
數(shù)據(jù)分析精華:模型融合方法總結(jié)!
一、背景
之前有段時間打數(shù)據(jù)挖掘類比賽,看到很多選手用模型融合的技巧,特別是比賽后期的時候,很多選手開始找隊友,多數(shù)是為了融模型。雖然我也有嘗試過一些模型融合,但卻一直缺乏體系化了解,所以在看了荷蘭Kaggle選手Triskelion的《KAGGLE ENSEMBLING GUIDE》[1],我決定體系化整理下機器學習模型融合的常見方法,自我查缺補漏。
二、融合對象
在講模型融合方法前,我們先了解下融合對象,我們?nèi)诘氖鞘裁矗渴遣煌膫€體學習器 (Individual Leaner)。"一個世界從來不是由某個單獨個體簡單構(gòu)成的,而是由具有不同屬性的個體共同構(gòu)成的"。對于個體學習器來說,它們的不同體現(xiàn)在:
不同訓練數(shù)據(jù):數(shù)據(jù)集使用比例、預(yù)處理方法 (缺失值填補、特征工程等);
不同模型結(jié)構(gòu):RF、XGBoost、LightGBM、CatBoost、CNN、LSTM等;
不同超參:隨機種子數(shù)、權(quán)重初始化、收斂相關(guān)參數(shù) (例如學習率、batch size、epoch、早停步數(shù))、損失函數(shù)、子采樣比例等。
三、融合方法
我一年前秋招有次電話面某公司,讓我介紹簡歷上的項目,其中有個項目是MLR+ARIMA結(jié)合在一起做的,然后我說這是模型集成,結(jié)果被人駁斥說,這不是模型集成(大概率面試官認為只有Boosting和Bagging是屬于模型集成,而其他模型結(jié)合不能稱作模型集成)。但我事后去翻西瓜書 [2],書上寫道:
集成學習 (Ensemble Learning) 通過構(gòu)建并結(jié)合多個學習器來完成學習任務(wù),有時也被稱作多分類器系統(tǒng) (Multi-classifier System)、基于委員會的學習 (Committee-based Learning)等。 《機器學習》- 周志華
所以說,模型集成不是只有同質(zhì)學習器的集成 (例如Boosting和Bagging) 才稱作模型集成,還有異質(zhì)學習器的集成也是模型集成。OS:面試面得我很冤枉。雖然我覺得稱作”模型集成“也沒錯,但為了避嫌,我這邊都統(tǒng)一稱作“模型融合"。本文不細講關(guān)于同質(zhì)學習器集成的內(nèi)容了 (即Boosting和Bagging),這里,我主要是基于 [1] 的內(nèi)容主線,分享異質(zhì)學習器的一些融合手段。
1. 投票法
適用于分類任務(wù),對多個學習器的預(yù)測結(jié)果進行投票,即少數(shù)服從多數(shù)。投票法有兩種:普通投票法和加權(quán)投票法。加權(quán)的權(quán)重可以人工主觀設(shè)置或者根據(jù)模型評估分數(shù)來設(shè)置權(quán)重。投票需要3個及3個以上的模型,同時建議要保證模型的多樣性,有時候?qū)ν|(zhì)模型們使用投票法并不能取得較好的表現(xiàn),這是因為同質(zhì)模型得到的結(jié)果之間可能具有較強的相關(guān)性,從而會導致多數(shù)人把少數(shù)人的好想法給壓下去了。為了避免這個問題,可以參考在2014年KDD Cup上Marios Michailid的做法,他對所有結(jié)果文件計算Pearson系數(shù),最后選取其中相關(guān)性小的模型結(jié)果進行投票,分數(shù)獲得了提升。
2. 平均法
適用于回歸、分類 (針對概率) 任務(wù),對多個學習器的預(yù)測結(jié)果進行平均。平均法的好處在于平滑結(jié)果,從而減少過擬合。常見的平均法有三種:算術(shù)平均法、幾何平均法和加權(quán)平均法。
假設(shè)我們有n個模型的預(yù)測結(jié)果
(1) 算術(shù)平均法:
(2) 幾何平均法:
(3) 加權(quán)平均法:
幾何平均法受極端值的影響較算術(shù)平均法小。另外,關(guān)于加權(quán)平均法的權(quán)重,也可以人工主觀或根據(jù)模型分數(shù)來設(shè)置。同時也建議盡量平均差異性小的模型們。
3. 排序法
如果模型評估標準是與排序或者閾值相關(guān) (例如AUC),簡單使用平均法并不見得都能取得較好得結(jié)果,為什么呢?我們可以看個例子:
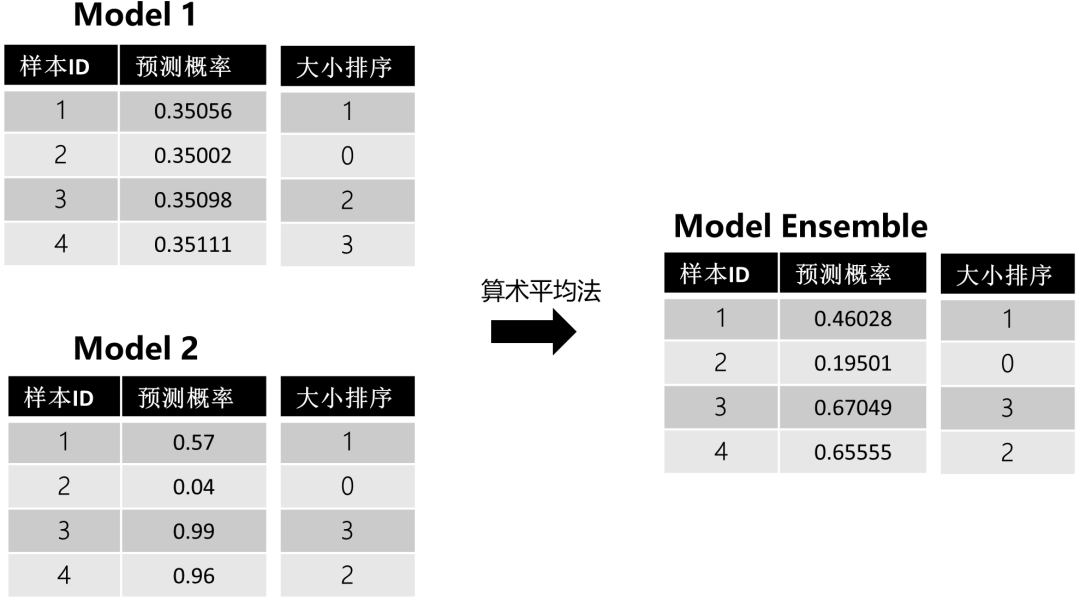
圖1:算術(shù)平均法樣例
上圖能發(fā)現(xiàn),模型1幾乎沒有給模型2帶來大的影響,因為像這種波動小的模型做融合,對最終結(jié)果造成的影響不大。為了解決這個問題,可以考慮使用排序平均法。在賽圈,碰到AUC,很多都會采用這種方法進行模型融合。比如在招商銀行的 “消費金融場景下的用戶購買預(yù)測” 的冠軍方案中 [3] 便針對賽題方的AUC評分標準,采用了基于排序的模型融合方法。排序法的具體步驟如下:
(1) 對預(yù)測結(jié)果進行排序;
(2) 對排序序號進行平均;
(3) 對平均排序序號進行歸一化。
這里還是用上面的例子幫助理解:
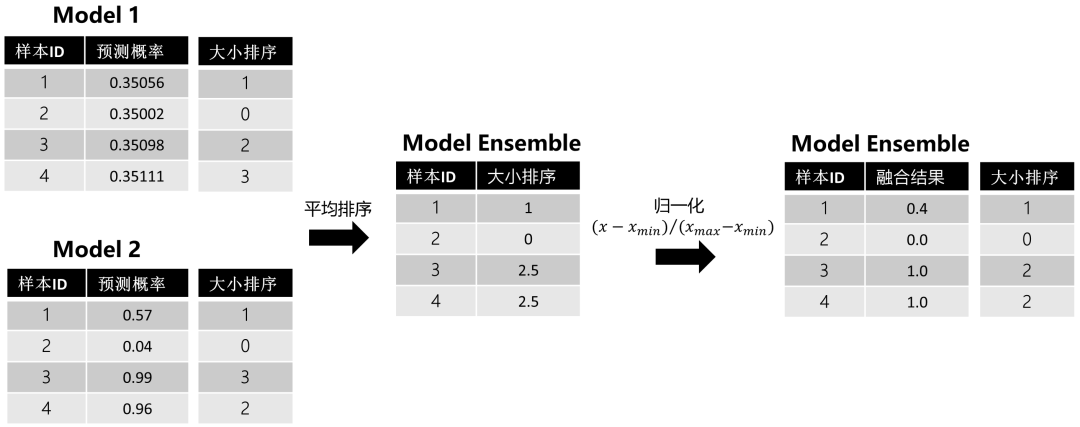
圖2:排序平均法樣例
通過平均排序和歸一化,我們能發(fā)現(xiàn)波動小的模型1給最終的模型融合帶來了影響。但在使用排序法的時候,有個地方我們需要注意:我們都知道,排序是針對測試集預(yù)測結(jié)果來做的,但如果在工業(yè)界使用,很多時候會有新樣本進來要你預(yù)測,此時該怎么辦呢?,針對新樣本,其實有兩種處理方式:
重新排序:將新樣本放入原測試集中,重新排序,一旦數(shù)據(jù)量大,時間復(fù)雜度會增加。
參考歷史排序:先將歷史測試集的預(yù)測結(jié)果和排序結(jié)果保存,新樣本進來后,在歷史測試集中找到與新樣本預(yù)測值最近的值,然后取其排序號賦予新樣本。之后平均排序,使用歷史最大最小值進行歸一化操作即可。
4. Stacking
Stacking堆疊法是相對比較高級的模型融合法,也是本文的重點。Stacking的思路是基于原始數(shù)據(jù),訓練出多個基學習器,然后將基學習器的預(yù)測結(jié)果組合成新的訓練集,去訓練一個新的學習器。
Stacking主要分為以下三類:
單層Stacking
多層Stacking
其它技術(shù)與Stacking的結(jié)合
(1) 單層Stacking
單層Stacking是指在基學習器上只堆疊一層元學習器,這也是最常見的Stacking結(jié)構(gòu),示意圖如下所示:
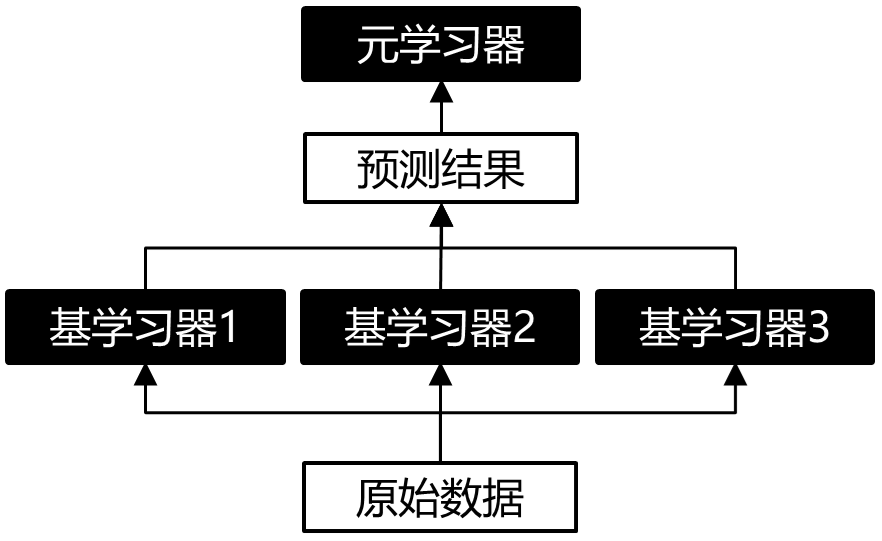
圖3:單層Stacking結(jié)構(gòu)示意圖
圖3里的基學習器可以是同質(zhì)或異質(zhì)的模型,而元學習器在傳統(tǒng)做法中是選用邏輯回歸模型,當然也能使用非線性模型作為元學習器,例如GBDT, KNN, NN, RF等。比如在 ”天池零基礎(chǔ)入門金融風控-貸款違約預(yù)測“ 一賽中,TOP6的方案 [4] 使用了LightGBM,CatBoost和XGBoost作為基學習器,然后利用Pearson相關(guān)系數(shù)分析模型結(jié)果差異性,選取差異較大的結(jié)果文件,再輸入第二層元學習器RF進一步融合結(jié)果。如果我們有4個特征的數(shù)據(jù)集和3個基學習器,,單層Stacking (5-Fold) 的訓練和預(yù)測的具體細節(jié)是怎樣的呢?請見下圖:
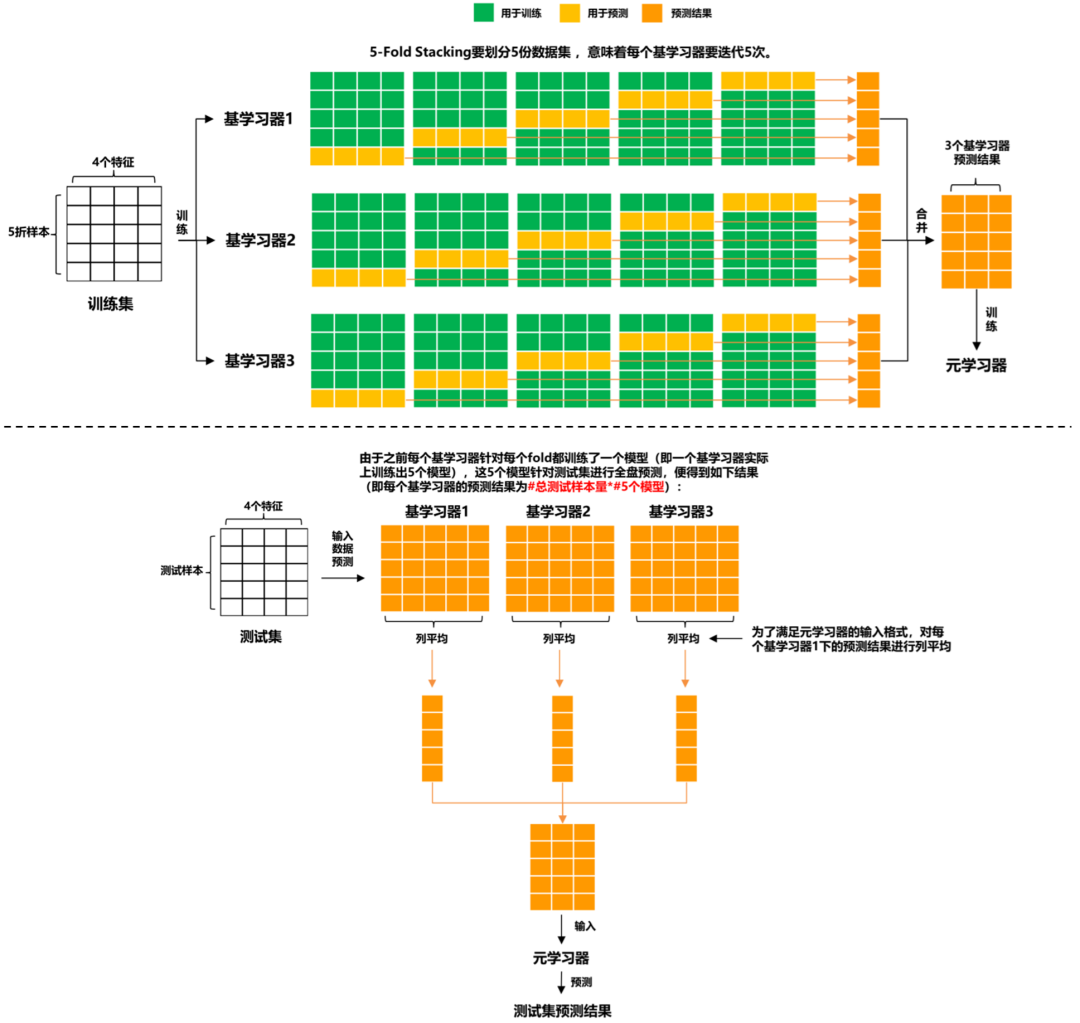
圖4:單層Stacking (5-Fold) 的訓練預(yù)測流程圖
單層Stacking在基學習器和元學習器上可靈活選用自己喜歡的模型,甚至說能暴力去做(量力而行):
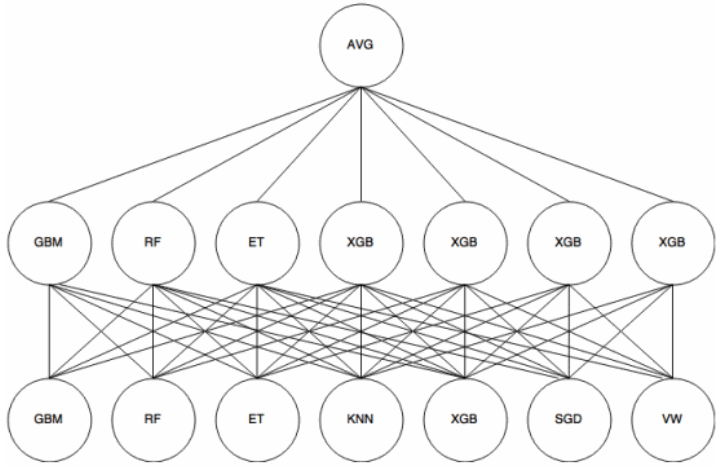
圖5:暴力單層Stacking [1]
除此之外,Stacking在特征上也可以玩出一些花樣,其中,[1] 便介紹了兩種單層Stacking上的特征交互方法:
Feature-weighted Linear Stacking (FWLS):Still等人在論文 [5] 中提出了該方法。基學習器們的預(yù)測結(jié)果叫元特征,因為它們是用于訓練元學習器。FWLS提出可以在元學習器前,對元特征進行特征交互,交互對象可以是元特征本身,也可以是原始特征(即:元特征*元特征 或 元特征*原始特征)。
Quadratic Linear Stacking of Models:它采用的特征交互模式是:元特征*元特征+元特征*原始特征。
(2) 多層Stacking
這個是聽說的,即增加多層元學習器,但我也沒用過。大概結(jié)構(gòu)示意圖如下:
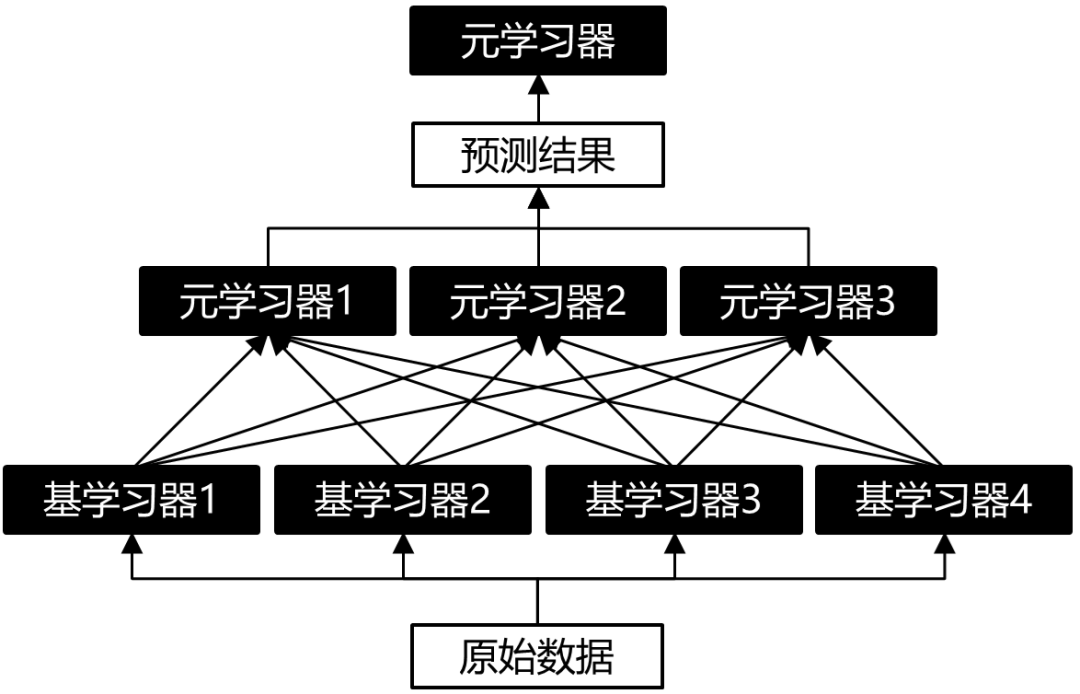
圖6:雙層Stacking結(jié)構(gòu)示意圖
(3) 其它技術(shù)與Stacking的結(jié)合
Stacking可以與無監(jiān)督學習方法結(jié)合。例如:使用t-SNE將數(shù)據(jù)降維到2或3維,然后用非線性元學習器來融合。案例可參考Kaggle的“Otto Group Product Classification Challenge”中,Mike Kim提出的方法 [6]。
5. Blending
我們思考下Stacking,基學習器和元學習器本質(zhì)上都是用同一訓練集訓練的 (雖然輸入的x不一樣,但標簽y一樣),這就會造成信息泄露,從而導致元學習器過擬合我們的數(shù)據(jù)集。