
面試必問 | HBase最新面試總結(jié)
關(guān)注我,回復(fù)"資料",獲取精美的大數(shù)據(jù)資料
最近看了好多粉絲的面試題,于是總結(jié)出關(guān)于HBase相關(guān)的面試題,今天分享給大家,認(rèn)真閱讀,記得收藏。
一、講一下 Hbase 架構(gòu)
Hbase主要包含HMaster/HRegionServer/Zookeeper
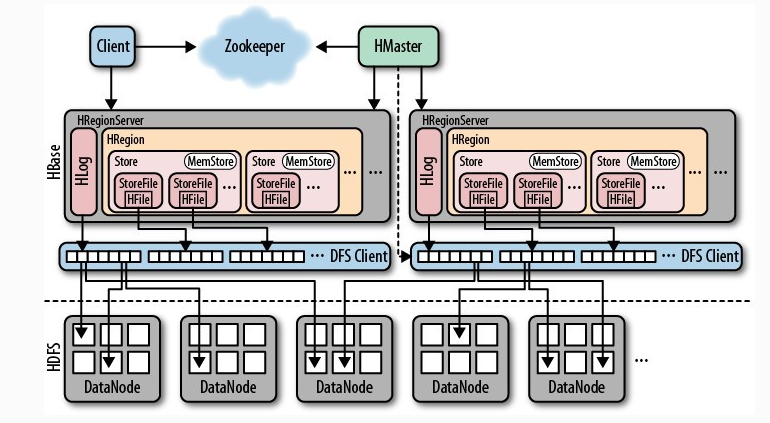
Client:
訪問數(shù)據(jù)的入口,包含訪問hbase的API接口,維護(hù)著一些cache來加快對hbase的訪問
Zookeeper:
1.zookeeper的選舉機(jī)制保證任何時候,集群中只有一個master
2.實時監(jiān)控Region Server的狀態(tài),將Region server的上線和下線信息實時通知給Master
3.存儲Hbase的schema
4.存貯所有Region的尋址入口
Master:
1.為Region server分配region
2.負(fù)責(zé)region server的負(fù)載均衡
3.發(fā)現(xiàn)失效的region server并重新分配其上的region
4.處理schema(元數(shù)據(jù))更新請求
說明:Hmaster短時間下線,hbase集群依然可用,長時間不行。
Region server:
1.Region server維護(hù)Master分配給它的region,處理對這些region的IO請求
2.Region server負(fù)責(zé)切分在運行過程中變得過大的region
二、hbase 如何設(shè)計rowkey
RowKey長度原則
Rowkey是一個二進(jìn)制碼流,Rowkey的長度被很多開發(fā)者建議說設(shè)計在10~100個字節(jié),不過建議是越短越好,不要超過16個字節(jié)。
原因如下:
數(shù)據(jù)的持久化文件HFile中是按照KeyValue存儲的,如果Rowkey過長比如100個字節(jié),1000萬列數(shù)據(jù)光Rowkey就要占用100*1000萬=10億個字節(jié),將近1G數(shù)據(jù),這會極大影響HFile的存儲效率;
MemStore將緩存部分?jǐn)?shù)據(jù)到內(nèi)存,如果Rowkey字段過長內(nèi)存的有效利用率會降低,系統(tǒng)將無法緩存更多的數(shù)據(jù),這會降低檢索效率。因此Rowkey的字節(jié)長度越短越好。
目前操作系統(tǒng)是都是64位系統(tǒng),內(nèi)存8字節(jié)對齊。控制在16個字節(jié),8字節(jié)的整數(shù)倍利用操作系統(tǒng)的最佳特性。
RowKey散列原則
如果Rowkey是按時間戳的方式遞增,不要將時間放在二進(jìn)制碼的前面,建議將Rowkey的高位作為散列字段,由程序循環(huán)生成,低位放時間字段,這樣將提高數(shù)據(jù)均衡分布在每個Regionserver實現(xiàn)負(fù)載均衡的幾率。如果沒有散列字段,首字段直接是時間信息將產(chǎn)生所有新數(shù)據(jù)都在一個RegionServer上堆積的熱點現(xiàn)象,這樣在做數(shù)據(jù)檢索的時候負(fù)載將會集中在個別RegionServer,降低查詢效率。
RowKey唯一原則
必須在設(shè)計上保證其唯一性。
三、講一下hbase的存儲結(jié)構(gòu),這樣的存儲結(jié)構(gòu)有什么優(yōu)缺點
Hbase的優(yōu)點及應(yīng)用場景:
半結(jié)構(gòu)化或非結(jié)構(gòu)化數(shù)據(jù): 對于數(shù)據(jù)結(jié)構(gòu)字段不夠確定或雜亂無章非常難按一個概念去進(jìn)行抽取的數(shù)據(jù)適合用HBase,因為HBase支持動態(tài)添加列。 記錄很稀疏:RDBMS的行有多少列是固定的。為null的列浪費了存儲空間。HBase為null的Column不會被存儲,這樣既節(jié)省了空間又提高了讀性能。 多版本號數(shù)據(jù):依據(jù)Row key和Column key定位到的Value能夠有隨意數(shù)量的版本號值,因此對于須要存儲變動歷史記錄的數(shù)據(jù),用HBase是很方便的。比方某個用戶的Address變更,用戶的Address變更記錄也許也是具有研究意義的。 僅要求最終一致性:對于數(shù)據(jù)存儲事務(wù)的要求不像金融行業(yè)和財務(wù)系統(tǒng)這么高,只要保證最終一致性就行。(比如HBase+elasticsearch時,可能出現(xiàn)數(shù)據(jù)不一致) 高可用和海量數(shù)據(jù)以及很大的瞬間寫入量:WAL解決高可用,支持PB級數(shù)據(jù),put性能高 適用于插入比查詢操作更頻繁的情況。比如,對于歷史記錄表和日志文件。(HBase的寫操作更加高效) 業(yè)務(wù)場景簡單:不需要太多的關(guān)系型數(shù)據(jù)庫特性,列入交叉列,交叉表,事務(wù),連接等。
Hbase的缺點:
單一RowKey固有的局限性決定了它不可能有效地支持多條件查詢 不適合于大范圍掃描查詢 不直接支持 SQL 的語句查詢
四、?ush機(jī)制
全局的memstore的?ush機(jī)制默認(rèn)為堆總大小(多個memstore 多個region)的40%,超過該大小會觸發(fā)?ush到磁盤的操作,會阻塞客戶端讀寫,?ush將所有的memstore全部?ush。
單個的memstore默認(rèn)為數(shù)據(jù)達(dá)到128M或1h或者數(shù)據(jù)為堆大小 0.95倍將會?ush. memstore默認(rèn)將會先提前?ush 5M.(先?ush一小部分,等后面數(shù)據(jù)達(dá)到閾值在?ush后 面的數(shù)據(jù)) 這樣會比一次?ush效率高
hbase
不建議配置過多列族:過多的列族會消耗大量的內(nèi)存,同時數(shù)據(jù)在?ush時消耗磁盤IO. 一個regionserver讀寫操作可用堆內(nèi)存的80%,讀取占用40% ,寫入占用40%。這兩個參數(shù)直接 影響hbase讀寫性能。
五、HMaster宕機(jī)的時候,哪些操作還能正常工作
對表內(nèi)數(shù)據(jù)的增刪查改是可以正常進(jìn)行的,因為hbase client 訪問數(shù)據(jù)只需要通過 zookeeper 來找到 rowkey 的具體 region 位置即可. 但是對于創(chuàng)建表/刪除表等的操作就無法進(jìn)行了,因為這時候是需要HMaster介入, 并且region的拆分,合并,遷移等操作也都無法進(jìn)行了
六、講一下hbase的寫數(shù)據(jù)的流程
Client先訪問zookeeper,從.META.表獲取相應(yīng)region信息,然后從meta表獲取相應(yīng)region信息 根據(jù)namespace、表名和rowkey根據(jù)meta表的數(shù)據(jù)找到寫入數(shù)據(jù)對應(yīng)的region信息 找到對應(yīng)的regionserver 把數(shù)據(jù)先寫到WAL中,即HLog,然后寫到MemStore上 MemStore達(dá)到設(shè)置的閾值后則把數(shù)據(jù)刷成一個磁盤上的StoreFile文件。 當(dāng)多個StoreFile文件達(dá)到一定的大小后(這個可以稱之為小合并,合并數(shù)據(jù)可以進(jìn)行設(shè)置,必須大于等于2,小于10——hbase.hstore.compaction.max和hbase.hstore.compactionThreshold,默認(rèn)為10和3),會觸發(fā)Compact合并操作,合并為一個StoreFile,(這里同時進(jìn)行版本的合并和數(shù)據(jù)刪除。) 當(dāng)Storefile大小超過一定閾值后,會把當(dāng)前的Region分割為兩個(Split)【可稱之為大合并,該閾值通過hbase.hregion.max.filesize設(shè)置,默認(rèn)為10G】,并由Hmaster分配到相應(yīng)的HRegionServer,實現(xiàn)負(fù)載均衡
七、講一下hbase的寫數(shù)據(jù)的流程
4.Memstore達(dá)到閾值,會把Memstore中的數(shù)據(jù)?ush到Store?le中
5.當(dāng)Store?le越來越多,達(dá)到一定數(shù)量時,會觸發(fā)Compact合并操作,將多個小文件合并成一個大文件。
6.Store?le越來越大,Region也會越來越大,達(dá)到閾值后,會觸發(fā)Split操作,變成兩個文件。
說明:hbasez 支持?jǐn)?shù)據(jù)修改(偽修改),實際上是相同rowkey數(shù)據(jù)的添加。hbase只顯示最后一次的添加
八、講一下hbase讀數(shù)據(jù)的流程
meta表是hbase系統(tǒng)自帶的一個表。里面存儲了hbase用戶表的元信息。
元信息為meta表內(nèi)記錄一行數(shù)據(jù)是用戶表一個region的start key 到endkey的范圍。
meta表存儲在regionserver里。 具體存儲在哪個regionserver里?zookeeper知道。
過程:
1.客戶端到zookeeper詢問meta表在哪
2.客戶端到meta所在的節(jié)點(regionserver)讀取meta表的數(shù)據(jù)
3.客戶端找到region 獲取region和regionserver的對應(yīng)關(guān)系,直接到regionserver讀取region數(shù)據(jù)
九、Hbase 和 hive 有什么區(qū)別hive 與 hbase 的底層存儲是什么?hive是產(chǎn)生的原因是什么?habase是為了彌補(bǔ)hadoop的什么缺陷?共同點:
共同點:
hbase與hive都是架構(gòu)在hadoop之上的。都是用hadoop作為底層存儲
區(qū)別:
HIVE
1、Hive是建立在Hadoop之上為了減少MapReducejobs編寫工作的批處理系統(tǒng)
2、Hive本身不存儲和計算數(shù)據(jù),它完全依賴于HDFS和MapReduce,Hive中的表純邏輯。
3、hive借用hadoop的MapReduce來完成一些hive中的命令的執(zhí)行
4、hive需要用到hdfs存儲文件,需要用到MapReduce計算框架
HBASE
1、HBase是為了支持彌補(bǔ)Hadoop對實時操作的缺陷的項目 。
2、想象你在操作RMDB數(shù)據(jù)庫,如果是全表掃描,就用Hive+Hadoop,如果是索引訪問,就用HBase+Hadoop 。
3、HBase是非常高效的,肯定比Hive高效的多。
4、hbase是物理表,不是邏輯表,提供一個超大的內(nèi)存hash表,搜索引擎通過它來存儲索引,方便查詢操作。
5、hbase是列存儲。
6、hdfs作為底層存儲,hdfs是存放文件的系統(tǒng),而Hbase負(fù)責(zé)組織文件。
十、直接將時間戳作為行健,在寫入單個 region 時候會發(fā)生熱點問題,為什么呢?
region 中的 rowkey 是有序存儲,若時間比較集中。就會存儲到一個 region 中,這樣一個 region 的數(shù)據(jù)變多,其它的 region 數(shù)據(jù)很少,加載數(shù)據(jù)就會很慢,直到 region 分裂,此問題才會得到緩解。
十一、解釋下 hbase 實時查詢的原理
實時查詢,可以認(rèn)為是從內(nèi)存中查詢,一般響應(yīng)時間在 1 秒內(nèi)。HBase 的機(jī)制是數(shù)據(jù)先寫入到內(nèi)存中,當(dāng)數(shù)據(jù)量達(dá)到一定的量(如 128M),再寫入磁盤中, 在內(nèi)存中,是不進(jìn)行數(shù)據(jù)的更新或合并操作的,只增加數(shù)據(jù),這使得用戶的寫操作只要進(jìn)入內(nèi)存中就可以立即返回,保證了 HBase I/O 的高性能。