
ViLT:最簡單的多模態(tài)Transformer
之所以用這一篇作為多模態(tài)的開篇是因為這篇清楚的歸納了各種多模態(tài)算法,可以當(dāng)成一個小綜述來看,然后還提出了一種非常簡單的多模態(tài)Transformer方法ViLT。
先闡述一下4種不同類型的Vision-and-Language Pretraining(VLP),然后歸納2種模態(tài)相互作用方式和3種visual embedding方式,最后講一下ViLT的設(shè)計思路。
01
Taxonomy of VLP
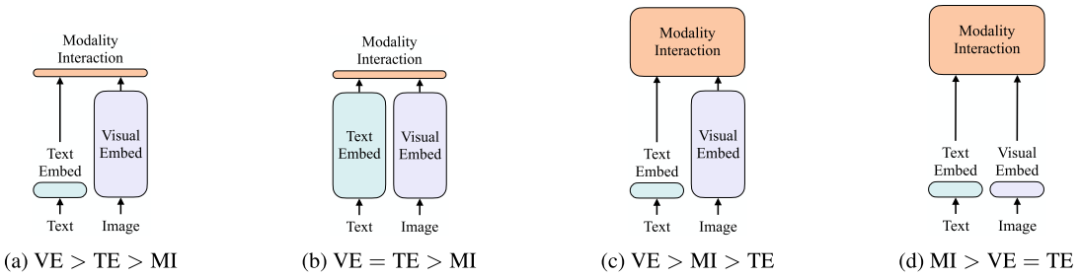
上圖是4種不同類型的VLP模型示意圖。其中每個矩形的高表示相對計算量大小,VE、TE和MI分別是visual embedding、text embedding和modality interaction的簡寫。
作者提出這4種類型的主要依據(jù)有兩點:
1.在參數(shù)或者計算上,兩種模態(tài)是否保持平衡。
2.在網(wǎng)絡(luò)深層中,兩種模態(tài)是否相互作用。
VSE、VSE++和SCAN屬于(a)類型。對圖像和文本獨立使用encoder,圖像的更重,文本的更輕,使用簡單的點積或者淺層attention層來表示兩種模態(tài)特征的相似性。
CLIP屬于(b)類型。每個模態(tài)單獨使用重的transformer encoder,使用池化后的圖像特征點積計算特征相似性。
ViLBERT、UNTER和Pixel-BERT屬于(c)類型。這些方法使用深層transformer進(jìn)行交互作用,但是由于VE仍然使用重的卷積網(wǎng)絡(luò)進(jìn)行特征抽取,導(dǎo)致計算量依然很大。
作者提出的ViLT屬于(d)類型。ViLT是首個將VE設(shè)計的如TE一樣輕量的方法,該方法的主要計算量都集中在模態(tài)交互上。
Modality Interaction Schema
模態(tài)交互部分可以分成兩種方式:一種是single-stream(如BERT和UNITER),另一種是dual-stream(如ViLBERT和LXMERT)。其中single-stream是對圖像和文本concate然后進(jìn)行交互操作,而dual-stream是不對圖像和文本concate然后進(jìn)行交互操作。ViLT延用single-stream的交互方式,因為dual-stream會引入額外的計算量。
Visual Embedding Schema
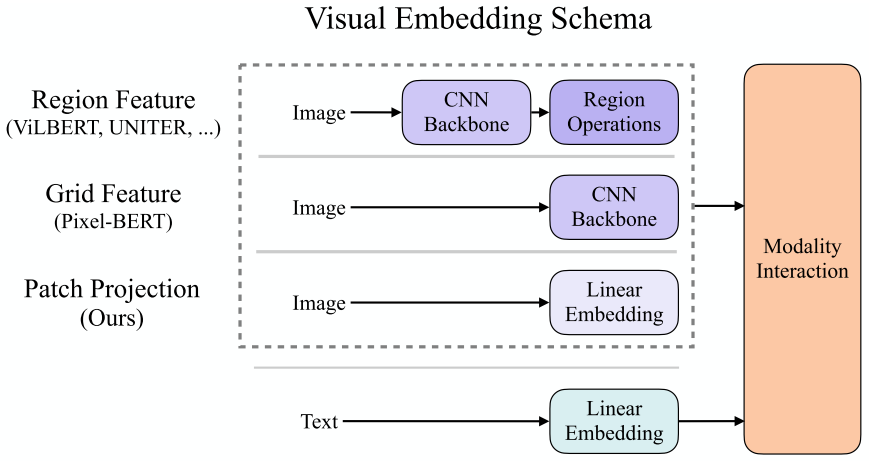
現(xiàn)有的VLP模型的text embedding基本上都使用類BERT結(jié)構(gòu),但是visual embedding存在著差異。在大多數(shù)情況下,visual embedding是現(xiàn)有VLP模型的瓶頸。visual embedding的方法總共有三大類,其中region feature方法通常采用Faster R-CNN二階段檢測器提取region的特征,grid feature方法直接使用CNN提取grid的特征,patch projection方法將輸入圖片切片投影提取特征。ViLT是首個使用patch projection來做visual embedding的方法。
02
ViLT
Model Overview
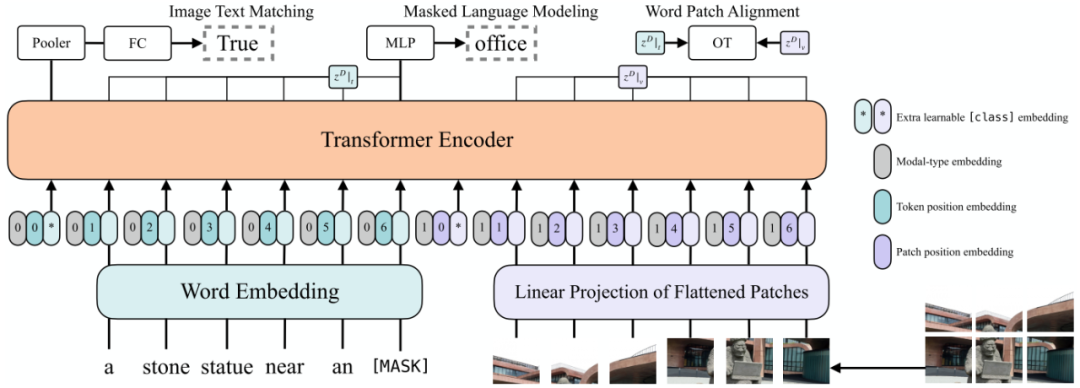
作者提出的ViLT可以認(rèn)為是目前最簡單的多模態(tài)Transformer方法。ViLT使用預(yù)訓(xùn)練的ViT來初始化交互的transformer,這樣就可以直接利用交互層來處理視覺特征,不需要額外增加一個視覺encoder。
文本特征輸入部分,將文本看成一個詞序列,通過word embedding matrix轉(zhuǎn)化成word embedding,然后和position embedding進(jìn)行相加,最后和modal-type embedding進(jìn)行concate。
