
深入理解G1垃圾收集器
1. 垃圾收集器簡(jiǎn)析
Java語(yǔ)言一直使用GC技術(shù)進(jìn)行JVM自動(dòng)內(nèi)存管理,避免手動(dòng)管理帶來(lái)的一系列問(wèn)題,以提升開(kāi)發(fā)人員效率。衡量垃圾回收的三個(gè)最重要指標(biāo):
內(nèi)存占用(Footprint); 吞吐量(Throughput); 延遲(Latency);
目前的垃圾收集器能是盡量在這三個(gè)指標(biāo)中尋找平衡,以達(dá)到最大的回收效率,能同時(shí)達(dá)到這三個(gè)指標(biāo)完美的垃圾收集器是比較困難的,但是隨著20多年來(lái)垃圾收集器的技術(shù)進(jìn)步,一款優(yōu)秀的收集器也越來(lái)越滿足大家的需求。目前,比較經(jīng)典的垃圾收集器有如下幾種:
Serial收集器,歷史最悠久,GC是單線程,會(huì)有“Stop The World”,內(nèi)存消耗最小,作用于新生代,基于標(biāo)記-復(fù)制算法實(shí)現(xiàn); Serial Old收集器,是Serial的老年代版本,基于標(biāo)記-整理算法實(shí)現(xiàn),在JDK5及之前,和Parallel Scavenge搭配使用,以及作為CMS失敗時(shí)的備選方案; ParNew收集器,是Serial收集器的多線程并行版本,作用于新生代,基于標(biāo)記-復(fù)制算法實(shí)現(xiàn),也會(huì)暫停所有用戶(hù)線程; Parallel Scavenge收集器,作用于新生代,基于標(biāo)記-復(fù)制算法實(shí)現(xiàn),側(cè)重于吞吐量,有自適應(yīng)調(diào)節(jié)策略,合理搭配新生代和老年代大小; Parallel Old收集器,是Parallel Scavenge的老年代版本,基于標(biāo)記-整理算法實(shí)現(xiàn),JDK6開(kāi)始提供; CMS收集器,作用于老年代,目標(biāo)是低延遲,收集速度較快,基于標(biāo)記-清除算法實(shí)現(xiàn),會(huì)有內(nèi)存碎片;
各垃圾收集器作用域及組合關(guān)系可參考下圖:

2. G1收集器
2.1 G1收集器介紹
Garbage First(G1)收集器是垃圾回收技術(shù)發(fā)展歷史上里程碑式的成果,它開(kāi)創(chuàng)了收集器面向局部收集的設(shè)計(jì)思路和基于Region的堆內(nèi)存布局,自JDK7之后開(kāi)始發(fā)布,到了JDK8 Update 40版本后,G1提供了類(lèi)卸載的支持,這個(gè)版本的G1被Oracle稱(chēng)為全功能垃圾收集器(Fully-Featured Garbage Collector)。G1主要面向服務(wù)端應(yīng)用,自JDK9之后,G1取代了Parallel Old + Parallel Old的組合,成為服務(wù)端模式下的默認(rèn)垃圾收集器。也是自JDK9之后,CMS和Serial Old被標(biāo)記為廢棄(Deprecate)狀態(tài)而不再推薦使用。
經(jīng)典的GC收集器將對(duì)內(nèi)存按代劃分,這種劃代方式的內(nèi)存在邏輯上是連續(xù)的。而G1垃圾收集器將堆內(nèi)存按Region劃分,回收的衡量標(biāo)準(zhǔn)不再是它屬于哪個(gè)分代,而是哪塊內(nèi)存中存放的垃圾數(shù)量最多,回收收益最大,這就是G1收集器獨(dú)有的Mixed GC模式。
2.2 G1收集器堆內(nèi)存分布
G1收集器的堆內(nèi)存布局可參考下圖:
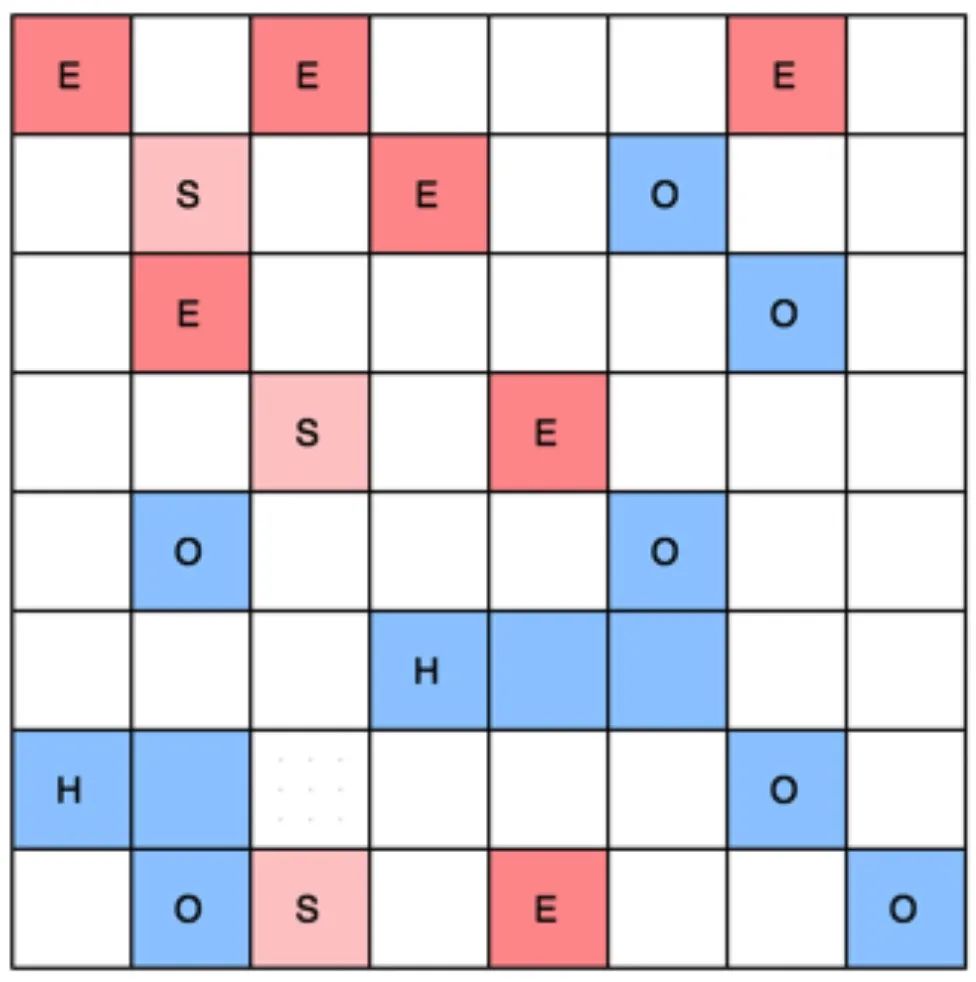
E,新生代Eden空間; S,新生代Survivor空間; O,老年代空間; H,Humongous區(qū)域,專(zhuān)門(mén)用來(lái)存儲(chǔ)大對(duì)象;
