
Flink 實時計算在微博的應(yīng)用
微博介紹
數(shù)據(jù)計算平臺介紹
Flink 在數(shù)據(jù)計算平臺的典型應(yīng)用
 GitHub 地址
GitHub 地址 一、微博介紹

二、數(shù)據(jù)計算平臺介紹
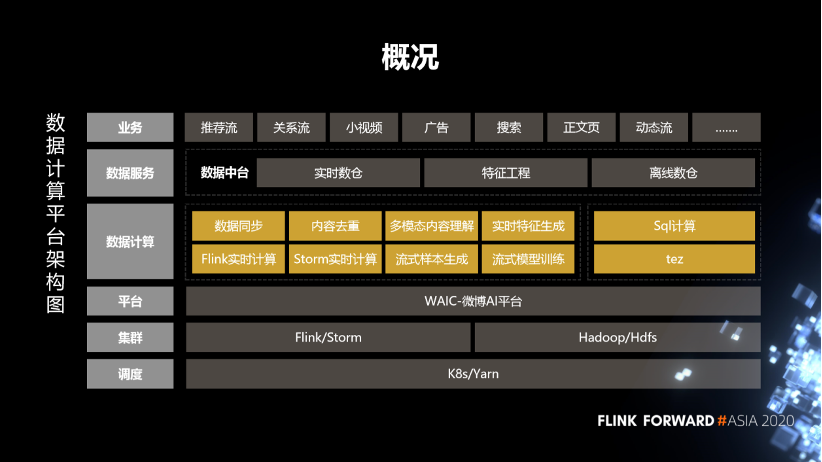
1. 數(shù)據(jù)計算平臺概況
首先是調(diào)度,這塊基于 K8s 和 Yarn 分別部署了實時數(shù)據(jù)處理的 Flink、Storm,以及用于離線處理的 SQL 服務(wù)。
在集群之上,我們部署了微博的 AI 平臺,通過這個平臺去對作業(yè)、數(shù)據(jù)、資源、樣本等進行管理。
在平臺之上我們構(gòu)建了一些服務(wù),通過服務(wù)化的方式去支持各個業(yè)務(wù)方。
實時計算這邊的服務(wù)主要包括數(shù)據(jù)同步、內(nèi)容去重、多模態(tài)內(nèi)容理解、實時特征生成、實時樣本拼接、流式模型訓(xùn)練,這些是跟業(yè)務(wù)關(guān)系比較緊密的服務(wù)。另外,還支持 Flink 實時計算和 Storm 實時計算,這些是比較通用的基礎(chǔ)計算框架。 離線這部分,結(jié)合 Hive 的 SQL,SparkSQL 構(gòu)建一個 SQL 計算服務(wù),目前已經(jīng)支持了微博內(nèi)部絕大多數(shù)的業(yè)務(wù)方。
