
實戰(zhàn) | flink sql 與微博熱搜的碰撞!!!
1.序篇
通過本文你可以 get 到:
背景篇 定義篇-屬于哪類特點的指標 數(shù)據(jù)應用篇-預期效果是怎樣的 難點剖析篇-此類指標建設、保障的難點 數(shù)據(jù)建設篇-具體實現(xiàn)方案詳述 數(shù)據(jù)服務篇-數(shù)據(jù)服務選型 數(shù)據(jù)保障篇-數(shù)據(jù)時效監(jiān)控以及保障方案 效果篇-上述方案最終的效果 現(xiàn)狀以及展望篇
2.背景篇
根據(jù)微博目前站內詞條消費情況,計算 top 50 消費熱度詞條,每分鐘更新一次,并且按照列表展現(xiàn)給用戶。
3.定義篇-屬于哪類特點的指標
這類指標可以統(tǒng)一劃分到 topN 類別的指標中。即輸入是具體詞條消費日志,輸出是詞條消費排行榜。
4.數(shù)據(jù)應用篇-預期效果是怎樣的
預期效果如下。
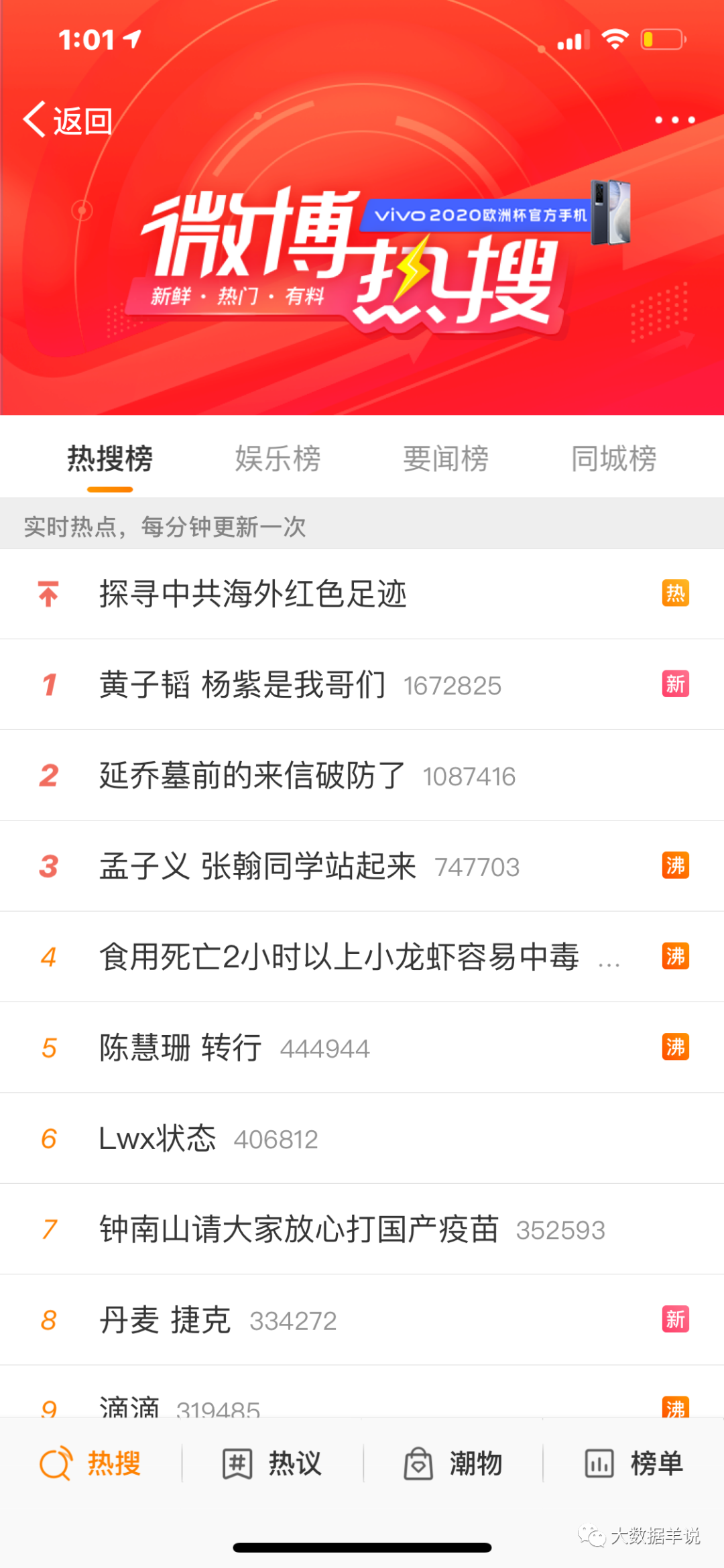
5.難點剖析篇-此類指標建設、保障的難點
5.1.數(shù)據(jù)建設
5.1.1.難點
榜單類的指標有一個特點,就是客戶端獲取到的數(shù)據(jù)必須是同一分鐘當時的詞條消費熱度,這就要求我們產出的每一條數(shù)據(jù)需要包含 topN 中的所有數(shù)據(jù)。這樣才能保障用戶獲取到的數(shù)據(jù)的一致性。 flink 任務大狀態(tài):詞條多,狀態(tài)大;詞條具有時效性,所以對于低熱詞條需要進行刪除 flink 任務大流量、高性能:數(shù)據(jù)源是全站的詞條消費流量,得扛得住突發(fā)流量的暴揍
5.1.2.業(yè)界方案調研
5.1.2.1.Flink DataStream api 實時計算 topN 熱榜
Flink DataStream api 實時計算topN熱榜[1]
優(yōu)點:可以按照用戶自定義邏輯計算排名,基于 watermark 推動整個任務的計算,具備數(shù)據(jù)可回溯性。 缺點:開發(fā)成本高,而本期主要介紹 flink sql 的方案,這個方案可以供大家進行參考。 「結論:雖可實現(xiàn),但并非 sql api 實現(xiàn)。」
5.1.2.2.Flink SQL api 實時計算 topN 熱榜
Flink SQL TopN語句[2]
Flink SQL 功能解密系列 —— 流式 TopN 挑戰(zhàn)與實現(xiàn)[3]
優(yōu)點:用戶理解、開發(fā)成本低 缺點:只有排名發(fā)生變化的詞條才會輸出,排名未發(fā)生變化數(shù)據(jù)不會輸出(后續(xù)會在「數(shù)據(jù)建設」模塊進行解釋),不能做到每一條數(shù)據(jù)包含目前 topN 的所有數(shù)據(jù)的需求。 「結論:不滿足需求。」
5.1.2.3.結論
我們需要制定自己的 flink sql 解決方案,以實現(xiàn)上述需求。這也是本節(jié)重點要講述的內容,即在「數(shù)據(jù)建設篇-具體實現(xiàn)方案詳述」詳細展開。
5.2.數(shù)據(jù)保障
5.2.1.難點
flink 任務高可用 榜單數(shù)據(jù)可回溯性
5.2.2.業(yè)界方案調研
flink 任務高可用:宕機之后快速恢復;有異地多活熱備鏈路可隨時切換 榜單數(shù)據(jù)可回溯性:任務失敗之后,按照詞條時間數(shù)據(jù)的進行回溯
5.3.數(shù)據(jù)服務保障
5.3.1.難點
數(shù)據(jù)服務引擎高可用 數(shù)據(jù)服務 server 高可用
5.3.2.業(yè)界方案調研
