
Flink 實(shí)踐 | Flink 流批一體在 Shopee 的大規(guī)模實(shí)踐
????1.? 流批一體在 Shopee 的應(yīng)用場(chǎng)景 ????2.? 批處理能力的生產(chǎn)優(yōu)化 ????3.? 與離線生態(tài)的完全集成 ? ? 4.?平臺(tái)在流批一體上的建設(shè)和演進(jìn)
Tips: 點(diǎn)擊 「閱讀原文」 免費(fèi)領(lǐng)取 5000CU*小時(shí) Flink 云資源
01
流批一體在 Shopee 的應(yīng)用場(chǎng)景

首先,先來了解一下 Flink 在 Shopee 的使用情況。
除了流任務(wù),僅從支持的批任務(wù)來看,F(xiàn)link 平臺(tái)上的作業(yè)已經(jīng)到達(dá)了一個(gè)比較大的規(guī)模。
目前 Flink 批任務(wù)已經(jīng)在 Shopee 內(nèi)部超過 60 個(gè) Project 上使用,作業(yè)數(shù)量也超過了 1000,這些作業(yè)在調(diào)度系統(tǒng)的支持下,每天會(huì)生成超過 5000 個(gè)實(shí)例來支持各個(gè)業(yè)務(wù)線。
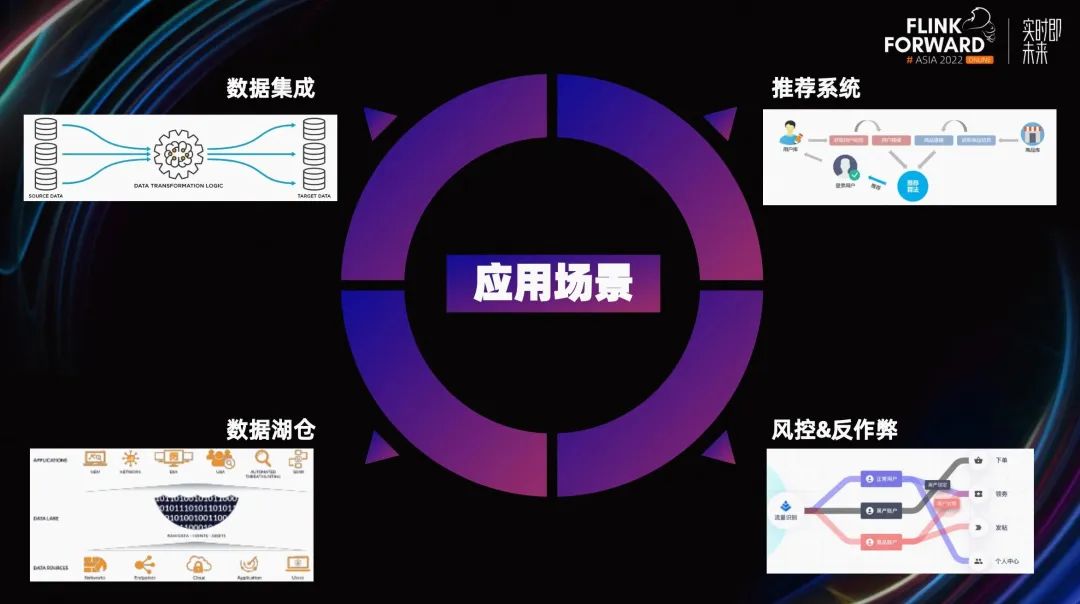
從應(yīng)用場(chǎng)景劃分,這些作業(yè)在 Shopee 主要分為以下四個(gè)部分:
-
第一個(gè)應(yīng)用場(chǎng)景是數(shù)據(jù)集成領(lǐng)域。
-
第二個(gè)應(yīng)用場(chǎng)景是數(shù)倉領(lǐng)域。
-
第三個(gè)應(yīng)用場(chǎng)景是特征工程,主要用于實(shí)時(shí)和離線特征的生成。
- 第四個(gè)應(yīng)用場(chǎng)景是風(fēng)控反作弊領(lǐng)域,用做實(shí)時(shí)反作弊和離線反作弊。
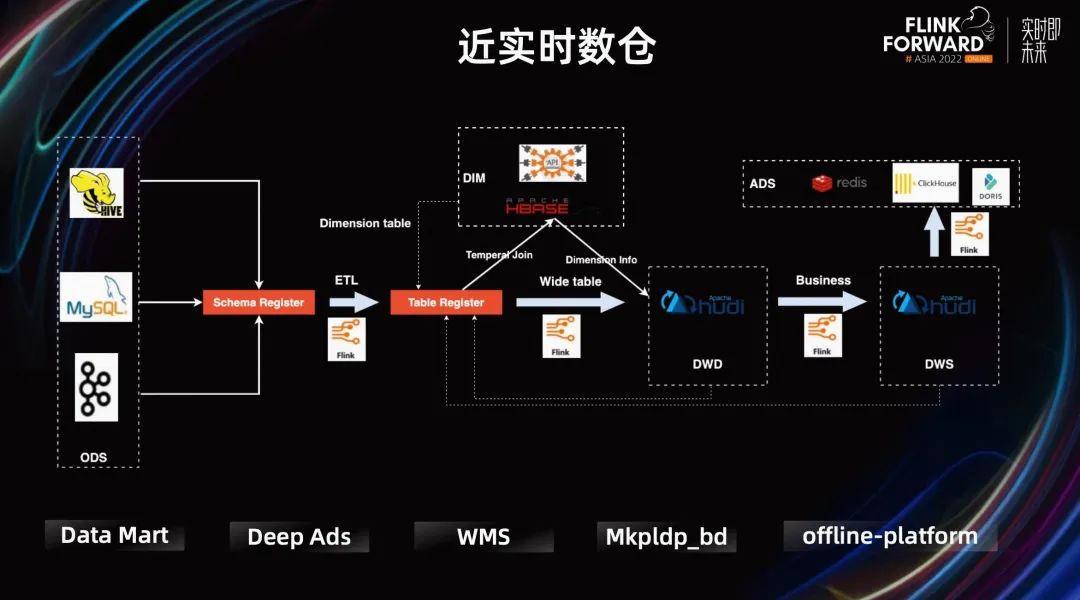
從 Shopee 內(nèi)部的業(yè)務(wù)場(chǎng)景來看,數(shù)倉是一個(gè)流批一體發(fā)揮重要作用的領(lǐng)域。
目前,業(yè)內(nèi)還沒有這樣一個(gè)端到端流式數(shù)倉的成熟解決方案,大部分都是通過一些純流的方案 + 離線數(shù)倉方案 + 交互式查詢方案疊加起來達(dá)到近似效果。
在這類 Lambda 架構(gòu)中,F(xiàn)link 流批一體主要帶來的優(yōu)勢(shì)是實(shí)現(xiàn)計(jì)算統(tǒng)一。通過計(jì)算統(tǒng)一去降低用戶的開發(fā)及維護(hù)成本,解決兩套系統(tǒng)中計(jì)算邏輯和數(shù)據(jù)口徑不一致的問題。
但這樣的 Lambda 架構(gòu)復(fù)雜性又太高了。所以針對(duì)時(shí)延要求不高的業(yè)務(wù),Shopee 實(shí)時(shí)團(tuán)隊(duì)主推通過 Flink+ Hudi 的替代方案,構(gòu)建近實(shí)時(shí)數(shù)倉,這種方案可以解決很多場(chǎng)景的問題。
這種方案的好處很明顯,它實(shí)現(xiàn)了部分的流批一體:Flink 統(tǒng)一的引擎,Hudi 提供統(tǒng)一的存儲(chǔ)。它的限制也很明顯,Hudi 數(shù)據(jù)可見性與 Commit 的間隔相關(guān),進(jìn)而與 Flink 做 Checkpoint 的時(shí)間間隔相關(guān),這延長(zhǎng)了整個(gè)數(shù)據(jù)鏈路的時(shí)延。
