
使用深度學(xué)習(xí)進(jìn)行瘧疾檢測(cè) | PyTorch版
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
蚊子看起來(lái)很小,很脆弱,但是是非常危險(xiǎn)的。眾所周知,瘧疾對(duì)所有年齡段的人來(lái)說(shuō)都是一種威脅生命的疾病,它通過(guò)蚊子傳播。更重要的是,在最初的階段,這些癥狀很容易被誤認(rèn)為是發(fā)燒、流感或普通感冒。但是,在晚期,它可以通過(guò)感染和破壞細(xì)胞結(jié)構(gòu)造成嚴(yán)重破壞,這可能危及生命。如果不及時(shí)治療,甚至可能導(dǎo)致死亡。
雖然大多數(shù)研究人員認(rèn)為這種疾病起源于非洲大陸,但這種疾病的起源仍有爭(zhēng)議。南美洲國(guó)家、非洲國(guó)家和印度次大陸由于瘧疾而面臨很高的感染風(fēng)險(xiǎn),這主要是由于它們的熱帶氣候是受感染雌蚊的催化劑和繁殖場(chǎng)所,而受感染的雌蚊攜帶造成這種疾病的瘧原蟲(chóng)寄生蟲(chóng)。
我們這個(gè)項(xiàng)目的目標(biāo)是開(kāi)發(fā)一個(gè)系統(tǒng),可以檢測(cè)這種致命的疾病,而不必完全依靠醫(yī)學(xué)測(cè)試。
所以,在進(jìn)入主要部分之前,讓我們先完成一些相關(guān)工作。
這個(gè)數(shù)據(jù)集最初來(lái)自于美國(guó)國(guó)立衛(wèi)生研究院的網(wǎng)站并上傳到 Kaggle。數(shù)據(jù)集包含27558張細(xì)胞圖像。其中,我們有13779張被瘧疾感染的細(xì)胞圖像和另外13779張未感染的圖像。我們正在試圖解決一個(gè)分類問(wèn)題。使用的框架是 Pytorch。數(shù)據(jù)集下載地址為:https://www.kaggle.com/iarunava/cell-images-for-detecting-malaria
現(xiàn)在,讓我們開(kāi)始創(chuàng)建我們的瘧疾檢測(cè)模型。
導(dǎo)入相關(guān)庫(kù)
現(xiàn)在讓我們來(lái)做一些數(shù)據(jù)探索:
首先,我們將輸入數(shù)據(jù)并對(duì)其進(jìn)行圖像相關(guān)處理
import osimport torchimport pandas as pdimport numpy as npfrom torch.utils.data import Dataset, random_split, DataLoaderfrom PIL import Imageimport torchvision.models as modelsimport matplotlib.pyplot as pltimport torchvision.transforms as transformsfrom sklearn.metrics import f1_scoreimport torch.nn.functional as Fimport torch.nn as nnfrom torchvision.utils import make_grid%matplotlib inline
a) 數(shù)據(jù)集包含不規(guī)則形狀的圖像。這將阻礙模特訓(xùn)練。因此,我們將圖像調(diào)整為128 x 128的形狀。
b) 我們還將把數(shù)據(jù)轉(zhuǎn)換為張量,因?yàn)樗鞘褂蒙疃葘W(xué)習(xí)訓(xùn)練模型的有用格式。
PyTorch 的美妙之處在于,它允許我們通過(guò)使用非常少的代碼行來(lái)進(jìn)行圖像的各種操作。
from torchvision.datasets import ImageFolderfrom torchvision.transforms import ToTensorfrom torchvision.transforms import Composefrom torchvision.transforms import Resizefrom torchvision.transforms import ToPILImagedataset = ImageFolder(data_dir, transform=Compose([Resize((128, 128), interpolation=3),ToTensor()]))classes = dataset.classesprint(classes)len(dataset)
['Parasitized', 'Uninfected']
27558現(xiàn)在,我們將編寫(xiě)一個(gè)輔助函數(shù)來(lái)可視化一些圖像。
import matplotlib.pyplot as pltdef show_example(img, label):print('Label: ', dataset.classes[label], "("+str(label)+")")plt.imshow(img.permute(1, 2, 0))
讓我們看一組這兩個(gè)類的圖像。
show_example(*dataset[2222])
show_example(*dataset[22269])
為了獲得可重復(fù)的結(jié)果,我們需要通過(guò)設(shè)置seed。
random_seed = 42torch.manual_seed(random_seed);
現(xiàn)在,讓我們將整個(gè)圖像集劃分為訓(xùn)練集、驗(yàn)證集和測(cè)試集。顯然,訓(xùn)練集是用于訓(xùn)練模型的,而驗(yàn)證集是用于確保訓(xùn)練朝著正確的方向進(jìn)行。測(cè)試集是用來(lái)測(cè)試模型最后的性能。
val_size = 6000train_size = 16000test_size = len(dataset) - val_size - train_sizetrain_ds, val_ds, test_ds = random_split(dataset, [train_size, val_size, test_size])len(train_ds), len(val_ds), len(test_ds)
(16000, 6000, 5558)
我們將嘗試通過(guò)使用批量圖像來(lái)訓(xùn)練我們的模型。在這里,PyTorch 的 DataLoader 為我們提供了便利。它提供了對(duì)給定數(shù)據(jù)集的迭代。
from?torch.utils.data.dataloader?import?DataLoaderbatch_size=128
我們將使用 DataLoader 創(chuàng)建用于訓(xùn)練和驗(yàn)證的批處理。我們需要確保在訓(xùn)練期間內(nèi)部調(diào)整批次。這只是為了在模型中引入一些隨機(jī)性。我們沒(méi)有用于驗(yàn)證集的內(nèi)部 shuffle,因?yàn)槲覀冎皇鞘褂盟鼇?lái)驗(yàn)證每個(gè)epoch的模型性能。
train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)val_dl = DataLoader(val_ds, batch_size*2, num_workers=4, pin_memory=True)
現(xiàn)在讓我們嘗試可視化一批圖像。
from torchvision.utils import make_griddef show_batch(dl):for images, labels in dl:fig, ax = plt.subplots(figsize=(12, 6))ax.set_xticks([]); ax.set_yticks([])ax.imshow(make_grid(images, nrow=16).permute(1, 2, 0))break

因?yàn)槲覀兊臄?shù)據(jù)是圖像,所以我們要訓(xùn)練一個(gè)卷積神經(jīng)網(wǎng)絡(luò)。如果你害怕聽(tīng)這些,那么你并不孤單。當(dāng)我第一次聽(tīng)到 CNN 時(shí),我也非常害怕。但是,坦白地說(shuō),由于 Tensorflow 和 PyTorch 這樣的深度學(xué)習(xí)框架,它們的理解非常簡(jiǎn)單,實(shí)現(xiàn)起來(lái)也非常簡(jiǎn)單。
細(xì)胞神經(jīng)網(wǎng)絡(luò)的使用卷積運(yùn)算在初始層提取特征。最后的圖層是普通的線性圖層。
我們將為包含各種功能函數(shù)的模型定義一個(gè) Base 類。如果我們將來(lái)試圖解決類似的問(wèn)題,這些方法可能會(huì)有所幫助。
def accuracy(outputs, labels):_, preds = torch.max(outputs, dim=1)return torch.tensor(torch.sum(preds == labels).item() / len(preds))class ImageClassificationBase(nn.Module):def training_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossreturn lossdef validation_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossacc = accuracy(out, labels) # Calculate accuracyreturn {'val_loss': loss.detach(), 'val_acc': acc}def validation_epoch_end(self, outputs):batch_losses = [x['val_loss'] for x in outputs]epoch_loss = torch.stack(batch_losses).mean() # Combine lossesbatch_accs = [x['val_acc'] for x in outputs]epoch_acc = torch.stack(batch_accs).mean() # Combine accuraciesreturn {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}def epoch_end(self, epoch, result):print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['train_loss'], result['val_loss'], result['val_acc']))
現(xiàn)在讓我們定義一個(gè)繼承 ImageClassificationBase 類的 Malaria2CnnModel 類:
class Malaria2CnnModel(ImageClassificationBase):def __init__(self):super().__init__()self.network = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 64 x 64 x 64nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 128 x 32 x 32nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 256 x 16 x 16nn.Flatten(),nn.Linear(256*16*16, 1024),nn.ReLU(),nn.Linear(1024, 512),nn.ReLU(),nn.Linear(512, 2))def forward(self, xb):return self.network(xb)
model = Malaria2CnnModel()model
Malaria2CnnModel(
(network): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU()
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU()
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU()
(14): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(15): Flatten()
(16): Linear(in_features=65536, out_features=1024, bias=True)
(17): ReLU()
(18): Linear(in_features=1024, out_features=512, bias=True)
(19): ReLU()
(20): Linear(in_features=512, out_features=2, bias=True)
)
)如果我們使用 CPU,訓(xùn)練一個(gè)深度學(xué)習(xí)模型是非常耗時(shí)耗力的。有很多像 Kaggle 和 google 的 Colab 這樣的平臺(tái)提供免費(fèi)的 GPU 計(jì)算來(lái)訓(xùn)練模型。下面的幫助函數(shù)可以幫助我們找到是否有任何 GPU 可用于我們的系統(tǒng)。如果是的話,我們可以把我們的數(shù)據(jù)和模型轉(zhuǎn)移到 GPU 中,以便更快的計(jì)算。
def get_default_device():"""Pick GPU if available, else CPU"""if torch.cuda.is_available():return torch.device('cuda')else:return torch.device('cpu')def to_device(data, device):"""Move tensor(s) to chosen device"""if isinstance(data, (list,tuple)):return [to_device(x, device) for x in data]return data.to(device, non_blocking=True)class DeviceDataLoader():"""Wrap a dataloader to move data to a device"""def __init__(self, dl, device):self.dl = dlself.device = devicedef __iter__(self):"""Yield a batch of data after moving it to device"""for b in self.dl:yield to_device(b, self.device)def __len__(self):"""Number of batches"""return len(self.dl)
device = get_default_device()device
device(type='cuda')我們已經(jīng)定義了一個(gè) DeviceDataLoader 類來(lái)傳輸我們的模型、訓(xùn)練和驗(yàn)證數(shù)據(jù)。
train_dl = DeviceDataLoader(train_dl, device)val_dl = DeviceDataLoader(val_dl, device)to_device(model, device);
現(xiàn)在,我們將定義我們的fit()函數(shù)和evaluate()函數(shù)。fit()用于訓(xùn)練模型,evaluate()用于查看每個(gè)epoch結(jié)束時(shí)的模型性能。一個(gè)epoch可以理解為整個(gè)訓(xùn)練過(guò)程中的一個(gè)步驟。
def evaluate(model, val_loader):model.eval()outputs = [model.validation_step(batch) for batch in val_loader]return model.validation_epoch_end(outputs)def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):history = []optimizer = opt_func(model.parameters(), lr)for epoch in range(epochs):# Training Phasemodel.train()train_losses = []for batch in train_loader:loss = model.training_step(batch)train_losses.append(loss)loss.backward()optimizer.step()optimizer.zero_grad()# Validation phaseresult = evaluate(model, val_loader)result['train_loss'] = torch.stack(train_losses).mean().item()model.epoch_end(epoch, result)history.append(result)return history
讓我們把我們的模型轉(zhuǎn)移到一個(gè) GPU 設(shè)備上。
model = to_device(Malaria2CnnModel(), device)我們將對(duì)模型進(jìn)行評(píng)估,以便在訓(xùn)練之前了解它在驗(yàn)證集上的執(zhí)行情況。
evaluate(model, val_dl){'val_loss': 0.6931465864181519, 'val_acc': 0.5000697374343872}在訓(xùn)練之前,我們可以達(dá)到50% 的準(zhǔn)確率。對(duì)于醫(yī)療保健領(lǐng)域的關(guān)鍵應(yīng)用來(lái)說(shuō),這個(gè)數(shù)字非常低。我們將設(shè)置 epochs 的數(shù)目為10,設(shè)置優(yōu)化器為torch.optim.Adam,以及學(xué)習(xí)率設(shè)定為0.001。
num_epochs = 10opt_func = torch.optim.Adamlr = 0.001
我們將要定義一些功能,在每個(gè)epoch結(jié)束時(shí)計(jì)算損失和準(zhǔn)確度。
def plot_accuracies(history):accuracies = [x['val_acc'] for x in history]plt.plot(accuracies, '-x')plt.xlabel('epoch')plt.ylabel('accuracy')plt.title('Accuracy vs. No. of epochs');
def plot_losses(history):train_losses = [x.get('train_loss') for x in history]val_losses = [x['val_loss'] for x in history]plt.plot(train_losses, '-bx')plt.plot(val_losses, '-rx')plt.xlabel('epoch')plt.ylabel('loss')plt.legend(['Training', 'Validation'])plt.title('Loss vs. No. of epochs');
現(xiàn)在,讓我們使用fit()函數(shù)來(lái)訓(xùn)練我們的模型。
history = fit(num_epochs, lr, model, train_dl, val_dl, opt_func)Epoch [0], train_loss: 0.6955, val_loss: 0.6876, val_acc: 0.5228 Epoch [1], train_loss: 0.5154, val_loss: 0.2328, val_acc: 0.9327 Epoch [2], train_loss: 0.1829, val_loss: 0.1574, val_acc: 0.9540 Epoch [3], train_loss: 0.1488, val_loss: 0.1530, val_acc: 0.9552 Epoch [4], train_loss: 0.1330, val_loss: 0.1388, val_acc: 0.9562 Epoch [5], train_loss: 0.1227, val_loss: 0.1372, val_acc: 0.9576 Epoch [6], train_loss: 0.1151, val_loss: 0.1425, val_acc: 0.9591 Epoch [7], train_loss: 0.1043, val_loss: 0.1355, val_acc: 0.9586 Epoch [8], train_loss: 0.0968, val_loss: 0.1488, val_acc: 0.9579 Epoch [9], train_loss: 0.0949, val_loss: 0.1570, val_acc: 0.9554
訓(xùn)練結(jié)束后,我們的模型從之前的50% 的準(zhǔn)確率提高到了95.54%。
讓我們繪制每個(gè)epoch后的精確度和損失圖表以幫助我們理解我們的模型。
plot_accuracies(history)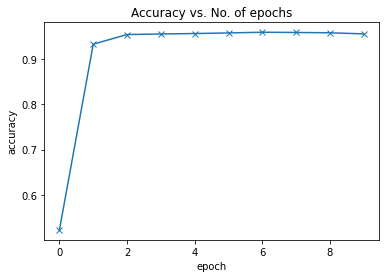
plot_losses(history)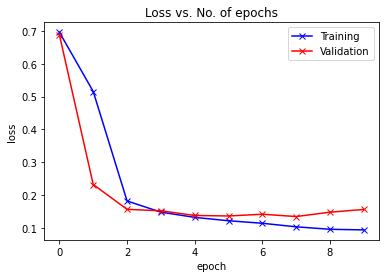
現(xiàn)在我們將編寫(xiě)一個(gè)函數(shù)來(lái)預(yù)測(cè)單個(gè)圖像的類別。然后我們將對(duì)整個(gè)測(cè)試集進(jìn)行預(yù)測(cè),并檢查整個(gè)測(cè)試集的準(zhǔn)確性。
def predict_image(img, model):# Convert to a batch of 1xb = to_device(img.unsqueeze(0), device)# Get predictions from modelyb = model(xb)# Pick index with highest probabilitypreds = torch.max(yb, dim=1)# Retrieve the class labelreturn dataset.classes[preds[0].item()]
對(duì)一張圖片進(jìn)行預(yù)測(cè):
img, label = test_ds[0]plt.imshow(img.permute(1, 2, 0))print('Label:', dataset.classes[label], ', Predicted:', predict_image(img, model))
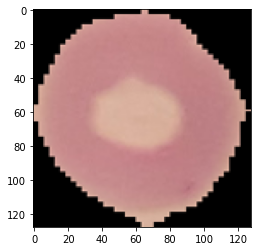
現(xiàn)在讓我們來(lái)預(yù)測(cè)一下整個(gè)測(cè)試集:
test_loader = DeviceDataLoader(DataLoader(test_ds, batch_size*2), device)result = evaluate(model, test_loader)result
{'val_loss': 0.14322155714035034, 'val_acc': 0.9600048065185547}我們?cè)谶@里得到了一些相當(dāng)不錯(cuò)的結(jié)果。96% 是一個(gè)非常好的結(jié)果,但是我認(rèn)為這仍然可以通過(guò)改變超參數(shù)來(lái)改進(jìn)。我們也可以設(shè)置更多的epoch。
擴(kuò)展想法:
我們將嘗試應(yīng)用遷移學(xué)習(xí)技巧,看看它是否能進(jìn)一步提高準(zhǔn)確性;
我們將嘗試使用圖像分割分析技術(shù)和圖像定位技術(shù)將這些紅色球狀結(jié)構(gòu)聚集在一起,并對(duì)其進(jìn)行分析以尋找證據(jù);
我們將嘗試使用數(shù)據(jù)增強(qiáng)技術(shù)來(lái)限制我們的模型過(guò)擬合;
我們將學(xué)習(xí)如何在生產(chǎn)環(huán)境中部署模型,以便向不理解代碼的人展示我們的工作。
·? END? ·