
自動駕駛視覺感知算法
點擊上方“小白學視覺”,選擇加"星標"或“置頂” 重磅干貨,第一時間送達
自動駕駛視覺感知算法(一)
環(huán)境感知是自動駕駛的第一環(huán),是車輛和環(huán)境交互的紐帶。一個自動駕駛系統(tǒng)整體表現(xiàn)的好壞,很大程度上都取決于感知系統(tǒng)的好壞。目前,環(huán)境感知技術有兩大主流技術路線:
①以視覺為主導的多傳感器融合方案,典型代表是特斯拉;
②以激光雷達為主導,其他傳感器為輔助的技術方案,典型代表如谷歌、百度等。
我們將圍繞著環(huán)境感知中關鍵的視覺感知算法進行介紹,其任務涵蓋范圍及其所屬技術領域如下圖所示。我們分為兩節(jié)分別梳理了2D和3D視覺感知算法的脈絡和方向。
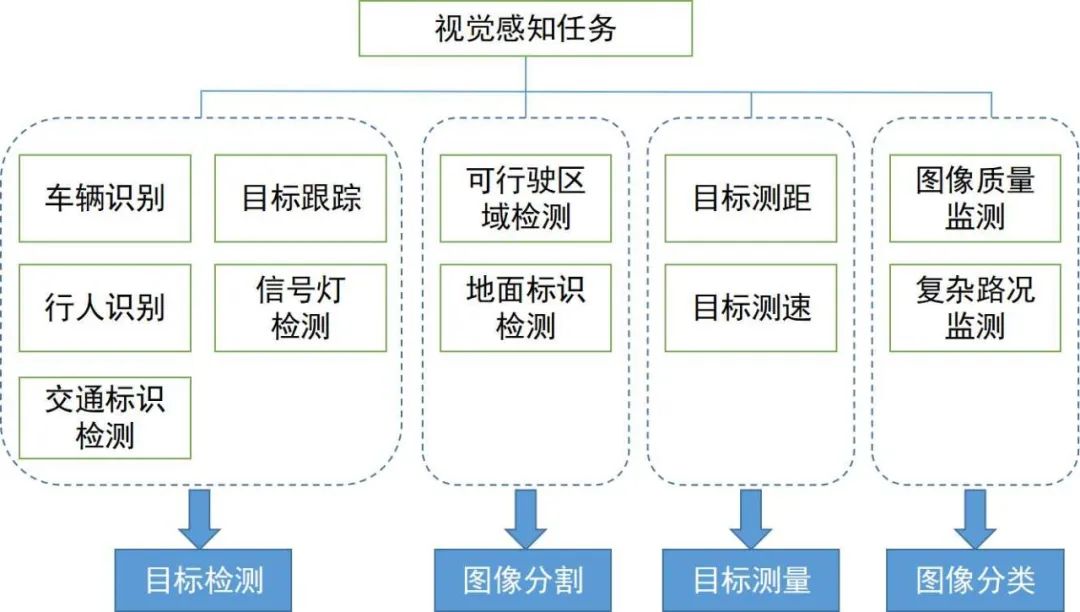
本節(jié)我們先從廣泛應用于自動駕駛的幾個任務出發(fā)介紹2D視覺感知算法,包括基于圖像或視頻的2D目標檢測和跟蹤,以及2D場景的語義分割。近些年,深度學習滲透到視覺感知的各個領域,取得不錯的成績,因此,我們梳理了一些經(jīng)典的深度學習算法。
1.1 兩階段檢測
兩階段指的是實現(xiàn)檢測的方式有先后兩個過程,一是提取物體區(qū)域;二是對區(qū)域進行CNN分類識別;因此,“兩階段”又稱基于候選區(qū)域(Region proposal)的目標檢測。代表性算法有R-CNN系列(R-CNN、Fast R-CNN、Faster R-CNN)等。
Faster R-CNN是第一個端到端的檢測網(wǎng)絡。第一階段利用一個區(qū)域候選網(wǎng)絡(RPN)在特征圖的基礎上生成候選框,使用ROIPooling對齊候選特征的大小;第二階段用全連接層做細化分類和回歸。這里提出了Anchor的思想,減少運算難度,提高速度。特征圖的每個位置會生成不同大小、長寬比的Anchor,用來作為物體框回歸的參考。Anchor的引入使得回歸任務只用處理相對較小的變化,因此網(wǎng)絡的學習會更加容易。下圖是Faster R-CNN的網(wǎng)絡結構圖。
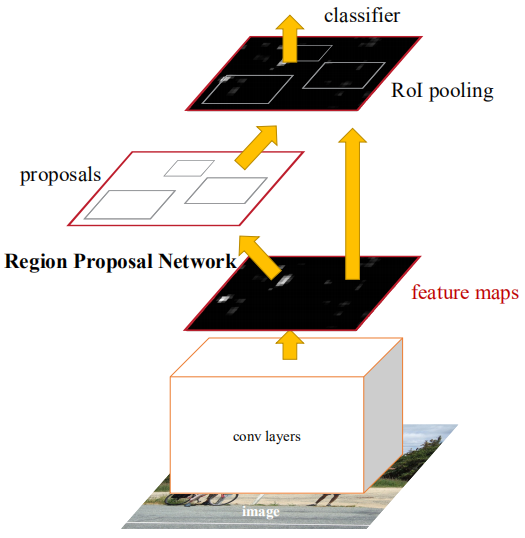
CascadeRCNN第一階段和Faster R-CNN完全一樣,第二階段使用多個RoiHead層進行級聯(lián)。后續(xù)的一些工作多是圍繞著上述網(wǎng)絡的一些改進或者前人工作的雜燴,罕有突破性提升。
1.2 單階段檢測
相較于兩階段算法,單階段算法只需一次提取特征即可實現(xiàn)目標檢測,其速度算法更快,一般精度稍微低一些。這類算法的開山之作是YOLO,隨后SSD、Retinanet依次對其進行了改進,提出YOLO的團隊將這些有助于提升性能的trick融入到YOLO算法中,后續(xù)又提出了4個改進版本YOLOv2~YOLOv5。盡管預測準確率不如雙階段目標檢測算法,由于較快的運行速度,YOLO成為了工業(yè)界的主流。下圖是YOLOv3的網(wǎng)絡結構圖。
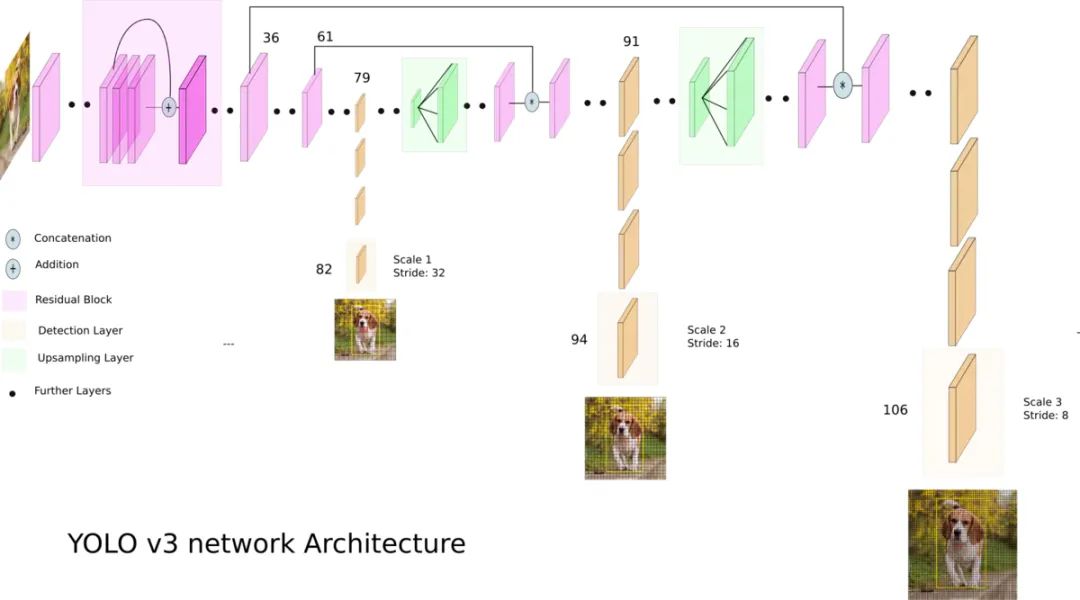
1.3 Anchor-free檢測(無Anchor檢測)
這類方法一般是將物體表示為一些關鍵點,CNN被用來回歸這些關鍵點的位置。關鍵點可以是物體框的中心點(CenterNet)、角點(CornerNet)或者代表點(RepPoints)。CenterNet將目標檢測問題轉換成中心點預測問題,即用目標的中心點來表示該目標,并通過預測目標中心點的偏移量與寬高來獲取目標的矩形框。Heatmap表示分類信息,每一個類別將會產(chǎn)生一個單獨的Heatmap圖。對于每張Heatmap圖而言,當某個坐標處包含目標的中心點時,則會在該目標處產(chǎn)生一個關鍵點,我們利用高斯圓來表示整個關鍵點,下圖展示了具體的細節(jié)。

RepPoints提出將物體表示為一個代表性點集,并且通過可變形卷積來適應物體的形狀變化。點集最后被轉換為物體框,用于計算與手工標注的差異。
1.4 Transformer檢測
無論是單階段還是兩階段目標檢測,無論采用Anchor與否,都沒有很好地利用到注意力機制。針對這種情況,Relation Net和DETR利用Transformer將注意力機制引入到目標檢測領域。Relation Net利用Transformer對不同目標之間的關系建模,在特征之中融入了關系信息,實現(xiàn)了特征增強。DETR則是基于Transformer提出了全新的目標檢測架構,開啟了目標檢測的新時代,下圖是DETR的算法流程,先采用CNN提取圖像特征,然后用Transformer對全局的空間關系進行建模,最后得到的輸出通過二分圖匹配算法與手工標注進行匹配。
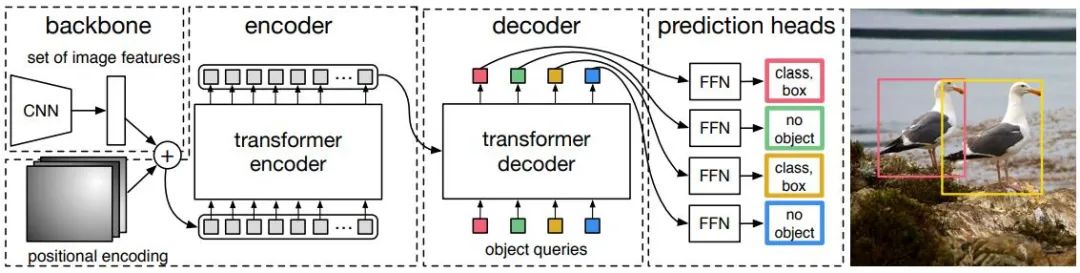
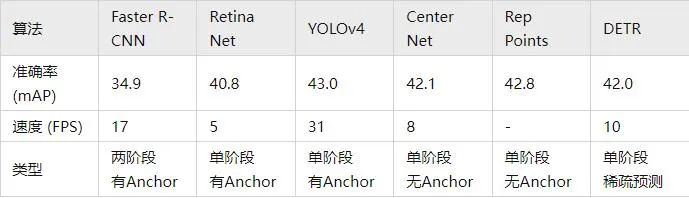
下表中的準確度采用MSCOCO數(shù)據(jù)庫上的mAP作為指標,而速度則采用FPS來衡量,對比了上述部分算法,由于網(wǎng)絡的結構設計中存在很多不同的選擇(比如不同的輸入大小,不同的Backbone網(wǎng)絡等),各個算法的實現(xiàn)硬件平臺也不同,因此準確率和速度并不完全可比,這里只列出來一個粗略的結果供大家參考。
在自動駕駛應用中,輸入的是視頻數(shù)據(jù),需要關注的目標有很多,比如車輛,行人,自行車等等。因此,這是一個典型的多物體跟蹤任務(MOT)。對于MOT任務來說,目前最流行的框架是Tracking-by-Detection,其流程如下:
①由目標檢測器在單幀圖像上得到目標框輸出;
②提取每個檢測目標的特征,通常包括視覺特征和運動特征;
③根據(jù)特征計算來自相鄰幀的目標檢測之間的相似度,以判斷其來自同一個目標的概率;
④將相鄰幀的目標檢測進行匹配,給來自同一個目標的物體分配相同的ID。
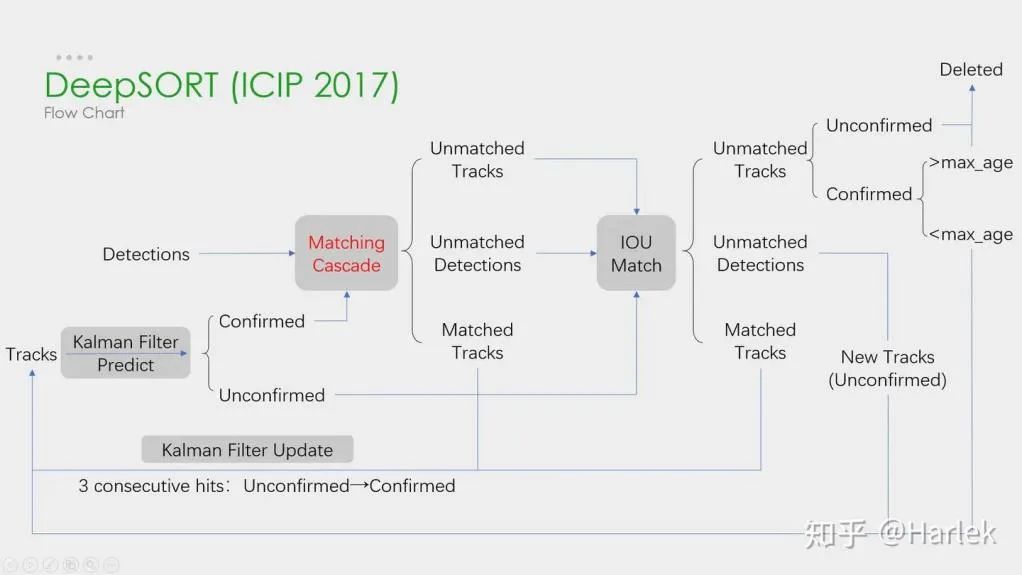
深度學習在以上這四個步驟中都有應用,但是以前兩個步驟為主。在步驟1中,深度學習的應用主要在于提供高質(zhì)量的目標檢測器,因此一般都選擇準確率較高的方法。SORT是基于Faster R-CNN的目標檢測方法,并利用卡爾曼濾波算法+匈牙利算法,極大提高了多目標跟蹤的速度,同時達到了SOTA的準確率,也是在實際應用中使用較為廣泛的一個算法。在步驟2中,深度學習的應用主要在于利用CNN提取物體的視覺特征。DeepSORT最大的特點是加入外觀信息,借用了ReID模塊來提取深度學習特征,減少了ID switch的次數(shù)。整體流程圖如下:
此外,還有一種框架Simultaneous Detection and Tracking。如代表性的CenterTrack,它起源于之前介紹過的單階段無Anchor的檢測算法CenterNet。與CenterNet相比,CenterTrack增加了前一幀的RGB圖像和物體中心Heatmap作為額外輸入,增加了一個Offset分支用來進行前后幀的Association。與多個階段的Tracking-by-Detection相比,CenterTrack將檢測和匹配階段用一個網(wǎng)絡來實現(xiàn),提高了MOT的速度。
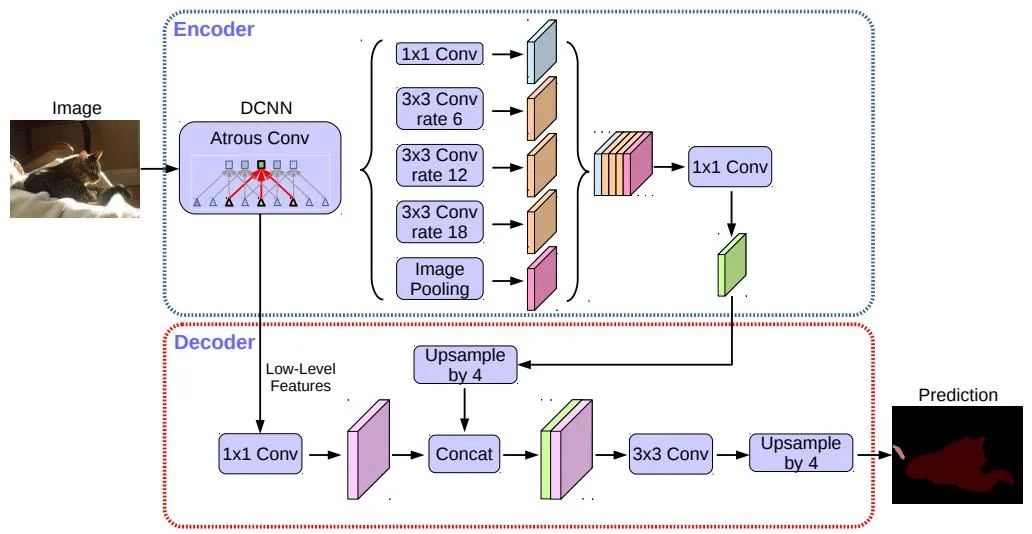
在自動駕駛的車道線檢測和可行駛區(qū)域檢測任務中均用到了語義分割。代表性的算法有FCN、U-Net、DeepLab系列等。DeepLab使用擴張卷積和ASPP(Atrous Spatial Pyramid Pooling)結構,對輸入圖像進行多尺度處理。最后采用傳統(tǒng)語義分割方法中常用的條件隨機場(CRF)來優(yōu)化分割結果。下圖是DeepLab v3+的網(wǎng)絡結構。
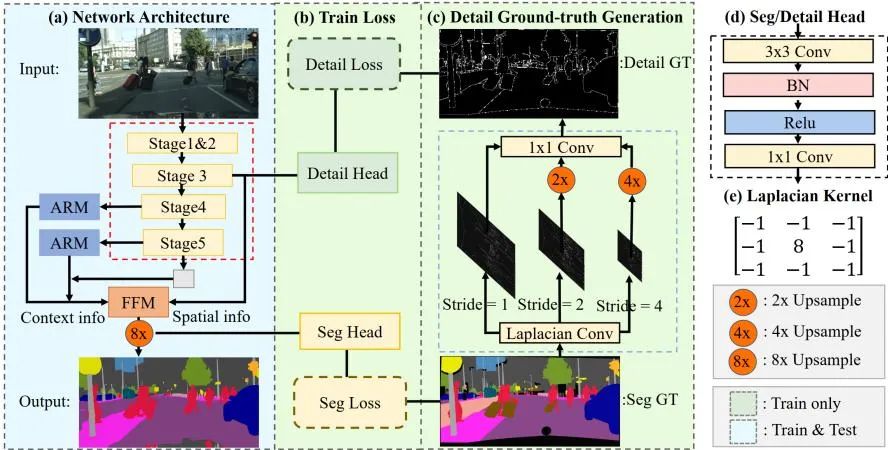
近些年的STDC算法采用了類似FCN算法的結構,去掉了U-Net算法復雜的decoder結構。但同時在網(wǎng)絡下采樣的過程中,利用ARM模塊不斷地去融合來自不同層特征圖的信息,因此也避免了FCN算法只考慮單個像素關系的缺點。可以說,STDC算法很好的做到了速度與精度的平衡,其可以滿足自動駕駛系統(tǒng)實時性的要求。算法流程如下圖所示。
自動駕駛視覺感知算法(二)
基于單攝像頭圖像來感知3D環(huán)境是一個不適定問題,但是可以通過幾何假設(比如像素位于地面)、先驗知識或者一些額外信息(比如深度估計)來輔助解決。本次將從實現(xiàn)自動駕駛的兩個基本任務(3D目標檢測和深度估計)出發(fā)進行相關算法介紹。

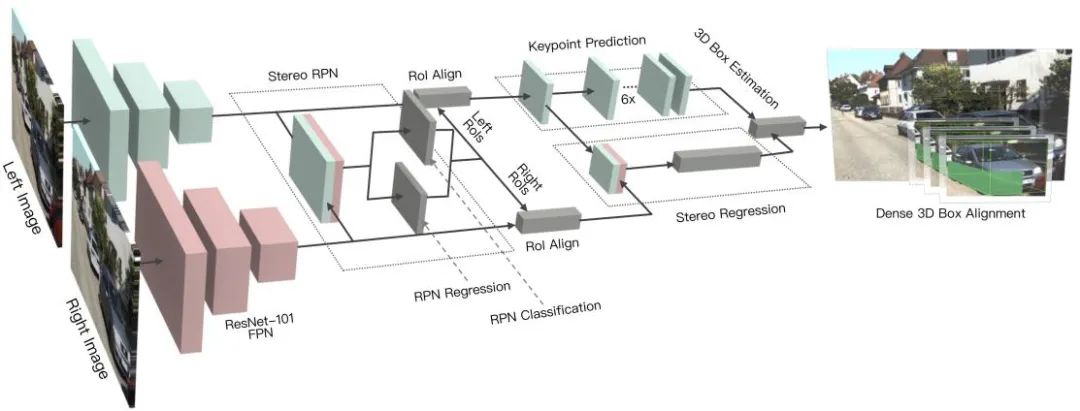
關鍵點和3D模型:待檢測目標如車輛、行人等其大小和形狀相對固定且已知,這些可以被用作估計目標3D信息的先驗知識。DeepMANTA是這個方向的開創(chuàng)性工作之一。首先,采用一些目標檢測算法比如Faster RNN來得到2D目標框,同時也檢測目標的關鍵點。然后,將這些2D目標框和關鍵點與數(shù)據(jù)庫中的多種3D車輛CAD模型分別進行匹配,選擇相似度最高的模型作為3D目標檢測的輸出。MonoGRNet則提出將單目3D目標檢測分成四個步驟:2D目標檢測、實例級深度估計、投影3D中心估計和局部角點回歸,算法流程如下圖所示。這類方法都假設目標有相對固定的形狀模型,對于車輛來說一般是滿足的,對于行人來說就相對困難一些。

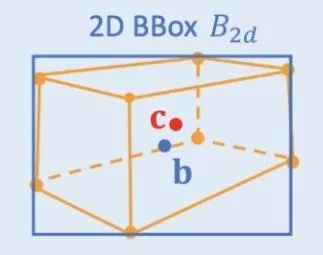
2D/3D幾何約束:對3D中心和粗略實例深度的投影進行回歸,并使用這二者估算粗略的3D位置。開創(chuàng)性的工作是Deep3DBox,首先用2D目標框內(nèi)的圖像特征來估計目標大小和朝向。然后,通過一個2D/3D的幾何約束來求解中心點3D位置。這個約束就是3D目標框在圖像上的投影是被2D目標框緊密包圍的,即2D目標框的每條邊上都至少能找到一個3D目標框的角點。通過之前已經(jīng)預測的大小和朝向,再配合上相機的標定參數(shù),可以求解出中心點的3D位置。2D和3D目標框之間的幾何約束如下圖所示。Shift R-CNN在Deep3DBox的基礎上將之前得到的2D目標框、3D目標框以及相機參數(shù)合并起來作為輸入,采用全連接網(wǎng)絡預測更為精確的3D位置。
1.2 深度估計
雙目視覺可以解決透視變換帶來的歧義性,因此從理論上來說可以提高3D感知的準確度。但是雙目系統(tǒng)在硬件和軟件上要求都比較高。硬件上來說需要兩個精確配準的攝像頭,而且需要保證在車輛運行過程中始終保持配準的正確性。軟件上來說算法需要同時處理來自兩個攝像頭的數(shù)據(jù),計算復雜度較高,算法的實時性難以保證。與單目相比,雙目的工作相對較少。接下來也同樣從3D目標檢測和深度估計兩方面進行簡單介紹。
2.1 3D目標檢測
雙目深度估計的原理很簡單,就是根據(jù)左右視圖上同一個3D點之間的像素距離d(假設兩個相機保持同一高度,因此只考慮水平方向的距離)即視差,相機的焦距f,以及兩個相機之間的距離B(基線長度),來估計3D點的深度,公式如下,估計出視差就可以計算出深度。那么,需要做的就是為每個像素點在另一張圖像上找出與之匹配的點。