數(shù)據(jù)服務引擎高可用:數(shù)據(jù)服務引擎本身的高可用,異地雙活實現(xiàn) 數(shù)據(jù)服務 server 高可用:異地雙活實現(xiàn);上游不更新數(shù)據(jù),數(shù)據(jù)服務 server 模塊也能查詢出上一次的結果進行展示,至少不會什么數(shù)據(jù)都展示不了
6.數(shù)據(jù)建設篇-具體實現(xiàn)方案詳述
6.1.整體數(shù)據(jù)服務架構
首先,我們最初的方案是如下圖所示,單機房的服務端,但是很明顯基本沒有高可用保障。我們本文主要介紹 flink sql 方案,所以下文先介紹 flink sql,后文 6.6 介紹各種高可用、高性能優(yōu)化及保障。
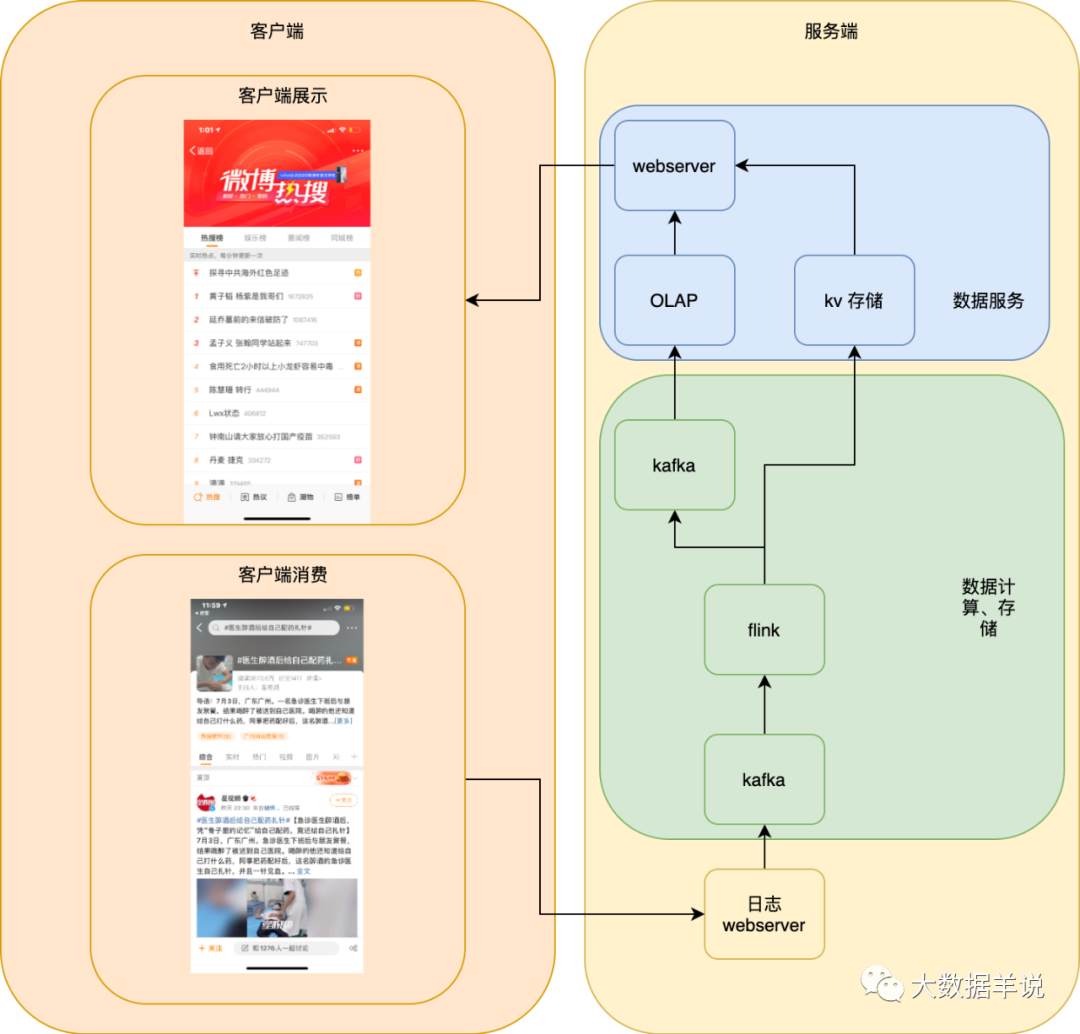
6.2.flink 方案設計
從本節(jié)開始,正式介紹 flink sql 相關的方案設計。
我們會從以下三個角度去介紹:
數(shù)據(jù)源:了解數(shù)據(jù)源的 schema 數(shù)據(jù)匯:從數(shù)據(jù)應用角度出發(fā)設計數(shù)據(jù)匯的 schema 數(shù)據(jù)建設:從數(shù)據(jù)源、數(shù)據(jù)匯從而推導出我們要實現(xiàn)的 flink sql 方案
6.3.數(shù)據(jù)源
數(shù)據(jù)源即安裝在各位的手機微博客戶端上報的用戶消費明細日志,即用戶消費一次某個詞條,就會上報一條對應的日志。
6.3.1.schema
| 字段名 | 備注 |
|---|---|
| user_id | 消費詞條的用戶 |
| 熱搜詞條_name | 消費詞條名稱 |
| timestamp | 消費詞條時間戳 |
| ... | ... |
6.4 數(shù)據(jù)匯
6.4.1.schema
最開始設計的 schema 如下:
| 字段名 | 字段類型 | 備注 |
|---|---|---|
| timestamp | bigint | 當前分鐘詞條時間戳 |
| 熱搜詞條_name | string | 詞條名 |
| rn | bigint | 排名 1 - 50 |
但是排名展示時,需要將這一分鐘的前 50 名的數(shù)據(jù)全部查詢到展示。而 flink 任務輸出排名數(shù)據(jù)到外部存儲時,保障前 50 名的詞條數(shù)據(jù)事務性的輸出(要么同時輸出到數(shù)據(jù)服務中,要么一條也不輸出)是一件比較復雜事情。所以我們索性將前 50 名的數(shù)據(jù)全部收集到同一條數(shù)據(jù)當中,時間戳最新的一條數(shù)據(jù)就是最新的結果數(shù)據(jù)。
重新設計的 schema 如下:
| 字段名 | 字段類型 | 備注 |
|---|---|---|
| timestamp | bigint | 當前分鐘詞條時間戳 |
| 熱搜榜單 | string | 熱搜榜單,schema 如 {"排名第一的詞條1" : "排名第一的詞條消費量", "排名第二的詞條1" : "排名第二的詞條消費量", "排名第三的詞條1" : "排名第三的詞條消費量"...} 前 50 名 |
6.5.數(shù)據(jù)建設
6.5.1.方案1 - 內層 rownum + 外層自定義 udf
從排名的角度出發(fā),自然可以想到 「rownum」 進行排名(阿里云也有對應的實現(xiàn)案例) 最終要把排行榜合并到一條數(shù)據(jù)進行輸出,那就必然會涉及到「自定義 udf」 將排名數(shù)據(jù)進行合并
6.5.1.1.sql
INSERT INTO
target_db.target_table
SELECT
max(timestamp) AS timestamp,
熱搜_top50_json(熱搜詞條_name, cnt) AS data -- 外層 udaf 將所有數(shù)據(jù)進行 merge
FROM
(
SELECT
熱搜詞條_name,
cnt,
timestamp,
row_number() over(
PARTITION by
熱搜詞條_name
ORDER BY
cnt ASC
) AS rn -- 內層 rownum 進行排名
FROM
(
SELECT
熱搜詞條_name,
count(1) AS cnt,
max(timestamp) AS timestamp
FROM
source_db.source_table
GROUP BY
熱搜詞條_name
-- 如果有熱點詞條導致數(shù)據(jù)傾斜,可以加一層打散層
)
)
WHERE
rn <= 100
GROUP BY
0;
6.5.1.2.udf
udaf 開發(fā)參考:https://www.alibabacloud.com/help/zh/doc-detail/69553.htm?spm=a2c63.o282931.b99.244.4ad11889wWZiHL
top50_udaf:作用是將已經經過上游處理的消費量排前 100 名詞條拿到進行排序后,合并成一個 top50 排行榜 json 字符串產出。
Accumulator:由需求可以知道,當前 udaf 是為了計算前 50 名的消費詞條,所以 Accumulator 應該存儲截止當前時間按照消費 cnt 數(shù)排名的前 100 名的詞條。我們由此就可以想到使用 「最小堆」 來當做 Accumulator,Accumulator 中只存儲消費 cnt 前 100 的數(shù)據(jù)。
最小堆的實現(xiàn):https://blog.csdn.net/jiutianhe/article/details/41441881
topN 設計偽代碼如下:
public class 熱搜_top50_json extends AggregateFunction<Map<String, Long>, TopN<Pair<String, Long>>> {
@Override
public TopN<Pair<String, Long>> createAccumulator() {
// 創(chuàng)建 acc -> 最小堆實現(xiàn)的 Top 50
}
@Override
public String getValue(TopN<Pair<String, Long>> acc) {
// 1.將最小堆 acc 中列表數(shù)據(jù)拿到
// 2.然后將列表按照從大到小進行排序
// 3.產出結果數(shù)據(jù)
}
public void accumulate(TopN<Pair<String, Long>> acc, String 詞條名稱, long cnt) {
// 1.獲取到當前最小堆中的最小值
// 如果當前詞條的消費量 cnt 小于最小堆的堆頂
// 則直接進行過濾
// 2.如果最小堆中不存在當前詞條
// 則直接將當前詞條放入最小堆中
// 3.如果最小堆中已經存在當前詞條存在
// 那么將最小堆中這個詞條的消費 cnt 與
// 當前詞條的 cnt 作比較,將大的那個放入最小堆中
}
public void retract(TopN<Pair<String, Long>> acc, String id, long cnt) {
// 不需要實現(xiàn) retract 方法
// 由于 topn 具有特殊性:即我們只取每一個詞條的最大值
// 進行排名,所以可以不需要實現(xiàn) retract 方法
// 比較排名都在 accumulate 方法中已經實現(xiàn)完成
}
}
?Notes:
?
上述 udf 最好設計成一個固定大小排行榜的 udf,比如一個 udf 實現(xiàn)類就只能用于處理一個固定大小的排行,防止用戶進行】、 誤用; sql 內層計算的排行榜大小一定要比 sql 外層(聚合)排行榜大小大。舉反例:假如內層計算前 30 名,外層計算前 50 名,內層 A 分桶第 31 名可能比 B 分桶第 1 名的值還大,但是 A 桶的第 31 名就不會被輸出。反之則正確。
6.5.1.3.flink-conf.yaml 參數(shù)配置
由于上述 sql 是在無限流上的操作,所以上游數(shù)據(jù)每更新一次都會向下游發(fā)送一次 retract 消息以及最新的數(shù)據(jù)的消息進行計算。
那么就會存在這樣一個問題,即 source qps 為 x 時,任務內的吞吐就為 x * n 倍,sink qps 也為 x,這會導致性能大幅下降的同時也會導致輸出結果數(shù)據(jù)量非常大。
而我們只需要每分鐘更新一次結果即可,所以可以使用 flink sql 自帶的 minibatch 參數(shù)來控制輸出結果的頻次。
minibatch 具體參考可參考下面兩篇文章:
https://www.alibabacloud.com/help/zh/doc-detail/182012.htm?spm=a2c63.p38356.b99.288.698a785cSiDhEG https://www.jianshu.com/p/aa2e94628e24
table.exec.mini-batch.enabled : true
-- minibatch 是下面兩個任意一個符合條件就會起觸發(fā)計算
-- 60s 一次
table.exec.mini-batch.allow-latency : 60 s
-- 數(shù)量達到 10000000000 觸發(fā)一次
-- 設置為 10000000000 是為了讓上面的 allow-latency 觸發(fā),每 60s 輸出一次來滿足我們的需求
table.exec.mini-batch.size : 10000000000
狀態(tài)過期,如果不設置的話,詞條狀態(tài)會越來越大,對非高熱詞條進行清除。
http://apache-flink.147419.n8.nabble.com/Flink-sql-state-ttl-td10158.html
-- 設置 1 天的 ttl,如果一天過后
-- 這個詞條還沒有更新,則直接刪除
table.exec.state.ttl : 86400 s
6.5.2.方案2 - 自定義 udf
「自定義排名 udf」
6.5.2.1.sql
INSERT INTO target_db.target_table
SELECT
max(timestamp) AS timestamp,
-- udf 計算每一個分桶的前 100 名列表
熱搜_top50_json(cast(熱搜詞條_name AS string), cnt) AS bucket_top100
FROM
(
SELECT
熱搜詞條_name AS 熱搜詞條_name,
count(1) AS cnt,
max(timestamp) AS timestamp
FROM
source_db.source_table
GROUP BY
熱搜詞條_name
-- 如果有熱點詞條導致數(shù)據(jù)傾斜
-- 可以加一層打散層
)
GROUP BY
0
-- 由于這里是 group by 0
-- 所以可能會到導致熱點,所以如果需要也可以加一層打散層
-- 在內部先算 top50,在外層將內部分桶的 top50 榜單進行 merge
6.5.2.2.udf
此 udf 與 方案1 的 udf(見 6.5.1.2.udf) 完全相同。
6.5.2.3.flink-conf.yaml 參數(shù)配置
參數(shù)同 6.5.1.3 flink-conf.yaml 參數(shù)配置
6.6.高可用、高性能
6.6.1.整體高可用保障
異地雙鏈路熱備如下圖:
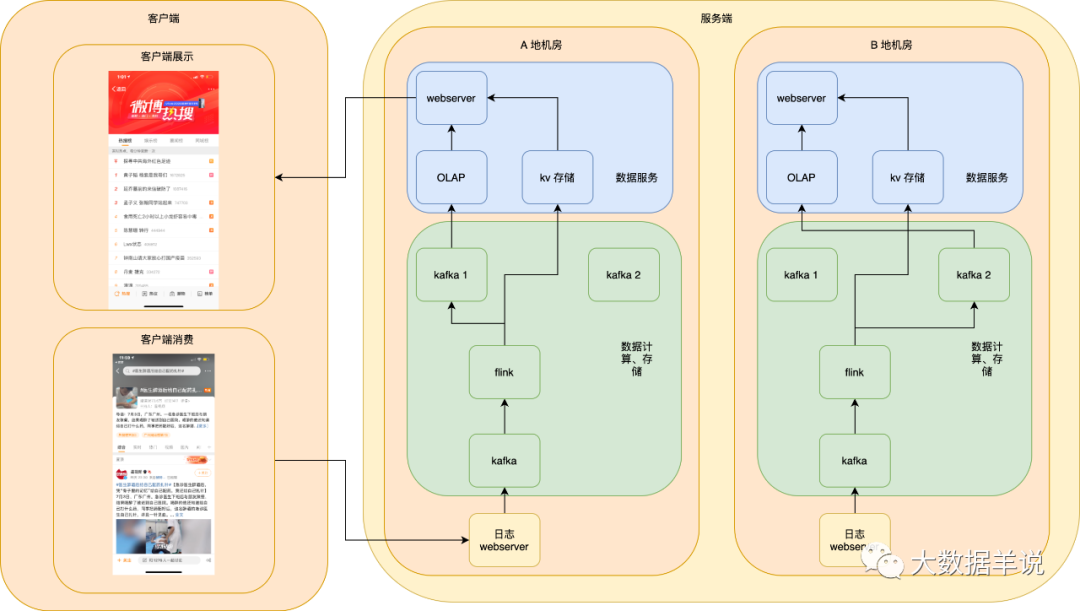
可能會發(fā)現(xiàn)圖中有異地機房,但是我們目前只畫出了 A 地區(qū)機房的數(shù)據(jù)鏈路,B 地區(qū)機房還沒有畫全,接著我們一步一步將這個圖進行補全。
?「Notes:」
「異地雙機房只是雙鏈路的熱備的一種案例。如果有同城雙機房、雙集群也可進行同樣的服務部署。」
「為什么說異地機房的保障能力 > 同城異地機房 > 同城同機房雙集群容災能力?」
「同城同機房:只要這個機房掛了,即使你有兩套鏈路也沒救。」「同城異地機房:很小幾率情況會同城異地兩個機房都掛了。。」「異地機房:幾乎不可能同時異地兩個機房都被炸了。。。」
?
6.6.1.1.數(shù)據(jù)源日志高可用
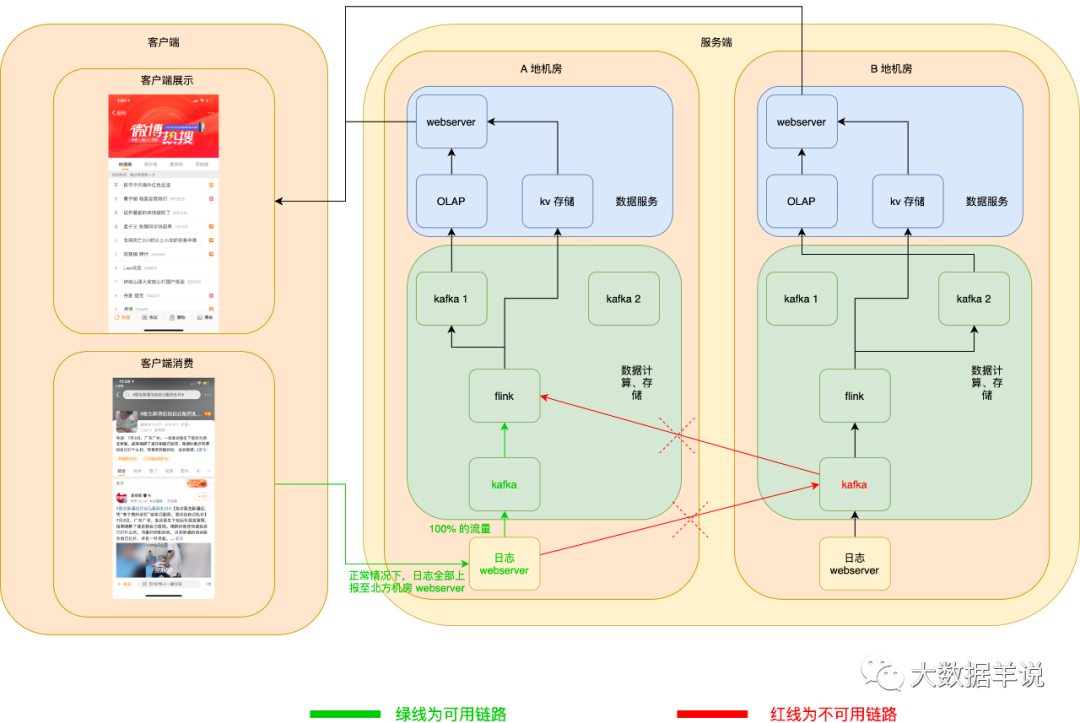
數(shù)據(jù)源日志 server 服務高可用:異地機房,當一個機房掛了之后,在客戶端可以自動將日志發(fā)送到另一個機房的 webserver 數(shù)據(jù)源日志 kafka 服務高可用:kafka 使用異地機房 topic,其實就是兩個 topic,每個機房一個 topic,兩個 topic 互為熱備,producer 在向下游兩個機房的 topic 寫數(shù)據(jù)時,可以將 50% 的流量寫入一個機房,另外 50% 的流量寫入另一個機房,一旦一個機房的 kafka 集群宕機,則 producer 端可以自動將 100% 的流量切換到另一個機房的 kafka。
正常情況下如圖所示:
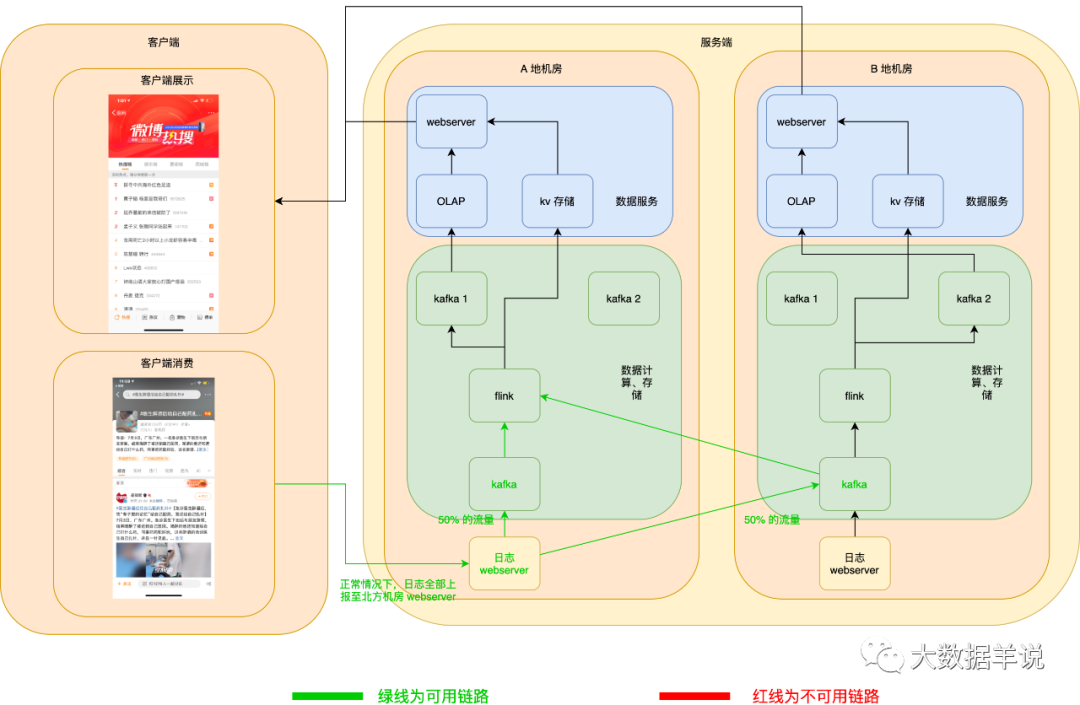
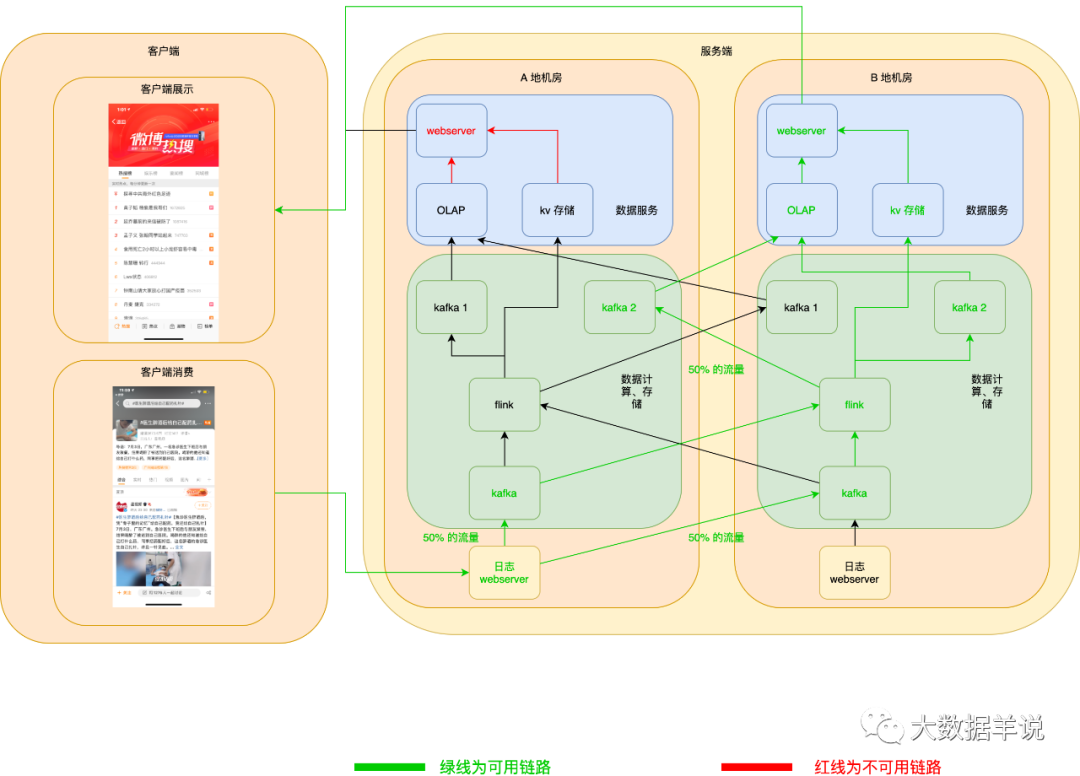
當發(fā)生 A 地機房 webserver 宕機時,客戶端自動切換上報日志至 B 地機房 webserver。如下圖所示:
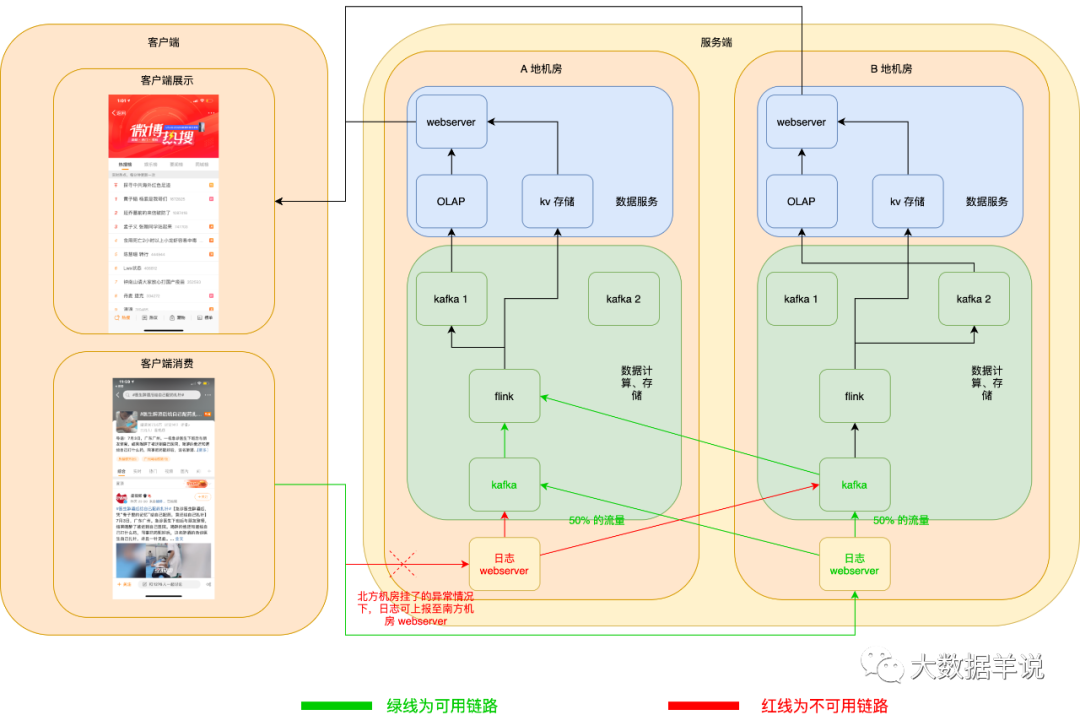