數(shù)據(jù)的輸出是采用數(shù)倉、特征工程這些數(shù)據(jù)中臺的組建,對外提供數(shù)據(jù)輸出。整體上來說,目前我們在線跑的實時計算的作業(yè)將近 1000 多個,離線作業(yè)超過了 5000 多個,每天處理的數(shù)據(jù)量超過了 3 PB。
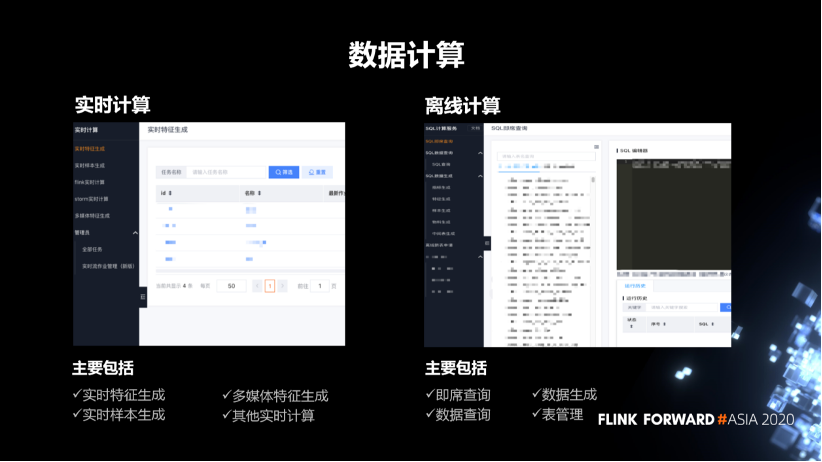
2. 數(shù)據(jù)計算
實時計算主要包括實時的特征生成,多媒體特征生成和實時樣本生成,這些跟業(yè)務(wù)關(guān)系比較緊密。另外,也提供一些基礎(chǔ)的 flink 實時計算和 storm 實時計算。
離線計算主要包括 SQL 計算。主要包括 SQL 的即席查詢、數(shù)據(jù)生成、數(shù)據(jù)查詢和表管理。表管理主要就是數(shù)倉的管理,包括表的元數(shù)據(jù)的管理,表的使用權(quán)限,還有表的上下游的血緣關(guān)系。
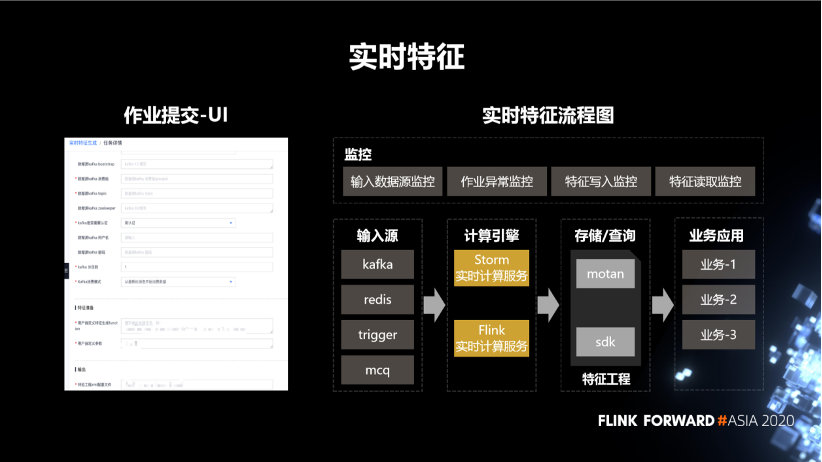
3. 實時特征
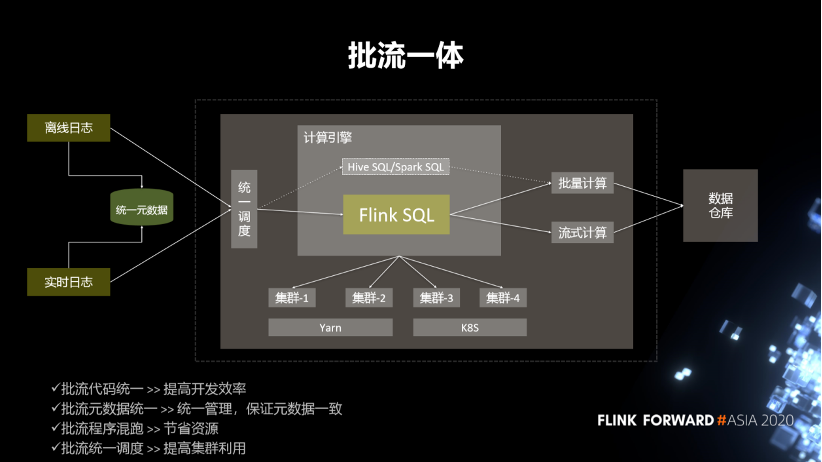
4. 流批一體
第一,批流代碼統(tǒng)一,提高開發(fā)效率。
第二,批流元數(shù)據(jù)統(tǒng)一。統(tǒng)一管理,保證元數(shù)據(jù)一致。
第三,批流程序混跑,節(jié)省資源。
第四,批流統(tǒng)一調(diào)度,提高集群利用率。
