
AI編程利器:Copilot
2021 年 6 月 30 日,微軟旗下代碼托管平臺 GitHub 推出了名為 Copilot 的 AI 結對編程工具,Copilot 的主要定位是提供代碼補全與建議功能,可根據(jù)當前文件的內容和光標位置自動生成代碼。
據(jù)了解,Copilot 由 OpenAI 的 Codex 系統(tǒng)提供支持。據(jù) Copilot 網(wǎng)站稱,Codex 模型由“互聯(lián)網(wǎng)上的公共代碼和文本”訓練,“既能理解編程,也能理解人類語言”。作為 Visual Studio Code 的擴展,Copilot “將你的評論和代碼發(fā)送到 GitHub Copilot 服務,然后它會使用 OpenAI Codex 來合成并建議個別行和整個函數(shù)”。
作為一款 AI 編程神器,Copilot 從誕生之初就爭議不斷。
擁護者認為它確實可以提高生產(chǎn)力,反對者認為它寫的代碼錯誤率高,開發(fā)者還需要花費額外的時間做代碼審查。有的爭議焦點集中在 Copilot 是否涉及侵權上——畢竟 Copilot 宣稱的基于公開代碼訓練,其實是在未遵循開源許可證的情況下,肆意“抄襲”開源代碼。
在 Copilot 正式發(fā)布一年之際,GitHub 對 2000 多名開發(fā)者展開了調查,以期了解 Copilot 到底改變了什么?
Copilot 大調研結合調查與實驗,GitHub 整理出一份 Copilot 在開發(fā)者群體中實際影響力的結論性資料。
GitHub 研究員 Eirini Kalliamvakou 在一篇博文中提到:由于 AI 輔助開發(fā)還是個相對較新的領域,作為研究人員,我們幾乎找不到可供借鑒的早期成果。我們希望衡量 GitHub Copilot 的實際效果如何,而且在早期觀察和用戶采訪之后,我們決定對 2000 多名開發(fā)者進行大規(guī)模調查,了解他們的使用體驗和感受。
在設計研究方法時,我們主要考慮到以下三大重點:
-
立足整體關注生產(chǎn)力。在 GitHub,我們喜歡廣泛且可持續(xù)地考量開發(fā)者的生產(chǎn)力及相關影響因素。我們使用 SPACE 生產(chǎn)力框架選擇需要調查的具體方向。
-
考量來自開發(fā)者的第一手觀點。我們開展了多輪研究,包括定性(認知)與定量(觀察)數(shù)據(jù),希望拼湊出可靠的真相。我們希望驗證:(1)用戶的實際體驗,能否證實我們推斷出的結論?(2)我們的定性反饋,是否同樣適合更廣大的用戶群體?
-
評估 GitHub Copilot 在日常開發(fā)場景中的效果。在設計研究方法時,我們特別注意覆蓋專業(yè)開發(fā)人員,并圍繞他們在工作日內面對的典型任務進行測試設計。最終的調查結果,既有意料之中的發(fā)現(xiàn),也有意外驚喜。
除了加快開發(fā)速度之外,Copilot 還能給程序員帶來哪些額外幫助?
調查發(fā)現(xiàn):
-
開發(fā)者滿意度有所提升。60% 至 75% 的用戶表示,他們對現(xiàn)在的工作體驗更滿意,編碼時的精神壓力更小,而且 Copilot 能幫助他們更專注地達成令人滿意的工作成效。
-
緩解精神內耗。開發(fā)者們報告稱,Copilot 能幫助他們穩(wěn)步推進開發(fā)流程(73%),并在處理重復性任務期間降低精力消耗(87%)。
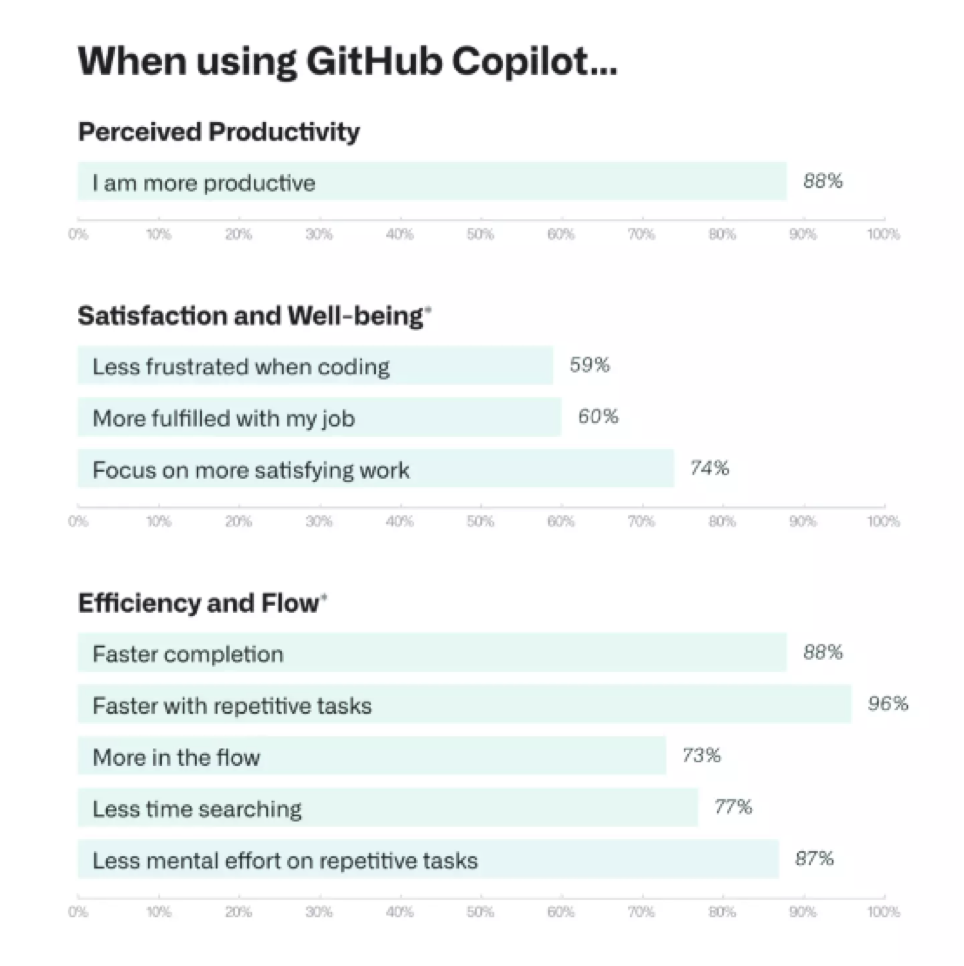
有近 90% 的開發(fā)者們表示,在使用 Copilot 時,他們完成任務,特別是重復性任務的速度更快了。這也符合 GitHub 在產(chǎn)品設計時做出的基本預期。
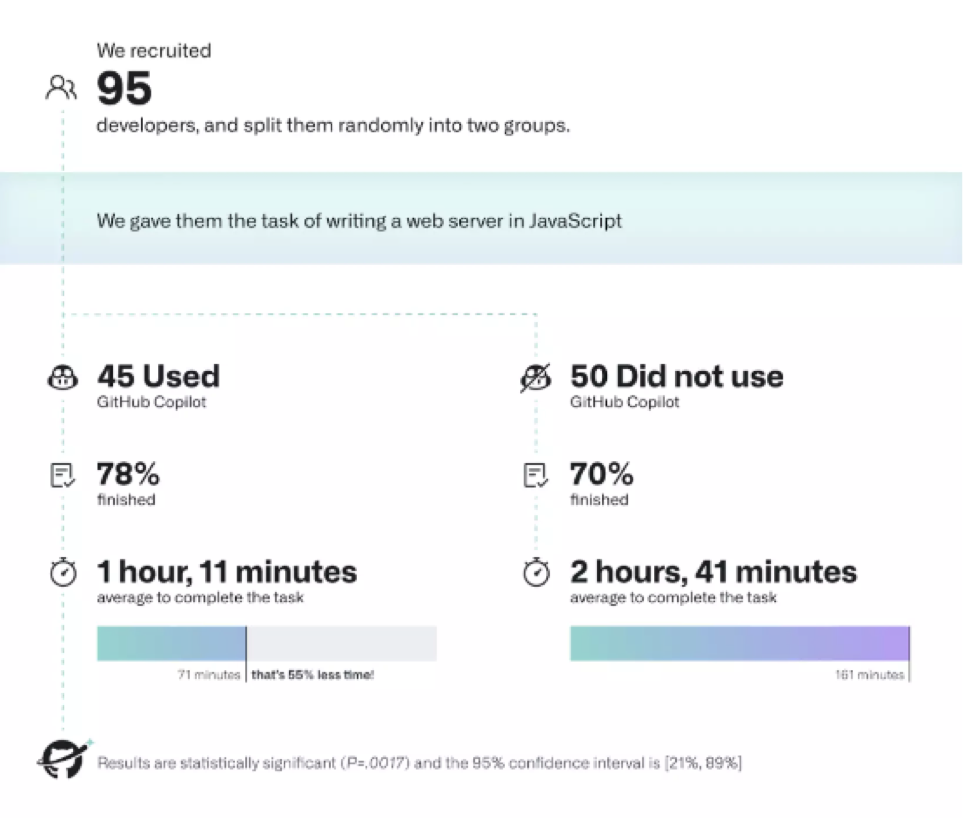
為了在實踐中觀察并量化這種提升效果,GitHub 組織了一場對照實驗。兩個受試小組(其中一組使用 Copilot)需要接受計時,核算用 JavaScript 編寫 HTTP 服務器的平均用時。
實驗發(fā)現(xiàn):
-
使用 Copilot 的小組完成任務的比例更高,為 78%,未使用 Copilot 的小組完成任務比例為 70%。
-
更顯著的區(qū)別在于,使用 Copilot 的開發(fā)者完成任務的速度明顯更快,要比未使用 Copilot 的開發(fā)者快 55%。具體來看,使用 Copilot 的開發(fā)者完成此項任務的平均用時為 1 小時 11 分鐘,而未使用 Copilot 的開發(fā)者平均用時達 2 小時 41 分鐘。綜上,該項調查和實驗最終得出的結論是,“Copilot 有助于加快工作完成速度,幫助開發(fā)者減少精神內耗,以更加飽滿的精神狀態(tài)專注于工作內容,最終在自己的編碼過程中找到更多樂趣。”
對于這一調查結果,有開發(fā)者留言表示支持:“使用 Copilot,我能盡量少把精力浪費在枯燥重復的工作身上。它點燃的靈感火花,讓我感到編碼過程更有趣、更高效了。”
GitHub 研究員 Eirini Kalliamvakou 表示,“隨著 Copilot 的出現(xiàn),我們在 AI 驅動型代碼補全工具的探索道路上不再是孤軍奮戰(zhàn)。在實際生產(chǎn)領域,我們最近看到一項針對 24 名學生的評估,谷歌也在內部評估利用機器學習增強代碼補全的可能性。
著眼于整個行業(yè),研究社區(qū)正認真分析 GitHub Copilot 在各類場景下的實際影響,包括教育、安全、勞動力市場,乃至開發(fā)者的實踐與行為。我們目前正在各類環(huán)境下觀察 Copilot 的實際效果。這是個不斷發(fā)展的領域,我們對研究社區(qū)和自身調查中的發(fā)現(xiàn)感到振奮,也將未來幾個月內為大家揭曉更多消息。”
為什么 Copilot 會編寫出 糟糕的代碼?GitHub 的調研結果展現(xiàn)了 Copilot 在開發(fā)者群里中起到積極作用的一面,但任何事物都有其兩面性,Copilot 本身帶有的爭議也不容忽視。開發(fā)者在決定是否采用 Copilot 前,需要對其有充分的了解。
其中,Copilot 比較大的一個爭議點在于代碼錯誤率高。
