
JVM垃圾怎么回收?
點(diǎn)擊上方藍(lán)色字體,選擇“標(biāo)星公眾號(hào)”
優(yōu)質(zhì)文章,第一時(shí)間送達(dá)
作者 | aduner
來源 | urlify.cn/jI3AJj
76套java從入門到精通實(shí)戰(zhàn)課程分享
前言
往往被問到Java與C/C++有什么區(qū)別的時(shí)候,最先想到的答案就是Java可與自動(dòng)回收內(nèi)存垃圾。
在JVM學(xué)習(xí)中,垃圾回收幾乎是最重要的知識(shí)點(diǎn)。
那么,自動(dòng)垃圾回收機(jī)制到底是如何實(shí)現(xiàn)的呢,下面我們來梳理一遍。
什么是垃圾回收
垃圾回收(Garbage Collection)誕生于1960年 MIT 的 Lisp 語言,距今已經(jīng)超過半個(gè)世紀(jì)了。
垃圾回收顧名思義,就是收集垃圾,JVM中的垃圾就是指的內(nèi)存中不再使用的對(duì)象。
將這些不再使用的對(duì)象清除,給后來的新對(duì)象騰地方。
后文我們簡(jiǎn)稱GC。
垃圾回收的區(qū)域
Java 的自動(dòng)內(nèi)存管理主要是針對(duì)對(duì)象內(nèi)存的回收和對(duì)象內(nèi)存的分配。
Java 堆是垃圾收集器管理的主要區(qū)域,而 Java 自動(dòng)內(nèi)存管理最核心的功能是 堆 內(nèi)存中對(duì)象的分配與回收,因此也被稱作GC 堆(Garbage Collected Heap)。
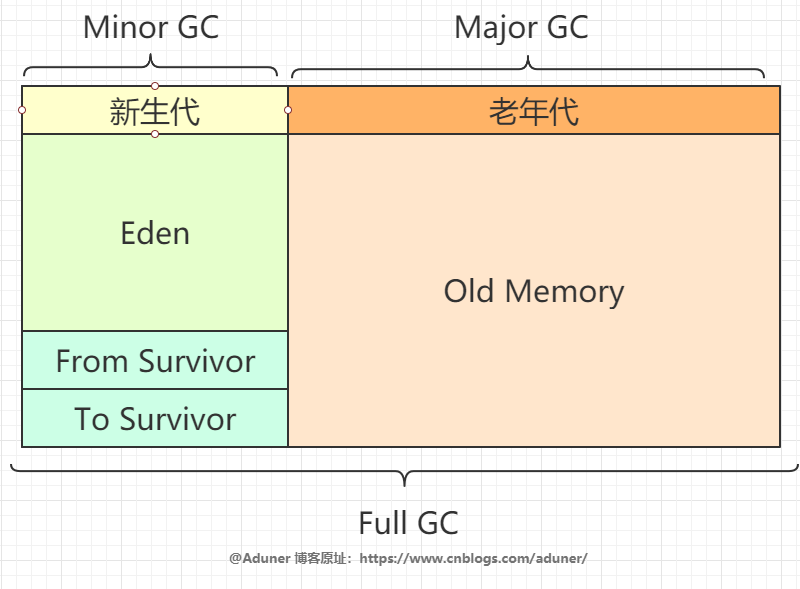
從垃圾回收的角度,由于現(xiàn)在收集器基本都采用分代垃圾收集算法,所以 Java 堆還可以細(xì)分:
堆分為新生代(占堆1/3),老生代(占堆2/3)
新生代(內(nèi)部比例8:1:1)
Eden 空間
From Survivor 空間
To Survivor 空間
老年代
進(jìn)一步劃分的目的是更好地回收內(nèi)存,或者更快地分配內(nèi)存。
垃圾回收機(jī)制
流程
大多數(shù)情況,對(duì)象都會(huì)首先在 Eden 區(qū)域分配,當(dāng) eden 區(qū)沒有足夠空間進(jìn)行分配時(shí),虛擬機(jī)將發(fā)起一次新生代垃圾回收(Minor GC)。
大對(duì)象會(huì)直接進(jìn)入老年代,為了避免為大對(duì)象分配內(nèi)存時(shí)由于分配擔(dān)保機(jī)制帶來的復(fù)制而降低效率。
在一次Minor GC后,如果對(duì)象還存活,則會(huì)進(jìn)入兩個(gè)Survivor中的一個(gè),然后對(duì)象的年齡加 1。
它的年齡增加到年齡閾值(默認(rèn)為 15 ),就會(huì)被晉升到老年代中。
