù)機(jī)構(gòu)發(fā)布了首個(gè)關(guān)于擴(kuò)散模型在視頻任務(wù)工作的綜述,系統(tǒng)梳理了擴(kuò)散模型在視頻生成、視頻編輯以及視頻理解等方向的學(xué)術(shù)前沿成果。

論文鏈接:https://arxiv.org/abs/2310.10647
主頁鏈接:https://github.com/ChenHsing/Awesome-Video-Diffusion-Models
視頻生成
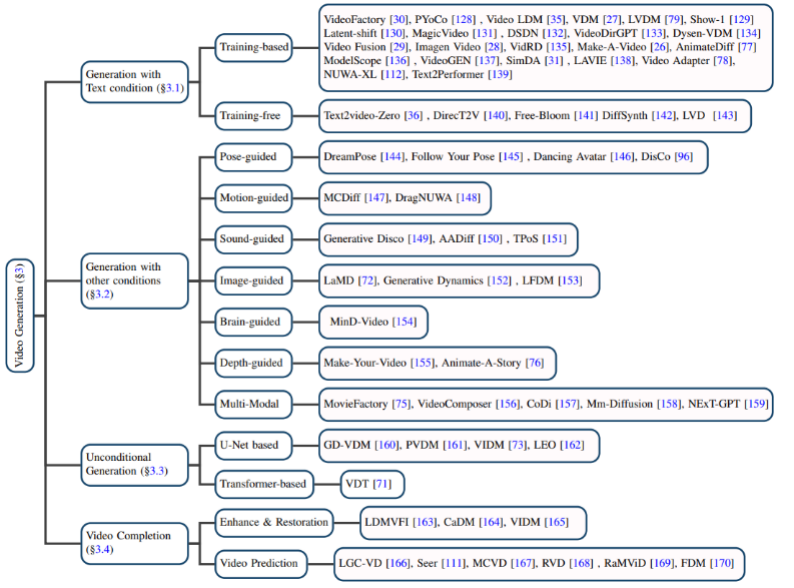
基于文本的視頻生成:自然語言作為輸入的視頻生成是視頻生成領(lǐng)域最為重要的任務(wù)之一。作者首先回顧了擴(kuò)散模型提出之前該領(lǐng)域的研究成果,然后分別介紹了基于訓(xùn)練的和無需訓(xùn)練的文本 - 視頻生成模型。

Christmas tree holiday celebration winter snow animation.
基于其他條件的視頻生成:細(xì)分領(lǐng)域的視頻生成工作。作者將它們歸類為基于以下的條件:姿勢(pose-guided)、動(dòng)作(motion-guided)、聲音(sound-guided)、圖像(image-guided)、深度圖(depth-guided)等。


