
Flink 在廣告業(yè)務(wù)的實(shí)踐
一、業(yè)務(wù)場(chǎng)景
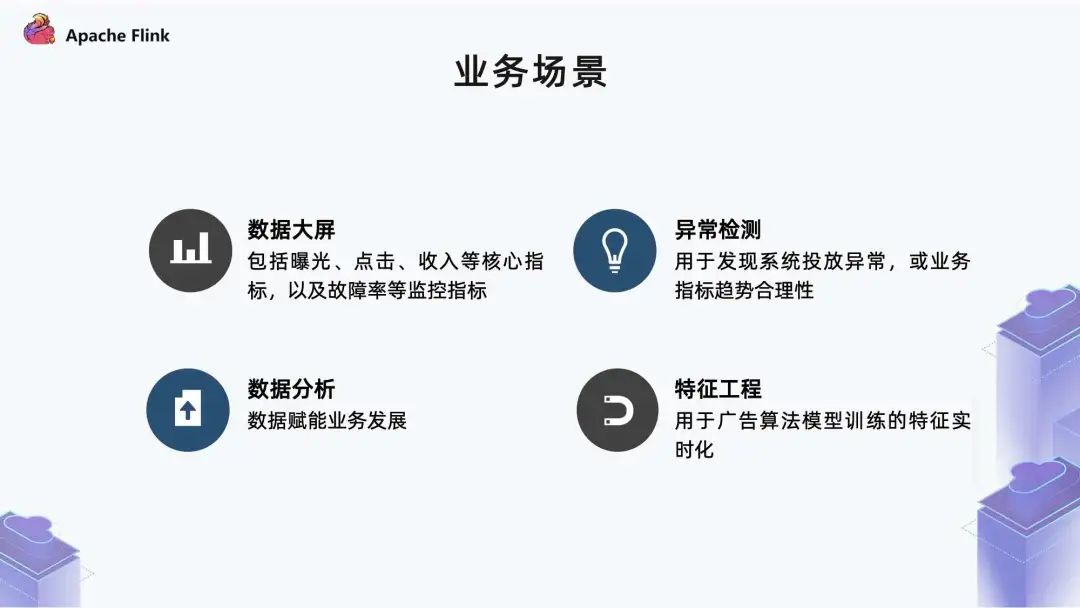
數(shù)據(jù)大屏:包括曝光、點(diǎn)擊、收入等核心指標(biāo)的展示,以及故障率等監(jiān)控指標(biāo); 異常監(jiān)測(cè):因?yàn)閺V告投放的鏈路比較?,所以如果鏈路上發(fā)生任何波動(dòng)的話(huà),都會(huì)對(duì)整體的投放效果產(chǎn)生影響。除此之外,各個(gè)團(tuán)隊(duì)在上線(xiàn)過(guò)程中是否會(huì)對(duì)整體投放產(chǎn)生影響,都是通過(guò)異常監(jiān)測(cè)系統(tǒng)能夠觀測(cè)到的。我們還能夠觀測(cè)業(yè)務(wù)指標(biāo)走勢(shì)是否合理,比如在庫(kù)存正常的情況下,曝光是否有不同的波動(dòng)情況,這可以用來(lái)實(shí) 時(shí)發(fā)現(xiàn)問(wèn)題; 數(shù)據(jù)分析:主要用于數(shù)據(jù)賦能業(yè)務(wù)發(fā)展。我們可以實(shí)時(shí)分析廣告投放過(guò)程中的一些異常問(wèn)題,或者基于當(dāng)前的投放效果去研究怎樣優(yōu)化,從而達(dá)到更好的效果; 特征工程:廣告算法團(tuán)隊(duì)主要是做一些模型訓(xùn)練,用于支持線(xiàn)上投放。技術(shù)特征最初大部分是離線(xiàn),隨著實(shí)時(shí)的發(fā)展,開(kāi)始把一些工程轉(zhuǎn)到實(shí)時(shí)。
二、業(yè)務(wù)實(shí)踐
1. 實(shí)時(shí)數(shù)倉(cāng)
■?1.1 實(shí)時(shí)數(shù)倉(cāng) - 目標(biāo)

數(shù)據(jù)完整性:在廣告業(yè)務(wù)里,實(shí)時(shí)數(shù)據(jù)主要是用于指導(dǎo)決策,比如廣告主需要根據(jù)當(dāng)前投放的實(shí)時(shí)數(shù)據(jù),指導(dǎo)后面的出價(jià)或調(diào)整預(yù)算。另外,故障率的監(jiān)控需要數(shù)據(jù)本身是穩(wěn)定的。