為了避免這種問題,Blending方法被提出了,它的想法是:對原始數(shù)據(jù)集先劃分出一個較小的留出集,比如10%訓練集被當做留出集,那么Blending用90%的數(shù)據(jù)做基學習器的訓練,而10%留出集用作訓練元學習器,這樣基學習器和元學習是用不同數(shù)據(jù)集來訓練的。Blending的示意圖如下所示:
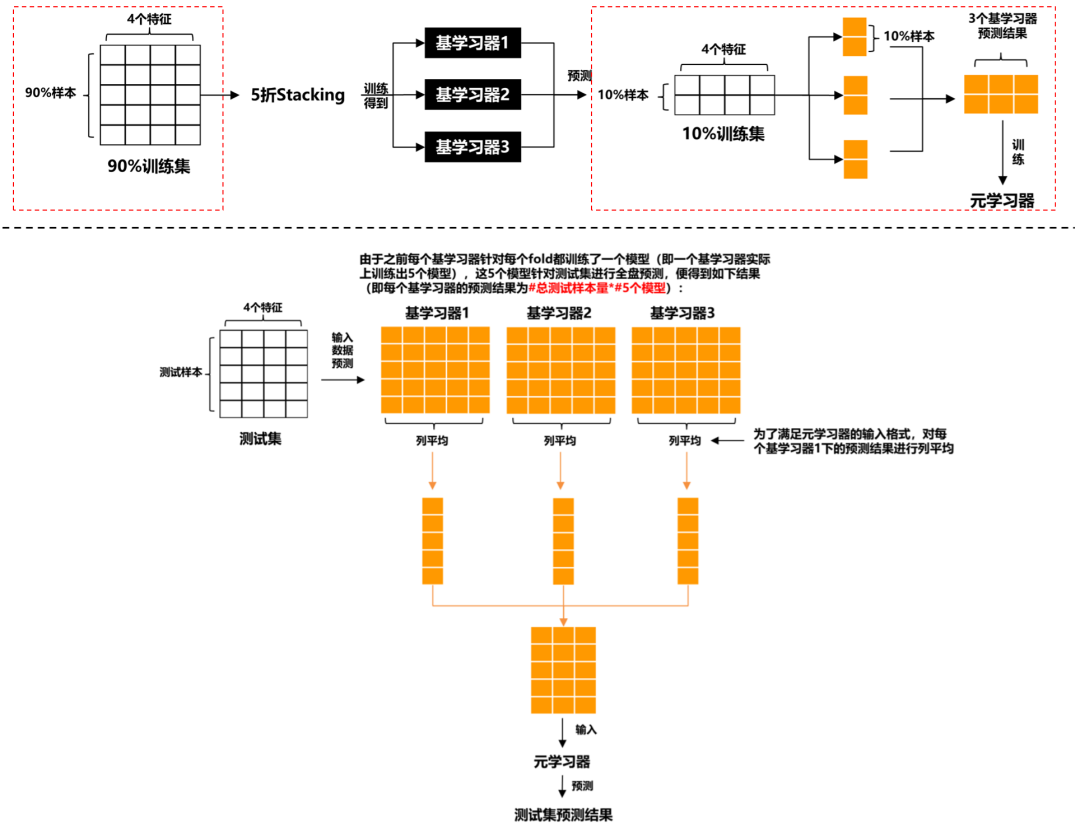
圖7:Blending的訓練預(yù)測流程圖
上圖的紅框是區(qū)分Stacking的關(guān)鍵。相比于Stacking,Blending能有效防止信息泄露,但也正因為如此,元學習器只用了較小部分的數(shù)據(jù)集進行訓練,且容易對留出集過擬合。如果數(shù)據(jù)量有限,個人更偏好于Stacking。
四、總結(jié)
模型融合看起來很贊,很多比賽選手也熱衷于在比賽后期去找使用不同模型的隊友進行模型融合,但真實工業(yè)中,還是Less is better。例如:在2006年,Netflix組織的第一場數(shù)據(jù)科學競賽,隊伍Korbell以8.43%的提升獲得了第一進步獎,為此,他們?nèi)诤狭?07個算法且耗時2000小時。由于融合帶來的復(fù)雜度,最后Netflix并沒有將他們方案完全應(yīng)用在產(chǎn)品中 [7]。現(xiàn)在很多比賽平臺也聲明禁止選手過多堆砌模型,特別是很多比賽已經(jīng)開始將預(yù)測時間加入分數(shù)評估中。對于我們來說,模型融合是一種提升分數(shù)的有力技巧,但還是建議平衡好整個解決方案的準確率和效率。
參考資料
[1] 《KAGGLE ENSEMBLING GUIDE》- MLWave: [https://mlwave.com/kaggle-ensembling-guide/](https://mlwave.com/kaggle-ensembling-guide/)
[2] 《機器學習》- 周志華
[3] 招商銀行的消費金融場景下的用戶購買預(yù)測的冠軍方案: [https://github.com/sunwantong/China-Merchants-Bank-credit-card-Cente-User-purchase-forecast](https://github.com/sunwantong/China-Merchants-Bank-credit-card-Cente-User-purchase-forecast)
[4] 《天池新人賽:貸款違約預(yù)測TOP6方案分享》- 曹歡 (Coggle小組成員)
[5] Sill, J., Takács, G., Mackey, L., & Lin, D. (2009). Feature-weighted linear stacking. arXiv preprint arXiv:0911.0460.
[6] T-SNE+Stacking:[https://www.kaggle.com/c/otto-group-product-classification-challenge/discussion/14295](https://www.kaggle.com/c/otto-group-product-classification-challenge/discussion/14295)
[7] Netflix Recommendations: Beyond the 5 stars (Part 1): [https://netflixtechblog.com/netflix-recommendations-beyond-the-5-stars-part-1-55838468f429](https://netflixtechblog.com/netflix-recommendations-beyond-the-5-stars-part-1-55838468f429)

推薦閱讀
歡迎長按掃碼關(guān)注「數(shù)據(jù)管道」