kafka 也相同。如下圖所示:
6.6.1.2.flink 任務高可用
flink 任務以 A 地機房做主鏈路,B 地機房啟動相同的任務做熱備雙跑鏈路。
當 A 地機房 flink 任務宕機且無法恢復時,則 B 地機房的任務做熱備替換。
正常情況下如圖所示:
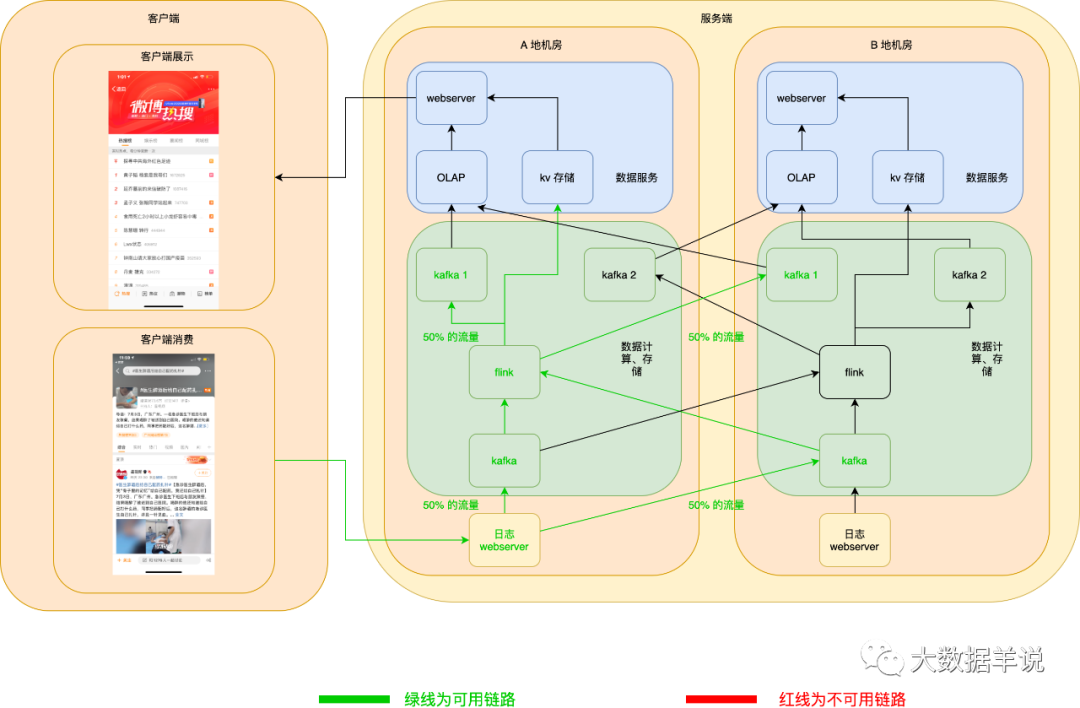
當 A 地機房 flink 任務宕機且無法恢復時,熱備鏈路 flink 任務就可以頂上。如下圖所示:

6.6.1.3.數(shù)據(jù)服務高可用
正常情況如下:
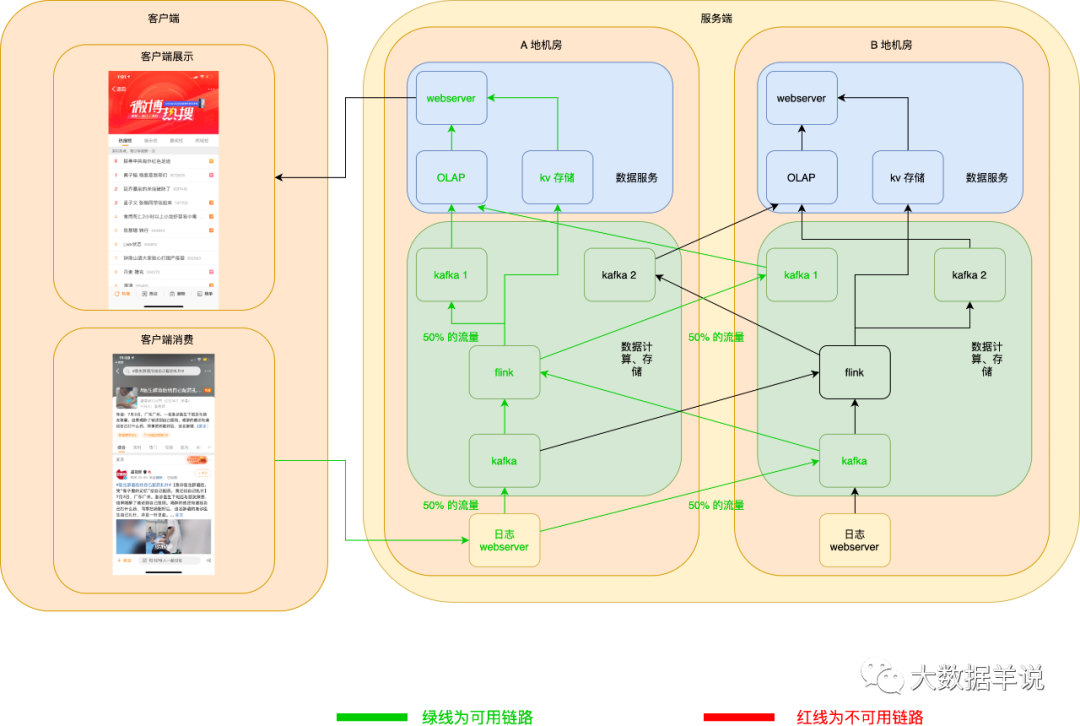
當 A 地 OLAP 或者 KV 存儲掛了之后,webserver 可以自動切換至 B 地 OLAP 或者 KV 存儲。如下圖所示:
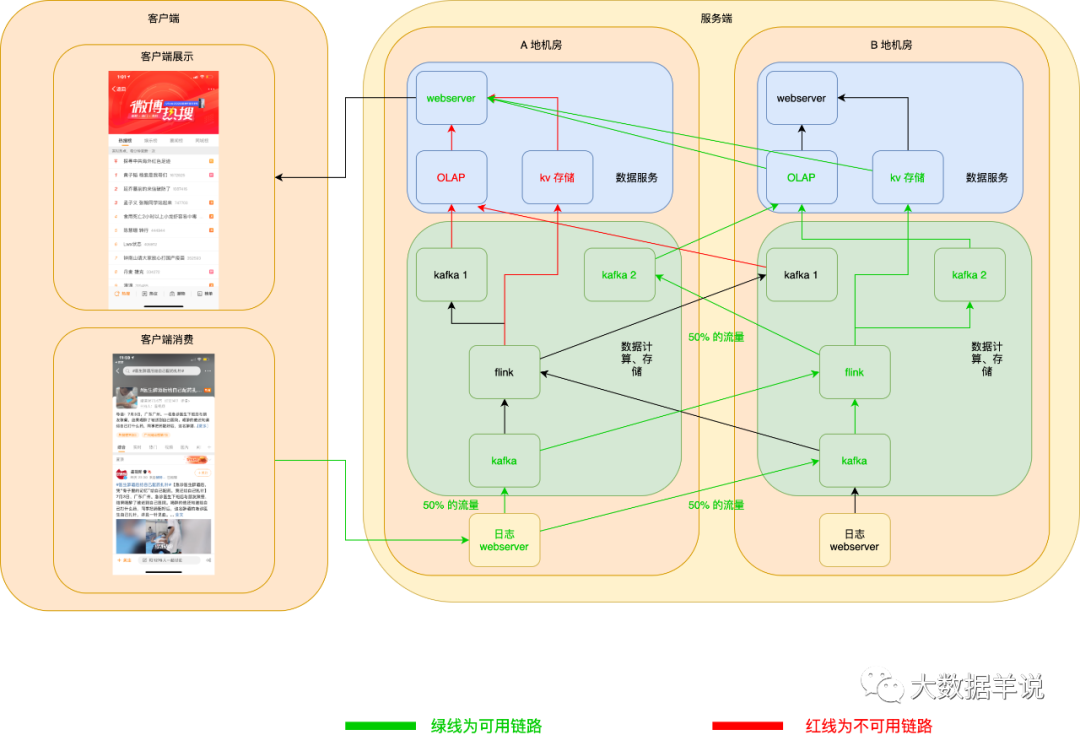
當 A 地 webserver 掛了之后,客戶端可以自動拉取 B 地 webserver 數(shù)據(jù),如下圖所示:
6.6.2.大流量、高性能
6.6.2.1.數(shù)據(jù)源
數(shù)據(jù)源、匯反序列化性能提升:靜態(tài)反序列化性能 > 動態(tài)反序列化性能。舉例 ProtoBuf。可以在 source 端先進行代碼生成,然后用生成好的代碼去反序列化源消息的性能會遠好于使用 ProtoBuf Dynamic Message。flink 官方實現(xiàn)[4]
6.6.3.縮減狀態(tài)大小
將狀態(tài)中的 string 長度做映射之后變小 如果要計算 uv,可以將 string 類的 id 轉換為 long 類型 rocksdb 增量 checkpoint,減小任務做 checkpoint 的壓力
7.數(shù)據(jù)服務篇-數(shù)據(jù)服務選型
7.1.kv 存儲
根據(jù)我們上述設計的數(shù)據(jù)匯 schema 來看,最適合存儲引擎就是 kv 引擎,因為前端只需要展示最新的排行榜數(shù)據(jù)即可。所以我們可以使用 redis 等 kv 存儲引擎來存儲最新的數(shù)據(jù)。
7.2.OLAP
如果用戶有需求需要記錄上述數(shù)據(jù)的歷史記錄,我們也可以使用時序數(shù)據(jù)庫或者 OLAP 引擎直接進行存儲。
8.數(shù)據(jù)保障篇-數(shù)據(jù)時效監(jiān)控以及保障方案
8.1.數(shù)據(jù)時效保障
見下文。

8.2.數(shù)據(jù)質量保障
數(shù)據(jù)質量保障篇樓主正在 gang...
9.效果篇-上述方案最終的效果
9.1.輸出結果示例
{
"黃子韜 楊紫是我哥們": 1672825,
"延喬墓前的來信破防了": 1087416,
"孟子義 張翰同學站起來": 747703
// ...
}
9.2.應用產品示例
10.現(xiàn)狀以及展望篇
雖然上述 udf 是通用的 udf,但是是否能夠脫離自定義 udf,直接計算出 top 50 的值?
我目前的一個想法就是將結果 schema 拍平。舉例:
| 字段名 | 字段類型 | 備注 |
|---|---|---|
| timestamp | bigint | 當前分鐘事件時間戳 |
| 熱搜詞條_1 | string | 第一名的熱搜詞條名稱 |
| 熱搜詞條_2 | string | 第二名的熱搜詞條名稱 |
| 熱搜詞條_3 | string | 第三名的熱搜詞條名稱 |
| 熱搜詞條_4 | string | 第四名的熱搜詞條名稱 |
| 熱搜詞條_5 | string | 第五名的熱搜詞條名稱 |
| ... | ... | ... |
| 熱搜詞條_n | string | 第 n 名的詞條名稱 |
每一次輸出都將目前每一個排名的數(shù)據(jù)產出。但是目前在 flink sql 的實現(xiàn)思路上不太明了。