
40張圖看懂分布式追蹤系統(tǒng)原理及實(shí)踐
前言
分布式追蹤系統(tǒng)原理及作用
SkyWalking的原理及架構(gòu)設(shè)計(jì)
我司在分布式調(diào)用鏈上的實(shí)踐
?
分布式追蹤系統(tǒng)的原理及作用
接口的 RT 你怎么知道?
是否有異常響應(yīng)?
主要慢在哪里?
單體架構(gòu)
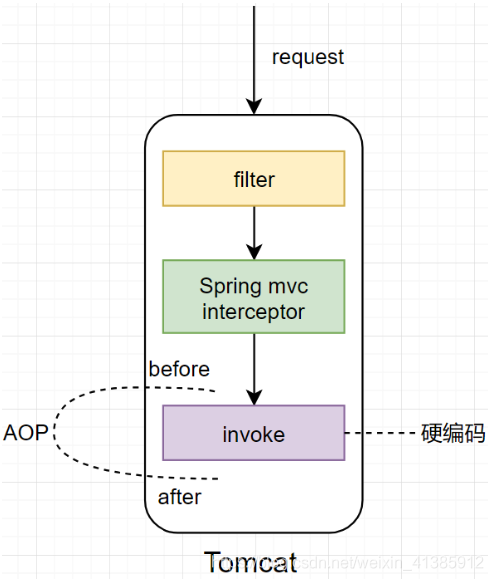
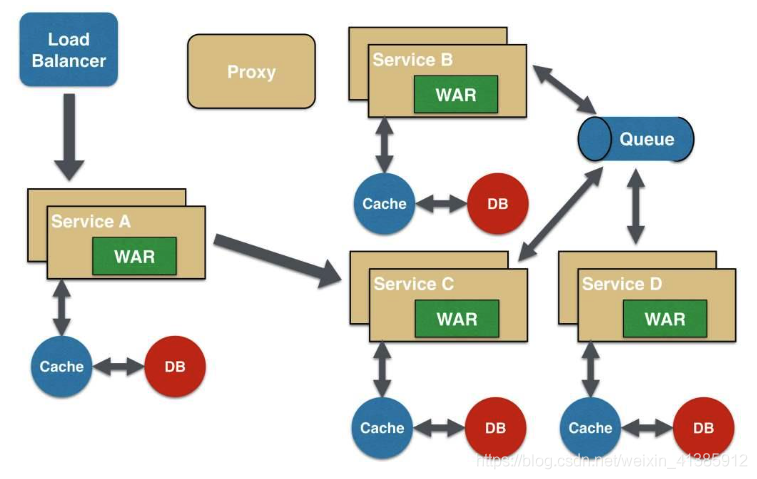
微服務(wù)架構(gòu)
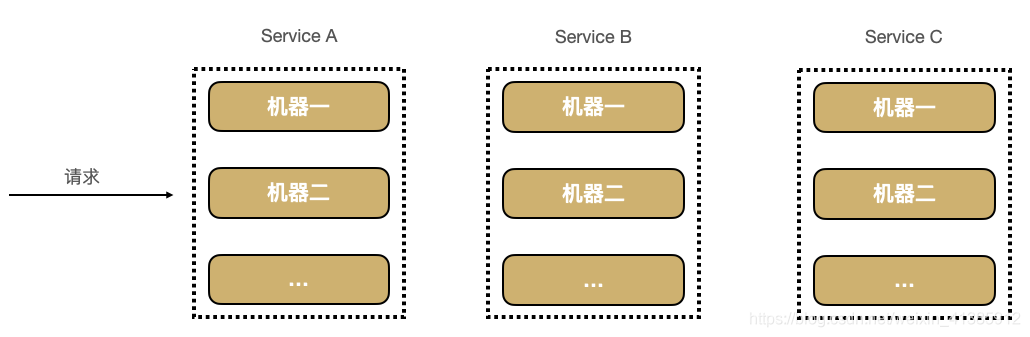
排查問題難度大,周期長(zhǎng)
特定場(chǎng)景難復(fù)現(xiàn)
系統(tǒng)性能瓶頸分析較難
自動(dòng)采取數(shù)據(jù) ?
