本文由 InfoQ 整理自小年糕算法中臺后端架構(gòu)師封幼林在 QCon+ 大廠案例(2021 冬季北京站)的分享《高并發(fā)推薦系統(tǒng)架構(gòu)設(shè)計》。
你好!我是封幼林,在小年糕負責推薦系統(tǒng),主要從事服務(wù)架構(gòu)相關(guān)工作。今天我要和你分享的話題是《高并發(fā)推薦系統(tǒng)架構(gòu)設(shè)計》。
這次分享主要分為以下這幾個部分:
推薦系統(tǒng)的基本架構(gòu);
舊版線上架構(gòu)的并發(fā)瓶頸問題;
新版線上架構(gòu)編程語言的選擇;
印象深刻的 Go 踩坑經(jīng)歷。
我們進入第一部分,推薦系統(tǒng)的基本架構(gòu)。第一個問題是,什么是推薦系統(tǒng)?以及為什么要有推薦系統(tǒng)?
 推薦系統(tǒng)
推薦系統(tǒng)
經(jīng)過近幾年互聯(lián)網(wǎng)應用的飛速發(fā)展,我們迎來了數(shù)據(jù)爆炸時代。以時下流行的短視頻應用為例,平臺上有海量的視頻資源。當一個用戶到來時,平臺需要展示他感興趣的內(nèi)容,用戶的體驗直接關(guān)系到平臺的盈利能力。所以推薦系統(tǒng)本質(zhì)上是一個信息過濾裝置,用來在數(shù)以萬計的內(nèi)容中篩選出最符合用戶興趣的那一少部分。通過推薦系統(tǒng),用戶可以發(fā)現(xiàn)自己感興趣的內(nèi)容,從而提升體驗;平臺也可以自動發(fā)現(xiàn)有價值的內(nèi)容,從而提高效率并帶來更多收益。
 一個通用推薦系統(tǒng)的架構(gòu)
一個通用推薦系統(tǒng)的架構(gòu)
一個通用的推薦系統(tǒng),就是以物料數(shù)據(jù)和用戶行為日志為輸入,經(jīng)過預處理和特征工程之后得到相應的特征數(shù)據(jù),再用一些算法模型學習特征數(shù)據(jù)中的隱含知識,最后基于學到的知識實現(xiàn)精準的個性化推薦。整個架構(gòu)中,包含離線部分和線上部分。
推薦系統(tǒng)的線上架構(gòu),才是真正處理用戶請求的部分。
 推薦系統(tǒng) Online 架構(gòu)
推薦系統(tǒng) Online 架構(gòu)
當一個請求到來時,首先經(jīng)過 AB 分流模塊,在這里,基于用戶的某些特征應用哈希算法來進行分流,對分流后的用戶應用不同的動態(tài)配置,主要用來支持不同策略的對比試驗。AB 模塊之后是多路召回,就是根據(jù)用戶的特征在多個召回服務(wù)和 Redis 中并發(fā)獲取數(shù)據(jù)。召回的數(shù)據(jù)經(jīng)過過濾去重之后,就得到了本次推薦的粗略列表。再對這個列表應用模型排序,就得到了符合用戶興趣的個性化推薦結(jié)果。最后把結(jié)果返回給用戶之前,還要根據(jù)具體業(yè)務(wù)規(guī)則,對結(jié)果進行一次重排序。關(guān)于推薦系統(tǒng)基本架構(gòu)的介紹就到這里,后續(xù)內(nèi)容都是基于推薦系統(tǒng)的線上架構(gòu)展開的。
接下來進入第二部分,在這里,我要和你分享一個真實的并發(fā)瓶頸問題。
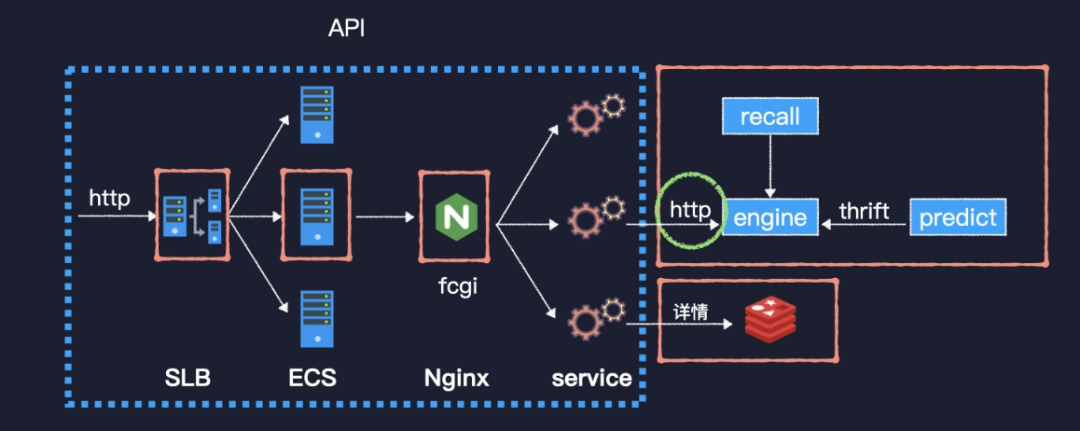 舊版推薦系統(tǒng)
舊版推薦系統(tǒng)
我們的舊版推薦系統(tǒng)是使用 C++ 開發(fā)的,主要包含以下幾個核心服務(wù)。
接口服務(wù) API 實現(xiàn)了業(yè)務(wù)側(cè)的接口,推薦引擎 engine 實現(xiàn)了推薦的主要流程,recall 和 predict 分別是召回和模型預測服務(wù)。API 服務(wù)主要實現(xiàn)了兩個接口,feed 流推薦接口和詳情接口。當一個 http 請求到來時,先經(jīng)過 SLB 到達一臺 ECS,再經(jīng)過本機部署的 Nginx,轉(zhuǎn)換為 FastCGI 協(xié)議到達我們的服務(wù)程序。服務(wù)程序采用的是多進程單線程模式,類似于 php-fpm。推薦接口依賴于后續(xù)的幾個服務(wù),而詳情接口比較簡單,就是讀取 Redis 并返回而已。要說的這個問題就出現(xiàn)在 API 服務(wù)上。
有一天晚高峰,接口的最大延遲突然從 300 毫秒左右飆升至 30 秒,觸發(fā)了一系列報警。監(jiān)控平臺顯示,API 兩個接口的延遲曲線基本一致。API 和 engine 的 CPU 使用率都沒超過 50%,但是 predict 服務(wù)卻幾乎跑滿了 CPU。于是我們緊急將 predict 服務(wù)翻倍擴容,擴容后負載和延遲都下降至正常水平。
事后復盤發(fā)現(xiàn)有一個問題無法解釋,那就是不依賴于后續(xù)服務(wù)的詳情接口為何也會延遲飆升。帶著這個問題去分析程序底層框架的源碼,發(fā)現(xiàn) FastCGI 模塊是基于 epoll 實現(xiàn)的,但是用來發(fā)起 http 請求以及用來讀寫 Redis 的模塊,都是工作在阻塞式 IO 之下的。所以在并發(fā)量很高時,進程都因等待后續(xù)服務(wù)的響應而阻塞,無法處理新的請求,這才造成詳情接口延遲飆升。
沿著這個問題,我們來對比一下阻塞式 IO 與 IO 多路復用的不同。
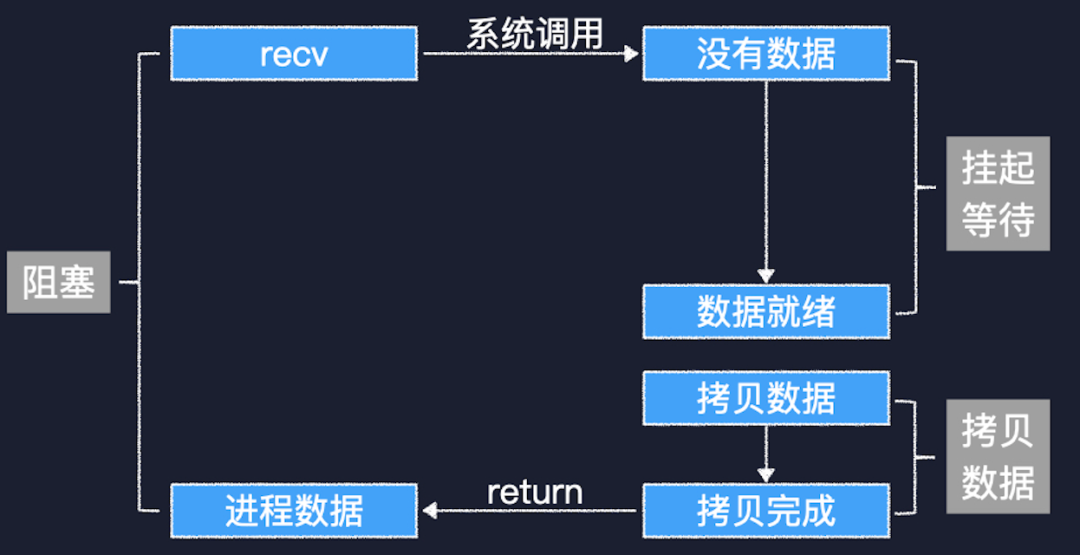 阻塞式 IO
阻塞式 IO
首先來看阻塞式 IO,線程調(diào)用 recv 來接收數(shù)據(jù),內(nèi)核這邊發(fā)現(xiàn) socket 接收緩沖區(qū)里沒有數(shù)據(jù),就把當前線程掛起。等到網(wǎng)絡(luò)對端的數(shù)據(jù)發(fā)送過來,線程被喚醒向用戶空間拷貝數(shù)據(jù)。

再來看 IO 多路復用,當前線程通過 epoll 監(jiān)聽多個 socket 上的可讀、可寫事件,調(diào)用 epoll_wait 時只要有一個 socket 能夠滿足要求,線程就不會被掛起。即使被掛起,也是只要有一個 socket 上的 IO 事件觸發(fā)就能被喚醒。因為實現(xiàn)了多路監(jiān)聽,所以總是能夠及時處理可讀或可寫的 socket。 Linux 平臺的 IO 多路復用:epollLinux 系統(tǒng)上的 IO 多路復用技術(shù)就是 epoll,我們調(diào)用 epoll_create1 來創(chuàng)建一個 epoll 實例,這其實會在內(nèi)核中創(chuàng)建一個 eventpoll 對象。eventpoll 中有一顆紅黑樹,用來管理所有監(jiān)聽的文件描述符,還有一個就緒隊列,里面是 IO 事件已經(jīng)觸發(fā)的文件描述符。調(diào)用 epoll_ctl 把一個 socket 描述符添加到 epoll 中的時候,就會在紅黑樹中添加一個新的節(jié)點,同時還會在網(wǎng)絡(luò) IO 模塊的 socket 對象那里設(shè)置一個回調(diào)。當這個 socket 對象上的 IO 事件觸發(fā)時,就會調(diào)用這個回調(diào),從而把對應的文件描述符添加到就緒隊列中。線程調(diào)用 epoll_wait 的時候,只需要關(guān)心這個就緒隊列就可以了,所以效率很高。前面只是理論層面的分析,我們再來通過實際的應用場景對比一下兩者的不同
Linux 平臺的 IO 多路復用:epollLinux 系統(tǒng)上的 IO 多路復用技術(shù)就是 epoll,我們調(diào)用 epoll_create1 來創(chuàng)建一個 epoll 實例,這其實會在內(nèi)核中創(chuàng)建一個 eventpoll 對象。eventpoll 中有一顆紅黑樹,用來管理所有監(jiān)聽的文件描述符,還有一個就緒隊列,里面是 IO 事件已經(jīng)觸發(fā)的文件描述符。調(diào)用 epoll_ctl 把一個 socket 描述符添加到 epoll 中的時候,就會在紅黑樹中添加一個新的節(jié)點,同時還會在網(wǎng)絡(luò) IO 模塊的 socket 對象那里設(shè)置一個回調(diào)。當這個 socket 對象上的 IO 事件觸發(fā)時,就會調(diào)用這個回調(diào),從而把對應的文件描述符添加到就緒隊列中。線程調(diào)用 epoll_wait 的時候,只需要關(guān)心這個就緒隊列就可以了,所以效率很高。前面只是理論層面的分析,我們再來通過實際的應用場景對比一下兩者的不同 基于阻塞式 IO 的 HTTP 請求讀取過程一個 http 請求可以分為請求行、請求頭和請求體三個部分。在這個例子中,第一行就是請求行。然后是請求頭,以一個空行結(jié)束。最后是請求體。基于阻塞式 IO 來讀取一個 http 請求時,只要循環(huán)地調(diào)用 recv 就可以了。檢測到第一個\r\n 時,就表明接收到了完整的請求行。檢測到兩個連續(xù)的\r\n 時,就說明完成了請求頭的接收。對于一個比較短的請求,請求頭中一般會有 Content-Length,通過它,我們就可以知道需要接收多長的請求體。整個過程中,當前線程大部分時間應該都在掛起等待。
基于阻塞式 IO 的 HTTP 請求讀取過程一個 http 請求可以分為請求行、請求頭和請求體三個部分。在這個例子中,第一行就是請求行。然后是請求頭,以一個空行結(jié)束。最后是請求體。基于阻塞式 IO 來讀取一個 http 請求時,只要循環(huán)地調(diào)用 recv 就可以了。檢測到第一個\r\n 時,就表明接收到了完整的請求行。檢測到兩個連續(xù)的\r\n 時,就說明完成了請求頭的接收。對于一個比較短的請求,請求頭中一般會有 Content-Length,通過它,我們就可以知道需要接收多長的請求體。整個過程中,當前線程大部分時間應該都在掛起等待。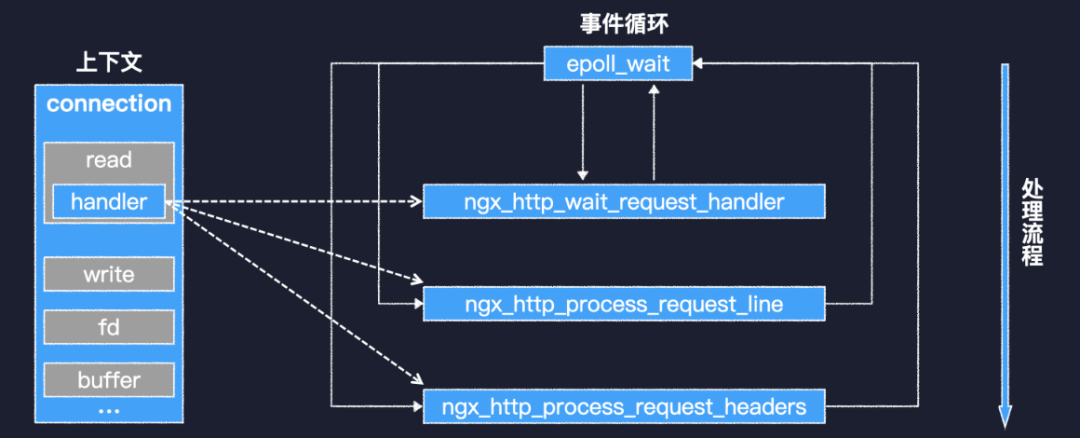 基于 IO 多路復用的 HTTP 請求讀取,以 Nginx 為例再來看看基于 IO 多路復用的場景,以 Nginx 為例。因為是基于事件循環(huán),所以 Nginx 實現(xiàn)了一系列的回調(diào)函數(shù),并且用 connection 對象來存儲每個連接的上下文。其中 read 對象的 handler 字段,就是現(xiàn)階段處理可讀事件的回調(diào)函數(shù)。http 連接建立之初,handler 指向 wait request 函數(shù),該函數(shù)會等到客戶端有數(shù)據(jù)發(fā)送過來,才實際分配需要的資源,并把 handler 指向 process request line 函數(shù)。后者會在接收到完整的請求行之后,把 handler 指向 process request headers 函數(shù)。就像這樣,整個處理流程被分成了多個階段,由一系列回調(diào)函數(shù)來完成。這樣雖然性能很好,但確實不易于編程。所以除了 Nginx、Redis 這些基礎(chǔ)軟件之外,很少見到基于事件循環(huán)開發(fā)的業(yè)務(wù)系統(tǒng)。所以,要想基于 IO 多路復用來重構(gòu)我們的推薦系統(tǒng),是十分困難的。
基于 IO 多路復用的 HTTP 請求讀取,以 Nginx 為例再來看看基于 IO 多路復用的場景,以 Nginx 為例。因為是基于事件循環(huán),所以 Nginx 實現(xiàn)了一系列的回調(diào)函數(shù),并且用 connection 對象來存儲每個連接的上下文。其中 read 對象的 handler 字段,就是現(xiàn)階段處理可讀事件的回調(diào)函數(shù)。http 連接建立之初,handler 指向 wait request 函數(shù),該函數(shù)會等到客戶端有數(shù)據(jù)發(fā)送過來,才實際分配需要的資源,并把 handler 指向 process request line 函數(shù)。后者會在接收到完整的請求行之后,把 handler 指向 process request headers 函數(shù)。就像這樣,整個處理流程被分成了多個階段,由一系列回調(diào)函數(shù)來完成。這樣雖然性能很好,但確實不易于編程。所以除了 Nginx、Redis 這些基礎(chǔ)軟件之外,很少見到基于事件循環(huán)開發(fā)的業(yè)務(wù)系統(tǒng)。所以,要想基于 IO 多路復用來重構(gòu)我們的推薦系統(tǒng),是十分困難的。
接下來就進入了第三部分,繼續(xù)前面的話題,我們要重構(gòu)推薦系統(tǒng),希望有一種語言或框架,能夠兼得阻塞式 IO 的簡單易用和 IO 多路復用的高并發(fā)、高性能。這就是下面這個 IO 事件驅(qū)動的協(xié)程調(diào)度模型。 IO 事件驅(qū)動的協(xié)程調(diào)度來看這張圖,我們?yōu)槊總€請求分配一個棧,也就成為了一個協(xié)程。當這個協(xié)程要等待網(wǎng)絡(luò) IO 時,我們把對應的 socket 描述符添加到 epoll 中,然后切換到下一個可運行的協(xié)程,后續(xù)的協(xié)程也是這樣。等到?jīng)]有可運行的協(xié)程時,再調(diào)用 epoll_wait,得到一組已經(jīng)就緒的文件描述符。再找到每個描述符所關(guān)聯(lián)的棧,就可以進行新一輪的調(diào)度。事件循環(huán)被封裝在底層,每個協(xié)程中可以像阻塞式 IO 那樣平鋪直敘的寫代碼。但是這個模型還是很簡陋,沒有考慮 CPU 密集型應用,以及多核 CPU 上的擴展性等問題。而這些問題,通過 Go 語言的 GMP 調(diào)度模型都能夠很好的解決。
IO 事件驅(qū)動的協(xié)程調(diào)度來看這張圖,我們?yōu)槊總€請求分配一個棧,也就成為了一個協(xié)程。當這個協(xié)程要等待網(wǎng)絡(luò) IO 時,我們把對應的 socket 描述符添加到 epoll 中,然后切換到下一個可運行的協(xié)程,后續(xù)的協(xié)程也是這樣。等到?jīng)]有可運行的協(xié)程時,再調(diào)用 epoll_wait,得到一組已經(jīng)就緒的文件描述符。再找到每個描述符所關(guān)聯(lián)的棧,就可以進行新一輪的調(diào)度。事件循環(huán)被封裝在底層,每個協(xié)程中可以像阻塞式 IO 那樣平鋪直敘的寫代碼。但是這個模型還是很簡陋,沒有考慮 CPU 密集型應用,以及多核 CPU 上的擴展性等問題。而這些問題,通過 Go 語言的 GMP 調(diào)度模型都能夠很好的解決。 Go 語言的 GMP 調(diào)度模型在 GMP 中,G 就是協(xié)程,M 是工作線程,而 P 是個虛擬的處理器,持有一組資源。M 必須要關(guān)聯(lián)一個 P 才能執(zhí)行 Go 代碼,系統(tǒng)中 P 的數(shù)量默認等于 CPU 核數(shù),所以有很好的擴展性。每個 P 有自己的就緒隊列,避免了頻繁爭用全局鎖。在 M執(zhí)行系統(tǒng)調(diào)用的時候,其關(guān)聯(lián)的 P 可以被其他 M 搶占,保證了資源的利用率。多個 P 之間可以通過全局隊列均衡任務(wù),或者直接進行任務(wù)竊取,調(diào)度器還實現(xiàn)了基于時間片的搶占式調(diào)度,保證了調(diào)度的公平性。那么 IO 多路復用技術(shù)是如何與調(diào)度系統(tǒng)結(jié)合起來的呢?那就要看 Go 語言的 netpoller 模塊。
Go 語言的 GMP 調(diào)度模型在 GMP 中,G 就是協(xié)程,M 是工作線程,而 P 是個虛擬的處理器,持有一組資源。M 必須要關(guān)聯(lián)一個 P 才能執(zhí)行 Go 代碼,系統(tǒng)中 P 的數(shù)量默認等于 CPU 核數(shù),所以有很好的擴展性。每個 P 有自己的就緒隊列,避免了頻繁爭用全局鎖。在 M執(zhí)行系統(tǒng)調(diào)用的時候,其關(guān)聯(lián)的 P 可以被其他 M 搶占,保證了資源的利用率。多個 P 之間可以通過全局隊列均衡任務(wù),或者直接進行任務(wù)竊取,調(diào)度器還實現(xiàn)了基于時間片的搶占式調(diào)度,保證了調(diào)度的公平性。那么 IO 多路復用技術(shù)是如何與調(diào)度系統(tǒng)結(jié)合起來的呢?那就要看 Go 語言的 netpoller 模塊。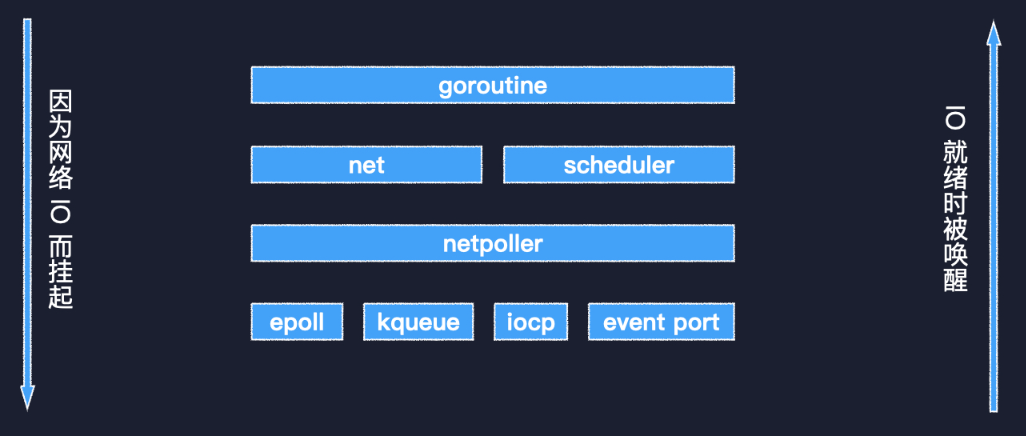 Go 語言 IO 多路復用模塊netpoller 封裝了具體平臺相關(guān)的技術(shù)細節(jié),Linux 的 epoll,BSD 的 kqueue,Windows 的 IO Completion Port,以及 Solaris 的 Event Port 等。在 netpoller 之上是標準庫的 net 包和調(diào)度器。最上層的 goroutine 可能會因為調(diào)用 net 包中的相關(guān)函數(shù)執(zhí)行網(wǎng)絡(luò) IO 而掛起,等到 IO 就緒后,被 netpoller 喚醒,進而得到調(diào)度執(zhí)行。一個 goroutine 是如何因為網(wǎng)絡(luò) IO 而被掛起的呢?
Go 語言 IO 多路復用模塊netpoller 封裝了具體平臺相關(guān)的技術(shù)細節(jié),Linux 的 epoll,BSD 的 kqueue,Windows 的 IO Completion Port,以及 Solaris 的 Event Port 等。在 netpoller 之上是標準庫的 net 包和調(diào)度器。最上層的 goroutine 可能會因為調(diào)用 net 包中的相關(guān)函數(shù)執(zhí)行網(wǎng)絡(luò) IO 而掛起,等到 IO 就緒后,被 netpoller 喚醒,進而得到調(diào)度執(zhí)行。一個 goroutine 是如何因為網(wǎng)絡(luò) IO 而被掛起的呢?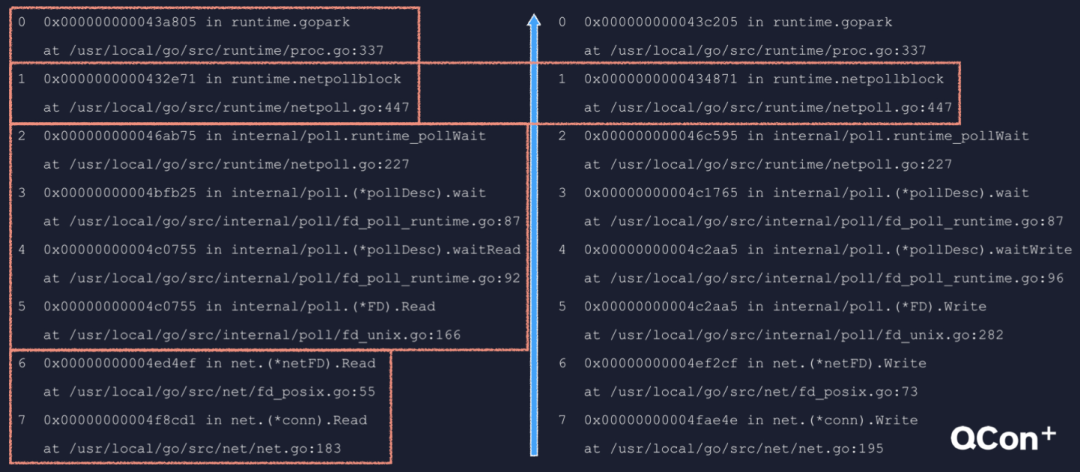 一個 goroutine 是如何因為網(wǎng)絡(luò) IO 被掛起的這里給出了兩個調(diào)用棧,左邊是因為調(diào)用網(wǎng)絡(luò)連接的 Read 方法而被掛起,右邊是因為調(diào)用 Write 方法而被掛起。可以根據(jù)不同的包把調(diào)用棧分為三個部分,net 包、internal/poll 包,最后是 runtime 包。兩個調(diào)用棧的層級完全一致,最終都是由 netpollblock 函數(shù)調(diào)用 gopark 掛起了當前 goroutine。我們就來看一下這個 netpollblock 的邏輯。
一個 goroutine 是如何因為網(wǎng)絡(luò) IO 被掛起的這里給出了兩個調(diào)用棧,左邊是因為調(diào)用網(wǎng)絡(luò)連接的 Read 方法而被掛起,右邊是因為調(diào)用 Write 方法而被掛起。可以根據(jù)不同的包把調(diào)用棧分為三個部分,net 包、internal/poll 包,最后是 runtime 包。兩個調(diào)用棧的層級完全一致,最終都是由 netpollblock 函數(shù)調(diào)用 gopark 掛起了當前 goroutine。我們就來看一下這個 netpollblock 的邏輯。 netpollblock 的邏輯第一個參數(shù)是個 pollDesc 類型的指針,這是 pollDesc 的結(jié)構(gòu)定義。其中 fd 就是 socket 文件描述符,rg 是指向等待讀事件的 goroutine 的指針。它有 4 種取值,0 表示沒有協(xié)程在等待,IO 也沒有就緒。pdReady 表示 IO 已經(jīng)就緒,pdWait 表示有個協(xié)程即將在這里掛起等待,最后一種取值是一個 goroutine 的地址,指向在這里等待的 goroutine。wg 與 rg 類似,只不過針對的是寫事件我們來看函數(shù)代碼,mode 參數(shù)可能為 r 或 w,gpp 相應的指向 rg 或 wg。如果 old 為 pdReady,那就是 IO 已經(jīng)就緒了,把它改成 0 也就是消費掉這個就緒狀態(tài),然后返回 true。如果 old 不為 pdReady,那就只應該是 0,否則那就是多個協(xié)程等待同一個 fd 的同一種事件,屬于嚴重錯誤。internal/poll 包中 FD 類型的相關(guān)方法,內(nèi)部通過鎖來避免這種問題。接下來的 CAS 操作,把狀態(tài)置為 pdWait,然后 gopark 掛起當前協(xié)程,netpollblockcommit 在掛起后會把 pdWait 改成 goroutine 的地址。最后,協(xié)程被喚醒后會來到這里,如果 old 等于 pdReady,說明是因為 IO 就緒而被喚醒,否則就應該是等待超時。總結(jié)一下,netpollblock 會被發(fā)起網(wǎng)絡(luò) IO 的協(xié)程調(diào)用,在 IO 已就緒的情況下不會掛起協(xié)程,若未就緒就掛起協(xié)程并把指針設(shè)置到 rg 或 wg 字段中。
netpollblock 的邏輯第一個參數(shù)是個 pollDesc 類型的指針,這是 pollDesc 的結(jié)構(gòu)定義。其中 fd 就是 socket 文件描述符,rg 是指向等待讀事件的 goroutine 的指針。它有 4 種取值,0 表示沒有協(xié)程在等待,IO 也沒有就緒。pdReady 表示 IO 已經(jīng)就緒,pdWait 表示有個協(xié)程即將在這里掛起等待,最后一種取值是一個 goroutine 的地址,指向在這里等待的 goroutine。wg 與 rg 類似,只不過針對的是寫事件我們來看函數(shù)代碼,mode 參數(shù)可能為 r 或 w,gpp 相應的指向 rg 或 wg。如果 old 為 pdReady,那就是 IO 已經(jīng)就緒了,把它改成 0 也就是消費掉這個就緒狀態(tài),然后返回 true。如果 old 不為 pdReady,那就只應該是 0,否則那就是多個協(xié)程等待同一個 fd 的同一種事件,屬于嚴重錯誤。internal/poll 包中 FD 類型的相關(guān)方法,內(nèi)部通過鎖來避免這種問題。接下來的 CAS 操作,把狀態(tài)置為 pdWait,然后 gopark 掛起當前協(xié)程,netpollblockcommit 在掛起后會把 pdWait 改成 goroutine 的地址。最后,協(xié)程被喚醒后會來到這里,如果 old 等于 pdReady,說明是因為 IO 就緒而被喚醒,否則就應該是等待超時。總結(jié)一下,netpollblock 會被發(fā)起網(wǎng)絡(luò) IO 的協(xié)程調(diào)用,在 IO 已就緒的情況下不會掛起協(xié)程,若未就緒就掛起協(xié)程并把指針設(shè)置到 rg 或 wg 字段中。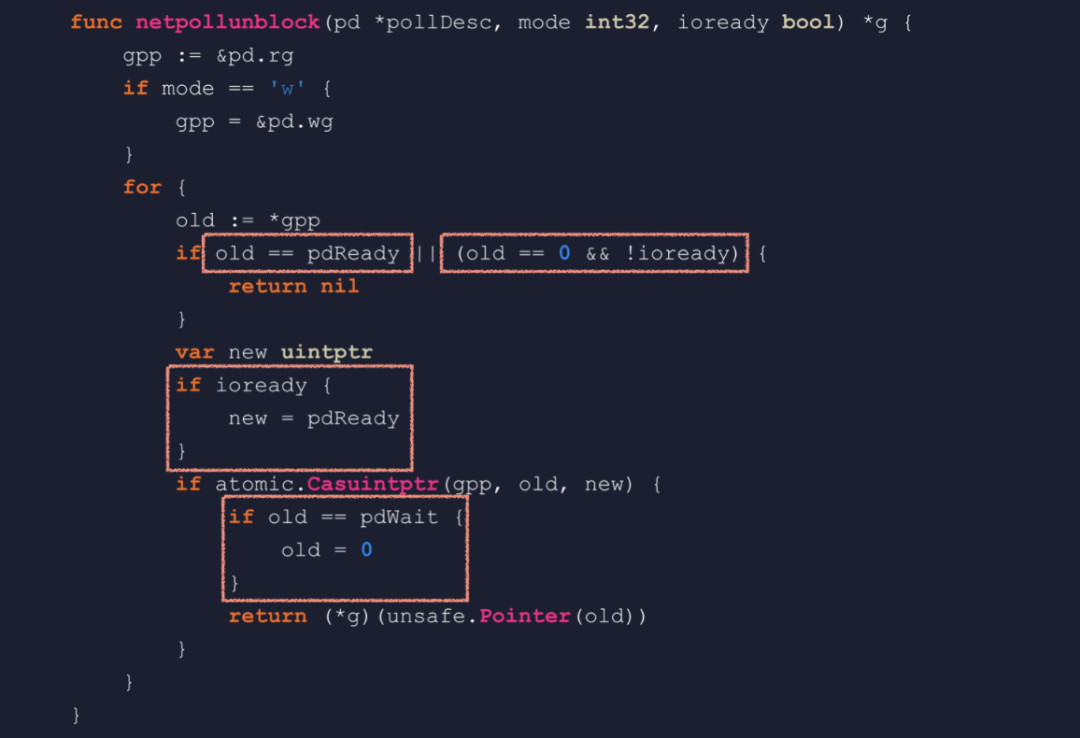 netpollunblock 函數(shù)當 IO 就緒時,netpoller 需要喚醒等待的協(xié)程,這就需要用到 netpollunblock 函數(shù)。這個函數(shù)會從 pollDesc 中取出等待 IO 的協(xié)程,并且根據(jù)觸發(fā)的 IO 事件來更新 rg 或 wg。如果 old 等于 pdReady,那就說明沒有協(xié)程在等待,并且已經(jīng)記錄了 IO 就緒狀態(tài),不需要更新,直接返回。old 等于 0 也是沒有協(xié)程在等待,ioready 為 false 說明 IO 事件未觸發(fā),不需要更新狀態(tài),直接返回。ioready 為 true 的話,就要把記錄的狀態(tài)改成 pdReady。來到這里時,old 可能為 0、pdWait 或一個有效的 g 指針,pdWait 不是一個合法的指針,所以返回之前需要置為 0,也就是 nil。總結(jié)一下,netpolllunblock 用來提取等待 IO 事件的協(xié)程的地址,并把已觸發(fā)的 IO 事件記錄到 rg 或 wg 中。那么,netpoll 是在哪里被調(diào)用的呢?
netpollunblock 函數(shù)當 IO 就緒時,netpoller 需要喚醒等待的協(xié)程,這就需要用到 netpollunblock 函數(shù)。這個函數(shù)會從 pollDesc 中取出等待 IO 的協(xié)程,并且根據(jù)觸發(fā)的 IO 事件來更新 rg 或 wg。如果 old 等于 pdReady,那就說明沒有協(xié)程在等待,并且已經(jīng)記錄了 IO 就緒狀態(tài),不需要更新,直接返回。old 等于 0 也是沒有協(xié)程在等待,ioready 為 false 說明 IO 事件未觸發(fā),不需要更新狀態(tài),直接返回。ioready 為 true 的話,就要把記錄的狀態(tài)改成 pdReady。來到這里時,old 可能為 0、pdWait 或一個有效的 g 指針,pdWait 不是一個合法的指針,所以返回之前需要置為 0,也就是 nil。總結(jié)一下,netpolllunblock 用來提取等待 IO 事件的協(xié)程的地址,并把已觸發(fā)的 IO 事件記錄到 rg 或 wg 中。那么,netpoll 是在哪里被調(diào)用的呢? netpoll在調(diào)度循環(huán)的 findrunnable 函數(shù),GC 關(guān)鍵點 pollWork 和 startTheWorldWithSema,以及監(jiān)控線程 sysmon 中,都會調(diào)用 netpoll。netpoll 會返回一個包含 IO 就緒協(xié)程的列表,然后這個列表會被 injectglist 函數(shù)添加到全局隊列中,保證了 IO 就緒的協(xié)程能夠及時得到調(diào)度。
netpoll在調(diào)度循環(huán)的 findrunnable 函數(shù),GC 關(guān)鍵點 pollWork 和 startTheWorldWithSema,以及監(jiān)控線程 sysmon 中,都會調(diào)用 netpoll。netpoll 會返回一個包含 IO 就緒協(xié)程的列表,然后這個列表會被 injectglist 函數(shù)添加到全局隊列中,保證了 IO 就緒的協(xié)程能夠及時得到調(diào)度。 新版推薦系統(tǒng)線上架構(gòu)部署架構(gòu)這是我們重構(gòu)后新版系統(tǒng)的部署架構(gòu),伴隨了一些基礎(chǔ)設(shè)施升級,服務(wù)間的依賴關(guān)系并沒有太大改變。但是因為基于 Go 語言的關(guān)系,服務(wù)的并發(fā)處理能力大大提升。接下來進入最后一部分,和你分享一個印象深刻的踩坑經(jīng)歷。我給起的名字呢,叫做一次線上 Redis 幻讀問題分析。這個幻讀是加了引號的,Redis 本身是不會幻讀的,出現(xiàn)問題是因為踩了 Go 的坑。一個后端服務(wù)中連接多個 Redis 是很常見的,我們的推薦服務(wù)也不例外。
新版推薦系統(tǒng)線上架構(gòu)部署架構(gòu)這是我們重構(gòu)后新版系統(tǒng)的部署架構(gòu),伴隨了一些基礎(chǔ)設(shè)施升級,服務(wù)間的依賴關(guān)系并沒有太大改變。但是因為基于 Go 語言的關(guān)系,服務(wù)的并發(fā)處理能力大大提升。接下來進入最后一部分,和你分享一個印象深刻的踩坑經(jīng)歷。我給起的名字呢,叫做一次線上 Redis 幻讀問題分析。這個幻讀是加了引號的,Redis 本身是不會幻讀的,出現(xiàn)問題是因為踩了 Go 的坑。一個后端服務(wù)中連接多個 Redis 是很常見的,我們的推薦服務(wù)也不例外。 一個后端服務(wù)中連接多個 Redis新版推薦系統(tǒng)上線后,效果卻出乎意料的不太理想。經(jīng)過全面的排查,發(fā)現(xiàn)從 Redis 中讀取特征數(shù)據(jù)時,時而能讀到時而讀不到,但是卻不是網(wǎng)絡(luò)通信錯誤造成的。從命令行查看,Redis 中的數(shù)據(jù)是一直存在的,這讓我們大惑不解。最后不得已在一臺機上抓包,通過分析網(wǎng)絡(luò)包,發(fā)現(xiàn)程序竟然連接了錯誤的 Redis。也就是本來數(shù)據(jù)在 1 號 Redis 中,程序卻跑到 3 號 Redis 去讀。這個發(fā)現(xiàn)真的令人非常震驚,我們立即重新 review 了一次代碼。
一個后端服務(wù)中連接多個 Redis新版推薦系統(tǒng)上線后,效果卻出乎意料的不太理想。經(jīng)過全面的排查,發(fā)現(xiàn)從 Redis 中讀取特征數(shù)據(jù)時,時而能讀到時而讀不到,但是卻不是網(wǎng)絡(luò)通信錯誤造成的。從命令行查看,Redis 中的數(shù)據(jù)是一直存在的,這讓我們大惑不解。最后不得已在一臺機上抓包,通過分析網(wǎng)絡(luò)包,發(fā)現(xiàn)程序竟然連接了錯誤的 Redis。也就是本來數(shù)據(jù)在 1 號 Redis 中,程序卻跑到 3 號 Redis 去讀。這個發(fā)現(xiàn)真的令人非常震驚,我們立即重新 review 了一次代碼。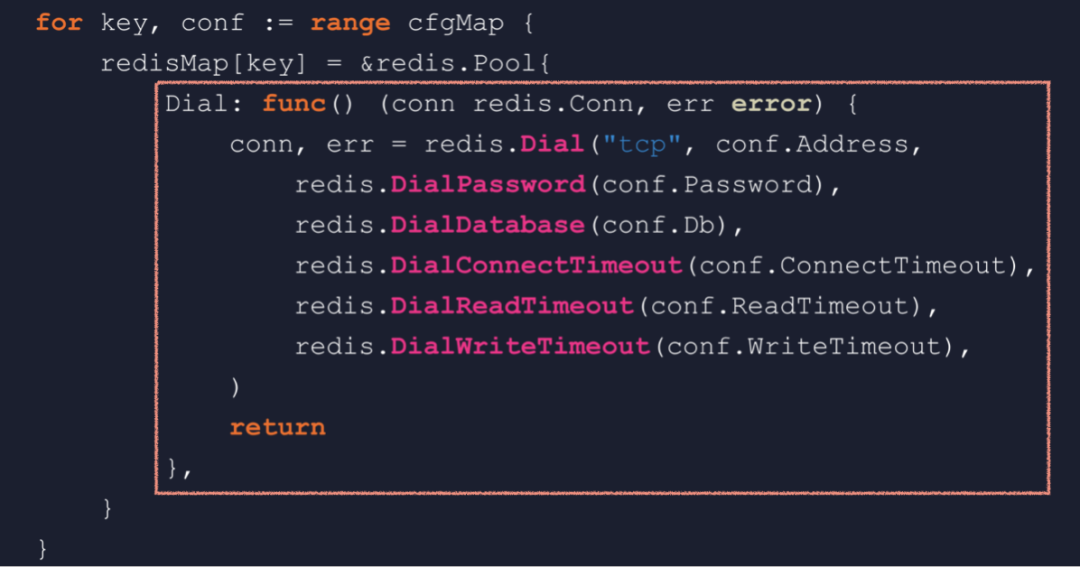 看似正常實則有問題的 Redis 連接池初始化代碼于是就發(fā)現(xiàn)了這樣一段看似正常,實則很有問題的代碼。這段代碼在程序初始化階段負責初始化 Redis 連接池,它會遍歷一個包含所有 Redis 配置的 map,然后逐個創(chuàng)建連接池,并且存放到另一個 map 中。如果已經(jīng)有了一定的 Go 應用經(jīng)驗,你可能一眼就會發(fā)現(xiàn)這里的循環(huán)套閉包問題。有很多人被這個問題給坑過,然而這底層到底是什么原理呢?要弄清這個問題,我們先要弄清楚閉包的廬山真面目。所謂閉包,通俗來講就是內(nèi)層函數(shù)使用了外層函數(shù)局部作用域中的變量,這段代碼就會返回一個閉包。我們通常會有個疑問,就是外層函數(shù)返回之后,棧幀也隨即釋放,變量 n 也就銷毀了。那么,內(nèi)層函數(shù)如何能夠合法的訪問變量 n 呢?
看似正常實則有問題的 Redis 連接池初始化代碼于是就發(fā)現(xiàn)了這樣一段看似正常,實則很有問題的代碼。這段代碼在程序初始化階段負責初始化 Redis 連接池,它會遍歷一個包含所有 Redis 配置的 map,然后逐個創(chuàng)建連接池,并且存放到另一個 map 中。如果已經(jīng)有了一定的 Go 應用經(jīng)驗,你可能一眼就會發(fā)現(xiàn)這里的循環(huán)套閉包問題。有很多人被這個問題給坑過,然而這底層到底是什么原理呢?要弄清這個問題,我們先要弄清楚閉包的廬山真面目。所謂閉包,通俗來講就是內(nèi)層函數(shù)使用了外層函數(shù)局部作用域中的變量,這段代碼就會返回一個閉包。我們通常會有個疑問,就是外層函數(shù)返回之后,棧幀也隨即釋放,變量 n 也就銷毀了。那么,內(nèi)層函數(shù)如何能夠合法的訪問變量 n 呢? 閉包的廬山真面目——閉包對象我們通過反編譯來看看到底是怎么回事,看到 runtime.newobject 函數(shù),這就說明在堆上分配了一個對象。再根據(jù)后面幾條指令,可以推導出這個對象的結(jié)構(gòu)。第一個字段 F,就是內(nèi)層函數(shù)的地址;第二個字段 n,其實是變量 n 的副本。外層函數(shù)最終返回的,是這個對象的地址,我們就稱它為閉包對象。runtime 中的 funcval 結(jié)構(gòu)描述了一個閉包對象的結(jié)構(gòu),第一個字段永遠是函數(shù)地址,后面是捕獲列表,閉包會捕獲它用到的變量。那么,內(nèi)層函數(shù)如何得知被捕獲變量的地址呢?我們再反編譯一下內(nèi)層函數(shù),返現(xiàn)編譯器會使用 DX 寄存器傳遞閉包對象地址,類似于 C++ 的 thiscall。好了,我們現(xiàn)在對閉包的原理有了最基本的了解。
閉包的廬山真面目——閉包對象我們通過反編譯來看看到底是怎么回事,看到 runtime.newobject 函數(shù),這就說明在堆上分配了一個對象。再根據(jù)后面幾條指令,可以推導出這個對象的結(jié)構(gòu)。第一個字段 F,就是內(nèi)層函數(shù)的地址;第二個字段 n,其實是變量 n 的副本。外層函數(shù)最終返回的,是這個對象的地址,我們就稱它為閉包對象。runtime 中的 funcval 結(jié)構(gòu)描述了一個閉包對象的結(jié)構(gòu),第一個字段永遠是函數(shù)地址,后面是捕獲列表,閉包會捕獲它用到的變量。那么,內(nèi)層函數(shù)如何得知被捕獲變量的地址呢?我們再反編譯一下內(nèi)層函數(shù),返現(xiàn)編譯器會使用 DX 寄存器傳遞閉包對象地址,類似于 C++ 的 thiscall。好了,我們現(xiàn)在對閉包的原理有了最基本的了解。 何時捕獲值,何時捕獲地址還是這段代碼,我們已經(jīng)知道它的閉包對象是這樣的,捕獲了 n 的值。我們把這段代碼稍作改動,返回之前修改一下變量 n,相應的閉包對象就變成了這個樣子,捕獲了 n 的地址。所以我們簡單地得出結(jié)論,變量無改動,捕獲值,變量有改動,捕獲地址。這個改動不僅限于內(nèi)層函數(shù)中,前面的循環(huán)套閉包問題,就是因為外層循環(huán)不斷改變循環(huán)變量的值,造成閉包捕獲地址。從語義角度來講,閉包本應該總是捕獲變量地址,但是這樣會造成更多的變量逃逸。所以,作為一種優(yōu)化,編譯器在邏輯允許的條件下,改為捕獲值。最后,再跟你介紹一種方法,可以直接看到閉包對象的結(jié)構(gòu)。
何時捕獲值,何時捕獲地址還是這段代碼,我們已經(jīng)知道它的閉包對象是這樣的,捕獲了 n 的值。我們把這段代碼稍作改動,返回之前修改一下變量 n,相應的閉包對象就變成了這個樣子,捕獲了 n 的地址。所以我們簡單地得出結(jié)論,變量無改動,捕獲值,變量有改動,捕獲地址。這個改動不僅限于內(nèi)層函數(shù)中,前面的循環(huán)套閉包問題,就是因為外層循環(huán)不斷改變循環(huán)變量的值,造成閉包捕獲地址。從語義角度來講,閉包本應該總是捕獲變量地址,但是這樣會造成更多的變量逃逸。所以,作為一種優(yōu)化,編譯器在邏輯允許的條件下,改為捕獲值。最后,再跟你介紹一種方法,可以直接看到閉包對象的結(jié)構(gòu)。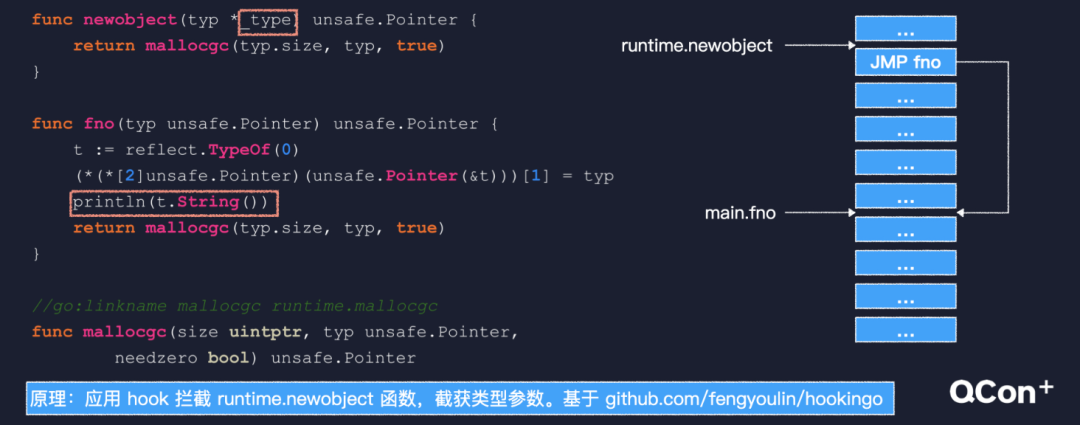 將閉包逮個正著我們已經(jīng)知道,在堆上分配閉包對象會調(diào)用 newobject 函數(shù),該函數(shù)有個 type 參數(shù),這個 type 類型在 Go 語言的類型系統(tǒng)中用來描述一種數(shù)據(jù)類型,是反射得以實現(xiàn)的基礎(chǔ)。我們 hook 技術(shù)攔截 newobject 函數(shù),就可以獲得這個參數(shù)。Hook 技術(shù),就是運行階段修改函數(shù)代碼,把入口處替換為一條無條件跳轉(zhuǎn)指令,跳轉(zhuǎn)到一個我們給出的函數(shù)。在該函數(shù)里用反射,就可以打印出閉包對象的結(jié)構(gòu)。1.多路復用技術(shù)是實現(xiàn)高性能網(wǎng)絡(luò) IO 的基礎(chǔ),但是事件循環(huán)不易于編程;2.Go 基于協(xié)程和 netpoller 把事件循環(huán)封裝在 runtime內(nèi)部,編碼方式對開發(fā)者友好;3.GMP 調(diào)度模型在多核 CPU 上有很好的擴展性,能充分發(fā)揮系統(tǒng)的計算能力;4.閉包的捕獲列表會盡量捕獲值,只有變量會被修改時捕獲地址。最后,如果我再做一遍這個項目,我可能會從兩個角度上再優(yōu)化一下:1.要落實系統(tǒng)、全面的測試。尤其在進行重構(gòu)的時候,我們遇到過的很多問題,都是因為測試不完善,或者測試環(huán)境不能模擬真實環(huán)境所致。很多本來是可以避免的,所以落實系統(tǒng)、全面的測試真的很有必要。2.避免過度設(shè)計。我們從一入行就被告知,寫的程序要靈活易于擴展。長此以往之后,很多人實際上會做過度設(shè)計。反思我自己也有這種問題,代碼中的各種設(shè)計模式,還有服務(wù)模塊的拆分等等。不僅造成了較高的維護成本,還會在一定程度上影響性能。所以一定要結(jié)合實際需求進行設(shè)計。
將閉包逮個正著我們已經(jīng)知道,在堆上分配閉包對象會調(diào)用 newobject 函數(shù),該函數(shù)有個 type 參數(shù),這個 type 類型在 Go 語言的類型系統(tǒng)中用來描述一種數(shù)據(jù)類型,是反射得以實現(xiàn)的基礎(chǔ)。我們 hook 技術(shù)攔截 newobject 函數(shù),就可以獲得這個參數(shù)。Hook 技術(shù),就是運行階段修改函數(shù)代碼,把入口處替換為一條無條件跳轉(zhuǎn)指令,跳轉(zhuǎn)到一個我們給出的函數(shù)。在該函數(shù)里用反射,就可以打印出閉包對象的結(jié)構(gòu)。1.多路復用技術(shù)是實現(xiàn)高性能網(wǎng)絡(luò) IO 的基礎(chǔ),但是事件循環(huán)不易于編程;2.Go 基于協(xié)程和 netpoller 把事件循環(huán)封裝在 runtime內(nèi)部,編碼方式對開發(fā)者友好;3.GMP 調(diào)度模型在多核 CPU 上有很好的擴展性,能充分發(fā)揮系統(tǒng)的計算能力;4.閉包的捕獲列表會盡量捕獲值,只有變量會被修改時捕獲地址。最后,如果我再做一遍這個項目,我可能會從兩個角度上再優(yōu)化一下:1.要落實系統(tǒng)、全面的測試。尤其在進行重構(gòu)的時候,我們遇到過的很多問題,都是因為測試不完善,或者測試環(huán)境不能模擬真實環(huán)境所致。很多本來是可以避免的,所以落實系統(tǒng)、全面的測試真的很有必要。2.避免過度設(shè)計。我們從一入行就被告知,寫的程序要靈活易于擴展。長此以往之后,很多人實際上會做過度設(shè)計。反思我自己也有這種問題,代碼中的各種設(shè)計模式,還有服務(wù)模塊的拆分等等。不僅造成了較高的維護成本,還會在一定程度上影響性能。所以一定要結(jié)合實際需求進行設(shè)計。最后送你一句話,知其所以然,磨刀不誤砍柴工。
推薦閱讀:
世界的真實格局分析,地球人類社會底層運行原理
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
華為干部與人才發(fā)展手冊(附PPT)
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
【中臺實踐】華為大數(shù)據(jù)中臺架構(gòu)分享.pdf
華為的數(shù)字化轉(zhuǎn)型方法論
華為如何實施數(shù)字化轉(zhuǎn)型(附PPT)
超詳細280頁Docker實戰(zhàn)文檔!開放下載
華為大數(shù)據(jù)解決方案(PPT)