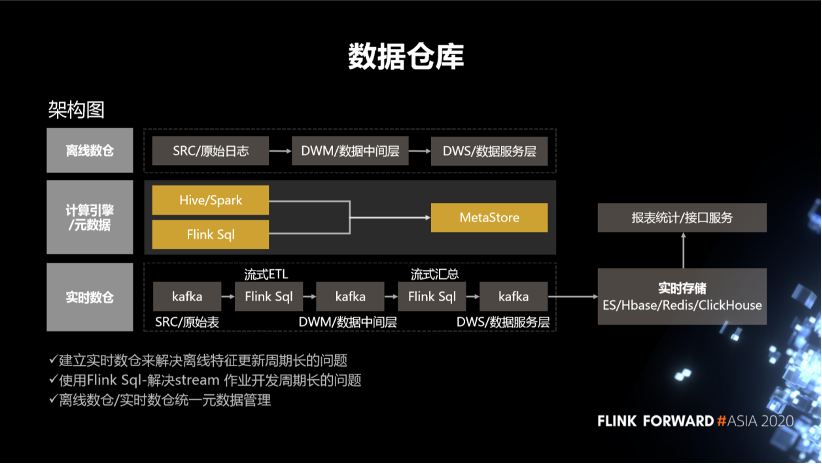
5. 數(shù)據(jù)倉庫
針對離線倉庫,我們把數(shù)據(jù)分成了三層,一個是原始日志,另外一個是中間層,還有一個是數(shù)據(jù)服務(wù)層。中間是元數(shù)據(jù)的統(tǒng)一,下邊是實時數(shù)倉。
針對實時數(shù)倉,我們通過 FlinkSQL 對這些原始日志做流式的一個 ETL,再通過一個流式匯總將最終的數(shù)據(jù)結(jié)果寫到數(shù)據(jù)的服務(wù)層,同時也會把它存儲到各種實時存儲,比如 ES、Hbase、Redis、ClickHouse 中去。我們可以通過實時存儲對外提供數(shù)據(jù)的查詢。還提供數(shù)據(jù)進一步數(shù)據(jù)計算的能力。也就是說,建立實時數(shù)倉主要是去解決離線特征生成的周期長的問題。另外就是使用 FlinkSQL 去解決 streaming 作業(yè)開發(fā)周期比較長的問題。其中的一個關(guān)鍵點還是離線數(shù)倉跟實時數(shù)倉的元數(shù)據(jù)的管理。
三、Flink 在數(shù)據(jù)計算平臺的典型應(yīng)用
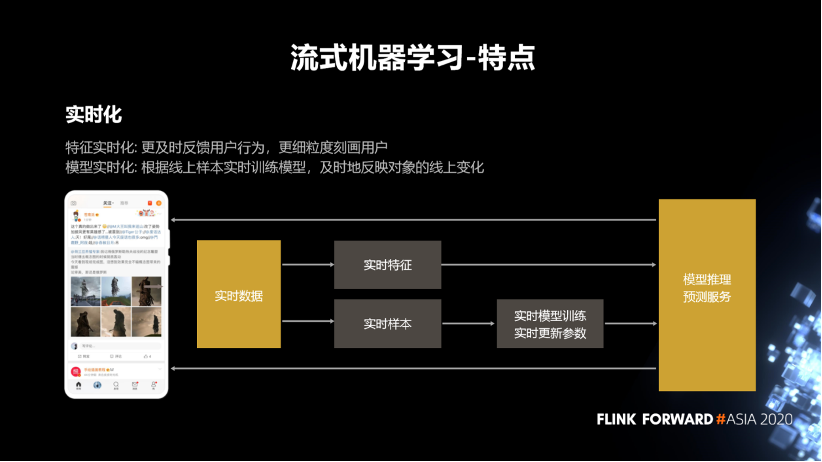
1. 流式機器學(xué)習(xí)
特征實時化主要是為了更及時的去反饋用戶行為,更細(xì)粒度的去刻畫用戶。
模型實時化是要根據(jù)線上樣本實時訓(xùn)練模型,及時反映對象的線上變化情況。
