
【推薦系統(tǒng)】推薦系統(tǒng)概述
編譯:伯樂在線 - Marticles,英文:Toby Daigle
http://blog.jobbole.com/114167/
“聆忠言者眾,惟智者受益。” — 哈珀·李
許多人把推薦系統(tǒng)視為一種神秘的存在,他們覺得推薦系統(tǒng)似乎知道我們的想法是什么。Netflix 向我們推薦電影,還有亞馬遜向我們推薦該買什么樣的商品。推薦系統(tǒng)從早期發(fā)展到現(xiàn)在,已經得到了很大的改進和完善,以不斷地提高用戶體驗。盡管推薦系統(tǒng)中許多都是非常復雜的系統(tǒng),但其背后的基本思想依然十分簡單。
推薦系統(tǒng)是什么?
推薦系統(tǒng)是信息過濾系統(tǒng)的一個子類,它根據用戶的偏好和行為,來向用戶呈現(xiàn)他(或她)可能感興趣的物品。推薦系統(tǒng)會嘗試去預測你對一個物品的喜好,以此向你推薦一個你很有可能會喜歡的物品。
如何構建一個推薦系統(tǒng)?
現(xiàn)在已經有很多種技術來建立一個推薦系統(tǒng)了,我選擇向你們介紹其中最簡單,也是最常用的三種。他們是:一,協(xié)同過濾;二,基于內容的推薦系統(tǒng);三,基于知識的推薦系統(tǒng)。我會解釋前面的每個系統(tǒng)相關的弱點,潛在的缺陷,以及如何去避免它們。最后,我在文章末尾為你們準備了一個推薦系統(tǒng)的完整實現(xiàn)。
協(xié)同過濾
協(xié)同過濾,是首次被用于推薦系統(tǒng)上的技術,至今仍是最簡單且最有效的。協(xié)同過濾的過程分為這三步:一開始,收集用戶信息,然后以此生成矩陣來計算用戶關聯(lián),最后作出高可信度的推薦。這種技術分為兩大類:一種基于用戶,另一種則是基于組成環(huán)境的物品。
基于用戶的協(xié)同過濾
基于用戶的協(xié)同過濾本質上是尋找與我們的目標用戶具有相似品味的用戶。如果Jean-Pierre和Jason曾對幾部電影給出了相似的評分,那么我們認為他們就是相似的用戶,接著我們就可以使用Jean Pierre的評分來預測Jason的未知評分。例如,如果Jean-Pierre喜歡星球大戰(zhàn)3:絕地武士歸來和星球大戰(zhàn)5:帝國反擊戰(zhàn),Jason也喜歡絕地武士歸來,那么帝國反擊戰(zhàn)對Jason來說是就是一個很好的推薦。一般來說,你只需要一小部分與Jason相似的用戶來預測他的評價。

在下表中,每行代表一個用戶,每列代表一部電影,只需簡單地查找這個矩陣中行之間的相似度,就可以找到相似的用戶了。