如果數(shù)據(jù)是波動(dòng)的,指導(dǎo)意義就非常差,甚至沒(méi)有什么指導(dǎo)意義。因此完整性本身是對(duì)時(shí)效性和完整性之間做了一個(gè)權(quán)衡; 服務(wù)穩(wěn)定性:生產(chǎn)鏈包括數(shù)據(jù)接入、計(jì)算(多層)、數(shù)據(jù)寫(xiě)入、進(jìn)度服務(wù)和查詢(xún)服務(wù)。除此之外還有數(shù)據(jù)質(zhì)量,包括數(shù)據(jù)的準(zhǔn)確性以及數(shù)據(jù)趨勢(shì)是否符合預(yù)期; 查詢(xún)能力:在廣告業(yè)務(wù)有多種使用場(chǎng)景,在不同場(chǎng)景里可能使用了不同的 OLAP 引擎,所以查詢(xún)方式和性能的要求不一致。另外,在做數(shù)據(jù)分析的時(shí)候,除了最新最穩(wěn)定的實(shí)時(shí)數(shù)據(jù)之外,同時(shí)也會(huì)實(shí)時(shí) + 離線(xiàn)做分析查詢(xún),此外還包括數(shù)據(jù)跨源和查詢(xún)性能等要求。
■?1.2 實(shí)時(shí)數(shù)倉(cāng) - 挑戰(zhàn)

數(shù)據(jù)進(jìn)度服務(wù):需要在時(shí)效性和完整性之間做一個(gè)權(quán)衡; 數(shù)據(jù)穩(wěn)定性:由于生產(chǎn)鏈路比較長(zhǎng),中間可能會(huì)用到多種功能組件,所以端到端的服務(wù)穩(wěn)定性對(duì)整體數(shù)據(jù)準(zhǔn)確性的影響是比較關(guān)鍵的; 查詢(xún)性能:主要包括 OLAP 分析能力。在實(shí)際場(chǎng)景中,數(shù)據(jù)表包含了離線(xiàn)和實(shí)時(shí),單表規(guī)模達(dá)上百列,行數(shù)也是非常大的。
■?1.3 廣告數(shù)據(jù)平臺(tái)架構(gòu)
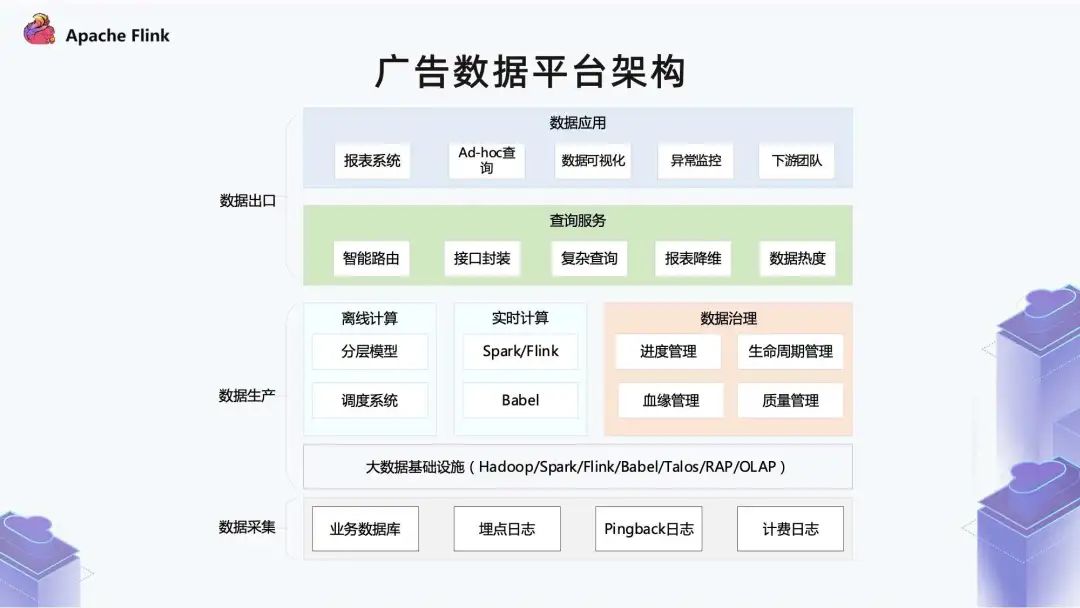