當(dāng)老年代空間不足時(shí),將會(huì)觸發(fā)老年代回收(Major GC)
針對(duì) HotSpot 實(shí)現(xiàn),它里面的 GC 其實(shí)準(zhǔn)確分類只有兩大種:
部分收集 (Partial GC):
新生代收集(Minor GC / Young GC):只對(duì)新生代進(jìn)行垃圾收集;
老年代收集(Major GC / Old GC):只對(duì)老年代進(jìn)行垃圾收集。
混合收集(Mixed GC):對(duì)整個(gè)新生代和部分老年代進(jìn)行垃圾收集。
整堆收集 (Full GC):收集整個(gè) Java 堆和方法區(qū)。
對(duì)象晉升到老年代的年齡閾值,可以通過參數(shù)
-XX:MaxTenuringThreshold設(shè)置
怎么判斷對(duì)象已經(jīng)死亡
垃圾回收前的第一步就是要判斷哪些對(duì)象已經(jīng)死亡,主要用到如下幾種算法來判斷。
引用計(jì)數(shù)法
原理很簡(jiǎn)單,如下:
給對(duì)象中添加一個(gè)引用計(jì)數(shù)器,每當(dāng)有一個(gè)地方引用它,計(jì)數(shù)器就加 1;
當(dāng)引用失效,計(jì)數(shù)器就減 1;任何時(shí)候計(jì)數(shù)器為 0 的對(duì)象就是不可能再被使用的。
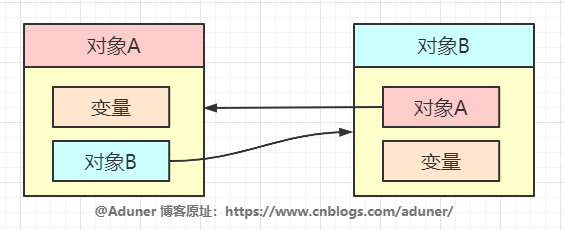
這個(gè)算法實(shí)現(xiàn)簡(jiǎn)單,效率高,但是目前主流的虛擬機(jī)中并沒有選擇這個(gè)算法來管理內(nèi)存,其最主要的原因是它很難解決對(duì)象之間相互循環(huán)引用的問題。
循環(huán)引用就是兩個(gè)對(duì)象互相引用,但是又沒有其他任何對(duì)象使用這兩個(gè)對(duì)象,兩個(gè)對(duì)象就像是互相抱著的兩個(gè)孤兒,非常可憐。
可達(dá)性分析算法
這個(gè)原理也很簡(jiǎn)單,如下:
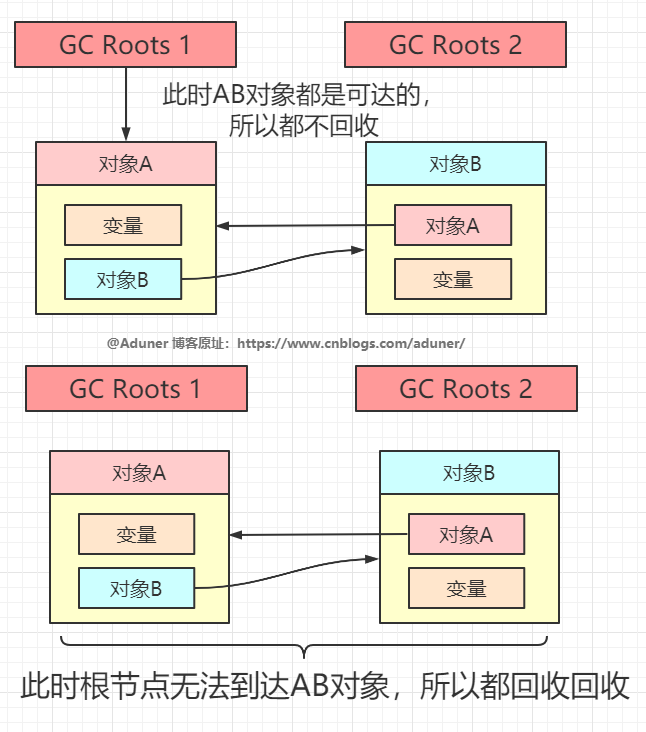
定義一系列的稱為 “GC Roots” 的對(duì)象作為根起點(diǎn)
從這些節(jié)點(diǎn)開始向下搜索,節(jié)點(diǎn)所走過的路徑稱為引用鏈
當(dāng)一個(gè)對(duì)象到 GC Roots 沒有任何引用鏈相連的話,則證明此對(duì)象是不可用的
可作為 GC Roots 的對(duì)象包括下面幾種:
虛擬機(jī)棧(棧幀中的本地變量表)中引用的對(duì)象
本地方法棧(Native 方法)中引用的對(duì)象
方法區(qū)中類靜態(tài)屬性引用的對(duì)象
方法區(qū)中常量引用的對(duì)象
