
一萬字詳解 Redis Cluster Gossip 協(xié)議
點擊上方"程序員歷小冰",選擇“置頂或者星標”
? ?你的關注意義重大!
大家好,我是歷小冰,今天來講一下 Reids Cluster 的 Gossip 協(xié)議和集群操作,文章的思維導圖如下所示。
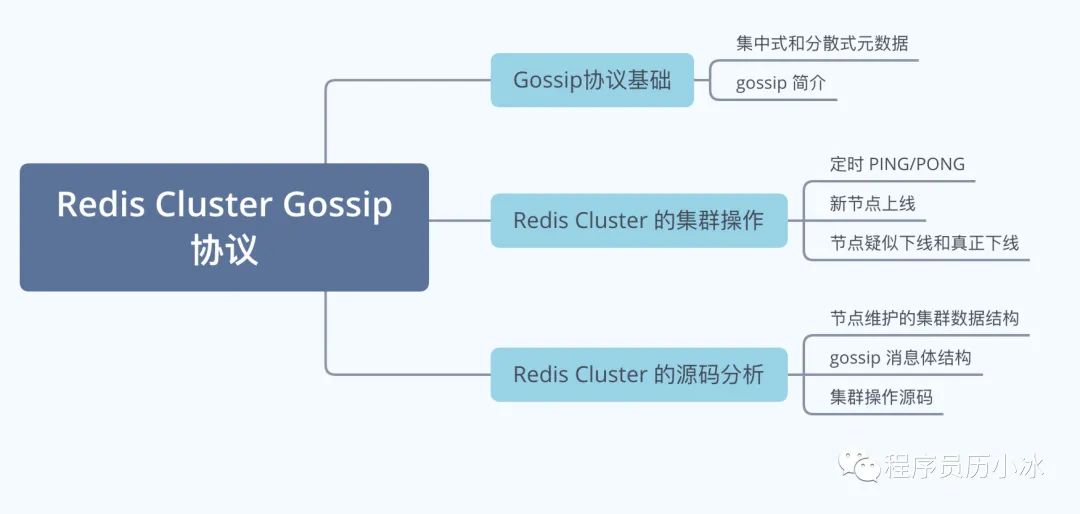
集群模式和 Gossip 簡介
對于數(shù)據(jù)存儲領域,當數(shù)據(jù)量或者請求流量大到一定程度后,就必然會引入分布式。比如 Redis,雖然其單機性能十分優(yōu)秀,但是因為下列原因時,也不得不引入集群。
單機無法保證高可用,需要引入多實例來提供高可用性 單機能夠提供高達 8W 左右的QPS,再高的QPS則需要引入多實例 單機能夠支持的數(shù)據(jù)量有限,處理更多的數(shù)據(jù)需要引入多實例; 單機所處理的網(wǎng)絡流量已經(jīng)超過服務器的網(wǎng)卡的上限值,需要引入多實例來分流。
有集群,集群往往需要維護一定的元數(shù)據(jù),比如實例的ip地址,緩存分片的 slots 信息等,所以需要一套分布式機制來維護元數(shù)據(jù)的一致性。這類機制一般有兩個模式:分散式和集中式
分散式機制將元數(shù)據(jù)存儲在部分或者所有節(jié)點上,不同節(jié)點之間進行不斷的通信來維護元數(shù)據(jù)的變更和一致性。Redis Cluster,Consul 等都是該模式。
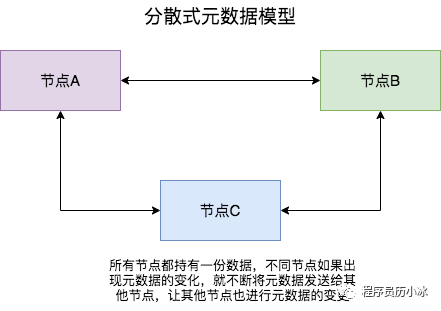
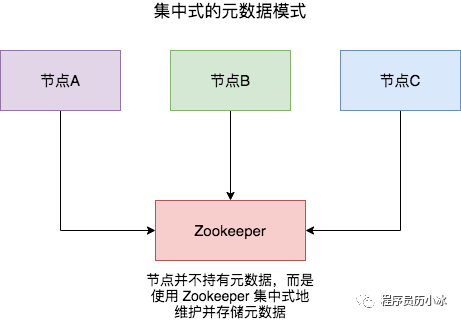
| 模式 | 優(yōu)點 | 缺點 |
|---|---|---|
| 集中式 | 數(shù)據(jù)更新及時,時效好,元數(shù)據(jù)的更新和讀取,時效性非常好,一旦元數(shù)據(jù)出現(xiàn)了變更,立即就更新到集中式的外部節(jié)點中,其他節(jié)點讀取的時候立即就可以感知到; | 較大數(shù)據(jù)更新壓力,更新壓力全部集中在外部節(jié)點,作為單點影響整個系統(tǒng) |
| 分散式 | 數(shù)據(jù)更新壓力分散,元數(shù)據(jù)的更新比較分散,不是集中某一個節(jié)點,更新請求比較分散,而且有不同節(jié)點處理,有一定的延時,降低了并發(fā)壓力 | 數(shù)據(jù)更新延遲,可能導致集群的感知有一定的滯后 |
分散式的元數(shù)據(jù)模式有多種可選的算法進行元數(shù)據(jù)的同步,比如說 Paxos、Raft 和 Gossip。Paxos 和 Raft 等都需要全部節(jié)點或者大多數(shù)節(jié)點(超過一半)正常運行,整個集群才能穩(wěn)定運行,而 Gossip 則不需要半數(shù)以上的節(jié)點運行。
Gossip 協(xié)議,顧名思義,就像流言蜚語一樣,利用一種隨機、帶有傳染性的方式,將信息傳播到整個網(wǎng)絡中,并在一定時間內(nèi),使得系統(tǒng)內(nèi)的所有節(jié)點數(shù)據(jù)一致。對你來說,掌握這個協(xié)議不僅能很好地理解這種最常用的,實現(xiàn)最終一致性的算法,也能在后續(xù)工作中得心應手地實現(xiàn)數(shù)據(jù)的最終一致性。
Gossip 協(xié)議又稱 epidemic 協(xié)議(epidemic protocol),是基于流行病傳播方式的節(jié)點或者進程之間信息交換的協(xié)議,在P2P網(wǎng)絡和分布式系統(tǒng)中應用廣泛,它的方法論也特別簡單:
在一個處于有界網(wǎng)絡的集群里,如果每個節(jié)點都隨機與其他節(jié)點交換特定信息,經(jīng)過足夠長的時間后,集群各個節(jié)點對該份信息的認知終將收斂到一致。
這里的“特定信息”一般就是指集群狀態(tài)、各節(jié)點的狀態(tài)以及其他元數(shù)據(jù)等。Gossip協(xié)議是完全符合 BASE 原則,可以用在任何要求最終一致性的領域,比如分布式存儲和注冊中心。另外,它可以很方便地實現(xiàn)彈性集群,允許節(jié)點隨時上下線,提供快捷的失敗檢測和動態(tài)負載均衡等。
此外,Gossip 協(xié)議的最大的好處是,即使集群節(jié)點的數(shù)量增加,每個節(jié)點的負載也不會增加很多,幾乎是恒定的。這就允許 Redis Cluster 或者 Consul 集群管理的節(jié)點規(guī)模能橫向擴展到數(shù)千個。
Redis Cluster 的 Gossip 通信機制
Redis Cluster 是在 3.0 版本引入集群功能。為了讓讓集群中的每個實例都知道其他所有實例的狀態(tài)信息,Redis 集群規(guī)定各個實例之間按照 Gossip 協(xié)議來通信傳遞信息。
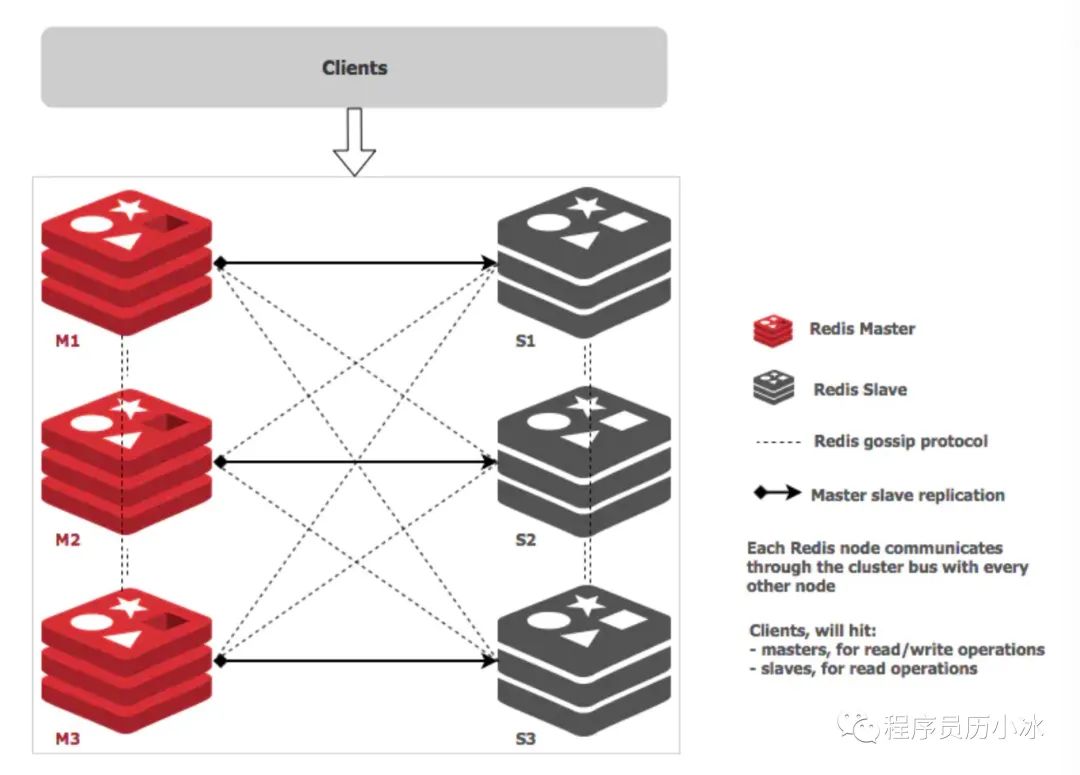