底部是數(shù)據(jù)采集層,這里與大部分公司基本一致。業(yè)務(wù)數(shù)據(jù)庫(kù)主要包含了廣告主的下單數(shù)據(jù)以及投放的策略;埋點(diǎn)日志和計(jì)費(fèi)日志是廣告投放鏈路過(guò)程中產(chǎn)生的日志; 中間是數(shù)據(jù)生產(chǎn)的部分,數(shù)據(jù)生產(chǎn)的底層是大數(shù)據(jù)的基礎(chǔ)設(shè)施,這部分由公司的一個(gè)云平臺(tái)團(tuán)隊(duì)提供,其中包含 Spark / Flink 計(jì)算引擎,Babel 統(tǒng)一的管理平臺(tái)。Talos 是實(shí)時(shí)數(shù)倉(cāng)服務(wù),RAP 和 OLAP 對(duì)應(yīng)不同的實(shí)時(shí)分析以及 OLAP 存儲(chǔ)和查詢(xún)服務(wù)。 數(shù)據(jù)生產(chǎn)的中間層是廣告團(tuán)隊(duì)包含的一些服務(wù),例如在生產(chǎn)里比較典型的離線(xiàn)計(jì)算和實(shí)時(shí)計(jì)算。 離線(xiàn)是比較常見(jiàn)的一個(gè)分層模型,調(diào)度系統(tǒng)是對(duì)生產(chǎn)出的離線(xiàn)任務(wù)做有效的管理和調(diào)度。 實(shí)時(shí)計(jì)算這邊使用的引擎也比較多,我們的實(shí)時(shí)化是從 2016 年開(kāi)始,當(dāng)時(shí)選的是 Spark Streaming,后面隨著大數(shù)據(jù)技術(shù)發(fā)展以及公司業(yè)務(wù)需求產(chǎn)生了不同場(chǎng)景,又引入了計(jì)算引擎 Flink。 實(shí)時(shí)計(jì)算底層調(diào)度依賴(lài)于云計(jì)算的 Babel 系統(tǒng),除了計(jì)算之外還會(huì)伴隨數(shù)據(jù)治理,包括進(jìn)度管理,就是指實(shí)時(shí)計(jì)算里一個(gè)數(shù)據(jù)報(bào)表當(dāng)前已經(jīng)穩(wěn)定的進(jìn)度到哪個(gè)時(shí)間點(diǎn)。離線(xiàn)里其實(shí)就對(duì)應(yīng)一個(gè)表,有哪些分區(qū)。 血緣管理包括兩方面,離線(xiàn)包括表級(jí)別的血緣以及字段血緣。實(shí)時(shí)主要還是在任務(wù)層面的血緣。 至于生命周期管理,在離線(xiàn)的一個(gè)數(shù)倉(cāng)里,它的計(jì)算是持續(xù)迭代的。但是數(shù)據(jù)保留時(shí)間非常長(zhǎng)的話(huà),數(shù)據(jù)量對(duì)于底層的存儲(chǔ)壓力就會(huì)比較大。 數(shù)據(jù)生命周期管理主要是根據(jù)業(yè)務(wù)需求和存儲(chǔ)成本之間做一個(gè)權(quán)衡。 質(zhì)量管理主要包括兩方面,一部分在數(shù)據(jù)接入層,判斷數(shù)據(jù)本身是否合理;另外一部分在數(shù)據(jù)出口,就是結(jié)果指標(biāo)這一層。因?yàn)槲覀兊臄?shù)據(jù)會(huì)供給其他很多團(tuán)隊(duì)使用,因此在數(shù)據(jù)出口這一層要保證數(shù)據(jù)計(jì)算沒(méi)有問(wèn)題。 再上層是統(tǒng)一查詢(xún)服務(wù),我們會(huì)封裝很多接口進(jìn)行查詢(xún)。
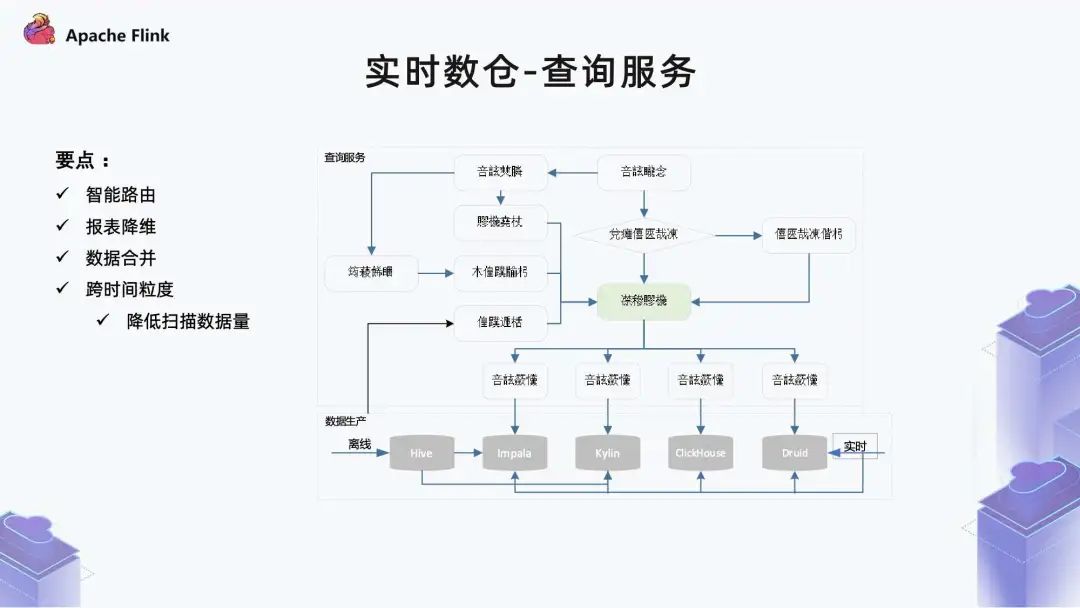
因?yàn)閿?shù)據(jù)化包括離線(xiàn)和實(shí)時(shí),另外還有跨集群,所以在智能路由這里會(huì)進(jìn)行一些選集群、選表以及復(fù)雜查詢(xún)、拆分等核心功能。 查詢(xún)服務(wù)會(huì)對(duì)歷史查詢(xún)進(jìn)行熱度的統(tǒng)一管理。這樣一方面可以更應(yīng)進(jìn)一步服務(wù)生命周期管理,另一方面可以去看哪些數(shù)據(jù)對(duì)于業(yè)務(wù)的意義非常大。 除了生命周期管理之外,它還可以指導(dǎo)我們的調(diào)度系統(tǒng),比如哪些報(bào)表比較關(guān)鍵,在資源緊張的時(shí)候就可以?xún)?yōu)先調(diào)度這些任務(wù)。 再往上是數(shù)據(jù)應(yīng)用,包括報(bào)表系統(tǒng)、Add - hoc 查詢(xún)、數(shù)據(jù)可視化、異常監(jiān)控和下游團(tuán)隊(duì)。
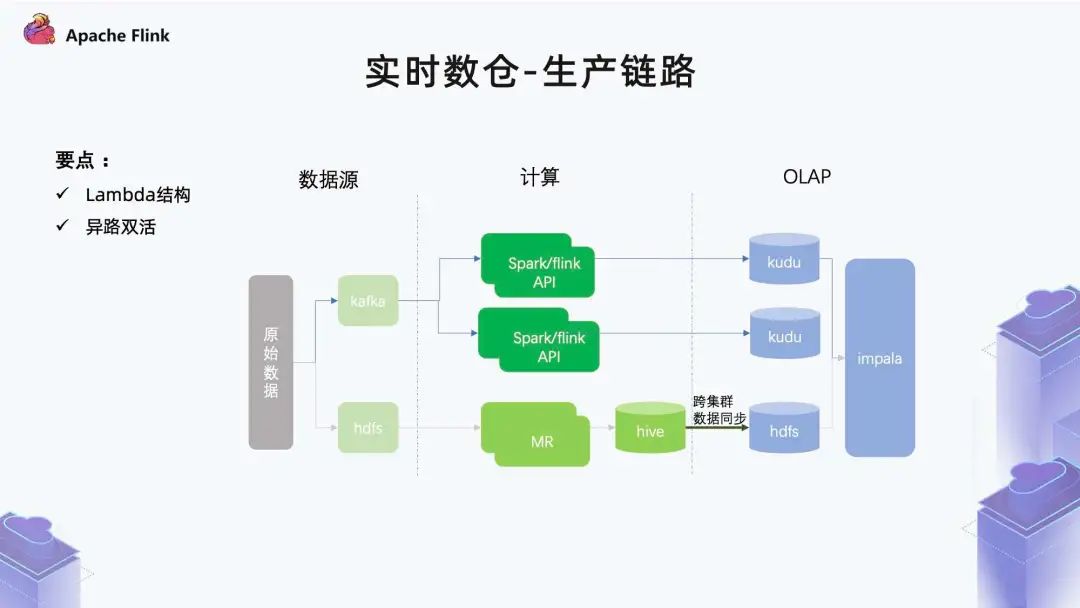
■?1.4 實(shí)時(shí)數(shù)倉(cāng) - 生產(chǎn)鏈路
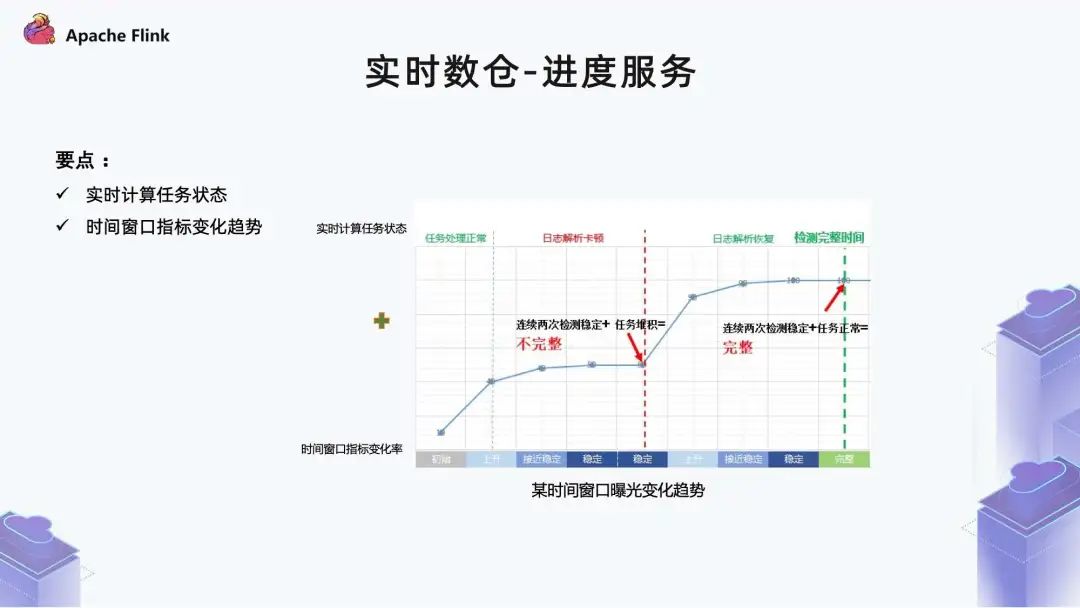
■?1.5 實(shí)時(shí)數(shù)倉(cāng) - 進(jìn)度服務(wù)
■?1.6 實(shí)時(shí)數(shù)倉(cāng) - 查詢(xún)服務(wù)
■?1.7 數(shù)據(jù)生產(chǎn) - 規(guī)劃
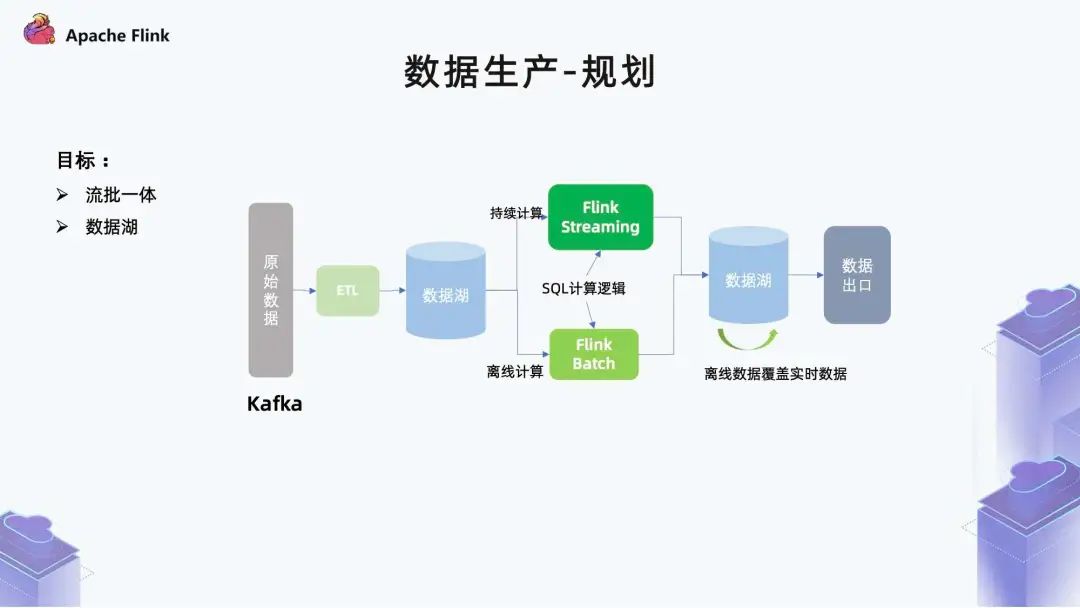
一方面是他們的邏輯可能會(huì)發(fā)生差異,最終導(dǎo)致結(jié)果表不一致;
另一方面是人力成本,同時(shí)需要兩個(gè)團(tuán)隊(duì)進(jìn)行開(kāi)發(fā)。
■?1.8 數(shù)據(jù)生產(chǎn) - SQL 化
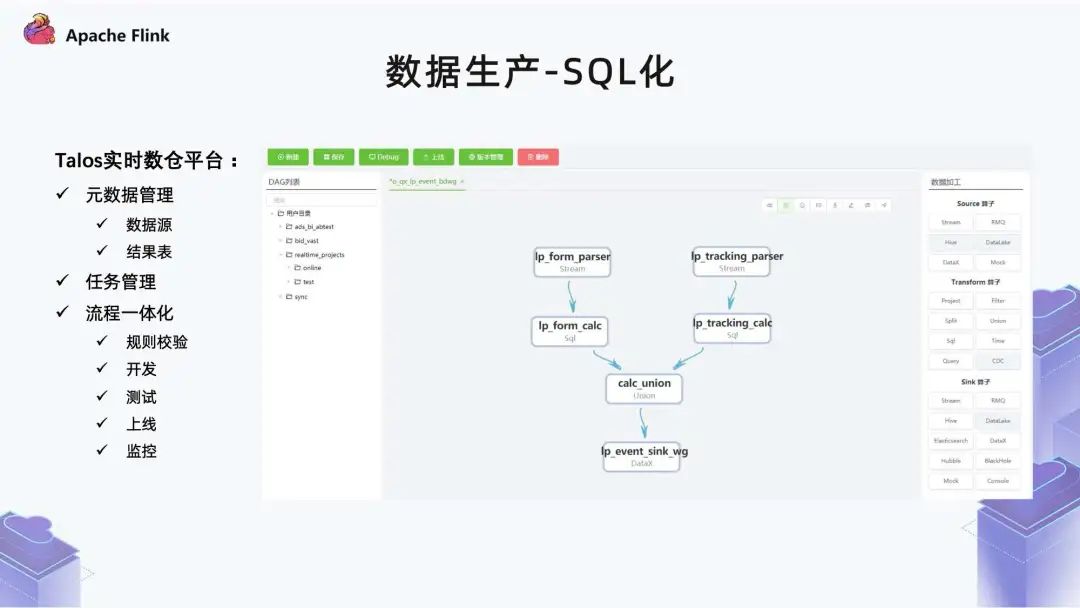
有一些業(yè)務(wù)團(tuán)隊(duì)本身對(duì)于計(jì)算引擎算子非常熟,那么他們便可以做一些代碼開(kāi)發(fā); 但是很多業(yè)務(wù)團(tuán)隊(duì)可能對(duì)引擎并不是那么了解,或者沒(méi)有強(qiáng)烈的意愿去了解,他們就可以通過(guò)這種可視化的方式,拼接出一個(gè)作業(yè)。
2. 特征工程

第一個(gè)需求是實(shí)時(shí)化,因?yàn)閿?shù)據(jù)價(jià)值隨著時(shí)間的遞增會(huì)越來(lái)越低。比如某用戶(hù)表現(xiàn)出來(lái)的觀影行為是喜歡看兒童內(nèi)容,平臺(tái)就會(huì)推薦兒童相關(guān)的廣告。另外,用戶(hù)在看廣告過(guò)程中,會(huì)有一些正/負(fù)反饋的行為,如果把這些數(shù)據(jù)實(shí)時(shí)迭代到特征里,就可以有效提升后續(xù)的轉(zhuǎn)化效果。
特征工程的第二個(gè)需求是服務(wù)穩(wěn)定性。
首先是作業(yè)容錯(cuò),比如作業(yè)在異常的時(shí)候能否正常恢復(fù); 另外是數(shù)據(jù)質(zhì)量,在實(shí)時(shí)數(shù)據(jù)里追求端到端精確一次。
■?2.1 點(diǎn)擊率預(yù)估
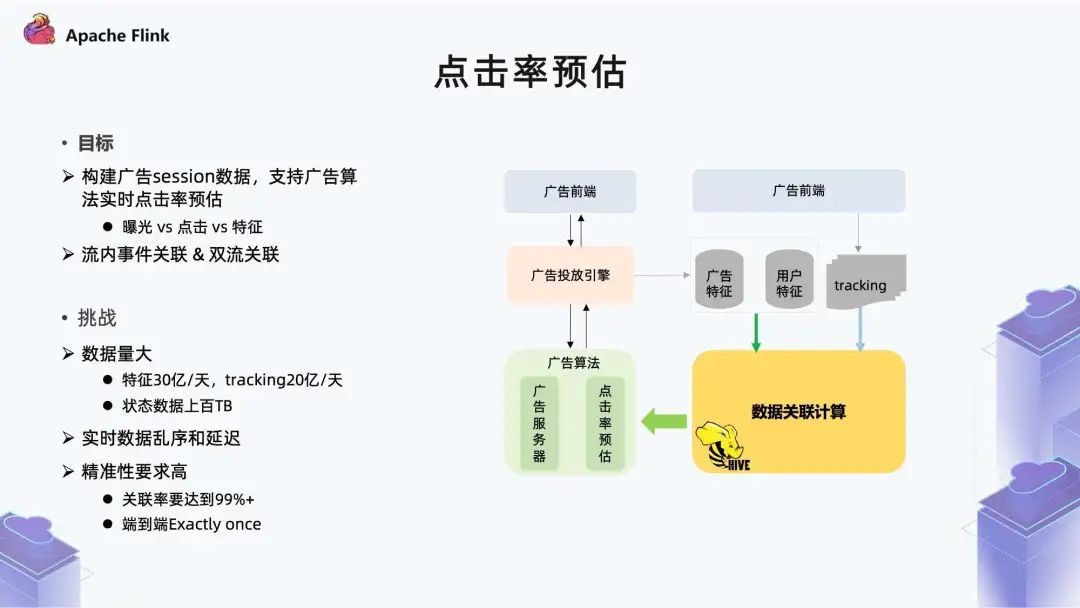
一方面是 Tracking 流里曝光、點(diǎn)擊事件的關(guān)聯(lián); 另一方面是特征流跟用戶(hù)行為的關(guān)聯(lián)。
