
湖倉一體 | 網(wǎng)易湖倉一體的探索與實踐
背景介紹
數(shù)據(jù)分析從上世紀 80 年代興起以來,大體經(jīng)歷了企業(yè)數(shù)倉(EDW)、數(shù)據(jù)湖(Data Lake)、以及現(xiàn)在的云原生數(shù)倉、湖倉一體等過程。
企業(yè)數(shù)倉是數(shù)據(jù)倉庫最原始的版本,主要用于企業(yè)內(nèi)部的決策支持和商業(yè)分析(BI)。企業(yè)數(shù)倉的數(shù)據(jù)放置于集中式倉庫當中,并以 schema-on-write(寫時模式)的方式寫入。從當前的視角來看,企業(yè)數(shù)倉存在著只能處理結(jié)構(gòu)化數(shù)據(jù)、集中式的存儲和計算、以及成本昂貴等缺點。
數(shù)據(jù)湖是伴隨著數(shù)據(jù)爆炸式增長而出現(xiàn)的技術(shù),它能夠存儲結(jié)構(gòu)化以及非結(jié)構(gòu)化的數(shù)據(jù)、擁有分布式的存儲、以及經(jīng)濟的成本。但由于其“不管后面用不用,先存儲起來”的理念(schema-on-read 模式),在數(shù)據(jù)治理、數(shù)據(jù)質(zhì)量方面有很多的缺失,因此在后續(xù)實際的使用當中會面臨較多的問題。
湖倉一體是當前較新的理念,它的目標是解決上述企業(yè)數(shù)倉和數(shù)據(jù)湖的主要缺點,并提供企業(yè)數(shù)倉和數(shù)據(jù)湖融合的優(yōu)勢。使其擁有數(shù)據(jù)湖的多樣化結(jié)構(gòu)支持、分布式存儲、低成本以及企業(yè)數(shù)倉的數(shù)據(jù)治理能力,高速 SQL 訪問性能等兩者的優(yōu)點。同時,作為一個新興的形態(tài),湖倉一體自身也帶來了一系列增強的功能,如事務(wù)支持(ACID),支持數(shù)據(jù) UPDATE/DELETE,更高的數(shù)據(jù)實時性甚至流式數(shù)據(jù)的生產(chǎn)和消費支持等等。
在業(yè)內(nèi),最早提出湖倉一體的是 Databricks,其在 2020 年初的時候介紹了 “Lakehouse” 概念[1],可以算是業(yè)內(nèi)對湖倉一體概念最早的定義和說明。在技術(shù)層面上,不同的實現(xiàn)方案也爭相出現(xiàn),目前開源且活躍度較高的湖倉一體實現(xiàn)方案就已有 Delta Lake、Apache Hudi 及 Apache Iceberg 等。此外阿里云、華為云等也都根據(jù)自身的技術(shù)棧提供了湖倉一體解決方案。
網(wǎng)易在 2020 年上半年即開始湖倉一體的探索,設(shè)計并開發(fā)了 Arctic 系統(tǒng)。Arctic 支持數(shù)據(jù) update/delete,兼容用戶原有 hive 表并能賦予 hive 表小時級甚至分鐘級數(shù)據(jù)延遲能力。在數(shù)據(jù)實時性及能效成本方面相對原有的方案能取得大幅的提升。Arctic 相關(guān)的實現(xiàn)也在實際業(yè)務(wù)場景中取得了落地,積累了一定的實踐經(jīng)驗。在實現(xiàn)新的湖倉一體方案過程當中,我們結(jié)合自身業(yè)務(wù)場景的需求,做了很多探索。本次我們分享一下實現(xiàn)過程中的一些核心功能點的思路和經(jīng)驗。
數(shù)據(jù)高效 update/delete
2.1 動態(tài)哈希結(jié)構(gòu)
支持數(shù)據(jù)的 update / delete 可以有效的支持數(shù)據(jù)修正及支持業(yè)務(wù) CDC 場景等,也是實現(xiàn) “One Data” 應(yīng)對多種上層應(yīng)用場景的基礎(chǔ)。而要在分布式海量數(shù)據(jù)存儲上實現(xiàn)數(shù)據(jù)更新和刪除功能,我們首先要面對的問題是:如何高效的定位所需修改/刪除的數(shù)據(jù)?
一種方案是維護所有數(shù)據(jù)的主鍵索引(比如通過文件級 bloom filter 或 HBase 存儲),但顯而易見的是在海量的數(shù)據(jù)規(guī)模上維護主鍵索引代價很大,且引入第三方組件的存儲會給整個系統(tǒng)的實現(xiàn)和維護帶來額外的復(fù)雜度。在 Arctic 實現(xiàn)中,我們通過維護一個動態(tài) hash 二叉樹結(jié)構(gòu)(我們稱之為 Arctic Tree),將數(shù)據(jù)根據(jù)主鍵的 hash 值進行劃分,數(shù)據(jù)分布在二叉樹的結(jié)點中。這個結(jié)構(gòu)的好處是,我們只需要維護每個文件各自所屬結(jié)點位置信息,并附加在文件的屬性上即可。Arctic Tree 結(jié)構(gòu)簡單示意圖:

理論上,隨著樹的層級加大,我們可以使每個樹結(jié)點只擁有一個數(shù)據(jù)文件。這是文件劃分的最極端的一種情況,此時經(jīng)主鍵 hash 后同結(jié)點的數(shù)據(jù)必然落在此文件當中。當然,實際的情況當中大可不必如此,我們可以讓一個結(jié)點保留多個數(shù)據(jù)文件,只要確保一個結(jié)點的文件作為一個計算任務(wù)的算子節(jié)點輸入時,對內(nèi)存的要求不超過節(jié)點限制即可。
另外,隨著數(shù)據(jù)的增大或減少,Arctic Tree 的數(shù)據(jù)結(jié)點還可以進行分裂(1->2^n)或合并(2^n->1)。這也是我們稱之為動態(tài) hash 二叉樹結(jié)構(gòu)的原因。Arctic Tree 也是 Arctic 系統(tǒng)中實現(xiàn)很多后續(xù)功能的基礎(chǔ)。
2.2 Delete 文件的拆分及數(shù)據(jù)順序保證
在解決數(shù)據(jù)定位效率問題后,第二個問題隨之而來。變更數(shù)據(jù)和普通新增數(shù)據(jù)混合在一起容易使需要讀取到內(nèi)存的文件過大,引起 OOM,我們需要將不同類型數(shù)據(jù)拆分開來。由于更新數(shù)據(jù)我們可以拆解為先刪除后插入,因此我們只需要拆分兩種類型的數(shù)據(jù),Insert 和 Delete。
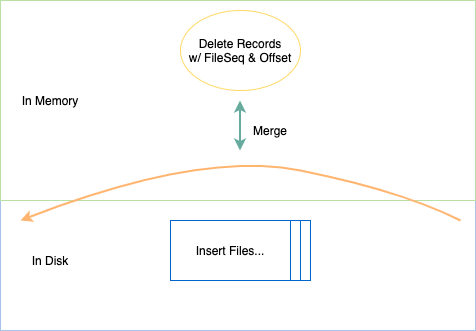
不過文件類型拆分后,如何確保數(shù)據(jù)先后順序的正確性?由于 delete 數(shù)據(jù)和 insert 數(shù)據(jù)已分屬不同的文件,我們無法簡單判斷其先后。如果將 delete 作用在整個 insert 文件上,那所有相關(guān)的插入數(shù)據(jù)都將被刪除,導(dǎo)致最終錯誤的結(jié)果。在解決這個問題上,不同開源社區(qū)的實現(xiàn)走上了不同的道路。在 Arctic 中,我們通過維護一個 File Sequence + Record Offset 解決。File Sequence 由一次提交(commit)時遞增生成且本次提交內(nèi)的所有文件共享,并記錄在 commit 元數(shù)據(jù)信息當中。Record Offset 由 Writer 在寫入時賦予,只需保證單個 commit 周期內(nèi)單調(diào)遞增且唯一即可。File Sequence + Record Offset 就保證了數(shù)據(jù)的全局唯一性及先后順序性。

有了 File Sequence 及 Record Offset 之后,即使插入數(shù)據(jù)與刪除數(shù)據(jù)位于不同的文件,生成文件的時機不同,我們也可以根據(jù) File Sequence + Record Offset 組成一條邏輯時間軸,以確定不同數(shù)據(jù)在時間軸上的前后順序。另外,對于增量數(shù)據(jù)的回放而言,也只需要根據(jù)時間軸的順序往下游進行輸出即可。
數(shù)據(jù)實時性
在湖倉一體的設(shè)計當中,由于變更數(shù)據(jù)和插入數(shù)據(jù)分開進行了存放,因此,決定數(shù)據(jù)實時性的除了寫入端的提交頻率外,還有變更數(shù)據(jù)與插入數(shù)據(jù)的合并時機。對于兩類數(shù)據(jù)的合并,我們通常有兩種方式:寫時復(fù)制(copy on write)和讀時合并(merge on read),寫時復(fù)制可以同步執(zhí)行也可以異步執(zhí)行,但出于寫入端性能的考慮,我們一般選擇異步后臺執(zhí)行。讀時合并是實時性最優(yōu)的操作類型,但由于上層在進行數(shù)據(jù)讀取時,通常會有一個期望的響應(yīng)時間閾值,而過多的讀時合并操作會拖慢整個查詢流程的性能,因此該如何去應(yīng)用讀時合并也需要做合理的權(quán)衡。
3.1 copy on write
在目前開源社區(qū)的實現(xiàn)中,copy on write 都單獨設(shè)計為了一種 Action,需要用戶主動調(diào)用來進行觸發(fā)。而在 Arctic 中,有單獨的后臺服務(wù)進行 copy on write 管理,可以自動根據(jù)表中數(shù)據(jù)/文件的狀態(tài)和用戶的配置進行觸發(fā),對用戶更加友好和更易使用。
除了調(diào)用時機可靈活配置外,在空間管理上,Arctic 也預(yù)留了不同的實現(xiàn)策略,比如 Arctic 支持只對表中的一個或部分分區(qū)進行 copy on write 操作,這樣一來可以避免每次都對整個表進行操作,以致出現(xiàn)生成的整個任務(wù)過大,中間極易出現(xiàn)異常等問題。另外則可以滿足用戶某些情況下只需要及時更新某些分區(qū)數(shù)據(jù)的要求。此外,由于 copy on write 需要將所有相關(guān)文件讀出,再合并寫入,整體上是一個寫很重的操作,也較容易引起寫放大的問題。因此,對于 copy on write,一般不會頻繁的去觸發(fā)。總體上而言,copy on write 是一個主要面向數(shù)據(jù)小時級或 10 分鐘以上級別延遲的操作。
3.2 merge on read
相對于 copy on write 而言,想要更高的實時性,就需要由 merge on read 來完成。merge on read 的實現(xiàn)內(nèi)嵌于數(shù)據(jù)查詢流程當中,在執(zhí)行具體讀取時進行文件范圍的篩選,任務(wù) plan 及數(shù)據(jù)合并等操作,且依賴不同的查詢執(zhí)行器實現(xiàn)略有不同。這里簡單以 Arctic 中基于 Spark SQL 3.0 實現(xiàn)的 merge on read 介紹下實現(xiàn)原理。
實現(xiàn) merge on read 需要對 Spark SQL 所做的擴展主要有兩塊,自定義 Catalog 及自定義 DataSource 數(shù)據(jù)源。Spark SQL 對于用戶實現(xiàn)自己的擴展比較友好,都已經(jīng)預(yù)留好了接口。有的人可能比較好奇,為何還要擴展 Catalog 呢?其實這是由 Arctic 需要兼容用戶原有的 Hive 表所致的,因為我們需要通過自定義實現(xiàn)的 Catalog 進行區(qū)分用戶原有的 hive 表和 Arctic 表。Spark SQL 3.x 支持了 Multiple Catalog,我們只要在 SQL 解析流程中,加入一個 ArcticCatalog,并作為用戶首選的 catalog,所有的 sql 請求,都首先經(jīng)過 ArcticCatalog 進行甄別,Arctic 表由 ArcticCatalog 處理,非 Arctic 表則由 ArcticCatalog 分配至默認的 SparkCatalog 進行處理即可。
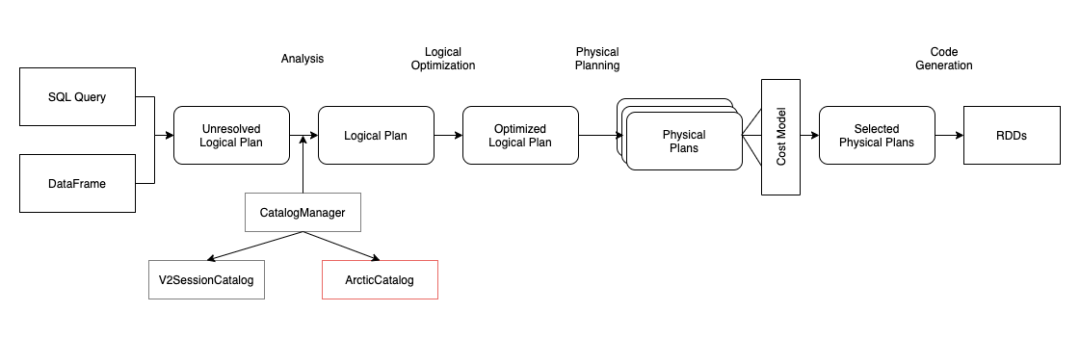
對于數(shù)據(jù)源的擴展,主要是依賴 DataSourceV2 接口。其中的核心點是擴展 spark 的 partition reader,在數(shù)據(jù)讀取時,需要加上 insert/delete 數(shù)據(jù)合并邏輯。最終返回給用戶一致的、正確的數(shù)據(jù)。
其他功能
除上述的幾個功能外,Arctic 還支持從業(yè)務(wù)數(shù)據(jù)庫(MySQL/Oracle)全自動同步全量/增量數(shù)據(jù)至 Arctic 表,支持文件治理、數(shù)據(jù)訪問權(quán)限控制、ACID 特性等功能,已基本具備了作為湖倉一體基礎(chǔ)設(shè)施的能力。
未來展望
湖倉一體技術(shù)正在蓬勃的發(fā)展,所適配的應(yīng)用場景也肯定會越來越豐富。目前大家對于湖倉一體設(shè)施主要印象還是應(yīng)用于 OLAP 數(shù)據(jù)分析場景,但對于我們期待的 “One Data Fit All” 的目標來說,用戶的需求遠不止如此。比如我們遇到的湖倉一體中的數(shù)據(jù)在滿足實時性的同時,還需要能滿足推薦等業(yè)務(wù)的數(shù)據(jù)”點查“需求,這也是 Arctic 后續(xù)發(fā)力的方向。未來湖倉一體技術(shù)不僅能滿足高效 OLAP 的需求,還將能滿足機器學(xué)習、科學(xué)計算等多種場景業(yè)務(wù)需求。
此外,Arctic 還會完善 AP 端生態(tài),覆蓋 Spark SQL,Presto 等多種查詢引擎。同時也會與內(nèi)部的有數(shù)大數(shù)據(jù)平臺集成,基于有數(shù)平臺成熟的增強可視化建模等技術(shù),進一步降低用戶的使用門檻。對于 SQL 查詢性能,Arctic 也會考慮設(shè)計更優(yōu)的二級索引,或是引入優(yōu)秀的開源實現(xiàn)如 Alluxio 等作為查詢緩存存儲,以進一步縮短響應(yīng)時間,更好的提升用戶體驗。
[1] https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
大鯨,網(wǎng)易實時數(shù)倉開發(fā)工程師,曾從事搜索系統(tǒng)、實時計算平臺等相關(guān)工作。