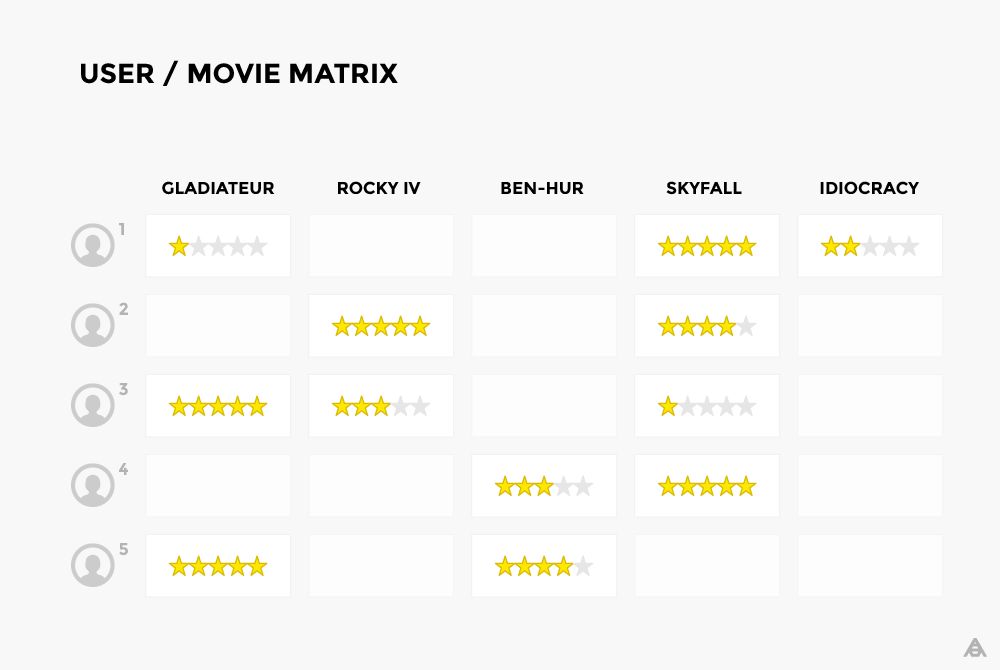
然而,基于用戶的協(xié)同過濾在實現(xiàn)中存在一些以下問題:
用戶偏好會隨時間的推移而改變,推薦系統(tǒng)生成的許多推薦可能會隨之變得過時。
用戶的數量越多,生成推薦的時間就越長。
基于用戶會導致對托攻擊敏感,這種攻擊方法是指惡意人員通過繞過推薦系統(tǒng),使得特定物品的排名高于其他物品。
(托攻擊即Shilling Attack,是一種針對協(xié)同過濾根據近鄰偏好產生推薦的特點,惡意注入偽造的用戶模型,推高或打壓目標排名,從而達到改變推薦系統(tǒng)結果的攻擊方式)
基于物品的協(xié)同過濾
基于物品的協(xié)同過濾過程很簡單。兩個物品的相似性基于用戶給出的評分來算出。讓我們回到Jean-Pierre與Jason的例子,他們兩人都喜歡“絕地武士歸來”和“帝國反擊戰(zhàn)”。因此,我們可以推斷,喜歡第一部電影的大多數用戶也可能會喜歡第二部電影。所以,對于喜歡“絕地武士歸來”的第三個人Larry來說,”帝國反擊戰(zhàn)“的推薦將是有意義的。
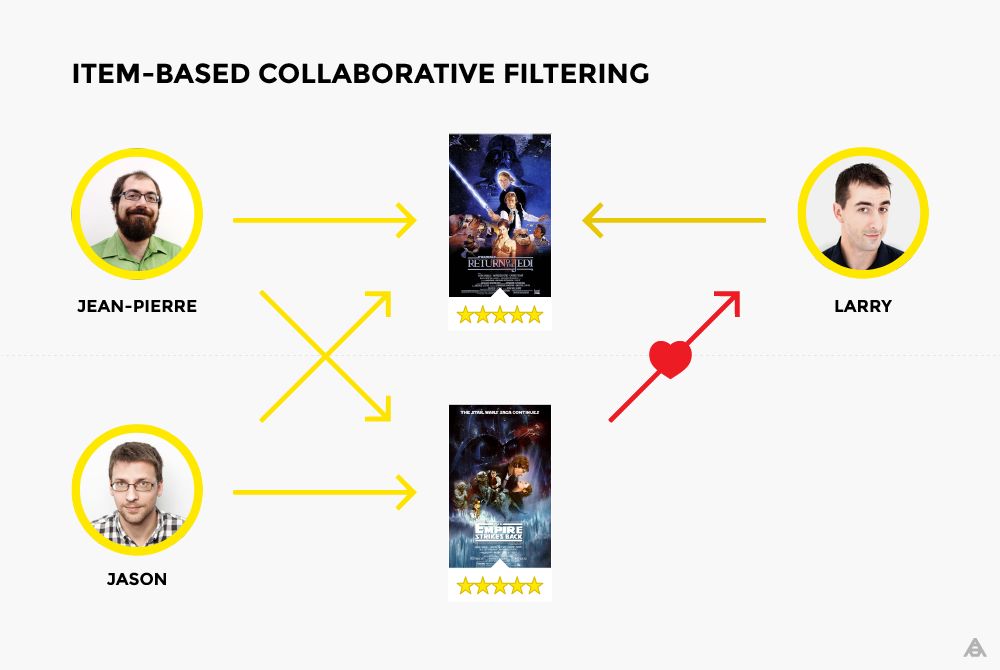
所以,這里的相似度是根據列而不是行來計算的(與上面的用戶-電影矩陣中所見的不同)。基于物品的協(xié)同過濾常常受到青睞,因為它沒有任何基于用戶的協(xié)同過濾的缺點。首先,系統(tǒng)中的物品(在這個例子中物品就是電影)不會隨著時間的推移而改變,所以推薦會越來越具有關聯(lián)性。此外,通常推薦系統(tǒng)中的物品都會比用戶少,這減少了推薦的處理時間。最后,考慮到沒有用戶能夠改變系統(tǒng)中的物品,這種系統(tǒng)要更難于被欺騙或攻擊。
基于內容的推薦系統(tǒng)
在基于內容的推薦系統(tǒng)中,元素的描述性屬性被用來構成推薦。“內容Content”一詞指的就是這些描述。舉個例子,根據Sophie的聽歌歷史,推薦系統(tǒng)注意到她似乎喜歡鄉(xiāng)村音樂。因此,系統(tǒng)可以推薦相同或相似類型的歌曲。更復雜的推薦系統(tǒng)能夠發(fā)現(xiàn)多個屬性之間的關系,從而產生更高質量的推薦。例如,音樂基因組計劃(Music Genome Project)根據450個不同的屬性將數據庫中的每支歌曲進行分類。該項目為Pandor的歌曲推薦提供技術支持。(Pandor提供在線音樂流媒體服務,類似Spolify)
基于知識的推薦系統(tǒng)
