
JVM垃圾回收器介紹
? ? ? ? ? ? ? ? ? ?
? ? ? ?在我們的經(jīng)驗(yàn)之中,大部分的對象在生成之后就會(huì)馬上變成垃圾,很少有對象能夠或很久。這個(gè)就是我們將對象分成新生代和老年代的依據(jù)。在不同的代采用不同的收集是算法,從而提高內(nèi)存的利用率。
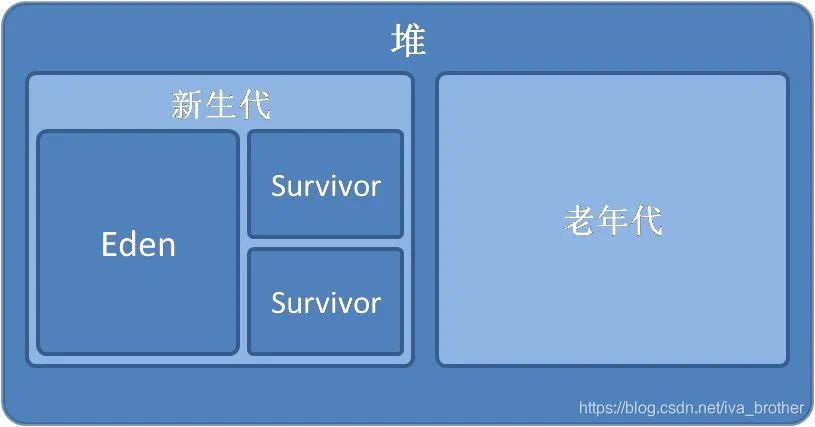
? ? ? ?我們的分區(qū)一般如下圖所示,一個(gè)生成空間,兩個(gè)大小相等的幸存空間,一個(gè)老年代空間。而針對它們的回收,我們的叫法也不相同。
? ? ? ? 新生代GC(minor GC):指發(fā)生在新生代的垃圾回收動(dòng)作,因?yàn)镴ava對象大多都具備朝生夕滅的特點(diǎn),所以minor GC發(fā)生得非常頻繁,一般回收速度也比較塊。
? ? ? ? 老年代GC(Major GC/Full GC):指發(fā)生在老年代的GC,它的速度會(huì)比minor GC慢很多。
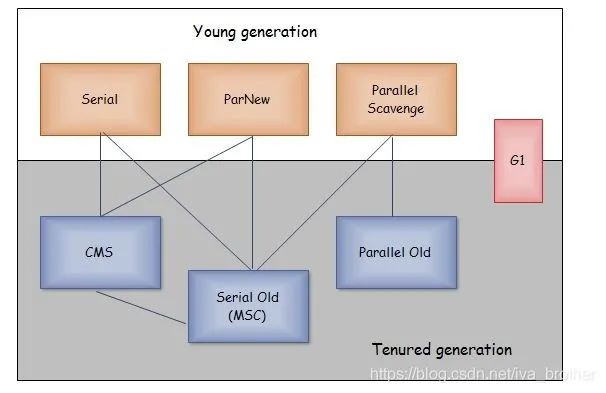
? ? ? ? 前面我們介紹的所有回收算法都是為實(shí)現(xiàn)垃圾回收器服務(wù)的,而垃圾回收器就是內(nèi)存回收的具體實(shí)現(xiàn)。目前HotSpot虛擬機(jī)用到的垃圾回收器如下圖所示。注意只有兩個(gè)回收器之間有連線才能配合使用。
1、串行垃圾回收器
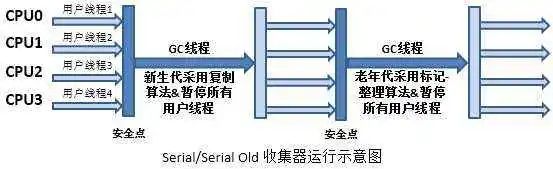
? ? ? ? 在JDK1.3.1之前,單線程回收器是唯一的選擇。它的單線程意義不僅僅是說它只會(huì)使用一個(gè)CPU或一個(gè)收集線程去完成垃圾收集工作。而且它進(jìn)行垃圾回收的時(shí)候,必須暫停其他所有的工作線程(Stop The World,STW),直到它收集完成。它適合Client模式的應(yīng)用,在單CPU環(huán)境下,它簡單高效,由于沒有線程交互的開銷,專心垃圾收集自然可以獲得最高的單線程效率。
? ? ? ? 串行的垃圾收集器有兩種,Serial與Serial Old,一般兩者搭配使用。新生代采用Serial,是利用復(fù)制算法;老年代使用Serial Old采用標(biāo)記-整理算法。Client應(yīng)用或者命令行程序可以,通過-XX:+UseSerialGC可以開啟上述回收模式。下圖是其運(yùn)行過程示意圖。
2、并行垃圾回收器
? ? ? ?整體來說,并行垃圾回收相對于串行,是通過多線程運(yùn)行垃圾收集的。也會(huì)stop-the-world。適合Server模式以及多CPU環(huán)境。一般會(huì)和jdk1.5之后出現(xiàn)的CMS搭配使用。并行的垃圾回收器有以下幾種:
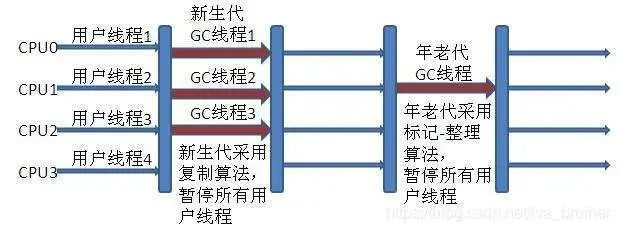
? ? ? ? ParNew:Serial收集器的多線程版本,默認(rèn)開啟的收集線程數(shù)和cpu數(shù)量一樣,運(yùn)行數(shù)量可以通過修改ParallelGCThreads設(shè)定。用于新生代收集,復(fù)制算法。使用-XX:+UseParNewGC,和Serial Old收集器組合進(jìn)行內(nèi)存回收。如下圖所示。
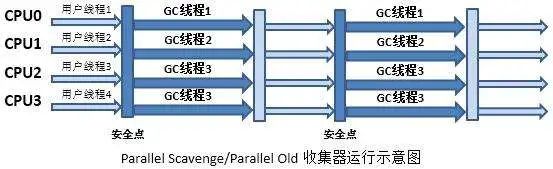
? ? ? ? Parallel Scavenge: 關(guān)注吞吐量,吞吐量優(yōu)先,吞吐量=代碼運(yùn)行時(shí)間/(代碼運(yùn)行時(shí)間+垃圾收集時(shí)間),也就是高效率利用cpu時(shí)間,盡快完成程序的運(yùn)算任務(wù)可以設(shè)置最大停頓時(shí)間MaxGCPauseMillis以及,吞吐量大小GCTimeRatio。如果設(shè)置了-XX:+UseAdaptiveSizePolicy參數(shù),則隨著GC,會(huì)動(dòng)態(tài)調(diào)整新生代的大小,Eden,Survivor比例等,以提供最合適的停頓時(shí)間或者最大的吞吐量。用于新生代收集,復(fù)制算法。通過-XX:+UseParallelGC參數(shù),Server模式下默認(rèn)提供了其和SerialOld進(jìn)行搭配的分代收集方式。
? ? ? ? Parllel Old:Parallel Scavenge的老年代版本。JDK 1.6開始提供的。在此之前Parallel Scavenge的地位也很尷尬,而有了Parllel Old之后,通過-XX:+UseParallelOldGC參數(shù)使用Parallel Scavenge + Parallel Old器組合進(jìn)行內(nèi)存回收,如下圖所示。
3、CMS收集器
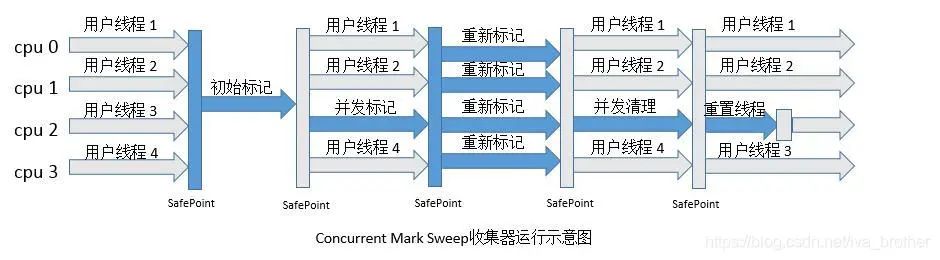
? ? ? ?CMS(Concurrent Mark Sweep)收集器是一種以獲得最短回收停頓時(shí)間為目標(biāo)的收集器。從名字就能直到其是給予標(biāo)記-清除算法的。但是它比一般的標(biāo)記-清除算法要復(fù)雜一些,分為以下4個(gè)階段:
? ? ? ?初始標(biāo)記:標(biāo)記一下GC Roots能直接關(guān)聯(lián)到的對象,會(huì)“Stop The World”。
? ? ? ?并發(fā)標(biāo)記:GC Roots Tracing,可以和用戶線程并發(fā)執(zhí)行。
? ? ? ?重新標(biāo)記:標(biāo)記期間產(chǎn)生的對象存活的再次判斷,修正對這些對象的標(biāo)記,執(zhí)行時(shí)間相對并發(fā)標(biāo)記短,會(huì)“Stop The World”。
? ? ? ?并發(fā)清除:清除對象,可以和用戶線程并發(fā)執(zhí)行。
? ? ? ?由于垃圾回收線程可以和用戶線程同時(shí)運(yùn)行,也就是說它是并發(fā)的,那么它會(huì)對CPU的資源非常敏感,CMS默認(rèn)啟動(dòng)的回收線程數(shù)是(CPU數(shù)量+3)/ 4,當(dāng)CPU<4個(gè)時(shí),并發(fā)回收是垃圾收集線程就不會(huì)少于25%,而且隨著CPU減少而增加,這樣會(huì)影響用戶線程的執(zhí)行。而且由于它是基于標(biāo)記-清除算法的,那么就無法避免空間碎片的產(chǎn)生。CMS收集器無法處理浮動(dòng)垃圾(Floating Garbage),可能出現(xiàn)“Concurrent Mode Failure”失敗而導(dǎo)致另一次Full GC的產(chǎn)生。
