
ClickHouse在騰訊游戲營銷效果分析中的探索實踐
導(dǎo)讀:營銷活動作為游戲運(yùn)營的一種重要手段,可以靈活快速的配合游戲各個運(yùn)營節(jié)點(diǎn)的需要而推出,不受游戲版本節(jié)奏的影響。而面對數(shù)量眾多的營銷活動和不同的業(yè)務(wù)訴求,如何在海量日志中評價營銷的效果是一個典型的多維分析問題,本次分享主要介紹騰訊游戲營銷效果分析的一些概況以及ClickHouse的應(yīng)用實踐情況。通過實踐表明,ClickHouse完美解決了查詢瓶頸,20億行以下的數(shù)據(jù)量級查詢,90%可以在亞秒(1秒內(nèi))給到結(jié)果。
營銷活動在游戲之外配合熱點(diǎn)事件和用戶深入交流,是拉回流、促活躍的重要手段。那么,大量營銷活動如何快速進(jìn)行效果分析,得到準(zhǔn)確的營銷效果?
我們先來看一個具體的營銷行為路徑:
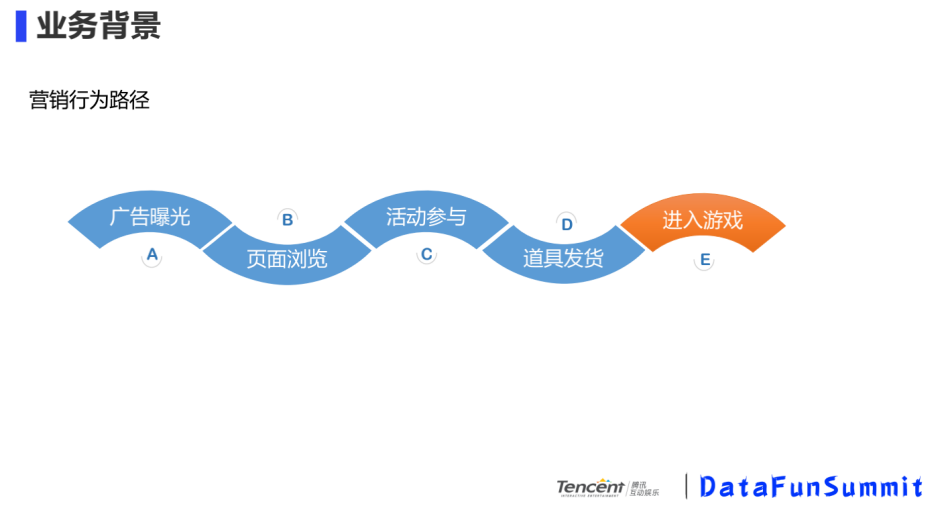
游戲玩家被營銷活動投放的廣告吸引過來,到營銷活動的頁面瀏覽,瀏覽的同時,如果玩家對營銷活動感興趣,會進(jìn)行下一步的活動參與,參與達(dá)到條件后,會根據(jù)營銷活動的規(guī)則,獲得道具或者是裝備的發(fā)放、領(lǐng)取,之后游戲玩家進(jìn)入游戲。
對于上述場景,用戶的每個行為階段都會產(chǎn)生不同的指標(biāo),運(yùn)營方往往有很多的分析訴求:
運(yùn)營A:我的活動剛剛發(fā)布了,能不能看下現(xiàn)在實時的曝光和參與情況?
運(yùn)營B:我的活動投入了一個新出的稀有道具,能看到這個道具的發(fā)放情況并提出用戶包嗎?
運(yùn)營C:我在某投放平臺買了廣告位,能分析下這個廣告位帶給我的效果情況嗎?
運(yùn)營D:這次活動主要目的是拉回流,能看看我到底給游戲拉了多少回流嗎?
運(yùn)營E:這次活動是精細(xì)化挖掘推薦,能看看特定大R人群的參與情況嗎?
