Python騷操作:一行代碼實(shí)現(xiàn)探索性數(shù)據(jù)分析
點(diǎn)擊上方“數(shù)據(jù)管道”,選擇“置頂星標(biāo)”公眾號(hào)
干貨福利,第一時(shí)間送達(dá)

dataprep.eda
在使用數(shù)據(jù)前,我們首先要做的是觀察數(shù)據(jù),包括查看數(shù)據(jù)的類型、數(shù)據(jù)的范圍、數(shù)據(jù)的分布等。dataprep.eda是個(gè)非常不錯(cuò)的工具,它可以幫你快速生成數(shù)據(jù)概覽。dataprep.eda包含的一些智能特性:
為每個(gè) EDA 任務(wù)選擇正確的圖形來可視化數(shù)據(jù) 列類型推斷(數(shù)字型、類別型和日期時(shí)間型) 選擇合適的時(shí)間單位(用戶也可以指定) 對(duì)數(shù)量龐大的類型數(shù)據(jù)輸出清晰的可視化方案(用戶也可以指定)
dataprep安裝
安裝dataprep僅需要執(zhí)行pip instal dataprep即可,由于依賴比較多,安裝過程比較慢,需要耐心等待。

如果報(bào)錯(cuò),多半是權(quán)限問題,可以在后面加上--user

實(shí)例
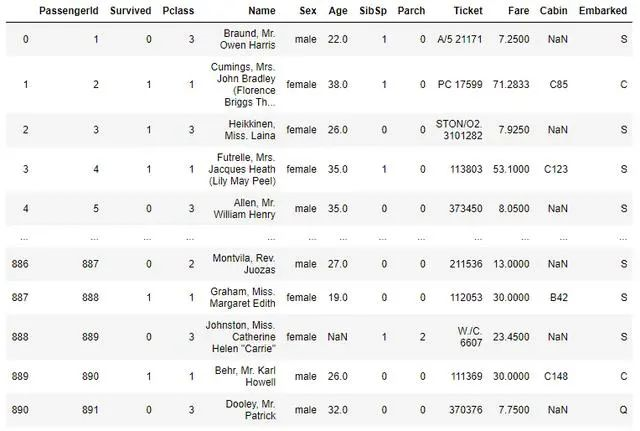
為了看到這一點(diǎn)的實(shí)際應(yīng)用,我們將使用一個(gè)泰坦尼克數(shù)據(jù)集,我們從數(shù)據(jù)集的概述開始:
from dataprep.eda import *import pandas as pdtrain_df = pd.read_csv('titanic/train.csv')train_df
一行代碼實(shí)現(xiàn)數(shù)據(jù)集可視化探索
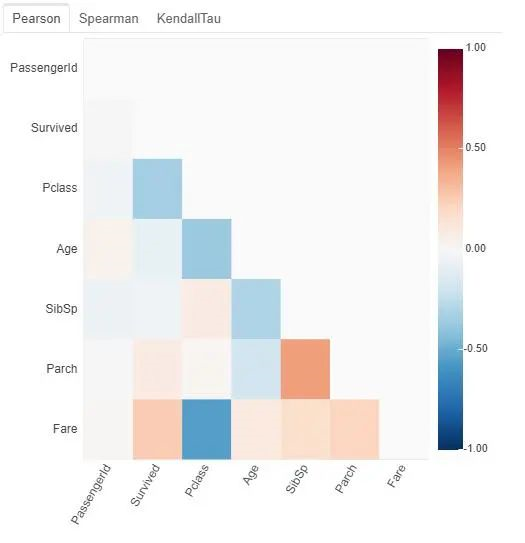
plot(train_df)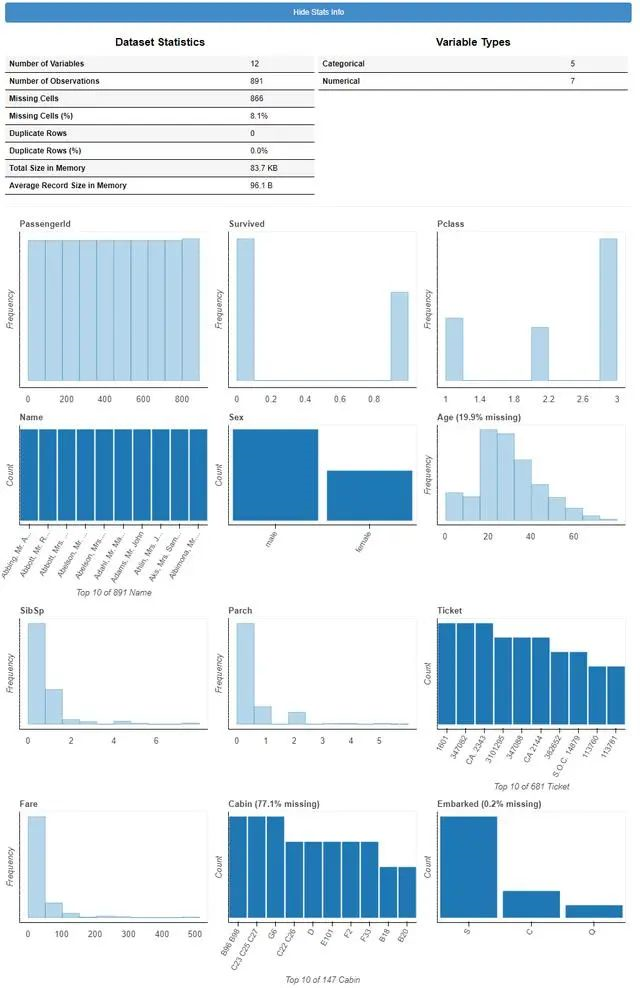
plot(df)顯示每列的分布。對(duì)于分類列,它以藍(lán)色顯示條形圖。對(duì)于數(shù)字列,它以灰色顯示直方圖。從圖的輸出,我們知道:
所有列:有1個(gè)標(biāo)簽列和11個(gè)特征 分類欄:幸存,PassengerId,Pclass,姓名,性別,票證,出發(fā)。 數(shù)字列:年齡,SibSp,parch,票價(jià)。 缺失值:從圖形標(biāo)題中,我們可以找到3列缺失值。即年齡(19.9%),機(jī)艙(77.1%),登機(jī)(0.2%)。 標(biāo)簽余額:來自幸存者的分布,我們知道,正面和負(fù)面的訓(xùn)練實(shí)例并不太平衡。 有38%的數(shù)據(jù)帶有標(biāo)簽Survived = 1。當(dāng)前,列類型(即分類或數(shù)字)基于輸入數(shù)據(jù)框中的列類型。因此,如果某些列類型被錯(cuò)誤地標(biāo)識(shí),則可以在數(shù)據(jù)框中更改其類型。例如,通過調(diào)用df [col] = df [col] .astype(“ object”),可以將col標(biāo)識(shí)為分類列。
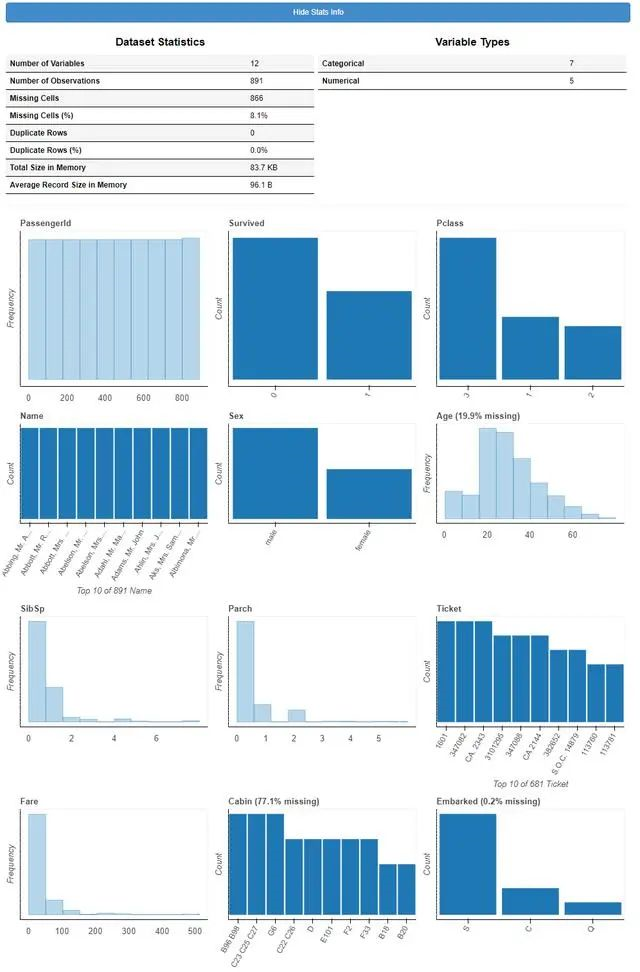