目前這種 Flink+Hudi 的方案已經(jīng)在 Shopee 內(nèi)部很多業(yè)務(wù)線上進(jìn)行使用。比如廣告業(yè)務(wù)的 Deep ads.和 offline-platform ads.用于給廣告主和產(chǎn)品運(yùn)營(yíng)產(chǎn)出廣告數(shù)據(jù)。又比如 Shopee 核心業(yè)務(wù) supply chain 的 WMS。WMS 的數(shù)據(jù)服務(wù)整體使用的是 lambda 架構(gòu)。但對(duì)于核心業(yè)務(wù)使用該方案生成的近實(shí)時(shí)數(shù)據(jù),用于與離線數(shù)據(jù)做 diff,監(jiān)控實(shí)時(shí)鏈路提供的數(shù)據(jù)質(zhì)量。
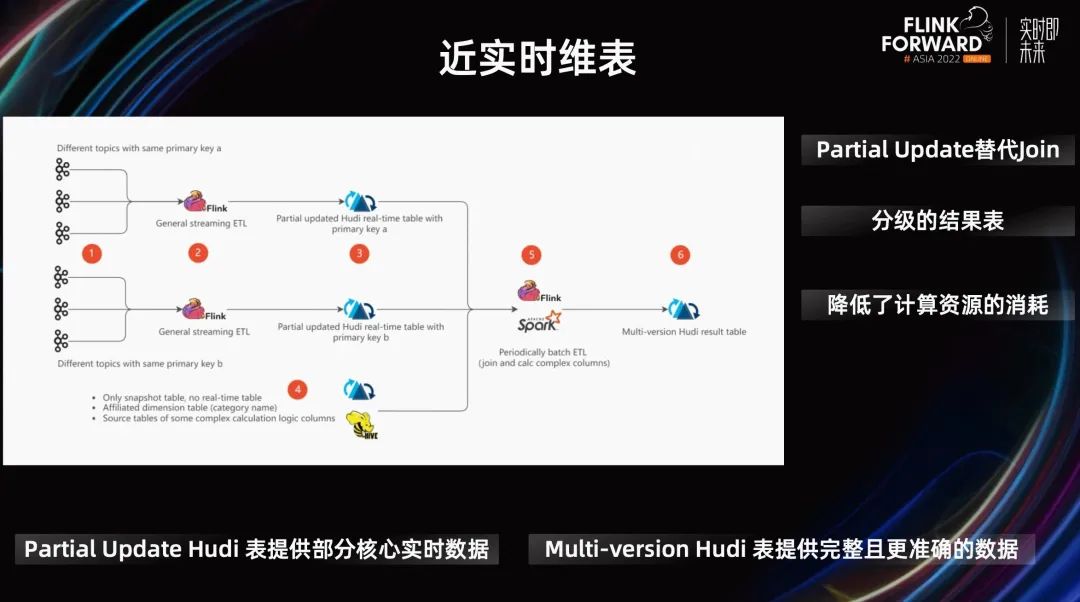
上圖 PPT 展示了 Datamart 的一個(gè)例子。Datamart 使用 Hudi partital update 完成 DIM 表的 Join 更新,降低資源使用量。
之前,他們每小時(shí)對(duì)最近 3 小時(shí)的數(shù)據(jù)進(jìn)行計(jì)算和刷新,在保證數(shù)據(jù)及時(shí)更新的情況下,解決數(shù)據(jù)延遲、Join 時(shí)間不對(duì)齊等問題。但隨著數(shù)據(jù)量的迅速增長(zhǎng),小時(shí)級(jí)數(shù)據(jù) SLA 的保障難度和計(jì)算資源的消耗都在不斷增加。
現(xiàn)在,用戶一方面通過 Flink 加速計(jì)算,另一方面通過與批處理結(jié)合來確保數(shù)據(jù)的最終一致性。并通過提供分級(jí)的結(jié)果表來滿足不同場(chǎng)景的及時(shí)性要求,實(shí)時(shí)計(jì)算產(chǎn)出的 Partial Update Hudi 表提供部分核心實(shí)時(shí)數(shù)據(jù),批處理產(chǎn)出的 Multi-version Hudi 表提供完整且更準(zhǔn)確的數(shù)據(jù)。
最終,在確保數(shù)據(jù)一致性的基礎(chǔ)上,達(dá)到了分鐘級(jí)延遲,并有效降低了計(jì)算資源的消耗。

除了業(yè)務(wù)線使用之外,目前 Shopee 內(nèi)部提供的一些平臺(tái)服務(wù)也在使用 Flink。 第一個(gè)例子是 Data Infra 團(tuán)隊(duì)提供的 Data Hub, 它提供了一些離線集成和實(shí)時(shí)集成的常用模塊。之前他們必須引入不同的引擎來支持不同的集成模塊,導(dǎo)致項(xiàng)目依賴復(fù)雜,用戶也需要了解多套引擎。
使用 Flink 后,在之后新的需求中,Data Hub 不再需要引入不同的引擎來解決批和流兩套數(shù)據(jù)的集成。
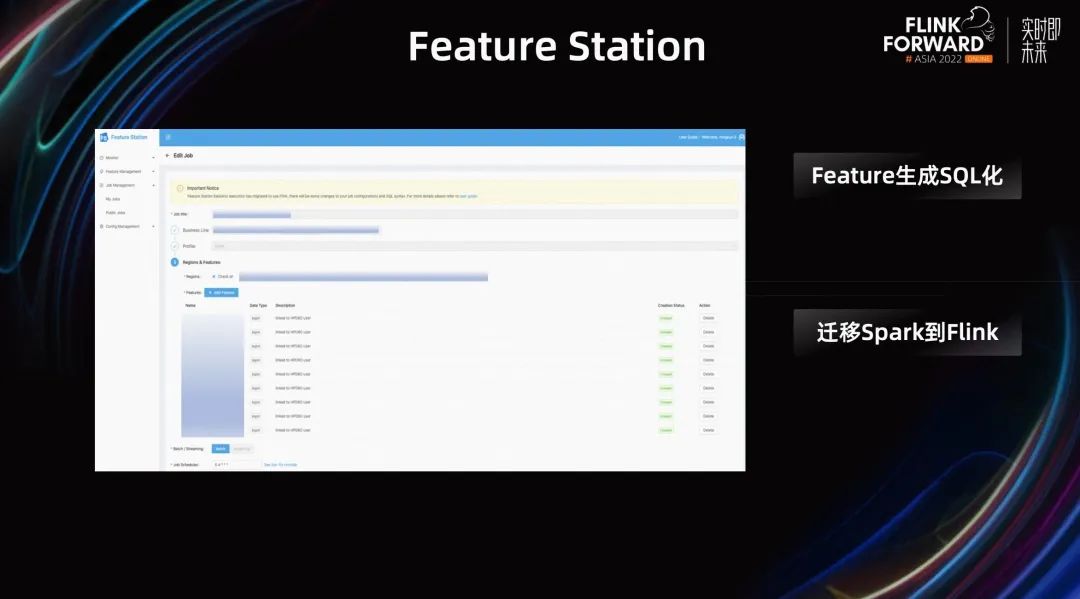
第二個(gè)例子是 Feature Station,F(xiàn)eature Station 是 Shopee 內(nèi)部提供的一個(gè) 特征生成的平臺(tái)。它提供了一些降低用戶運(yùn)維成本的功能,比如 Feature 生成 SQL 化,支持多業(yè)務(wù)線并行開發(fā)等等。
之前這個(gè)平臺(tái)的任務(wù)依賴 Spark,后來從 Spark 全部遷移到了 Flink。Flink 帶來的一個(gè)很大的優(yōu)勢(shì)是便于擴(kuò)展。如果之后用戶有實(shí)時(shí)特征需求,用戶可以將離線特征的生成邏輯非常快速的復(fù)用到實(shí)時(shí)特征上。
上面介紹的都是 Shopee 內(nèi)部流批一體應(yīng)用場(chǎng)景的一些例子,我們內(nèi)部還有很多團(tuán)隊(duì)也正在嘗試 Flink 的流批一體,未來會(huì)使用的更廣泛。
02
批處理能力的生產(chǎn)優(yōu)化
Flink 在流處理方面一直有著天然的優(yōu)勢(shì),相對(duì)而言,批的能力較弱一些。我們都能看到,社區(qū)最近幾個(gè)版本中,一直在大力推進(jìn) Flink 批處理的能力。而對(duì)批支持的好壞也一直是用戶選擇 Flink 流批一體的一個(gè)重要影響因素。下面將基于內(nèi)部的實(shí)踐,我將介紹一下 Shopee 對(duì) Flink 批在生產(chǎn)上的一些優(yōu)化,主要分為穩(wěn)定性和易用性兩個(gè)方向。
2.1 穩(wěn)定性

批作業(yè)一般都是通過調(diào)度系統(tǒng)周期性調(diào)度的。用戶一般會(huì)管理大量的批作業(yè),所以在生產(chǎn)實(shí)踐中,他們非常關(guān)注作業(yè)的穩(wěn)定性。
Flink Batch 在使用過程中,我們主要遇到了以下的問題:
-
當(dāng)大作業(yè)執(zhí)行時(shí)間長(zhǎng)時(shí),任務(wù)越容易遇到各種問題,失敗次數(shù)會(huì)顯著增加。
- Task 失敗后 failover 的成本過高,作業(yè)的整體耗時(shí)會(huì)被嚴(yán)重拉長(zhǎng)。
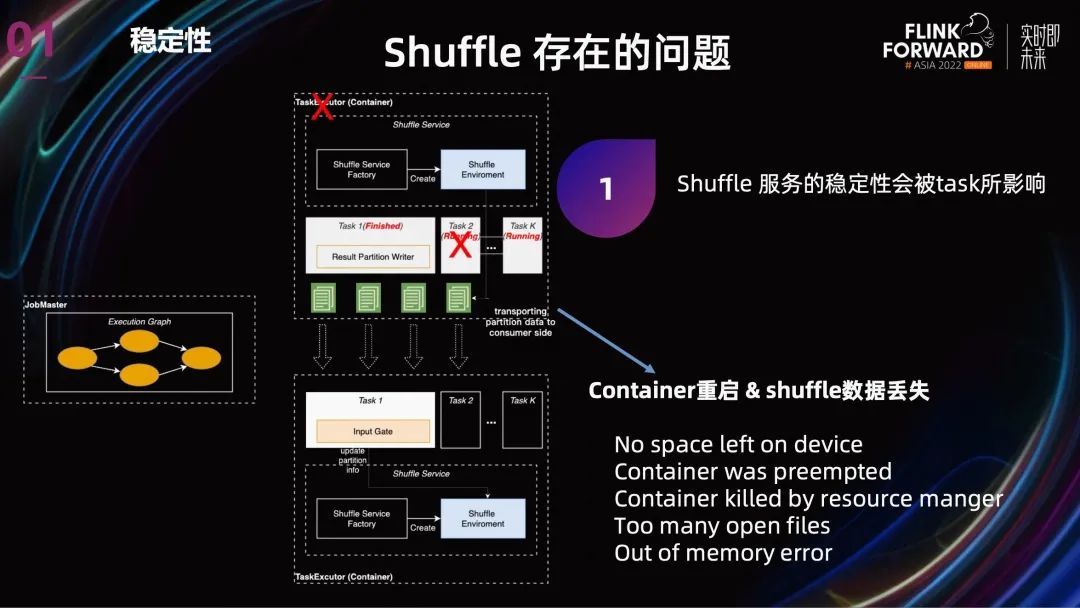
Flink 目前提供了兩種 Shuffle,Hash Shuffle 和 Sort Shuffle,但這兩種 Shuffle 的不同主要是表現(xiàn)在 Shuffle 數(shù)據(jù)的結(jié)構(gòu)上,從 Shuffle 的整體架構(gòu)上看,兩者都是 Internal Shuffle。Internal Shuffle 就是 Shuffle 服務(wù)與 Task 共享進(jìn)程,TaskManager 在 Task 執(zhí)行完成之后還要繼續(xù)保留去做 Shuffle 服務(wù)。
Internal Shuffle 的問題主要有兩個(gè):
第一個(gè)是:Shuffle 服務(wù)的穩(wěn)定性會(huì)被有問題的 task 所影響。
-
這個(gè)有問題 task 可能來自 job 本身,也可能是同機(jī)器的其他 job。在 Shopee 內(nèi)部,Spark 與 Flink Batch 跑在相同的離線集群,所以也會(huì)受到其他類型離線任務(wù)的影響。同樣,yarn 的穩(wěn)定性也會(huì)影響 Flink batch 任務(wù)。
- 按照現(xiàn)在的 failover 邏輯,TaskManager 無論是由于內(nèi)部原因還是外部原因?qū)е卤罎ⅲ琓ask 都會(huì)重跑,Shuffle 數(shù)據(jù)也都會(huì)丟失。盡管可能只是部分 Task 重跑,但因?yàn)槲覀兡壳笆褂玫?1.15 沒有推測(cè)執(zhí)行,所以也會(huì)導(dǎo)致 Job 整體執(zhí)行時(shí)間嚴(yán)重拉長(zhǎng)。
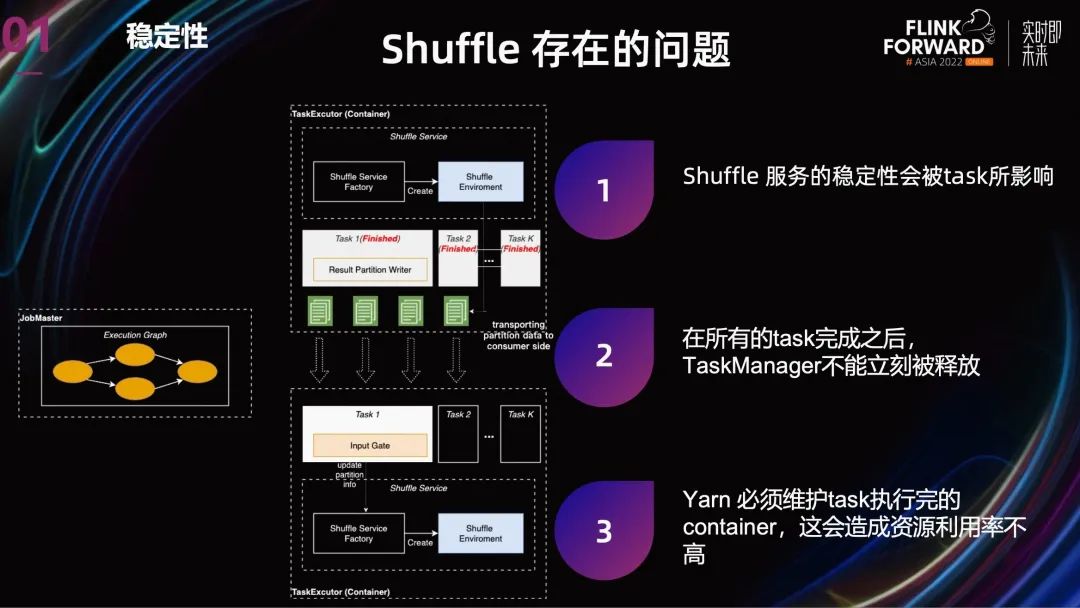
第二個(gè)是:當(dāng) Task 完成之后,由于 TaskManager 不能立刻被釋放,還要提供 Shuffle 服務(wù),這就導(dǎo)致 Yarn 必須維護(hù) Task 執(zhí)行完的 container,造成集群資源利用率不高。
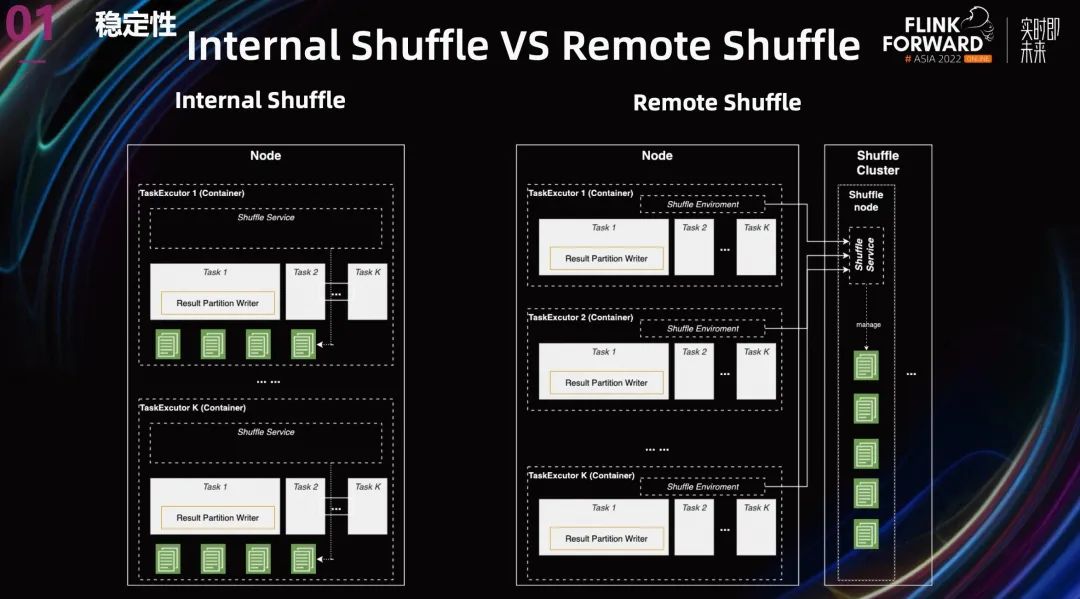
針對(duì) Internal Shuffle 的問題,其實(shí)業(yè)界也已經(jīng)有了成熟的方案,那就是 Remote Shuffle。
上圖中展示了兩張架構(gòu)圖,一個(gè)是 Internal Shuffle,另一個(gè)是 Remote Shuffle,其實(shí)還有一個(gè) external Shuffle,External Shuffle 就是把 Shuffle 服務(wù)拆分到另一個(gè)進(jìn)程中。Spark 使用的 yarn auxilary external Shuffle,就是把 Shuffle 服務(wù)挪到了 Node Manager 里面,但是這還是存儲(chǔ)跟計(jì)算混合在一起的架構(gòu)。
所以我們選擇一步到位,使用 Remote Shuffle。就是轉(zhuǎn)門搭建一套 Shuffle 集群來提供 Shuffle 服務(wù)。
這種存儲(chǔ)與計(jì)算分離的架構(gòu)有以下幾個(gè)好處:
-
計(jì)算和存儲(chǔ)再也不會(huì)相互影響。Shuffle 服務(wù)與用戶的代碼完全隔離。
-
將 Shuffle 的工作轉(zhuǎn)移到 Remote Shuffle 集群后,Task 執(zhí)行完畢時(shí),Task Manager 的資源可以立刻被釋放。
- 在這種架構(gòu)下,計(jì)算跟資源解耦 了,我們可以自由的擴(kuò)展或者收縮各自的資源量。
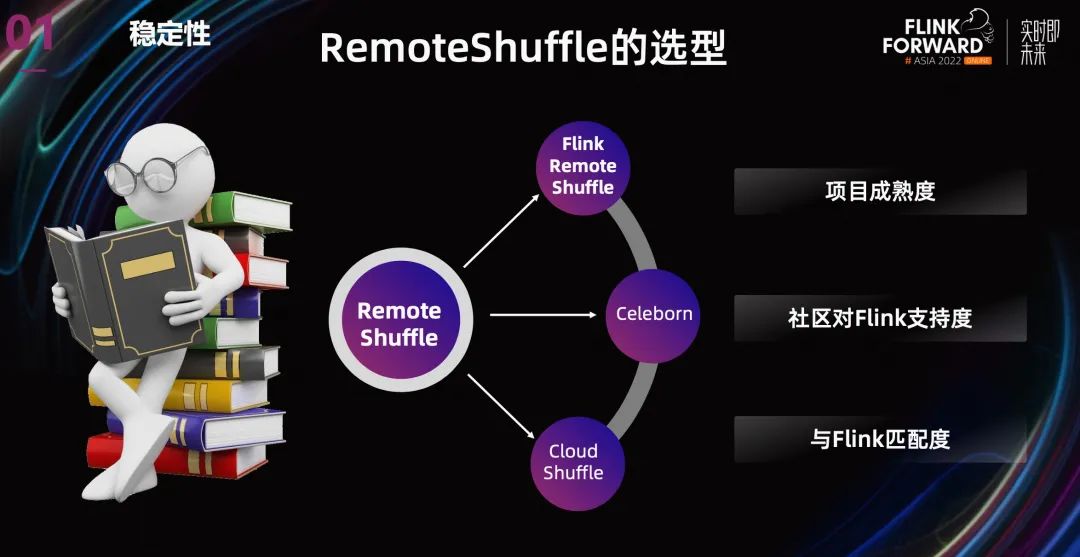
業(yè)界有不少 Remote Shuffle 的方案,比如阿里云的 Celeborn,字節(jié)的 Cloud ShuffleService,另外還有 Uber Remote Shuffle Service,Splash 等等。但是這些 Remote Shuffle 大部分主要是為了支持 Spark,支持 Flink 的并不多,另外有一些只在內(nèi)部版本中支持 Flink。
最后在選型的標(biāo)準(zhǔn)里面,我們主要考慮了項(xiàng)目本身的成熟度,社區(qū)對(duì) Flink 的支持度,與 Flink 的匹配程度,最終還是采用了 Flink Remote Shuffle。
這個(gè)方案有幾個(gè)好處:
-
Flink Remote Shuffle 是 Flink 的一個(gè)擴(kuò)展項(xiàng)目,原生就是為了支持 Flink,社區(qū)的支持力度大,之后有了問題可以跟社區(qū)多交流。
- 目前 Flink 的 Batch 正在快速發(fā)展,每個(gè)版本都有很大的變動(dòng)和提高,比如 1.16 的 hybrid Shuffle 和推測(cè)執(zhí)行,其他的 Remote Shuffle 不可能這么快速跟進(jìn)。
雖然 Flink Remote Shuffle 也有缺點(diǎn),但暫時(shí)可以忍受。另外 Remote Shuffle 其實(shí)是跟計(jì)算引擎分離的,等之后 Flink Batch 的特性穩(wěn)定了,我們最終希望是離線能共用一套 Remote Shuffle service。

在集群部署方案上,我們采取了跟 Presto 混部的方案。主要的考慮是為了充分的利用資源,Presto 和 Remote Shuffle 在資源使用上剛好互補(bǔ)。Remote Shuffle 本身是一個(gè)存儲(chǔ)服務(wù),它不怎么使用 CPU 和 memory,但會(huì)占用大量的磁盤。相反,Presto 會(huì)占用大量的 CPU 和 memory,磁盤使用量相對(duì)較少。
另外,從時(shí)間上看,Batch 任務(wù)更多的集中在晚上,交互式查詢更多集中在白天,這也有利于資源復(fù)用。再就是為了避免相互影響,我們使用 Ggroup 來為兩個(gè)服務(wù)提供資源限制和隔離。
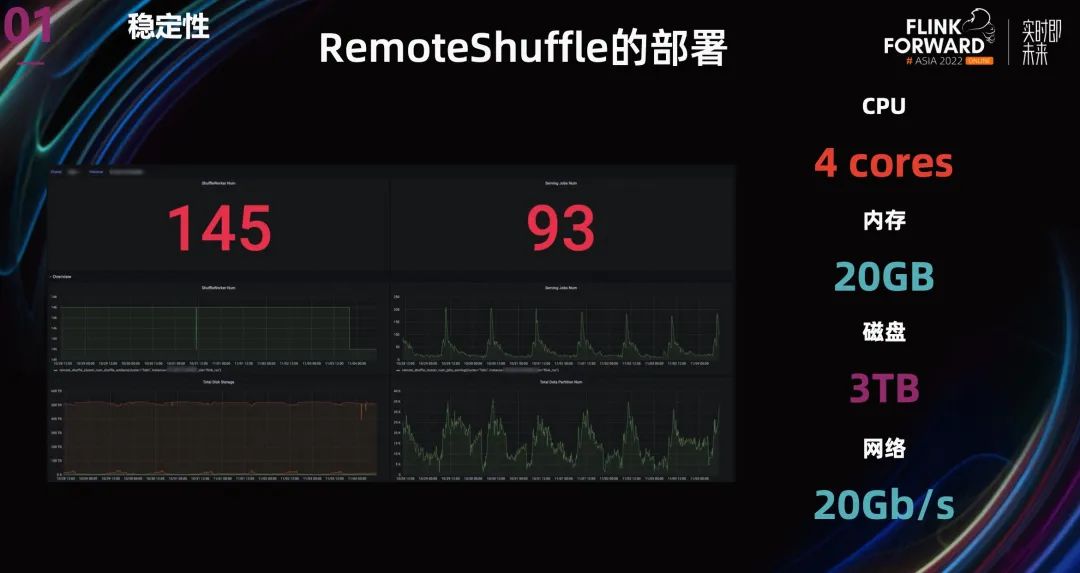
最后,我們搭建了一個(gè)有 145 個(gè)節(jié)點(diǎn)的 Shuffle 集群,為線上的 Batch 任務(wù)提供 Shuffle 服務(wù)。其中每個(gè)節(jié)點(diǎn)使用一個(gè) 3TB 的 SSD 來保存數(shù)據(jù),有效保證 Shuffle 數(shù)據(jù)的存取性能。
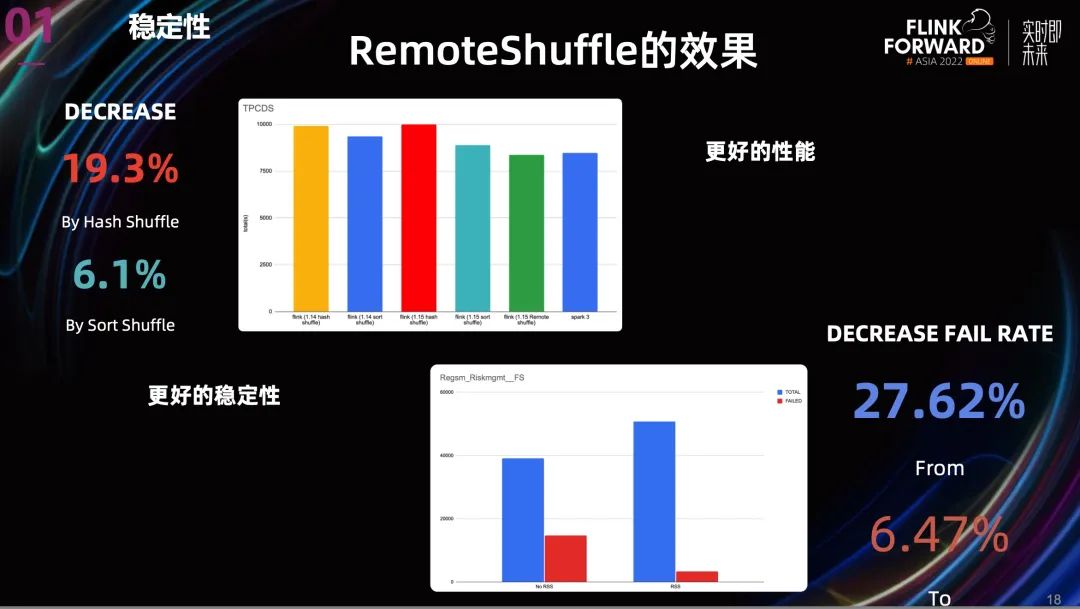
在集群搭建好之后,我們也在 Remote Shuffle Service 上做了一些測(cè)試和生產(chǎn)驗(yàn)證。從上圖就可以看到效果。
從性能上看,相比 Hash Shuffle , Remote Shuffle 的性能提升了 19.3%, 相比 Sort Shuffle, 性能提升了 6.1%。
從穩(wěn)定性上看,我們?nèi)×艘粋€(gè)之前非常不穩(wěn)定的 project。結(jié)果是 Task 失敗率降低了超過 70%。
所以無論從性能還是穩(wěn)定性,Remote Shuffle 都能帶來很好的收益。
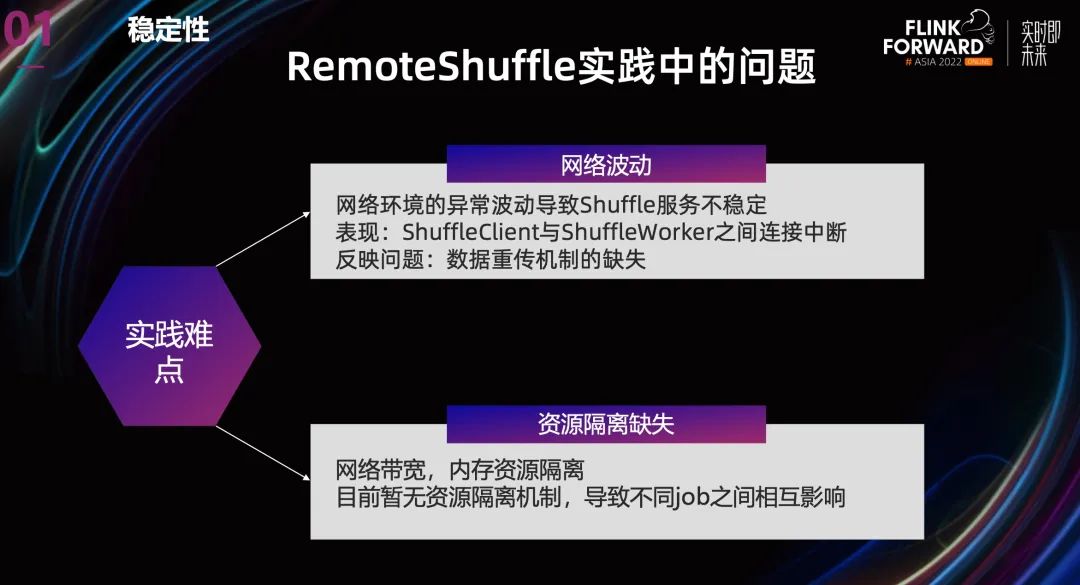
當(dāng)然,Remote Shuffle 這個(gè)項(xiàng)目也還有一些問題。
-
網(wǎng)絡(luò)環(huán)境的異常波動(dòng)會(huì)導(dǎo)致 Shuffle 服務(wù)不穩(wěn)定,表現(xiàn)出來主要是 ShuffleClient 與 ShuffleWorker 之間連接中斷。這反映了一個(gè)問題,就是數(shù)據(jù)重傳機(jī)制的缺失。
- 另外就是沒有多租戶資源隔離機(jī)制,無論是帶寬還是磁盤資源,目前都沒有隔離機(jī)制,這會(huì)導(dǎo)致不同 Job 之間相互影響。
當(dāng)然,這些問題也都在不斷改進(jìn)中,總的來看,F(xiàn)link Remote Shuffle 對(duì) Flink Batch 有很大的幫助。
2.2 易用性

除了上面針對(duì) Shuffle 的優(yōu)化之外,Shopee 也在易用性方面做了很多工作。大家都知道,對(duì)于流批一體,F(xiàn)link SQL 為核心載體。在使用過程中,SQL 也存在一系列使用上的困難。
第一個(gè)問題是 SQL 任務(wù)有問題后,對(duì)于用戶而言定位困難。之前我們的流任務(wù)主要依賴 web UI,沒有 History Server。有了 History Server 之后,定位 Task 的問題得到了緩解。但是還有一個(gè)比較麻煩的事情,就是 SQL 任務(wù)經(jīng)過 Planner 優(yōu)化之后,執(zhí)行計(jì)劃與 SQL 結(jié)構(gòu)上有了較大差異,用戶使用過程中,經(jīng)常很難根據(jù) Task 信息定位到相關(guān)的 SQL 語句。
第二個(gè)問題是 SQL 配置困難。SQL 任務(wù)各 Task 之間資源使用經(jīng)常不均衡,有的是 CPU 密集型,有的是內(nèi)存密集型,很難通過統(tǒng)一的 TM 配置來解決。社區(qū) SQL API 也并沒有提供細(xì)粒度資源配置的接口。導(dǎo)致一些高級(jí)用戶希望優(yōu)化資源使用量時(shí),SQL 任務(wù)的資源配置十分困難。
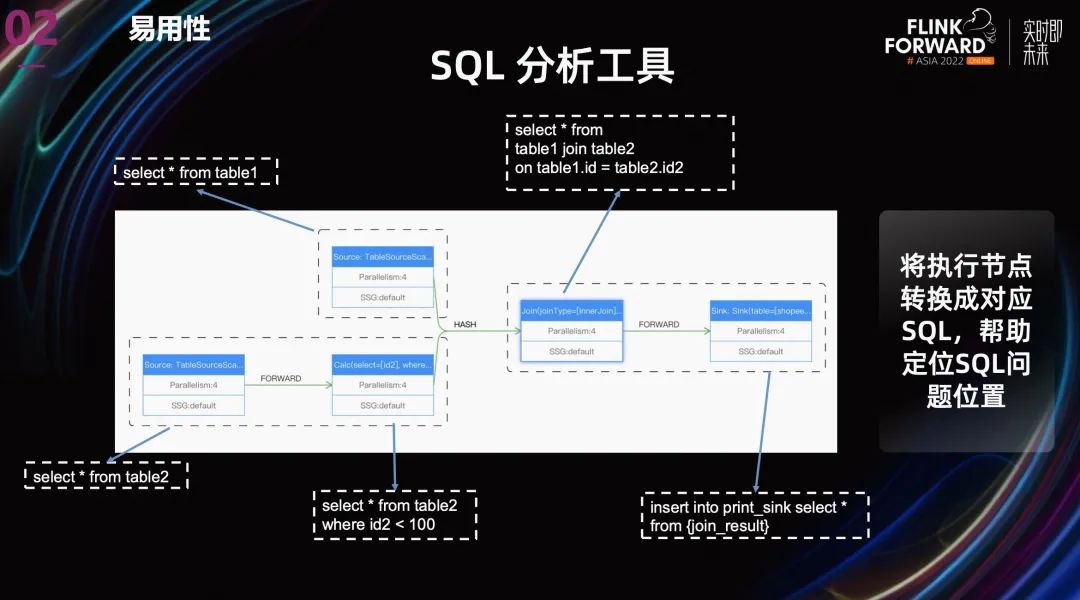
針對(duì) SQL 問題分析定位的難點(diǎn),我們做了兩點(diǎn)優(yōu)化:
-
在用戶提交 SQL 任務(wù)之前,展示作業(yè)的 streamgraph,讓用戶執(zhí)行之前就能看到 SQL 的執(zhí)行邏輯,以判斷是否符合自己的預(yù)期。
- 第二個(gè)優(yōu)化就像上圖中展示的一樣,將執(zhí)行節(jié)點(diǎn)轉(zhuǎn)換成對(duì)應(yīng) SQL,讓用戶知道每個(gè) Task 的對(duì)應(yīng)的 SQL 段,幫助定位問題位置。

另外,一些算子為了在不同的數(shù)據(jù)下有更好的性能,同一個(gè)算子會(huì)有多種實(shí)現(xiàn)方案,比如 join。一些用戶在排查問題時(shí),會(huì)關(guān)心優(yōu)化器對(duì) SQL operator 的具體實(shí)現(xiàn)邏輯。所以,除了展示每個(gè) Task 的對(duì)應(yīng)的 SQL 之外,我們還提供展示 SQL 算子對(duì)應(yīng)生成的 Java code,以確定算子底層實(shí)現(xiàn)邏輯,輔助排查 SQL 故障。
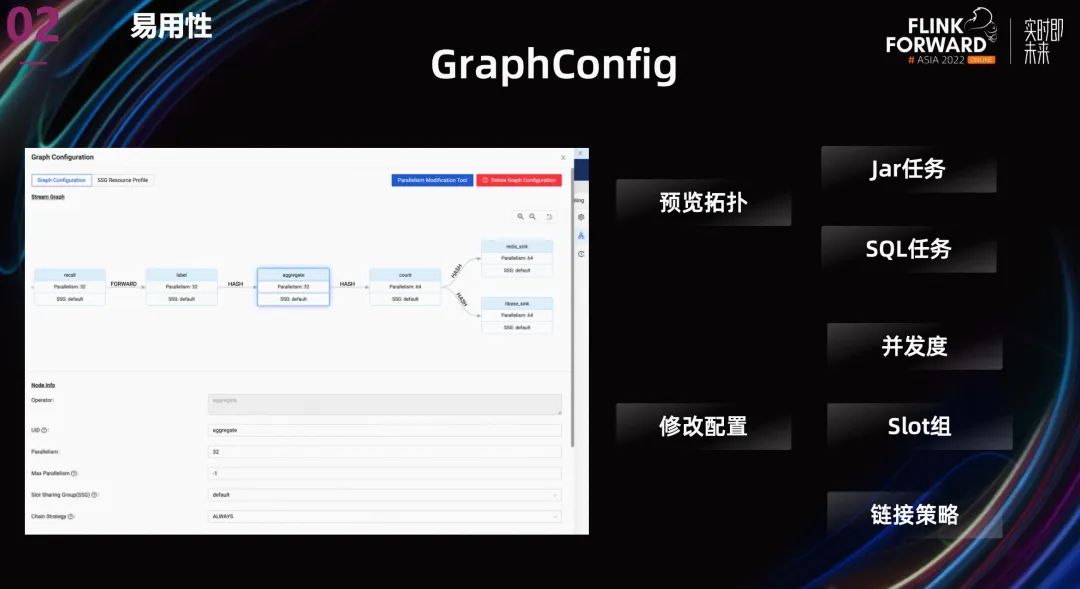
針對(duì)第二個(gè) SQL 任務(wù)資源優(yōu)化的問題,我們?cè)谡故?streamgraph 的基礎(chǔ)上,允許為不同的 operator 配置不同的并發(fā)度,鏈接策略還有 slot group 等等。
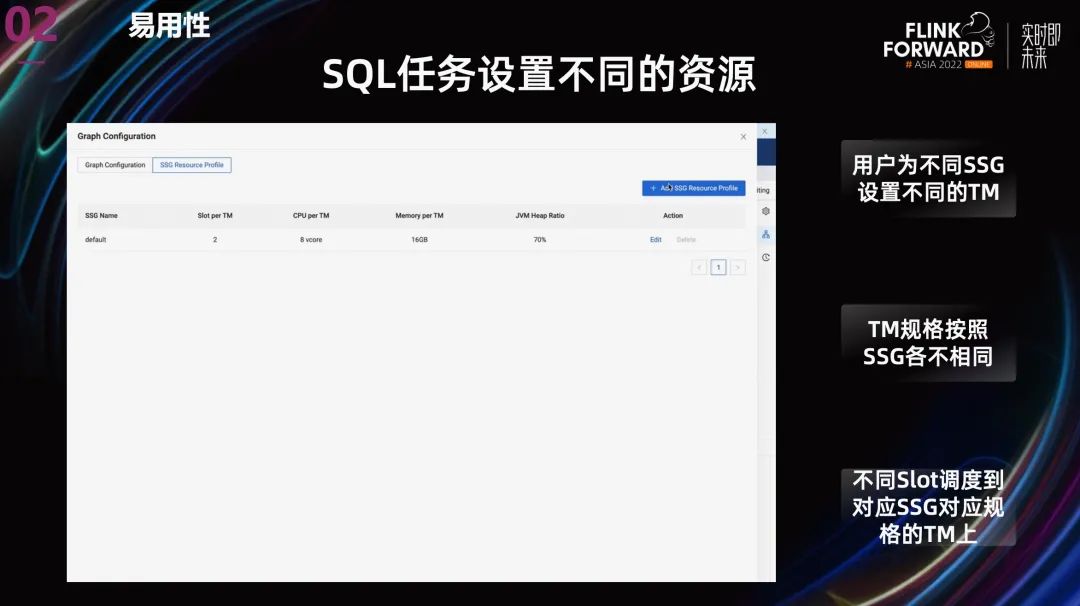
在資源配置上,我們并沒有使用社區(qū)提供的 operator 級(jí)別的細(xì)粒度資源配置。主要有兩個(gè)原因:
- Slot 資源使用量用戶很難監(jiān)控,目前最多監(jiān)控到 TM 粒度。這導(dǎo)致用戶沒有監(jiān)控依據(jù),無法準(zhǔn)確預(yù)估每個(gè) slot 的資源使用量。
- 動(dòng)態(tài)資源切割機(jī)制導(dǎo)致機(jī)器上出現(xiàn)大量碎片。
我們最后使用了自己開發(fā)的 SlotGroup 級(jí)別的資源配置,整體思路是不同的 SlotGroup 申請(qǐng)不同規(guī)格的 TM,Slot 依然是均分 TaskManager 的資源,但可以通過為不同的 Operator 設(shè)置不同的 SlotGroup,進(jìn)而設(shè)置不同的資源量。
這種方案讓用戶可以很方便的依據(jù) TaskManager 使用監(jiān)控,定位到配置不合理的 SlotGroup 和 Operator, 進(jìn)而調(diào)整 TM 資源配置,優(yōu)化作業(yè)的整體資源利用率。 上圖中的功能依賴于我們內(nèi)部開發(fā)的“SlotGroup 粒度的資源調(diào)度”。

當(dāng)然除了以上對(duì) Batch 的優(yōu)化之外,我們還進(jìn)行很多其他的優(yōu)化。比如復(fù)用 stream 模式下 compact 小文件的邏輯;調(diào)整容錯(cuò)機(jī)制, 支持 Batch SQL 的小文件 compact 還有就是 parquet 的 nested projection/filter pushdown;優(yōu)化超過 64 位 GroupId 生成策略;優(yōu)化 FileSourceCoodinator 創(chuàng)建邏輯等等。
這些優(yōu)化都有效解決了生產(chǎn)過程中 Shopee 各個(gè)業(yè)務(wù)線遇的問題。
03
與離線生態(tài)的完全集成
在流批一體落地的過程中,用戶最關(guān)心的就是技術(shù)架構(gòu)的改動(dòng)成本和潛在風(fēng)險(xiǎn)。作為 Flink 平臺(tái),面臨的一個(gè)很重要的挑戰(zhàn)就是如何兼容好用戶已經(jīng)廣泛應(yīng)用的離線批處理能力。所以第三部分主要介紹與離線生態(tài)的集成,主要涉及開發(fā)和執(zhí)行兩個(gè)層面的問題。
3.1 開發(fā)層面

開發(fā)層面主要是復(fù)用的問題,復(fù)用的目的是為了降低用戶的使用成本。由于很多用戶已經(jīng)在其他引擎上積累的大量的業(yè)務(wù) UDF,所以我們提供的統(tǒng)一 UDF 來解決 UDF 復(fù)用的問題。
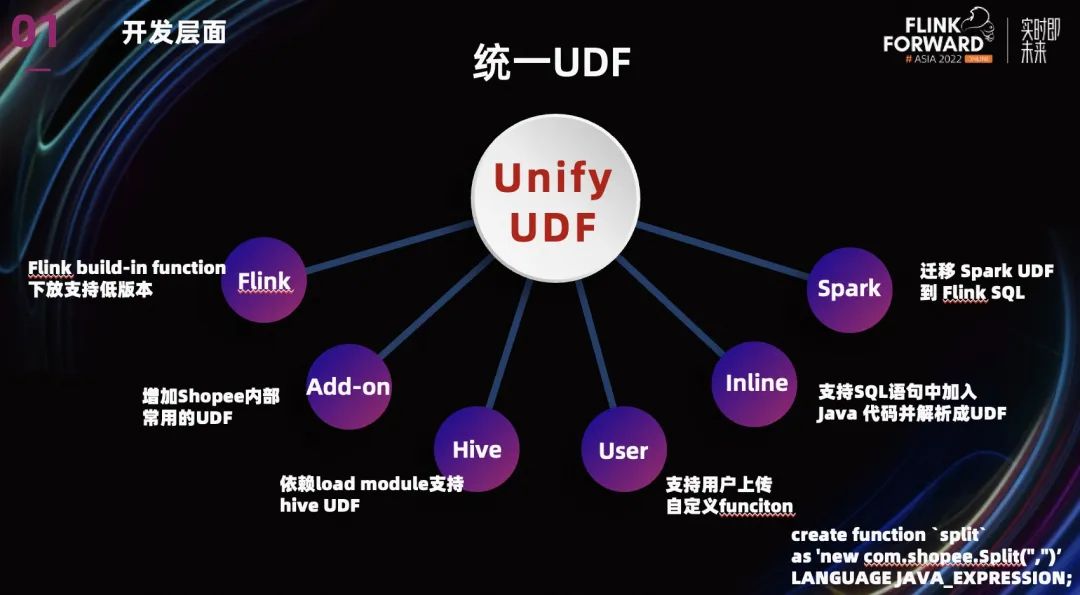
統(tǒng)一 UDF 的目標(biāo)是為了用戶能在 Flink 平臺(tái)上無縫訪問各種 UDF。目前我們已經(jīng)支持了很多類型的 UDF。
-
Flink 本身的 UDF,我們將很多 Flink build-in function 下放支持低版本。
-
增加了一些 Shopee 內(nèi)部常用的 UDF,用戶也可以上傳共享自定義的 UDF。
-
針對(duì)其他引擎的 UDF,我們依賴 load module 支持了的 Hive UDF。對(duì)于 Spark build in 的 UDF,為了降低用戶使用成本,我們也把大量常用的 Spark UDF 遷移到了 Flink。
- 值得一提的是,我們團(tuán)隊(duì)目前已經(jīng)支持了 SQL 語句中加入 Java 代碼并解析成 UDF。上圖中有個(gè)例子,之后我們還會(huì)支持 lambda 表達(dá)式等等,這將大大方便用戶對(duì) UDF 的使用。
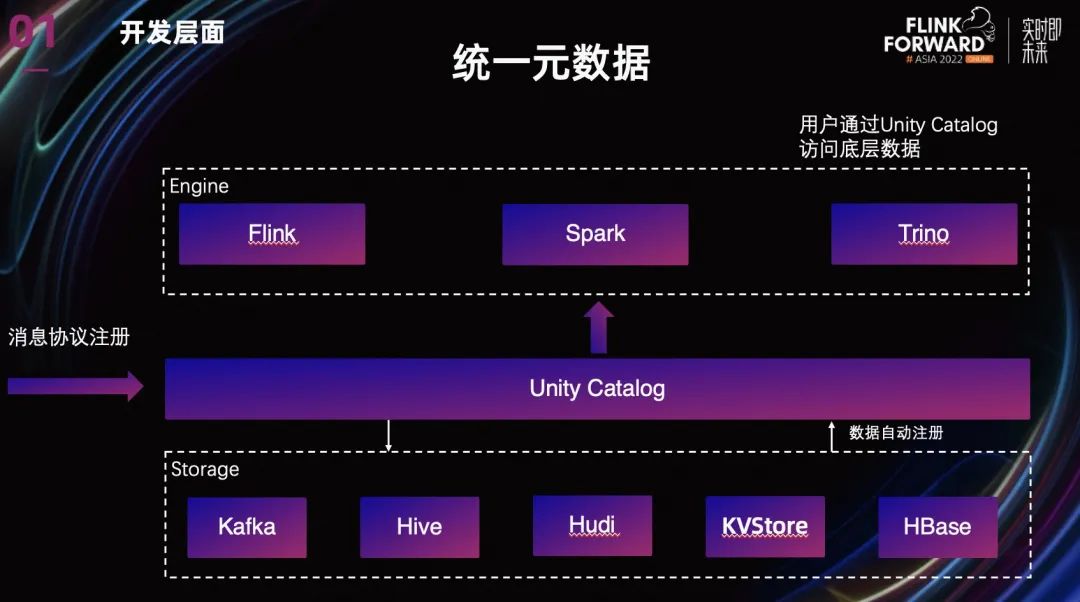
除了復(fù)用 UDF 以外,我們還通過統(tǒng)一元數(shù)據(jù)來復(fù)用已經(jīng)存在的離線數(shù)據(jù)模型。與其他各自已有的元數(shù)據(jù)管理一起,加上依賴 HDP scheme registry 構(gòu)建的實(shí)時(shí)元數(shù)據(jù),一起構(gòu)建形成 Unity Catalog。
用戶可以只通過 Unity Catalog 來訪問底層不同的數(shù)據(jù),在平臺(tái)提供的 SQL IDE 中,可以十分方便的訪問已有的 Catalog 和數(shù)據(jù)表。目前已經(jīng)支持了 Kafka,Hive,Hudi, Redis, Hbase 這幾個(gè)不同的數(shù)據(jù)類型。
3.2 執(zhí)行層面
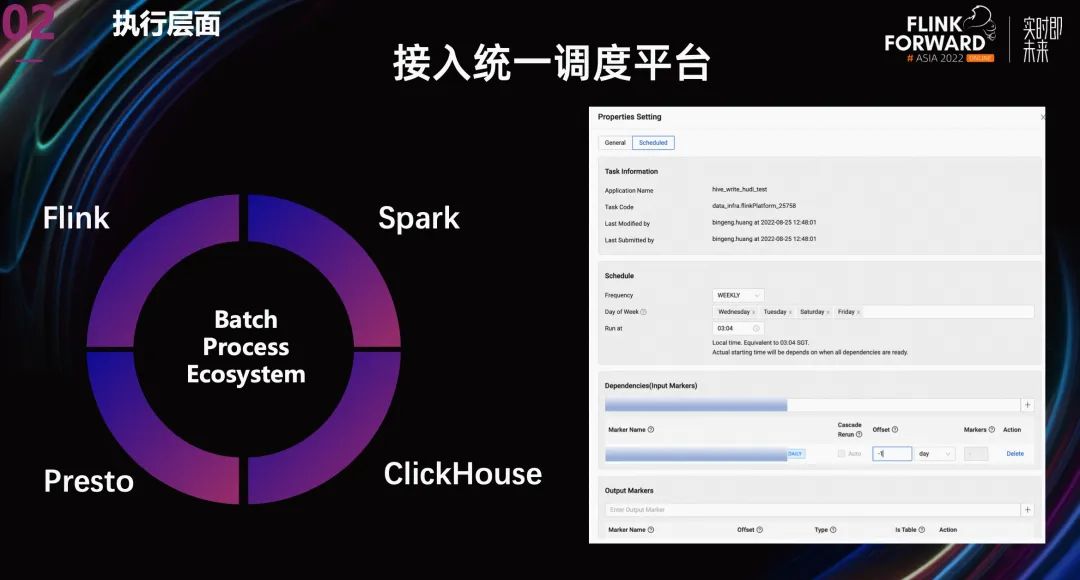
在執(zhí)行層面,隨著 Flink 能力的增強(qiáng),用戶希望 Flink SQL 批任務(wù)嵌入到當(dāng)前的數(shù)據(jù)加工過程中,作為中間的一個(gè)環(huán)節(jié)。所以我們將 Flink Batch 接入了 Shopee 內(nèi)部的統(tǒng)一調(diào)度平臺(tái) Data Scheduler。并且通過統(tǒng)一的數(shù)據(jù) marker 服務(wù)來進(jìn)行數(shù)據(jù)依賴。最終將 FlinkBatch 與已有的其他數(shù)據(jù)處理引擎打通,更好的服務(wù)用戶。
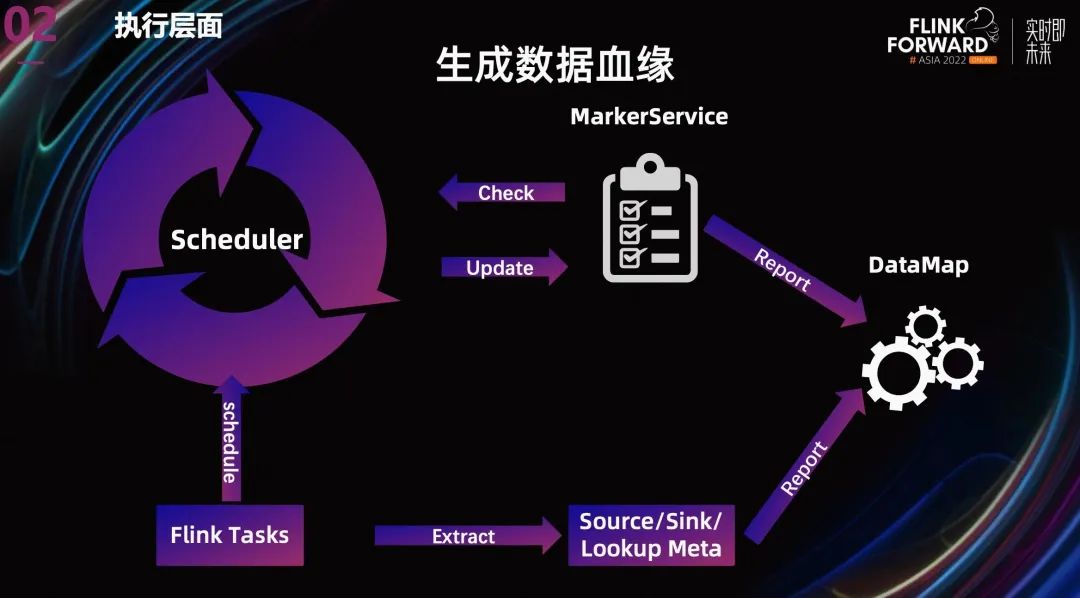
另外,在離線領(lǐng)域,清晰的血緣是對(duì)數(shù)據(jù)進(jìn)行追溯和影響分析的基礎(chǔ)。當(dāng)數(shù)據(jù)有了清晰的血緣和歸屬,系統(tǒng)中的數(shù)據(jù)就有了清晰的結(jié)構(gòu)。
我們團(tuán)隊(duì)目前除了通過上一張 PPT 提到的數(shù)據(jù) marker 來提供數(shù)據(jù)依賴關(guān)系之外, 還從 gragh 中抽取 Source,Sink,Lookup 的元數(shù)據(jù)信息,報(bào)告給 Datamap,以生成更完整的數(shù)據(jù)血緣。
當(dāng)然除了離線數(shù)據(jù)的元數(shù)據(jù)之外, 我們也正在設(shè)計(jì)將實(shí)時(shí)數(shù)據(jù)的元數(shù)據(jù)整合到現(xiàn)有的數(shù)據(jù)血緣中,徹底將所有數(shù)據(jù)的歸屬打通。
04
平臺(tái)在流批一體上的建設(shè)和演進(jìn)
最后我想介紹一下我們 Flink 平臺(tái)在流批一體上的建設(shè)和演進(jìn)。其實(shí)在上面介紹中,已經(jīng)展示了不少平臺(tái)的功能。所以這一部分,我只會(huì)重點(diǎn)介紹一下平臺(tái)對(duì)運(yùn)維工具 History Server 的優(yōu)化。
其實(shí) Flink 流任務(wù)對(duì) History Server 的需求并不大,因?yàn)榱魅蝿?wù)理論上一直在運(yùn)行,我們可以用 web UI。但是對(duì)于批任務(wù),History Server 卻是一個(gè)非常有效的運(yùn)維追溯工具。
4.1 HistoryServer 接入 Yarn 日志
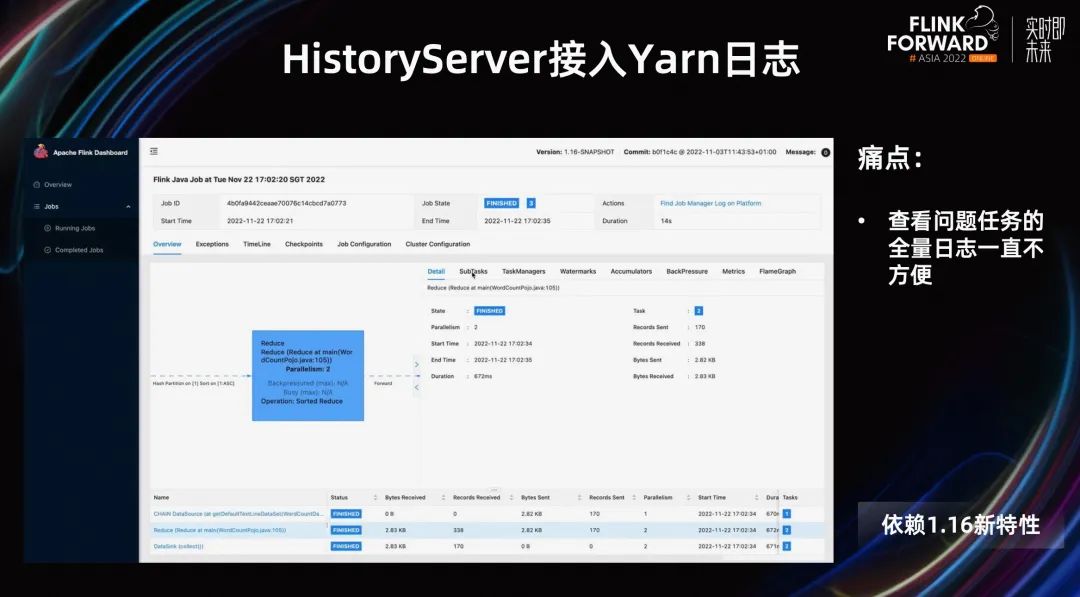
首先我要宣傳一下 1.16 的新特性:跳轉(zhuǎn)外部 log。