以上的訴求總結(jié)下來就是多指標(biāo)、多維度、時效性、去重用戶包。
技術(shù)難點(diǎn):面對眾多的營銷活動,每個營銷活動周期都不一樣,維度眾多,在這個基礎(chǔ)上還會有多種指標(biāo),如何在海量日志下做多周期、多維度的去重分析?我們來看看我們的技術(shù)選型及演進(jìn)。
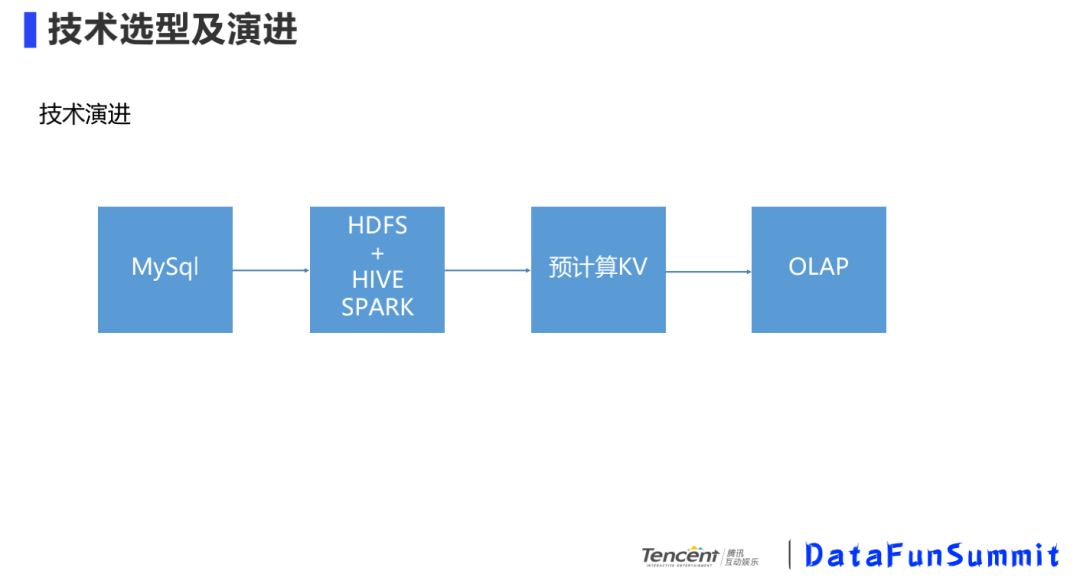
技術(shù)演進(jìn)是每個公司都有的過程,一開始數(shù)據(jù)量較小,直接在DB數(shù)據(jù)庫中就可以滿足分析需求;隨著數(shù)據(jù)規(guī)模越來越大,要借助hdfs、hive/spark的一些框架;再往后,隨著實時性的要求越來越高,需要實時計算框架,對維度做預(yù)計算;隨著維度爆炸,預(yù)計算就不太適用了,分析路徑比較死,增加一個維度得改模型,這時就需要為OLAP專門量身打造分析型數(shù)據(jù)庫。