分析數(shù)據(jù)產(chǎn)生完整調(diào)用鏈:有了請(qǐng)求的完整調(diào)用鏈,問題有很大概率可復(fù)現(xiàn)
數(shù)據(jù)可視化:每個(gè)組件的性能可視化,能幫助我們很好地定位系統(tǒng)的瓶頸,及時(shí)找出問題所在
分布式調(diào)用鏈標(biāo)準(zhǔn) - OpenTracing
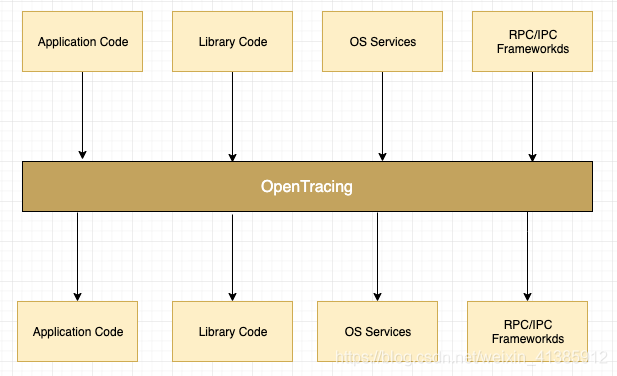
這樣 OpenTracing 通過提供平臺(tái)無關(guān),廠商無關(guān)的 API,使得開發(fā)人員能夠方便地添加追蹤系統(tǒng)的實(shí)現(xiàn)。
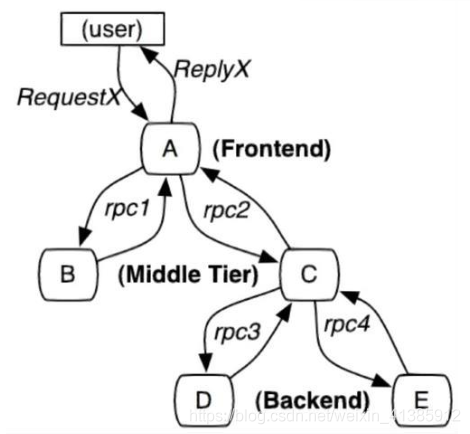
Trace:一個(gè)完整請(qǐng)求鏈路
Span:一次調(diào)用過程(需要有開始時(shí)間和結(jié)束時(shí)間)
SpanContext:Trace 的全局上下文信息, 如里面有traceId
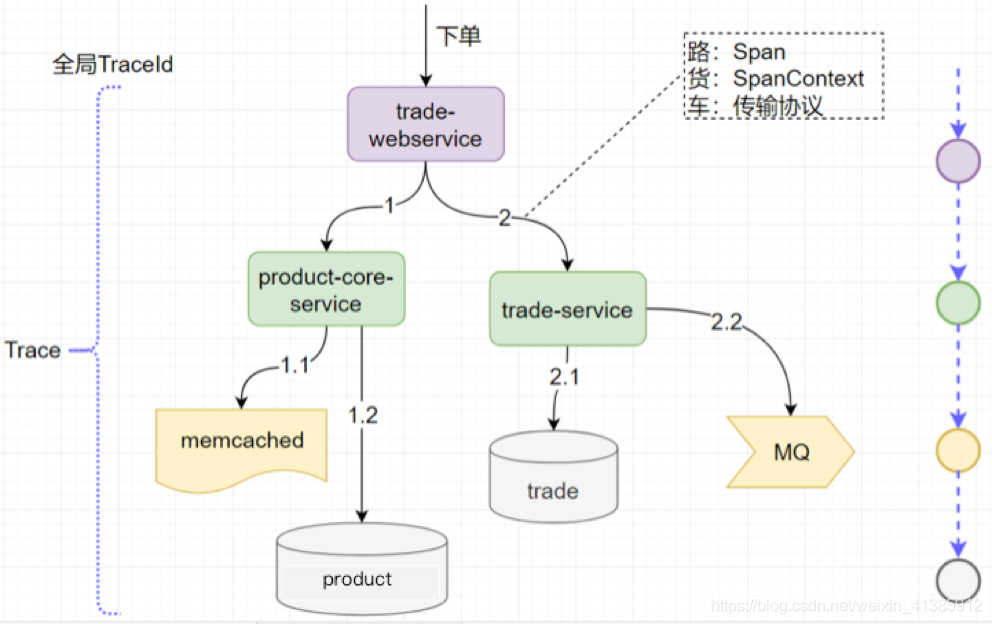
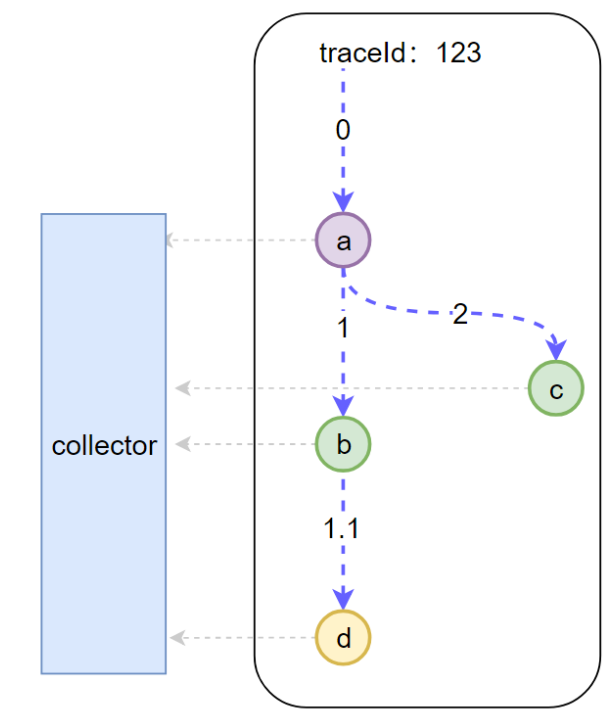
全局 trace_id:這是顯然的,這樣才能把每一個(gè)子調(diào)用與最初的請(qǐng)求關(guān)聯(lián)起來
span_id: 圖中的 0,1,1.1,2,這樣就能標(biāo)識(shí)是哪一個(gè)調(diào)用
parent_span_id:比如 b 調(diào)用 d 的 ?span_id 是 1.1,那么它的 parent_span_id 即為 a 調(diào)用 b 的 span_id 即 1,這樣才能把兩個(gè)緊鄰的調(diào)用關(guān)聯(lián)起來。

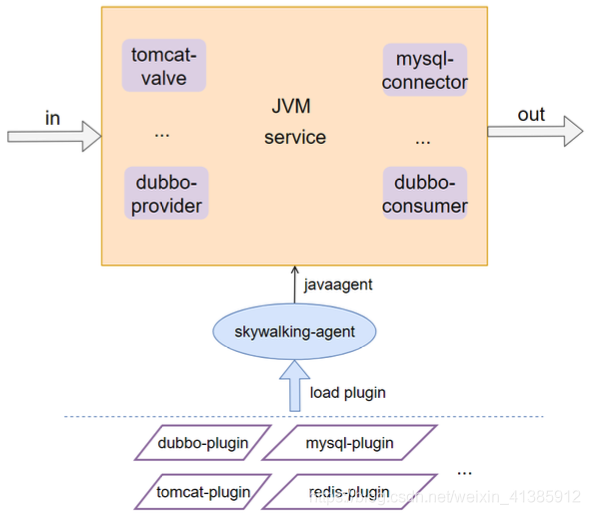
怎么自動(dòng)采集 span 數(shù)據(jù):自動(dòng)采集,對(duì)業(yè)務(wù)代碼無侵入
如何跨進(jìn)程傳遞 context
traceId 如何保證全局唯一
請(qǐng)求量這么多采集會(huì)不會(huì)影響性能
?
SkyWalking的原理及架構(gòu)設(shè)計(jì)
怎么自動(dòng)采集 span 數(shù)據(jù)
如何跨進(jìn)程傳遞 context
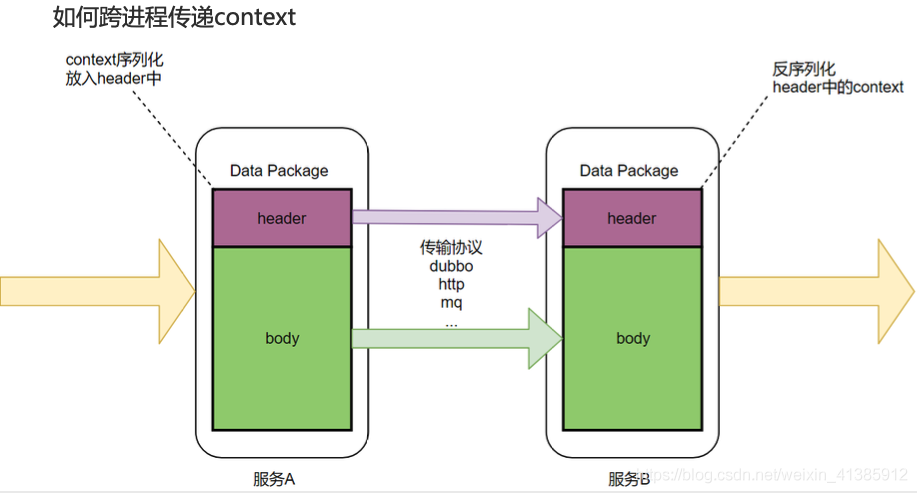 dubbo 中的 attachment 就相當(dāng)于 header ,所以我們把 context 放在 attachment 中,這樣就解決了 context 的傳遞問題。
dubbo 中的 attachment 就相當(dāng)于 header ,所以我們把 context 放在 attachment 中,這樣就解決了 context 的傳遞問題。 小提示:這里的傳遞 context 流程均是在 dubbo plugin 處理的,業(yè)務(wù)無感知,這個(gè) plugin 是怎么實(shí)現(xiàn)的呢,下文會(huì)分析
小提示:這里的傳遞 context 流程均是在 dubbo plugin 處理的,業(yè)務(wù)無感知,這個(gè) plugin 是怎么實(shí)現(xiàn)的呢,下文會(huì)分析traceId 如何保證全局唯一
 圖示: snowflake 算法生成的 id
圖示: snowflake 算法生成的 id 每生成一個(gè) id,都會(huì)記錄一下生成 id 的時(shí)間(lastTimestamp),如果發(fā)現(xiàn)當(dāng)前時(shí)間比上一次生成 id 的時(shí)間(lastTimestamp)還小,那說明發(fā)生了時(shí)間回?fù)埽藭r(shí)會(huì)生成一個(gè)隨機(jī)數(shù)來作為 traceId。這里可能就有同學(xué)要較真了,可能會(huì)覺得生成的這個(gè)隨機(jī)數(shù)也會(huì)和已生成的全局 id 重復(fù),是否再加一層校驗(yàn)會(huì)好點(diǎn)。
每生成一個(gè) id,都會(huì)記錄一下生成 id 的時(shí)間(lastTimestamp),如果發(fā)現(xiàn)當(dāng)前時(shí)間比上一次生成 id 的時(shí)間(lastTimestamp)還小,那說明發(fā)生了時(shí)間回?fù)埽藭r(shí)會(huì)生成一個(gè)隨機(jī)數(shù)來作為 traceId。這里可能就有同學(xué)要較真了,可能會(huì)覺得生成的這個(gè)隨機(jī)數(shù)也會(huì)和已生成的全局 id 重復(fù),是否再加一層校驗(yàn)會(huì)好點(diǎn)。請(qǐng)求量這么多,全部采集會(huì)不會(huì)影響性能?
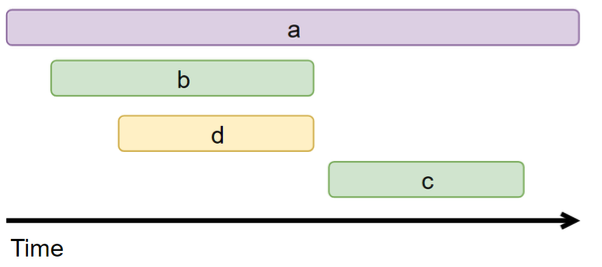
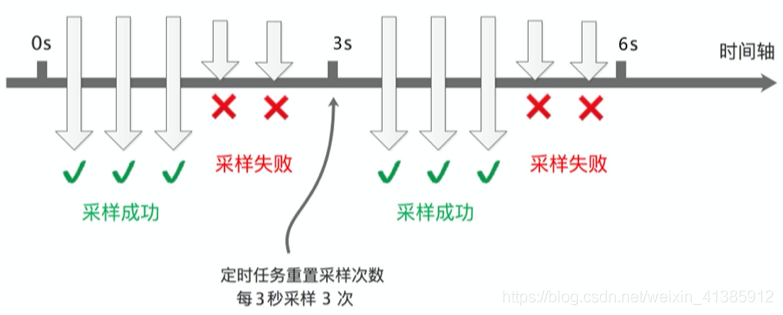 這樣的采樣頻率其實(shí)足夠我們分析組件的性能了,按 3 秒采樣 3 次這樣的頻率來采樣數(shù)據(jù)會(huì)有啥問題呢。理想情況下,每個(gè)服務(wù)調(diào)用都在同一個(gè)時(shí)間點(diǎn)(如下圖示)這樣的話每次都在同一時(shí)間點(diǎn)采樣確實(shí)沒問題
這樣的采樣頻率其實(shí)足夠我們分析組件的性能了,按 3 秒采樣 3 次這樣的頻率來采樣數(shù)據(jù)會(huì)有啥問題呢。理想情況下,每個(gè)服務(wù)調(diào)用都在同一個(gè)時(shí)間點(diǎn)(如下圖示)這樣的話每次都在同一時(shí)間點(diǎn)采樣確實(shí)沒問題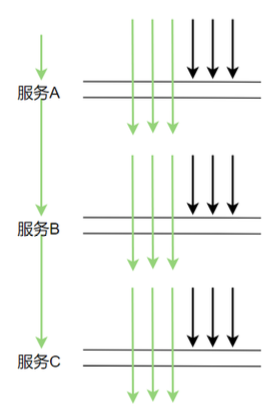 但在生產(chǎn)上,每次服務(wù)調(diào)用基本不可能都在同一時(shí)間點(diǎn)調(diào)用,因?yàn)槠陂g有網(wǎng)絡(luò)調(diào)用延時(shí)等,實(shí)際調(diào)用情況很可能是下圖這樣
但在生產(chǎn)上,每次服務(wù)調(diào)用基本不可能都在同一時(shí)間點(diǎn)調(diào)用,因?yàn)槠陂g有網(wǎng)絡(luò)調(diào)用延時(shí)等,實(shí)際調(diào)用情況很可能是下圖這樣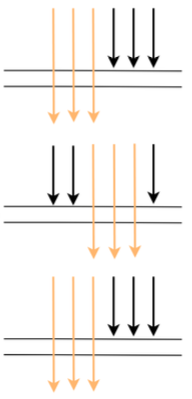
SkyWalking 的基礎(chǔ)架構(gòu)
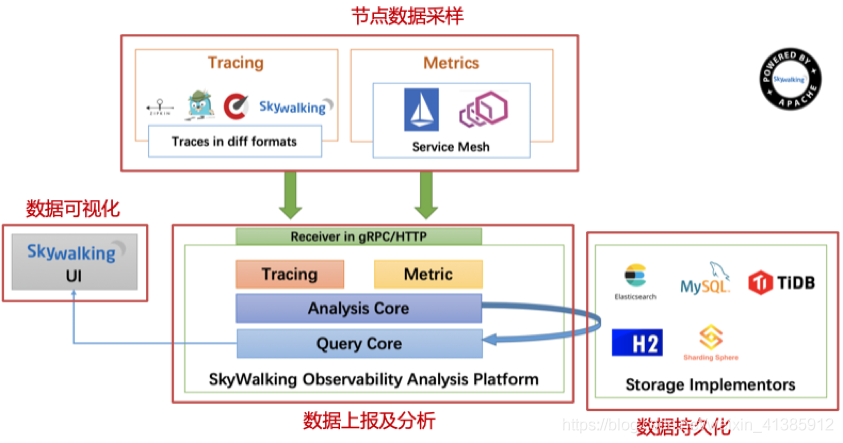 首先當(dāng)然是節(jié)點(diǎn)數(shù)據(jù)的定時(shí)采樣,采樣后將數(shù)據(jù)定時(shí)上報(bào),將其存儲(chǔ)到 ES, MySQL 等持久化層,有了數(shù)據(jù)自然而然可根據(jù)數(shù)據(jù)做可視化分析。
首先當(dāng)然是節(jié)點(diǎn)數(shù)據(jù)的定時(shí)采樣,采樣后將數(shù)據(jù)定時(shí)上報(bào),將其存儲(chǔ)到 ES, MySQL 等持久化層,有了數(shù)據(jù)自然而然可根據(jù)數(shù)據(jù)做可視化分析。SkyWalking 的性能如何
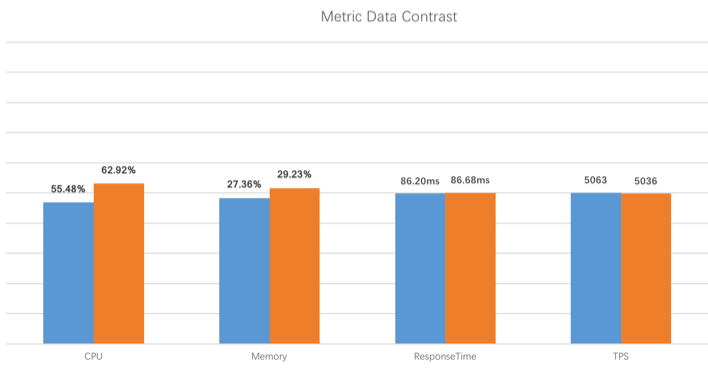
對(duì)多語言的支持,組件豐富:目前其支持 Java, .Net Core, PHP, NodeJS, Golang, LUA 語言,組件上也支持dubbo, mysql 等常見組件,大部分能滿足我們的需求。 擴(kuò)展性:對(duì)于不滿足的插件,我們按照 SkyWalking 的規(guī)則手動(dòng)寫一個(gè)即可,新實(shí)現(xiàn)的插件對(duì)代碼無入侵。
?
我司在分布式調(diào)用鏈上的實(shí)踐
SkyWalking 在我司的應(yīng)用架構(gòu)
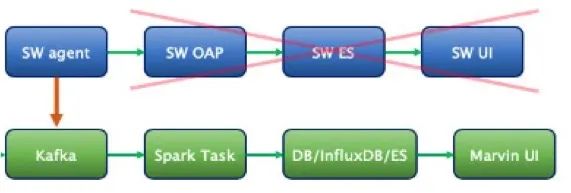
我司對(duì) SkyWalking 作了哪些改造和實(shí)踐
預(yù)發(fā)環(huán)境由于調(diào)試需要強(qiáng)制采樣 實(shí)現(xiàn)更細(xì)粒度的采樣? 日志中嵌入traceId 自研實(shí)現(xiàn)了 SkyWalking 插件
預(yù)發(fā)環(huán)境由于調(diào)試需要強(qiáng)制采樣
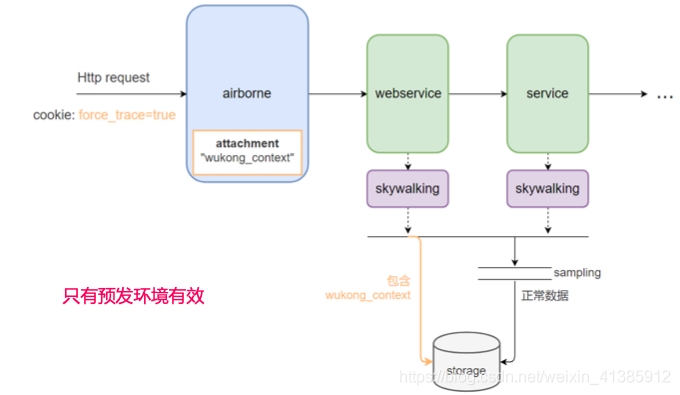
實(shí)現(xiàn)更細(xì)粒度的采樣?
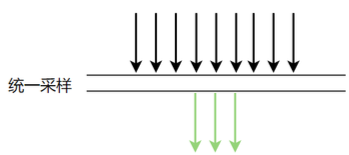 我們知道這種方式默認(rèn)是 3 秒采樣前 3 次,其他請(qǐng)求都丟棄,這樣的話有個(gè)問題,假設(shè)在這臺(tái)機(jī)器上在 3 秒內(nèi)有多個(gè) dubbo,mysql,redis 調(diào)用,但在如果前三次都是 dubbo 調(diào)用的話,其他像 mysql, redis 等調(diào)用就采樣不到了,所以我們對(duì) skywalking 進(jìn)行了改造,實(shí)現(xiàn)了分組采樣,如下
我們知道這種方式默認(rèn)是 3 秒采樣前 3 次,其他請(qǐng)求都丟棄,這樣的話有個(gè)問題,假設(shè)在這臺(tái)機(jī)器上在 3 秒內(nèi)有多個(gè) dubbo,mysql,redis 調(diào)用,但在如果前三次都是 dubbo 調(diào)用的話,其他像 mysql, redis 等調(diào)用就采樣不到了,所以我們對(duì) skywalking 進(jìn)行了改造,實(shí)現(xiàn)了分組采樣,如下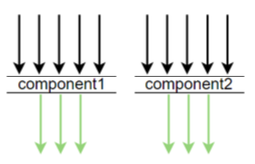 就是說 3 秒內(nèi)進(jìn)行 3 次 redis, dubbo, mysql 等的采樣,也就避免了此問題
就是說 3 秒內(nèi)進(jìn)行 3 次 redis, dubbo, mysql 等的采樣,也就避免了此問題日志中如何嵌入traceId?

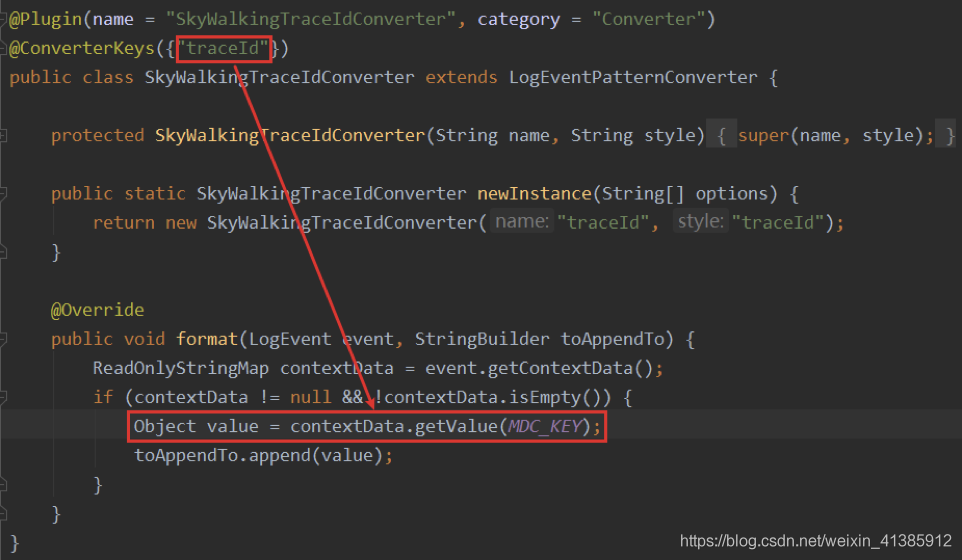 首先 log4j 的插件要定義一個(gè)類,這個(gè)類要繼承 LogEventPatternConverter 這個(gè)類,并且用標(biāo)準(zhǔn) Plugin 將其自身聲明為 Plugin,通過 @ConverterKeys 這個(gè)注解指定了要替換的占位符,然后在 format 方法里將其替換掉。這樣在日志中就會(huì)出現(xiàn)我們想要的 TraceId ,如下
首先 log4j 的插件要定義一個(gè)類,這個(gè)類要繼承 LogEventPatternConverter 這個(gè)類,并且用標(biāo)準(zhǔn) Plugin 將其自身聲明為 Plugin,通過 @ConverterKeys 這個(gè)注解指定了要替換的占位符,然后在 format 方法里將其替換掉。這樣在日志中就會(huì)出現(xiàn)我們想要的 TraceId ,如下
我司自研了哪些 skywalking 插件
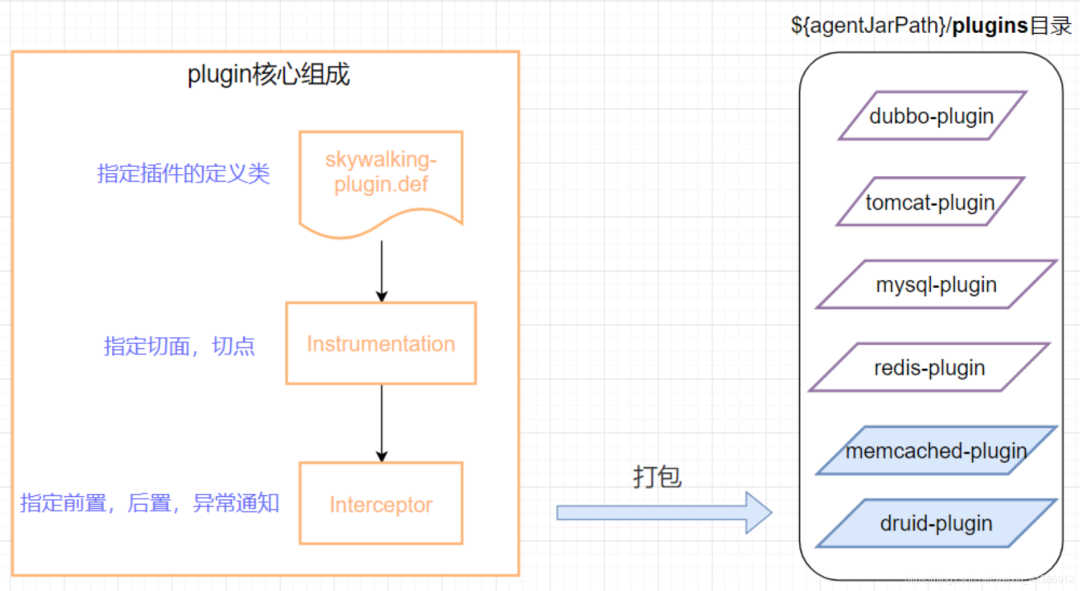
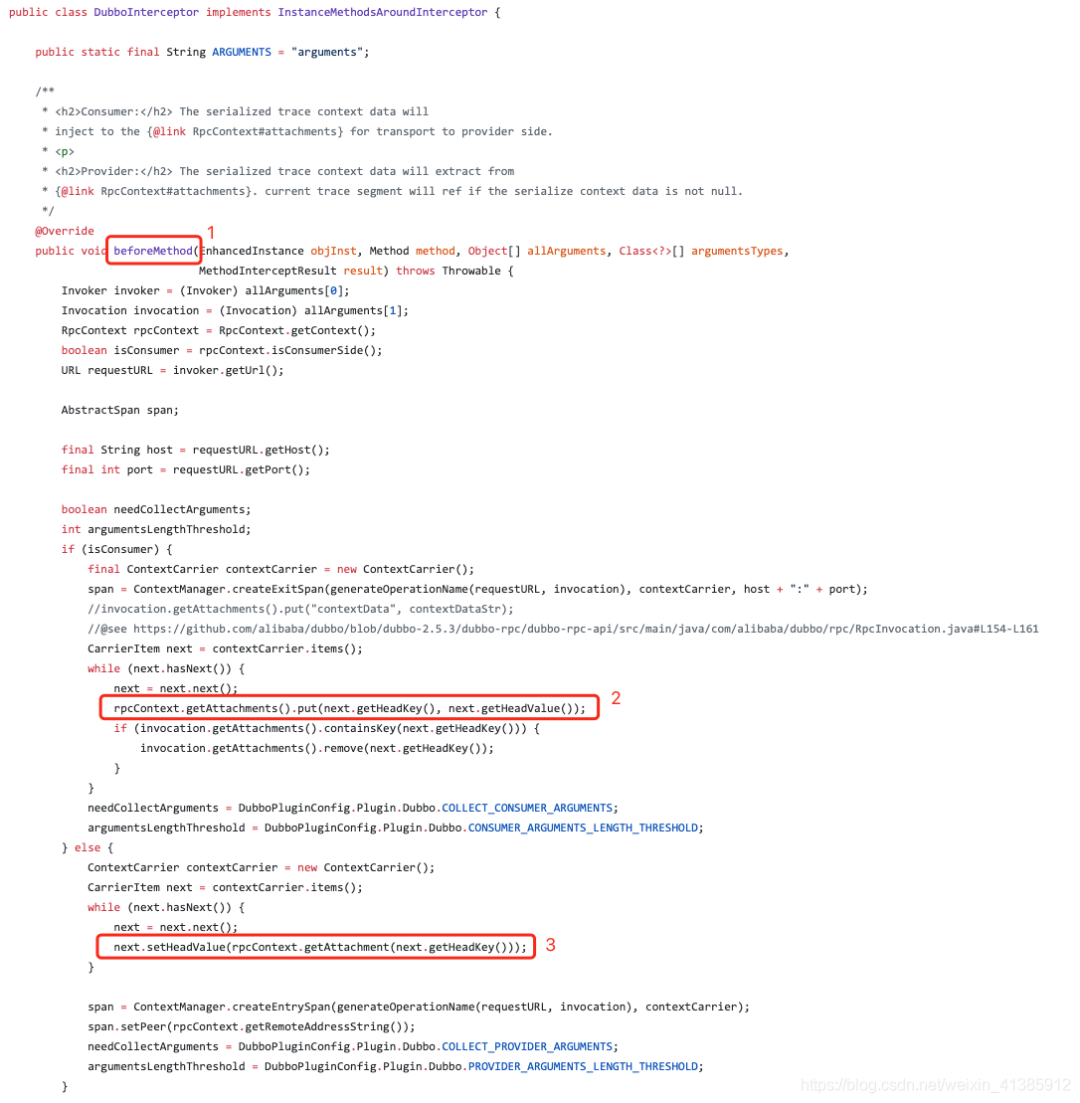
插件定義類: 指定插件的定義類,最終會(huì)根據(jù)這里的定義類打包生成 plugin Instrumentation: 指定切面,切點(diǎn),要對(duì)哪個(gè)類的哪個(gè)方法進(jìn)行增強(qiáng) Interceptor,指定步驟 2 中要在方法的前置,后置還是異常中寫增強(qiáng)邏輯
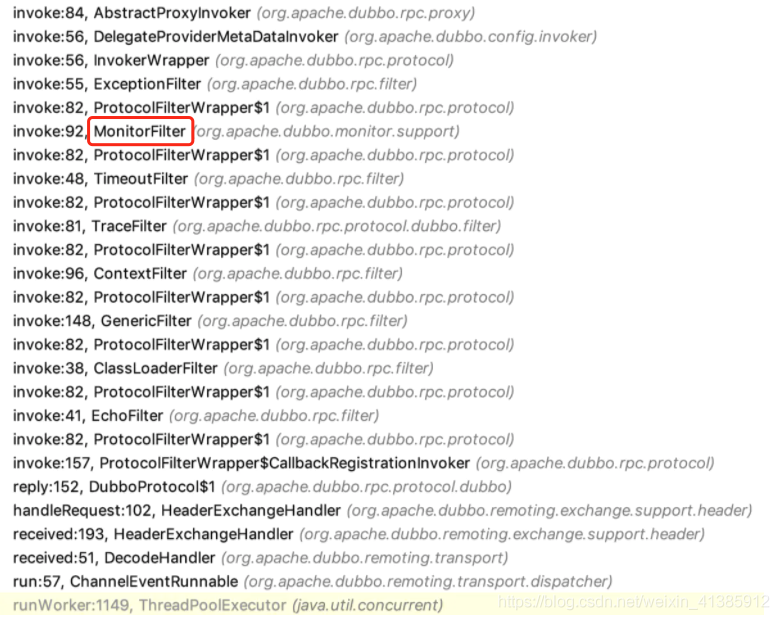 而 MonitorFilter 可以攔截所有客戶端發(fā)出請(qǐng)求或者服務(wù)端處理請(qǐng)求,所以我們可以對(duì) MonitorFilter 作增強(qiáng),在其調(diào)用 invoke 方法前,將全局 traceId ?注入到其 Invocation 的 attachment 中,這樣就可以確保在請(qǐng)求到達(dá)真正的業(yè)務(wù)邏輯前就已經(jīng)存在全局 traceId。
而 MonitorFilter 可以攔截所有客戶端發(fā)出請(qǐng)求或者服務(wù)端處理請(qǐng)求,所以我們可以對(duì) MonitorFilter 作增強(qiáng),在其調(diào)用 invoke 方法前,將全局 traceId ?注入到其 Invocation 的 attachment 中,這樣就可以確保在請(qǐng)求到達(dá)真正的業(yè)務(wù)邏輯前就已經(jīng)存在全局 traceId。
// skywalking-plugin.def 文件dubbo=org.apache.skywalking.apm.plugin.asf.dubbo.DubboInstrumentation
這樣打包出來的插件就會(huì)對(duì) MonitorFilter 的 ?invoke 方法進(jìn)行增強(qiáng),在 invoke 方法執(zhí)行前對(duì)期 attachment 作注入全局 traceId 等操作,這一切都是靜默的,對(duì)代碼無侵入的。