
7張圖揭曉RocketMQ存儲設(shè)計的精髓
RocketMQ作為一款基于磁盤存儲的中間件,具有無限積壓能力,并提供高吞吐、低延遲的服務(wù)能力,其最核心的部分必然是它優(yōu)雅的存儲設(shè)計。本文摘自《RocketMQ技術(shù)內(nèi)幕》第二版,為你揭曉RocketMQ存儲設(shè)計的精髓。
1、存儲概述
RocketMQ存儲的文件主要包括Commitlog文件、ConsumeQueue文件、Index文件。
RocketMQ將所有主題的消息存儲在同一個文件中,確保消息發(fā)送時按順序?qū)懳募M最大能力確保消息發(fā)送的高可用性與高吞吐量。
但消息中間件一般都是基于主題的訂閱與發(fā)布模式,消息消費時必須按照主題進行篩選消息,顯然從Commitlog文件中按照topic去篩選消息會變得及其低效,為了提高根據(jù)主題檢索消息的效率,RocketMQ引入了ConsumeQueue文件,俗稱消費隊列文件。
關(guān)系型數(shù)據(jù)庫可以按照字段屬性進行記錄檢索,作為一款主要面向業(yè)務(wù)開發(fā)的消息中間件,RocketMQ也提供了基于消息屬性的檢索能力,底層的核心設(shè)計理念是為Commitlog文件建立哈希索引,并存儲在Index文件中。
在RocketMQ中順序?qū)懭氲紺ommitlog文件后,ConsumeQueue與Index文件都是異步構(gòu)建的,其數(shù)據(jù)流向圖如下: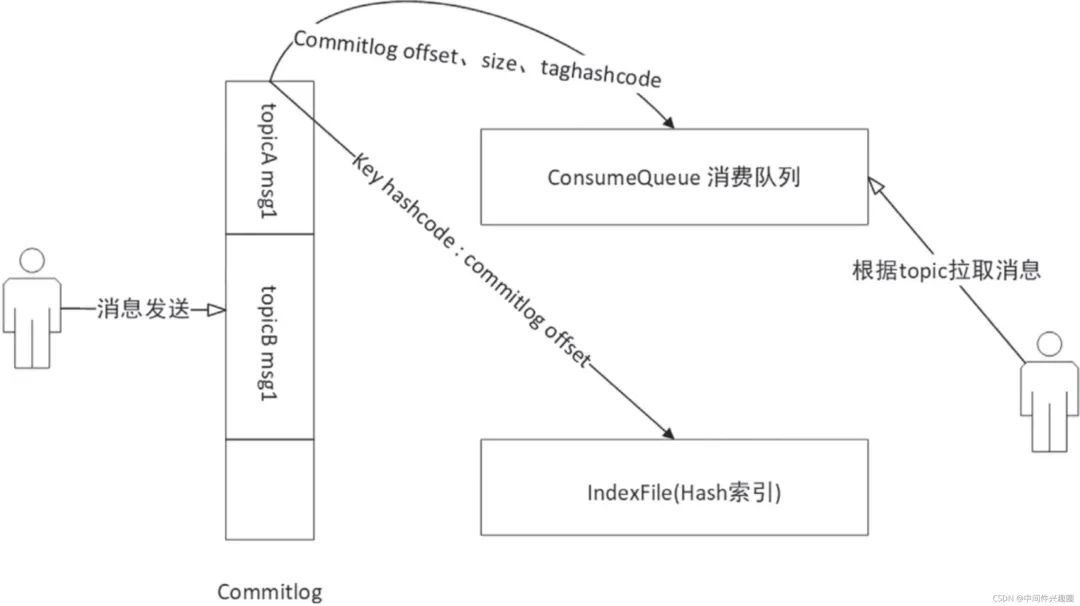
2、存儲文件組織方式
RocketMQ在消息寫入過程中追求極致的磁盤順序?qū)憽K兄黝}的消息全部寫入一個文件,即Commitlog文件。所有消息按抵達順序依次追加到文件中,消息一旦寫入,不支持修改。Commitlog文件的具體布局如下圖所示: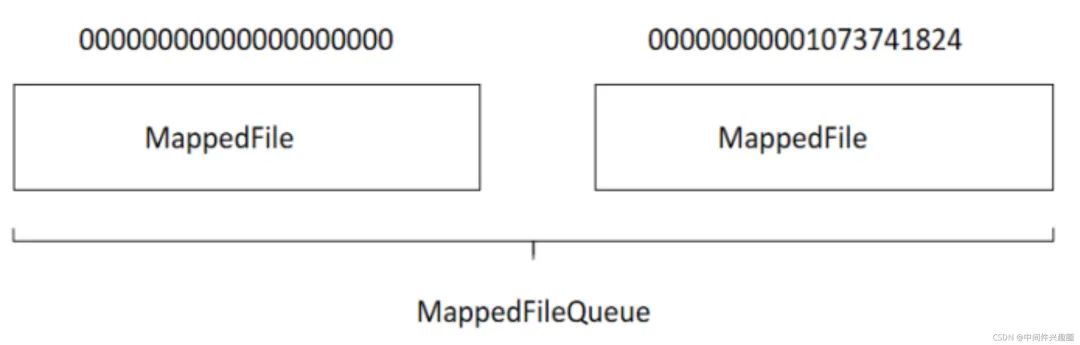 基于文件編程與基于內(nèi)存編程有一個很大的不同是在基于內(nèi)存的編程模式中我們有現(xiàn)成的數(shù)據(jù)結(jié)構(gòu),例如 List、HashMap,對數(shù)據(jù)的讀寫非常方便,那么一條一條消息存入文件Commitlog后,該如何查找呢?
基于文件編程與基于內(nèi)存編程有一個很大的不同是在基于內(nèi)存的編程模式中我們有現(xiàn)成的數(shù)據(jù)結(jié)構(gòu),例如 List、HashMap,對數(shù)據(jù)的讀寫非常方便,那么一條一條消息存入文件Commitlog后,該如何查找呢?
