
270億參數(shù)、刷榜CLUE,達摩院神作!
經(jīng)歷「大煉模型」后,人工智能領域正進入「煉大模型」時代。自去年 OpenAI 發(fā)布英文領域超大規(guī)模預訓練語言模型 GPT-3 后,中文領域同類模型的訓練進程備受關注。今日,阿里達摩院發(fā)布了 270 億參數(shù)、1TB + 訓練數(shù)據(jù)的全球最大中文預訓練語言模型 PLUG,并以 80.614 的分數(shù)刷新了中文語言理解評測基準 CLUE 分類榜單歷史紀錄。
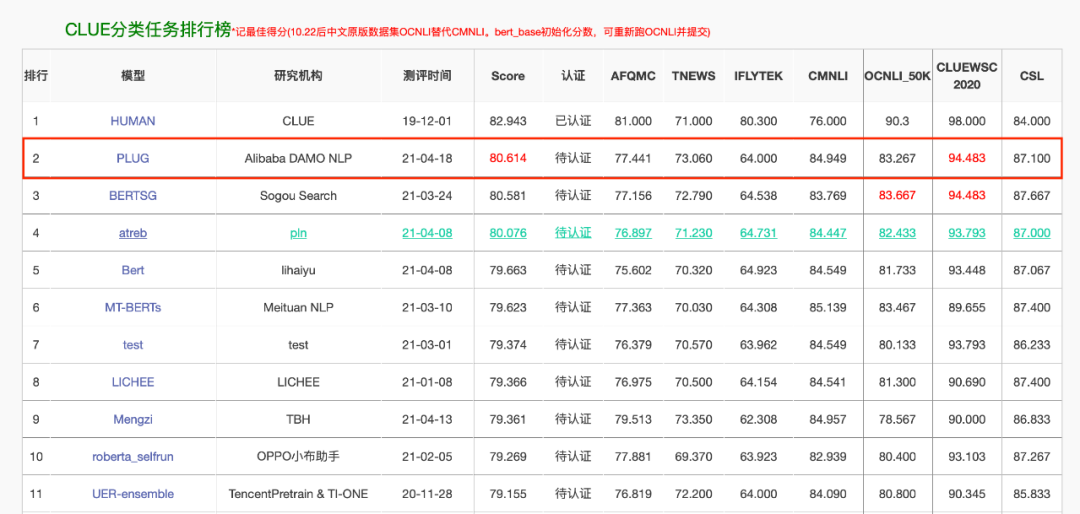
PLUG 是目前中文社區(qū)最大規(guī)模的純文本預訓練語言模型;
PLUG 集語言理解與生成能力于一身,在語言理解(NLU)任務上,以 80.614 的得分刷新了 Chinese GLUE 分類榜單的新記錄排名第一;在語言生成(NLG)任務上,在多項業(yè)務數(shù)據(jù)上較 SOTA 平均提升 8% 以上;
PLUG 可為目標任務做針對性優(yōu)化,通過利用下游訓練數(shù)據(jù)微調模型使其在特定任務上生成質量達到最優(yōu),彌補之前其它大規(guī)模生成模型 few-shot inference 的生成效果不足,可應用于實際生成任務上;
PLUG 采用了大規(guī)模的高質量中文訓練數(shù)據(jù)(1TB 以上),同時,PLUG 采用 encoder-decoder 的雙向建模方式,因此,在傳統(tǒng)的 zero-shot 生成的表現(xiàn)上,無論是生成的多樣性、領域的廣泛程度,還是生成長文本的表現(xiàn),較此前的模型均有明顯的優(yōu)勢。
首先在第一階段,達摩院團隊訓練了一個 24 layers/8192 hidden size 的標準 StructBERT 模型作為 encoder。這個過程共計訓練了 300B tokens 的訓練數(shù)據(jù),規(guī)模與 GPT-3 的訓練規(guī)模相當;
在第二階段,達摩院團隊將這個 encoder 用于生成模型的初始化,并外掛了一個 6 layers / 8192 hidden size 的 decoder,在訓練生成模型的過程中,在 encoder 端和 decoder 端均隨機確定長度 [32, 512] 進行數(shù)據(jù)采樣,確保適應下游廣泛的生成任務。這一階段共計訓練了 100B tokens 的訓練數(shù)據(jù),前 90% 的訓練中,團隊保留了 Masked LM 任務以保持模型的 NLU 能力,后 10% 的訓練中,去掉 MLM 任務進行微調,以使得生成的 PPL 降到更低,能取得更好的生成效果。

? THE END
轉載請聯(lián)系原公眾號獲得授權
投稿或尋求報道:[email protected]

點個在看 paper不斷!