圖像特征輸入部分,將圖像切塊看成一個圖像塊序列,通過linear projection轉(zhuǎn)化成visual embedding,然后和postion embedding進(jìn)行相加,最后和modal-type embedding進(jìn)行concate。
其中word embedding和visual embedding通過可學(xué)習(xí)的modal-type embedding標(biāo)志位來區(qū)分,其中0標(biāo)志位表示word embedding部分,1標(biāo)志位表示visual embedding部分。
wrod embedding和visual embedding分別都嵌入了一個額外的可學(xué)習(xí)[class] embedding,方便和下游任務(wù)對接。
Pretraining Objectives
ViLT預(yù)訓(xùn)練的優(yōu)化目標(biāo)有兩個:一個是image text matching(ITM),另一個是masked language modeling(MLM)。
ImageText Matching:隨機以0.5的概率將文本對應(yīng)的圖片替換成不同的圖片,然后對文本標(biāo)志位對應(yīng)輸出使用一個線性的ITM head將輸出feature映射成一個二值logits,用來判斷圖像文本是否匹配。另外ViLT還設(shè)計了一個word patch alignment (WPA)來計算teextual subset和visual subset的對齊分?jǐn)?shù)。
Masked Language Modeling:MLM的目標(biāo)是通過文本的上下文信息去預(yù)測masked的文本tokens。隨機以0.15的概率mask掉tokens,然后文本輸出接兩層MLP與車mask掉的tokens。
Whole Word Masking:另外ViLT還使用了whole word masking技巧。whole word masking是將連續(xù)的子詞tokens進(jìn)行mask的技巧,應(yīng)用于BERT和Chinese BERT是有效的。比如將“giraffe”詞tokenized成3個部分["gi", "##raf", "##fe"],那么可以mask成["gi", "[MASK]", "##fe"],模型使用[“gi”,“##fe”]來預(yù)測mask的“##raf”,而不使用圖像信息。
03
實驗結(jié)果

如圖所示,ViLT相比于region feature的方法速度快了60倍,相比于grid feature的方法快了4倍,而且下游任務(wù)表現(xiàn)出相似甚至更好的性能。
從table2、table3和table4中可以看出,相對于region和grid的方法,ViLT在下游任務(wù)表現(xiàn)出相似甚至更好的性能。
可視化

通過可視化可以看出,ViLT學(xué)到了word和image patch之間的對應(yīng)關(guān)系。
04
總結(jié)
BERT和ViT給多模態(tài)Transformer提供了基礎(chǔ),通過巧妙的proxy task設(shè)計,ViLT成功將BERT和ViT應(yīng)用于多模態(tài)Transformer。總體上來看基于patch projection的多模態(tài)方法速度優(yōu)勢非常大,但是整體上性能還是略低于region feature的方法,期待未來會有更強的基于patch projection的多模態(tài)方法出現(xiàn)。
Reference
[1] ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision

覺得有用給個在看吧 