
【深度學習】實戰(zhàn)深度學習檢測瘧疾
編譯 | VK
來源 | Towards Data Science
在這個項目中,我們將通過美國國立衛(wèi)生研究院提供的一個數(shù)據(jù)集,從150名感染了惡性瘧原蟲寄生蟲的患者身上獲取27558張不同的細胞圖像,并與50名健康患者的細胞圖像混合,這些圖像可以通過這里的鏈接下載:
https://www.kaggle.com/iarunava/cell-images-for-detecting-malaria
我們的任務是建立一個機器學習/深度學習算法,能夠?qū)z測到的細胞是否被寄生蟲感染進行分類。
在這個項目中,我們將使用一種深度學習算法,即卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network, CNN)算法,它通過訓練來分類某個細胞的圖像是否被感染。由于這是一個超過330mb數(shù)據(jù)的大項目,我建議將其應用到jupiter Notebook中。
首先,我們需要導入必要的起始庫:
import pandas as pd
import numpy as np
import os
import cv2
import random
你之前可能使用panda.read_csv()導入csv格式的數(shù)據(jù)集,但是,由于所有數(shù)據(jù)都是png格式的,因此可能需要使用os和cv2庫以不同的方式導入它們。
OS是一個強大的Python庫,允許你與操作系統(tǒng)進行交互,無論操作系統(tǒng)是Windows、Mac OS還是Linux。
另一方面,cv2是一個專門設計用于解決各種計算機視覺問題,如讀取和加載圖像。
首先,我們需要設置一個變量來設置我們的路徑,因為我們以后會繼續(xù)使用它:
root = '../Malaria/cell_images/'
in = '/Parasitized/'
un = '/Uninfected/'
因此,從上面的路徑是名為“瘧疾(Malaria)”的文件夾是我的細胞圖像文件夾文件存儲的地方,這也是寄生和未感染細胞的圖像存儲的地方。這樣,我們就能更容易地操縱這些路徑。
現(xiàn)在讓我們操作系統(tǒng)列表目錄(“path”)函數(shù)列出被寄生和未受感染文件夾中的所有圖像,如下所示:
Parasitized = os.listdir(root+in)
Uninfected = os.listdir(root+un)
使用OpenCV和Matplotlib顯示圖像
例如,與csv文件不同,我們只能使用pandas的函數(shù)head列出多個數(shù)據(jù),df.head(10) 顯示10行數(shù)據(jù),對于圖像,我們需要使用for循環(huán)和matplotlib庫來顯示數(shù)據(jù)。
因此,首先讓我們導入matplotlib并為每個寄生和未感染的細胞圖像繪制圖像,如下所示:
import matplotlib.pyplot as plt
然后繪制圖像:
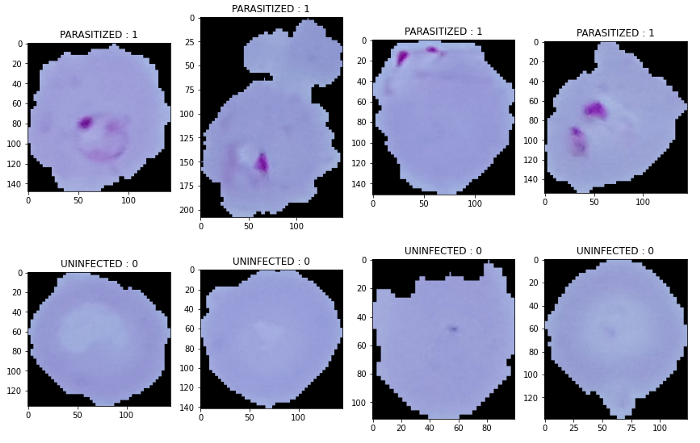
plt.figure(figsize = (12,24))
for i in range(4):
plt.subplot(1, 4, i+1)
img = cv2.imread(root+in+ Parasitized[i])
plt.imshow(img)
plt.title('PARASITIZED : 1')
plt.tight_layout()
plt.show()
plt.figure(figsize = (12,24))
for i in range(4):
plt.subplot(2, 4, i+1)
img = cv2.imread(root+un+ Uninfected[i+1])
plt.imshow(img)
plt.title('UNINFECTED : 0')
plt.tight_layout()
plt.show()
因此,為了繪制圖像,我們需要matplotlib中的figure函數(shù),然后我們需要根據(jù)figsize函數(shù)確定每個圖形的大小。