? ? ? ? 所謂浮動(dòng)垃圾,在CMS并發(fā)清理階段用戶線程還在運(yùn)行著,伴隨程序運(yùn)行自然還會(huì)有新的垃圾不斷產(chǎn)生,這一部分垃圾出現(xiàn)在標(biāo)記過程之后,CMS無法在當(dāng)次收集中處理掉它們,只能留待下一次GC時(shí)再清理掉。
? ? ? ?把G1單獨(dú)拿出來的原因是其比較復(fù)雜,在JDK 1.7確立是項(xiàng)目目標(biāo),在JDK 7u2版本之后發(fā)布,并在JDK 9中成為了默認(rèn)的垃圾回收器。通過“-XX:+UseG1GC”啟動(dòng)參數(shù)即可指定使用G1 GC。
? ? ? ?G1從整體看還是基于標(biāo)記-清除算法的,但是局部上是基于復(fù)制算法的。這樣就意味者它空間整合做的比較好,因?yàn)椴粫?huì)產(chǎn)生空間碎片。G1還是并發(fā)與并行的,它能夠充分利用多CPU、多核的硬件環(huán)境來縮短“stop the world”的時(shí)間。G1還是分代收集的,但是G1不再像上文所述的垃圾收集器,需要分代配合不同的垃圾收集器,因?yàn)镚1中的垃圾收集區(qū)域是“分區(qū)”(Region)的。G1的分代收集和以上垃圾收集器不同的就是除了有年輕代的ygc,全堆掃描的full GC外,還有包含所有年輕代以及部分老年代Region的Mixed GC。G1還可預(yù)測停頓,通過調(diào)整參數(shù),制定垃圾收集的最大停頓時(shí)間。
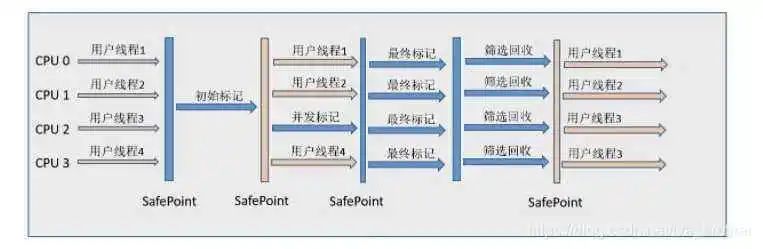
? ? ? ?G1收集器的運(yùn)作大致可以分為以下步驟:初始標(biāo)記、并發(fā)標(biāo)記、最終標(biāo)記、篩選回收。其中初始標(biāo)記階段僅僅只是標(biāo)記一下GC Roots能直接關(guān)聯(lián)到的對象,并且修改TAMS(Next Top at Mark Set)的值,讓下一個(gè)階段用戶程序并發(fā)運(yùn)行時(shí),能在正確可用的Region中創(chuàng)建新對象,這個(gè)階段需要STW,但耗時(shí)很短。并發(fā)標(biāo)記階段是從GC Roots開始對堆中對象進(jìn)行可達(dá)性分析,找到存活的對象,這階段耗時(shí)較長,但是可以和用戶線程并發(fā)運(yùn)行。最終標(biāo)記階段則是為了修正在并發(fā)標(biāo)記期間因用戶程序繼續(xù)運(yùn)行而導(dǎo)致標(biāo)記產(chǎn)生變化的那一部分標(biāo)記記錄,虛擬機(jī)將這段時(shí)間對象變化記錄在線程Remembered Set Logs里面,最終標(biāo)記需要把Remembered Set Logs的數(shù)據(jù)合并到Remembered Sets中,這階段需要暫停線程,但是可并行執(zhí)行。最后的篩選回收階段首先對各個(gè)Region的回收價(jià)值和成本進(jìn)行排序,根據(jù)用戶所期望的GC停頓時(shí)間來確定回收計(jì)劃。G1收集器運(yùn)行示意圖如下圖所示。
G1分區(qū)的概念
? ? ? ?G1的堆區(qū)在分代的基礎(chǔ)上,引入分區(qū)的概念。G1將堆分成了若干Region,以下和”分區(qū)”代表同一概念。(這些分區(qū)不要求是連續(xù)的內(nèi)存空間)Region的大小可以通過G1HeapRegionSize參數(shù)進(jìn)行設(shè)置,其必須是2的冪,范圍允許為1Mb到32Mb。JVM的會(huì)基于堆內(nèi)存的初始值和最大值的平均數(shù)計(jì)算分區(qū)的尺寸,平均的堆尺寸會(huì)分出約2000個(gè)Region。分區(qū)大小一旦設(shè)置,則啟動(dòng)之后不會(huì)再變化。如下圖簡單畫了下G1分區(qū)模型。

Eden regions(年輕代-Eden區(qū))
Survivor regions(年輕代-Survivor區(qū))
Old regions(老年代)
Humongous regions(巨型對象區(qū)域)
Free regions(未分配區(qū)域,也會(huì)叫做可用分區(qū))-上圖中空白的區(qū)域
? ? ? ?G1中的巨型對象是指,占用了Region容量的50%以上的一個(gè)對象。Humongous區(qū),就專門用來存儲(chǔ)巨型對象。如果一個(gè)H區(qū)裝不下一個(gè)巨型對象,則會(huì)通過連續(xù)的若干H分區(qū)來存儲(chǔ)。因?yàn)榫扌蛯ο蟮霓D(zhuǎn)移會(huì)影響GC效率,所以并發(fā)標(biāo)記階段發(fā)現(xiàn)巨型對象不再存活時(shí),會(huì)將其直接回收。ygc也會(huì)在某些情況下對巨型對象進(jìn)行回收。
? ? ? ?分區(qū)可以有效利用內(nèi)存空間,因?yàn)槭占w是使用“標(biāo)記-整理”,Region之間基于“復(fù)制”算法,GC后會(huì)將存活對象復(fù)制到可用分區(qū)(未分配的分區(qū)),所以不會(huì)產(chǎn)生空間碎片。
G1 GC的分類和過程
? ? ? ? JDK10 之前的G1中的GC只有Young GC,Mixed GC。Full GC處理會(huì)交給單線程的Serial Old垃圾收集器。
Young?GC年輕代收集
? ? ? ?在分配一般對象(非巨型對象)時(shí),當(dāng)所有Eden region使用達(dá)到最大閥值并且無法申請足夠內(nèi)存時(shí),會(huì)觸發(fā)一次Young GC。每次Young GC會(huì)回收所有Eden以及Survivor區(qū),并且將存活對象復(fù)制到Old區(qū)以及另一部分的Survivor區(qū)。到Old區(qū)的標(biāo)準(zhǔn)就是在PLAB中得到的計(jì)算結(jié)果。因?yàn)閅oung GC會(huì)進(jìn)行根掃描,所以會(huì)stop the world。
Young GC的回收過程如下:
1、根掃描,跟CMS類似,Stop the world,掃描GC Roots對象。
2、處理Dirty card,更新RSet.
3、掃描RSet,掃描RSet中所有old區(qū)對掃描到的young區(qū)或者survivor去的引用。
4、拷貝掃描出的存活的對象到survivor2/old區(qū)
5、處理引用隊(duì)列,軟引用,弱引用,虛引用
Mix?GC混合收集
? ? ? ?Mixed GC是G1 GC特有的,跟Full GC不同的是Mixed GC只回收部分老年代的Region。哪些old region能夠放到CSet里面,有很多參數(shù)可以控制。比如G1HeapWastePercent參數(shù),在一次young GC之后,可以允許的堆垃圾百占比,超過這個(gè)值就會(huì)觸發(fā)mixed GC。
? ? ? G1MixedGCLiveThresholdPercent參數(shù)控制的,old代分區(qū)中的存活對象比,達(dá)到閥值時(shí),這個(gè)old分區(qū)會(huì)被放入CSet。
? ? ? Mixed GC一般會(huì)發(fā)生在一次Young GC后面,為了提高效率,Mixed GC會(huì)復(fù)用Young GC的全局的根掃描結(jié)果,因?yàn)檫@個(gè)Stop the world過程是必須的,整體上來說縮短了暫停時(shí)間。
? ? ? ? Mix GC的回收過程可以理解為Young GC后附加的全局concurrent marking,全局的并發(fā)標(biāo)記主要用來處理old區(qū)(包含H區(qū))的存活對象標(biāo)記,過程如下:
1. 初始標(biāo)記(Initial Mark)。標(biāo)記GC Roots,會(huì)STW,一般會(huì)復(fù)用Young GC的暫停時(shí)間。如前文所述,初始標(biāo)記會(huì)設(shè)置好所有分區(qū)的NTAMS值。
2. 根分區(qū)掃描(Root Region Scan)。這個(gè)階段GC的線程可以和應(yīng)用線程并發(fā)運(yùn)行。其主要掃描初始標(biāo)記以及之前Young GC對象轉(zhuǎn)移到的Survivor分區(qū),并標(biāo)記Survivor區(qū)中引用的對象。所以此階段的Survivor分區(qū)也叫根分區(qū)(Root Region)。
3. 并發(fā)標(biāo)記(Concurrent Mark)。會(huì)并發(fā)標(biāo)記所有非完全空閑的分區(qū)的存活對象,也即使用了SATB算法,標(biāo)記各個(gè)分區(qū)。
4. 最終標(biāo)記(Remark)。主要處理SATB緩沖區(qū),以及并發(fā)標(biāo)記階段未標(biāo)記到的漏網(wǎng)之魚(存活對象),會(huì)STW,可以參考上文的SATB處理。
5. 清除階段(Clean UP)。上述SATB也提到了,會(huì)進(jìn)行bitmap的swap,以及PTAMS,NTAMS互換。整理堆分區(qū),調(diào)整相應(yīng)的RSet(比如如果其中記錄的Card中的對象都被回收,則這個(gè)卡片的也會(huì)從RSet中移除),如果識(shí)別到了完全空的分區(qū),則會(huì)清理這個(gè)分區(qū)的RSet。這個(gè)過程會(huì)STW。
清除階段之后,還會(huì)對存活對象進(jìn)行轉(zhuǎn)移(復(fù)制算法),轉(zhuǎn)移到其他可用分區(qū),所以當(dāng)前的分區(qū)就變成了新的可用分區(qū)。復(fù)制轉(zhuǎn)移主要是為了解決分區(qū)內(nèi)的碎片問題。
Full?GC
G1在對象復(fù)制/轉(zhuǎn)移失敗或者沒法分配足夠內(nèi)存(比如巨型對象沒有足夠的連續(xù)分區(qū)分配)時(shí),會(huì)觸發(fā)Full GC。Full GC使用的是stop the world的單線程的Serial Old模式,所以一旦觸發(fā)Full GC則會(huì)STW應(yīng)用線程,并且執(zhí)行效率很慢。JDK 8版本的G1是不提供Full GC的處理的。對于G1 GC的優(yōu)化,很大的目標(biāo)就是沒有Full GC。
https://blog.csdn.net/lijingyao8206/article/details/80513383
https://blog.csdn.net/coderlius/article/details/79272773
《深入理解Java虛擬機(jī)》
《垃圾回收的算法與實(shí)現(xiàn)》
? ? ? ? ? ? ? ? ?
end
*版權(quán)聲明:轉(zhuǎn)載文章和圖片均來自公開網(wǎng)絡(luò),版權(quán)歸作者本人所有,推送文章除非無法確認(rèn),我們都會(huì)注明作者和來源。如果出處有誤或侵犯到原作者權(quán)益,請與我們聯(lián)系刪除或授權(quán)事宜。
長按識(shí)別圖中二維碼
關(guān)注獲取更多資訊
不點(diǎn)關(guān)注,我們哪來故事?

點(diǎn)個(gè)再看,你最好看