無條件的視頻生成:該任務(wù)指的是在特定領(lǐng)域中無需輸入條件的視頻生成,作者根據(jù)模型架構(gòu)主要分為基于 U-Net 和基于 Transformer 的生成模型。
視頻補(bǔ)全:主要包括視頻增強(qiáng)和恢復(fù)、視頻預(yù)測等任務(wù)。
數(shù)據(jù)集:視頻生成任務(wù)所用到的數(shù)據(jù)集可分為以下兩類:
1.Caption-level:每個(gè)視頻都有與之對(duì)應(yīng)的文本描述信息,最具代表性的就是 WebVid10M 數(shù)據(jù)集。
2.Category-level:視頻只有分類標(biāo)簽而沒有文本描述信息,UCF-101 是目前在視頻生成、視頻預(yù)測等任務(wù)上最常用的數(shù)據(jù)集。
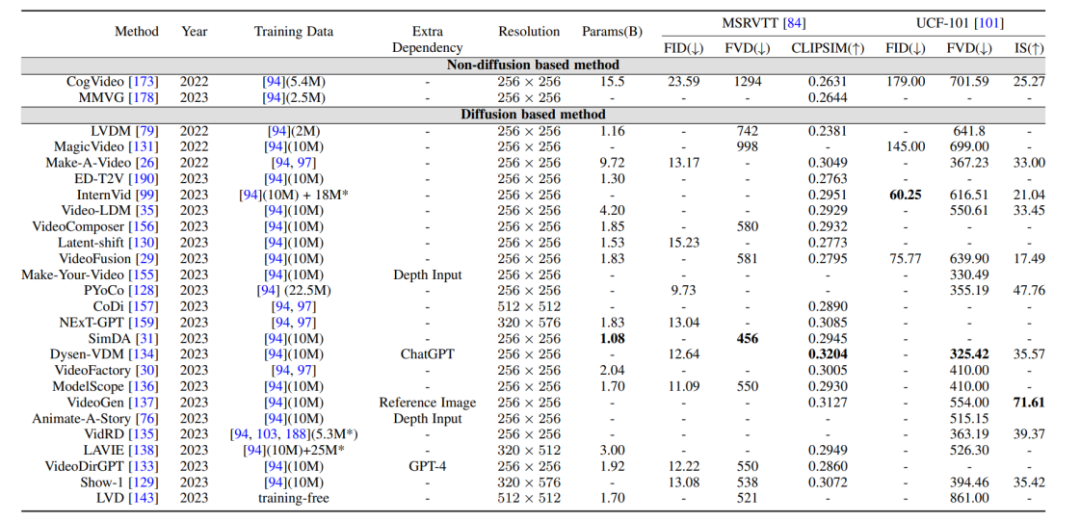
評(píng)價(jià)指標(biāo)與結(jié)果對(duì)比:視頻生成的評(píng)價(jià)指標(biāo)主要分為質(zhì)量層面的評(píng)價(jià)指標(biāo)和定量層面的評(píng)價(jià)指標(biāo),質(zhì)量層面的評(píng)價(jià)指標(biāo)主要是基于人工主觀打分的方式,而定量層面的評(píng)價(jià)指標(biāo)又可以分為:
1. 圖像層面的評(píng)價(jià)指標(biāo):視頻是由一系列的圖像幀所組成的,因此圖像層面的評(píng)估方式基本上參照 T2I 模型的評(píng)價(jià)指標(biāo)。
2. 視頻層面的評(píng)價(jià)指標(biāo):相比于圖像層面的評(píng)價(jià)指標(biāo)更偏向于逐幀的衡量,視頻層面的評(píng)價(jià)指標(biāo)能夠衡量生成視頻的時(shí)序連貫性等方面。
此外,作者還將前述提到的生成模型在基準(zhǔn)數(shù)據(jù)集上的評(píng)價(jià)指標(biāo)進(jìn)行了橫向比較。
視頻編輯
通過對(duì)許多研究的梳理,作者發(fā)現(xiàn)視頻編輯任務(wù)的核心目標(biāo)在于實(shí)現(xiàn):
1. 保真度(fidelity):編輯后的視頻的對(duì)應(yīng)幀應(yīng)當(dāng)與原視頻在內(nèi)容上保持一致。
2. 對(duì)齊性(alignment):編輯后的視頻需要和輸入的條件保持對(duì)齊。
3. 高質(zhì)量(high quality):編輯后的視頻應(yīng)當(dāng)是連貫且高質(zhì)量的。
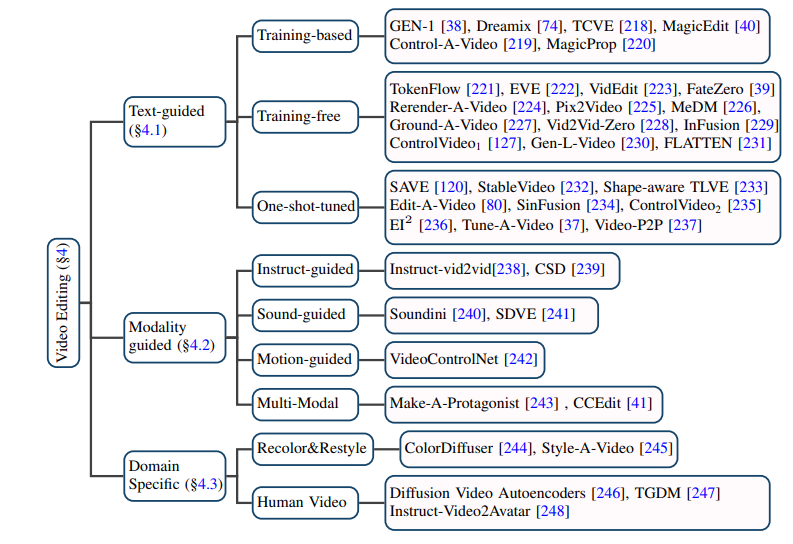
基于文本的視頻編輯:考慮到現(xiàn)有文本 - 視頻數(shù)據(jù)規(guī)模有限,目前大多數(shù)基于文本的視頻編輯任務(wù)都傾向于利用預(yù)訓(xùn)練的 T2I 模型,在此基礎(chǔ)上解決視頻幀的連貫性和語義不一致性等問題。作者進(jìn)一步將此類任務(wù)細(xì)分為基于訓(xùn)練的(training-based)、無需訓(xùn)練的(training-free)和一次性調(diào)優(yōu)的(one-shot tuned)方法,分別加以總結(jié)。


基于其他條件的視頻編輯:隨著大模型時(shí)代的到來,除了最為直接的自然語言信息作為條件的視頻編輯,由指令、聲音、動(dòng)作、多模態(tài)等作為條件的視頻編輯正受到越來越多的關(guān)注,作者也對(duì)相應(yīng)的工作進(jìn)行了分類梳理。
特定細(xì)分領(lǐng)域的視頻編輯:一些工作關(guān)注到在特定領(lǐng)域?qū)σ曨l編輯任務(wù)有特殊定制化的需求,例如視頻著色、人像視頻編輯等。
視頻理解
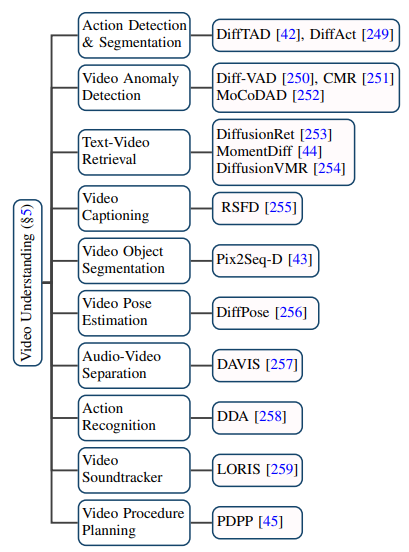
擴(kuò)散模型在視頻領(lǐng)域的應(yīng)用已遠(yuǎn)不止傳統(tǒng)的視頻生成和編輯任務(wù),它在視頻理解任務(wù)上也展現(xiàn)了出巨大的潛能。通過對(duì)前沿論文的追蹤,作者歸納了視頻時(shí)序分割、視頻異常檢測、視頻物體分割、文本視頻檢索、動(dòng)作識(shí)別等 10 個(gè)現(xiàn)有的應(yīng)用場景。
未來與總結(jié)
該綜述全面細(xì)致地總結(jié)了 AIGC 時(shí)代擴(kuò)散模型在視頻任務(wù)上的最新研究,根據(jù)研究對(duì)象和技術(shù)特點(diǎn),將百余份前沿工作進(jìn)行了分類和概述,在一些經(jīng)典的基準(zhǔn)(benchmark)上對(duì)這些模型進(jìn)行比較。此外,擴(kuò)散模型在視頻任務(wù)領(lǐng)域也還有一些新的研究方向和挑戰(zhàn),如:
1. 大規(guī)模的文本 - 視頻數(shù)據(jù)集收集:T2I 模型的成功離不開數(shù)以億計(jì)高質(zhì)量的文本 - 圖像數(shù)據(jù)集,同樣地,T2V 模型也需要大量無水印、高分辨率的文本 - 視頻數(shù)據(jù)作為支撐。
2. 高效的訓(xùn)練和推理:視頻數(shù)據(jù)相比于圖像數(shù)據(jù)規(guī)模巨大,在訓(xùn)練和推理階段所需要的算力也呈幾何倍數(shù)增加,高效的訓(xùn)練和推理算法能極大地降低成本。
3. 可靠的基準(zhǔn)和評(píng)價(jià)指標(biāo):現(xiàn)有視頻領(lǐng)域的評(píng)價(jià)指標(biāo)往往在于衡量生成視頻與原視頻在分布上的差異,而未能全面衡量生成視頻的質(zhì)量。同時(shí),目前用戶測試仍然是重要的評(píng)估方式之一,考慮到其需要大量人力且主觀性強(qiáng),因此迫切需要更為客觀全面的評(píng)價(jià)指標(biāo)。
——The End——

分享
收藏
點(diǎn)贊
在看