萬字詳解數(shù)據(jù)中心的百萬級消息服務(wù)實戰(zhàn)

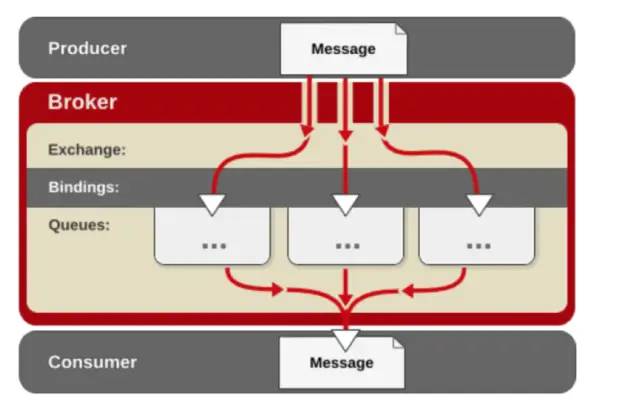
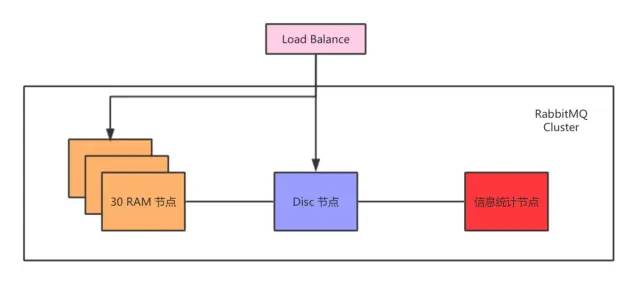
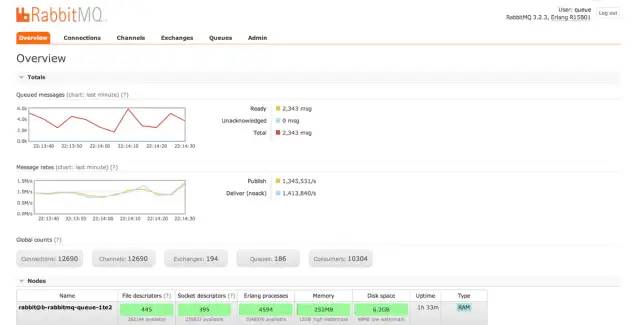
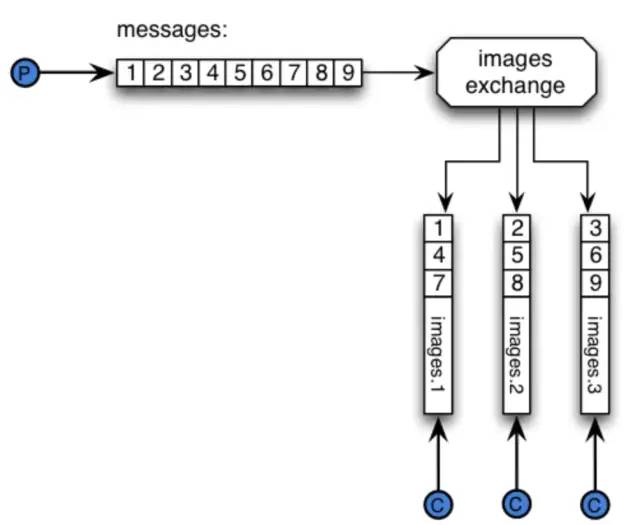
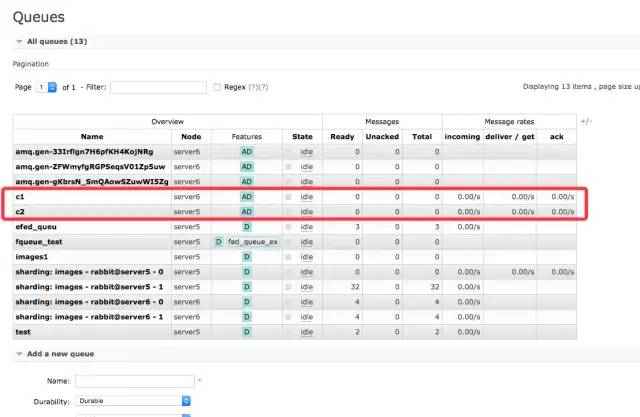
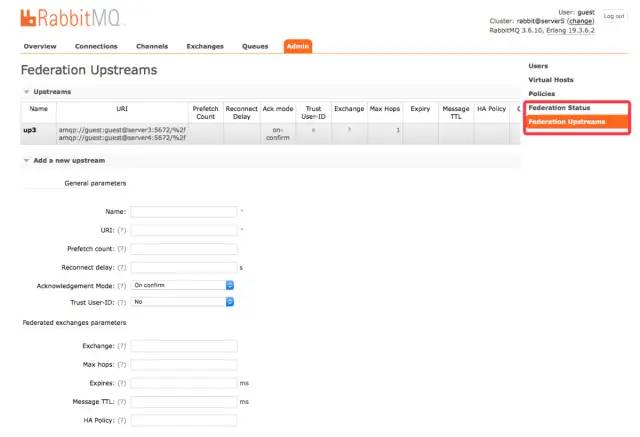
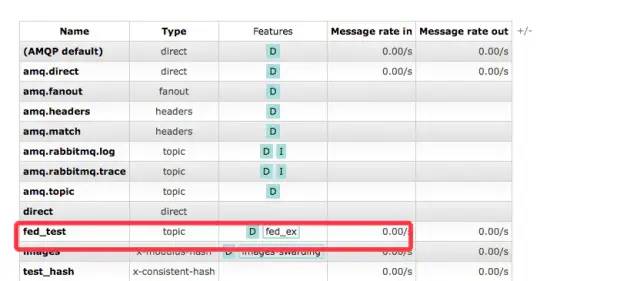