基于知識的推薦系統(tǒng)在物品購買頻率很低的情況下特別適用。例如房屋、汽車、金融服務甚至是昂貴的奢侈品。在這種情況下,推薦的過程中常常缺乏商品的評價。基于知識的推薦系統(tǒng)不使用評價來作出推薦。相反,推薦過程是基于顧客的需求和商品描述之間的相似度,或是對特定用戶的需求使用約束來進行的。這使得這種類型的系統(tǒng)是獨一無二的,因為它允許顧客明確地指定他們想要什么。關于約束,當應用時,它們大多是由該領域的專家實施的,這些專家從一開始就知道該如何實施這些約束。例如,當用戶明確指出在一個特定的價格范圍內尋找一個家庭住宅時,系統(tǒng)必須考慮到這個用戶規(guī)定的約束。
推薦系統(tǒng)中的冷啟動問題
推薦系統(tǒng)中的主要問題之一是最初可用的評價數量相對較小。當新用戶還沒有給電影打分,或者一部新的電影被添加到系統(tǒng)中時,我們該怎么做呢?在這種情況下,應用傳統(tǒng)的協(xié)同過濾模型會更加困難。盡管基于內容和基于知識的推薦算法在面臨冷啟動問題時比協(xié)同過濾更具有魯棒性,但基于內容和基于知識并不總是可用的。因此,一些新方法,比如混合系統(tǒng),已經被設計出用來解決這個問題了。
混合推薦系統(tǒng)
文章到目前為止所介紹的不同類型的推薦系統(tǒng)都各有優(yōu)劣,他們根據不同的數據給出推薦。一些推薦系統(tǒng),如基于知識的推薦系統(tǒng),在數據量有限的冷啟動環(huán)境下最為有效。其他系統(tǒng),如協(xié)同過濾,在有大量數據可用時則更加有效。在多數情況下,數據都是多樣化的,我們可以為同一任務靈活采用多種方法。因此,我們可以結合多種不同技術的推薦來提高整個系統(tǒng)的推薦質量。許多的組合性技術已經被探索出來了,包括:
加權:為推薦系統(tǒng)中的每種算法都賦予不同的權重,使得推薦偏向某種算法
交叉:將所有的推薦結果集合在一起展現(xiàn),沒有偏重
增強:一個系統(tǒng)的推薦將作為下一個系統(tǒng)的輸入,循環(huán)直至最后一個系統(tǒng)為止
切換:隨機選擇一種推薦方法
混合推薦系統(tǒng)中的一個最有名的例子是于2006至2009年舉行的Netflix Price算法競賽。這個競賽的目標是將Netflix的電影推薦系統(tǒng)Cinematch的算法準確率提高至少10%。Bellkor’s Pragmatix Chaos團隊用一種融合了107種不同算法的方案將Cinematch系統(tǒng)的推薦準確率提高了10.06%,并最終獲得了100萬美元獎金。你可能會對這個例子中的準確率感到好奇,準確率其實就是對電影的預測評分與實際評分接近程度的度量。
推薦系統(tǒng)與AI?
