本文約5000字,建議閱讀10分鐘
本文將介紹如何為成功的面試做準(zhǔn)備的,以及可以幫助我們面試的一些資源。
在這篇文章中,將介紹如何為成功的面試做準(zhǔn)備的,以及可以幫助我們面試的一些資源。
代碼開發(fā)基礎(chǔ)
如果你是數(shù)據(jù)科學(xué)家或軟件開發(fā)人員,那么應(yīng)該已經(jīng)知道一些 Python 和 SQL 的基本知識(shí),這對(duì)數(shù)據(jù)科學(xué)家的面試已經(jīng)足夠了,因?yàn)榇蠖鄶?shù)的公司基本上是這樣的——但是,在你的簡(jiǎn)歷中加入 Spark 是一個(gè)很好的加分項(xiàng)。對(duì)于 SQL,你應(yīng)該知道一些最簡(jiǎn)單的操作,例如:- 連接兩個(gè)表(內(nèi)連接、左連接、右連接和外連接)
- 匯總結(jié)果(總和、平均值、最大值、最小值)
- 處理df(pandas),例如讀取、加入、合并、過濾
- 操作字符串,例如使用正則表達(dá)式、搜索字符串包含的內(nèi)容
- 在 Python 中創(chuàng)建函數(shù)和類
在你的編程面試中,掌握 SQL 和 Python 是很重要的。了解數(shù)據(jù)結(jié)構(gòu)和算法
這是一個(gè)重要的問題,可能不像對(duì)軟件開發(fā)人員那么重要,但是對(duì)數(shù)據(jù)結(jié)構(gòu)和算法有很好的理解肯定會(huì)讓你與眾不同。以下是一個(gè)好的開始:下面進(jìn)入本文的正題,將介紹一些基本的ML面試相關(guān)資料,可以作為筆記收藏。線性回歸
我關(guān)于線性回歸的大部分筆記都是基于《統(tǒng)計(jì)學(xué)習(xí)導(dǎo)論》這本書。
Logistic 回歸
它是一種廣泛使用的技術(shù),因?yàn)樗浅8咝В恍枰嘤?jì)算資源,高度可解釋,不需要縮放輸入特征,不需要任何調(diào)整,易于正則化,并且它輸出經(jīng)過良好校準(zhǔn)的預(yù)測(cè)概率。與線性回歸一樣,當(dāng)刪除與輸出變量無關(guān)的屬性以及彼此非常相似(相關(guān))的屬性時(shí),邏輯回歸的效果會(huì)更好。所以特征工程在邏輯和線性回歸的性能方面起著重要作用。Logistic 回歸的另一個(gè)優(yōu)點(diǎn)是,它非常容易實(shí)現(xiàn)并且訓(xùn)練效率很高。我通常從邏輯回歸模型作為基準(zhǔn)開始,然后嘗試使用更復(fù)雜的算法。由于其簡(jiǎn)單性以及可以相對(duì)容易和快速地實(shí)現(xiàn)的事實(shí),邏輯回歸是一個(gè)很好的基準(zhǔn)可以使用它來衡量其他更復(fù)雜算法的性能。它的一個(gè)最主要的缺點(diǎn)是我們不能用它解決非線性問題,因?yàn)樗臎Q策面是線性的。邏輯回歸的假設(shè):首先,邏輯回歸不需要因變量和自變量之間的線性關(guān)系。其次,誤差項(xiàng)(殘差)不需要服從正態(tài)分布。第三,不需要同方差性。最后,邏輯回歸中的因變量不是在區(qū)間或比率尺度上測(cè)量的。首先,二元邏輯回歸要求因變量是二元的,而序數(shù)邏輯回歸要求因變量為序數(shù)。其次,邏輯回歸要求觀察結(jié)果彼此獨(dú)立。換言之,觀察結(jié)果不應(yīng)來自重復(fù)測(cè)量或匹配數(shù)據(jù)。第三,邏輯回歸要求自變量之間很少或沒有多重共線性。這意味著自變量之間的相關(guān)性不應(yīng)太高。第四,邏輯回歸假設(shè)自變量和對(duì)數(shù)幾率是線性的。雖然這種分析不要求因變量和自變量線性相關(guān),但它要求自變量與對(duì)數(shù)幾率線性相關(guān)。最后,邏輯回歸通常需要大樣本量。對(duì)于模型中的每個(gè)自變量,一般情況下至少需要 10 個(gè)結(jié)果頻率最低的樣本。聚類
使用 GMM 有兩個(gè)好處。首先,GMM 在集群協(xié)方差方面比 K-Means 靈活得多;由于標(biāo)準(zhǔn)偏差參數(shù),簇可以呈現(xiàn)任何橢圓形狀,而不是僅限于圓形。K-Means 實(shí)際上是 GMM 的一種特殊情況,其中每個(gè)集群在所有維度上的協(xié)方差都接近 0。其次,由于 GMM 使用概率,因此每個(gè)數(shù)據(jù)點(diǎn)可以屬于多個(gè)簇。因此,如果一個(gè)數(shù)據(jù)點(diǎn)位于兩個(gè)重疊集群的中間,我們可以簡(jiǎn)單地定義它的類,方法是說它屬于類 1 的 X 百分比和屬于類 2 的 Y 百分比。隨機(jī)森林和提升樹