正如關(guān)系型數(shù)據(jù)會為每一條數(shù)據(jù)引入一個ID字段,在基于文件編程的模型中,也會為一條消息引入一個身份標志:消息物理偏移量,即消息存儲在文件的起始位置。
正是有了物理偏移量的概念,Commitlog的文件名命名也是極具技巧性,使用了存儲在該文件的第一條消息在整個Commitlog文件組中的偏移量來命名,例如第一個 Commitlog文件為 0000000000000000000,第二個文件為00000000001073741824,然后依次類推。
這樣做的好處是給出任意一個消息的物理偏移量,例如消息偏移量為 73741824,可以通過二分法進行查找,快速定位這個文件在第一個文件中,然后用消息的物理偏移量減去該文件的名稱所得到的差值,就是在該文件中的絕對地址。
Commitlog文件的設(shè)計理念是追求極致的消息寫,但我們知道消息消費模型是基于主題的訂閱機制,即一個消費組是消費特定主題的消息。如果根據(jù)主題從commitlog文件中檢索消息,我們會發(fā)現(xiàn)這絕不是一個好主意,只能從文件的第一條消息逐條檢索,其性能可想而知,故為了解決基于topic的消息檢索問題,RocketMQ引入了consumequeue文件,consumequeue的結(jié)構(gòu)如下圖所示。 ConsumeQueue文件是消息消費隊列文件,是Commitlog文件基于Topic的索引文件,主要用于消費者根據(jù)Topic消費消息,其組織方式為/topic/queue,同一個隊列中存在多個文件。
ConsumeQueue文件是消息消費隊列文件,是Commitlog文件基于Topic的索引文件,主要用于消費者根據(jù)Topic消費消息,其組織方式為/topic/queue,同一個隊列中存在多個文件。
Consumequeue的設(shè)計極具技巧,每個條目長度固定(8字節(jié)commitlog物理偏移量、4字節(jié)消息長度、8字節(jié)tag hashcode)。
這里不是存儲tag的原始字符串,而選擇存儲hashcode,目的就是確保每個條目的長度固定,可以使用訪問類似數(shù)組下標的方式快速定位條目,極大地提高了ConsumeQueue文件的讀取性能。
試想一下,消息消費者根據(jù)topic、消息消費進度(consumeuqe邏輯偏移量),即第幾個Consumeque條目,這樣的消費進度去訪問消息的方法為使用邏輯偏移量logicOffset * 20即可找到該條目的起始偏移量(consumequeue文件中的偏移量),然后讀取該偏移量后20個字節(jié)即得到一個條目,無須遍歷consumequeue文件。
RocketMQ與Kafka相比具有一個強大的優(yōu)勢,就是支持按消息屬性檢索消息,引入consumequeue文件解決了基于topic查找的問題,但如果想基于消息的某一個屬性查找消息,consumequeue文件就無能為力了。
RocketMQ引入了Index索引文件,實現(xiàn)基于文件的哈希索引。IndexFile的文件存儲結(jié)構(gòu)如下圖所示: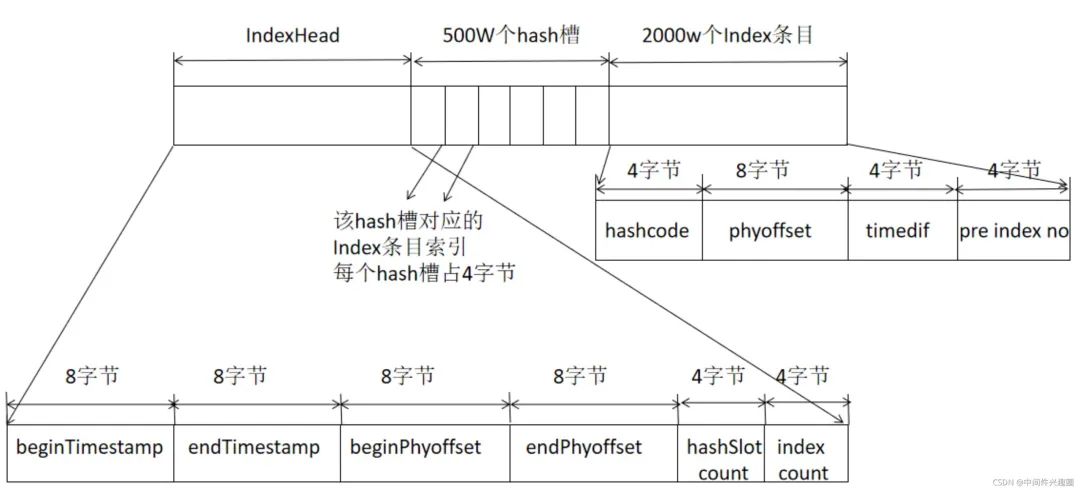 IndexFile文件基于物理磁盤文件實現(xiàn)Hash索引。其文件由40字節(jié)的文件頭、500萬個哈希槽,每個哈希槽4個字節(jié),最后由2000萬個Index條目,每個條目由20個字節(jié)構(gòu)成,分別為4字節(jié)索引key的hashcode、8字節(jié)消息物理偏移量、4字節(jié)時間戳、4字節(jié)的前一個Index條目(哈希沖突的鏈表結(jié)構(gòu))。
IndexFile文件基于物理磁盤文件實現(xiàn)Hash索引。其文件由40字節(jié)的文件頭、500萬個哈希槽,每個哈希槽4個字節(jié),最后由2000萬個Index條目,每個條目由20個字節(jié)構(gòu)成,分別為4字節(jié)索引key的hashcode、8字節(jié)消息物理偏移量、4字節(jié)時間戳、4字節(jié)的前一個Index條目(哈希沖突的鏈表結(jié)構(gòu))。
即建立了索引Key的hashcode與物理偏移量的映射關(guān)系,根據(jù)key先快速定義到commitlog文件,關(guān)于Hash索引具體到工作機制,可以參考《RocketMQ技術(shù)內(nèi)幕》第二版4.5.3節(jié)的詳細介紹。
3、順序?qū)?/span>
基于磁盤的讀寫,提高其寫入性能的另外一個設(shè)計原理是磁盤順序?qū)?/strong>。
磁盤順序?qū)憦V泛用在基于文件的存儲模型中,大家不妨思考一下 MySQL Redo 日志的引入目的,我們知道在 MySQL InnoDB 的存儲引擎中,會有一個內(nèi)存 Pool,用來緩存磁盤的文件塊,當更新語句將數(shù)據(jù)修改后,會首先在內(nèi)存中進行修改,然后將變更寫入到 redo 文件(刷寫到磁盤),然后定時將InnoDB內(nèi)存池中的數(shù)據(jù)刷寫到磁盤。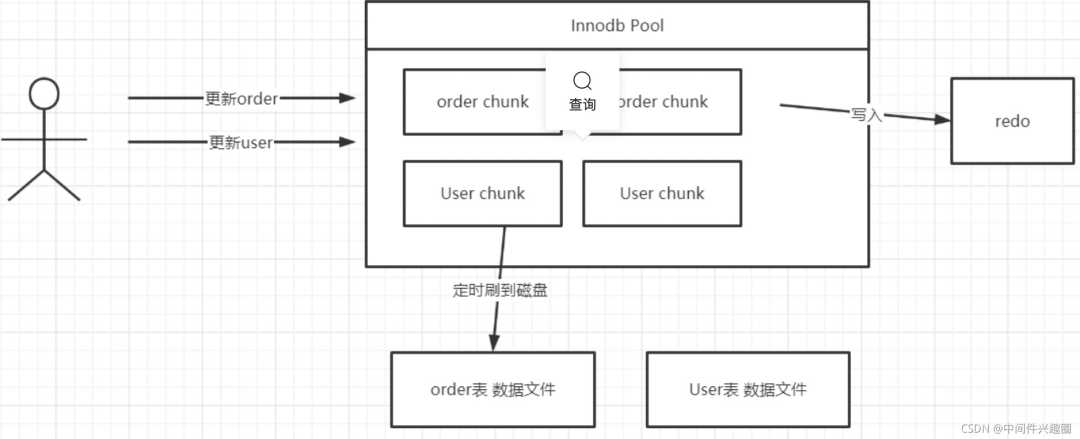 為什么不一有數(shù)據(jù)變更,就直接更新到指定的數(shù)據(jù)文件中呢?以MySQL InnoDB中一個庫存在上千張,每一個張的數(shù)據(jù)會使用單獨的文件存儲,如果每一個表的數(shù)據(jù)發(fā)生變更,就刷寫到磁盤,就會存在大量的隨機寫入,性能無法得到提升,故引入一個redo文件,順序?qū)憆edo文件,從表面上多了一步刷盤操作,但由于是順序?qū)懀啾入S機寫,帶來的性能提升是非常顯著的。
為什么不一有數(shù)據(jù)變更,就直接更新到指定的數(shù)據(jù)文件中呢?以MySQL InnoDB中一個庫存在上千張,每一個張的數(shù)據(jù)會使用單獨的文件存儲,如果每一個表的數(shù)據(jù)發(fā)生變更,就刷寫到磁盤,就會存在大量的隨機寫入,性能無法得到提升,故引入一個redo文件,順序?qū)憆edo文件,從表面上多了一步刷盤操作,但由于是順序?qū)懀啾入S機寫,帶來的性能提升是非常顯著的。
4、內(nèi)存映射機制
雖然基于磁盤的順序?qū)懣梢詷O大提高IO的寫效率,但如果基于文件的存儲采用常規(guī)的JAVA文件操作API,例如 FileOutputStream等,其性能提升會很有限,RocketMQ引入了內(nèi)存映射,將磁盤文件映射到內(nèi)存中,以操作內(nèi)存的方式操作磁盤,性能又提升了一個檔次。
在JAVA中可通過FileChannel的map方法創(chuàng)建內(nèi)存映射文件。
在Linux服務(wù)器中由該方法創(chuàng)建的文件使用的就是操作系統(tǒng)的pagecache,即頁緩存。
Linux操作系統(tǒng)中的內(nèi)存使用策略時會盡可能地利用機器的物理內(nèi)存,并常駐內(nèi)存中,就是所謂的頁緩存。在操作系統(tǒng)的內(nèi)存不夠的情況下,采用緩存置換算法,例如LRU將不常用的頁緩存回收,即操作系統(tǒng)會自動管理這部分內(nèi)存。
如果RocketMQ Broker進程異常退出,存儲在頁緩存中的數(shù)據(jù)并不會丟失,操作系統(tǒng)會定時將頁緩存中的數(shù)據(jù)持久化到磁盤,做到數(shù)據(jù)安全可靠。不過如果是機器斷電等異常情況,存儲在頁緩存中的數(shù)據(jù)就有可能丟失。
5、靈活多變的刷盤策略
有了順序?qū)懞蛢?nèi)存映射的加持,RocketMQ的寫入性能得到了極大的保證,但凡事都有利弊,引入了內(nèi)存映射和頁緩存機制,消息會先寫入到頁緩存,此時消息并沒有真正持久化到磁盤。那么broker收到客戶端的消息發(fā)送后,是存儲到頁緩存中就直接返回成功,還是要持久化到磁盤中才返回成功呢?
這是一個“艱難”的抉擇,是在性能與消息可靠性方面進行權(quán)衡。為此,RocketMQ提供了多種策略:同步刷盤、異步刷盤。
5.1 同步刷盤
同步刷盤在RocketMQ的實現(xiàn)中成為組提交,并不是每一條消息都必須刷盤。其設(shè)計理念如圖所示: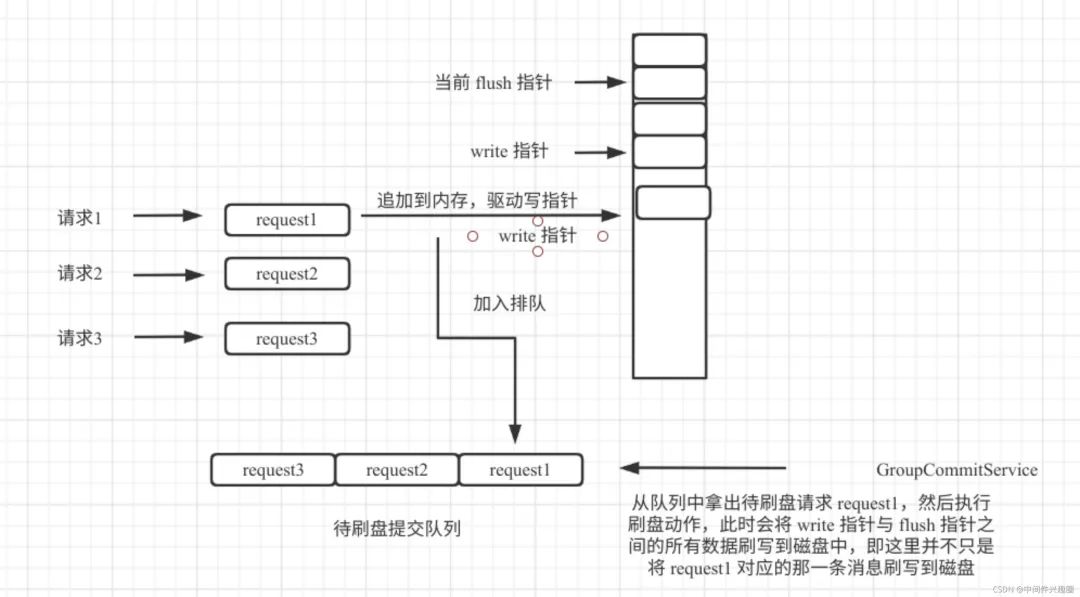 采用同步刷盤,每一個線程將數(shù)據(jù)追到到內(nèi)存后,并向刷盤線程提交刷盤請求,然后會阻塞;刷盤線程從任務(wù)隊列中獲取一個任務(wù),然后觸發(fā)一次刷盤,但并不只刷與請求相關(guān)的消息,而是會直接將內(nèi)存中待刷盤的所有消息一次批量刷盤,然后就可以喚醒一組請求線程,實現(xiàn)組刷盤。
采用同步刷盤,每一個線程將數(shù)據(jù)追到到內(nèi)存后,并向刷盤線程提交刷盤請求,然后會阻塞;刷盤線程從任務(wù)隊列中獲取一個任務(wù),然后觸發(fā)一次刷盤,但并不只刷與請求相關(guān)的消息,而是會直接將內(nèi)存中待刷盤的所有消息一次批量刷盤,然后就可以喚醒一組請求線程,實現(xiàn)組刷盤。
5.2 異步刷盤
同步刷盤的優(yōu)點是能保證消息不丟失,即向客戶端返回成功就代表這條消息已被持久化到磁盤,即消息非常可靠,但這是以犧牲寫入響應(yīng)延遲性能為代價的,由于RocketMQ的消息是先寫入 pagecache,故消息丟失的可能性較小,如果能容忍一定幾率的消息丟失,可以考慮使用異步刷盤。
異步刷盤指的是broker將消息存儲到pagecache后就立即返回成功,然后開啟一個異步線程定時執(zhí)行FileChannel的forece方法,將內(nèi)存中的數(shù)據(jù)定時刷寫到磁盤,默認間隔為500ms。
6、內(nèi)存級讀寫分離
RocketMQ為了降低pagecache的使用壓力引入了transientStorePoolEnable機制,即內(nèi)存級別的讀寫分離機制。
默認情況下RocketMQ將消息寫入pagecache,消息消費時從pagecache中讀取,這樣在高并發(fā)時pagecache的壓力會比較大,容易出現(xiàn)瞬時broker busy,故RocketMQ還引入了transientStorePoolEnable,將消息先寫入堆外內(nèi)存并立即返回,然后異步將堆外內(nèi)存中的數(shù)據(jù)提交到pagecache,再異步刷盤到磁盤中。其工作機制如下圖所示: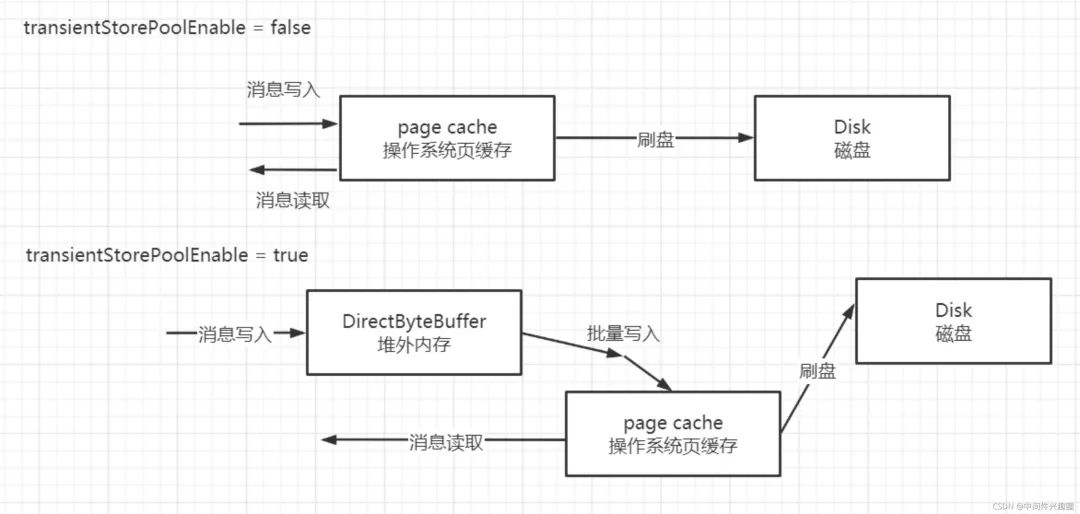 消息在消費讀取時不會嘗試從堆外內(nèi)存中讀,而是從pagecache中讀取,這樣就形成了內(nèi)存級別的讀寫分離,即消息寫入時主要面對堆外內(nèi)存,而讀消息時主要面對pagecache。
消息在消費讀取時不會嘗試從堆外內(nèi)存中讀,而是從pagecache中讀取,這樣就形成了內(nèi)存級別的讀寫分離,即消息寫入時主要面對堆外內(nèi)存,而讀消息時主要面對pagecache。
該方案的優(yōu)點是消息是直接寫入堆外內(nèi)存,然后異步寫入pagecache。相比每條消息追加直接寫入pagechae,其最大的優(yōu)勢是將消息寫入pagecache操作批量化。
該方案的缺點是如果由于某些意外操作導(dǎo)致Broker進程異常退出,那么存儲在堆外內(nèi)存的數(shù)據(jù)會丟失,但如果是放入pagecache,broker異常退出并不會丟失消息。
更多有關(guān)RocketMQ的精彩內(nèi)容建議關(guān)注新上市的《RocketMQ技術(shù)內(nèi)幕:RocketMQ架構(gòu)設(shè)計與實現(xiàn)原理(第2版)》