推薦系統(tǒng)常用于人工智能領域。推薦系統(tǒng)的能力 – 洞察力,預測事件的能力和突出關聯(lián)的能力常被用于人工智能中。另一方面,機器學習技術常被用于實現(xiàn)推薦系統(tǒng)。例如,在Arcbees,我們使用了神經網絡和來自IMdB的數據成功建立了一個電影評分預測系統(tǒng)。神經網絡可以快速地執(zhí)行復雜的任務并輕松地處理大量數據。通過使用電影列表作為神經網絡的輸入,并將神經網絡的輸出與用戶評分進行比較,神經網絡可以自我學習規(guī)則以預測特定用戶的未來評分。
專家建議
在我讀過許多資料中,我注意到有兩個很重要的建議經常被推薦系統(tǒng)領域內的專家提及。第一,基于用戶付費的物品進行推薦。當一個用戶有購買意愿時,你就可以斷定他的評價一定是更具有相關性與準確的。第二,使用多種算法總是比改進一種算法要好。Netflix Prize競賽就是一個很好的例子。
實現(xiàn)一個基于物品的推薦系統(tǒng)
下面的代碼演示了實現(xiàn)一個基于物品的推薦系統(tǒng)是多么的簡單與快速。所使用的語言是Python,并使用了Pandas與Numpy這兩個在推薦系統(tǒng)領域中最流行的庫。所使用的數據是電影評分,數據集來自MovieLens。
第一步:尋找相似的電影
1.讀取數據
import pandas as pd
import numpy as np
ratings_cols = ['user_id', 'movie_id', 'rating']
ratings = pd.read_csv('u.data', sep='t', names=ratings_cols, usecols=range(3))
movies_cols = ['movie_id', 'title']
movies = pd.read_csv('u.item', sep='|', names=movies_cols, usecols=range(2))
ratings = pd.merge(ratings, movies)
2.構造用戶的電影矩陣
movieRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating')
3.選擇一部電影并生成這部電影與其他所有電影的相似度
starWarsRatings = movieRatings['Star Wars (1977)']
similarMovies = movieRatings.corrwith(starWarsRatings)
similarMovies = similarMovies.dropna()
df = pd.DataFrame(similarMovies)
4.去除不流行的電影以避免生成不合適的推薦
ratingsCount = 100
movieStats = ratings.groupby('title').agg({'rating': [np.size, np.mean]})
popularMovies = movieStats['rating']['size'] >= ratingsCount
movieStats[popularMovies].sort_values([('rating', 'mean')], ascending=False)[:15]
5.提取與目標電影相類似的流行電影
df = movieStats[popularMovies].join(pd.DataFrame(similarMovies, columns=['similarity']))
df.sort_values(['similarity'], ascending=False)[:15]
第二步:基于用戶的所有評分做出推薦
1.生成每兩部電影之間的相似度,并只保留流行電影的相似度
userRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating')
corrMatrix = userRatings.corr(method='pearson', min_periods=100)
2.對于每部用戶看過并評分過的電影,生成推薦(這里我們選擇用戶0)
myRatings = userRatings.loc[0].dropna()
simCandidates = pd.Series()
for i in range(0, len(myRatings.index)):
#取出與評分過電影相似的電影
sims = corrMatrix[myRatings.index[i]].dropna()
#以用戶對這部電影的評分高低來衡量它的相似性
sims = sims.map(lambda x: x * myRatings[i])
#將結果放入相似性候選列表中
simCandidates = simCandidates.append(sims)
simCandidates.sort_values(inplace = True, ascending = False)
3.將所有相同電影的相似度加和
simCandidates = simCandidates.groupby(simCandidates.index).sum()
simCandidates.sort_values(inplace = True, ascending = False)
4.只保留用戶沒有看過的電影
filteredSims = simCandidates.drop(myRatings.index)
如何更進一步?
在上面的實例中,Pandas與我們的CPU足以處理MovieLens的數據集。然而,當數據集變得更龐大時,處理的時間也會變得更加漫長。因此,你應該轉為使用具有更強大處理能力的解決方案,如Spark或MapReduce。
我希望我已經成功讓你看到,實現(xiàn)一個簡單而有效的推薦系統(tǒng)中并沒有什么復雜之處。如果你有任何問題,不要猶豫,直接評論就好了。
往期精彩回顧 本站qq群851320808,加入微信群請掃碼: