
擴(kuò)散模型爆火!這是首篇綜述
本文首次對(duì)現(xiàn)有的擴(kuò)散生成模型(diffusion model)進(jìn)行了全面的總結(jié)分析,還在Github分類匯總了相關(guān)論文。


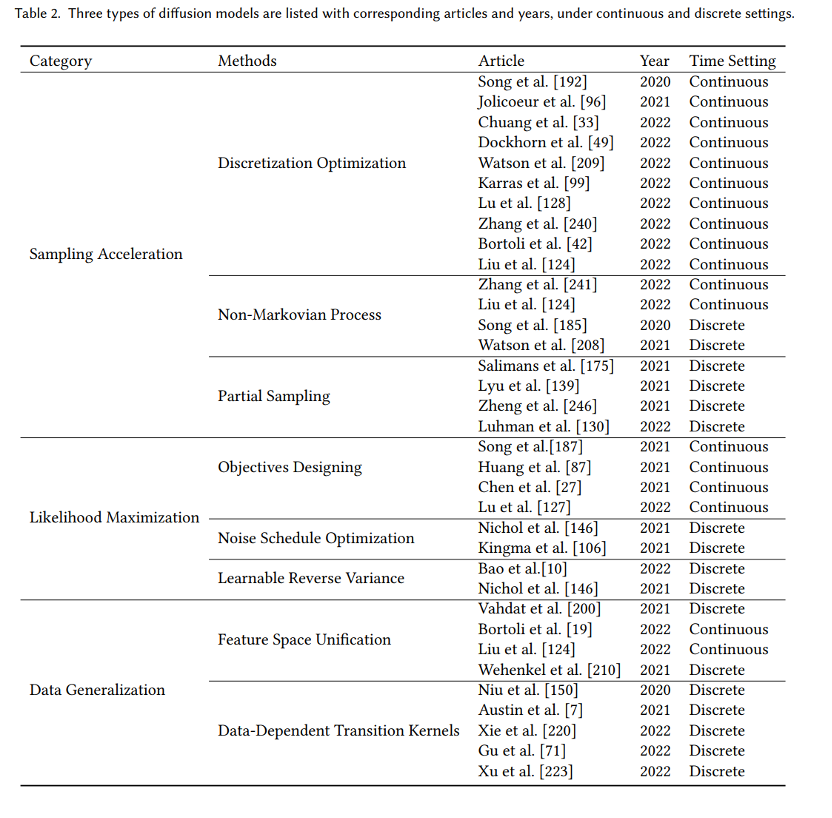
新的分類方法:我們對(duì)擴(kuò)散模型和其應(yīng)用提出了一種新的、系統(tǒng)的分類法。具體的我們將模型分為三類:采樣速度增強(qiáng)、最大似然估計(jì)增強(qiáng)、數(shù)據(jù)泛化增強(qiáng)。進(jìn)一步地,我們將擴(kuò)散模型的應(yīng)用分為七類:計(jì)算機(jī)視覺(jué),NLP、波形信號(hào)處理、多模態(tài)建模、分子圖建模、時(shí)間序列建模、對(duì)抗性凈化。 全面的回顧:我們首次全面地概述了現(xiàn)代擴(kuò)散模型及其應(yīng)用。我們展示了每種擴(kuò)散模型的主要改進(jìn),和原始模型進(jìn)行了必要的比較,并總結(jié)了相應(yīng)的論文。對(duì)于擴(kuò)散模型的每種類型的應(yīng)用,我們展示了擴(kuò)散模型要解決的主要問(wèn)題,并說(shuō)明它們?nèi)绾谓鉀Q這些問(wèn)題。 未來(lái)研究方向:我們對(duì)未來(lái)研究提出了開(kāi)放型問(wèn)題,并對(duì)擴(kuò)散模型在算法和應(yīng)用方面的未來(lái)發(fā)展提供了一些建議。
 表示原始數(shù)據(jù)及其分布, 則前向鏈的分布是可由下式表達(dá):
表示原始數(shù)據(jù)及其分布, 則前向鏈的分布是可由下式表達(dá):
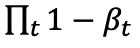 趨于 1 時(shí),x_T 可以近似認(rèn)為服從標(biāo)準(zhǔn)高斯分布。當(dāng)β_t 很小時(shí),逆向過(guò)程的轉(zhuǎn)移核可以近似認(rèn)為也是高斯的:
趨于 1 時(shí),x_T 可以近似認(rèn)為服從標(biāo)準(zhǔn)高斯分布。當(dāng)β_t 很小時(shí),逆向過(guò)程的轉(zhuǎn)移核可以近似認(rèn)為也是高斯的: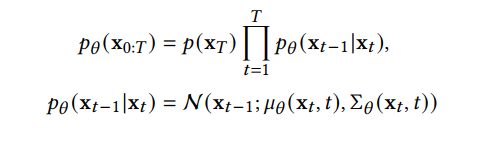
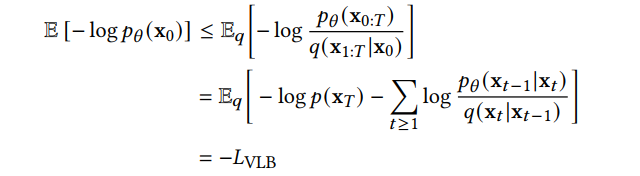
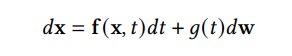
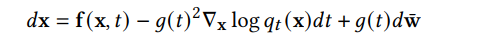
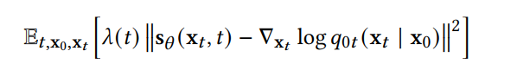
