
NVLink到底Link了啥?


? ? ? ? 幾個(gè)月前,NVIDIA創(chuàng)始人兼首席執(zhí)行官黃仁勛從廚房烤箱端出了世上首款基于NVIDIA? Ampere架構(gòu)的GPU ——?NVIDIA A100,頓時(shí)吸引了一眾網(wǎng)友的前排關(guān)注,小伙伴們紛紛表示被(喪)震(心)驚(病)了(狂)!
?最新A100 GPU有五大技術(shù)性突破設(shè)計(jì):
NVIDIA Ampere架構(gòu)
具有TF32的第三代Tensor Core核心
多實(shí)例GPU?(MIG)
第三代NVIDIA NVLink
結(jié)構(gòu)化稀疏
其中一個(gè)關(guān)鍵性創(chuàng)新就是采用了第三代NVIDIA NVLink,不知不覺(jué)就已經(jīng)第三代了,今天,我們就主要來(lái)說(shuō)道說(shuō)道這個(gè)NVLink!
簡(jiǎn)單來(lái)說(shuō),NVIDIA? NVLink?是一個(gè)能夠在GPU-GPU以及GPU-CPU之間實(shí)現(xiàn)高速大帶寬直連通訊的快速互聯(lián)機(jī)制。

隨著開(kāi)發(fā)人員在人工智能 (AI) 計(jì)算等應(yīng)用領(lǐng)域中越來(lái)越依賴并行結(jié)構(gòu),各行各業(yè)中的多GPU和多CPU系統(tǒng)愈發(fā)普及。其中包括采用PCIe系統(tǒng)互聯(lián)技術(shù)的4 GPU和 8 GPU系統(tǒng)配置來(lái)解決非常復(fù)雜的重大難題。然而,在多GPU系統(tǒng)層面,PCIe帶寬逐漸成為瓶頸,為了解決這一問(wèn)題,NVIDIA提出了NVLink技術(shù)。
NVIDIA最早在2014年GTC大會(huì)上首次提出NVLink技術(shù),直到2016年,發(fā)布了P100,這是搭載NVLink的第一款產(chǎn)品,單個(gè)GPU具有160GB/s的帶寬,相當(dāng)于PCIe Gen3 * 16帶寬的5倍。在GTC 2017上發(fā)布的V100搭載的NVLink 2.0更是將GPU帶寬提升到了300G/s,差不多是PCIe的10倍了。再到今年的線上GTC大會(huì),A100集成了最新的第三代NVLink,單個(gè)NVIDIA A100 Tensor核心GPU支持多達(dá)12個(gè)第三代NVLink連接,總帶寬為每秒600G/s,幾乎是PCIe Gen 4帶寬的10倍。
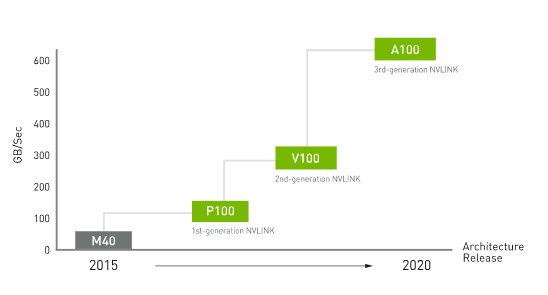
NVLink的受眾相當(dāng)廣泛,不僅可以依據(jù)不同需求完成GPU-GPU節(jié)點(diǎn)內(nèi)部的高速互聯(lián),同時(shí)還能在GPU-CPU甚至CPU-CPU之間形成高速互聯(lián)。它既可以像PCIe,也可以像QPI。所有多GPU并行工作的場(chǎng)合,無(wú)論是價(jià)值數(shù)億美元的超級(jí)計(jì)算機(jī)集群還是桌面的SLI都將會(huì)從中獲得更高的并行通訊帶寬。
可能大家覺(jué)得NVLink比較適用于對(duì)數(shù)據(jù)交換帶寬敏感的HPC應(yīng)用,而往往忽視掉了它在圖形應(yīng)用場(chǎng)景領(lǐng)域的價(jià)值,其所帶來(lái)的更大的GPU之間與GPU的互聯(lián)帶寬可以讓SLI場(chǎng)合,尤其是多卡SLI以及單卡多芯場(chǎng)合從中獲益。
利用NVLink橋接器,能夠連接兩塊NVIDIA? Quadro?顯卡,從而實(shí)現(xiàn)顯存和性能擴(kuò)展,滿足最大視覺(jué)計(jì)算工作負(fù)載的需求。

提到NVLink不得不提到NVSwitch, NVIDIA NVSwitch?是將多個(gè)NVLink加以整合,在單個(gè)節(jié)點(diǎn)內(nèi)以NVLink的較高速度實(shí)現(xiàn)多對(duì)多的GPU通信,從而進(jìn)一步提高互聯(lián)性能。NVLink和NVSwitch的結(jié)合使NVIDIA得以高效地將AI性能擴(kuò)展到多個(gè)GPU。
?

上圖NVSwitch拓?fù)鋱D顯示的是兩個(gè)GPU的連接。8個(gè)或16個(gè)GPU以相同方式通過(guò) NVSwitch進(jìn)行多對(duì)多連接。
由于PCIe帶寬經(jīng)常會(huì)在多GPU系統(tǒng)級(jí)別造成瓶頸,因此深度學(xué)習(xí)技術(shù)的快速應(yīng)用使得對(duì)速度更快、可擴(kuò)展性更強(qiáng)的互連的需求日益迫切。要擴(kuò)展深度學(xué)習(xí)工作負(fù)載,需要顯著提高帶寬并降低延遲。
NVIDIA NVSwitch以NVLink的先進(jìn)通信能力為基礎(chǔ),能夠解決該問(wèn)題。它采用可在一臺(tái)服務(wù)器中支持更多GPU以及GPU之間的全帶寬連接的GPU架構(gòu),可將深度學(xué)習(xí)性能提升到更高水平。每個(gè)GPU都有12個(gè)連接NVSwitch的NVLink鏈路,可實(shí)現(xiàn)高速的多對(duì)多通信。
轉(zhuǎn)載申明:轉(zhuǎn)載本號(hào)文章請(qǐng)注明作者和來(lái)源,本號(hào)發(fā)布文章若存在版權(quán)等問(wèn)題,請(qǐng)留言聯(lián)系處理,謝謝。
推薦閱讀
更多架構(gòu)相關(guān)技術(shù)知識(shí)總結(jié)請(qǐng)參考“架構(gòu)師技術(shù)全聯(lián)盟書(shū)店”相關(guān)電子書(shū)(35本技術(shù)資料打包匯總詳情可通過(guò)“閱讀原文”獲取)。
內(nèi)容持續(xù)更新,現(xiàn)下單“架構(gòu)師技術(shù)全店打包匯總(全)”,后續(xù)可享全店內(nèi)容更新“免費(fèi)”贈(zèng)閱,格僅收188元(原總價(jià)270元)。
溫馨提示:
掃描二維碼關(guān)注公眾號(hào),點(diǎn)擊閱讀原文鏈接獲取“架構(gòu)師技術(shù)全店資料打包匯總(全)”電子書(shū)資料詳情。