G1其實(shí)也遵循了按代回收的理念,只是不再固定的分配各代的大小,而是把連續(xù)的堆劃分為多個(gè)大小相等的獨(dú)立空間(Region),每一個(gè)Region,可以根據(jù)需要,扮演新生代(Eden、Survivor)、老年代的角色。收集器能夠?qū)Π缪莶煌巧腞egion采用不同的策略去處理,這樣無(wú)論是新對(duì)象還是老對(duì)象,熬過(guò)多次收集的舊對(duì)象都能夠有較好的收集效果。G1中還有一類(lèi)Humongous區(qū)域,G1認(rèn)為大小大于等于Region一半的對(duì)象即可判定為大對(duì)象。對(duì)于超過(guò)1個(gè)Region容量的大對(duì)象,將會(huì)被存放在N個(gè)連續(xù)的H Region之中,G1的大多數(shù)行為都把H Region作為來(lái)年代的一部分來(lái)看待。
每個(gè)Region的大小可通過(guò)參數(shù)-XX:G1HeapRegionSize設(shè)定,取值范圍1~32MB,且應(yīng)該為2的N次冪。
2.3 停頓預(yù)測(cè)模型
停頓預(yù)測(cè)模型(Pause Prediction Model)是指能夠支持指定在一個(gè)長(zhǎng)度為M的時(shí)間片段內(nèi),垃圾回收的時(shí)間不超過(guò)N的模型。G1的內(nèi)存被劃分為一系列不需要連續(xù)區(qū)域,即將Region作為單次回收的最小單元,每次垃圾回收到的空間都是Region大小的整數(shù)倍,這樣可以有計(jì)劃地避免在整個(gè)堆空間收集,也更容易控制垃圾回收時(shí)間。G1也會(huì)跟蹤各個(gè)Region的價(jià)值大小,建立各個(gè)Region空間的優(yōu)先級(jí)列表,已達(dá)到最大化的垃圾收集的收益。
那么如何建立可靠的停頓預(yù)測(cè)模型呢?用戶(hù)在啟動(dòng)Java程序時(shí)可以通過(guò)-XX:MaxGCPauseMillis指定停頓時(shí)間的最大期望值,在垃圾收集過(guò)程中,G1收集每個(gè)Region的回收耗時(shí),再根據(jù)歷史數(shù)據(jù)的偏差、置信度等統(tǒng)計(jì)數(shù)據(jù),由哪些Region組成的回收集合才能達(dá)到期望停頓值之內(nèi)的最高收益。
// share/vm/gc_implementation/g1/g1CollectorPolicy.hpp
double get_new_prediction(TruncatedSeq* seq) {
return MAX2(seq->davg() + sigma() * seq->dsd(),
seq->davg() * confidence_factor(seq->num()));
}
在這個(gè)預(yù)測(cè)計(jì)算公式中:davg表示衰減均值,sigma()返回一個(gè)系數(shù),表示信賴(lài)度,dsd表示衰減標(biāo)準(zhǔn)偏差,confidence_factor表示可信度相關(guān)系數(shù)。而方法的參數(shù)TruncateSeq,是一個(gè)截?cái)嗟男蛄校桓櫫诵蛄兄械淖钚碌膎個(gè)元素。TruncateSeq(繼承了AbsSeq)中,用來(lái)計(jì)算衰減均值、衰減變量,衰減標(biāo)準(zhǔn)偏差等:
// src/share/vm/utilities/numberSeq.cpp
void AbsSeq::add(double val) {
if (_num == 0) {
// if the sequence is empty, the davg is the same as the value
_davg = val;
// and the variance is 0
_dvariance = 0.0;
} else {
// otherwise, calculate both
_davg = (1.0 - _alpha) * val + _alpha * _davg;
double diff = val - _davg;