自編碼器
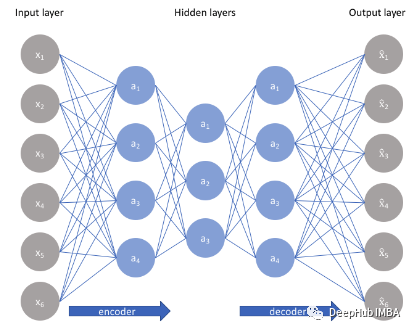
自編碼器是一種無監(jiān)督學(xué)習(xí)技術(shù),利用神經(jīng)網(wǎng)絡(luò)來完成表示學(xué)習(xí)的任務(wù)。具體來說,設(shè)計(jì)一個(gè)神經(jīng)網(wǎng)絡(luò)架構(gòu),以便我們?cè)诰W(wǎng)絡(luò)中包含一個(gè)瓶頸層(壓縮),強(qiáng)制原始輸入的壓縮知識(shí)表示。如果輸入特征彼此獨(dú)立,那么這種壓縮和隨后的重建將是一項(xiàng)非常困難的任務(wù)。但是如果數(shù)據(jù)中存在某種結(jié)構(gòu)(即輸入特征之間的相關(guān)性),則可以學(xué)習(xí)這種結(jié)構(gòu),從而在強(qiáng)制輸入通過網(wǎng)絡(luò)瓶頸時(shí)加以利用。如上圖所示,我們可以將一個(gè)未標(biāo)記的數(shù)據(jù)集構(gòu)建為一個(gè)監(jiān)督學(xué)習(xí)問題,其任務(wù)是輸出 x? ,即原始輸入 x 的重建。可以通過最小化重建誤差 (x,x? ) 來訓(xùn)練該網(wǎng)絡(luò),該誤差衡量我們的原始輸入與后續(xù)重建之間的差異。瓶頸層是我們網(wǎng)絡(luò)設(shè)計(jì)的關(guān)鍵屬性;在不存在信息瓶頸的情況下,我們的網(wǎng)絡(luò)可以很容易地學(xué)會(huì)通過網(wǎng)絡(luò)傳遞這些值來簡(jiǎn)單地記住輸入值。注意:事實(shí)上,如果我們要構(gòu)建一個(gè)線性網(wǎng)絡(luò)(即在每一層不使用非線性激活函數(shù)),我們將觀察到與 PCA 中觀察到的相似的降維。因?yàn)樯窠?jīng)網(wǎng)絡(luò)能夠?qū)W習(xí)非線性關(guān)系,這可以被認(rèn)為是比 PCA 更強(qiáng)大的(非線性)泛化。PCA 試圖發(fā)現(xiàn)描述原始數(shù)據(jù)的低維超平面,而自動(dòng)編碼器能夠?qū)W習(xí)非線性流形(流形簡(jiǎn)單地定義為連續(xù)的、不相交的表面)。梯度下降
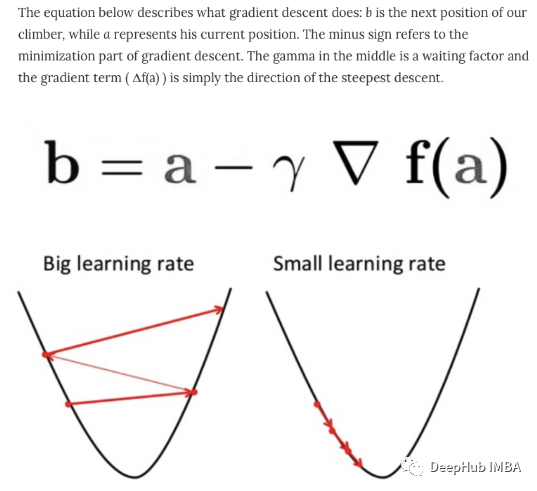
梯度下降是一種用于尋找可微函數(shù)的局部最小值的優(yōu)化算法。梯度下降通過最小化成本函數(shù)的方法找到函數(shù)參數(shù)(系數(shù))的值。這是一個(gè)迭代逼近的過程。梯度只是衡量所有權(quán)重相對(duì)于誤差變化的變化。也可以將梯度視為函數(shù)的斜率。梯度越高,斜率越陡,模型學(xué)習(xí)的速度就越快。但是如果斜率為零,模型就會(huì)停止學(xué)習(xí)。在數(shù)學(xué)術(shù)語中,梯度是關(guān)于其輸入的偏導(dǎo)數(shù)。批量梯度下降:批量梯度下降,也稱為普通梯度下降,計(jì)算訓(xùn)練數(shù)據(jù)集中每個(gè)示例的誤差,但只有在評(píng)估了所有訓(xùn)練示例之后,模型才會(huì)更新。這整個(gè)過程就像一個(gè)循環(huán),稱為一個(gè)訓(xùn)練輪次。批量梯度下降的一些優(yōu)點(diǎn)是它的計(jì)算效率,它產(chǎn)生穩(wěn)定的誤差梯度和穩(wěn)定的收斂。缺點(diǎn)是穩(wěn)定的誤差梯度有時(shí)會(huì)導(dǎo)致收斂狀態(tài)不是模型所能達(dá)到的最佳狀態(tài)。它還要求整個(gè)訓(xùn)練數(shù)據(jù)集都在內(nèi)存中并且可供算法使用。隨機(jī)梯度下降:相比之下,隨機(jī)梯度下降 (SGD) 對(duì)數(shù)據(jù)集中的每個(gè)訓(xùn)練示例執(zhí)行此操作,這意味著它會(huì)一一更新每個(gè)訓(xùn)練示例的參數(shù)。這可以使 SGD 比批量梯度下降更快。但是頻繁更新比批量梯度下降方法的計(jì)算成本更高。每一個(gè)樣本都計(jì)算梯度也會(huì)收到噪聲的影響,導(dǎo)致不是向著梯度的方向移動(dòng)導(dǎo)致訓(xùn)練時(shí)間的增加。小批量梯度下降:小批量梯度下降是首選方法,因?yàn)樗Y(jié)合了 SGD 和批量梯度下降的概念。它只是將訓(xùn)練數(shù)據(jù)集分成小批,并為每個(gè)批執(zhí)行更新。這在隨機(jī)梯度下降的魯棒性和批量梯度下降的效率之間建立了平衡。常見的 mini-batch 大小在 50 到 256 之間,但與任何其他機(jī)器學(xué)習(xí)技術(shù)一樣,沒有明確的規(guī)則,因?yàn)樗虿煌膽?yīng)用程序而異。這是訓(xùn)練神經(jīng)網(wǎng)絡(luò)時(shí)的首選算法,也是深度學(xué)習(xí)中最常見的梯度下降類型。獨(dú)熱編碼與標(biāo)簽編碼
我們應(yīng)該如何處理分類變量呢?事實(shí)證明,有多種處理分類變量的方法。在本文中將討論兩種最廣泛使用的技術(shù):標(biāo)簽編碼是一種用于處理分類變量的流行編碼技術(shù)。在這種技術(shù)中,每個(gè)標(biāo)簽都根據(jù)字母順序分配一個(gè)唯一的整數(shù)。讓我們看看如何使用 scikit-learn 庫在 Python 中實(shí)現(xiàn)標(biāo)簽編碼,并了解標(biāo)簽編碼的挑戰(zhàn)。第一列 Country 是分類特征,因?yàn)樗蓪?duì)象數(shù)據(jù)類型表示,其余的是數(shù)字特征,因?yàn)樗鼈冇?int64 表示。# Import label encoderfrom sklearn import preprocessing# label_encoder object knows how to understand word labels.label_encoder = preprocessing.LabelEncoder()# Encode labels in column ‘Country’.data[‘Country’]= label_encoder.fit_transform(data[‘Country’])print(data.head())
在上述場(chǎng)景中,國家名稱沒有順序或等級(jí)。但是很可能會(huì)因?yàn)閿?shù)字本身導(dǎo)致模型很有可能捕捉到印度<日本<美國等國家之間的關(guān)系,這是不正確的。那么如何才能克服這個(gè)障礙呢?這里出現(xiàn)了 One-Hot Encoding 的概念。One-Hot Encoding 是另一種處理分類變量的流行技術(shù)。它只是根據(jù)分類特征中唯一值的數(shù)量創(chuàng)建附加特征。類別中的每個(gè)唯一值都將作為特征添加。在這種編碼技術(shù)中,每個(gè)類別都表示為一個(gè)單向量。讓我們看看如何在 Python 中實(shí)現(xiàn) one-hot 編碼:# importing one hot encoderfrom sklearn from sklearn.preprocessing import OneHotEncoder# creating one hot encoder objectonehotencoder = OneHotEncoder()#reshape the 1-D country array to 2-D as fit_transform expects 2-D and finally fit the objectX = onehotencoder.fit_transform(data.Country.values.reshape(-1,1)).toarray()#To add this back into the original dataframedfOneHot = pd.DataFrame(X, columns = [“Country_”+str(int(i)) for i in range(data.shape[1])])df = pd.concat([data, dfOneHot], axis=1)#droping the country columndf= df.drop([‘Country’], axis=1)#printing to verifyprint(df.head())
One-Hot Encoding 會(huì)導(dǎo)致虛擬變量陷阱,因?yàn)榭梢越柚溆嘧兞枯p松預(yù)測(cè)一個(gè)變量的結(jié)果。虛擬變量陷阱導(dǎo)致稱為多重共線性的問題。當(dāng)獨(dú)立特征之間存在依賴關(guān)系時(shí),就會(huì)發(fā)生多重共線性。多重共線性是線性回歸和邏輯回歸等機(jī)器學(xué)習(xí)模型中的一個(gè)嚴(yán)重問題。因此,為了克服多重共線性問題,必須刪除其中虛擬變量。下面將實(shí)際演示在執(zhí)行 one-hot 編碼后如何引入多重共線性問題。檢查多重共線性的常用方法之一是方差膨脹因子 (VIF):最后說明:如果使用的樹型模型,使用標(biāo)簽編碼就足夠了,使用線性模型建議還是使用獨(dú)熱編碼。超參數(shù)調(diào)優(yōu)
通常,我們對(duì)最佳超參數(shù)只有一個(gè)模糊的概念,因此縮小搜索范圍的最佳方法是評(píng)估每個(gè)超參數(shù)值。使用 Scikit-Learn 的 RandomizedSearchCV 方法,我們可以定義超參數(shù)范圍的網(wǎng)格,并從網(wǎng)格中隨機(jī)采樣,對(duì)每個(gè)值組合執(zhí)行 K-Fold CV。from sklearn.model_selection import RandomizedSearchCV# Number of trees in random forestn_estimators = [int(x) for x in np.linspace(start = 200, stop = 2000, num = 10)]# Number of features to consider at every splitmax_features = [‘a(chǎn)uto’, ‘sqrt’]# Maximum number of levels in treemax_depth = [int(x) for x in np.linspace(10, 110, num = 11)]max_depth.append(None)# Minimum number of samples required to split a nodemin_samples_split = [2, 5, 10]# Minimum number of samples required at each leaf nodemin_samples_leaf = [1, 2, 4]# Method of selecting samples for training each treebootstrap = [True, False]# Create the random gridrandom_grid = {‘n_estimators’: n_estimators,‘max_features’: max_features,‘max_depth’: max_depth,‘min_samples_split’: min_samples_split,‘min_samples_leaf’: min_samples_leaf,‘bootstrap’: bootstrap}pprint(random_grid){‘bootstrap’: [True, False],‘max_depth’: [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, None],‘max_features’: [‘a(chǎn)uto’, ‘sqrt’],‘min_samples_leaf’: [1, 2, 4],‘min_samples_split’: [2, 5, 10],‘n_estimators’: [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]}# Use the random grid to search for best hyperparameters# First create the base model to tunerf = RandomForestRegressor()# Random search of parameters, using 3 fold cross validation,# search across 100 different combinations, and use all available coresrf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 3, verbose=2, random_state=42, n_jobs = -1)# Fit the random search modelrf_random.fit(train_features, train_labels)
RandomizedSearchCV中最重要的參數(shù)是n_iter,它控制要嘗試的不同組合的數(shù)量,cv是用于交叉驗(yàn)證的分折次數(shù)(我們分別使用100和3)。更多的迭代將覆蓋更大的搜索空間,更多的cv折疊將減少過擬合的機(jī)會(huì),但提高每一個(gè)將增加運(yùn)行時(shí)間。機(jī)器學(xué)習(xí)是一個(gè)權(quán)衡取舍的領(lǐng)域,性能與時(shí)間是最基本的權(quán)衡之一。我們可以通過擬合隨機(jī)搜索來查看最佳參數(shù):rf_random.best_params_{‘bootstrap’: True,‘max_depth’: 70,‘max_features’: ‘a(chǎn)uto’,‘min_samples_leaf’: 4,‘min_samples_split’: 10,‘n_estimators’: 400}
隨機(jī)搜索允許縮小每個(gè)超參數(shù)的范圍。也可以顯式地指定要嘗試的每個(gè)設(shè)置組合。使用GridSearchCV來實(shí)現(xiàn)這一點(diǎn),該方法不是從一個(gè)分布中隨機(jī)抽樣,而是評(píng)估我們定義的所有組合。為了使用網(wǎng)格搜索,我們根據(jù)隨機(jī)搜索提供的最佳值創(chuàng)建另一個(gè)網(wǎng)格:from sklearn.model_selection import GridSearchCV
# Create the parameter grid based on the results of random searchparam_grid = {‘bootstrap’: [True],‘max_depth’: [80, 90, 100, 110],‘max_features’: [2, 3],‘min_samples_leaf’: [3, 4, 5],‘min_samples_split’: [8, 10, 12],‘n_estimators’: [100, 200, 300, 1000]}
# Create a based modelrf = RandomForestRegressor()
# Instantiate the grid search modelgrid_search = GridSearchCV(estimator = rf, param_grid = param_grid,cv = 3, n_jobs = -1, verbose = 2)
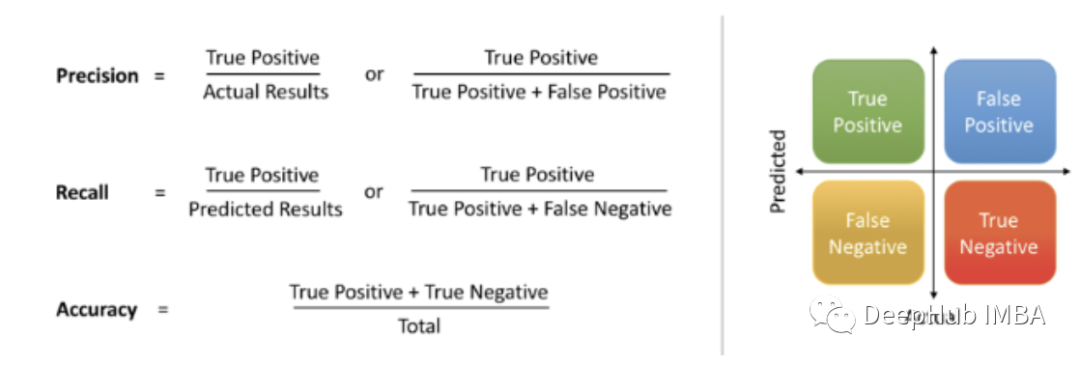
精度和召回
這些指標(biāo)表示了模型在數(shù)據(jù)集中找到所有相關(guān)案例的能力:
損失函數(shù)
在數(shù)學(xué)上,如果目標(biāo)變量的分布是高斯分布,則它是最大似然推理框架下的首選損失函數(shù)。首先要想到并且可以使直接使用損失函數(shù),只有在有充分理由的情況下才建議使用其他的損失函數(shù)。在一些回歸問題中,目標(biāo)變量的分布可能主要是高斯分布,但可能有異常值,例如平均值的大值或小值距離很遠(yuǎn)。在這種情況下,平均絕對(duì)誤差或 MAE 損失是一個(gè)合適的損失函數(shù),因?yàn)樗鼘?duì)異常值更穩(wěn)健。它被計(jì)算為實(shí)際值和預(yù)測(cè)值之間的絕對(duì)差的平均值。交叉熵:交叉熵將計(jì)算一個(gè)分?jǐn)?shù),該分?jǐn)?shù)總結(jié)了預(yù)測(cè)類 1 的實(shí)際概率分布和預(yù)測(cè)概率分布之間的平均差異,完美的交叉熵值為 0。對(duì)于二元分類問題,交叉熵的替代方法是Hinge Loss,主要開發(fā)用于支持向量機(jī) (SVM) 模型。它旨在與目標(biāo)值在集合 {-1, 1} 中的二進(jìn)制分類一起使用。Hinge Loss鼓勵(lì)示例具有正確的符號(hào),當(dāng)實(shí)際和預(yù)測(cè)的類值之間的符號(hào)存在差異時(shí)分配更多錯(cuò)誤。Hinge Loss的性能報(bào)告是混合的,有時(shí)在二元分類問題上比交叉熵有更好的性能。最后總結(jié)
本文分享了一些在面試中常見的問題,后續(xù)我們還會(huì)整理更多的文章,希望這篇文章對(duì)你有幫助,并祝你為即將到來的面試做好準(zhǔn)備!編輯:王菁