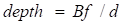
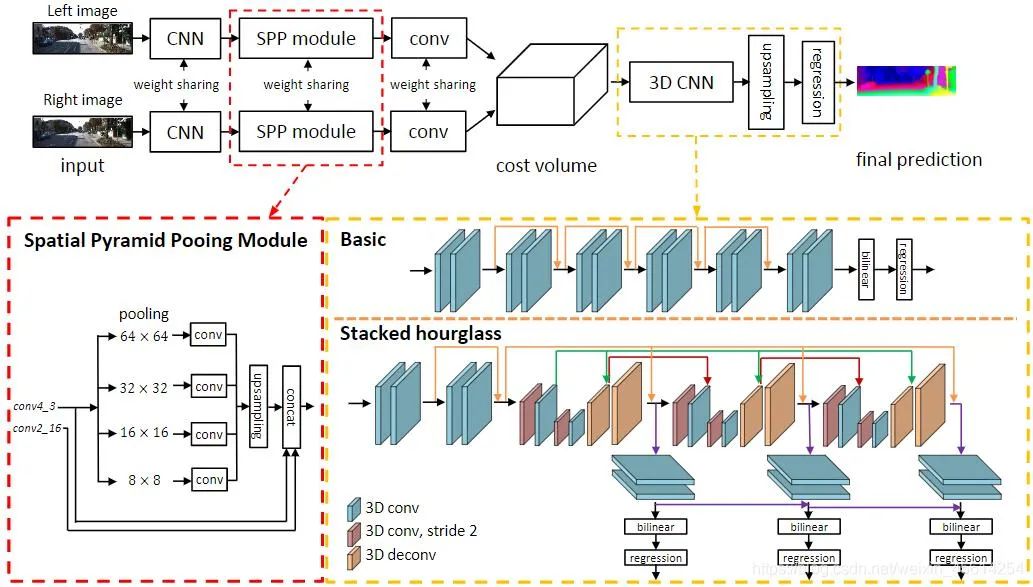
對于每一個可能的d,都可以計算每個像素點處的匹配誤差,因此就得到了一個三維的誤差數(shù)據(jù)Cost Volume。通過Cost Volume,我們可以很容易得到每個像素處的視差(對應最小匹配誤差的d),從而得到深度值。MC-CNN用一個卷積神經(jīng)網(wǎng)絡來預測兩個圖像塊的匹配程度,并用它來計算立體匹配成本。通過基于交叉的成本匯總和半全局匹配來細化成本,然后進行左右一致性檢查以消除被遮擋區(qū)域中的錯誤。PSMNet提出了一個不需要任何后處理的立體匹配的端到端學習框架,引入金字塔池模塊,將全局上下文信息納入圖像特征,并提供了一個堆疊沙漏3D CNN進一步強化全局信息。下圖是其網(wǎng)絡結構。
本文僅做學術分享,如有侵權,請聯(lián)系刪文。
下載1:OpenCV-Contrib擴展模塊中文版教程
在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。
下載2:Python視覺實戰(zhàn)項目52講
在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。
下載3:OpenCV實戰(zhàn)項目20講
在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學習進階。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~