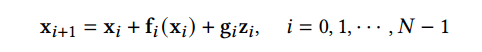
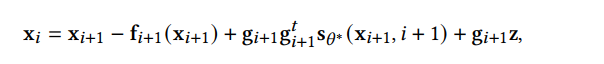
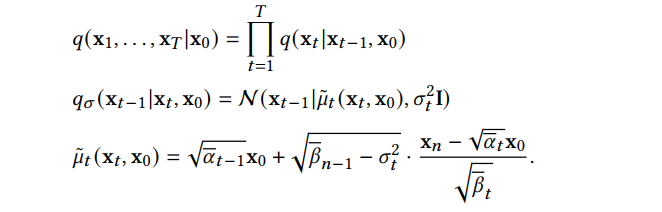

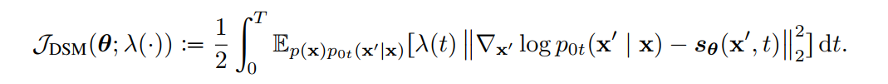
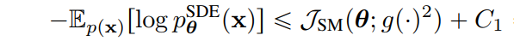
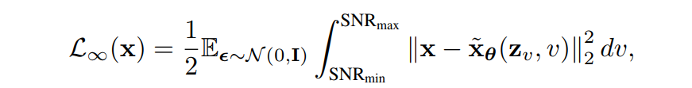



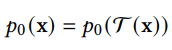
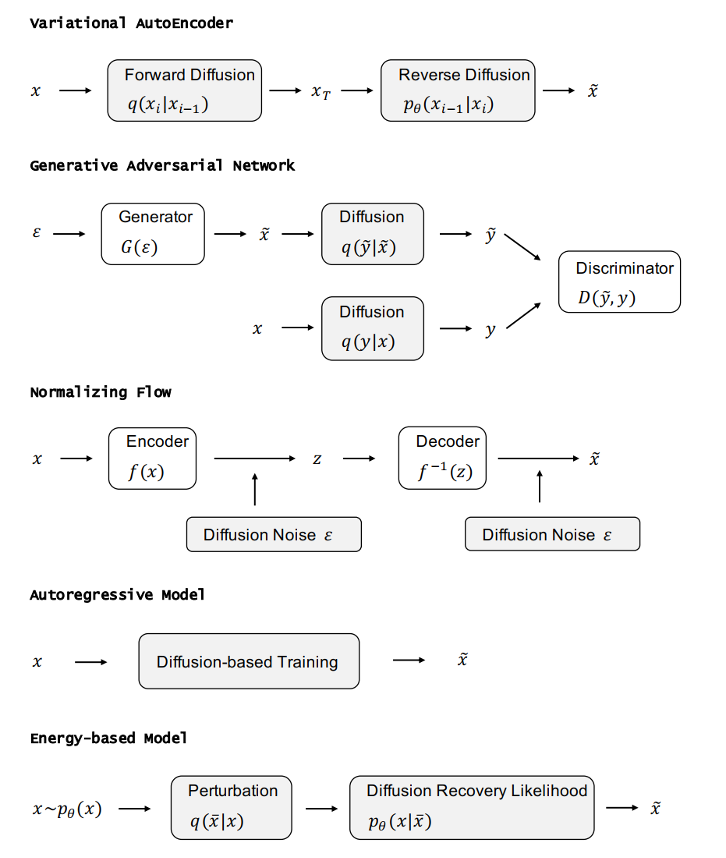
DDPM 可以視作層次馬爾可夫 VAE(hierarchical Markovian VAE)。但 DDPM 和一般的 VAE 也有區(qū)別。DDPM 作為 VAE,它的 encoder 和 decoder 都服從高斯分布、有馬爾科夫行;其隱變量的維數(shù)和數(shù)據(jù)維數(shù)相同;decoder 的所有層都共用一個(gè)神經(jīng)網(wǎng)絡(luò)。 DDPM 可以幫助 GAN 解決訓(xùn)練不穩(wěn)定的問(wèn)題。因?yàn)閿?shù)據(jù)是在高維空間中的低維流形中,所以 GAN 生成數(shù)據(jù)的分布和真實(shí)數(shù)據(jù)的分布重合度低,導(dǎo)致訓(xùn)練不穩(wěn)定。擴(kuò)散模型提供了一個(gè)系統(tǒng)地增加噪音的過(guò)程,通過(guò)擴(kuò)散模型向生成的數(shù)據(jù)和真實(shí)數(shù)據(jù)添加噪音,然后將加入噪音的數(shù)據(jù)送入判別器,這樣可以高效地解決 GAN 無(wú)法訓(xùn)練、訓(xùn)練不穩(wěn)定的問(wèn)題。 Normalizing flow 通過(guò)雙射函數(shù)將數(shù)據(jù)轉(zhuǎn)換到先驗(yàn)分布,這樣的作法限制了 Normalizing flow 的表達(dá)能力,導(dǎo)致應(yīng)用效果較差。類比擴(kuò)散模型向 encoder 中加入噪聲,可以增加 Normalizing flow 的表達(dá)能力,而從另一個(gè)視角看,這樣的做法是將擴(kuò)散模型推廣到前向過(guò)程也可學(xué)習(xí)的模型。 Autoregressive model 在需要保證數(shù)據(jù)有一定的結(jié)構(gòu),這導(dǎo)致設(shè)計(jì)和參數(shù)化自回歸模型非常困難。擴(kuò)散模型的訓(xùn)練啟發(fā)了自回歸模型的訓(xùn)練,通過(guò)特定的訓(xùn)練方式避免了設(shè)計(jì)的困難。 Energy-based model 直接對(duì)原始數(shù)據(jù)的分布建模,但直接建模導(dǎo)致學(xué)習(xí)和采樣都比較困難。通過(guò)使用擴(kuò)散恢復(fù)似然,模型可以先對(duì)樣本加入微小的噪聲,再?gòu)挠新晕⒃肼暤臉颖痉植紒?lái)推斷原始樣本的分布,使的學(xué)習(xí)和采樣過(guò)程更簡(jiǎn)單和穩(wěn)定。




應(yīng)用假設(shè)再檢驗(yàn)。我們需要檢查我們?cè)趹?yīng)用中普遍接受的假設(shè)。例如,實(shí)踐中普遍認(rèn)為擴(kuò)散模型的前向過(guò)程會(huì)將數(shù)據(jù)轉(zhuǎn)換為標(biāo)準(zhǔn)高斯分布,但事實(shí)并非如此,更多的前向擴(kuò)散步驟會(huì)使最終的樣本分布與標(biāo)準(zhǔn)高斯分布更接近,與采樣過(guò)程一致;但更多的前向擴(kuò)散步驟也會(huì)使估計(jì)分?jǐn)?shù)函數(shù)更加困難。理論的條件很難獲得,因此在實(shí)踐中操作中會(huì)導(dǎo)致理論和實(shí)踐的不匹配。我們應(yīng)該意識(shí)到這種情況并設(shè)計(jì)適當(dāng)?shù)臄U(kuò)散模型。 從離散時(shí)間到連續(xù)時(shí)間。由于擴(kuò)散模型的靈活性,許多經(jīng)驗(yàn)方法可以通過(guò)進(jìn)一步分析得到加強(qiáng)。通過(guò)將離散時(shí)間的模型轉(zhuǎn)化到對(duì)應(yīng)的連續(xù)時(shí)間模型,然后再設(shè)計(jì)更多、更好的離散方法,這樣的研究思路有前景。 新的生成過(guò)程。擴(kuò)散模型通過(guò)兩種主要方法生成樣本:一是離散化反向擴(kuò)散 SDE,然后通過(guò)離散的反向 SDE 生成樣本;另一個(gè)是使用逆過(guò)程中馬爾可夫性質(zhì)對(duì)樣本逐步去噪。然而,對(duì)于一些任務(wù),在實(shí)踐中很難應(yīng)用這些方法來(lái)生成樣本。因此,需要進(jìn)一步研究新的生成過(guò)程和視角。 泛化到更復(fù)雜的場(chǎng)景和更多的研究領(lǐng)域。雖然目前 diffusion model 已經(jīng)應(yīng)用到多個(gè)場(chǎng)景中,但是大多數(shù)局限于單輸入單輸出的場(chǎng)景,將來(lái)可以考慮將其應(yīng)用到更復(fù)雜的場(chǎng)景,比如 text-to-audiovisual speech synthesis。也可以考慮和更多的研究領(lǐng)域相結(jié)合。
“整理不易,點(diǎn)贊三連↓
評(píng)論
圖片
表情