Copilot 由名為 Codex 的深度神經(jīng)網(wǎng)絡語言模型提供支持,該模型在 GitHub 上的公共代碼存儲庫上進行了訓練。它讀取了 GitHub 的整個公共代碼檔案,其中包含數(shù)千萬個存儲庫,匯聚了來自許多世界上最優(yōu)秀程序員的代碼。
那么,為什么 Copilot 還是會編寫出糟糕的代碼呢?
根據(jù) OpenAI 的論文,Codex 只有 29% 的時間會給出正確答案。而且它編寫的代碼往往重構得很差,無法充分利用現(xiàn)有的解決方案(即使這些方案就在 Python 的標準庫中)。
Copilot 編寫出糟糕的代碼,原因在于語言模型的工作機制。它們反映的是大多數(shù)人的平均寫作水平。它們不知道什么是正確的,什么是好的寫法。GitHub 上的大多數(shù)代碼(根據(jù)軟件標準)相當陳舊,并且(根據(jù)定義)是由水平一般的程序員編寫的。
Copilot 盡力猜測的是,如果這些程序員正在編寫的是你面對的這些文件,他們可能會寫什么代碼。OpenAI 在他們的 Codex 論文中討論了這一點:
“與其他訓練目標是預測下一個詞符的大型語言模型一樣,Codex 會生成與其訓練分布盡可能相似的代碼。這樣做的一個后果是,這種模型可能會做一些對用戶無益的事情”
Copilot 之所以比那些水平一般的程序員更糟糕,一個關鍵問題在于,它甚至沒有嘗試編譯代碼或檢查代碼是否有效,也沒有考慮過自己是否真的遵循了文檔的指示。此外,Codex 沒有接受過去一兩年內創(chuàng)建代碼的訓練,因此它完全沒學過最新版本、庫和語言特性。例如,提示它創(chuàng)建 fastai 代碼后,它只會給出使用 v1 API 的建議,而不是大約一年前發(fā)布的 v2 版本。
值得一提的是,今年 4 月,微軟推出了 AI 代碼審查工具 Jigsaw,以期進一步提升 AI 編碼的準確率。
在研究論文《Jigsaw:當大型語言模型牽手程序綜合》(Jigsaw: Large Language Models meet Program Synthesis,文章已被國際軟件工程會議 ICSE 2022 接收)中,微軟介紹了一種可以提高這類大型語言模型性能的新工具。Jigsaw 中包含可以理解程序語法及語義的后處理技術,可利用用戶的反饋不斷提升修正能力。配合多模輸入,Jigsaw 即可為 Python Pandas API 合成代碼。
隨著 Jigsaw 逐步在提高系統(tǒng)準確性方面發(fā)揮重要作用,Copilot 這類 AI 編程工具準確率或將獲得提升。
參考鏈接:
https://github.blog/2022-09-07-research-quantifying-github-copilots-impact-on-developer-productivity-and-happiness/
https://www.infoq.cn/article/mvLSYZfNmhmCj7vN8KVP
往期精彩:
?深度學習論文精讀[14]:Vision Transformer