
為什么Transformer適合做多模態(tài)任務(wù)?
提問:最近在學(xué)習(xí)Attention和Transformer相關(guān)的技術(shù),看到很多資料說Transformer適合做多模態(tài)任務(wù),看了模型結(jié)構(gòu)中不知道哪里體現(xiàn)出了這一點(diǎn)?
蠟筆小熊貓(復(fù)旦大學(xué)?計(jì)算機(jī))回答:
這個(gè)問題其實(shí)應(yīng)該從兩個(gè)方面回答:
第一個(gè)是任務(wù)方面,之前的多模態(tài)任務(wù)是怎么做的,為什么現(xiàn)在大家會(huì)轉(zhuǎn)向Transformer做多模態(tài)任務(wù)?
在Transformer,特別是Vision Transformer出來打破CV和NLP的模型壁壘之前,CV的主要模型是CNN,NLP的主要模型是RNN,那個(gè)時(shí)代的多模態(tài)任務(wù),主要就是通過CNN拿到圖像的特征,RNN拿到文本的特征,然后做各種各樣的Attention與concat過分類器,這個(gè)大家可以從我文章欄的一篇ACL論文解說《Writing by Memorizing: Hierarchical Retrieval-based Medical Report Generation》略窺一二,使用這種方式構(gòu)造出來的多模態(tài)模型會(huì)大量依賴各種模型輸出的特征進(jìn)行多重操作,pipeline巨大并且復(fù)雜,很難形成一個(gè)end2end的方便好用的模型
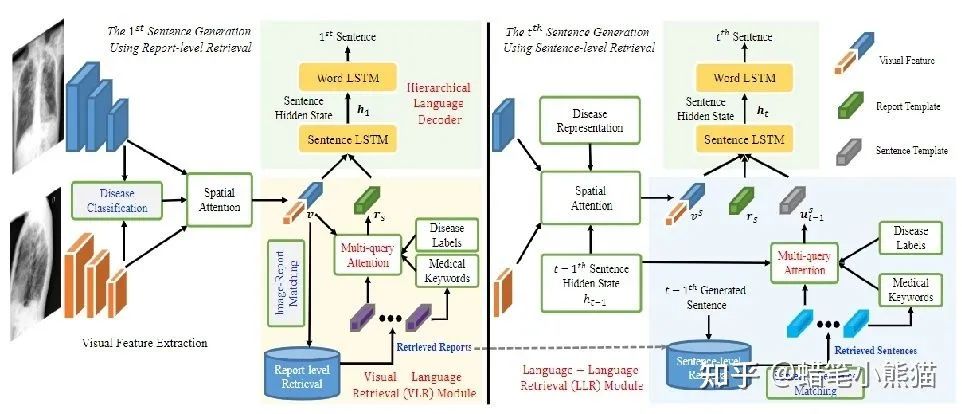
但是Transformer,特別是ViT(Vision Transformer)出來之后,這個(gè)模型壁壘就被打破了,人們發(fā)現(xiàn)原來對(duì)付圖像和文本都可以使用同一個(gè)模型,那么處理多模態(tài)的任務(wù),就直接使用把兩種模態(tài)輸進(jìn)這個(gè)模型,然后接上自己的下游任務(wù),省時(shí)省力end2end,還能把精力更多放在任務(wù)而不是特征如何concat和attention上
第二個(gè)是模型原理層面,為什么Transformer可以做圖像也可以做文本,為什么它適合做一個(gè)跨模態(tài)的任務(wù)?