Redis Cluster 中的每個節(jié)點都維護一份自己視角下的當前整個集群的狀態(tài),主要包括:
當前集群狀態(tài) 集群中各節(jié)點所負責的 slots信息,及其migrate狀態(tài) 集群中各節(jié)點的master-slave狀態(tài) 集群中各節(jié)點的存活狀態(tài)及懷疑Fail狀態(tài)
也就是說上面的信息,就是集群中Node相互八卦傳播流言蜚語的內(nèi)容主題,而且比較全面,既有自己的更有別人的,這么一來大家都相互傳,最終信息就全面而且一致了。
Redis Cluster 的節(jié)點之間會相互發(fā)送多種消息,較為重要的如下所示:
MEET:通過「cluster meet ip port」命令,已有集群的節(jié)點會向新的節(jié)點發(fā)送邀請,加入現(xiàn)有集群,然后新節(jié)點就會開始與其他節(jié)點進行通信; PING:節(jié)點按照配置的時間間隔向集群中其他節(jié)點發(fā)送 ping 消息,消息中帶有自己的狀態(tài),還有自己維護的集群元數(shù)據(jù),和部分其他節(jié)點的元數(shù)據(jù); PONG: ?節(jié)點用于回應 PING 和 MEET 的消息,結構和 PING 消息類似,也包含自己的狀態(tài)和其他信息,也可以用于信息廣播和更新; FAIL: 節(jié)點 PING 不通某節(jié)點后,會向集群所有節(jié)點廣播該節(jié)點掛掉的消息。其他節(jié)點收到消息后標記已下線。
Redis 的源碼中 cluster.h 文件定義了全部的消息類型,代碼為 redis 4.0版本。
//?注意,PING 、 PONG 和 MEET 實際上是同一種消息。
//?PONG?是對?PING?的回復,它的實際格式也為?PING?消息,
//?而?MEET?則是一種特殊的?PING?消息,用于強制消息的接收者將消息的發(fā)送者添加到集群中(如果節(jié)點尚未在節(jié)點列表中的話)
#define?CLUSTERMSG_TYPE_PING?0??????????/*?Ping?消息?*/
#define?CLUSTERMSG_TYPE_PONG?1??????????/*?Pong?用于回復Ping?*/
#define?CLUSTERMSG_TYPE_MEET?2??????????/*?Meet?請求將某個節(jié)點添加到集群中?*/
#define?CLUSTERMSG_TYPE_FAIL?3??????????/*?Fail?將某個節(jié)點標記為?FAIL?*/
#define?CLUSTERMSG_TYPE_PUBLISH?4???????/*?通過發(fā)布與訂閱功能廣播消息?*/
#define?CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST?5?/*?請求進行故障轉移操作,要求消息的接收者通過投票來支持消息的發(fā)送者?*/
#define?CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK?6?????/*?消息的接收者同意向消息的發(fā)送者投票?*/
#define?CLUSTERMSG_TYPE_UPDATE?7????????/*?slots?已經(jīng)發(fā)生變化,消息發(fā)送者要求消息接收者進行相應的更新?*/
#define?CLUSTERMSG_TYPE_MFSTART?8???????/*?為了進行手動故障轉移,暫停各個客戶端?*/
#define?CLUSTERMSG_TYPE_COUNT?9?????????/*?消息總數(shù)?*/
通過上述這些消息,集群中的每一個實例都能獲得其它所有實例的狀態(tài)信息。這樣一來,即使有新節(jié)點加入、節(jié)點故障、Slot 變更等事件發(fā)生,實例間也可以通過 PING、PONG 消息的傳遞,完成集群狀態(tài)在每個實例上的同步。下面,我們依次來看看幾種常見的場景。
定時 PING/PONG 消息
Redis Cluster 中的節(jié)點都會定時地向其他節(jié)點發(fā)送 PING 消息,來交換各個節(jié)點狀態(tài)信息,檢查各個節(jié)點狀態(tài),包括在線狀態(tài)、疑似下線狀態(tài) PFAIL 和已下線狀態(tài) FAIL。
Redis 集群的定時 PING/PONG 的工作原理可以概括成兩點:
一是,每個實例之間會按照一定的頻率,從集群中隨機挑選一些實例,把 PING 消息發(fā)送給挑選出來的實例,用來檢測這些實例是否在線,并交換彼此的狀態(tài)信息。PING 消息中封裝了發(fā)送消息的實例自身的狀態(tài)信息、部分其它實例的狀態(tài)信息,以及 Slot 映射表。 二是,一個實例在接收到 PING 消息后,會給發(fā)送 PING 消息的實例,發(fā)送一個 PONG 消息。PONG 消息包含的內(nèi)容和 PING 消息一樣。