① Mysql
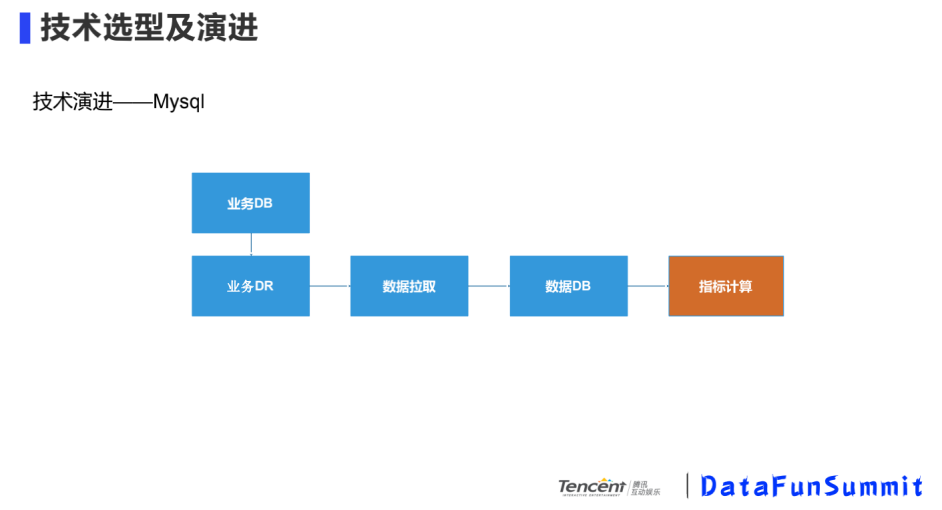
優(yōu)點(diǎn):直接從業(yè)務(wù)DB拉取數(shù)據(jù),比較簡單
缺點(diǎn):支持?jǐn)?shù)據(jù)規(guī)模小,和業(yè)務(wù)之間有耦合
② HDFS&HIVE/SPARK
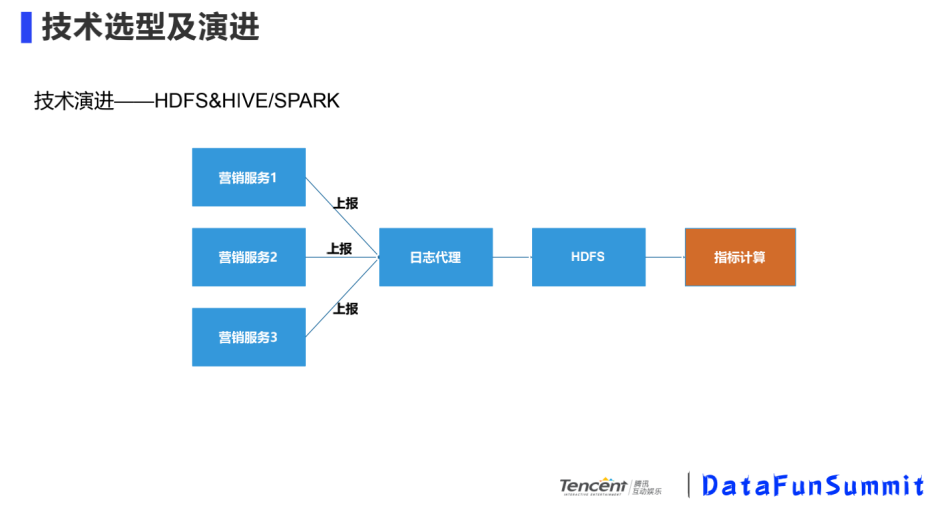
基于DB分析的缺點(diǎn),我們支持了大規(guī)模數(shù)據(jù)和業(yè)務(wù)做解耦,選用HDFS&HIVE/SPARK的方案。我們統(tǒng)一了營銷服務(wù)日志模型,當(dāng)接到上報日志后,上傳給HDFS。這個方案支持的數(shù)據(jù)量比較大,缺點(diǎn)是計算的速度比較慢,適用于T-1的計算效果。