_dvariance = (1.0 - _alpha) * diff * diff + _alpha * _dvariance;
}
}
3. G1收集器運(yùn)行過(guò)程
3.1 需要思考的問(wèn)題
將Java堆按Region劃分后,跨Region對(duì)象的引用怎么解決?G1的解決辦法是每個(gè)Region維護(hù)自己的記憶集(Remembered Set),可以看做一個(gè)哈希表,key是別的Region的地址,value是本地的索引,通過(guò)這種雙向的結(jié)構(gòu),記錄下“我指向誰(shuí)”和“誰(shuí)指向我”的問(wèn)題。由于需要額外記錄這些數(shù)據(jù),G1比其他經(jīng)典收集器多了很多內(nèi)存占用。
在并發(fā)標(biāo)記階段如何保證收集線程和用戶(hù)線程互不干擾的運(yùn)行?如果GC線程標(biāo)記對(duì)象時(shí),用戶(hù)線程改變了對(duì)象之間的引用關(guān)系,必須保證不能打破原有的對(duì)象依賴(lài)圖結(jié)構(gòu),G1采用原始快照(SATB,Snapshot At The Begining)算法來(lái)實(shí)現(xiàn),由字面理解,SATB是GC開(kāi)始時(shí)活著的對(duì)象的一個(gè)快照。根據(jù)對(duì)象標(biāo)記算法,把遍歷對(duì)象圖結(jié)構(gòu)中遇到的對(duì)象,按照“是否被訪問(wèn)過(guò)”分為三種顏色:
白色,該對(duì)象未被垃圾收集器訪問(wèn)過(guò),在可達(dá)性分析階段結(jié)束后,若仍是白色,即代表對(duì)象不可達(dá),會(huì)被當(dāng)做垃圾收集掉; 黑色,對(duì)象已經(jīng)被垃圾收集器訪問(wèn)過(guò),且對(duì)象的所有引用也被掃描過(guò)了,它是安全存活的,因此黑色對(duì)象不可能指向白色對(duì)象; 灰色,表示對(duì)象已被垃圾收集器訪問(wèn)過(guò),但這個(gè)對(duì)象還至少有一個(gè)引用還沒(méi)有掃描過(guò);
此時(shí),若用戶(hù)線程和GC線程并發(fā)工作,用戶(hù)也要修改對(duì)象間的引用關(guān)系結(jié)構(gòu),這樣就會(huì)產(chǎn)生兩種后果:一種是把原本消亡的對(duì)象標(biāo)記為存活;另一種是會(huì)把原本存活的對(duì)象標(biāo)記為消亡。
SATB快照的存在,就可以讓G1采用如下辦法解決上述問(wèn)題:當(dāng)灰色對(duì)象要?jiǎng)h除指向白色對(duì)象的引用關(guān)系時(shí),就將這個(gè)要?jiǎng)h除的引用記錄下來(lái),在并發(fā)掃描結(jié)束后,再以記錄過(guò)的引用關(guān)系中的灰色對(duì)象為根,重新掃描一次,這樣無(wú)論引用關(guān)系刪除與否,都會(huì)按照最初的對(duì)象結(jié)構(gòu)圖進(jìn)行搜索。虛擬機(jī)通過(guò)寫(xiě)屏障,實(shí)現(xiàn)操作記錄的記錄和修改,避免并發(fā)帶來(lái)的問(wèn)題。
G1垃圾收集器在收集過(guò)程中,此時(shí)若用戶(hù)線程還在創(chuàng)建新對(duì)象,G1在每個(gè)Region中劃出一部分空間用于垃圾收集過(guò)程中的新對(duì)象分配,而且在收集過(guò)程中,默認(rèn)這塊區(qū)域的對(duì)象都是存活的。
如果內(nèi)存回收的速度趕不上內(nèi)存分配的速度,G1收集器也要被迫凍結(jié)用戶(hù)線程的執(zhí)行,導(dǎo)致Full GC而產(chǎn)生較長(zhǎng)時(shí)間的”Stop The World”。
3.2 垃圾回收過(guò)程
初始標(biāo)記(Initial Marking),僅標(biāo)記GC Roots能直接關(guān)聯(lián)到的對(duì)象,這個(gè)階段需要停頓線程,但耗時(shí)很短,借用進(jìn)行Young GC的時(shí)候同步完成的,G1收集器在這個(gè)階段沒(méi)有額外的停頓; 并發(fā)標(biāo)記(Concurrent Marking),從GC Root開(kāi)始做可達(dá)性分析,掃描整個(gè)對(duì)象引用結(jié)構(gòu)圖,耗時(shí)較長(zhǎng),但是可與用戶(hù)線程并發(fā)執(zhí)行,掃描完成后,還要重新處理SATB記錄下的并發(fā)時(shí)有引用修改的對(duì)象; 最終標(biāo)記(Final Marking),此時(shí)用戶(hù)線程也需要短暫暫停,用于處理并發(fā)標(biāo)記結(jié)束后仍遺留的SATB記錄; 篩選回收(Counting and Evacuation),更新Region數(shù)據(jù),對(duì)Region的回收價(jià)值做優(yōu)先級(jí)排序,根據(jù)用戶(hù)期望時(shí)間值制定回收集合,然后把被回收的Region的存活對(duì)象復(fù)制到另一個(gè)空的Region區(qū)域,此階段暫停所有用戶(hù)線程;
從上收集過(guò)程可以看出,用戶(hù)指定期望停頓時(shí)間是G1收集器很重要的參數(shù),它會(huì)讓G1收集器在吞吐量和延遲兩個(gè)指標(biāo)之間取一個(gè)平衡。因此設(shè)置合理的期望停頓時(shí)間是必要的,通常設(shè)置為100到200ms是比較合理的。
4. 應(yīng)用及總結(jié)
4.1 G1使用
如果你的JDK是9及之后的版本,那會(huì)默認(rèn)開(kāi)啟G1收集器,G1收集器其他相關(guān)的參數(shù):
| 參數(shù) | 含義 |
|---|---|
-XX:+UseG1GC | 使用G1收集器 |
-XX:MaxGCPauseMillis | 設(shè)置G1期望停頓時(shí)間,默認(rèn)值200ms |
-XX:G1HeapRegionSize | 設(shè)置Region大小 |
-XX:ParallelGCThreads | STW時(shí)間并行的線程數(shù) |
-XX:ConcGCThreads | 并發(fā)標(biāo)記階段的線程數(shù) |
-XX:G1NewSizePercent | 新生代占比最小值,默認(rèn)值5% |
-XX:G1MaxNewSizePercent | 新生代占比最大值,默認(rèn)值60% |
4.2 G1總結(jié)
G1垃圾收集器,從整體上來(lái)說(shuō),以Region劃分,可以看做是基于標(biāo)記-整理實(shí)現(xiàn),但從局部來(lái)說(shuō),兩個(gè)Region之間又是采用標(biāo)記-復(fù)制的算法,因此G1垃圾收集器不會(huì)產(chǎn)生內(nèi)存碎片,收集完成后能提供較完整的可用內(nèi)存。
G1收集器的內(nèi)存停頓模型,把內(nèi)存的期望停頓時(shí)間交給了程序員,對(duì)控制GC停頓時(shí)間可依據(jù)不同的業(yè)務(wù)模型、硬件 條件來(lái)合理的設(shè)置。
G1收集器的額外負(fù)載高,G1的記憶集可能會(huì)占到整個(gè)堆容量的20%甚至更多。另外G1對(duì)寫(xiě)屏障的復(fù)雜操作要比其他收集器消耗更多的運(yùn)算資源。
5. 參考文檔
Getting Started with the G1 Garbage Collector Garbage First Garbage Collector Java Hotspot G1 GC的一些關(guān)鍵技術(shù) Java中9種常見(jiàn)的CMS GC問(wèn)題分析與解決 Best practice for JVM Tuning with G1 GC Garbage Collectors – Serial vs. Parallel vs. CMS vs. G1
以上內(nèi)容就是關(guān)于深入理解G1垃圾收集器的全部?jī)?nèi)容了,謝謝你閱讀到了這里!