下圖顯示了兩個實例間進行 PING、PONG 消息傳遞的情況,其中實例一為發(fā)送節(jié)點,實例二是接收節(jié)點

新節(jié)點上線
Redis Cluster 加入新節(jié)點時,客戶端需要執(zhí)行 CLUSTER MEET 命令,如下圖所示。
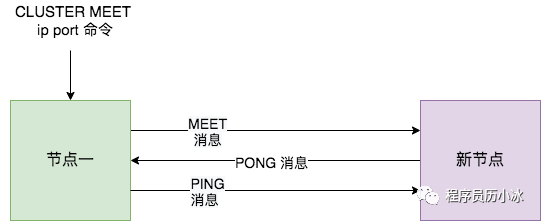
節(jié)點一在執(zhí)行 CLUSTER MEET 命令時會首先為新節(jié)點創(chuàng)建一個 clusterNode 數(shù)據(jù),并將其添加到自己維護的 clusterState 的 nodes 字典中。有關 clusterState 和 clusterNode 關系,我們在最后一節(jié)會有詳盡的示意圖和源碼來講解。
然后節(jié)點一會根據(jù)據(jù) CLUSTER MEET 命令中的 IP 地址和端口號,向新節(jié)點發(fā)送一條 MEET 消息。新節(jié)點接收到節(jié)點一發(fā)送的MEET消息后,新節(jié)點也會為節(jié)點一創(chuàng)建一個 clusterNode 結構,并將該結構添加到自己維護的 clusterState 的 nodes 字典中。
接著,新節(jié)點向節(jié)點一返回一條PONG消息。節(jié)點一接收到節(jié)點B返回的PONG消息后,得知新節(jié)點已經(jīng)成功的接收了自己發(fā)送的MEET消息。
最后,節(jié)點一還會向新節(jié)點發(fā)送一條 PING 消息。新節(jié)點接收到該條 PING 消息后,可以知道節(jié)點A已經(jīng)成功的接收到了自己返回的P ONG消息,從而完成了新節(jié)點接入的握手操作。
MEET 操作成功之后,節(jié)點一會通過稍早時講的定時 PING 機制將新節(jié)點的信息發(fā)送給集群中的其他節(jié)點,讓其他節(jié)點也與新節(jié)點進行握手,最終,經(jīng)過一段時間后,新節(jié)點會被集群中的所有節(jié)點認識。
節(jié)點疑似下線和真正下線
Redis Cluster 中的節(jié)點會定期檢查已經(jīng)發(fā)送 PING 消息的接收方節(jié)點是否在規(guī)定時間 ( cluster-node-timeout ) 內(nèi)返回了 PONG 消息,如果沒有則會將其標記為疑似下線狀態(tài),也就是 PFAIL 狀態(tài),如下圖所示。

然后,節(jié)點一會通過 PING 消息,將節(jié)點二處于疑似下線狀態(tài)的信息傳遞給其他節(jié)點,例如節(jié)點三。節(jié)點三接收到節(jié)點一的 PING 消息得知節(jié)點二進入 PFAIL 狀態(tài)后,會在自己維護的 clusterState 的 nodes 字典中找到節(jié)點二所對應的 clusterNode 結構,并將主節(jié)點一的下線報告添加到 clusterNode 結構的 fail_reports 鏈表中。

隨著時間的推移,如果節(jié)點十 (舉個例子) 也因為 PONG 超時而認為節(jié)點二疑似下線了,并且發(fā)現(xiàn)自己維護的節(jié)點二的 clusterNode 的 fail_reports 中有半數(shù)以上的主節(jié)點數(shù)量的未過時的將節(jié)點二標記為 PFAIL 狀態(tài)報告日志,那么節(jié)點十將會把節(jié)點二將被標記為已下線 FAIL 狀態(tài),并且節(jié)點十會立刻向集群其他節(jié)點廣播主節(jié)點二已經(jīng)下線的 FAIL 消息,所有收到 FAIL 消息的節(jié)點都會立即將節(jié)點二狀態(tài)標記為已下線。如下圖所示。
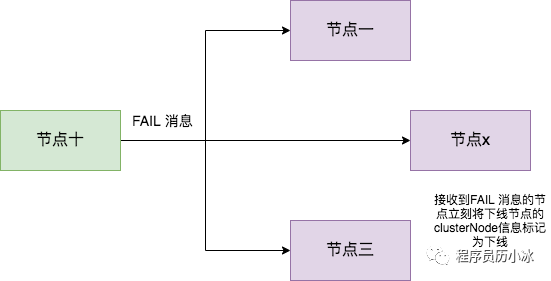
需要注意的是,報告疑似下線記錄是由時效性的,如果超過 cluster-node-timeout *2 的時間,這個報告就會被忽略掉,讓節(jié)點二又恢復成正常狀態(tài)。
Redis Cluster 通信源碼實現(xiàn)
綜上,我們了解了 Redis Cluster 在定時 PING/PONG、新節(jié)點上線、節(jié)點疑似下線和真正下線等環(huán)節(jié)的原理和操作流程,下面我們來真正看一下 Redis 在這些環(huán)節(jié)的源碼實現(xiàn)和具體操作。
涉及的數(shù)據(jù)結構體
首先,我們先來講解一下其中涉及的數(shù)據(jù)結構,也就是上文提到的 ClusterNode 等結構。
每個節(jié)點都會維護一個 clusterState 結構,表示當前集群的整體狀態(tài),它的定義如下所示。
typedef?struct?clusterState?{
???clusterNode?*myself;??/*?當前節(jié)點的clusterNode信息?*/
???....
???dict?*nodes;??????????/*?name到clusterNode的字典?*/
???....
???clusterNode?*slots[CLUSTER_SLOTS];?/*?slot?和節(jié)點的對應關系*/
???....
}?clusterState;
它有三個比較關鍵的字段,具體示意圖如下所示:
myself 字段,是一個 clusterNode 結構,用來記錄自己的狀態(tài); nodes 字典,記錄一個 name 到 clusterNode 結構的映射,以此來記錄其他節(jié)點的狀態(tài); slot 數(shù)組,記錄slot 對應的節(jié)點 clusterNode結構。
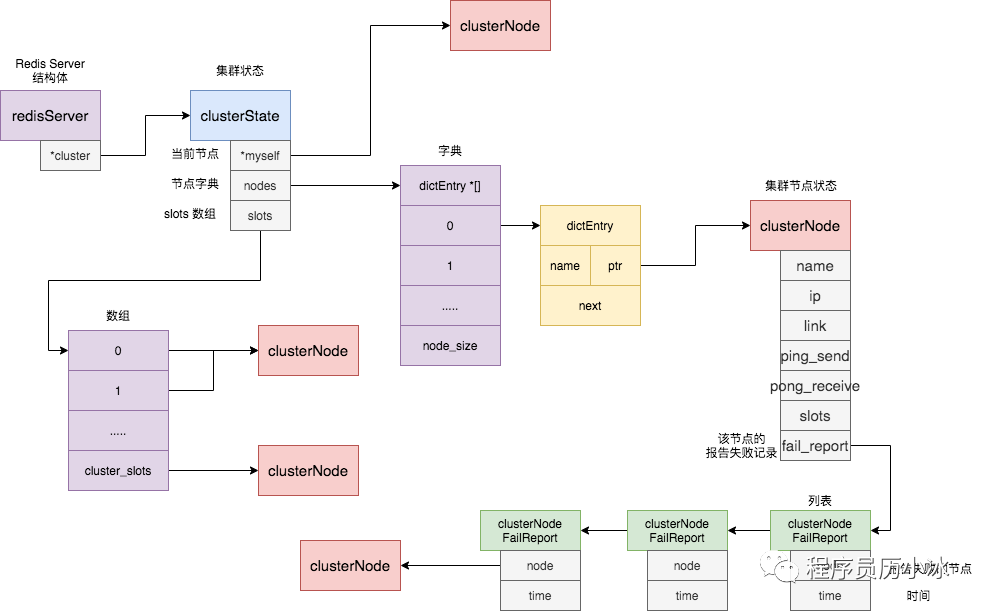
clusterNode 結構保存了一個節(jié)點的當前狀態(tài),比如節(jié)點的創(chuàng)建時間、節(jié)點的名字、節(jié)點 當前的配置紀元、節(jié)點的IP地址和端口號等等。除此之外,clusterNode結構的 link 屬性是一個clusterLink結構,該結構保存了連接節(jié)點所需的有關信息**,比如**套接字描述符,輸入緩沖區(qū)和輸出緩沖區(qū)。clusterNode 還有一個 fail_report 的列表,用來記錄疑似下線報告。具體定義如下所示。
typedef?struct?clusterNode?{
????mstime_t?ctime;?/*?創(chuàng)建節(jié)點的時間?*/
????char?name[CLUSTER_NAMELEN];?/*?節(jié)點的名字?*/
????int?flags;??????/*?節(jié)點標識,標記節(jié)點角色或者狀態(tài),比如主節(jié)點從節(jié)點或者在線和下線?*/
????uint64_t?configEpoch;?/*?當前節(jié)點已知的集群統(tǒng)一epoch?*/
????unsigned?char?slots[CLUSTER_SLOTS/8];?/*?slots?handled?by?this?node?*/
????int?numslots;???/*?Number?of?slots?handled?by?this?node?*/
????int?numslaves;??/*?Number?of?slave?nodes,?if?this?is?a?master?*/
????struct?clusterNode?**slaves;?/*?pointers?to?slave?nodes?*/
????struct?clusterNode?*slaveof;?/*?pointer?to?the?master?node.?Note?that?it
????????????????????????????????????may?be?NULL?even?if?the?node?is?a?slave
????????????????????????????????????if?we?don't?have?the?master?node?in?our
????????????????????????????????????tables.?*/
????mstime_t?ping_sent;??????/*?當前節(jié)點最后一次向該節(jié)點發(fā)送?PING?消息的時間?*/
????mstime_t?pong_received;??/*?當前節(jié)點最后一次收到該節(jié)點?PONG?消息的時間?*/
????mstime_t?fail_time;??????/*?FAIL?標志位被設置的時間?*/
????mstime_t?voted_time;?????/*?Last?time?we?voted?for?a?slave?of?this?master?*/
????mstime_t?repl_offset_time;??/*?Unix?time?we?received?offset?for?this?node?*/
????mstime_t?orphaned_time;?????/*?Starting?time?of?orphaned?master?condition?*/
????long?long?repl_offset;??????/*?當前節(jié)點的repl便宜?*/
????char?ip[NET_IP_STR_LEN];??/*?節(jié)點的IP?地址?*/
????int?port;???????????????????/*?端口?*/
????int?cport;??????????????????/*?通信端口,一般是端口+1000?*/
????clusterLink?*link;??????????/*?和該節(jié)點的?tcp?連接?*/
????list?*fail_reports;?????????/*?下線記錄列表?*/
}?clusterNode;
clusterNodeFailReport 是記錄節(jié)點下線報告的結構體, node 是報告節(jié)點的信息,而 time 則代表著報告時間。
typedef?struct?clusterNodeFailReport?{
????struct?clusterNode?*node;??/*?報告當前節(jié)點已經(jīng)下線的節(jié)點?*/
????mstime_t?time;?????????????/*?報告時間?*/
}?clusterNodeFailReport;
消息結構體
了解了 Reids 節(jié)點維護的數(shù)據(jù)結構體后,我們再來看節(jié)點進行通信的消息結構體。通信消息最外側的結構體為 clusterMsg,它包括了很多消息記錄信息,包括 RCmb 標志位,消息總長度,消息協(xié)議版本,消息類型;它還包括了發(fā)送該消息節(jié)點的記錄信息,比如節(jié)點名稱,節(jié)點負責的slot信息,節(jié)點ip和端口等;最后它包含了一個 clusterMsgData 來攜帶具體類型的消息。
typedef?struct?{
????char?sig[4];????????/*?標志位,"RCmb"?(Redis?Cluster?message?bus).?*/
????uint32_t?totlen;????/*?消息總長度?*/
????uint16_t?ver;???????/*?消息協(xié)議版本?*/
????uint16_t?port;??????/*?端口?*/
????uint16_t?type;??????/*?消息類型?*/
????uint16_t?count;?????/*??*/
????uint64_t?currentEpoch;??/*?表示本節(jié)點當前記錄的整個集群的統(tǒng)一的epoch,用來決策選舉投票等,與configEpoch不同的是:configEpoch表示的是master節(jié)點的唯一標志,currentEpoch是集群的唯一標志。?*/
????uint64_t?configEpoch;???/*?每個master節(jié)點都有一個唯一的configEpoch做標志,如果和其他master節(jié)點沖突,會強制自增使本節(jié)點在集群中唯一?*/
????uint64_t?offset;????/*?主從復制偏移相關信息,主節(jié)點和從節(jié)點含義不同?*/
????char?sender[CLUSTER_NAMELEN];?/*?發(fā)送節(jié)點的名稱?*/
????unsigned?char?myslots[CLUSTER_SLOTS/8];?/*?本節(jié)點負責的slots信息,16384/8個char數(shù)組,一共為16384bit?*/
????char?slaveof[CLUSTER_NAMELEN];?/*?master信息,假如本節(jié)點是slave節(jié)點的話,協(xié)議帶有master信息?*/
????char?myip[NET_IP_STR_LEN];????/*?IP?*/
????char?notused1[34];??/*?保留字段?*/
????uint16_t?cport;??????/*?集群的通信端口?*/
????uint16_t?flags;??????/*?本節(jié)點當前的狀態(tài),比如?CLUSTER_NODE_HANDSHAKE、CLUSTER_NODE_MEET?*/
????unsigned?char?state;?/*?Cluster?state?from?the?POV?of?the?sender?*/
????unsigned?char?mflags[3];?/*?本條消息的類型,目前只有兩類:CLUSTERMSG_FLAG0_PAUSED、CLUSTERMSG_FLAG0_FORCEACK */
????union?clusterMsgData?data;
}?clusterMsg;
clusterMsgData 是一個 union 結構體,它可以為 PING,MEET,PONG 或者 FAIL 等消息體。其中當消息為 PING、MEET 和 PONG 類型時,ping 字段是被賦值的,而是 FAIL 類型時,fail 字段是被賦值的。
//?注意這是?union?關鍵字
union?clusterMsgData?{
????/*?PING,?MEET?或者?PONG?消息時,ping?字段被賦值?*/
????struct?{
????????/*?Array?of?N?clusterMsgDataGossip?structures?*/
????????clusterMsgDataGossip?gossip[1];
????}?ping;
????/*??FAIL?消息時,fail?被賦值?*/
????struct?{
????????clusterMsgDataFail?about;
????}?fail;
????//?....?省略?publish?和?update?消息的字段
};
clusterMsgDataGossip 是 PING、PONG 和 MEET 消息的結構體,它會包括發(fā)送消息節(jié)點維護的其他節(jié)點信息,也就是上文中 clusterState 中 nodes 字段包含的信息,具體代碼如下所示,你也會發(fā)現(xiàn)二者的字段是類似的。
typedef?struct?{
?/*?節(jié)點的名字,默認是隨機的,MEET消息發(fā)送并得到回復后,集群會為該節(jié)點設置正式的名稱*/
????char?nodename[CLUSTER_NAMELEN];?
????uint32_t?ping_sent;?/*?發(fā)送節(jié)點最后一次給接收節(jié)點發(fā)送?PING?消息的時間戳,收到對應?PONG?回復后會被賦值為0?*/
????uint32_t?pong_received;?/*?發(fā)送節(jié)點最后一次收到接收節(jié)點發(fā)送?PONG?消息的時間戳?*/
????char?ip[NET_IP_STR_LEN];??/*?IP?address?last?time?it?was?seen?*/
????uint16_t?port;???????/*?IP*/???????
????uint16_t?cport;??????/*?端口*/??
????uint16_t?flags;??????/*?標識*/?
????uint32_t?notused1;???/*?對齊字符*/
}?clusterMsgDataGossip;
typedef?struct?{
????char?nodename[CLUSTER_NAMELEN];?/*?下線節(jié)點的名字?*/
}?clusterMsgDataFail;
看完了節(jié)點維護的數(shù)據(jù)結構體和發(fā)送的消息結構體后,我們就來看看 Redis 的具體行為源碼了。
隨機周期性發(fā)送PING消息
Redis 的 clusterCron 函數(shù)會被定時調(diào)用,每被執(zhí)行10次,就會準備向隨機的一個節(jié)點發(fā)送 PING 消息。
它會先隨機的選出 5 個節(jié)點,然后從中選擇最久沒有與之通信的節(jié)點,調(diào)用 clusterSendPing 函數(shù)發(fā)送類型為 CLUSTERMSG_TYPE_PING 的消息
//?cluster.c?文件?
//?clusterCron()?每執(zhí)行?10?次(至少間隔一秒鐘),就向一個隨機節(jié)點發(fā)送?gossip?信息
if?(!(iteration?%?10))?{
????int?j;
????/*?隨機?5?個節(jié)點,選出其中一個?*/
????for?(j?=?0;?j?5;?j++)?{
????????de?=?dictGetRandomKey(server.cluster->nodes);
????????clusterNode?*this?=?dictGetVal(de);
????????/*?不要?PING?連接斷開的節(jié)點,也不要?PING?最近已經(jīng)?PING?過的節(jié)點?*/
????????if?(this->link?==?NULL?||?this->ping_sent?!=?0)?continue;
????????if?(this->flags?&?(CLUSTER_NODE_MYSELF|CLUSTER_NODE_HANDSHAKE))
????????????continue;
????????/*?對比?pong_received?字段,選出更長時間未收到其?PONG?消息的節(jié)點(表示好久沒有接受到該節(jié)點的PONG消息了)?*/
????????if?(min_pong_node?==?NULL?||?min_pong?>?this->pong_received)?{
????????????min_pong_node?=?this;
????????????min_pong?=?this->pong_received;
????????}
????}
????/*?向最久沒有收到?PONG?回復的節(jié)點發(fā)送?PING?命令?*/
????if?(min_pong_node)?{
????????serverLog(LL_DEBUG,"Pinging?node?%.40s",?min_pong_node->name);
????????clusterSendPing(min_pong_node->link,?CLUSTERMSG_TYPE_PING);
????}
}
clusterSendPing 函數(shù)的具體行為我們后續(xù)再了解,因為該函數(shù)在其他環(huán)節(jié)也會經(jīng)常用到
節(jié)點加入集群
當節(jié)點執(zhí)行 CLUSTER MEET 命令后,會在自身給新節(jié)點維護一個 clusterNode 結構體,該結構體的 link 也就是TCP連接字段是 null,表示是新節(jié)點尚未建立連接。
clusterCron 函數(shù)中也會處理這些未建立連接的新節(jié)點,調(diào)用 createClusterLink 創(chuàng)立連接,然后調(diào)用 clusterSendPing 函數(shù)來發(fā)送 MEET 消息
/*?cluster.c?clusterCron?函數(shù)部分,為未創(chuàng)建連接的節(jié)點創(chuàng)建連接?*/
if?(node->link?==?NULL)?{
????int?fd;
????mstime_t?old_ping_sent;
????clusterLink?*link;
????/*?和該節(jié)點建立連接?*/
????fd?=?anetTcpNonBlockBindConnect(server.neterr,?node->ip,
????????node->cport,?NET_FIRST_BIND_ADDR);
????/*?....?fd?為-1時的異常處理?*/
????/*?建立?link?*/
????link?=?createClusterLink(node);
????link->fd?=?fd;
????node->link?=?link;
????aeCreateFileEvent(server.el,link->fd,AE_READABLE,
????????????clusterReadHandler,link);
????/*?向新連接的節(jié)點發(fā)送?PING?命令,防止節(jié)點被識進入下線?*/
????/*?如果節(jié)點被標記為?MEET?,那么發(fā)送?MEET?命令,否則發(fā)送?PING?命令?*/
????old_ping_sent?=?node->ping_sent;
????clusterSendPing(link,?node->flags?&?CLUSTER_NODE_MEET??
????????????CLUSTERMSG_TYPE_MEET?:?CLUSTERMSG_TYPE_PING);
????/*?....?*/
????/*?如果當前節(jié)點(發(fā)送者)沒能收到 MEET 信息的回復,那么它將不再向目標節(jié)點發(fā)送命令。*/
????/*?如果接收到回復的話,那么節(jié)點將不再處于?HANDSHAKE?狀態(tài),并繼續(xù)向目標節(jié)點發(fā)送普通?PING?命令*/
????node->flags?&=?~CLUSTER_NODE_MEET;
}
防止節(jié)點假超時及狀態(tài)過期
防止節(jié)點假超時和標記疑似下線標記也是在 clusterCron 函數(shù)中,具體如下所示。它會檢查當前所有的 nodes 節(jié)點列表,如果發(fā)現(xiàn)某個節(jié)點與自己的最后一個 PONG 通信時間超過了預定的閾值的一半時,為了防止節(jié)點是假超時,會主動釋放掉與之的 link 連接,然后會主動向它發(fā)送一個 PING 消息。
/*?cluster.c?clusterCron?函數(shù)部分,遍歷節(jié)點來檢查?fail?的節(jié)點*/
while((de?=?dictNext(di))?!=?NULL)?{
????clusterNode?*node?=?dictGetVal(de);
????now?=?mstime();?/*?Use?an?updated?time?at?every?iteration.?*/
????mstime_t?delay;
????/*?如果等到?PONG?到達的時間超過了?node?timeout?一半的連接?*/
????/*?因為盡管節(jié)點依然正常,但連接可能已經(jīng)出問題了?*/
????if?(node->link?&&?/*?is?connected?*/
????????now?-?node->link->ctime?>
????????server.cluster_node_timeout?&&?/*?還未重連?*/
????????node->ping_sent?&&?/*?已經(jīng)發(fā)過ping消息?*/
????????node->pong_received?ping_sent?&&?/*?還在等待pong消息?*/
????????/*?等待pong消息超過了?timeout/2?*/
????????now?-?node->ping_sent?>?server.cluster_node_timeout/2)
????{
????????/*?釋放連接,下次?clusterCron()?會自動重連?*/
????????freeClusterLink(node->link);
????}
????/*?如果目前沒有在?PING?節(jié)點*/
????/*?并且已經(jīng)有?node?timeout?一半的時間沒有從節(jié)點那里收到?PONG?回復?*/
????/*?那么向節(jié)點發(fā)送一個?PING?,確保節(jié)點的信息不會太舊,有可能一直沒有隨機中?*/
????if?(node->link?&&
????????node->ping_sent?==?0?&&
????????(now?-?node->pong_received)?>?server.cluster_node_timeout/2)
????{
????????clusterSendPing(node->link,?CLUSTERMSG_TYPE_PING);
????????continue;
????}
????/*?....?處理failover和標記遺失下線?*/
}
處理failover和標記疑似下線
如果防止節(jié)點假超時處理后,節(jié)點依舊未收到目標節(jié)點的 PONG 消息,并且時間已經(jīng)超過了 cluster_node_timeout,那么就將該節(jié)點標記為疑似下線狀態(tài)。
/*?如果這是一個主節(jié)點,并且有一個從服務器請求進行手動故障轉移,那么向從服務器發(fā)送?PING*/
if?(server.cluster->mf_end?&&
????nodeIsMaster(myself)?&&
????server.cluster->mf_slave?==?node?&&
????node->link)
{
????clusterSendPing(node->link,?CLUSTERMSG_TYPE_PING);
????continue;
}
/*?后續(xù)代碼只在節(jié)點發(fā)送了?PING?命令的情況下執(zhí)行*/
if?(node->ping_sent?==?0)?continue;
/*?計算等待?PONG?回復的時長?*/?
delay?=?now?-?node->ping_sent;
/*?等待?PONG?回復的時長超過了限制值,將目標節(jié)點標記為?PFAIL?(疑似下線)*/
if?(delay?>?server.cluster_node_timeout)?{
????/*?超時了,標記為疑似下線?*/
????if?(!(node->flags?&?(REDIS_NODE_PFAIL|REDIS_NODE_FAIL)))?{
????????redisLog(REDIS_DEBUG,"***?NODE?%.40s?possibly?failing",
????????????node->name);
????????//?打開疑似下線標記
????????node->flags?|=?REDIS_NODE_PFAIL;
????????update_state?=?1;
????}
}
實際發(fā)送Gossip消息
以下是前方多次調(diào)用過的clusterSendPing()方法的源碼,代碼中有詳細的注釋,大家可以自行閱讀。主要的操作就是將節(jié)點自身維護的 clusterState 轉換為對應的消息結構體,。
/*?向指定節(jié)點發(fā)送一條?MEET?、?PING?或者?PONG?消息?*/
void?clusterSendPing(clusterLink?*link,?int?type)?{
????unsigned?char?*buf;
????clusterMsg?*hdr;
????int?gossipcount?=?0;?/*?Number?of?gossip?sections?added?so?far.?*/
????int?wanted;?/*?Number?of?gossip?sections?we?want?to?append?if?possible.?*/
????int?totlen;?/*?Total?packet?length.?*/
????//?freshnodes?是用于發(fā)送?gossip?信息的計數(shù)器
????//?每次發(fā)送一條信息時,程序將?freshnodes?的值減一
????//?當?freshnodes?的數(shù)值小于等于?0?時,程序停止發(fā)送?gossip?信息
????//?freshnodes?的數(shù)量是節(jié)點目前的?nodes?表中的節(jié)點數(shù)量減去?2?
????//?這里的?2?指兩個節(jié)點,一個是?myself?節(jié)點(也即是發(fā)送信息的這個節(jié)點)
????//?另一個是接受?gossip?信息的節(jié)點
????int?freshnodes?=?dictSize(server.cluster->nodes)-2;
????
????/*?計算要攜帶多少節(jié)點的信息,最少3個,最多?1/10?集群總節(jié)點數(shù)量*/
????wanted?=?floor(dictSize(server.cluster->nodes)/10);
????if?(wanted?3)?wanted?=?3;
????if?(wanted?>?freshnodes)?wanted?=?freshnodes;
????/*?....?省略?totlen?的計算等*/
????/*?如果發(fā)送的信息是?PING?,那么更新最后一次發(fā)送?PING?命令的時間戳?*/
????if?(link->node?&&?type?==?CLUSTERMSG_TYPE_PING)
????????link->node->ping_sent?=?mstime();
????/*?將當前節(jié)點的信息(比如名字、地址、端口號、負責處理的槽)記錄到消息里面?*/
????clusterBuildMessageHdr(hdr,type);
????/*?Populate?the?gossip?fields?*/
????int?maxiterations?=?wanted*3;
????/*?每個節(jié)點有?freshnodes?次發(fā)送?gossip?信息的機會
???????每次向目標節(jié)點發(fā)送?2?個被選中節(jié)點的?gossip?信息(gossipcount?計數(shù))?*/
????while(freshnodes?>?0?&&?gossipcount?????????/*?從?nodes?字典中隨機選出一個節(jié)點(被選中節(jié)點)?*/
????????dictEntry?*de?=?dictGetRandomKey(server.cluster->nodes);
????????clusterNode?*this?=?dictGetVal(de);
????????/*?以下節(jié)點不能作為被選中節(jié)點:
?????????* Myself:節(jié)點本身。
?????????*?PFAIL狀態(tài)的節(jié)點
?????????*?處于 HANDSHAKE 狀態(tài)的節(jié)點。
?????????*?帶有?NOADDR?標識的節(jié)點
?????????*?因為不處理任何?Slot?而被斷開連接的節(jié)點?
?????????*/
????????if?(this?==?myself)?continue;
????????if?(this->flags?&?CLUSTER_NODE_PFAIL)?continue;
????????if?(this->flags?&?(CLUSTER_NODE_HANDSHAKE|CLUSTER_NODE_NOADDR)?||
????????????(this->link?==?NULL?&&?this->numslots?==?0))
????????{
????????????freshnodes--;?/*?Tecnically?not?correct,?but?saves?CPU.?*/
????????????continue;
????????}
????????//?檢查被選中節(jié)點是否已經(jīng)在?hdr->data.ping.gossip?數(shù)組里面
????????//?如果是的話說明這個節(jié)點之前已經(jīng)被選中了
????????//?不要再選中它(否則就會出現(xiàn)重復)
????????if?(clusterNodeIsInGossipSection(hdr,gossipcount,this))?continue;
????????/*?這個被選中節(jié)點有效,計數(shù)器減一?*/
????????clusterSetGossipEntry(hdr,gossipcount,this);
????????freshnodes--;
????????gossipcount++;
????}
????/*?....?如果有?PFAIL?節(jié)點,最后添加?*/
????/*?計算信息長度?*/
????totlen?=?sizeof(clusterMsg)-sizeof(union?clusterMsgData);
????totlen?+=?(sizeof(clusterMsgDataGossip)*gossipcount);
????/*?將被選中節(jié)點的數(shù)量(gossip?信息中包含了多少個節(jié)點的信息)記錄在?count?屬性里面*/
????hdr->count?=?htons(gossipcount);
????/*?將信息的長度記錄到信息里面?*/
????hdr->totlen?=?htonl(totlen);
????/*?發(fā)送網(wǎng)絡請求?*/
????clusterSendMessage(link,buf,totlen);
????zfree(buf);
}
void?clusterSetGossipEntry(clusterMsg?*hdr,?int?i,?clusterNode?*n)?{
????clusterMsgDataGossip?*gossip;
????/*?指向?gossip?信息結構?*/
????gossip?=?&(hdr->data.ping.gossip[i]);
????/*?將被選中節(jié)點的名字記錄到?gossip?信息?*/???
????memcpy(gossip->nodename,n->name,CLUSTER_NAMELEN);
????/*?將被選中節(jié)點的?PING?命令發(fā)送時間戳記錄到?gossip?信息?*/
????gossip->ping_sent?=?htonl(n->ping_sent/1000);
????/*?將被選中節(jié)點的?PONG?命令回復的時間戳記錄到?gossip?信息?*/
????gossip->pong_received?=?htonl(n->pong_received/1000);
????/*?將被選中節(jié)點的?IP?記錄到?gossip?信息?*/
????memcpy(gossip->ip,n->ip,sizeof(n->ip));
????/*?將被選中節(jié)點的端口號記錄到?gossip?信息?*/
????gossip->port?=?htons(n->port);
????gossip->cport?=?htons(n->cport);
????/*?將被選中節(jié)點的標識值記錄到?gossip?信息?*/
????gossip->flags?=?htons(n->flags);
????gossip->notused1?=?0;
}
下面是 clusterBuildMessageHdr 函數(shù),它主要負責填充消息結構體中的基礎信息和當前節(jié)點的狀態(tài)信息。
/*?構建消息的?header?*/
void?clusterBuildMessageHdr(clusterMsg?*hdr,?int?type)?{
????int?totlen?=?0;
????uint64_t?offset;
????clusterNode?*master;
????/*?如果當前節(jié)點是salve,則master為其主節(jié)點,如果當前節(jié)點是master節(jié)點,則master就是當前節(jié)點?*/
????master?=?(nodeIsSlave(myself)?&&?myself->slaveof)??
??????????????myself->slaveof?:?myself;
????memset(hdr,0,sizeof(*hdr));
????/*?初始化協(xié)議版本、標識、及類型,?*/
????hdr->ver?=?htons(CLUSTER_PROTO_VER);
????hdr->sig[0]?=?'R';
????hdr->sig[1]?=?'C';
????hdr->sig[2]?=?'m';
????hdr->sig[3]?=?'b';
????hdr->type?=?htons(type);
????/*?消息頭設置當前節(jié)點id?*/
????memcpy(hdr->sender,myself->name,CLUSTER_NAMELEN);
????/*?消息頭設置當前節(jié)點ip?*/
????memset(hdr->myip,0,NET_IP_STR_LEN);
????if?(server.cluster_announce_ip)?{
????????strncpy(hdr->myip,server.cluster_announce_ip,NET_IP_STR_LEN);
????????hdr->myip[NET_IP_STR_LEN-1]?=?'\0';
????}
????/*?基礎端口及集群內(nèi)節(jié)點通信端口?*/
????int?announced_port?=?server.cluster_announce_port??
?????????????????????????server.cluster_announce_port?:?server.port;
????int?announced_cport?=?server.cluster_announce_bus_port??
??????????????????????????server.cluster_announce_bus_port?:
??????????????????????????(server.port?+?CLUSTER_PORT_INCR);
????/*?設置當前節(jié)點的槽信息?*/
????memcpy(hdr->myslots,master->slots,sizeof(hdr->myslots));
????memset(hdr->slaveof,0,CLUSTER_NAMELEN);
????if?(myself->slaveof?!=?NULL)
????????memcpy(hdr->slaveof,myself->slaveof->name,?CLUSTER_NAMELEN);
????hdr->port?=?htons(announced_port);
????hdr->cport?=?htons(announced_cport);
????hdr->flags?=?htons(myself->flags);
????hdr->state?=?server.cluster->state;
????/*?設置?currentEpoch?and?configEpochs.?*/
????hdr->currentEpoch?=?htonu64(server.cluster->currentEpoch);
????hdr->configEpoch?=?htonu64(master->configEpoch);
????/*?設置復制偏移量?*/
????if?(nodeIsSlave(myself))
????????offset?=?replicationGetSlaveOffset();
????else
????????offset?=?server.master_repl_offset;
????hdr->offset?=?htonu64(offset);
????/*?Set?the?message?flags.?*/
????if?(nodeIsMaster(myself)?&&?server.cluster->mf_end)
????????hdr->mflags[0]?|=?CLUSTERMSG_FLAG0_PAUSED;
????/*?計算并設置消息的總長度?*/
????if?(type?==?CLUSTERMSG_TYPE_FAIL)?{
????????totlen?=?sizeof(clusterMsg)-sizeof(union?clusterMsgData);
????????totlen?+=?sizeof(clusterMsgDataFail);
????}?else?if?(type?==?CLUSTERMSG_TYPE_UPDATE)?{
????????totlen?=?sizeof(clusterMsg)-sizeof(union?clusterMsgData);
????????totlen?+=?sizeof(clusterMsgDataUpdate);
????}
????hdr->totlen?=?htonl(totlen);
}
后記
本來只想寫一下 Redis Cluster 的 Gossip 協(xié)議,沒想到文章越寫,內(nèi)容越多,最后源碼分析也是有點虎頭蛇尾,大家就湊合看一下,也希望大家繼續(xù)關注我后續(xù)的問題。
-關注我