③ 預(yù)計算KV
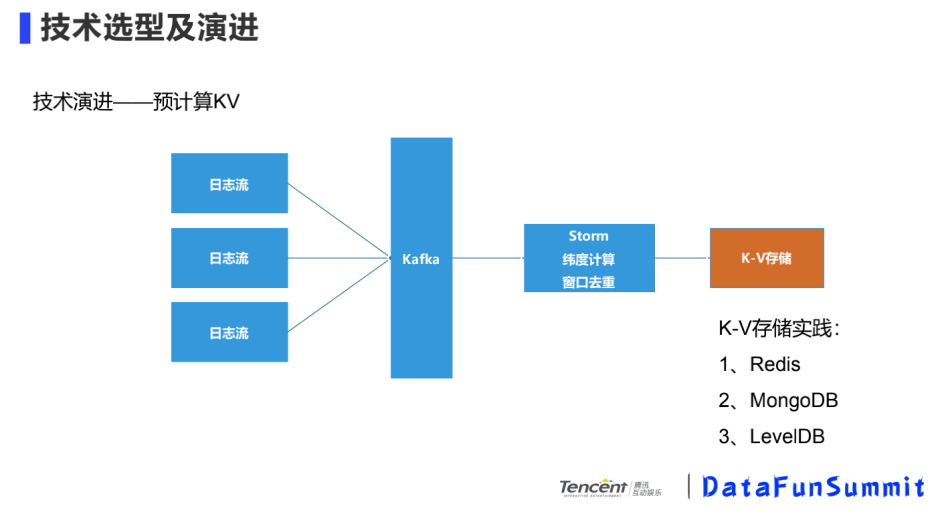
基于計算慢的問題,我們在日志流層面引入了實時計算框架,日志流經(jīng)過Kafka,入到Storm,對預(yù)設(shè)的維度進(jìn)行預(yù)計算,計算的結(jié)果存儲到K-V數(shù)據(jù)庫中,查詢時去K-V庫中查詢。這里基于業(yè)務(wù)場景,想要快速的導(dǎo)出用戶包,用文件數(shù)據(jù)庫存儲更方便,最大的缺點(diǎn)是新增維度要做一些處理,維度爆炸到一定程度,維護(hù)成本較高。
④ OLAP
面對緯度爆炸問題,我們開始調(diào)研OLAP。
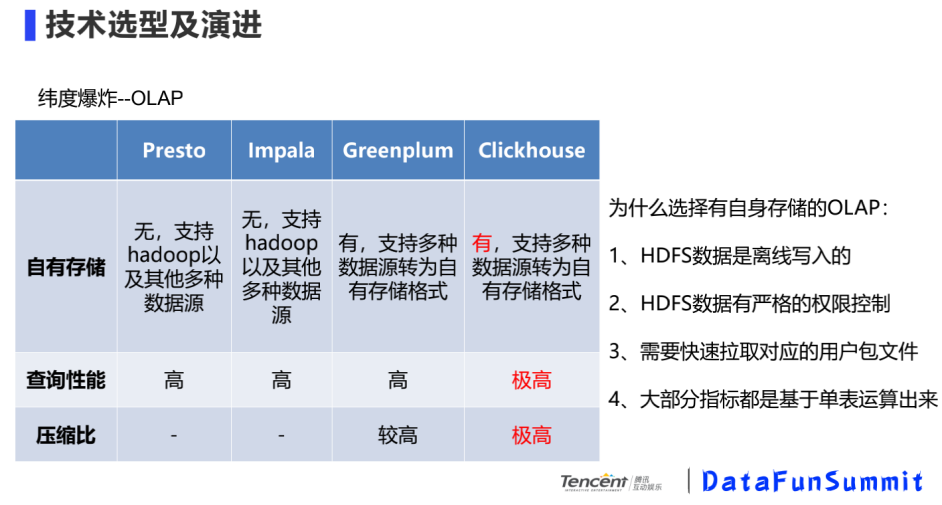
為什么選擇有自身存儲的OLAP?
HDFS數(shù)據(jù)是離線寫入的
HDFS數(shù)據(jù)由嚴(yán)格的權(quán)限控制
需要快速拉取對應(yīng)的用戶包文件
大部分指標(biāo)是基于單標(biāo)運(yùn)算出來
根據(jù)業(yè)務(wù)場景,對比上訴三個性能,最看重自有存儲。因為在一張大寬表下,查詢性能很重要。
1. ClickHouse介紹
ClickHouse是Yandex開源的一個用于實時數(shù)據(jù)分析的基于列存儲的數(shù)據(jù)庫,其處理數(shù)據(jù)的速度比傳統(tǒng)方法快100-1000倍。
ClickHouse的性能超過了目前市場上可比的面向列的DBMS,每臺服務(wù)器每秒可處理數(shù)億至十億行的數(shù)據(jù)。
OLAP的特點(diǎn):
讀多于寫:不同于事務(wù)處理(OLTP)的場景,數(shù)據(jù)分析(OLAP)場景通常是將數(shù)據(jù)批量導(dǎo)入后,進(jìn)行任意維度的靈活探索、BI工具洞察、報表制作等。
大寬表:讀大量行但是少量列,結(jié)果集較小。在OLAP場景中,通常存在一張或是幾張多列的大寬表,列數(shù)高達(dá)數(shù)百甚至數(shù)千列。對數(shù)據(jù)分析處理時,選擇其中的少數(shù)幾列作為維度列、其他少數(shù)幾列作為指標(biāo)列,然后對全表或某一個較大范圍內(nèi)的數(shù)據(jù)做聚合計算。這個過程會掃描大量的行數(shù)據(jù),但是只用到了其中的少數(shù)列。而聚合計算的結(jié)果集相比于動輒數(shù)十億的原始數(shù)據(jù),也明顯小得多。
數(shù)據(jù)批量寫入:OLTP類業(yè)務(wù)數(shù)據(jù)不更新或少更新,對于延時要求更高,要避免讓客戶等待造成業(yè)務(wù)損失;而OLAP類業(yè)務(wù),由于數(shù)據(jù)量非常大,通常更加關(guān)注寫入吞吐量。
無需事務(wù),數(shù)據(jù)一致性要求低:OLAP類業(yè)務(wù)對于事務(wù)需求較少,通常是導(dǎo)入歷史日志數(shù)據(jù),或搭配一款事務(wù)型數(shù)據(jù)庫并實時從事務(wù)型數(shù)據(jù)庫中進(jìn)行數(shù)據(jù)同步。