第一個(gè)挑戰(zhàn)是數(shù)據(jù)量; 第二個(gè)挑戰(zhàn)是實(shí)時(shí)數(shù)據(jù)亂序和延遲; 第三個(gè)挑戰(zhàn)是精確性要求高。
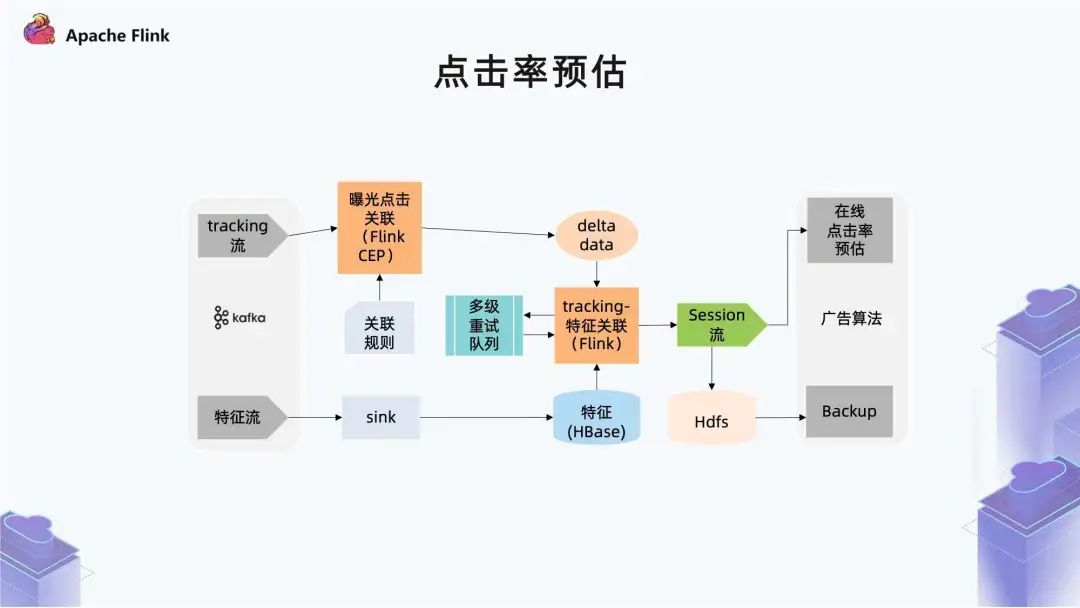
第一個(gè)部分是用戶(hù)行為流里曝光跟點(diǎn)擊事件的關(guān)聯(lián),這里通過(guò) CEP 實(shí)現(xiàn)。
第二個(gè)部分是兩個(gè)流的關(guān)聯(lián),前面介紹特征需要保留 7 天,它的狀態(tài)較大,已經(jīng)是上百 TB。這個(gè)量級(jí)在內(nèi)存里做管理,對(duì)數(shù)據(jù)穩(wěn)定性有比較大的影響,所以我們把特征數(shù)據(jù)放在一個(gè)外部存儲(chǔ) (Hbase) 里,然后和 HBase 特征做一個(gè)實(shí)時(shí)數(shù)據(jù)查詢(xún),就可以達(dá)到這樣一個(gè)效果。
■?2.2 點(diǎn)擊率預(yù)估 - 流內(nèi)事件關(guān)聯(lián)
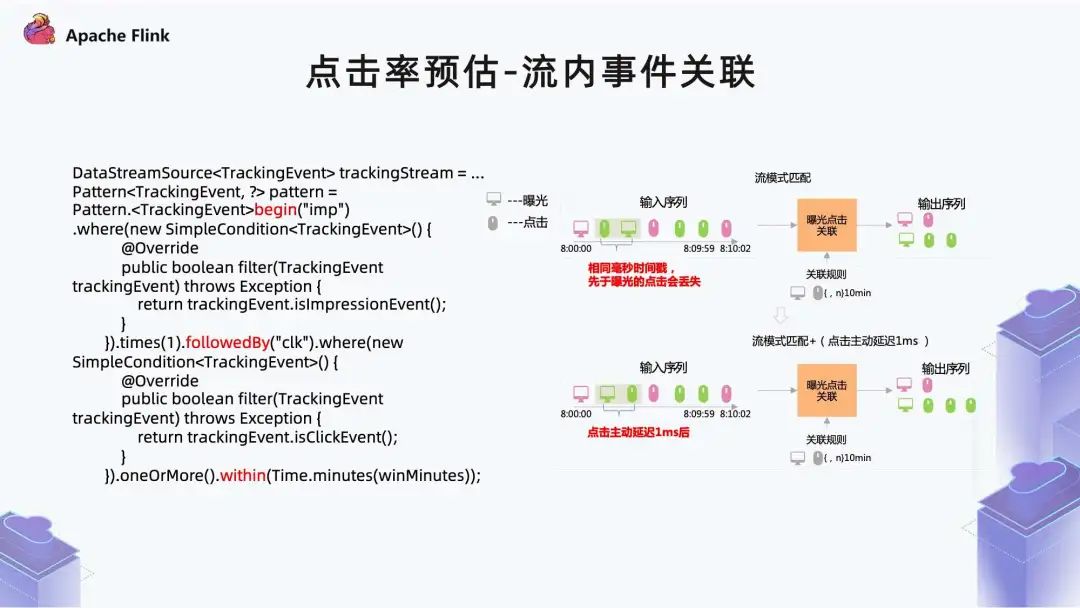
如果事件序列本身都在同一個(gè)窗口之內(nèi),數(shù)據(jù)沒(méi)有問(wèn)題; 但是當(dāng)事件序列跨窗口的時(shí)候,是達(dá)不到正常關(guān)聯(lián)效果的。
■?2.3 點(diǎn)擊率預(yù)估-雙流關(guān)聯(lián)
首先支持比較高的讀寫(xiě)并發(fā)能力; 另外它的時(shí)效性需要非常低; 同時(shí)因?yàn)閿?shù)據(jù)要保留 7 天,所以它最好具備生命周期管理能力。
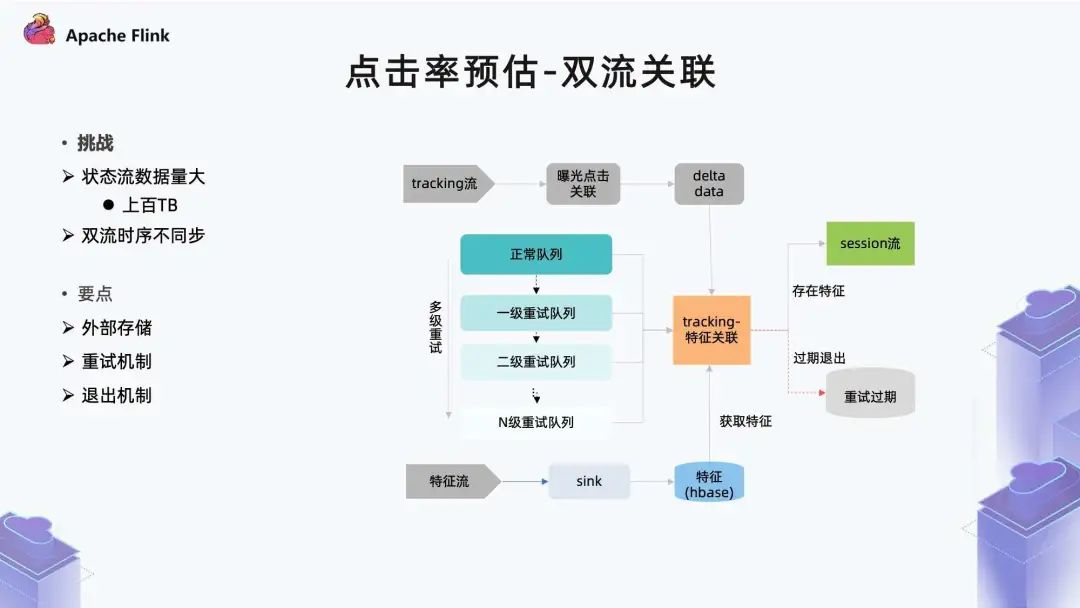
第一點(diǎn)是特征數(shù)據(jù)保留了 7 天,如果對(duì)應(yīng)特征是在 7 天之前,那么它本身是關(guān)聯(lián)不到的。
另外在廣告業(yè)務(wù)里,存在一些外部的刷量行為,比如刷曝光或刷點(diǎn)擊,但它本身并沒(méi)有真實(shí)存在的廣告請(qǐng)求,所以這種場(chǎng)景也拿不到對(duì)應(yīng)特征。
■?2.4 有效點(diǎn)擊
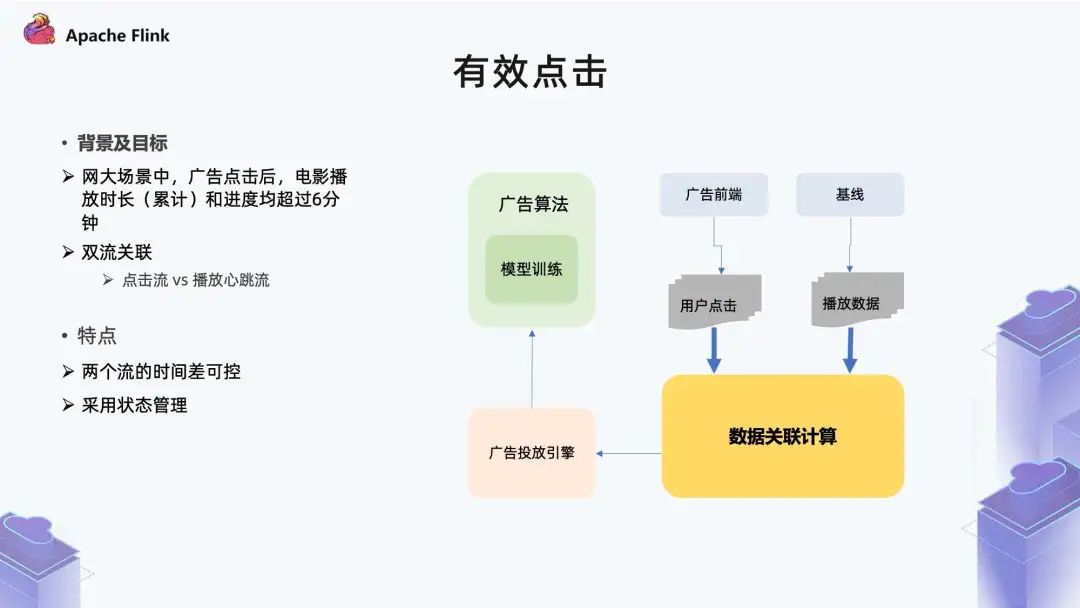
點(diǎn)擊流比較好理解,包括用戶(hù)的曝光和點(diǎn)擊等行為,從里面篩選點(diǎn)擊事件即可。
播放行為流是在用戶(hù)觀看的過(guò)程,會(huì)定時(shí)地把心跳信息回傳,比如三秒鐘回傳一個(gè)心跳,表明用戶(hù)在持續(xù)觀看。在定義時(shí)長(zhǎng)超過(guò) 6 分鐘的時(shí)候,需要把這個(gè)狀態(tài)本身做一些處理,才能滿(mǎn)足 6 分鐘的條件。
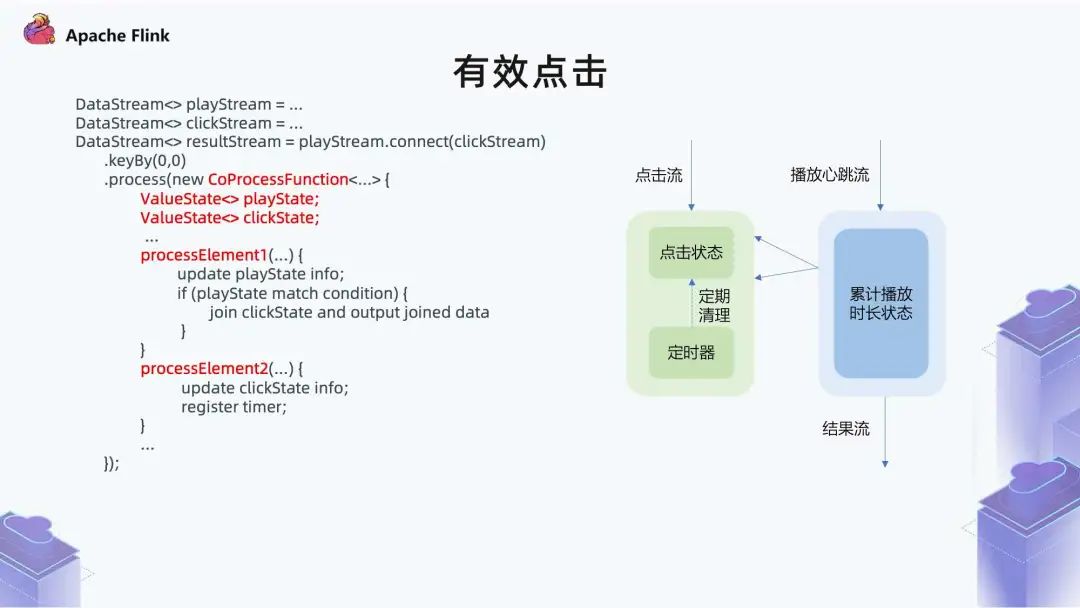
在左邊的狀態(tài)里面,一個(gè)點(diǎn)擊事件進(jìn)來(lái)之后,會(huì)對(duì)這個(gè)點(diǎn)擊做一個(gè)狀態(tài)記錄,同時(shí)會(huì)注冊(cè)一個(gè)定時(shí)器做定期清理,定時(shí)器是三個(gè)小時(shí)。因?yàn)榇蟛糠钟捌臅r(shí)長(zhǎng)在三小時(shí)以?xún)?nèi),如果這個(gè)時(shí)候?qū)?yīng)的播放事件還沒(méi)有一個(gè)目標(biāo)狀態(tài),點(diǎn)擊事件基本就可以過(guò)期了。
在右邊的播放心跳流里,這個(gè)狀態(tài)是對(duì)時(shí)長(zhǎng)做累計(jì),它本身是一個(gè)心跳流,比如每三秒傳一個(gè)心跳過(guò)來(lái)。我們需要在這里做一個(gè)計(jì)算,看它累計(jì)播放時(shí)長(zhǎng)是不是達(dá)到 6 分鐘了,另外也看當(dāng)前記錄是不是到了 6 分鐘。對(duì)應(yīng) Flink 里的一個(gè)實(shí)現(xiàn)就是把兩個(gè)流通過(guò) Connect 算子關(guān)系在一起,然后可以制定一個(gè) CoProcessFunction,在這里面有兩個(gè)核心算子。 第一個(gè)算子是拿到狀態(tài) 1 的流事件之后,需要做一些什么樣的處理; 第二個(gè)算子是拿到第 2 個(gè)流事件之后,可以自定義哪些功能。
■?2.5 特征工程 - 小結(jié)

三、Flink 使用過(guò)程中的問(wèn)題及解決
1. 容錯(cuò)

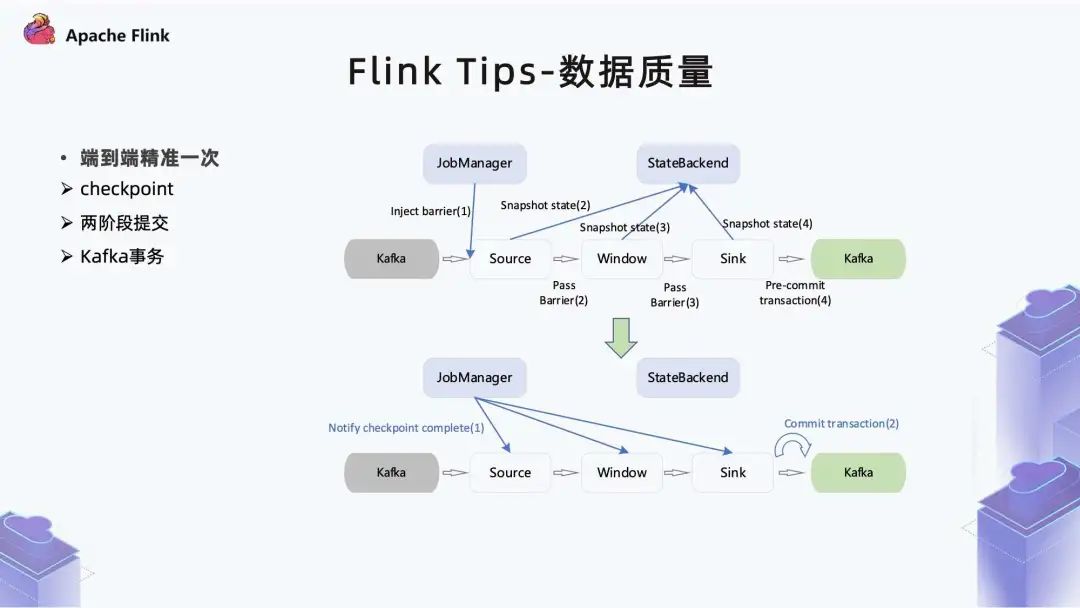
2. 數(shù)據(jù)質(zhì)量
3. Sink Kafka

第一個(gè)辦法是用戶(hù)自定義一個(gè) FlinkKafkaPartitioner;
另一個(gè)辦法是默認(rèn)不配置,默認(rèn)輪詢(xún)寫(xiě)入各個(gè) Partition。
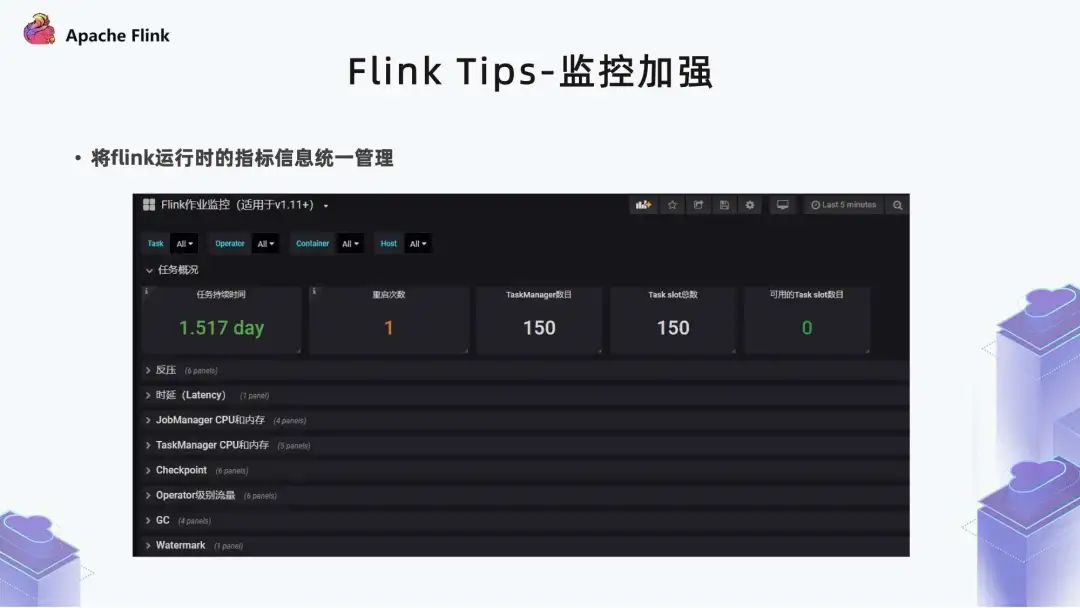
4. 監(jiān)控加強(qiáng)
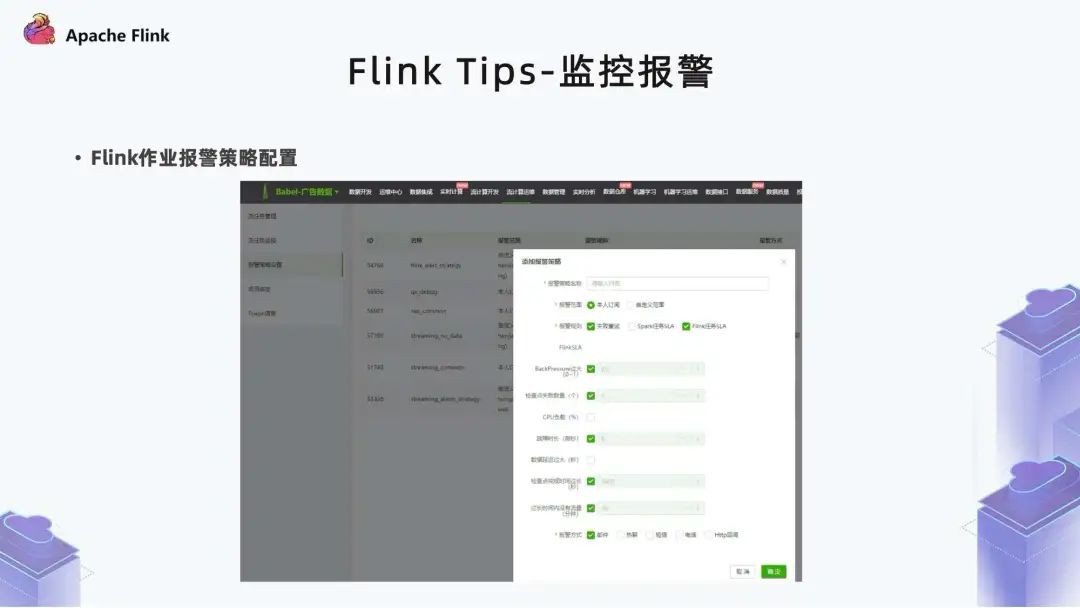
5. 監(jiān)控報(bào)警
6. 實(shí)時(shí)數(shù)據(jù)生產(chǎn)
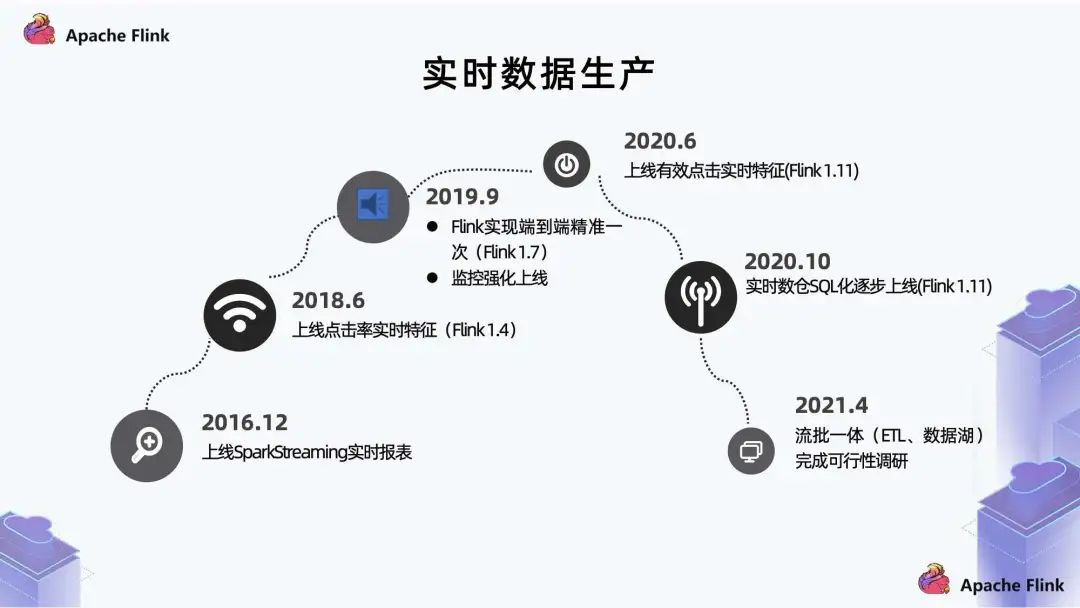
我們的實(shí)時(shí)是從 2016 年開(kāi)始起步,當(dāng)時(shí)主要功能點(diǎn)是做一些指標(biāo)實(shí)時(shí)化,使用的是 SparkStreaming; 2018 年上線(xiàn)了點(diǎn)擊率實(shí)時(shí)特征; 2019 年上線(xiàn)了 Flink 的端到端精確到一次和監(jiān)控強(qiáng)化。 2020 年上線(xiàn)了有效點(diǎn)擊實(shí)時(shí)特征; 同年10月,逐步推進(jìn)實(shí)時(shí)數(shù)倉(cāng)的改進(jìn),把 API 生產(chǎn)方式逐漸 SQL 化;
2021 年 4 月,進(jìn)行流批一體的探索,目前先把流批一體放在 ETL 實(shí)現(xiàn)。
四、未來(lái)規(guī)劃

首先是流批一體,這里包括兩個(gè)方面: 第一個(gè)是 ETL 一體,目前已經(jīng)是基本達(dá)到可線(xiàn)上的狀態(tài)。 第二個(gè)是實(shí)時(shí)報(bào)表 SQL 化和數(shù)據(jù)湖的結(jié)合。 另外,現(xiàn)在的反作弊主要是通過(guò)離線(xiàn)的方式實(shí)現(xiàn),后面可能會(huì)把一些線(xiàn)上的反 作弊模型轉(zhuǎn)成實(shí)時(shí)化,把風(fēng)險(xiǎn)降到最低。
評(píng)論
圖片
表情