
視覺傳感器:2D感知算法
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號(hào)
視覺/圖像重磅干貨,第一時(shí)間送達(dá)
1 前言
2 物體檢測
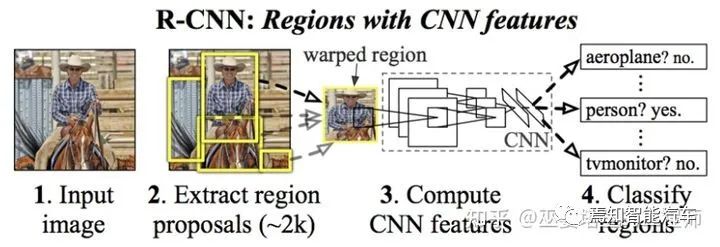
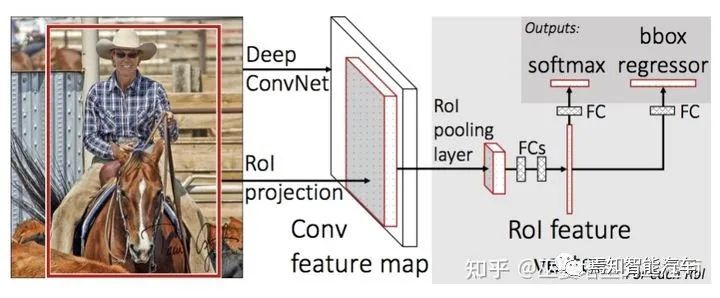
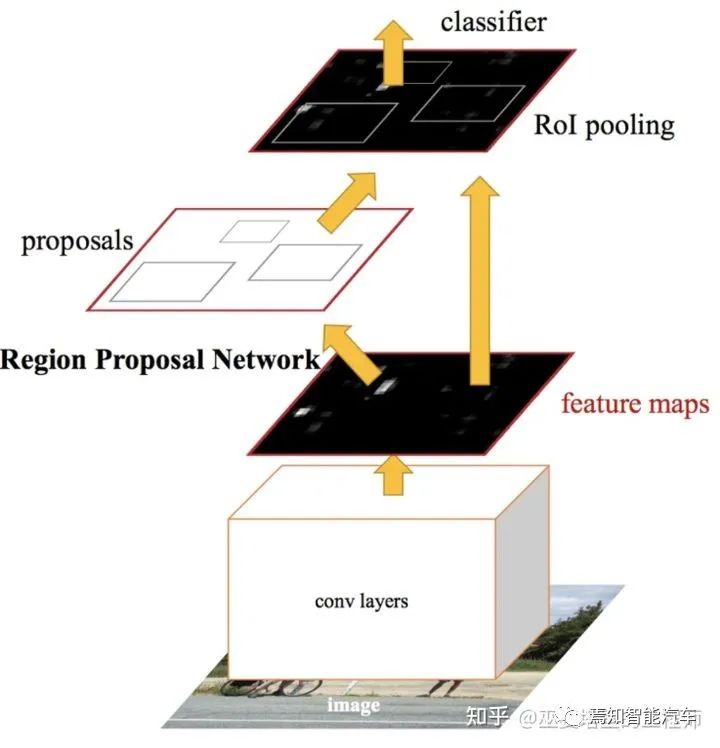
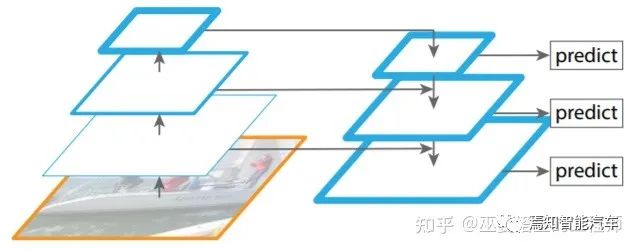
2.1 兩階段檢測
2.2 單階段檢測
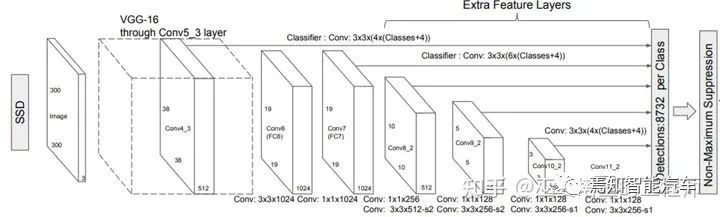
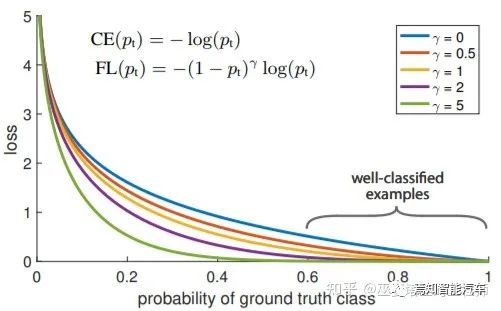
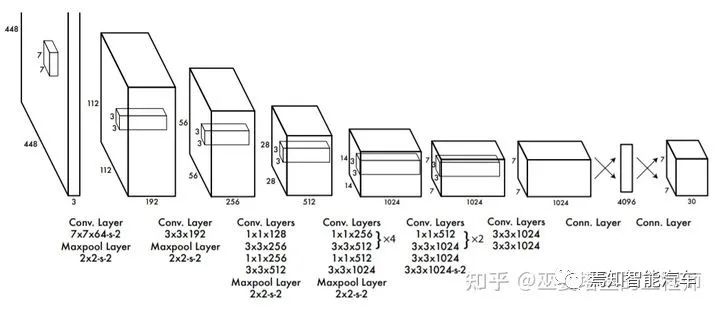
2.3 無Anchor檢測

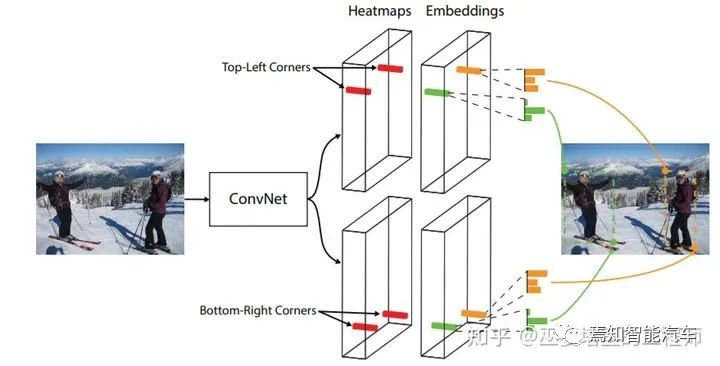
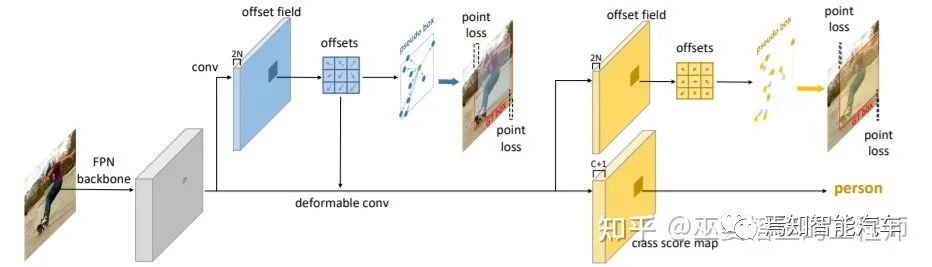

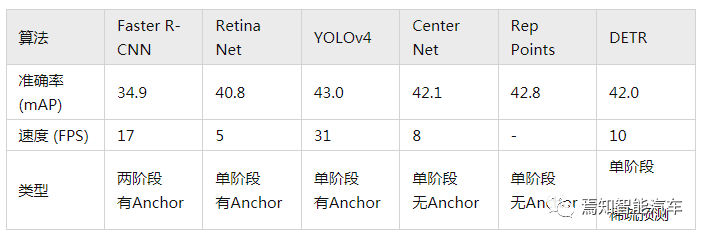
2.4 性能對(duì)比
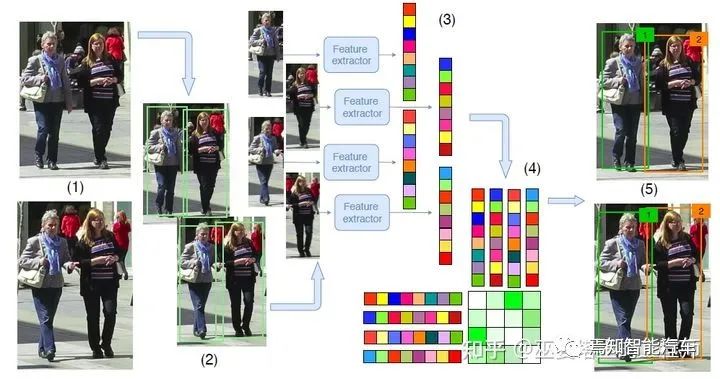
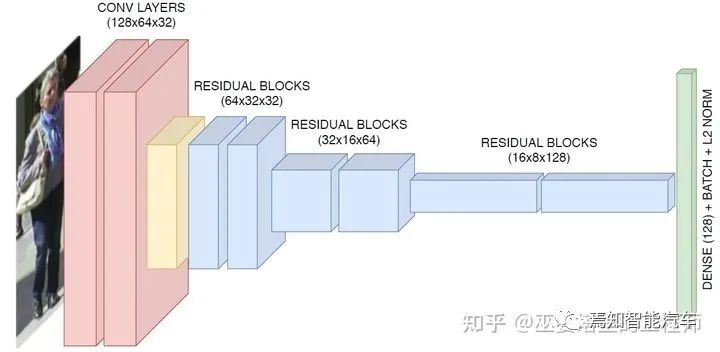
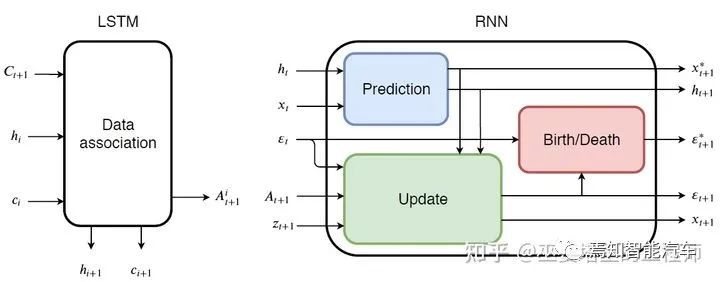
3 物體跟蹤
由物體檢測器在單幀圖像上得到物體框輸出。 提取每個(gè)檢測物體的特征,通常包括視覺特征和運(yùn)動(dòng)特征。 根據(jù)特征計(jì)算來自相鄰幀的物體檢測之間的相似度,以判斷其來自同一個(gè)目標(biāo)的概率。 將相鄰幀的物體檢測進(jìn)行匹配,給來自同一個(gè)目標(biāo)的物體分配相同的ID。

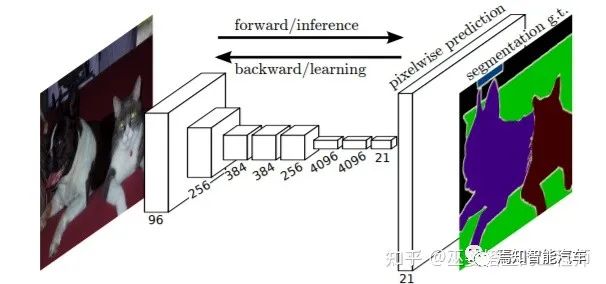
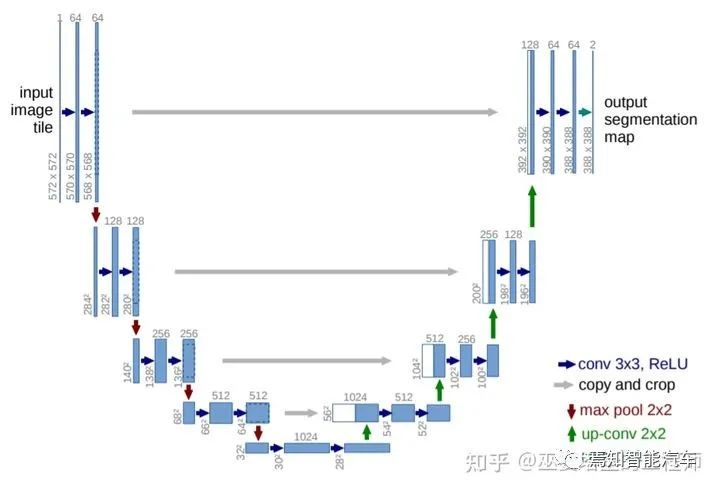
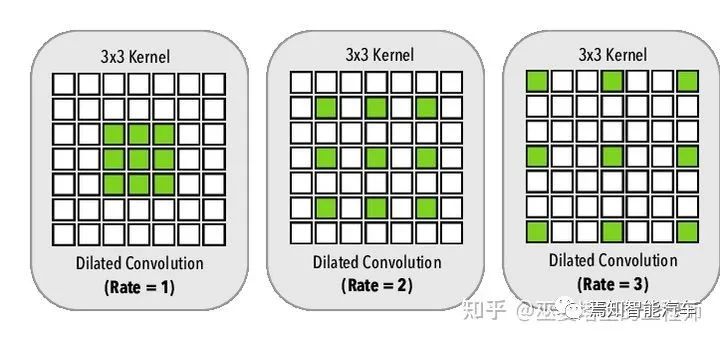
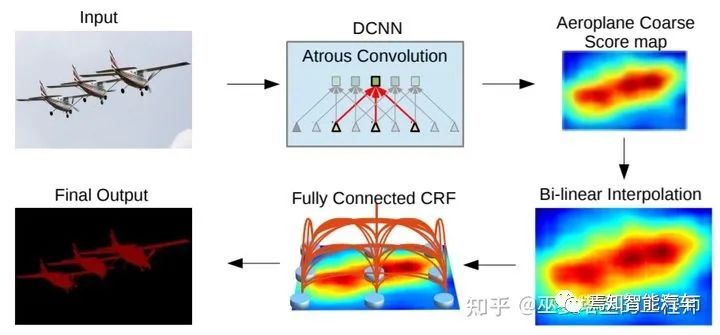
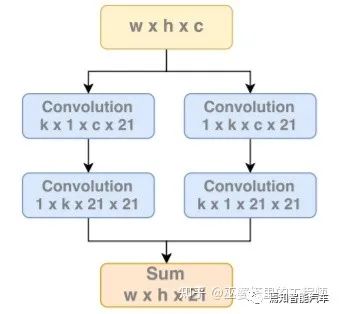
4 語義分割
參考文獻(xiàn):
[1] Girshick et al., Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation, 2014.
[2] Girshick, Fast R-CNN, 2015.
[3] Ren et al., Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
[4] Lin et al., Feature Pyramid Networks for Object Detection, 2017.
[5] Liu et al., SSD: Single Shot MultiBox Detector, 2015.
[6] Lin et al., Focal Loss for Dense Object Detection, 2017.
—版權(quán)聲明—
僅用于學(xué)術(shù)分享,版權(quán)屬于原作者。
若有侵權(quán),請(qǐng)聯(lián)系微信號(hào):yiyang-sy 刪除或修改!
評(píng)論
圖片
表情