雖然我們平臺(tái)已經(jīng)將用戶的日志接入的 kibana,但是因?yàn)槿罩臼腔旌系模圆樵兊臅r(shí)候用戶要先定位到 subTask,然后需要輸入各種篩選條件查詢,查詢流程比較長(zhǎng),速度也比較慢。所以我們一直想優(yōu)化這個(gè)流程,在最近發(fā)布的 1.16 中,支持了接入外部 log 的功能,我們針對(duì)日志較少的 Batch 任務(wù),直接使用該特性跳轉(zhuǎn)到 yarn 的 history log,十分方便查看問題 Task 的全量日志。
4.2 HistoryServer 小文件問題

另外,History Server 還有一個(gè)小文件的問題。從上圖左側(cè)可以看到,History Server 將歷史任務(wù)存儲(chǔ)為大量 Json 小文件用于服務(wù) Web UI。當(dāng)只支持流任務(wù)的時(shí)候這個(gè)問題并不明顯,但是隨著我們平臺(tái)支持批任務(wù)后,歷史任務(wù)的數(shù)量劇增。
數(shù)量的上漲帶來的幾個(gè)問題:
-
大拓?fù)洌蟛l(fā)的任務(wù)的解壓對(duì) History Server 服務(wù)產(chǎn)生壓力。
-
歷史任務(wù)產(chǎn)生的大量文件對(duì)部署節(jié)點(diǎn)的文件系統(tǒng)產(chǎn)生大量存儲(chǔ)開銷。大量小文件導(dǎo)致單個(gè) History Server 只能保存很短時(shí)間的歷史任務(wù)。不然就會(huì)將單機(jī)的 inode 耗光。
- History Server 目前重啟后需要重新拉取歷史 Job 信息并解壓。
這些都給生產(chǎn)帶來了問題。
4.3 HistoryServer 優(yōu)化方案
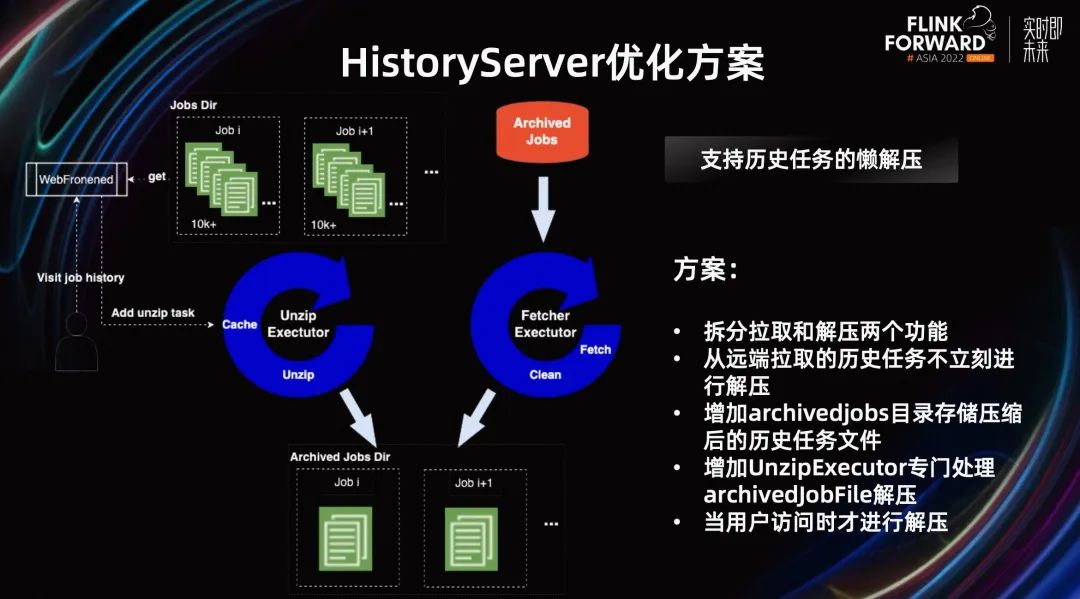
所以我們對(duì) History Server 整體架構(gòu)做了優(yōu)化,整體的思路是,只對(duì)需要的歷史 Job 進(jìn)行解壓。
第一,是拆分拉取和解壓兩個(gè)功能,將原有的 Fetcher Executor 拆分成了 Fetcher Executor 和 Unzip Executor。Unzip Executor 專門處理 archivedJobFile 解壓。
第二,增加 archivedJobs 目錄存儲(chǔ)壓縮后的歷史任務(wù)文件,從遠(yuǎn)端拉取的歷史任務(wù)不立刻進(jìn)行解壓。而是當(dāng)用戶訪問時(shí)增加一個(gè)解壓任務(wù)進(jìn)行解壓。
這樣就減少了 History Server 的工作量,降低了 History Server 的負(fù)載,也降低了部署節(jié)點(diǎn)的存儲(chǔ)開銷。這個(gè)方案在我們線上使用后,將存儲(chǔ)開銷降低了 90%以上,效果十分明顯。
4.4 Flink 平臺(tái)的演進(jìn)

我們內(nèi)部支持 Flink 的批是從去年三季度開始的,到現(xiàn)在為止一年多。從改造平臺(tái)支持 Batch,到并入離線生態(tài),打通依賴和血緣,再到搭建 Remote Shuffle。有效的支撐起了 Shopee 各個(gè)業(yè)務(wù)線對(duì) Flink 流批一體的需求。
整個(gè)落地過程中,最主要經(jīng)驗(yàn)的是要站在用戶的視角看待問題,合理地評(píng)估用戶的改動(dòng)成本以及收益,幫助用戶找出業(yè)務(wù)遷移的潛在風(fēng)險(xiǎn),降低用戶使用的門檻。
未來規(guī)劃主要還是在業(yè)務(wù)拓展方面。我們會(huì)加大 Flink 批任務(wù)的推廣,探索更多流批一體的業(yè)務(wù)場(chǎng)景。同時(shí)跟社區(qū)一起,在合適的場(chǎng)景下,加速用戶向 SQL 和流批一體的轉(zhuǎn)型。
往期精選





▼ 活動(dòng)推薦▼

? ??
點(diǎn)擊「閱
讀原文
」,免費(fèi)領(lǐng)取 5000CU*小時(shí) Flink 云資源
??
點(diǎn)擊「閱
讀原文
」,免費(fèi)領(lǐng)取 5000CU*小時(shí) Flink 云資源