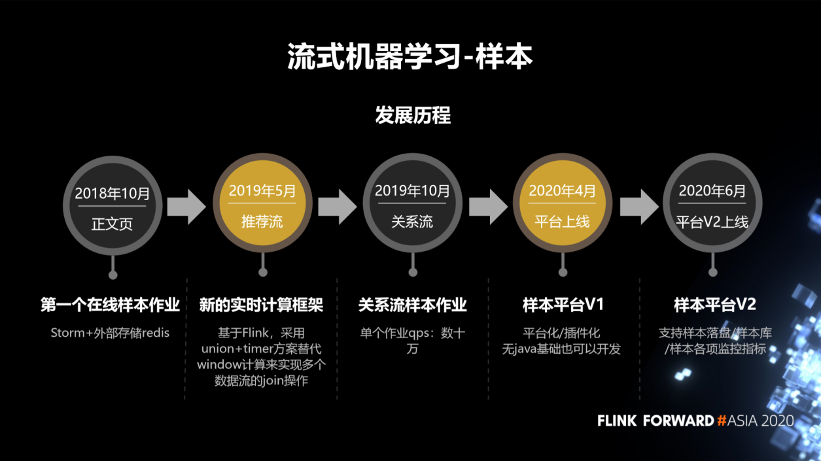
樣本的規(guī)模大,目前的實時樣本能達(dá)到百萬級別的 qps。
模型的規(guī)模大。模型訓(xùn)練參數(shù)這塊,整個框架會支持千億級別的訓(xùn)練規(guī)模。
對作業(yè)的穩(wěn)定性要求比較高。
樣本的實時性要求高。
模型的實時性高。
平臺業(yè)務(wù)需求多。
一個就是全鏈路,端到端的鏈路是比較長的。比如說,一個流式機器學(xué)習(xí)的流程會從日志收集開始,到特征生成,再到樣本生成,然后到模型訓(xùn)練,最終到服務(wù)上線,整個流程非常長。任何一個環(huán)節(jié)有問題,都會影響到最終的用戶體驗。所以我們針對每一個環(huán)節(jié)都部署了一套比較完善的全鏈路的監(jiān)控系統(tǒng),并且有比較豐富的監(jiān)控指標(biāo)。
另外一個是它的數(shù)據(jù)規(guī)模大,包括海量的用戶日志,樣本規(guī)模和模型規(guī)模。我們調(diào)研了常用的實時計算框架,最終選擇了 Flink 去解決這個問題。

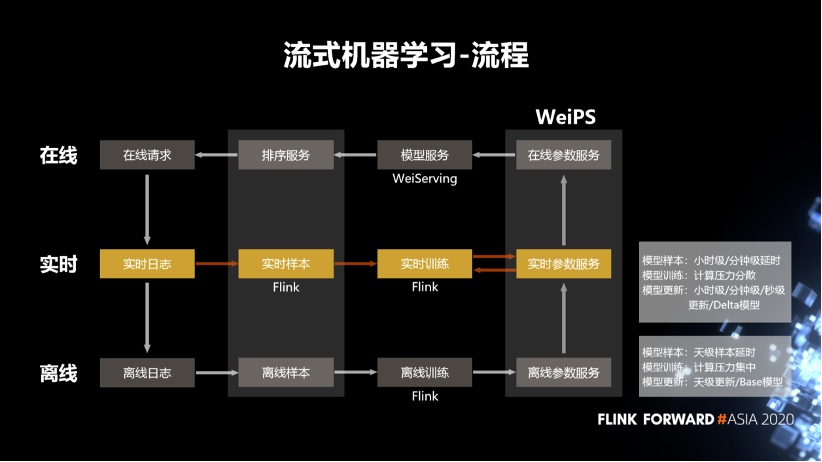
首先是離線訓(xùn)練,我們拿到離線日志,去離線的生成樣本之后,通過Flink去讀取樣本,然后去做離線訓(xùn)練。訓(xùn)練完成之后把這些訓(xùn)練的結(jié)果參數(shù)保存在離線的參數(shù)服務(wù)器中。這個結(jié)果會作為模型服務(wù)的 Base 模型,用于實時的冷啟動。
然后是實時的流式機器學(xué)習(xí)的流程。我們會去拉取實時的日志,比如說微博的發(fā)布內(nèi)容,互動日志等。拉取這些日志之后,使用 Flink 去生成它的樣本,然后做實時的訓(xùn)練。訓(xùn)練完成之后會把訓(xùn)練的參數(shù)保存在一個實時的參數(shù)服務(wù)器中,然后會定期的從實時的參數(shù)服務(wù)器同步到實時的參數(shù)服務(wù)器中。
最后是模型服務(wù)這一塊,它會從參數(shù)服務(wù)中拉取到模型對應(yīng)的那些參數(shù),去推薦用戶特征,或者說物料的特征。通過模型對用戶和物料相關(guān)的特征、行為打分,然后排序服務(wù)會調(diào)取打分的結(jié)果,加上一些推薦的策略,去選出它認(rèn)為最適合用戶的這一條物料,并反饋給用戶。用戶在客戶端產(chǎn)生一些互動行為之后,又發(fā)出新的在線請求,產(chǎn)生新的日志。所以整個流式學(xué)習(xí)的流程是一個閉環(huán)的流程。
離線的樣本的延時和模型的更新是天級或者小時級,而流式則達(dá)到了小時級或者分鐘級;
離線模型訓(xùn)練的計算壓力是比較集中的,而實時的計算壓力比較分散。
如果 k1 不存在,則注冊 timer,再存到 state 中。
如果 k1 存在,就從 state 中把它給拿出來,更新之后再存進去。到最后它的 timer 到期之后,就會將這條數(shù)據(jù)輸出,并且從 state 中清除掉。
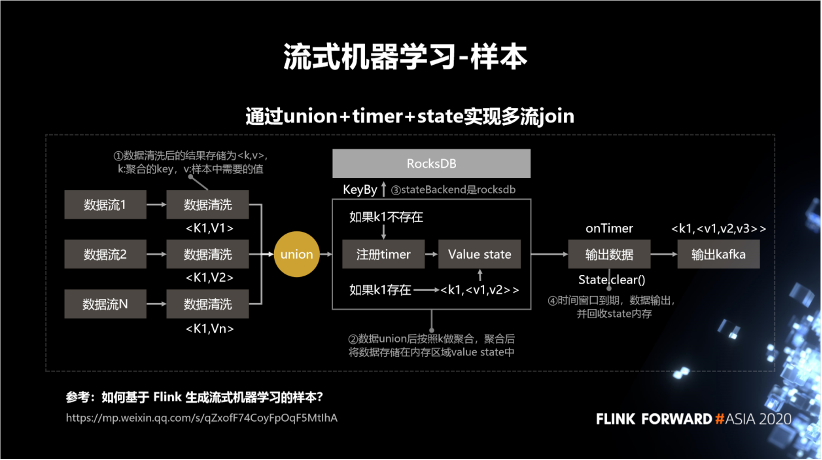
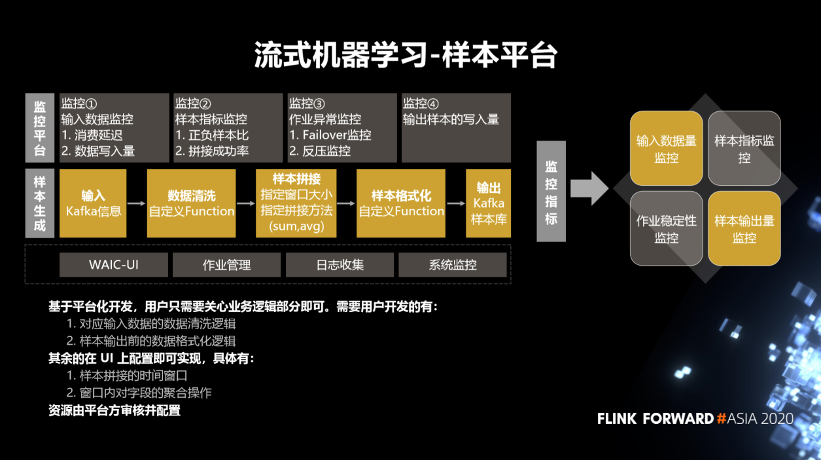
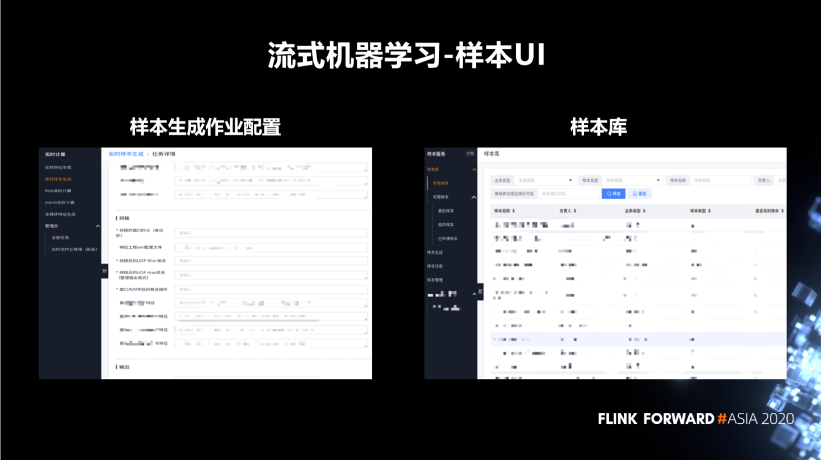
對應(yīng)輸入數(shù)據(jù)的數(shù)據(jù)清洗邏輯。
樣本輸出前的數(shù)據(jù)格式化邏輯。
樣本拼接的時間窗口。
窗口內(nèi)對字段的聚合操作。

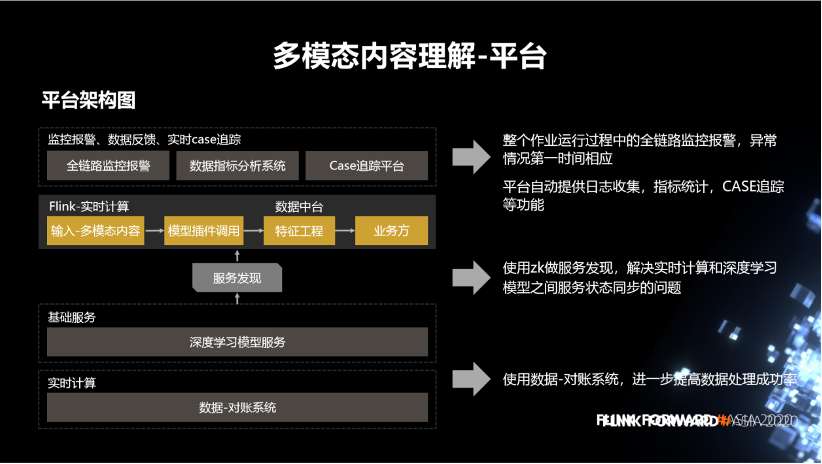
2. 多模態(tài)內(nèi)容理解
圖片這塊包括,物體識別打標(biāo)簽、OCR、人臉、明星、顏值、智能裁剪。
視頻這塊包括版權(quán)檢測、logo 識別。
音頻這塊有,語音轉(zhuǎn)文本、音頻的標(biāo)簽。
文本主要包括文本的分詞、文本的時效性、文本的分類標(biāo)簽。


3. 內(nèi)容去重服務(wù)

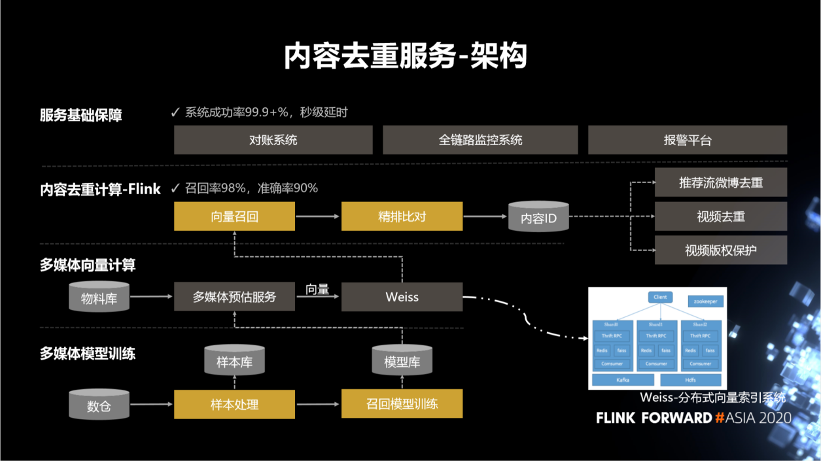
第一,支持視頻版權(quán) - 盜版視頻識別 - 穩(wěn)定性 99.99%,盜版識別率 99.99%。
第二,支持全站微博視頻去重 - 推薦場景應(yīng)用 - 穩(wěn)定性 99.99%,處理延遲秒級。
第三,推薦流物料去重 - 穩(wěn)定性 99%,處理延遲秒級,準(zhǔn)確率達(dá)到 90%

評論
圖片
表情