
收益率16.6%!超越ChatGPT的股票預(yù)測模型來了,還能給出合理解釋
 夕小瑤科技說 原創(chuàng)
夕小瑤科技說 原創(chuàng)作者 | 謝年年
股市變換莫測,任何一點風(fēng)吹草動都可能影響股票的走勢,面對這種不確定性,投資者們常常感到無所適從。
于是研究者們盯上了如今大火的大模型技術(shù),試圖通過高效地處理和分析海量的股市數(shù)據(jù),挖掘出其中的隱藏規(guī)律和趨勢,快速捕捉到新信息對市場的即時影響,預(yù)測未來股價的走勢,為投資者提供決策支持。
例如,前不久小瑤就跟大家分享過一篇論文《碾壓華爾街,GPT-4 選股收益超40%》。
今天再跟大家分享一篇近期發(fā)表在信息檢索頂級會議WWW2024上的一篇論文,不僅收益率達(dá)到恐怖的16.6%,超越了ChatGPT,而且還能給出合理的決策解釋!
論文標(biāo)題:
Learning to Generate Explainable Stock Predictions using Self-Reflective Large Language Models
論文鏈接為:
https://arxiv.org/pdf/2402.03659.pdf
這篇論文提出了一個“總結(jié)-解釋-預(yù)測”Summarize-Explain-Predict (SEP)的框架,該框架利用了一種模型自反思思想和近端策略優(yōu)化(PPO),使LLM能夠自主學(xué)習(xí)如何生成可解釋的股票預(yù)測。
通過自反思過程,模型學(xué)習(xí)如何解釋過去的股票波動。PPO訓(xùn)練過程中的訓(xùn)練樣本來自反思過程中生成的響應(yīng),無需人工標(biāo)注,極大得節(jié)省了人力,增大了生成的解釋質(zhì)量,并進(jìn)一步提高股票預(yù)測的正確性。
任務(wù)定義:可解釋的股票預(yù)測
給定一只股票及其過去天的相關(guān)文本語料庫,目標(biāo)是為下一個交易日生成一則股票預(yù)測,其中包括了一個二進(jìn)制價格變動 和一個可讀的解釋。
Summarize-Explain-Predict(SEP)框架
SEP框架包含三個主要組件,如下圖所示:
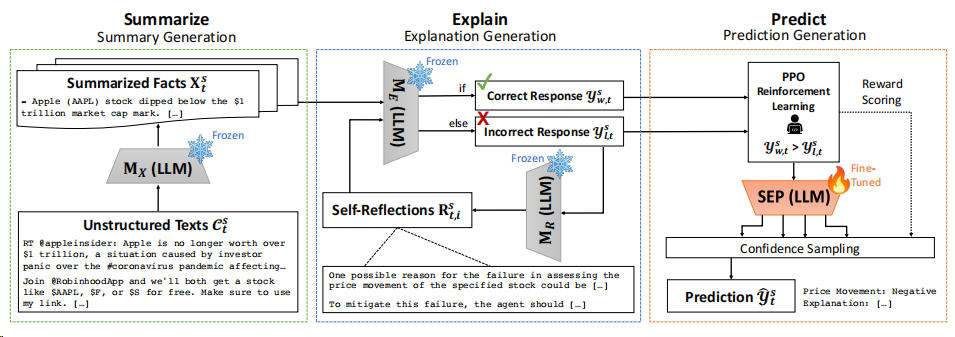
- 總結(jié):從非結(jié)構(gòu)化文本輸入中生成事實信息的摘要;
- 解釋:通過迭代的自反思過程生成股票預(yù)測的解釋并進(jìn)行改進(jìn);
- 預(yù)測::通過微調(diào)語言模型后使用自動生成的注釋樣本生成基于置信度的預(yù)測。
1. 自我總結(jié)模塊:從海量文本中提取關(guān)鍵信息