所有被同步鎖持有的對(duì)象
不可達(dá)的對(duì)象并非一定會(huì)回收
發(fā)現(xiàn)不可達(dá)時(shí),這些對(duì)象暫時(shí)處于“緩刑階段”,要真正宣告一個(gè)對(duì)象死亡,至少要經(jīng)歷兩次標(biāo)記過程:
第一次標(biāo)記,篩選的條件是此對(duì)象是否有必要執(zhí)行 finalize 方法。
被判定為需要執(zhí)行的對(duì)象將會(huì)被放在一個(gè)隊(duì)列中進(jìn)行第二次標(biāo)記,除非這個(gè)對(duì)象與引用鏈上的任何一個(gè)對(duì)象建立關(guān)聯(lián),否則就會(huì)被真的回收。
關(guān)于引用
JDK1.2 之前,Java 中引用的定義很傳統(tǒng):如果 reference 類型的數(shù)據(jù)存儲(chǔ)的數(shù)值代表的是另一塊內(nèi)存的起始地址,就稱這塊內(nèi)存代表一個(gè)引用。
JDK1.2 以后,Java 對(duì)引用的概念進(jìn)行了擴(kuò)充,將引用分為強(qiáng)引用、軟引用、弱引用、虛引用四種(引用強(qiáng)度逐漸減弱)
下面我們來看看這四種引用
強(qiáng)引用(StrongReference)
強(qiáng)引用非常霸道,只要是強(qiáng)引用,一定不會(huì)被GC回收,即便是內(nèi)存不夠,即便要OOM也不會(huì)回收它。
軟引用(SoftReference)
如果內(nèi)存空間足夠,垃圾回收器就不會(huì)回收它,如果內(nèi)存空間不足了,就會(huì)回收這些對(duì)象的內(nèi)存。
只要垃圾回收器沒有回收它,該對(duì)象就可以被程序使用。軟引用可用來實(shí)現(xiàn)內(nèi)存敏感的高速緩存。
弱引用(WeakReference)
只要發(fā)現(xiàn)了只具有弱引用的對(duì)象,就會(huì)直接回收。
不過,由于垃圾回收器是一個(gè)優(yōu)先級(jí)很低的線程, 因此不一定會(huì)很快發(fā)現(xiàn)那些只具有弱引用的對(duì)象。
弱引用與軟引用的區(qū)別在于:只具有弱引用的對(duì)象擁有更短暫的生命周期。
虛引用(PhantomReference)
"虛引用"顧名思義,就是形同虛設(shè),與其他幾種引用都不同,虛引用并不會(huì)決定對(duì)象的生命周期。
如果一個(gè)對(duì)象僅持有虛引用,那么它就和沒有任何引用一樣,在任何時(shí)候都可能被垃圾回收。
虛引用主要用來跟蹤對(duì)象被垃圾回收的活動(dòng)。
虛引用與軟引用和弱引用的一個(gè)區(qū)別在于: 虛引用必須和引用隊(duì)列(ReferenceQueue)聯(lián)合使用。