如上所示,其中第一個數(shù)字是寬度,第二個數(shù)字是高度。然后在for循環(huán)中,我們將使用i作為變量來迭代range()中指示的次數(shù)。
在本例中,我們將只顯示4個圖像。隨后,我們將使用library中的subplot函數(shù)來指示某個迭代的行數(shù)、列數(shù)和繪圖數(shù),我們使用i+1來實現(xiàn)。
由于我們已經(jīng)創(chuàng)建了子圖,但是子圖仍然是空的,因此,我們需要使用OpenCV庫,通過使用cv2.imread()函數(shù)導入圖像,并包括其中的路徑和變量i,這樣它將繼續(xù)循環(huán)到下一張圖片,直到提供的最大范圍為止。
最后,我們將cv2庫導入的圖像用plt.imshow()函數(shù)繪出,我們將獲得以下輸出:
將圖像和標簽分配到變量中
接下來,我們要將所有圖像(無論是寄生細胞圖像還是未感染細胞圖像)及其標簽插入到一個變量中,其中1表示寄生細胞,0表示未感染細胞。因此,首先,我們需要為圖像和標簽創(chuàng)建一個空變量。但在此之前,我們需要使用Keras的img_to_array()函數(shù)。
from tensorflow.keras.preprocessing.image import img_to_array
假設存儲圖像的變量稱為data,存儲標簽的變量稱為labels,那么我們可以執(zhí)行以下代碼:
data = []
labels = []
for img in Parasitized:
try:
img_read = plt.imread(root+in+ img)
img_resize = cv2.resize(img_read, (100, 100))
img_array = img_to_array(img_resize)
data.append(img_array)
labels.append(1)
except:
None
for img in Uninfected:
try:
img_read = plt.imread(root+un+ img)
img_resize = cv2.resize(img_read, (100, 100))
img_array = img_to_array(img_resize)
data.append(img_array)
labels.append(0)
except:
None
在為空數(shù)組賦值變量數(shù)據(jù)和標簽之后,我們需要使用for循環(huán)插入每一張圖像。
這里有一些不同之處,for循環(huán)中還包含了try和except。try用于在for循環(huán)中正常運行代碼,另一方面,except用于代碼遇到錯誤或崩潰時,以便代碼可以繼續(xù)循環(huán)。
與上面的圖像顯示代碼類似,我們可以使用plt.imread(“path”)函數(shù),但這一次,我們不需要顯示任何子圖。
你可能想知道我們?yōu)槭裁从胮lt.imread()而不是cv2.imread()。它們的功能是一樣的,事實上,還有很多其他的圖像讀取庫,例如,Pillow庫的image.open()或Scikit-Image庫的io.imread()。
然而,OpenCV以BGR或藍、綠、紅的順序讀取圖像,這就是為什么上面顯示的圖像是藍色的,盡管實際的圖片是粉色的。因此,我們需要使用以下代碼將其轉換回RGB順序:
cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
另一方面,Matplotlib、Scikit Image和Pillow Image reading函數(shù)會自動按RGB順序讀取圖像,因此,對于我們的單元格圖像實際顏色,我們不需要再進行轉換:
plt.imshow(data[0])
plt.show()

之后,我們可以通過使用OpenCV的cv2.resize()函數(shù)來調(diào)整圖像的大小,以將加載的圖像設置為一個特定的高度和寬度,如上面所示的100 width和100 height。