靈活多變,不適合預(yù)先建模:分析場景下,隨著業(yè)務(wù)變化要及時調(diào)整分析維度、挖掘方法,以盡快發(fā)現(xiàn)數(shù)據(jù)價值、更新業(yè)務(wù)指標(biāo)。
從自身的場景出發(fā),我們關(guān)注到的ClickHouse優(yōu)缺點(diǎn):

對于業(yè)務(wù)場景中去重類的聚合查詢,最終的查詢結(jié)果落到一臺機(jī)器上,對單機(jī)性能影響比較大。后面會具體講到這些缺點(diǎn)的解決方案。
我們的系統(tǒng)架構(gòu)如下:
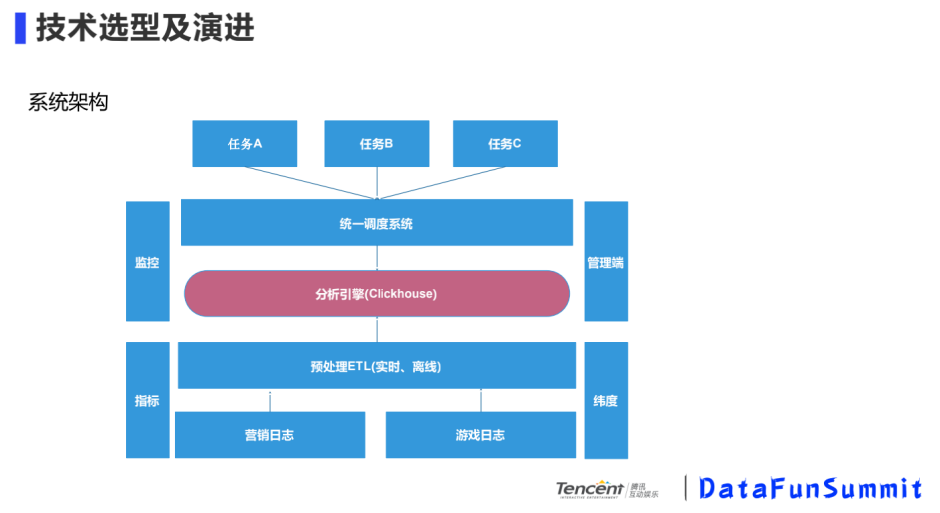
使用定位:高效的計算引擎
統(tǒng)一調(diào)度:緩存結(jié)果、限流、對一些很大的查詢邏輯加速
預(yù)處理ETL:壓縮日志、對日志清洗、對熱點(diǎn)數(shù)據(jù)邏輯分片
2. CK實踐優(yōu)化
① CK實踐優(yōu)化-集群限流

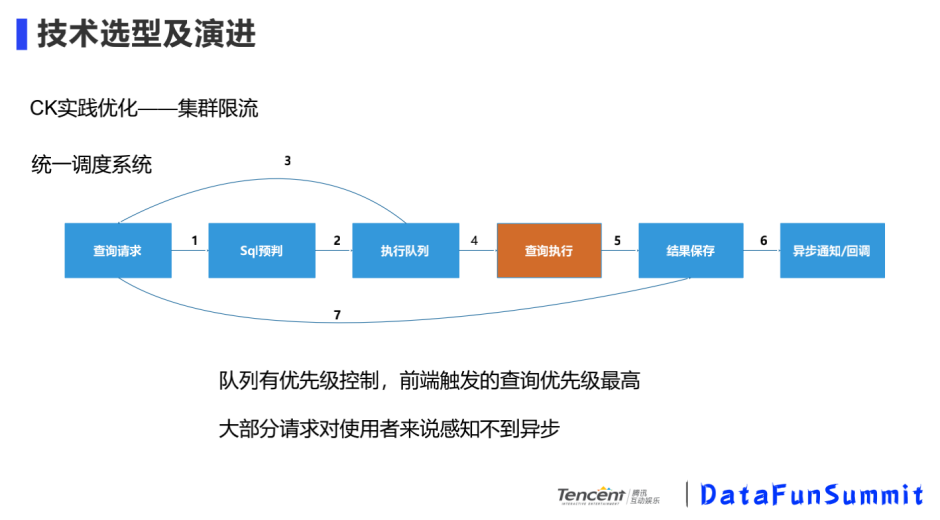
當(dāng)接到SQL查詢請求,我們做了一個SQL預(yù)判,將SQL放進(jìn)執(zhí)行隊列里,隊列里有優(yōu)先級控制,前端觸發(fā)的查詢優(yōu)先級最高,大部分請求對使用者來說感知不到異步,前端會做loading幾秒鐘,一般是可以接受,感知不到這個時間。
② CK實踐優(yōu)化-BadSQL檢測

不是說SQL本身語法或者邏輯不正確,而是指一些很大的SQL,比如說查詢的數(shù)據(jù)的時間段間隔很大,數(shù)據(jù)量較多,查詢可能會對集群安全性造成影響,會做些預(yù)判。
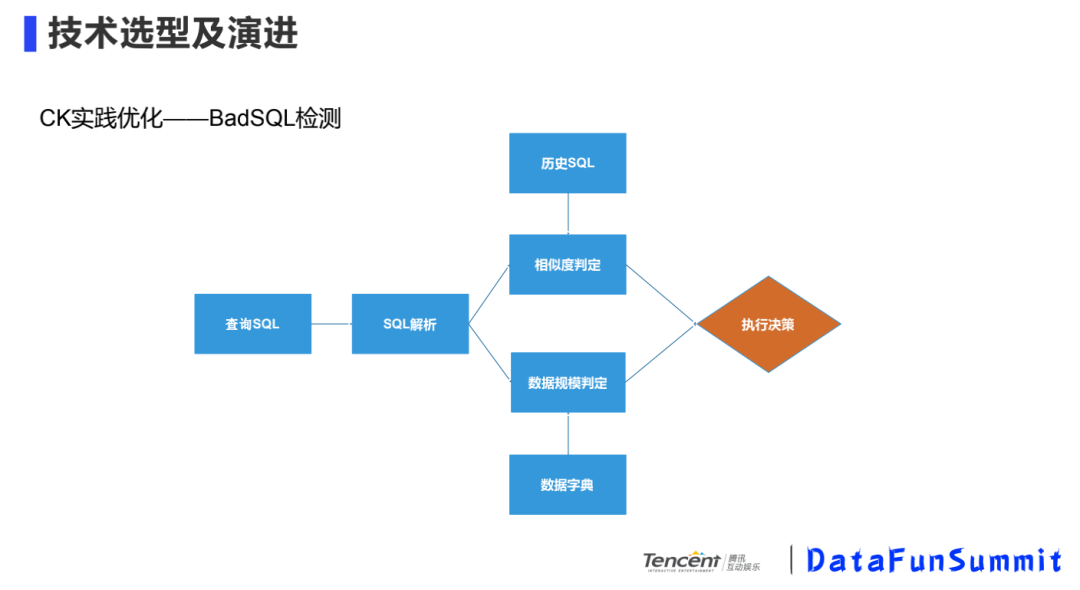
我們會對查詢SQL進(jìn)行解析,然后和歷史SQL進(jìn)行對比,看一下之前的SQL是怎么樣的,做一個相似度的判斷,結(jié)合數(shù)據(jù)字典,判斷掃描數(shù)據(jù)的規(guī)模。如果判斷這條SQL查詢的數(shù)據(jù)規(guī)模很大,會把一次查詢分成很多次查詢,將結(jié)果聚合起來得到最終結(jié)果。我們也會對一些較大的SQL做一些事后分析,對以后查詢提供歷史的SQL。
③ CK實踐優(yōu)化-數(shù)據(jù)預(yù)處理

CK本身有寫入并發(fā)不高的缺點(diǎn),而且在營銷活動的場景中,熱點(diǎn)的營銷活動數(shù)據(jù)會有傾斜現(xiàn)象,如何避免熱點(diǎn)數(shù)據(jù)傾斜問題,需要在寫入的時候做一些預(yù)處理。
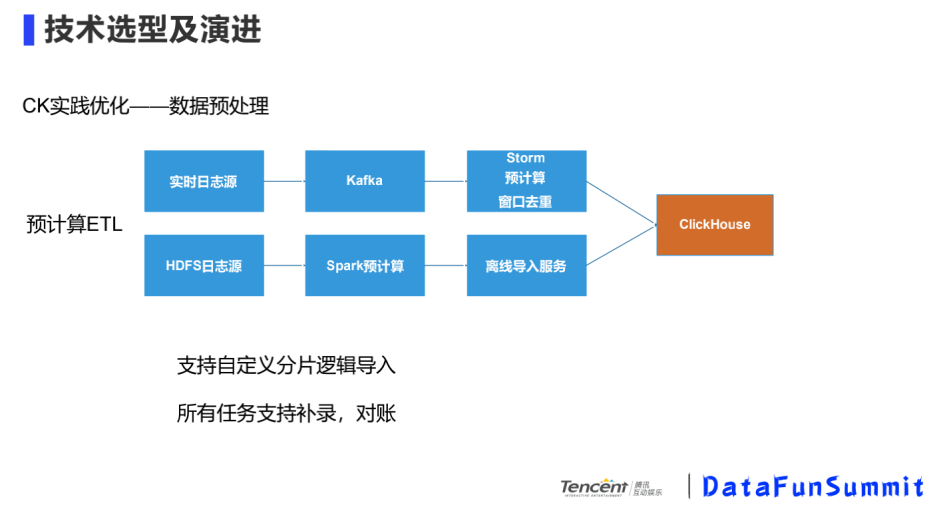
我們的業(yè)務(wù)場景有實時和離線的HDFS數(shù)據(jù)源,實時的數(shù)據(jù)源經(jīng)過Kafka,寫入到Storm中做一些預(yù)計算,去重工作;HDFS離線數(shù)據(jù)源,通過Spark做離線的預(yù)計算,在寫入時通過配置Hash Key將數(shù)據(jù)寫入到相應(yīng)的分片中。

目前營銷活動產(chǎn)生的數(shù)據(jù)量壓縮前50+TB,效果指標(biāo)100+,效果維度1000+,請求耗時85%以上都小于800ms,經(jīng)過歷史統(tǒng)計自定義去重比Hive提速500倍左右。
1. 熱點(diǎn)數(shù)據(jù)的處理

熱點(diǎn)數(shù)據(jù)是數(shù)據(jù)組件通用的問題,對數(shù)據(jù)寫入時進(jìn)行預(yù)分片,保證數(shù)據(jù)分散到每個計算node上,對事先分片的數(shù)據(jù)進(jìn)行分批查詢,一個shard一個shard的查詢。
對一些熱點(diǎn)數(shù)據(jù)也可以采用單獨(dú)部署的方式,避免受一些其他業(yè)務(wù)的影響。
2. zookeeper的使用

對于存儲性的組件,經(jīng)過優(yōu)化,正在逐步對zookeeper降低依賴程度:
自己保證數(shù)據(jù)一致性,不用走zookeeper,特別是臨時性的需求
ck集群對zk使用是表級別的,表的數(shù)量擴(kuò)張,znode數(shù)量也會急劇的擴(kuò)張,所以要控制集群中表的數(shù)量
搭建zk集群時,使用性能較好的機(jī)器
快照及時清理
搭建多zk集群,每一個zk集群指定不同的表,減少zk的壓力
3. 單機(jī)瓶頸

數(shù)據(jù)分析到最后一步聚合、去重,導(dǎo)出用戶包最終會落到一臺機(jī)器上,這對一臺機(jī)器的壓力就比較大,要提升硬件,增加內(nèi)存,cpu使用限制的配置,不然有可能將集群崩潰或者某個節(jié)點(diǎn)掛掉。
根據(jù)業(yè)務(wù)邏輯進(jìn)行拆分表,分shard根據(jù)不同的節(jié)點(diǎn)查詢。
4. 數(shù)據(jù)遷移


促進(jìn)ck在更多地業(yè)務(wù)場景落地,更多業(yè)務(wù)的接入:比如用戶的行為分析,實時數(shù)倉,實時報表,ck實時明細(xì)類報表的引入,能夠使得用戶更加實時,方便地進(jìn)行報表分析。
更加完善的周邊工具建設(shè):比如說ck支持更多的數(shù)據(jù)源,可以從多個數(shù)據(jù)源導(dǎo)入到ck中或者從ck中一鍵導(dǎo)出到其他數(shù)據(jù)源;再比如說安全、運(yùn)維的一些工具建設(shè),能更好的支持運(yùn)維。
容器化部署:容器化部署更高擁有更好的彈性伸縮能力,也能和其他的服務(wù)進(jìn)行混合部署節(jié)省成本。此外,有寫業(yè)務(wù)的導(dǎo)入數(shù)據(jù)量非常巨大。但是其實查詢量并不大,就是因為讀寫不分離,這時導(dǎo)入的數(shù)據(jù)量反而決定了集群的規(guī)模。因此希望將讀寫進(jìn)行分離,寫入部分通過容器化技術(shù)臨時構(gòu)建集群來完成。
Q:在擴(kuò)容時數(shù)據(jù)如何做Rebalance?
A:目前ck的最大痛點(diǎn)就是擴(kuò)容/縮容后的數(shù)據(jù)無法自平衡,如果說數(shù)據(jù)是無狀態(tài)的,和業(yè)務(wù)數(shù)據(jù)邏輯無關(guān)的,直接從shard級別復(fù)制就好。如果說是業(yè)務(wù)邏輯有關(guān)的熱點(diǎn)數(shù)據(jù),比如用戶ID切成100個分片,10臺機(jī)器擴(kuò)容到20臺,100個分片如何分布,目前基本上處于原始的一個階段。有邏輯的數(shù)據(jù),看一下之前的數(shù)據(jù)是怎樣分布的,邏輯的Rebalance,用remote函數(shù),如果數(shù)據(jù)量大的利用clickhouse-copier工具幫助運(yùn)維。
Q:Clickhouse的結(jié)果是怎么保存起來的?
A:做緩存的有一定要求,如果數(shù)據(jù)集在一定規(guī)模以下,就可以直接緩存在redis中,如果說是取包的操作,這個是沒辦法緩存的,后臺計算好load到一臺機(jī)器上,去什么地方拉取就可以。