
肝了3天,整理了50個Pandas高頻使用技巧,強烈建議收藏!
pandas當中經常會被用到的方法,篇幅可能有點長但是提供的都是干貨,讀者朋友們看完之后也可以點贊收藏,相信會對大家有所幫助,大致本文會講述這些內容DataFrame初印象 讀取表格型數據 篩選出特定的行 用 pandas來繪圖在DataFrame中新增行與列 DataFrame中的統(tǒng)計分析與計算 DataFrame中排序問題 合并多個表格 時序問題的處理 字符串類型數據的處理
DataFrame初印象
我們先來通過Python當中的字典類型來創(chuàng)建一個DataFrame,
import?pandas?as?pd
data?=?{"Country":?["Canada",?"USA",?"UK"],
????????"Population":?[10.52*10**6,?350.1*10**6,?65.2*10**6]
???????}
df?=?pd.DataFrame(data)
df
Python當中的字典來創(chuàng)建DataFrame,字典當中的keys會被當做是列名,而values則是表格當中的值??Country???Population
0??Canada???10520000.0
1?????USA??350100000.0
2??????UK???65200000.0
要是我們要獲取當中的某一列,我們可以這么來做
df["Country"]
output
0????Portugal
1?????????USA
2??????France
Name:?Country,?dtype:?object
而當我們想要獲取表格當中每一列的數據格式的時候,可以這么做
df.dtypes
output
Country????????object
Population????float64
dtype:?object
讀取數據
Pandas當中有特定的模塊可以來讀取數據,要是讀取的文件是csv格式,我們可以這么來做import?pandas?as?pd
df?=?pd.read_csv("titanic.csv")
我們要是想要查看表格的前面幾行,可以這么做
df.head(7)
output
???PassengerId??Survived??Pclass??...?????Fare?Cabin??Embarked
0????????????1?????????0???????3??...???7.2500???NaN?????????S
1????????????2?????????1???????1??...??71.2833???C85?????????C
2????????????3?????????1???????3??...???7.9250???NaN?????????S
3????????????4?????????1???????1??...??53.1000??C123?????????S
4????????????5?????????0???????3??...???8.0500???NaN?????????S
5????????????6?????????0???????3??...???8.4583???NaN?????????Q
6????????????7?????????0???????1??...??51.8625???E46?????????S
tail()方法來展示末尾的若干行的數據df.tail(7)
output
?????PassengerId??Survived??Pclass??...????Fare?Cabin??Embarked
884??????????885?????????0???????3??...???7.050???NaN?????????S
885??????????886?????????0???????3??...??29.125???NaN?????????Q
886??????????887?????????0???????2??...??13.000???NaN?????????S
887??????????888?????????1???????1??...??30.000???B42?????????S
888??????????889?????????0???????3??...??23.450???NaN?????????S
889??????????890?????????1???????1??...??30.000??C148?????????C
890??????????891?????????0???????3??...???7.750???NaN?????????Q
要是遇到文件的格式是excel格式,pandas當中也有相對應的方法
df?=?pd.read_excel("titanic.xlsx")
可以通過pandas當中的info()方法來獲取對表格數據的一個初步的印象
df.info()
output
'pandas.core.frame.DataFrame'>
RangeIndex:?891?entries,?0?to?890
Data?columns?(total?12?columns):
?#???Column???????Non-Null?Count??Dtype??
---??------???????--------------??-----??
?0???PassengerId??891?non-null????int64??
?1???Survived?????891?non-null????int64??
?2???Pclass???????891?non-null????int64??
?3???Name?????????891?non-null????object?
?4???Sex??????????891?non-null????object?
?5???Age??????????714?non-null????float64
?6???SibSp????????891?non-null????int64??
?7???Parch????????891?non-null????int64??
?8???Ticket???????891?non-null????object?
?9???Fare?????????891?non-null????float64
?10??Cabin????????204?non-null????object?
?11??Embarked?????889?non-null????object?
dtypes:?float64(2),?int64(5),?object(5)
memory?usage:?83.7+?KB
篩選出特定條件的行
要是我們想要篩選出年齡在30歲以上的乘客,我們可以這么來操作
df[df["Age"]?>?30]
output
?????PassengerId??Survived??Pclass??...?????Fare?Cabin??Embarked
1??????????????2?????????1???????1??...??71.2833???C85?????????C
3??????????????4?????????1???????1??...??53.1000??C123?????????S
4??????????????5?????????0???????3??...???8.0500???NaN?????????S
6??????????????7?????????0???????1??...??51.8625???E46?????????S
11????????????12?????????1???????1??...??26.5500??C103?????????S
..???????????...???????...?????...??...??????...???...???????...
873??????????874?????????0???????3??...???9.0000???NaN?????????S
879??????????880?????????1???????1??...??83.1583???C50?????????C
881??????????882?????????0???????3??...???7.8958???NaN?????????S
885??????????886?????????0???????3??...??29.1250???NaN?????????Q
890??????????891?????????0???????3??...???7.7500???NaN?????????Q
[305?rows?x?12?columns]
當然我們也可以將若干個條件合起來,一同做篩選,例如
survived_under_45?=?df[(df["Survived"]==1)?&?(df["Age"]<45)]
survived_under_45
output
?????PassengerId??Survived??Pclass??...?????Fare?Cabin??Embarked
1??????????????2?????????1???????1??...??71.2833???C85?????????C
2??????????????3?????????1???????3??...???7.9250???NaN?????????S
3??????????????4?????????1???????1??...??53.1000??C123?????????S
8??????????????9?????????1???????3??...??11.1333???NaN?????????S
9?????????????10?????????1???????2??...??30.0708???NaN?????????C
..???????????...???????...?????...??...??????...???...???????...
874??????????875?????????1???????2??...??24.0000???NaN?????????C
875??????????876?????????1???????3??...???7.2250???NaN?????????C
880??????????881?????????1???????2??...??26.0000???NaN?????????S
887??????????888?????????1???????1??...??30.0000???B42?????????S
889??????????890?????????1???????1??...??30.0000??C148?????????C
[247?rows?x?12?columns]
&也就是and的表達方式來將兩個條件組合到一起,表示要將上述兩個條件都滿足的數據給篩選出來。當然我們在上文也提到,數據集中有部分的列存在空值,我們可以以此來篩選行與列df[df["Age"].notna()]
output
?????PassengerId??Survived??Pclass??...?????Fare?Cabin??Embarked
0??????????????1?????????0???????3??...???7.2500???NaN?????????S
1??????????????2?????????1???????1??...??71.2833???C85?????????C
2??????????????3?????????1???????3??...???7.9250???NaN?????????S
3??????????????4?????????1???????1??...??53.1000??C123?????????S
4??????????????5?????????0???????3??...???8.0500???NaN?????????S
..???????????...???????...?????...??...??????...???...???????...
885??????????886?????????0???????3??...??29.1250???NaN?????????Q
886??????????887?????????0???????2??...??13.0000???NaN?????????S
887??????????888?????????1???????1??...??30.0000???B42?????????S
889??????????890?????????1???????1??...??30.0000??C148?????????C
890??????????891?????????0???????3??...???7.7500???NaN?????????Q
[714?rows?x?12?columns]
isin方法來進行篩選,df[df["Pclass"].isin([1,?2])]
output
?????PassengerId??Survived??Pclass??...?????Fare?Cabin??Embarked
1??????????????2?????????1???????1??...??71.2833???C85?????????C
3??????????????4?????????1???????1??...??53.1000??C123?????????S
6??????????????7?????????0???????1??...??51.8625???E46?????????S
9?????????????10?????????1???????2??...??30.0708???NaN?????????C
11????????????12?????????1???????1??...??26.5500??C103?????????S
..???????????...???????...?????...??...??????...???...???????...
880??????????881?????????1???????2??...??26.0000???NaN?????????S
883??????????884?????????0???????2??...??10.5000???NaN?????????S
886??????????887?????????0???????2??...??13.0000???NaN?????????S
887??????????888?????????1???????1??...??30.0000???B42?????????S
889??????????890?????????1???????1??...??30.0000??C148?????????C
[400?rows?x?12?columns]
df[(df["Pclass"]?==?1)?|?(df["Pclass"]?==?2)]
篩選出特定條件的行與列
df.loc[df["Age"]?>?40,"Name"]
output
6????????????????????????????????McCarthy,?Mr.?Timothy?J
11??????????????????????????????Bonnell,?Miss.?Elizabeth
15??????????????????????Hewlett,?Mrs.?(Mary?D?Kingcome)?
33?????????????????????????????????Wheadon,?Mr.?Edward?H
35????????????????????????Holverson,?Mr.?Alexander?Oskar
?????????????????????????????...????????????????????????
862????Swift,?Mrs.?Frederick?Joel?(Margaret?Welles?Ba...
865?????????????????????????????Bystrom,?Mrs.?(Karolina)
871?????Beckwith,?Mrs.?Richard?Leonard?(Sallie?Monypeny)
873??????????????????????????Vander?Cruyssen,?Mr.?Victor
879????????Potter,?Mrs.?Thomas?Jr?(Lily?Alexenia?Wilson)
Name:?Name,?Length:?150,?dtype:?object
loc\iloc來篩選出部分數據的時候,[]中的第一部分代表的是“行”,例如df["Age"] > 40,而[]中的第二部分代表的是“列”,例如Name,你可以選擇只要一列,也可以選擇需要多列,用括號括起來即可df.loc[df["Age"]?>?40,["Name",?"Sex"]]
如果我們將逗號后面的部分直接用:來代替,則意味著要所有的列
df.loc[df["Age"]?>?40,:]
output
?????PassengerId??Survived??Pclass??...?????Fare?Cabin??Embarked
6??????????????7?????????0???????1??...??51.8625???E46?????????S
11????????????12?????????1???????1??...??26.5500??C103?????????S
15????????????16?????????1???????2??...??16.0000???NaN?????????S
33????????????34?????????0???????2??...??10.5000???NaN?????????S
35????????????36?????????0???????1??...??52.0000???NaN?????????S
..???????????...???????...?????...??...??????...???...???????...
862??????????863?????????1???????1??...??25.9292???D17?????????S
865??????????866?????????1???????2??...??13.0000???NaN?????????S
871??????????872?????????1???????1??...??52.5542???D35?????????S
873??????????874?????????0???????3??...???9.0000???NaN?????????S
879??????????880?????????1???????1??...??83.1583???C50?????????C
[150?rows?x?12?columns]
iloc來進行篩選,只是與上面loc不同的在于,這里我們要填的是索引,例如我們想要前面的0-3列以及0-9行的內容,df.iloc[0:10,?0:3]
output
???PassengerId??Survived??Pclass
0????????????1?????????0???????3
1????????????2?????????1???????1
2????????????3?????????1???????3
3????????????4?????????1???????1
4????????????5?????????0???????3
5????????????6?????????0???????3
6????????????7?????????0???????1
7????????????8?????????0???????3
8????????????9?????????1???????3
9???????????10?????????1???????2
用Pandas來畫圖
我們還可以用Pandas來畫圖,而且實際用到的代碼量還比較的少
df.plot()
output
要是你想要單獨某一列的趨勢圖,我們也可以這么做
df["Age"].plot()
output
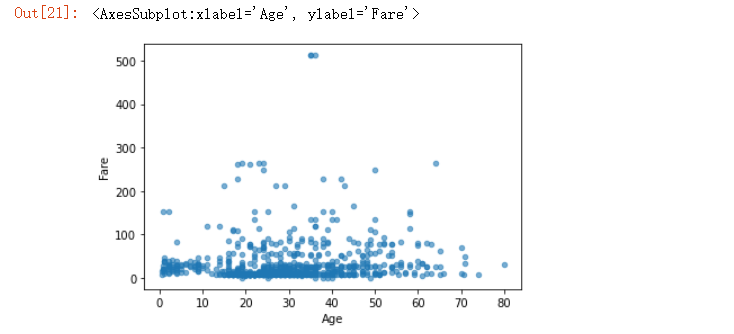
要是我們想要不同年齡對于船票費“Fare”的影響,畫圖可以這么來畫
df.plot.scatter(x?=?"Age",?y?=?"Fare",?alpha?=?0.6)
output
for?method_name?in?dir(df.plot):
????if?not?method_name.startswith("_"):
????????print(method_name)
output
area
bar
barh
box
density
hexbin
hist
kde
line
pie
scatter
df.plot.box()
output
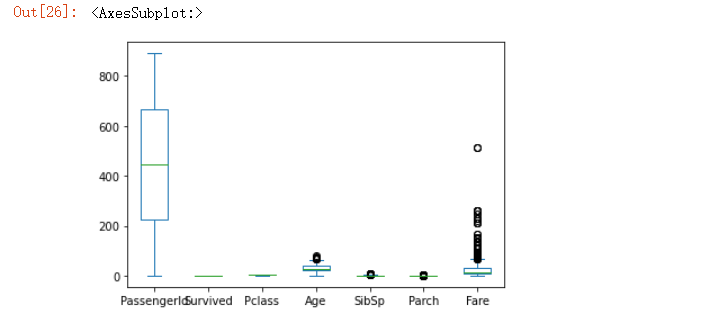
要是我們希望可以分開來繪制圖形,就可以這么來操作
df.plot.area(figsize=(12,?4),?subplots=True)
output
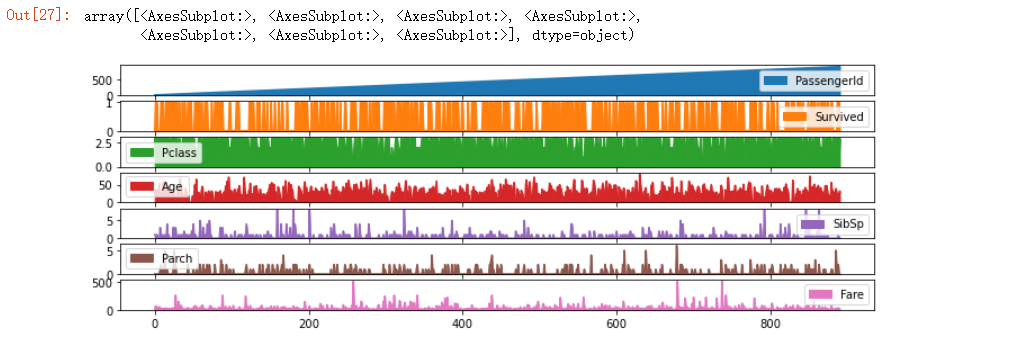
要是我們想要將繪制好的圖片保存下來,可以直接使用savefig方法,
import?matplotlib.pyplot?as?plt
fig,?axs?=?plt.subplots(figsize=(12,?4))
df.plot.area(ax=axs)
fig.savefig("test.png")
output
如何新增一列
在DataFrame當中新增一列其實不難,我們可以這么來操作
df["Date"]?=?pd.date_range("1912-04-02",?periods=len(df))
df.head()
output
???PassengerId??Survived??Pclass??...?Cabin?Embarked???????Date
0????????????1?????????0???????3??...???NaN????????S?1912-04-02
1????????????2?????????1???????1??...???C85????????C?1912-04-03
2????????????3?????????1???????3??...???NaN????????S?1912-04-04
3????????????4?????????1???????1??...??C123????????S?1912-04-05
4????????????5?????????0???????3??...???NaN????????S?1912-04-06
[5?rows?x?13?columns]
def?define_age(age):
????if?age?????????return?"少年"
????elif?age?>=?18?and?age?????????return?"青年"
????elif?age?>=?35?and?age?????????return?"中年"
????else:
????????return?"老年"
然后再用apply來實現
df["Generation"]?=?df["Age"].apply(define_age)
df.head()
output
???PassengerId??Survived??Pclass??...?Cabin?Embarked??Generation
0????????????1?????????0???????3??...???NaN????????S??????????青年
1????????????2?????????1???????1??...???C85????????C??????????中年
2????????????3?????????1???????3??...???NaN????????S??????????青年
3????????????4?????????1???????1??...??C123????????S??????????中年
4????????????5?????????0???????3??...???NaN????????S??????????中年
[5?rows?x?13?columns]
如果我們想給表格中的列名重新命名的話,可以使用rename方法,
df_renamed?=?df.rename(columns={"Name":"Full?Name",?"Sex":?"Gender",?"Ticket":?"FareTicket"})
df_renamed.head()
output
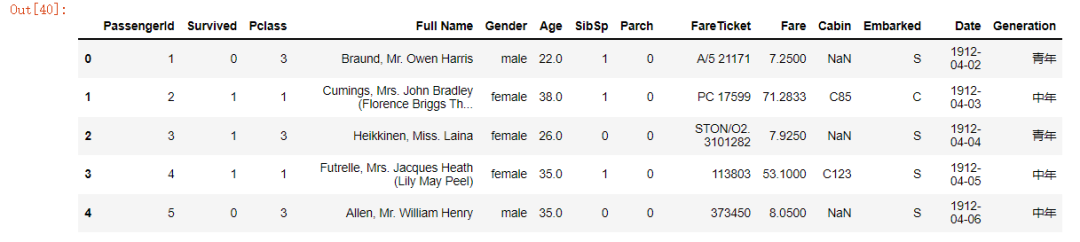
DataFrame中的統(tǒng)計分析
在Pandas中也提供了很多相關的方法來進行數據的統(tǒng)計分析
print(df["Age"].mean())
print(df["Age"].max())
print(df["Age"].min())
print(df["Age"].median())
29.69911764705882
80.0
0.42
28.0
同時我們也可以使用describe()方法
df.describe()
output
???????PassengerId????Survived??????Pclass??...???????SibSp???????Parch????????Fare
count???891.000000??891.000000??891.000000??...??891.000000??891.000000??891.000000
mean????446.000000????0.383838????2.308642??...????0.523008????0.381594???32.204208
std?????257.353842????0.486592????0.836071??...????1.102743????0.806057???49.693429
min???????1.000000????0.000000????1.000000??...????0.000000????0.000000????0.000000
25%?????223.500000????0.000000????2.000000??...????0.000000????0.000000????7.910400
50%?????446.000000????0.000000????3.000000??...????0.000000????0.000000???14.454200
75%?????668.500000????1.000000????3.000000??...????1.000000????0.000000???31.000000
max?????891.000000????1.000000????3.000000??...????8.000000????6.000000??512.329200
[8?rows?x?7?columns]
當然我們也可以對于特定幾列的數據進行統(tǒng)計分析
df.agg(
????{
????????"Age":?["min",?"max",?"mean"],
????????"Fare":?["min",?"max",?"mean"]
????}
)
output
????????????Age????????Fare
min????0.420000????0.000000
max???80.000000??512.329200
mean??29.699118???32.204208
groupby方法來進行數據的統(tǒng)計,例如我們想要知道不同的性別之下的平均年齡分別是多少,可以這么來操作df[["Sex",?"Age"]].groupby("Sex").mean()
output
??????????????Age
Sex??????????????
female??27.915709
male????30.726645
另外,value_counts()方法也可以針對單獨某一列數據,看一下數據的具體分布,
df["Pclass"].value_counts()
output
3????491
1????216
2????184
Name:?Pclass,?dtype:?int64
DataFrame中的排序問題
我們假設有這么一組數據,
data?=?{
????"Name":?["Mike",?"Peter",?"Clara",?"Tony",?"John"],
????"Age":?[30,?26,?20,?22,?25]
}
df?=?pd.DataFrame(data)
df
output
????Name??Age
0???Mike???30
1??Peter???26
2??Clara???20
3???Tony???22
4???John???25
我們可以將數據按照“Age”年齡這一列來進行排序
df.sort_values(by="Age")
output
????Name??Age
2??Clara???20
3???Tony???22
4???John???25
1??Peter???26
0???Mike???30
當然我們也可以按照降序來進行排列
df.sort_values("Age",?ascending=False)
output
????Name??Age
0???Mike???30
1??Peter???26
4???John???25
3???Tony???22
2??Clara???20
合并多個表格
例如我們有這么兩個表格,
df1?=?pd.DataFrame(
????{
????????"Name":?["Mike",?"John",?"Clara",?"Linda"],
?????????"Age":?[30,?26,?20,?22]
????}
)
df2?=?pd.DataFrame(
?????{
?????????"Name":?["Brian",?"Mary"],
?????????"Age":?[45,?38]
?????}
)
df_names_ages?=?pd.concat([df1,?df2],?axis=0)
df_names_ages
output
????Name??Age
0???Mike???30
1???John???26
2??Clara???20
3??Linda???22
0??Brian???45
1???Mary???38
concat方法來進行合并,當然我們也可以用join方法df1?=?pd.DataFrame(
????{
????????"Name":?["Mike",?"John",?"Clara",?"Sara"],
?????????"Age":?[30,?26,?20,?22],
????????"City":?["New?York",?"Shanghai",?"London",?"Paris"],
????}
)
df2?=?pd.DataFrame(
?????{
?????????"City":?["New?York",?"Shanghai",?"London",?"Paris"],
?????????"Occupation":?["Machine?Learning?Enginner",?"Data?Scientist",?"Doctor","Teacher"]
?????}
)
df_merged?=?pd.merge(df1,df2,how="left",?on="City")
df_merged
output
????Name??Age??????City?????????????????Occupation
0???Mike???30??New?York??Machine?Learning?Enginner
1???John???26??Shanghai?????????????Data?Scientist
2??Clara???20????London?????????????????????Doctor
3???Sara???22?????Paris????????????????????Teacher
join方法依次來進行合并。由于篇幅有限,小編在這里也就簡單地提及一下,后面再專門寫篇文章來詳細說明。時序問題的處理
在時序問題的處理上,小編之前專門寫過一篇文章,具體可以看
例如我們有這么一個數據集
df?=?pd.read_csv("air_quality.csv")
df?=?df.rename(columns={"date.utc":?"datetime"})
df.head()
output
????city?country???????????????????datetime?location?parameter??value
0??Paris??????FR??2019-06-21?00:00:00+00:00??FR04014???????no2???20.0
1??Paris??????FR??2019-06-20?23:00:00+00:00??FR04014???????no2???21.8
2??Paris??????FR??2019-06-20?22:00:00+00:00??FR04014???????no2???26.5
3??Paris??????FR??2019-06-20?21:00:00+00:00??FR04014???????no2???24.9
4??Paris??????FR??2019-06-20?20:00:00+00:00??FR04014???????no2???21.4
我們看一下目前“datetime”這一列的數據類型
df.dtypes
output
city??????????object
country???????object
datetime??????object
location??????object
parameter?????object
value????????float64
dtype:?object
pandas當中的to_datetime方法將“datetime”這一列轉換成“datetime”的格式df["datetime"]?=?pd.to_datetime(df["datetime"])
df["datetime"].head()
output
0???2019-06-21?00:00:00+00:00
1???2019-06-20?23:00:00+00:00
2???2019-06-20?22:00:00+00:00
3???2019-06-20?21:00:00+00:00
4???2019-06-20?20:00:00+00:00
Name:?datetime,?dtype:?datetime64[ns,?UTC]
我們便可以查看起始的日期
df["datetime"].min(),?df["datetime"].max()
output
(Timestamp('2019-05-07?01:00:00+0000',?tz='UTC'),
?Timestamp('2019-06-21?00:00:00+0000',?tz='UTC'))
中間相隔的時間
df["datetime"].max()?-?df["datetime"].min()
output
Timedelta('44?days?23:00:00')
文本數據的處理問題
當我們的數據集中存在文本數據時,pandas內部也有相對應的處理方法
data?=?{"Full?Name":?["Peter?Parker",?"Linda?Elisabeth",?"Bob?Dylan"],
????????"Age":?[40,?50,?60]}
df?=?pd.DataFrame(data)
df
output
?????????Full?Name??Age
0?????Peter?Parker???40
1??Linda?Elisabeth???50
2????????Bob?Dylan???60
可以用str方法將這些文本數據摘取出來,然后再進一步操作
df["Full?Name"].str.lower()
output
0?????? peter parker
1????linda?elisabeth
2??????????bob?dylan
Name:?Full?Name,?dtype:?object
或者也可以這樣來操作
df["Last?Name"]?=?df["Full?Name"].str.split("?").str.get(-1)
df
output
?????????Full?Name??Age??Last?Name
0?????Peter?Parker???40?????Parker
1??Linda?Elisabeth???50??Elisabeth
2????????Bob?Dylan???60??????Dylan
這樣我們可以將其“姓”的部分給提取出來,同樣的我們也可以提取“名”的部分
df["First?Name"]?=?df["Full?Name"].str.split("?").str.get(0)
df
output
?????????Full?Name??Age??Last?Name?First?Name
0?????Peter?Parker???40?????Parker??????Peter
1??Linda?Elisabeth???50??Elisabeth??????Linda
2????????Bob?Dylan???60??????Dylan????????Bob
我們也可以通過contains方法來查看字段中是不是包含了某一個字符串
df["Full?Name"].str.contains("Bob")
output
0????False
1????False
2?????True
Name:?Full?Name,?dtype:?bool
同樣也是通過str方法將文本數據也提取出來再進行進一步的操作
推薦閱讀
(點擊標題可跳轉閱讀)
老鐵,三連支持一下,好嗎?↓↓↓