接下來,因為我們的圖像是抽象格式的,我們以后將無法對其進行訓練、測試或?qū)⑵洳迦胱兞恐校虼耍覀冃枰褂胟eras的img_to_array()函數(shù)將其轉換為數(shù)組格式。這樣,我們就可以使用.append()函數(shù)將每個圖像插入變量的方括號中,該函數(shù)用于在不改變原始狀態(tài)的情況下將對象插入數(shù)組的最后一個列表。
所以在我們的循環(huán)中,我們不斷地在每個循環(huán)中添加一個新的圖像。
預處理數(shù)據(jù)
不像機器學習項目,我們可以立即分割我們的數(shù)據(jù),在深入學習,特別是神經(jīng)網(wǎng)絡,以減少方差,并減少過擬合。在Python中,有許多方法可以隨機化數(shù)據(jù),比如使用Sklearn,如下所示:
from sklearn.utils import shuffle
或使用如下所示的隨機方法:
from random import shuffle
但在這個項目中,我們將使用Numpy的隨機函數(shù)。因此,我們需要將數(shù)組轉換成Numpy的數(shù)組函數(shù),然后對圖像數(shù)據(jù)進行隨機化,如下所示:
image_data = np.array(data)
labels = np.array(labels)
idx = np.arange(image_data.shape[0])
np.random.shuffle(idx)
image_data = image_data[idx]
labels = labels[idx]
首先,我們將數(shù)據(jù)和標簽變量轉換為Numpy格式。然后,我們可以使用np.arange()然后使用np.random.shuffle()功能。最后,我們將被隨機數(shù)據(jù)重新分配到它們的原始變量中,以確保被隨機的數(shù)據(jù)被保存。
用于訓練、測試和驗證的拆分數(shù)據(jù)
在數(shù)據(jù)被隨機之后,我們應該通過導入必要的庫將它們拆分為訓練、測試和驗證標簽和數(shù)據(jù),如下所示:
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
然后我們設置一個函數(shù),將數(shù)據(jù)轉換為32位數(shù)據(jù)以保存:
def prep_dataset(X,y):
X_prep = X.astype('float32')/255
y_prep = to_categorical(np.array(y))
return (X_prep, y_prep)
然后通過使用Sklearn庫,我們可以將數(shù)據(jù)分為訓練、測試和驗證:
X_tr, X_ts, Y_tr, Y_ts = train_test_split(image_data,labels, test_size=0.15, shuffle=True,stratify=labels,random_state=42)
X_ts, X_val, Y_ts, Y_val = train_test_split(X_ts,Y_ts, test_size=0.5, stratify=Y_ts,random_state=42)
X_tr, Y_tr = prep_dataset(X_tr,Y_tr)
X_val, Y_val = prep_dataset(X_val,Y_val)
X_ts, _ = prep_dataset(X_ts,Y_ts)
由于存在驗證數(shù)據(jù),因此需要執(zhí)行兩次拆分。在spliting函數(shù)中,我們需要在前兩個參數(shù)中分配數(shù)據(jù)和標簽,然后告訴它們被劃分成的百分比,隨機狀態(tài)是為了確保它們產(chǎn)生的數(shù)據(jù)總是以一致的順序排列。
卷積神經(jīng)網(wǎng)絡模型的建立
在建立CNN模型之前,讓我們從理論上對它有一點更深入的了解。CNN主要應用于圖像分類,自1998年發(fā)明以來,由于其高性能和高精度,一直受到人們的歡迎。那么它是如何工作的呢?