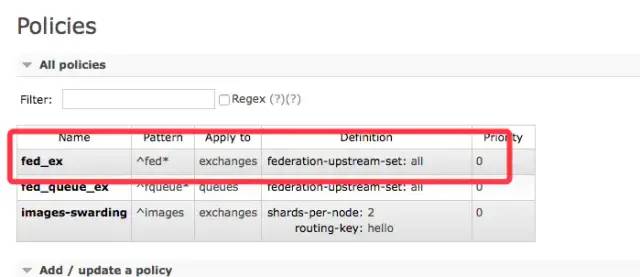
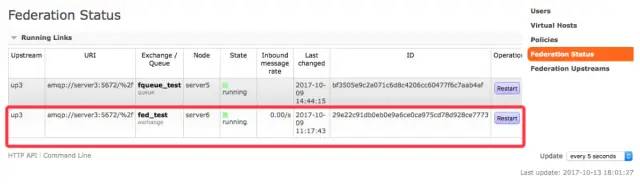
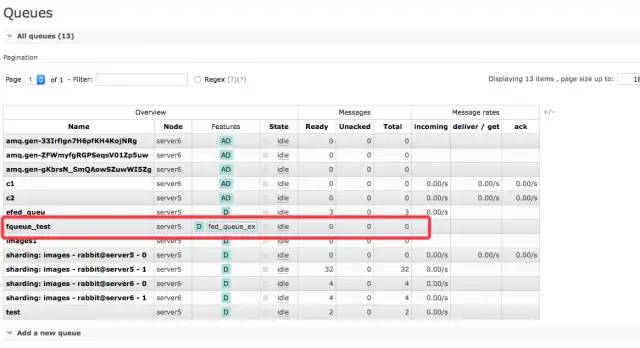
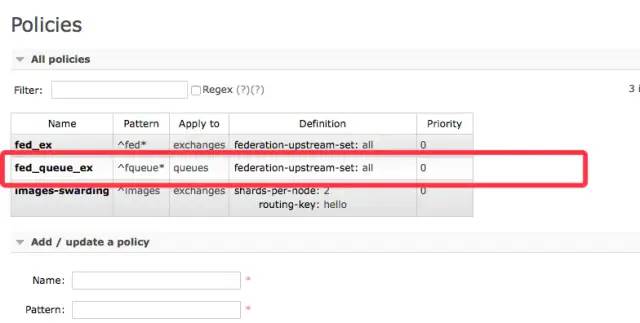
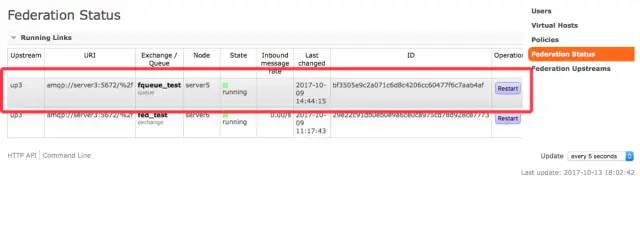
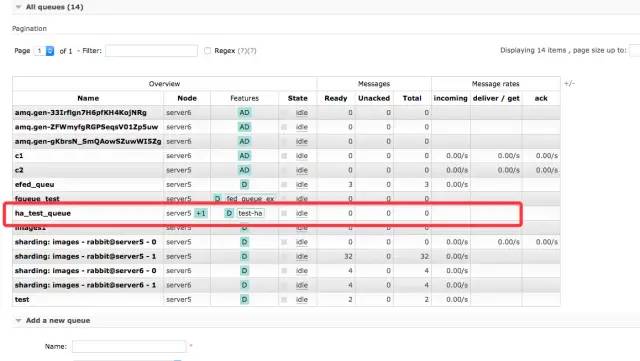
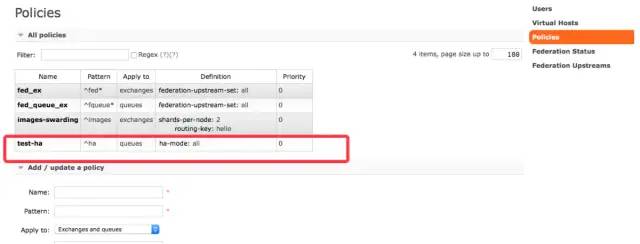
rabbitmq-pluginsenable?rabbitmq_sharding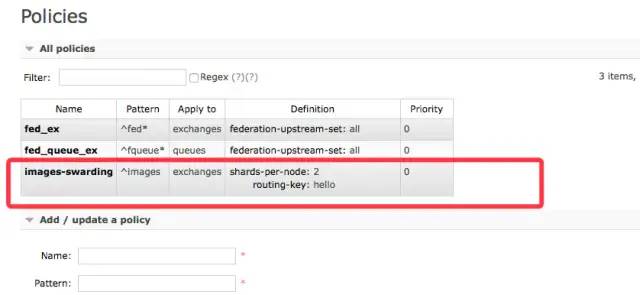
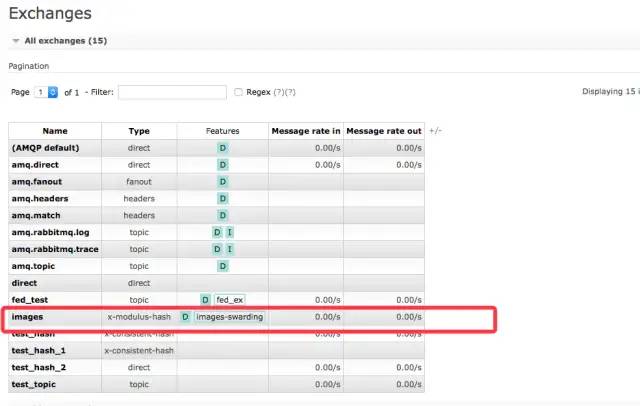
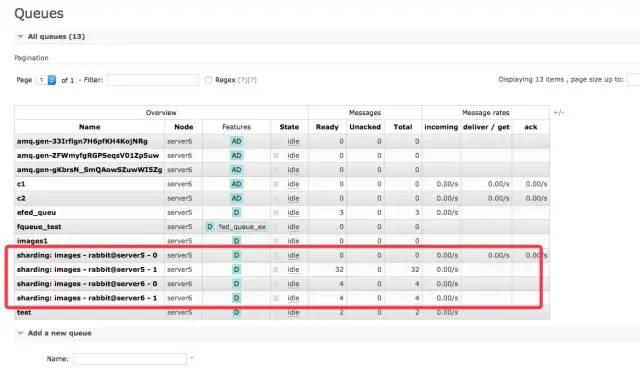
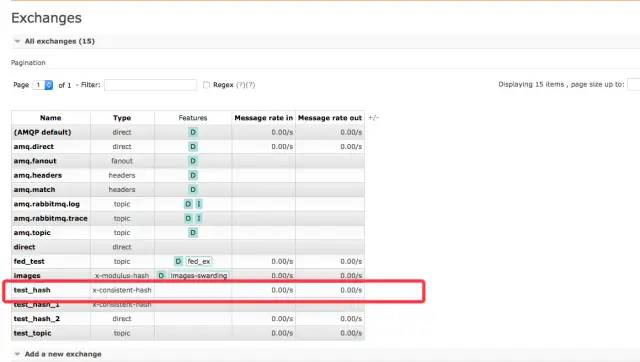







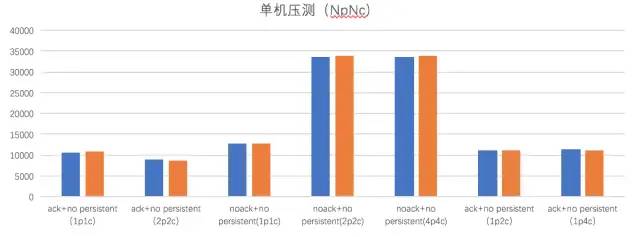
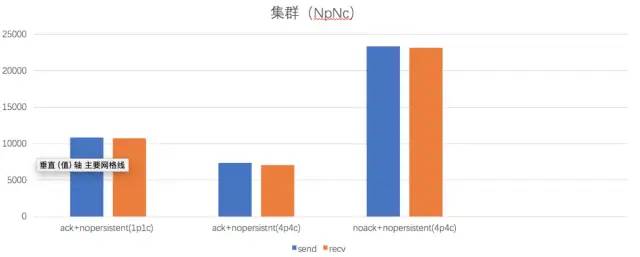
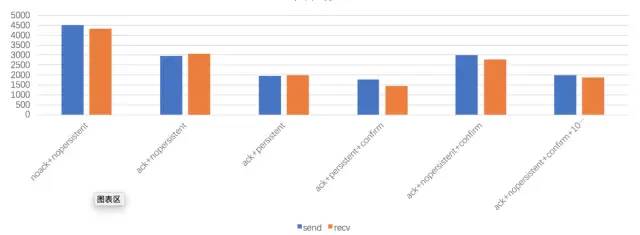
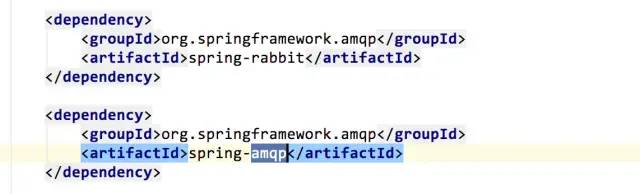
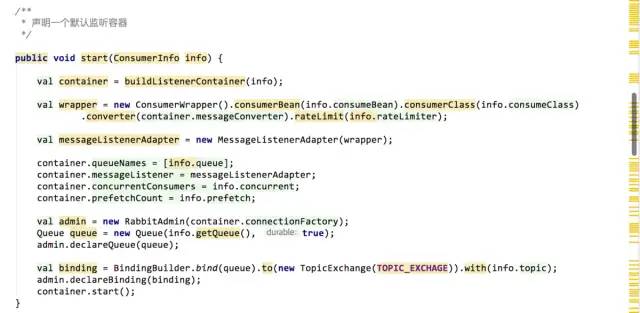
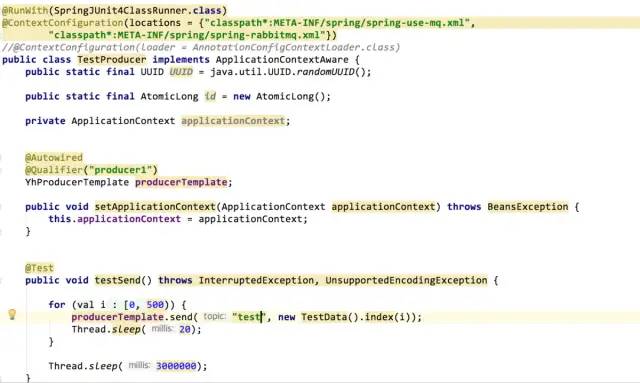
作者:有貨技術(shù)
來源:www.jianshu.com/p/ddca1548d0a1

評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APP
rabbitmq-pluginsenable?rabbitmq_sharding作者:有貨技術(shù)
來源:www.jianshu.com/p/ddca1548d0a1
<b id="afajh"><abbr id="afajh"></abbr></b>