當(dāng)垃圾回收器準(zhǔn)備回收一個(gè)對(duì)象時(shí),如果發(fā)現(xiàn)它還有虛引用,就會(huì)在回收對(duì)象的內(nèi)存之前,把這個(gè)虛引用加入到與之關(guān)聯(lián)的引用隊(duì)列中。程序可以通過判斷引用隊(duì)列中是否已經(jīng)加入了虛引用,來了解被引用的對(duì)象是否將要被垃圾回收。
程序如果發(fā)現(xiàn)某個(gè)虛引用已經(jīng)被加入到引用隊(duì)列,那么就可以在所引用的對(duì)象的內(nèi)存被回收之前采取必要的行動(dòng)。
特別注意,在程序設(shè)計(jì)中一般很少使用弱引用與虛引用,使用軟引用的情況較多,這是因?yàn)?strong style="margin-right: 3px;margin-left: 3px;">軟引用可以加速 JVM 對(duì)垃圾內(nèi)存的回收速度,可以維護(hù)系統(tǒng)的運(yùn)行安全,防止內(nèi)存溢出(OOM)等問題的產(chǎn)生。
判斷廢棄常量
假如在字符串常量池中存在字符串 "abc",如果當(dāng)前沒有任何 String 對(duì)象引用該字符串常量的話,就說明常量 "abc" 就是廢棄常量,如果這時(shí)發(fā)生內(nèi)存回收的話而且有必要的話,"abc" 就會(huì)被系統(tǒng)清理出常量池了。
判斷無用類
類需要同時(shí)滿足下面 3 個(gè)條件才能算是 “無用的類” :
該類所有的實(shí)例都已經(jīng)被回收,也就是 Java 堆中不存在該類的任何實(shí)例。
加載該類的 ClassLoader 已經(jīng)被回收。
該類對(duì)應(yīng)的
java.lang.Class對(duì)象沒有在任何地方被引用,無法在任何地方通過反射訪問該類的方法。
虛擬機(jī)可以對(duì)滿足上述 3 個(gè)條件的無用類進(jìn)行回收,這里說的僅僅是“可以”,而并不是和對(duì)象一樣不使用了就會(huì)必然被回收。
垃圾收集算法
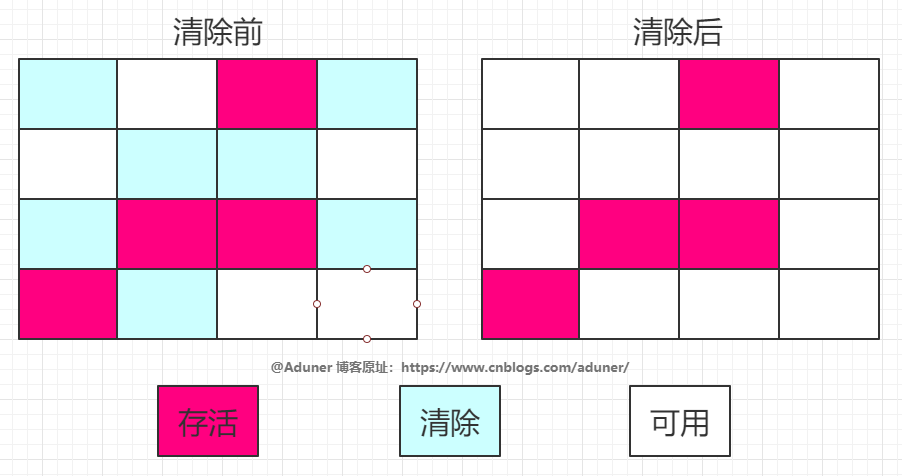
標(biāo)記-清除算法
該算法分為“標(biāo)記”和“清除”階段:
首先標(biāo)記出所有不需要回收的對(duì)象
標(biāo)記完成后統(tǒng)一回收掉所有沒有被標(biāo)記的對(duì)象。
它是最基礎(chǔ)的收集算法,后續(xù)的算法都是對(duì)其不足進(jìn)行改進(jìn)得到。
這種垃圾收集算法會(huì)帶來兩個(gè)明顯的問題:
效率問題,需要遍歷兩次進(jìn)行清除
空間問題,標(biāo)記清除后會(huì)產(chǎn)生大量不連續(xù)的碎片
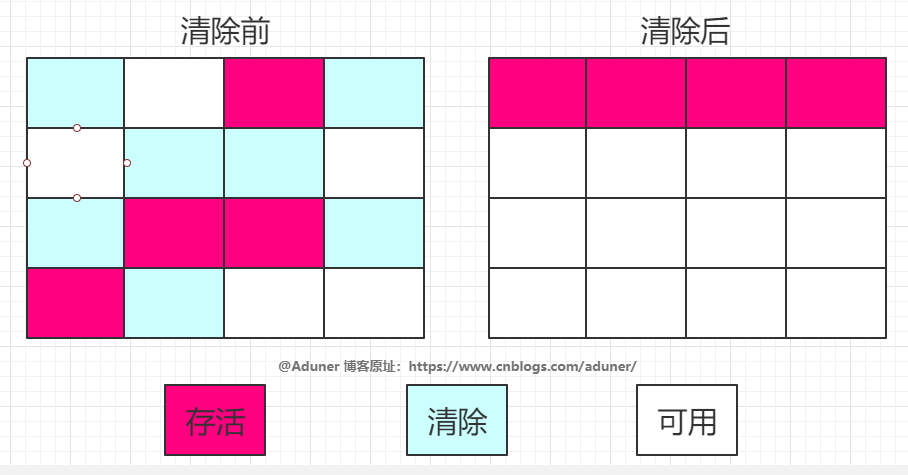
標(biāo)記-復(fù)制算法
標(biāo)記-復(fù)制算法是標(biāo)記-清除算法的改進(jìn)版本。
可以將內(nèi)存分為大小相同的兩塊,每次使用其中的一塊。
當(dāng)這一塊的內(nèi)存使用完后,就將還存活的對(duì)象復(fù)制到另一塊去,然后再把使用的空間一次清理掉。
這樣就使每次的內(nèi)存回收都是對(duì)內(nèi)存區(qū)間的一半進(jìn)行回收。
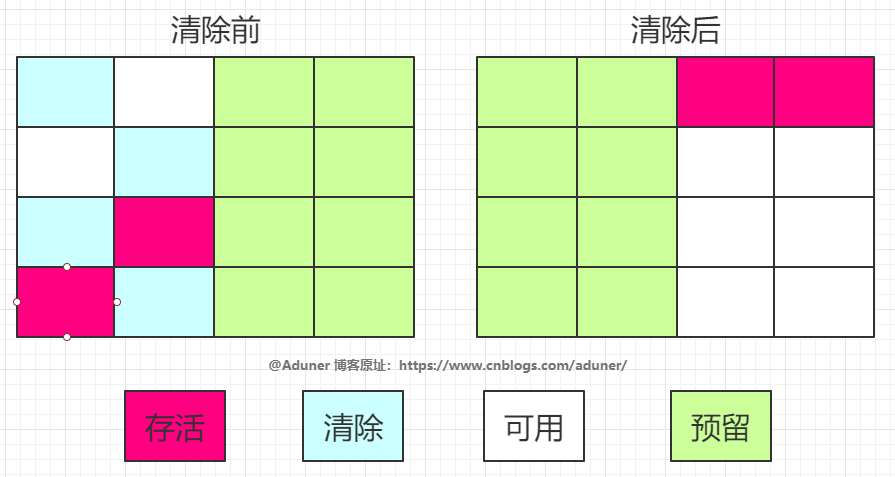
標(biāo)記-整理算法
根據(jù)老年代的特點(diǎn)提出的一種標(biāo)記算法,標(biāo)記過程仍然與“標(biāo)記-清除”算法一樣,但后續(xù)步驟不是直接對(duì)可回收對(duì)象回收,而是讓所有存活的對(duì)象向一端移動(dòng),然后直接清理掉端邊界以外的內(nèi)存。
分代收集算法
分代收集就是將新生代和老年代分開,根據(jù)各自的特點(diǎn)選擇合適的收集算法。
比如在新生代中,收集很頻繁,并且數(shù)量很多,所以可以選擇標(biāo)記-復(fù)制算法,只需要付出少量對(duì)象的復(fù)制成本就可以完成每次垃圾收集。
而老年代的對(duì)象存活幾率是比較高的,而且沒有額外的空間對(duì)它進(jìn)行分配擔(dān)保,標(biāo)記-整理算法就很合適
垃圾收集器
垃圾收集算法是垃圾收集的實(shí)現(xiàn)原理,而垃圾收集器就是內(nèi)存回收的具體實(shí)現(xiàn)。
實(shí)際生產(chǎn)中,我們需要根據(jù)自己的需求來選擇合適的垃圾收集器,需要記住一點(diǎn),沒有最好的,只有最合適的。
CMS 收集器
CMS(Concurrent Mark Sweep)收集器是一種以獲取最短回收停頓時(shí)間為目標(biāo)的收集器。
CMS收集器非常符合在注重用戶體驗(yàn)的應(yīng)用上使用
CMS收集器是 HotSpot 第一款真正意義上的并發(fā)收集器,實(shí)現(xiàn)了讓垃圾收集線程與用戶線程(基本上)同時(shí)工作。
CMS 收集器使用 “標(biāo)記-清除”算法。
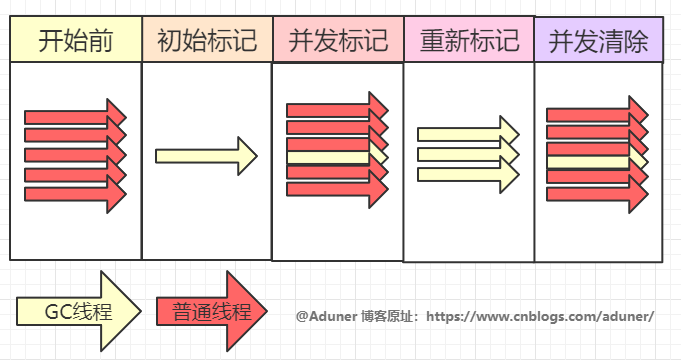
整個(gè)過程分為四個(gè)步驟:
初始標(biāo)記: 暫停所有的其他線程,并記錄下直接與 root 相連的對(duì)象,速度很快 ;
并發(fā)標(biāo)記:
同時(shí)開啟 GC 和用戶線程,用一個(gè)閉包結(jié)構(gòu)去記錄可達(dá)對(duì)象。
在階段結(jié)束,閉包結(jié)構(gòu)不能保證包含當(dāng)前所有的可達(dá)對(duì)象。
因?yàn)橛脩艟€程可能會(huì)不斷的更新引用域,所以 GC 線程無法保證可達(dá)性分析的實(shí)時(shí)性。
所以此算法里會(huì)跟蹤記錄這些發(fā)生引用更新的地方。
重新標(biāo)記:
修正并發(fā)標(biāo)記期間因?yàn)橛脩舫绦蚶^續(xù)運(yùn)行而導(dǎo)致標(biāo)記產(chǎn)生變動(dòng)的那一部分對(duì)象的標(biāo)記記錄,
停頓時(shí)間一般會(huì)比初始標(biāo)記階段的時(shí)間稍長(zhǎng),遠(yuǎn)遠(yuǎn)比并發(fā)標(biāo)記階段時(shí)間短。
并發(fā)清除: 開啟用戶線程,同時(shí) GC 線程開始對(duì)未標(biāo)記的區(qū)域做清掃。
優(yōu)點(diǎn):并發(fā)收集、低停頓。
缺點(diǎn):
對(duì) CPU 資源敏感。
無法處理浮動(dòng)垃圾。
收集結(jié)束時(shí)會(huì)有大量空間碎片產(chǎn)生。
Serial 收集器
Serial(串行)收集器是最基本、歷史最悠久的垃圾收集器了。
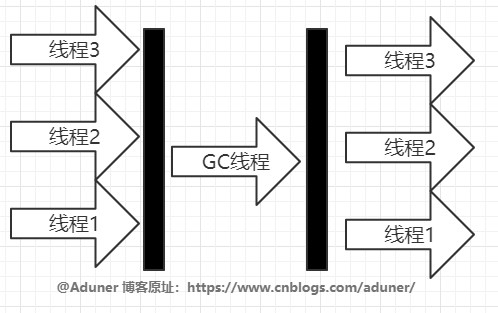
它收集器是一個(gè)單線程收集器了:
新生代采用標(biāo)記-復(fù)制算法
老年代采用標(biāo)記-整理算法
它最大的特點(diǎn)就是進(jìn)行GC時(shí),會(huì)阻塞其他線程。
它的優(yōu)點(diǎn)是簡(jiǎn)單高效,在單線程收集器中幾乎就是最快的存在,但是由于會(huì)阻塞其他線程,這讓他的使用起來體驗(yàn)并不算好。
ParNew 收集器
ParNew 收集器是 Serial 收集器的多線程版本,除了使用多線程進(jìn)行垃圾收集外,其余行為和 Serial 收集器完全一樣。
它是許多運(yùn)行在 Server 模式下的虛擬機(jī)的首要選擇,除了 Serial 收集器外,只有它能與 CMS 收集器配合工作。
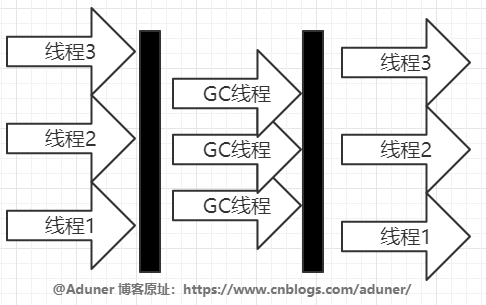
Parallel Scavenge 收集器
JDK1.8 默認(rèn)使用的是 Parallel Scavenge + Parallel Old
JDK1.8 默認(rèn)收集器
Parallel Scavenge 收集器幾乎和 ParNew 是一樣。
區(qū)別在于:
Parallel Scavenge 收集器關(guān)注點(diǎn)是吞吐量(高效率的利用 CPU)
CMS 等垃圾收集器的關(guān)注點(diǎn)更多的是用戶線程的停頓時(shí)間(提高用戶體驗(yàn))。
Serial Old 收集器
Serial 收集器的老年代版本,它同樣是一個(gè)單線程收集器。它主要有兩大用途:
一種用途是在 JDK1.5 以及以前的版本中與 Parallel Scavenge 收集器搭配使用,另一種用途是作為 CMS 收集器的后備方案。
Parallel Old 收集器
Parallel Scavenge 收集器的老年代版本。
使用多線程和“標(biāo)記-整理”算法。在注重吞吐量以及 CPU 資源的場(chǎng)合,都可以優(yōu)先考慮 Parallel Scavenge 收集器和 Parallel Old 收集器。
G1 收集器
G1 (Garbage-First) 是一款面向服務(wù)器的垃圾收集器,主要針對(duì)配備多顆處理器及大容量?jī)?nèi)存的機(jī)器。
以極高概率滿足 GC 停頓時(shí)間要求的同時(shí),還具備高吞吐量性能特征。
非常強(qiáng)的一款垃圾收集器,甚至它可能會(huì)引領(lǐng)JVM垃圾收集的未來。
它具備一下特點(diǎn):
并行與并發(fā):
G1 能充分利用 CPU、多核環(huán)境下的硬件優(yōu)勢(shì),使用多個(gè) CPU(CPU 或者 CPU 核心)來縮短停頓時(shí)間。
部分其他收集器原本需要停頓 Java 線程執(zhí)行的 GC 動(dòng)作,G1 收集器仍然可以通過并發(fā)的方式讓 Java 程序繼續(xù)執(zhí)行。
分代收集:雖然 G1 可以不需要其他收集器配合就能獨(dú)立管理整個(gè) GC 堆,但是還是保留了分代的概念。
空間整合:
G1 從整體來看是基于標(biāo)記-整理算法實(shí)現(xiàn)的收集器;
從局部上來看是基于標(biāo)記-復(fù)制算法實(shí)現(xiàn)的。
可預(yù)測(cè)的停頓:降低停頓時(shí)間是 G1 和 CMS 共同的關(guān)注點(diǎn),但 G1 除了追求低停頓外,還能建立可預(yù)測(cè)的停頓時(shí)間模型,能讓使用者明確指定在一個(gè)長(zhǎng)度為 M 毫秒的時(shí)間片段內(nèi)。
G1 收集器的運(yùn)作大致分為以下幾個(gè)步驟:
初始標(biāo)記
并發(fā)標(biāo)記
最終標(biāo)記
篩選回收
G1 收集器在后臺(tái)維護(hù)了一個(gè)優(yōu)先列表,每次根據(jù)允許的收集時(shí)間,優(yōu)先選擇回收價(jià)值最大的 Region(這也就是它的名字 Garbage-First 的由來) 。
這種使用 Region 劃分內(nèi)存空間以及有優(yōu)先級(jí)的區(qū)域回收方式,保證了 G1 收集器在有限時(shí)間內(nèi)可以盡可能高的收集效率(把內(nèi)存化整為零)。
ZGC 收集器
與G1 類似,但又互有不同,這里不展開了,感興趣可以自行了解。
粉絲福利:Java從入門到入土學(xué)習(xí)路線圖
??????

??長(zhǎng)按上方微信二維碼 2 秒
感謝點(diǎn)贊支持下哈 