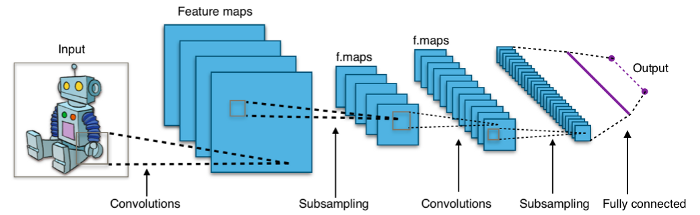
正如我們從上面的插圖中看到的,CNN對圖像進行分類,取圖像的一部分,并將其通過幾層卷積處理來分類圖像。從這幾個層中,可以將它們分為三種類型的層,分別是卷積層、池化層和全連接層。
卷積層
第一層,卷積層是CNN最重要的方面之一,它的名字來源于此。其目的是利用核函數(shù)從輸入圖像中提取特征。該核將使用點積連續(xù)掃描輸入圖像,創(chuàng)建一個新的分析層,稱為特征圖/激活圖。其機理如下:
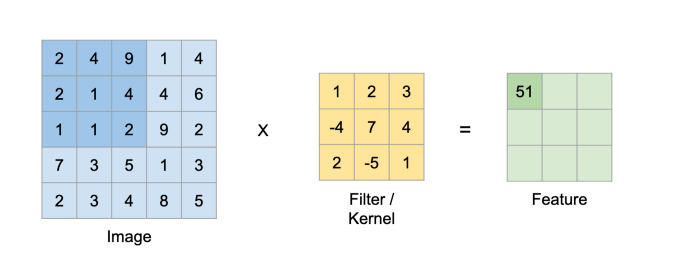
2*1 + 4*2 + 9*3 + 2*(-4) + 1*7 + 4*4 + 1*2 + 1*(-5) + 2*1 = 51
然后繼續(xù),直到所有特征圖的單元格都被填滿。
池化層
在我們創(chuàng)建了特征圖之后,我們將應用一個池化層來減小其大小以減少過擬合。此步驟中有幾個操作,但是,最流行的技術是最大池,其中特征圖的掃描區(qū)域?qū)H取最高值,如下圖所示:
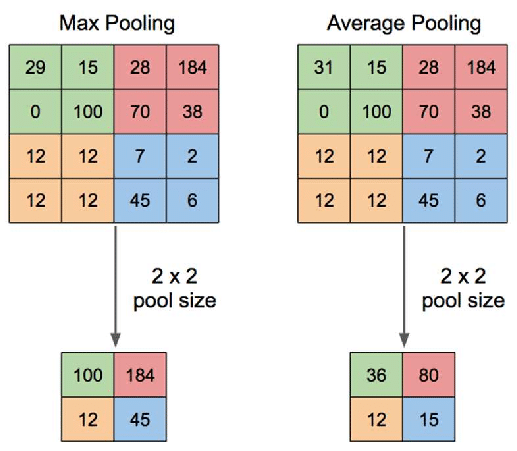
卷積和池的步驟可以重復,直到理想的大小是最后敲定,然后我們可以繼續(xù)分類部分,它被稱為全連接層。
全連通層
在這一階段,變換后的特征圖將被展平為一個列向量,該列向量將在每個迭代過程中經(jīng)過前饋神經(jīng)網(wǎng)絡和反向傳播過程,持續(xù)數(shù)個階段。最后,CNN模型將區(qū)分主要特征和非主要特征,利用Softmax分類對圖像進行分類。
在Python中,我們需要從Keras庫導入CNN函數(shù):
from tensorflow.keras import models, layers
from tensorflow.keras.callbacks import EarlyStopping
然后,我們將構建我們自己的CNN模型,包括4個卷積層和池化層:
model = models.Sequential()
#Input + Conv 1 + ReLU + Max Pooling
model.add(layers.Conv2D(32,(5,5),activation='relu',padding='same',input_shape=X_tr.shape[1:]))
model.add(layers.MaxPool2D(strides=4))
model.add(layers.BatchNormalization())
# Conv 2 + ReLU + Max Pooling
model.add(layers.Conv2D(64,(5,5),padding='same',activation='relu'))
model.add(layers.MaxPool2D(strides=2))
model.add(layers.BatchNormalization())
# Conv 3 + ReLU + Max Pooling
model.add(layers.Conv2D(128,(3,3),padding='same',activation='relu'))
model.add(layers.MaxPool2D(strides=2))
model.add(layers.BatchNormalization())
# Conv 4 + ReLU + Max Pooling
model.add(layers.Conv2D(256,(3,3),dilation_rate=(2,2),padding='same',activation='relu'))
model.add(layers.Conv2D(256,(3,3),activation='relu'))
model.add(layers.MaxPool2D(strides=2))
model.add(layers.BatchNormalization())
# Fully Connected + ReLU
model.add(layers.Flatten())
model.add(layers.Dense(300, activation='relu'))
model.add(layers.Dense(100, activation='relu'))