for col in ['Survived', 'Pclass']:train_df[col] = train_df[col].astype("object")plot(train_df)
要了解缺失值,我們首先調(diào)用plot_missing(df)來查看缺失值。
plot_missing(train_df)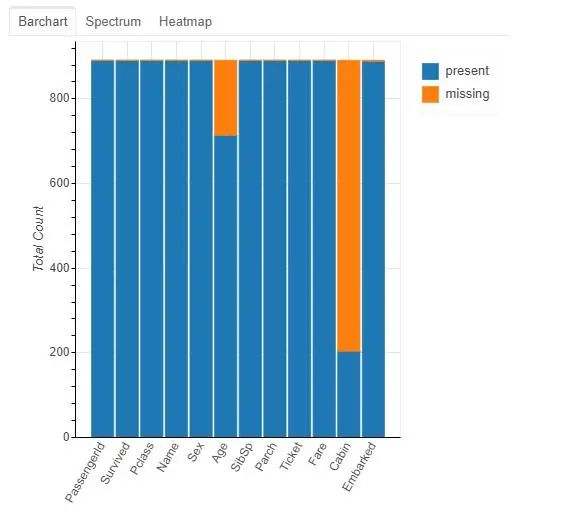
頂部是可選的,比如選擇spectrum可以更具體的看出缺失情況
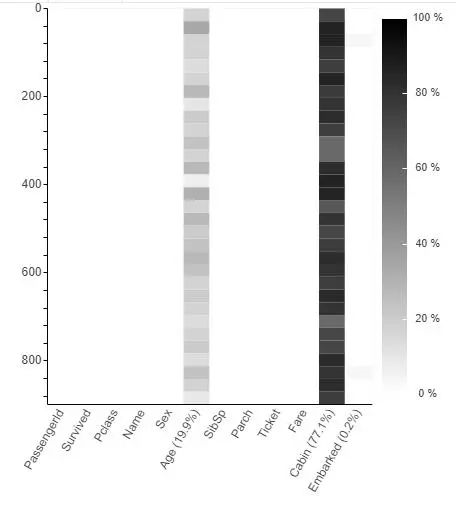
選擇heatmap可以用熱力圖形式查看缺失情況
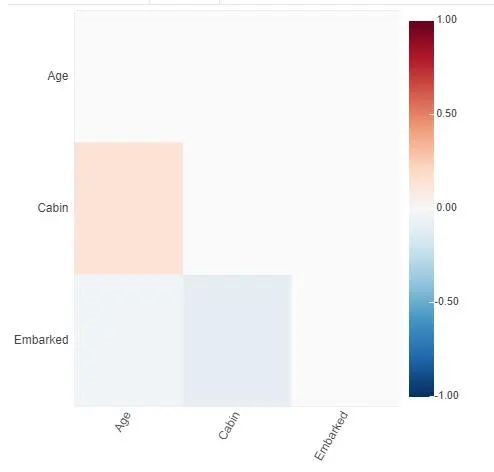
接下來,我們決定如何處理缺失值:如果要?jiǎng)h除缺失特征,刪除包含缺失值的行還是填充缺失值?我們首先分析它們是否與生存相關(guān)。如果它們是相關(guān)的,則我們可能不想刪除該特征。我們通過調(diào)用plot(df,x,y)分析兩列之間的相關(guān)性。這里就不展示了,大家可以探索一下,代碼如下
for feature in ['Age', 'Cabin', 'Embarked']:plot(train_df, feature, 'Survived')
現(xiàn)在,我們逐一確定了有用的特征,并刪除了無用的特征。雖然每個(gè)特征都可用于預(yù)測(cè)Survived,但是當(dāng)我們將它們一起考慮時(shí),我們可能不想要相關(guān)特征。因此,我們首先進(jìn)行身份相關(guān)的特征。這可以通過簡(jiǎn)單地調(diào)用plot_correlation(df)來完成。