
【HotSpot、G1】垃圾回收算法和垃圾收集器


上一篇我們說了如何判斷一個(gè)對(duì)象是否存活,這一篇呢,就是接著前面幾篇文章來的,我們知道堆中分為年輕代和老年代,有著不同的特點(diǎn);每個(gè)區(qū)域有著不同的特點(diǎn),也就有了多種垃圾回收算法,每種算法也是根據(jù)內(nèi)存情況進(jìn)行不同程度的優(yōu)化
就像上一篇提到的打掃屋子,接下來就是需要找到打掃屋子的最合適的方法,比如屋子的哪些東西歸為一類,哪些可以扔掉,哪些可以擺放到一起

JVM的算法有很多,大魚這里只說比較常見的四種:
標(biāo)記-清楚算法
復(fù)制算法
標(biāo)記-整理算法
分代收集算法
說完了算法,就會(huì)介紹下JVM的流行的各種收集器,收集器就是垃圾回收算法的實(shí)現(xiàn)咯,就是理論和實(shí)現(xiàn)的關(guān)系,一起來學(xué)習(xí)吧
我知道你們都是最愛學(xué)習(xí)的仔,沒錯(cuò)吧(暗示關(guān)注,因?yàn)榇篝~會(huì)持續(xù)給大家更新技術(shù)博文

四種算法分別是標(biāo)記清除、復(fù)制、標(biāo)記整理、分代收集四種算法
標(biāo)記-清除算法
”標(biāo)記-清楚“算法,顧名思義,就是分為標(biāo)記和清楚兩個(gè)階段:首先標(biāo)記出所有需要回收的對(duì)象,在標(biāo)記完成后統(tǒng)一回收掉所有被標(biāo)記的對(duì)象
這是屬于最基礎(chǔ)的垃圾回收算法,后續(xù)的多種算法都是基于它的改進(jìn)
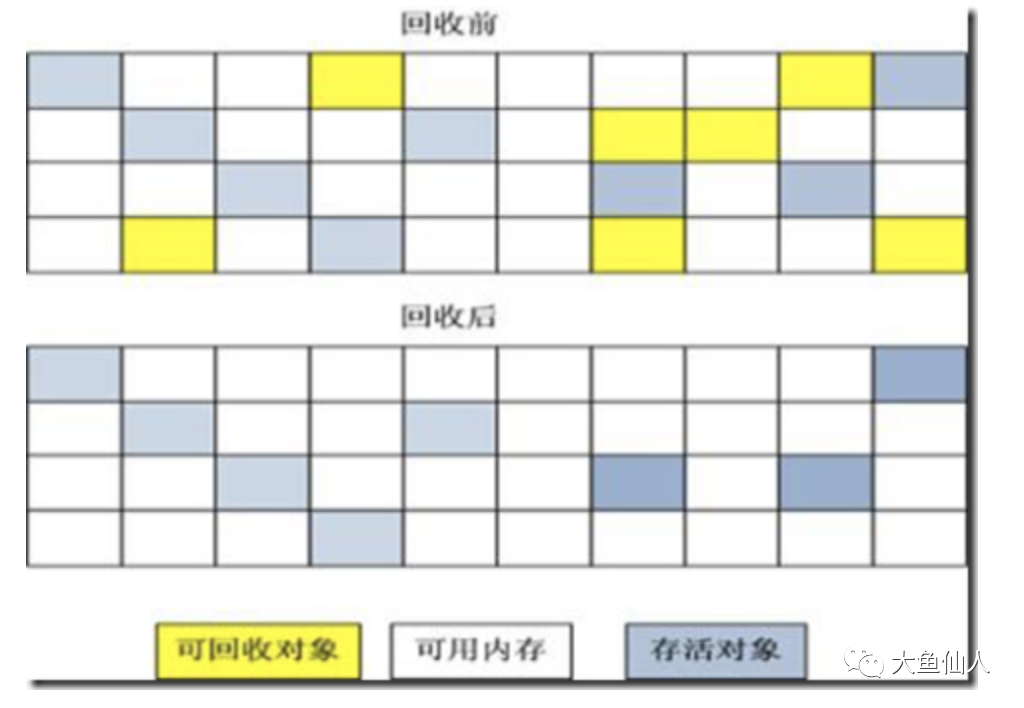
但是它有兩個(gè)主要的缺點(diǎn)的嘞
一個(gè)是效率問題,就是標(biāo)記和清楚的效率都比較低
二是空間問題,標(biāo)記清楚之后會(huì)產(chǎn)生大量的內(nèi)存碎片,空間碎片多了就會(huì)導(dǎo)致空間的利用率不高,你想啊,清楚之后出現(xiàn)很多比較小的空間,當(dāng)程序在以后的運(yùn)行過程中需要分配比較大的對(duì)象的時(shí)候,無法找到足夠的連續(xù)空間時(shí),便會(huì)提前觸發(fā)另一次的GC動(dòng)作
復(fù)制算法
為了解決效率問題,便出現(xiàn)了復(fù)制收集算法,它將可用的內(nèi)存按照容量劃分為大小相等的兩塊,每次只使用其中的一塊。當(dāng)這一塊的內(nèi)存用完了的時(shí)候,就把活著的對(duì)象復(fù)制到另一塊上,然后將已經(jīng)使用過的內(nèi)存空間全部清理掉
這樣便使得每次都是對(duì)其中一塊進(jìn)行內(nèi)存回收,內(nèi)存分配時(shí)就不需要考慮內(nèi)存碎片這樣的復(fù)雜情況;只需要移動(dòng)堆頂指針,按照順序分配內(nèi)存即可,實(shí)現(xiàn)很簡單,運(yùn)行起來也比較高效;不過這種算法的代價(jià)是將內(nèi)存縮小為原來的一半,持續(xù)復(fù)制生存期比較長的對(duì)象會(huì)導(dǎo)致效率降低
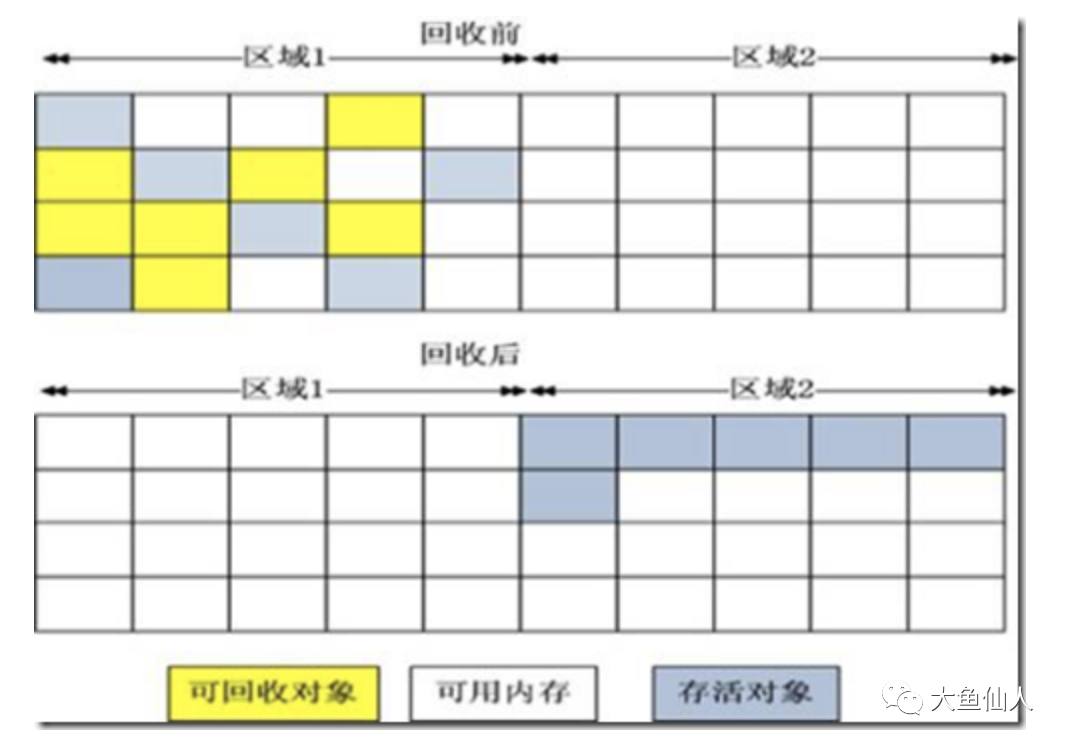
現(xiàn)在很多商業(yè)虛擬機(jī)都使用這種手機(jī)算法來回收新生代,新生代的98%對(duì)象都是朝生夕死的,所以呢,并不需要按照1:1的比例來劃分內(nèi)存空間,而是把內(nèi)存分成一塊較大的Eden區(qū)域和兩塊較小的Survivor空間
每次使用其中的Eden區(qū)域和一塊Survivor區(qū)域,最后復(fù)制的時(shí)候?qū)den和Survivor區(qū)域還存活的對(duì)象復(fù)制到另一塊Survivor區(qū)域,最后清理掉Eden區(qū)域和Survivor區(qū)域,只剩下剛剛復(fù)制過的Survivor區(qū)域,繼續(xù)使用Eden和這塊Survivor區(qū)域
這樣呢,每次也就只會(huì)浪費(fèi)10%的內(nèi)存,我們沒有辦法保證每次回收都只有不多于10%的對(duì)象存活,當(dāng)Survivor區(qū)域不夠用的時(shí)候,需要依賴其它內(nèi)存來進(jìn)行分配擔(dān)保(一般是老年代擔(dān)保);復(fù)制算法解決了內(nèi)存碎片的問題,提升了效率

標(biāo)記-整理算法
上面說的那種適用于新生代,因?yàn)?/span>新生代大多數(shù)都是朝生夕死的,所以也就能很好的利用那種回收算法;但是呢,對(duì)于老年代,這種方法就不適用了,因?yàn)槔夏甏拇蠖鄶?shù)對(duì)象都是很能活的,所以呢,復(fù)制來復(fù)制去的很浪費(fèi),很不合適
根據(jù)老年代的特點(diǎn),于是就衍生出了標(biāo)記-整理這種算法,標(biāo)記過程其實(shí)和標(biāo)記-清楚的算法類似,但是后續(xù)步驟不是直接對(duì)可回收對(duì)象進(jìn)行清理,而是讓所有存活的對(duì)象都向一端移動(dòng),然后直接清理掉端邊界以外的內(nèi)存
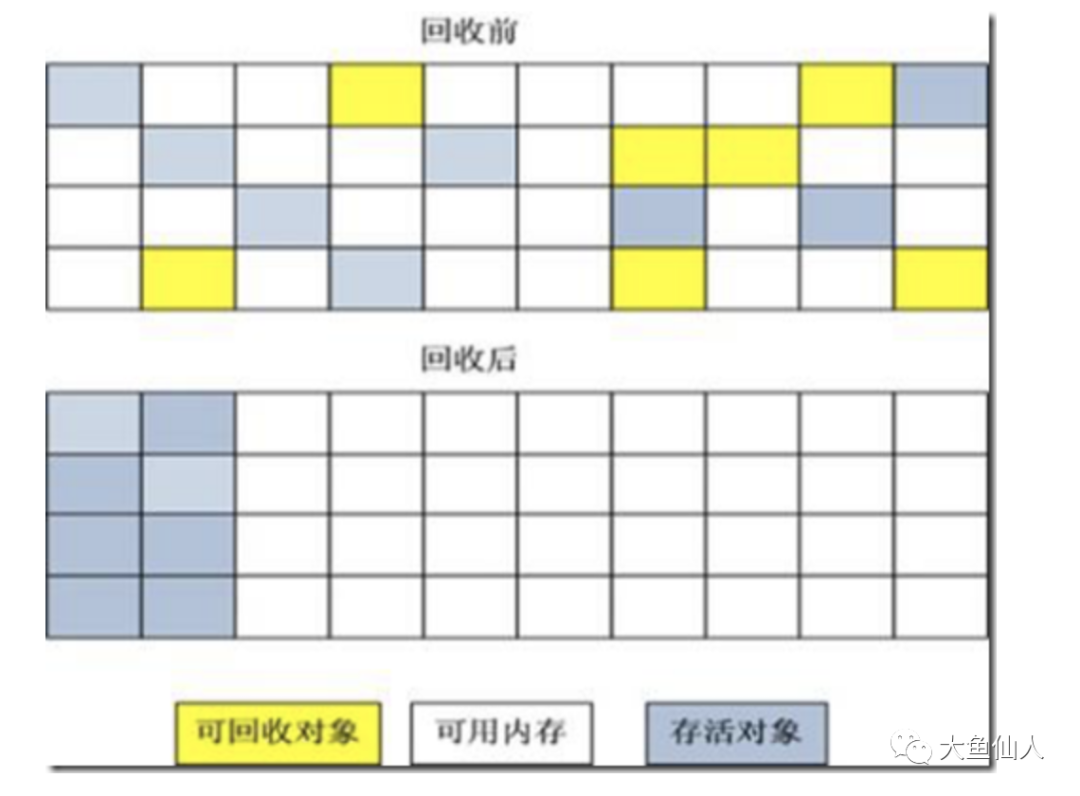
切記:是標(biāo)記完之后,先清理,再將存活的對(duì)象移動(dòng)到一端
標(biāo)記-整理算法相較于標(biāo)記-清楚算法增加了移動(dòng),所以成本更高,但是卻解決了內(nèi)存碎片的問題,對(duì)于老年代來說,是很合適的回收算法
分代收集算法
分代收集算法,聽名字就知道了,肯定就是根據(jù)年輕代還是老年代來采用不同的垃圾回收算法了,這樣就可以根據(jù)各個(gè)年代的特點(diǎn)采用最合適的收集算法了
在新生代中,每次垃圾收集時(shí)都有大量的對(duì)象死去,只有少量會(huì)存活,也就是選用復(fù)制算法,只需要付出少量存活對(duì)象的復(fù)制的成本即可;而對(duì)于老年代來說,回收率較低,每次存活的對(duì)象較多,就必須使用標(biāo)記-清楚或者標(biāo)記-整理算法來進(jìn)行回收咯
就像治理一個(gè)大企業(yè),或者治理一群人一樣,有的時(shí)候不能千篇一律的去采用同樣的對(duì)待方法,合適的人去用合適的對(duì)待方法,這樣才能恰到好處,功效最大化利用,我覺得我有當(dāng)boss的潛力,哈哈哈

快來關(guān)注我吧,等我哪天成了boss,我招聘高管的時(shí)候,要是我的粉絲,我就優(yōu)先給你offer(這么大的誘惑,快點(diǎn)動(dòng)動(dòng)小手點(diǎn)個(gè)關(guān)注吧
JVM虛擬機(jī)總的來說是一種標(biāo)準(zhǔn)規(guī)范,虛擬機(jī)有很多的實(shí)現(xiàn)版本,主要作用就是運(yùn)行Java的類文件的,而HotSpot是虛擬機(jī)的一種實(shí)現(xiàn),也是目前使用最廣泛的虛擬機(jī)
HotSpot,顧名思義,它是基于熱點(diǎn)代碼探測的,有JIT即時(shí)編譯功能,能夠提供高質(zhì)量的本地代碼,二者區(qū)別是一個(gè)是標(biāo)準(zhǔn),一個(gè)是實(shí)現(xiàn)方式
枚舉根節(jié)點(diǎn)
從可達(dá)性分析中,我們可以根據(jù)GC Roots節(jié)點(diǎn)找引用鏈這個(gè)操作為例子,可作為GC Roots的節(jié)點(diǎn)主要在全局性引用于執(zhí)行上下文中,現(xiàn)在的很多引用其實(shí)屬于很重量級(jí)了,僅僅方法區(qū)可能就會(huì)達(dá)到數(shù)百兆,如果要逐個(gè)檢查里面的引用,這樣必然會(huì)消耗很多時(shí)間
枚舉根節(jié)點(diǎn)的過程是必須停頓的,對(duì)時(shí)間的敏感也體現(xiàn)在GC的停頓上,因?yàn)檫@個(gè)分析工作必須在一個(gè)能夠確保一致性的快照中進(jìn)行
這里的一致性指的是在整個(gè)分析期間整個(gè)執(zhí)行系統(tǒng)看起來像被凍結(jié)在某個(gè)時(shí)間點(diǎn),不可以出現(xiàn)在過程中對(duì)象引用還在不斷變化的情況,這樣的話,準(zhǔn)確性就無法得到保證了
現(xiàn)在的虛擬機(jī)都是使用準(zhǔn)確實(shí)GC,所以當(dāng)執(zhí)行系統(tǒng)停頓下來之后,并不需要一個(gè)不漏的去檢查完所有執(zhí)行上下文和全局的引用位置,虛擬機(jī)應(yīng)該是知道哪些地方存放著這些對(duì)象引用
安全點(diǎn)
HotSpot虛擬機(jī)是使用一組OopMap的數(shù)據(jù)結(jié)構(gòu)來達(dá)到這個(gè)目的的,在類加載完成的時(shí)候,HotSpot就把對(duì)象內(nèi)什么偏移量上是什么類型的數(shù)據(jù)全都計(jì)算出來,在JIT編譯過程中,也會(huì)在特定的位置記錄下棧和寄存器中哪些位置是引用
有了OopMap,HotSpot可以快速且準(zhǔn)確地完成GC Roots的枚舉,但是呢,可能導(dǎo)致引用關(guān)系變化,或者OopMaori內(nèi)容變化的指令非常多,如果為每一條指令都生成對(duì)應(yīng)的OopMap,需要大量的額外空間,GC成本也會(huì)變高
哎啊,你這繞來繞去,到底咋辦呢

剛剛還說生成OopMap,現(xiàn)在又說成本太高了,那到底最后如何解決這個(gè)問題的呢
是這樣的,HotSpot并沒有為每個(gè)指令都生成OopMap,虛擬機(jī)在特定的位置記錄這些信息,這些位置被稱為安全點(diǎn)
在程序的執(zhí)行期間并非在所有位置都可以停下來GC,而是只有在達(dá)到安全點(diǎn)的時(shí)候才能夠暫停,所以安全點(diǎn)的選擇既不能太少讓GC等待時(shí)間太長,也不能過于頻繁以至于過分增大運(yùn)行時(shí)的負(fù)荷
GC發(fā)生時(shí)如何讓所有線程都跑到最近的安全點(diǎn)再停頓下來呢
這里呢,有兩種方案可以選擇,搶先試中斷和主動(dòng)式中斷
搶先試中斷不需要線程的執(zhí)行代碼主動(dòng)去配合,在GC發(fā)生時(shí),首先把所有線程全部中斷,如果發(fā)現(xiàn)有線程中斷的地方不在安全點(diǎn)上,就會(huì)恢復(fù)線程,讓它繼續(xù)跑到安全點(diǎn)上
其實(shí)現(xiàn)在幾乎沒有虛擬機(jī)實(shí)現(xiàn)采用搶先式來響應(yīng)GC事件了,我個(gè)人猜測是因?yàn)檫@種方法過于暴力,可控制性比較低
而主動(dòng)式中斷,則是當(dāng)GC需要中斷線程時(shí),不直接對(duì)線程進(jìn)行操作,僅僅簡單地設(shè)置一個(gè)標(biāo)志,各個(gè)線程的執(zhí)行會(huì)主動(dòng)去輪詢這個(gè)標(biāo)志,發(fā)現(xiàn)中斷標(biāo)志為真時(shí)就自己中斷掛起,輪詢標(biāo)志的地點(diǎn)和安全點(diǎn)是重合的
看似安全點(diǎn)已經(jīng)解決了停頓位置的問題,但是實(shí)際情況卻不是,因?yàn)樯厦鎯煞N方法考慮的都是程序的執(zhí)行期間,如果程序不執(zhí)行的時(shí)候呢
所謂的程序不執(zhí)行就是沒有分配CPU時(shí)間,比如線程處于Sleep和Blocked狀態(tài)時(shí),這樣線程無法響應(yīng)JVM的中短請(qǐng)求了,導(dǎo)致無法走到安全點(diǎn)去中斷掛起
安全區(qū)域
安全區(qū)域,大家應(yīng)該也能想出來了,指的是在一段代碼之中,引用關(guān)系不會(huì)發(fā)生變化,在這個(gè)區(qū)域的任意地方GC都是安全的,也可以把安全區(qū)域看成是擴(kuò)展的安全點(diǎn)
在線程執(zhí)行到安全區(qū)域中的代碼時(shí),首先標(biāo)識(shí)自己已經(jīng)進(jìn)入了安全區(qū)域,這樣在這段時(shí)間里JVM要發(fā)起GC時(shí),就不需要管標(biāo)識(shí)自己為安全區(qū)域狀態(tài)的線程了
在線程要離開安全區(qū)域時(shí),它要檢查系統(tǒng)是否已經(jīng)完成了根節(jié)點(diǎn)效率,如果完成了,則線程繼續(xù)執(zhí)行,否則則必須等待直到收到可以安全離開安全區(qū)域的信號(hào)為止
上面看了垃圾回收算法了,屬于方法論,垃圾收集器就是方法的具體實(shí)現(xiàn),收集器其實(shí)有很多種,因?yàn)镴ava虛擬機(jī)規(guī)范對(duì)垃圾收集器應(yīng)該如何實(shí)現(xiàn)也并沒有任何規(guī)定,所以呢,百花齊放
Serial收集器:復(fù)制算法
這個(gè)垃圾收集器屬于元老級(jí)別的收集器了,采用的復(fù)制算法,單線程收集器,只會(huì)使用一個(gè)CPU或者一個(gè)收集線程去完成垃圾收集工作,更重要的是它在進(jìn)行垃圾收集的時(shí)候,必須暫停其它所以的工作線程,直到收集結(jié)束為止
這個(gè)過程也就是大家都熟知的Stop The World,停止世界
這個(gè)工作是虛擬機(jī)在后臺(tái)自動(dòng)發(fā)起和自動(dòng)完成的,用戶不可見,但是會(huì)把用戶正常工作線程全部停掉,是有感知的,對(duì)于很多應(yīng)用是難以接受的
到現(xiàn)在為止,它依然是虛擬機(jī)運(yùn)行組Client模式下的默認(rèn)新生代收集器,也有著優(yōu)于其他收集器的地方:簡單而高效,單線程,沒有線程切換交互的開銷,專心做垃圾收集工作,收集幾十兆甚至一兩百兆的新生代內(nèi)存,停頓時(shí)間完全可以控制在幾十毫秒以內(nèi),這點(diǎn)停頓也是可以接受的
Serial Old收集器:標(biāo)記整理算法
Serial收集器的老年代版本,也同樣是一個(gè)單線程收集器,使用的標(biāo)記-整理算法,主要意義是給Client模式下的虛擬機(jī)使用
在Server模式下,主要有兩大用途:一種是在JDK1.5之前和Parallel Scavenge收集器搭配使用,另一種用途是作為CMS收集器的后備預(yù)案
ParNew收集器:復(fù)制算法
新生代的收集器,是多線程版本的Serial收集器,在多核CPU環(huán)境下有著比Serial更好的表現(xiàn);除了多線程工作之外,其余和Serial收集器很相似
它卻是很多運(yùn)行在Server模式下的虛擬機(jī)的新生代收集器,比較重要的原因就是除了Serial收集器,目前只有它可以和CMS收集器配合工作(CMS下面介紹)
ParNew Scavenge收集器:復(fù)制算法
一個(gè)新生代收集器,使用的是復(fù)制算法,屬于并行的多線程收集器,看上面和上面的ParNew收集器一樣啊,特別之處在哪里呢
ParNew Scanvenge收集器最大的特點(diǎn)是它的關(guān)注點(diǎn)與其它收集器不同,CMS等收集器的關(guān)注點(diǎn)是盡可能的縮短垃圾收集時(shí)的用戶線程的停頓時(shí)間,而Parallel Scavenge收集器的目的則是達(dá)到一個(gè)可控制的吞吐量
吞吐量:CPU用于運(yùn)行用戶代碼的時(shí)間和CPU總消耗時(shí)間的比值
停頓時(shí)間短更適合給用戶帶來更好的交互體驗(yàn),而高吞吐量則可以高效率的利用CPU時(shí)間,盡快的完成運(yùn)算任務(wù),主要適合在后臺(tái)運(yùn)算而不需要太多交互的任務(wù)
該收集器提供了兩個(gè)精確控制吞吐量的參數(shù):分別是控制最大垃圾收集停頓時(shí)間的-XX:MaxGCPauseMillis參數(shù)以及直接設(shè)置吞吐量大小的-XX:GCTimeRatio參數(shù)
Parallel Old收集器:標(biāo)記-整理算法
Parallel Scavenge收集器的老年代版本,是一個(gè)多線程的收集器
也正是由于它的出現(xiàn),Parallel Scavenge也正式有了合適的搭檔,正式產(chǎn)生了吞吐量優(yōu)先的的應(yīng)用組合,在注重吞吐量和CPU的資源敏感場合,都可以優(yōu)先考慮這一對(duì)搭檔
CMS:標(biāo)記-清楚算法
CMS收集器是以獲取最短回收停頓時(shí)間為目標(biāo),也就是能提供最好的客戶體驗(yàn)為準(zhǔn),在一些注重服務(wù)的響應(yīng)速度的應(yīng)用上很符合,基于標(biāo)記-清楚算法
CMS回收過程較為復(fù)雜,分為四個(gè)步驟:
初始標(biāo)記
并發(fā)標(biāo)記
重新標(biāo)記
并發(fā)清除
其中,前兩個(gè)步驟初始標(biāo)記、并發(fā)標(biāo)記是需要Stop The World的,初始標(biāo)記僅僅是標(biāo)記一下GC Roots能直接關(guān)聯(lián)到的對(duì)象,速度很快,并發(fā)標(biāo)記是進(jìn)行GC Roots的Tracing階段
重新標(biāo)記階段則是為了修正并發(fā)標(biāo)記期間因用戶程序繼續(xù)運(yùn)作而導(dǎo)致產(chǎn)生的標(biāo)記變動(dòng),這個(gè)階段的停頓時(shí)間一般會(huì)比初始標(biāo)記階段稍長一些,但遠(yuǎn)比并發(fā)標(biāo)記時(shí)間短
整個(gè)過程最耗時(shí)的并發(fā)標(biāo)記和并發(fā)清楚都是可以與用戶線程一起工作的,所以,總體上來看,CMS收集器的內(nèi)存回收過程和用戶線程一起并發(fā)執(zhí)行的
等下,大魚,我記得標(biāo)記-清楚算法你上面說了會(huì)有產(chǎn)生大量空間碎片的缺點(diǎn)啊,這樣的話,不利于接下來給大對(duì)象分配,可能出現(xiàn)很多不連續(xù)的小空間,這咋辦
為了解決這個(gè)問題,CMS收集器提供了一個(gè)-XX:+UseCMSCompactAtFullCollection的開關(guān)參數(shù),默認(rèn)是開啟的,用于在CMS收集器頂不住要進(jìn)行FullGC的時(shí)候開啟碎片的合并整理過程
不過內(nèi)存碎片整理的過程是無法并發(fā)的,空間碎片問題解決了,但是停頓時(shí)間不得不變長;虛擬機(jī)提供者還設(shè)計(jì)了一個(gè)參數(shù)-XX:CMSFullGCsBeforeCompaction,這個(gè)參數(shù)是用于設(shè)置執(zhí)行多少次不壓縮的Full GC,再來一次壓縮的(默認(rèn)值是0,表示每次進(jìn)行Full GC都會(huì)進(jìn)行內(nèi)存碎片整理)
最重要的G1收集器
G1收集器是當(dāng)今收集器技術(shù)發(fā)展最前沿的成果之一,所以這個(gè)是最需要熟悉的,與其它的收集器相比,G1收集器具備以下優(yōu)點(diǎn)
并行與并發(fā):高效利用多核CPU來縮短Stop The World的時(shí)間
分代收集:采用不同方式來處理堆中的不同特點(diǎn)的對(duì)象
空間整合:和CMS的標(biāo)記-清理是不同的,G1從整體上來看是基于標(biāo)記-整理算法,從局部Region之間來看是基于復(fù)制算法實(shí)現(xiàn)的,這兩種算法都不會(huì)有內(nèi)存碎片產(chǎn)生
可預(yù)測的停頓:這是特點(diǎn)之一,G1除了追求低停頓之外,還能建立可預(yù)測的停頓時(shí)間模型,能讓使用者明確指定在一個(gè)長度為M毫秒的時(shí)間片段之內(nèi),消耗在垃圾收集上的時(shí)間不得超過N毫秒
別的收集器的范圍都是整個(gè)新生代或者是老年代,而G1不再是針對(duì)于一部分,而是針對(duì)整個(gè)堆的收集器,有很大區(qū)別;它將Java堆劃分為多個(gè)大小相等的獨(dú)立的Region區(qū)域,雖然還保留有新生代和老年代的概念,但是新生代和老年代不再是物理隔離的,它們都是屬于一部分Region的集合
那它為什么可以建立可預(yù)測的停頓時(shí)間模型呢?
是這樣的,它可以有計(jì)劃的避免對(duì)整個(gè)堆進(jìn)行垃圾回收,G1跟蹤各個(gè)Region里面的垃圾堆積的價(jià)值大小,也就是回收獲得的空間大小以及回收所需的時(shí)間的經(jīng)驗(yàn)值,在后臺(tái)維護(hù)一個(gè)優(yōu)先列表,每次根據(jù)允許的收集時(shí)間,來優(yōu)先回收價(jià)值最大的Region,保證了G1收集器在有限時(shí)間內(nèi)可以獲取盡可能高的收集效率
好好說說G1的化整為零的思路
你可能覺得把內(nèi)存劃分為多個(gè)Region來管理,理解起來似乎很容易,但是其中的實(shí)現(xiàn)細(xì)節(jié),卻比較麻煩,我們來看一個(gè)細(xì)節(jié)
把Java堆分為多個(gè)Region之后,垃圾收集器就能以Region為單位來進(jìn)行管理了?實(shí)際上是Region不可能是獨(dú)立的,一個(gè)對(duì)象分配在某個(gè)Region中,它并非只能被本Region中的其他對(duì)象引用,而是可以和整個(gè)Java堆任意的對(duì)象發(fā)生引用關(guān)系
那這樣的話,在做可達(dá)性分析的時(shí)候,豈不是還是得掃描整個(gè)Java堆才能保證準(zhǔn)確性?
其實(shí)這個(gè)問題并非G1才有,而是G1更加突出,在以前的分代收集中,新生代比老年代小,新生代收集頻繁,那回收新生代對(duì)象時(shí)同樣有相同的問題,如果回收新生代的時(shí)候不得不掃描老年代,那Minor GC的效率肯定下降不少
如何來避免全堆掃描呢
在G1收集器中,Region之間的對(duì)象引用和其它收集器新生代與老年代之間的對(duì)象引用都是通過Remembered Set來避免全堆掃描的,G1中每個(gè)Region都有一個(gè)與之對(duì)應(yīng)的Remembered Set,在對(duì)Reference類型對(duì)象進(jìn)行寫操作時(shí),會(huì)產(chǎn)生一個(gè)Write Barrier暫時(shí)中斷寫操作,檢查Reference引用的對(duì)象是否處于不同的Region之中,如果是,便通過CardTable把相關(guān)引用信息記錄到被引用對(duì)象所屬的Region的Remembered Set之中
這樣,當(dāng)進(jìn)行內(nèi)存回收時(shí),在GC根節(jié)點(diǎn)的枚舉范圍中加入Remembered Set就可以保證不對(duì)全堆進(jìn)行掃描也不會(huì)有遺漏了
G1收集器的運(yùn)作步驟
初始標(biāo)記:標(biāo)記GC Roots能直接關(guān)聯(lián)的對(duì)象,需要停頓線程,時(shí)間較短
并發(fā)標(biāo)記:從GC Root在堆中進(jìn)行可達(dá)性分析,找出存活的對(duì)象,耗時(shí)較長,但可與用戶線程并發(fā)執(zhí)行
最終標(biāo)記:修正在并發(fā)標(biāo)記期間因用戶線程運(yùn)作而導(dǎo)致的標(biāo)記產(chǎn)生變動(dòng)的那一部分,把這個(gè)記錄在Remembered Set Logs里面,并且合并到Remembered Set中
篩選回收:對(duì)各個(gè)Region的回收價(jià)值和成本進(jìn)行排序,根據(jù)用戶期望來制定回收計(jì)劃
好了,以上就是全部內(nèi)容了,我是小魚仙,你們的學(xué)習(xí)成長小伙伴

我希望有一天能夠靠寫字養(yǎng)活自己,現(xiàn)在還在磨練,這個(gè)時(shí)間可能會(huì)有很多年,感謝你們做我最初的讀者和傳播者。請(qǐng)大家相信,只要給我一份愛,我終究會(huì)還你們一頁情的。
再次感謝大家能夠讀到這里,我后面會(huì)持續(xù)的更新技術(shù)文章以及一些記錄生活的靈魂文章,如果覺得不錯(cuò)的,覺得【大魚同學(xué)】有點(diǎn)東西的話,求點(diǎn)贊、關(guān)注、分享三連
哦,對(duì)了!后續(xù)的更新文章我都會(huì)及時(shí)放到這里,歡迎大家點(diǎn)擊觀看,都是干貨文章啊,建議收藏,以后隨時(shí)翻閱查看
https://github.com/DayuMM2021/Java