#Output
model.add(layers.Dense(2, activation='softmax'))
model.summary()
Keras中的卷積層
好的,在這段代碼中,你可能會感到困惑的第一件事是model .sequential()。
利用Keras構建深度學習模型有兩種選擇,一種是序列模型,另一種是函數(shù)模型。他們兩人之間的差異是序列模型只允許一層一層地建立一個模型,另一方面,函數(shù)模型允許層連接到前一層,多層,甚至任何層,你想建立一個更復雜的模型。由于我們正在構建一個簡單的CNN模型,所以我們將使用序列模型。
我們之前了解到,CNN由卷積層組成,卷積層后來使用池化層進行簡化,因此,我們需要使用Keras函數(shù)model.add()添加層,然后添加我們喜歡的層。
由于我們的圖像是2D形式,我們只需要2D卷積層,同樣使用卷積層的Keras函數(shù):layers.Conv2D(). 正如你在每一層所看到的,第一層有一個數(shù)字32,第二層有一個數(shù)字64,乘以2并以此類推。這叫做濾波器。它所做的是試圖捕捉圖像的模式。
因此,隨著濾波器尺寸的增大,我們可以在較小的圖像上捕獲更多的模式,盡管沒有太多理論的證明,然而,這被認為是最優(yōu)方法。
接下來,(5,5)和(3,3)矩陣是我們上面討論的用于創(chuàng)建特征圖的核。然后這里有兩個有趣的部分:ReLu的激活和填充。那些是什么?我們先來討論ReLu。它是由Rectified Linear Unit縮短而來的,其想法是采用更簡單的模型,提高訓練過程的效率。
下一個問題是填充。如我們所知,卷積層不斷減小圖像的大小,因此,如果我們在新的特征圖的所有四個邊上添加填充,我們將保持相同的大小。所以我們在處理后的圖像周圍添加新的單元格,值為0,以保持圖像的大小。填充有兩個選項:相同或零。接下來就是input_shape,它只是我們的輸入圖像,只在第一層中用于輸入我們的訓練數(shù)據(jù)。
Keras中的池化層
讓我們轉到池化層,我們可以使用Keras的layers.MaxPool2D()。這里有一種東西叫做跨步(stride)。它是核將在輸入上每次移動的步數(shù)。因此,如果我們用5x5的核,并且跨步為4,核將計算圖像最左邊的部分,然后跳過右邊的4個單元格來執(zhí)行下一次計算。
你可能會注意到,每個卷積層和池化層都以批標準化結束。為什么?因為在每一層中,都有不同的分布,訓練過程會變慢,因為它需要適應每一層。但是,如果強制所有層具有相似的分布,則可以跳過此步驟并提高訓練速度。這就是為什么我們在每一層中應用批標準化,通過如下所示的4個步驟對每一層中的輸入進行標準化:

Keras全連接層
現(xiàn)在我們已經(jīng)到了CNN的最后階段,也就是全連接的階段。但在進入這個階段之前,由于我們將在全連接階段使用“Dense”層,所以我們需要使用Keras層將處理過的數(shù)據(jù)平鋪成一維。Flatten()函數(shù)用于將垂直和水平的數(shù)據(jù)合并到單個列中。

我們將數(shù)據(jù)展平后,現(xiàn)在需要使用layers.Dense()函數(shù)將它們?nèi)B接起來,然后指定要用作輸出的神經(jīng)元數(shù)量,考慮到當前的神經(jīng)元是1024個。所以我們先使用300個神經(jīng)元,然后是100個神經(jīng)元,并使用ReLu對其進行優(yōu)化。
最后,我們到達輸出階段,這也是通過使用Dense函數(shù)來完成的,然而,由于我們的分類只有2個概率,即感染瘧疾或未感染瘧疾,因此,我們將輸出單位設置為2。此外,在分類任務中,我們在輸出層使用Softmax激活而不是ReLu,因為ReLu將所有負類設置為零。
綜上所述,我們構建的模型如下:
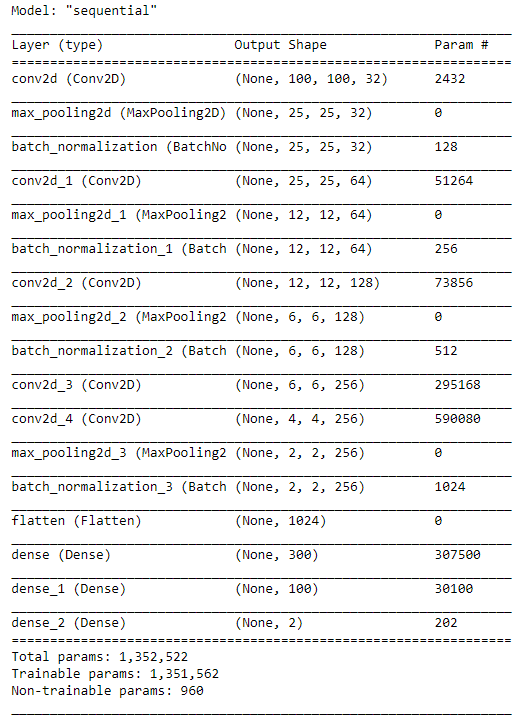
然后,我們將把我們的訓練和驗證數(shù)據(jù)整合到模型中:
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
es = EarlyStopping(monitor='val_accuracy',mode='max',patience=3,verbose=1)