鑒于??天的原始文本中的信息會超過字符限制,自我總結(jié)模塊利用LLMs強(qiáng)大的摘要能力,將大量文本輸入數(shù)據(jù)轉(zhuǎn)換為事實信息的要點摘要。提示包過兩個可變輸入:指定的股票,和每天的非結(jié)構(gòu)化文本輸入。然后LLM 生成影響股票的新聞?wù)纭鞍ㄌO果(AAPL)、谷歌、亞馬遜和Facebook在內(nèi)的大型科技股票超出了盈利預(yù)期”。可以表示為: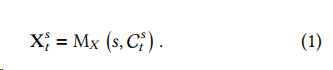
2. 自我解釋模塊:通過自反思過程生成股價解釋
自我解釋模塊的目標(biāo)是雙重的:一方面生成清晰的股票預(yù)測解釋,另一方面通過迭代的自反思過程改進(jìn)LLM自身的預(yù)測。
解釋模塊的提示包含兩個變量輸入:指定的股票和前一個模塊生成的一系列提取信息的序列。給定這些輸入,LLM 生成響應(yīng),其中應(yīng)包含下一交易日的價格變動 和一個可讀的解釋。形式化為: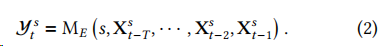
在此過程中,還加入了自我反思循壞迭代改進(jìn)回復(fù),如下圖所示:
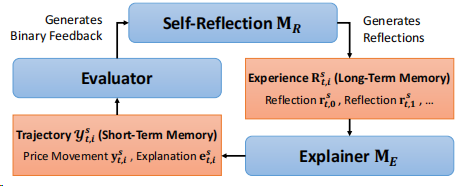
從生成的價格變動中,通過評估其與實際情況的一致性獲得二進(jìn)制反饋。對于錯誤的樣本,引入LLM 為每一次迭代生成一個口頭反饋。
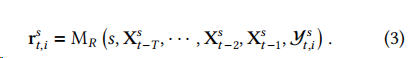
對于每一次迭代,每個反思代表LLM從失敗中學(xué)到的教訓(xùn),將其表示為一組反思,連同原始輸入再次輸入LLM ,以生成下一次迭代的價格變動和解釋。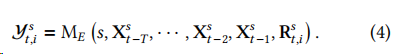
通過這個過程,能夠獲得每個成功的反思所對應(yīng)的正確和錯誤回答的一對。分別將其定義為和,用于后續(xù)模塊預(yù)測股票走勢。
3. 自我預(yù)測模塊:利用PPO訓(xùn)練優(yōu)化預(yù)測能力
自我預(yù)測模塊使用自我解釋模塊構(gòu)建的數(shù)據(jù)樣本微調(diào)LLM,以便在測試期間生成最可能的股票預(yù)測和解釋。具體流程如圖所示:

- 收集演示數(shù)據(jù):從初始迭代中的正確預(yù)測中獲取的,沒有相應(yīng)的“錯誤”回答。這些樣本用于使用監(jiān)督微調(diào)(SFT)方法訓(xùn)練一個監(jiān)督策略。
- 收集比較數(shù)據(jù):其中包含每個結(jié)構(gòu)化輸入的配對正確和錯誤回答和。是模型成功反思的正負(fù)樣本對,用于訓(xùn)練一個獎勵模型,為正確的回答給予更高的獎勵分?jǐn)?shù)。
- 使用有監(jiān)督的策略初始化模型,然后利用它為整體數(shù)據(jù)集中隨機(jī)選擇的樣本生成預(yù)測。接下來,獎勵模型用于為每個回復(fù)生成獎勵。通過最大化總體獎勵來優(yōu)化PPO模型。
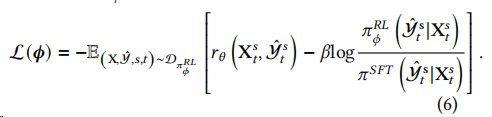
在推理過程中,首先使用預(yù)訓(xùn)練的LLM對無結(jié)構(gòu)化輸入文本進(jìn)行總結(jié)。然后,使用訓(xùn)練好的策略從總結(jié)的事實生成下一天的預(yù)測。對于生成預(yù)測,使用一個最佳采樣器,在生成個響應(yīng)之后,使用獎勵模型的分?jǐn)?shù)選擇最佳響應(yīng)。
實驗設(shè)計
1. 數(shù)據(jù)集構(gòu)建
本文遵循ACL18 StockNet數(shù)據(jù)集的收集方法,原始數(shù)據(jù)集的持續(xù)時間跨越2014年至2016年,作者又采集了2020年至2022年的更新版本。選擇了11個行業(yè)中市值最高的前5只股票,共計55只股票。股價數(shù)據(jù)從Yahoo Finance收集,而推文數(shù)據(jù)則通過Twitter API獲取。由于每天的推文數(shù)量龐大,作者采用了BERTopic聚類來識別每天的代表性推文,這些推文將作為所有模型的文本輸入。
2. 評估指標(biāo)
本文采用預(yù)測準(zhǔn)確性和Matthews相關(guān)系數(shù)(MCC)作為評估指標(biāo),用于二元股票分類任務(wù)。準(zhǔn)確性指標(biāo)衡量模型預(yù)測的準(zhǔn)確度,而MCC則考慮了真正例和假正例的比率,是一個更全面的性能指標(biāo)。此外,還通過定性分析來評估模型生成解釋的質(zhì)量。
實驗結(jié)果
1. 預(yù)測準(zhǔn)確性
在預(yù)測準(zhǔn)確性方面,SEP框架經(jīng)過實驗驗證,能夠在預(yù)測準(zhǔn)確性和MCC方面超越傳統(tǒng)深度學(xué)習(xí)和LLM方法,如表1所示。
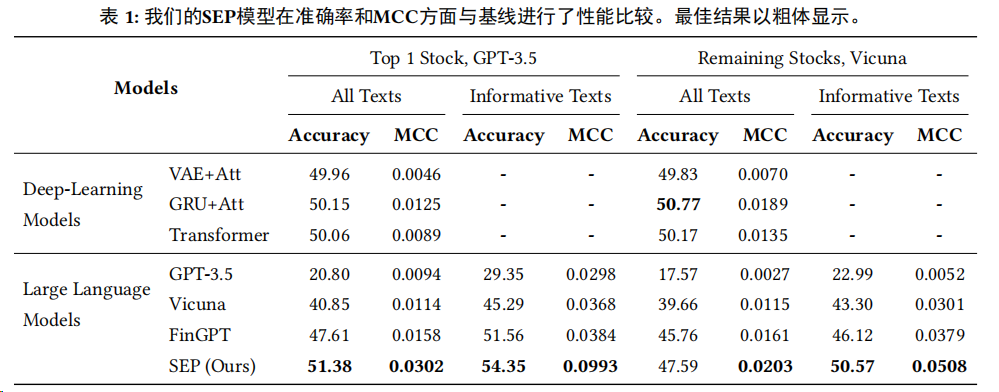
在使用GPT生成的解釋進(jìn)行微調(diào)的SEP模型中,預(yù)測準(zhǔn)確性比最強(qiáng)基線(GRU+Attention)提高了2.4%。
在MCC指標(biāo)上,SEP模型在所有設(shè)置下都優(yōu)于所有模型,展示了模型在考慮隨機(jī)猜測后理解自然語言文本對股票走勢影響的真實能力。
2. 解釋質(zhì)量的提升
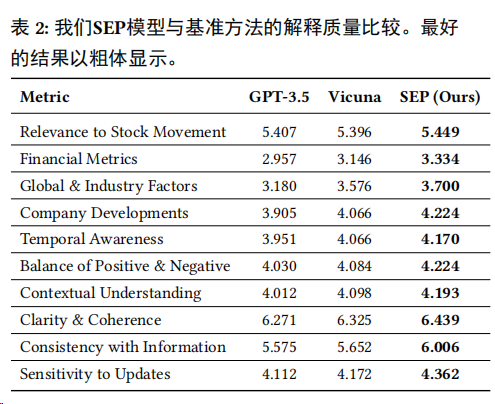
除了生成更好的預(yù)測外,使用LLM而不是傳統(tǒng)深度學(xué)習(xí)方法的一個自然優(yōu)勢是它們能夠為預(yù)測生成解釋。而SEP模型在使用自我反思數(shù)據(jù)微調(diào)后,相比一般的LLM能夠更加果斷地權(quán)衡新聞信息,給出質(zhì)量更高的解釋。
作者創(chuàng)建了一組解釋質(zhì)量指標(biāo),并使用GPT-4對樣本進(jìn)行評分。這些指標(biāo)包括與股票運動的相關(guān)性、財務(wù)指標(biāo)、全球和行業(yè)因素、公司發(fā)展、時間意識、正負(fù)信息的平衡、情境理解、清晰度和連貫性、信息一致性以及對更新的敏感性,對比結(jié)果如下表所示,可以看到SEP模型在所有指標(biāo)上都取得了最高分。
組件效能分析:各模塊對SEP框架性能的貢獻(xiàn)
SEP有三個核心組件:總結(jié)、解釋‘預(yù)測’模塊。這些模塊共同構(gòu)成了SEP框架,它們各自的功能和對整體性能的貢獻(xiàn)是不可或缺的。
1.總結(jié)模塊
通過摘要,模型能夠提取出最關(guān)鍵的信息,為后續(xù)的預(yù)測和解釋提供了堅實的基礎(chǔ)。作者將SEP與未經(jīng)總結(jié)和經(jīng)過總結(jié)的輸入文本進(jìn)行比較,還比較了分享最多前30篇文本和隨機(jī)抽取30篇文本之間的信心量的影響,如下表所示:
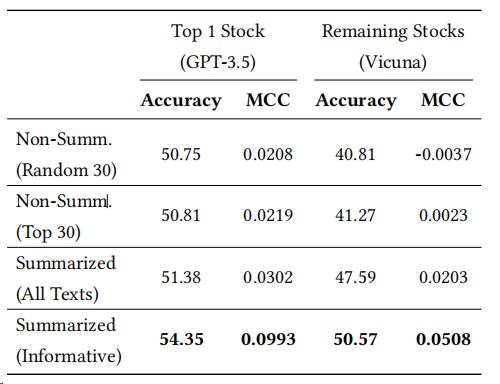
- 使用最常分享的文本要比隨機(jī)抽樣更好。
- 總結(jié)的文本提供了更好的結(jié)果。這也表明總結(jié)過程沒有丟失任何可能導(dǎo)致退化的重要信息。
- 總結(jié)時刪除一些非信息性的文本,可以提高表現(xiàn)。
2.解釋模塊
解釋模塊的目標(biāo)是生成清晰的股票預(yù)測解釋,并通過迭代的自我反思過程來提煉這些解釋。
為了調(diào)整LLM以產(chǎn)生預(yù)測和解釋,解釋模塊必須首先通過二進(jìn)制反饋和自省嘗試生成正確注釋的樣本。為了展示其效果,作者繪制了每次反思迭代后生成的“決定性”和“正確”預(yù)測數(shù)目的變化百分比,如下圖:
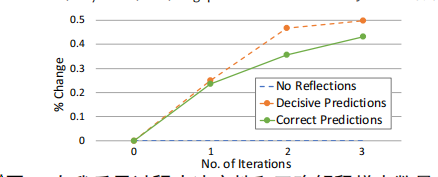
可以看到隨著多次自反思迭代,模型生成了越來越多的明確正確的注釋樣本。這凸顯了解釋模塊在生成標(biāo)注樣本方面的有效性,而無需人工專家的幫助。
3.預(yù)測模塊
預(yù)測模塊的目標(biāo)是通過使用PPO算法微調(diào)LLM,以便在測試期間生成最可能的股票預(yù)測和解釋。
作者對每個變體刪除了一個附加組件,即在推理中沒有??-shot采樣[SEP(1-shot)];沒有使用PPO增強(qiáng)學(xué)習(xí)[SEP(no PPO)];以及沒有解釋[SEP(binary)],即簡單地將LLM調(diào)整為進(jìn)行二元的上升/下降預(yù)測。
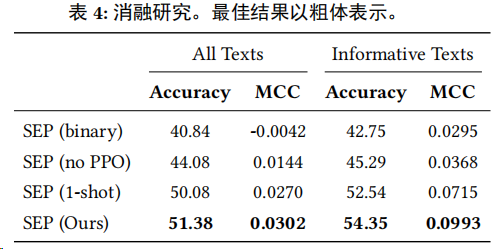
- 在指令調(diào)整過程中增加解釋組件,即從SEP(binary)到(binary),模型平均改進(jìn)了6.9%。
- PPO強(qiáng)化學(xué)習(xí)的加入顯著提高了模型的預(yù)測準(zhǔn)確性,平均改進(jìn)了14.8%,這突顯了預(yù)測模塊在提升SEP框架性能中的關(guān)鍵作用。
綜上所述,SEP框架中的每個組件都對性能有著顯著的貢獻(xiàn)。總結(jié)模塊通過提取關(guān)鍵信息減少了輸入的噪聲,解釋模塊通過自我反思生成了高質(zhì)量的訓(xùn)練樣本,而預(yù)測模塊則通過PPO訓(xùn)練提高了預(yù)測的準(zhǔn)確性。這些組件的協(xié)同工作使得SEP框架在股票預(yù)測任務(wù)中表現(xiàn)出色。
跨任務(wù)泛化能力:SEP框架在投資組合構(gòu)建任務(wù)中的應(yīng)用
SEP框架不僅在股票預(yù)測任務(wù)中表現(xiàn)出色,其泛化能力也在投資組合構(gòu)建任務(wù)中得到了驗證。
對于投資組合任務(wù),采用與上述相同的方法來微調(diào)LLM。輸入信息是每天股票籃子的所有生成解釋。對于這個實驗任務(wù),僅篩選出具有正預(yù)測的股票,以減少LLM需要評估的股票數(shù)量,并防止產(chǎn)生負(fù)權(quán)重。然后,提示LLM根據(jù)每個給定股票的前景生成投資組合權(quán)重,如下圖所示:
在每次自我反思迭代中,向反思型LLM提供投資組合權(quán)重和對應(yīng)的總體利潤,引導(dǎo)其思考如何提高預(yù)測準(zhǔn)確性來增加利潤。基于這些反思,LLM生成新的權(quán)重。接著,將新舊權(quán)重輸入PPO訓(xùn)練器,選擇利潤更高的權(quán)重作為優(yōu)化方向。
結(jié)果如下表所示:
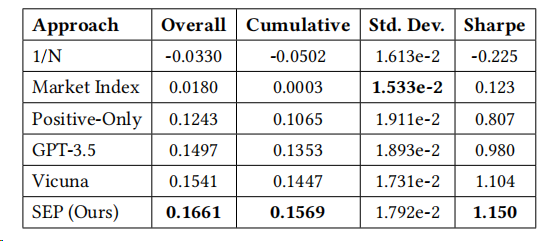
SEP模型在多個投資組合性能指標(biāo)上表現(xiàn)出色,包括總收益、累計收益、收益的標(biāo)準(zhǔn)差和年化夏普比率。這些結(jié)果表明,SEP框架能夠有效地將股票預(yù)測任務(wù)中學(xué)到的信息量化權(quán)衡,用于投資組合構(gòu)建任務(wù)。
結(jié)論
本文研究了利用自反思大型語言模型進(jìn)行股市預(yù)測的可解釋性任務(wù),并提出了SEP框架。該框架結(jié)合自反思代理和近端策略優(yōu)化(PPO)技術(shù),讓LLM自主學(xué)習(xí)生成可解釋的股票預(yù)測。實驗結(jié)果顯示,SEP框架在預(yù)測準(zhǔn)確性和生成解釋的質(zhì)量方面均優(yōu)于傳統(tǒng)方法和LLM。在投資組合構(gòu)建任務(wù)上的測試也證明了其泛化能力。
未來研究可關(guān)注減少SEP框架的累積誤差、利用更多數(shù)據(jù)源提高預(yù)測質(zhì)量,并改進(jìn)股票解釋的評估指標(biāo)。