說的直白一點(diǎn),因?yàn)門ransformer中的Self-Attetion機(jī)制很強(qiáng)大,使得Transformer是一個(gè)天然強(qiáng)力的一維長序列特征提取器,而所有模態(tài)的信息都可以合在一起變成一維長序列被Transformer處理

attention本身就是很強(qiáng)大的,已經(jīng)熱了很多年了,而self-attention更是使得Transformer的大規(guī)模pretrain成為可能的重要原因
self-attention的序列特征提取功能其實(shí)是非常強(qiáng)大的,如果你用CNN,那么一次提取的特征只有一個(gè)限定大小的矩陣,如果在句子里做TextCNN,那就是提取一小段文字的特征,最后匯聚到一起;如果做RNN,那么會(huì)產(chǎn)生長程依賴問題,當(dāng)句子 太長最后RNN會(huì)把前面的東西都忘掉
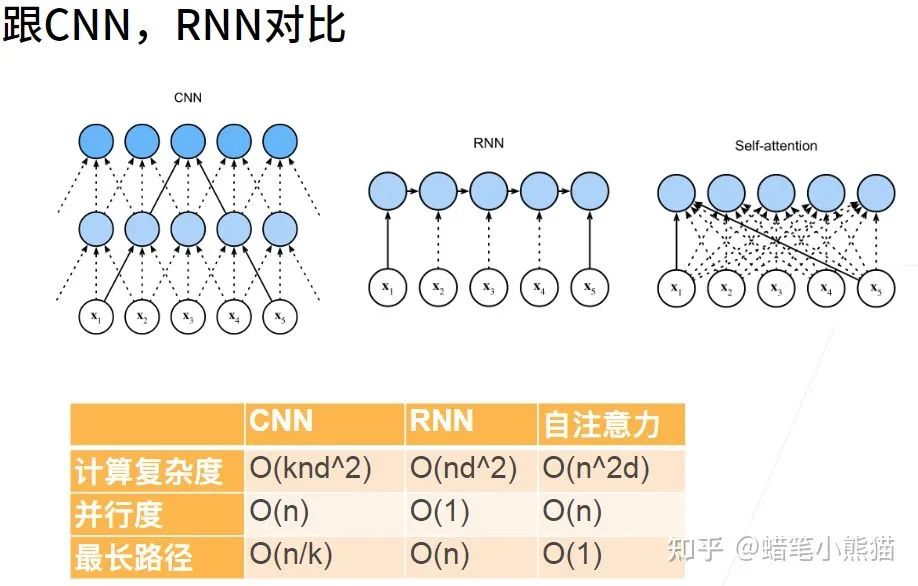
從上圖沐神的課件可以看到,面對(duì)同樣的長序列處理問題,self-attention既消除了RNN的并行度和遺忘問題,也消除了CNN的最長路徑問題
然而self-attention的本質(zhì)就是對(duì)每個(gè)token,計(jì)算這個(gè)token相對(duì)于這個(gè)句子其他所有token的特征再concat到一起,無視長度,輸入有多長,特征就提多遠(yuǎn)
那么如果傳入的不是句子,而是普通一維序列(也就是一個(gè)數(shù)組)呢?那就是對(duì)序列的每個(gè)點(diǎn)(數(shù)組的每個(gè)值),計(jì)算這個(gè)點(diǎn)與序列里其他點(diǎn)的所有特征,這也是Vision Transformer成功的原因,既然是對(duì)序列建模,我就把一張圖片做成序列不就完了?一整張圖片的像素矩陣直接平鋪?zhàn)兂尚蛄袕?fù)雜度太大,那就切大塊一點(diǎn)唄(反正CNN也是這種思想,卷積核獲得的是局部特征,換個(gè)角度來說也是特定patch的特征),ViT就把一張圖片做成了16個(gè)patch然后加上對(duì)應(yīng)的position embedding(就是割成小方塊變成token向量塞進(jìn)去加上patch對(duì)應(yīng)圖片原始位置的標(biāo)號(hào))
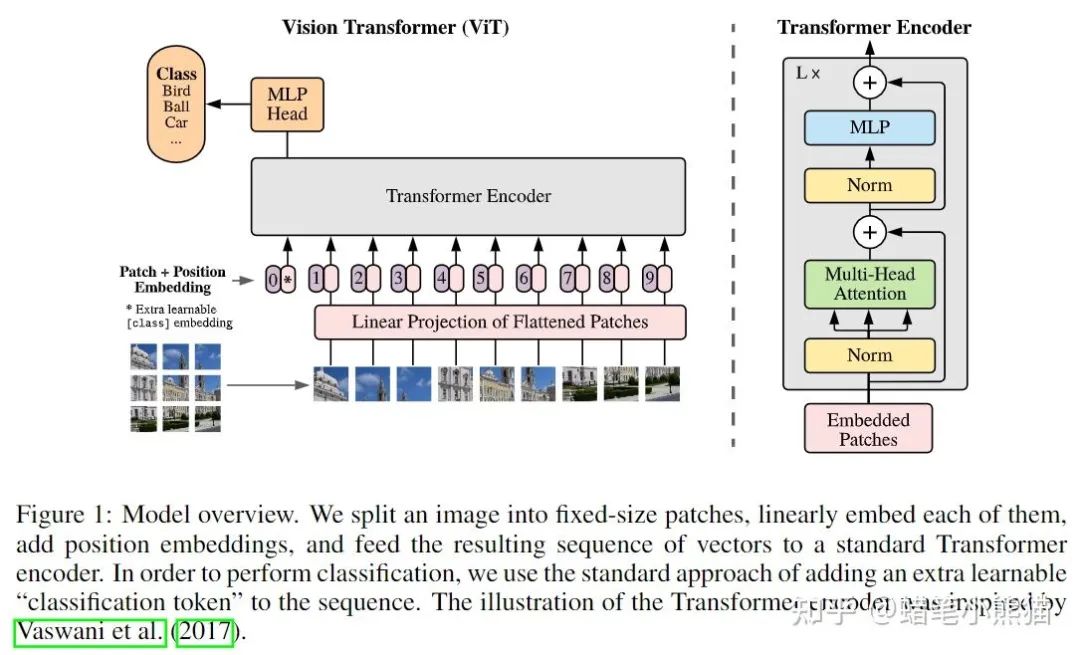
所以如果你用Transformer來當(dāng)backbone的時(shí)候,你需要做的就只是把圖片,文本,甚至表格信息等其他的所有模態(tài)信息全部flatten再concat或者相加成一維數(shù)組送進(jìn)Transformer,然后期待強(qiáng)大的Self-Attention開始work就可以了,比如圖片,你用CNN來提取特征得到了feature map,然后你再flatten成一維,和文本concat到一起就可以了
以下是幾個(gè)大公司的多模態(tài)Transformer的例子:
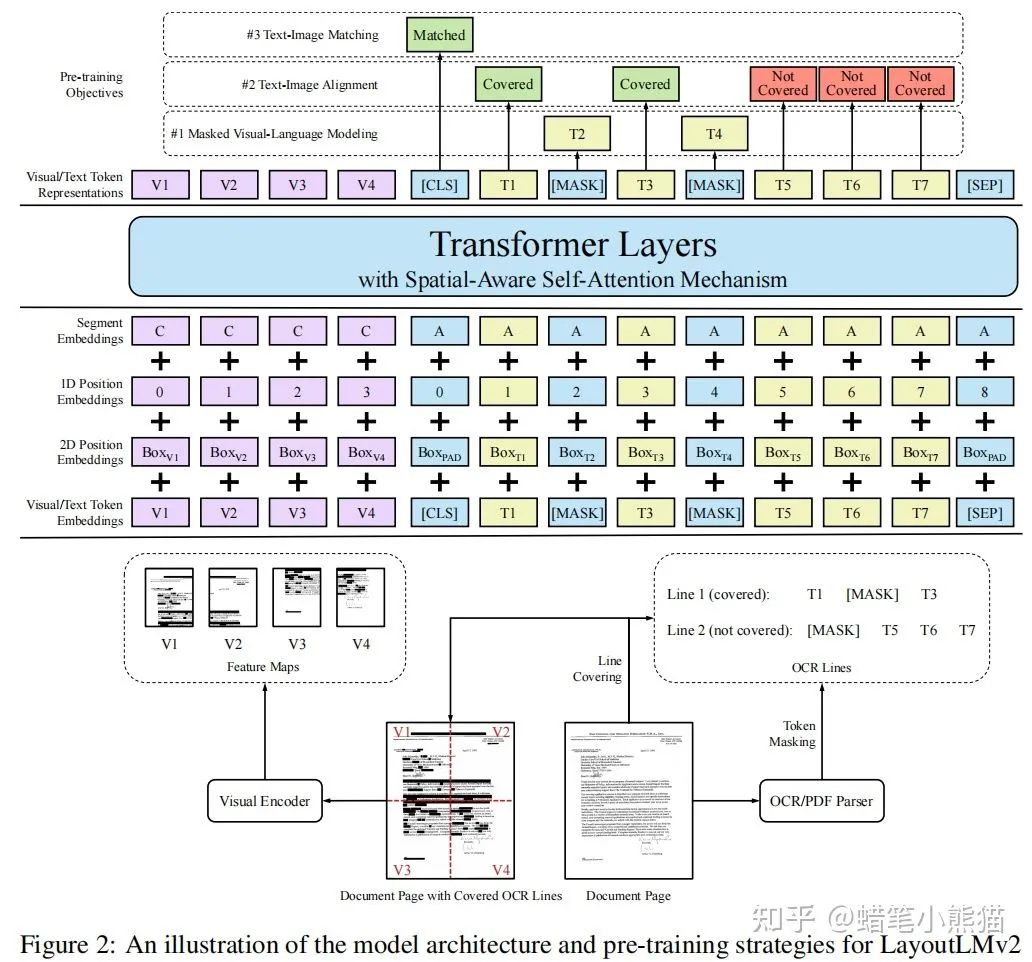
MSRA的LayoutLMv2,把layout信息的embedding和文本的embedding相加,然后再把image的embedding做concat送入Transformer
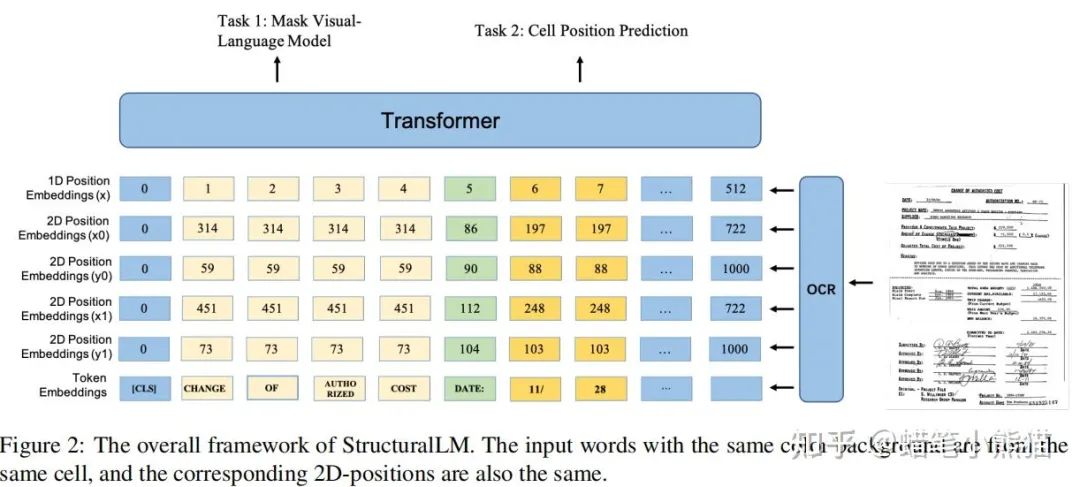
阿里達(dá)摩院的StructuralLM,將文本和layout的embedding相加送入Transformer

CMU的TABERT,將表格信息的embedding與文本信息的embedding相concate,還做了個(gè)Vertical Self-Attetion
多模態(tài)的Transfomer模型大抵如此,其實(shí)很暴力,你就想辦法把特征提出來做成embedding塞進(jìn)模型,接上下游任務(wù),然后祈禱神奇的self-attention開始運(yùn)作即可
參考文獻(xiàn):
Writing by Memorizing: Hierarchical Retrieval-based Medical Report Generation
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding
StructuralLM: Structural Pre-training for Form Understanding
TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data
李沐:自注意力和位置編碼 - 動(dòng)手學(xué)深度學(xué)習(xí)

霍華德回答:
真的嗎 ?真的嗎?
有些任務(wù)transformer不見得是最優(yōu)解吧!
transformer敢拿出來在youtube8m上和nextvlad比比嗎?
終究還是要看任務(wù)目標(biāo)吧!
多模態(tài)識(shí)別主要是挖掘不同模態(tài)之間的互補(bǔ)性,其核心在于怎么做圖像和文本的融合。
多模態(tài)匹配的重點(diǎn)在于如何將圖像和文本這兩種模態(tài)特征進(jìn)行對(duì)齊。
首先,transformer這個(gè)結(jié)構(gòu)最先提出是用在機(jī)器翻譯上的,它誕生之初就只是單一模態(tài)的模型。并且是經(jīng)典的encoder decoder結(jié)構(gòu)是設(shè)計(jì)來為sequence to sequence任務(wù)服務(wù)的。你很難看出他有什么針對(duì)多模態(tài)的特殊設(shè)計(jì)。
然后bert火了,成為了最強(qiáng)文本模型。然后多模態(tài)火了,為了不失去bert這個(gè)最強(qiáng)文本模型,同時(shí)把單一模態(tài)的bert擴(kuò)展到多模態(tài)比較容易,就誕生了一批基于transformer的多模態(tài)模型。
但這些模型設(shè)計(jì)在我看來并不是最優(yōu),文本一側(cè)是bert,圖像一側(cè)是resnet提特征,怎么看都比較別扭。最明顯一點(diǎn)就是兩側(cè)的粒度都沒有對(duì)齊,文本側(cè)是token字或詞,而圖像側(cè)是全局特征。比較好的建模方式,應(yīng)該把圖像的局部特征也轉(zhuǎn)化為視覺詞,形成一個(gè)類似SIFT時(shí)代碼表的東西,這樣文本詞就可以和視覺詞對(duì)齊。這樣的模型就非常漂亮了。
顯然有不少研究者也發(fā)現(xiàn)了這個(gè)問題。所以用ViT的方式來表征是視覺,把圖片分割成16×16的patch來代表視覺詞,此時(shí)粒度上就有了對(duì)齊的感覺了。但依然還比較粗糙,圖片里各種大大小小的物體,不可能用一個(gè)固定大小的patch來準(zhǔn)確捕捉所有語義。
到此為止,在transformer基礎(chǔ)上進(jìn)行了一系列改進(jìn),才使得transformer開始適合多模態(tài)任務(wù),但依然有很多需要改進(jìn)的點(diǎn)。但總體上來說,我對(duì)transformer多模態(tài)模型依然還是很樂觀的。
來源:知乎
文章轉(zhuǎn)載自知乎,著作權(quán)歸屬原作者,侵刪
——The ?End——

推薦閱讀
視覺Transformer BERT預(yù)訓(xùn)練新方式:中科大、MSRA等提出PeCo,優(yōu)于MAE、BEiT