history= model.fit(X_tr,Y_tr,
epochs=20,
batch_size=50,
validation_data=(X_val,Y_val),
callbacks=[es])
由于數(shù)據(jù)量很大,這個過程需要一些時間。如下圖所示,每個epoch平均運行9分鐘。

評估
我們可以通過繪制評估圖來評估模型性能,但在此之前,我們需要導入seaborn庫:
import seaborn as sns
然后將準確度和損失繪制如下:
fig, ax=plt.subplots(2,1,figsize=(12,10))
fig.suptitle('Train evaluation')
sns.lineplot(ax= ax[0],x=np.arange(0,len(history.history['accuracy'])),y=history.history['accuracy'])
sns.lineplot(ax= ax[0],x=np.arange(0,len(history.history['accuracy'])),y=history.history['val_accuracy'])
ax[0].legend(['Train','Validation'])
ax[0].set_title('Accuracy')
sns.lineplot(ax= ax[1],x=np.arange(0,len(history.history['loss'])),y=history.history['loss'])
sns.lineplot(ax= ax[1],x=np.arange(0,len(history.history['loss'])),y=history.history['val_loss'])
ax[1].legend(['Train','Validation'])
ax[1].set_title('Loss')
plt.show()
這將給我們一個輸出:
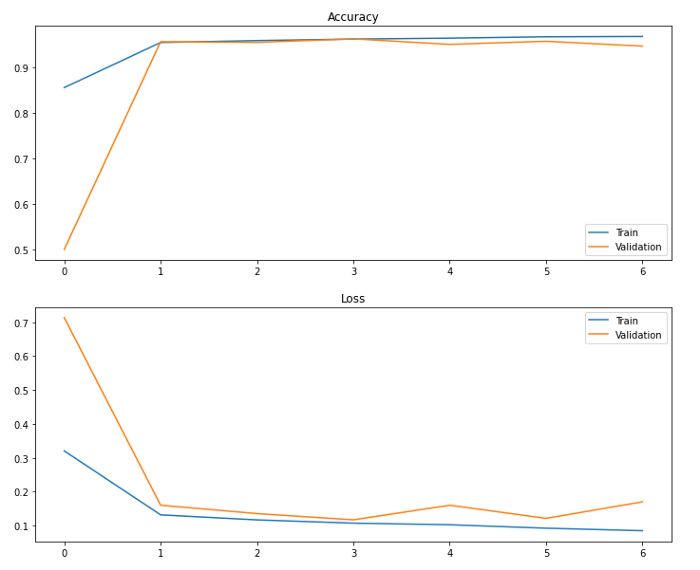
它的平均性能似乎超過90%,這是非常好的,正如CNN模型所預期的。不過,為了讓我們更具體地了解數(shù)據(jù)性能,讓我們使用Sklearn構建一個混淆矩陣,并預測輸出:
from sklearn.metrics import confusion_matrix, accuracy_score
Y_pred = model.predict(X_ts)
Y_pred = np.argmax(Y_pred, axis=1)
conf_mat = confusion_matrix(Y_ts,Y_pred)
sns.set_style(style='white')
plt.figure(figsize=(12,8))
heatmap = sns.heatmap(conf_mat,vmin=np.min(conf_mat.all()), vmax=np.max(conf_mat), annot=True,fmt='d', annot_kws={"fontsize":20},cmap='Spectral')
heatmap.set_title('Confusion Matrix Heatmap\n?Is the cell infected?', fontdict={'fontsize':15}, pad=12)
heatmap.set_xlabel('Predicted',fontdict={'fontsize':14})
heatmap.set_ylabel('Actual',fontdict={'fontsize':14})
heatmap.set_xticklabels(['NO','YES'], fontdict={'fontsize':12})
heatmap.set_yticklabels(['NO','YES'], fontdict={'fontsize':12})
plt.show()
print('-Acuracy achieved: {:.2f}%\n-Accuracy by model was: {:.2f}%\n-Accuracy by validation was: {:.2f}%'.
format(accuracy_score(Y_ts,Y_pred)*100,(history.history['accuracy'][-1])*100,(history.history['val_accuracy'][-1])*100))
這將為我們提供以下準確度:
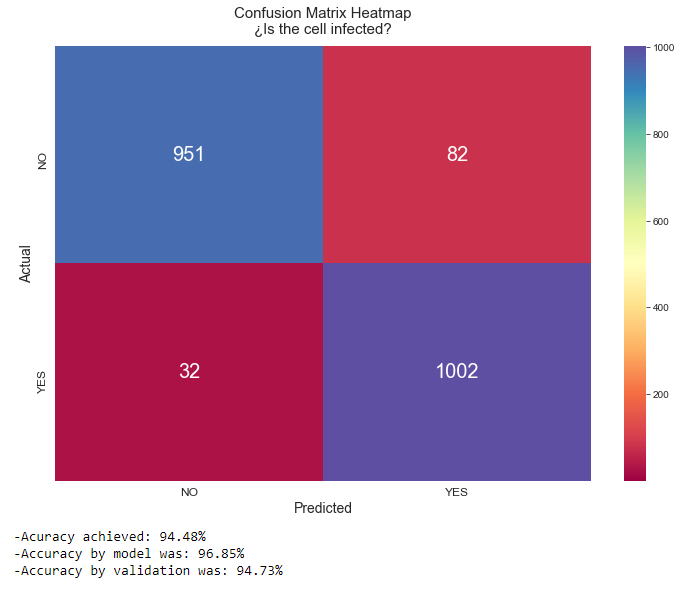
錯誤樣本
讓我們看看錯誤示例的樣子:
index=0
index_errors= []
for label, predict in zip(Y_ts,Y_pred):
if label != predict:
index_errors.append(index)
index +=1
plt.figure(figsize=(20,8))
for i,img_index in zip(range(1,17),random.sample(index_errors,k=16)):
plt.subplot(2,8,i)
plt.imshow(np.reshape(255*X_ts[img_index], (100,100,3)))
plt.title('Actual: '+str(Y_ts[img_index])+' Predict: '+str(Y_pred[img_index]))
plt.show()
輸出:
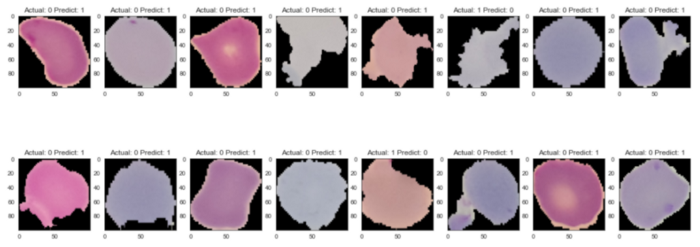
盡管未感染,但錯誤的預測圖像似乎包含了細胞上的幾個紫色斑塊,因此,模型實際預測它們?yōu)楦腥炯毎强梢岳斫獾摹?/span>
我想說CNN是一個非常強大的圖像分類模型,不需要做很多預處理任務,因為處理包含在卷積層和池化層中。
希望通過本文的學習,讓你能夠利用卷積神經(jīng)網(wǎng)絡進行圖像分類。
感謝你的閱讀。
看到這里,說明你喜歡這篇文章,請點擊「在看」或順手「轉發(fā)」「點贊」。
往期精彩回顧
本站qq群851320808,加入微信群請掃碼: