
硬核Redis總結(jié),看這篇就夠了!
高清思維導(dǎo)圖已同步Git:https://github.com/SoWhat1412/xmindfile
1、基本類型及底層實(shí)現(xiàn)
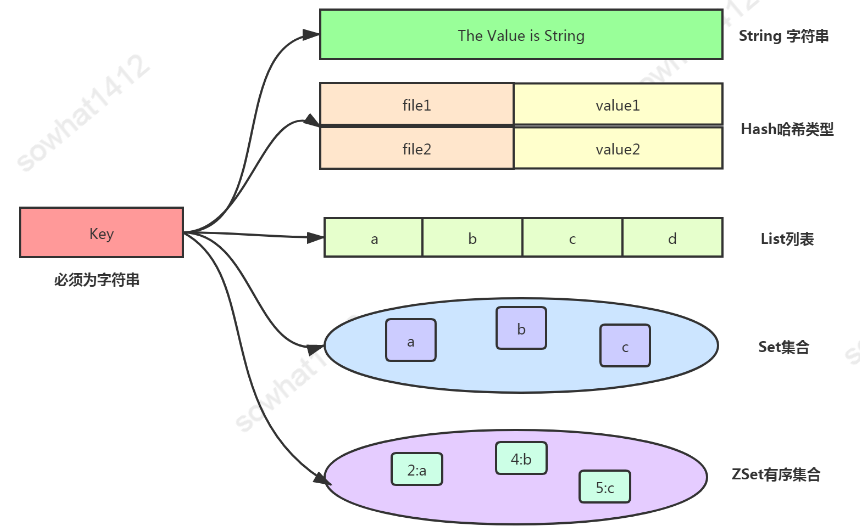
1.1、String
用途:
適用于簡(jiǎn)單key-value存儲(chǔ)、setnx key value實(shí)現(xiàn)分布式鎖、計(jì)數(shù)器(原子性)、分布式全局唯一ID。
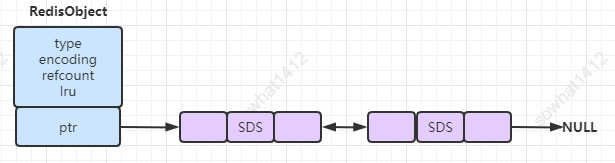
底層:C語言中String用char[]數(shù)組表示,源碼中用SDS(simple dynamic string)封裝char[],這是是Redis存儲(chǔ)的最小單元,一個(gè)SDS最大可以存儲(chǔ)512M信息。
struct?sdshdr{
??unsigned?int?len;?//?標(biāo)記char[]的長(zhǎng)度
??unsigned?int?free;?//標(biāo)記char[]中未使用的元素個(gè)數(shù)
??char?buf[];?//?存放元素的坑
}
Redis對(duì)SDS再次封裝生成了RedisObject,核心有兩個(gè)作用:
說明是5種類型哪一種。 里面有指針用來指向 SDS。
當(dāng)你執(zhí)行set name sowhat的時(shí)候,其實(shí)Redis會(huì)創(chuàng)建兩個(gè)RedisObject對(duì)象,鍵的RedisObject 和 值的RedisOjbect 其中它們type = REDIS_STRING,而SDS分別存儲(chǔ)的就是 name 跟 sowhat 字符串咯。
并且Redis底層對(duì)SDS有如下優(yōu)化:
SDS修改后大小 > 1M時(shí) 系統(tǒng)會(huì)多分配空間來進(jìn)行 空間預(yù)分配。SDS是 惰性釋放空間的,你free了空間,可是系統(tǒng)把數(shù)據(jù)記錄下來下次想用時(shí)候可直接使用。不用新申請(qǐng)空間。
1.2、List
 查看源碼底層
查看源碼底層 adlist.h 會(huì)發(fā)現(xiàn)底層就是個(gè) 雙端鏈表,該鏈表最大長(zhǎng)度為2^32-1。常用就這幾個(gè)組合。
lpush + lpop = stack 先進(jìn)后出的棧?
lpush + rpop = queue 先進(jìn)先出的隊(duì)列?
lpush + ltrim = capped collection 有限集合
lpush + brpop = message queue 消息隊(duì)列
一般可以用來做簡(jiǎn)單的消息隊(duì)列,并且當(dāng)數(shù)據(jù)量小的時(shí)候可能用到獨(dú)有的壓縮列表來提升性能。當(dāng)然專業(yè)點(diǎn)還是要 RabbitMQ、ActiveMQ等
1.3、Hash
散列非常適用于將一些相關(guān)的數(shù)據(jù)存儲(chǔ)在一起,比如用戶的購物車。該類型在日常用途還是挺多的。
這里需要明確一點(diǎn):Redis中只有一個(gè)K,一個(gè)V。其中 K 絕對(duì)是字符串對(duì)象,而 V 可以是String、List、Hash、Set、ZSet任意一種。
hash的底層主要是采用字典dict的結(jié)構(gòu),整體呈現(xiàn)層層封裝。從小到大如下:
1.3.1、dictEntry
真正的數(shù)據(jù)節(jié)點(diǎn),包括key、value 和 next 節(jié)點(diǎn)。

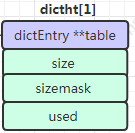
1.3.2、dictht
1、數(shù)據(jù) dictEntry 類型的數(shù)組,每個(gè)數(shù)組的item可能都指向一個(gè)鏈表。
2、數(shù)組長(zhǎng)度 size。
3、sizemask 等于 size - 1。
4、當(dāng)前 dictEntry 數(shù)組中包含總共多少節(jié)點(diǎn)。
1.3.3、dict
1、dictType 類型,包括一些自定義函數(shù),這些函數(shù)使得key和value能夠存儲(chǔ)
2、rehashidx 其實(shí)是一個(gè)標(biāo)志量,如果為
-1說明當(dāng)前沒有擴(kuò)容,如果不為 -1則記錄擴(kuò)容位置。3、dictht數(shù)組,兩個(gè)Hash表。
4、iterators 記錄了當(dāng)前字典正在進(jìn)行中的迭代器
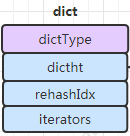
組合后結(jié)構(gòu)就是如下:
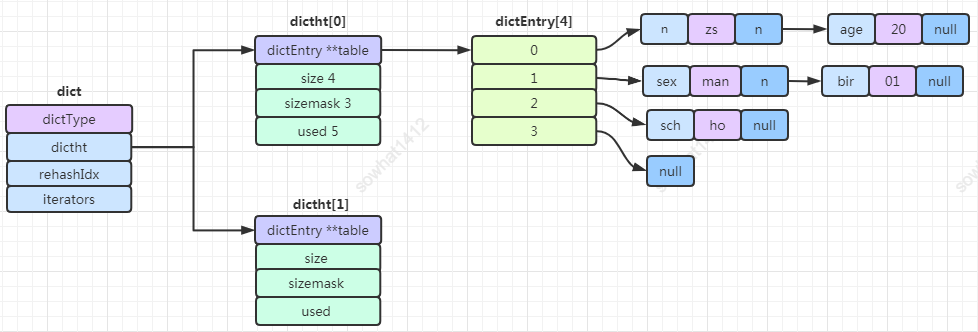
1.3.4、漸進(jìn)式擴(kuò)容
為什么 dictht ht[2]是兩個(gè)呢?目的是在擴(kuò)容的同時(shí)不影響前端的CURD,慢慢的把數(shù)據(jù)從ht[0]轉(zhuǎn)移到ht[1]中,同時(shí)rehashindex來記錄轉(zhuǎn)移的情況,當(dāng)全部轉(zhuǎn)移完成,將ht[1]改成ht[0]使用。
rehashidx = -1說明當(dāng)前沒有擴(kuò)容,rehashidx != -1則表示擴(kuò)容到數(shù)組中的第幾個(gè)了。
擴(kuò)容之后的數(shù)組大小為大于used*2的2的n次方的最小值,跟 HashMap 類似。然后挨個(gè)遍歷數(shù)組同時(shí)調(diào)整rehashidx的值,對(duì)每個(gè)dictEntry[i] 再挨個(gè)遍歷鏈表將數(shù)據(jù) Hash 后重新映射到 dictht[1]里面。并且 dictht[0].use 跟 dictht[1].use 是動(dòng)態(tài)變化的。
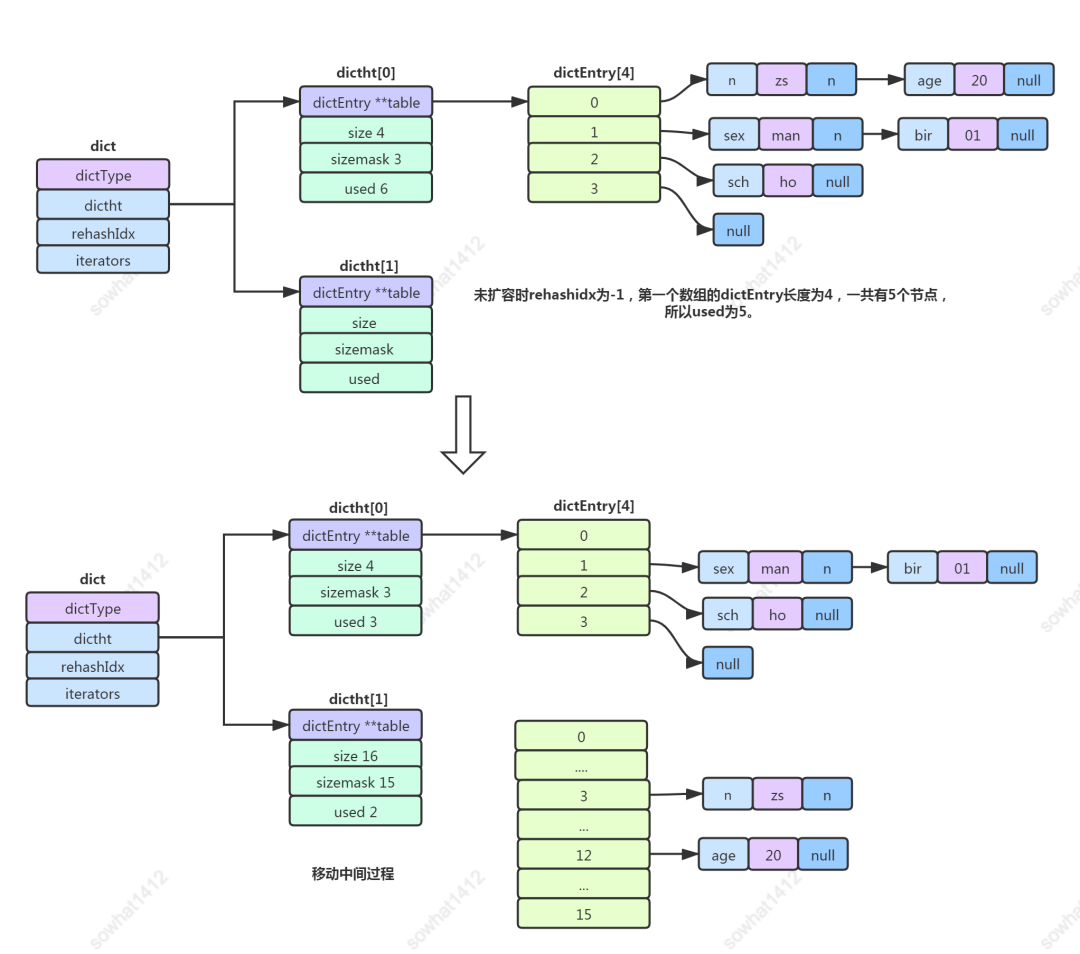 整個(gè)過程的重點(diǎn)在于
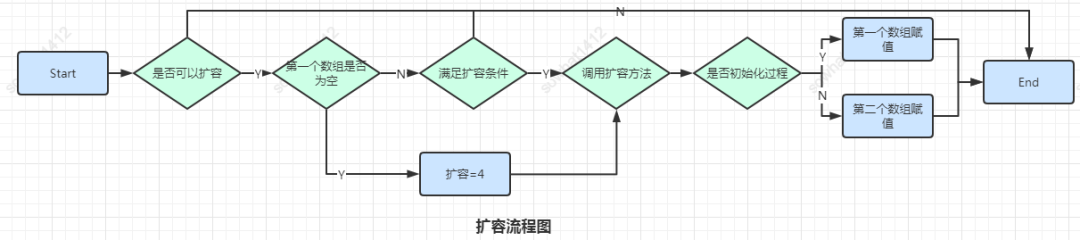
整個(gè)過程的重點(diǎn)在于rehashidx,其為第一個(gè)數(shù)組正在移動(dòng)的下標(biāo)位置,如果當(dāng)前內(nèi)存不夠,或者操作系統(tǒng)繁忙,擴(kuò)容的過程可以隨時(shí)停止。
停止之后如果對(duì)該對(duì)象進(jìn)行操作,那是什么樣子的呢?
1、如果是新增,則直接新增后第二個(gè)數(shù)組,因?yàn)槿绻略龅降谝粋€(gè)數(shù)組,以后還是要移過來,沒必要浪費(fèi)時(shí)間
2、如果是刪除,更新,查詢,則先查找第一個(gè)數(shù)組,如果沒找到,則再查詢第二個(gè)數(shù)組。
1.4、Set
如果你明白Java中HashSet是HashMap的簡(jiǎn)化版那么這個(gè)Set應(yīng)該也理解了。都是一樣的套路而已。這里你可以認(rèn)為是沒有Value的Dict。看源碼 t.set.c 就可以了解本質(zhì)了。
int?setTypeAdd(robj?*subject,?robj?*value)?{
????long?long?llval;
????if?(subject->encoding?==?REDIS_ENCODING_HT)?{
?????????//?看到底層調(diào)用的還是dictAdd,只不過第三個(gè)參數(shù)=?NULL
?????????if?(dictAdd(subject->ptr,value,NULL)?==?DICT_OK)?{
????????????incrRefCount(value);
????????????return?1;
????????}
????????....
1.5、ZSet
范圍查找 的天敵就是 有序集合,看底層 redis.h 后就會(huì)發(fā)現(xiàn) Zset用的就是可以跟二叉樹媲美的跳躍表來實(shí)現(xiàn)有序。跳表就是多層鏈表的結(jié)合體,跳表分為許多層(level),每一層都可以看作是數(shù)據(jù)的索引,這些索引的意義就是加快跳表查找數(shù)據(jù)速度。
每一層的數(shù)據(jù)都是有序的,上一層數(shù)據(jù)是下一層數(shù)據(jù)的子集,并且第一層(level 1)包含了全部的數(shù)據(jù);層次越高,跳躍性越大,包含的數(shù)據(jù)越少。并且隨便插入一個(gè)數(shù)據(jù)該數(shù)據(jù)是否會(huì)是跳表索引完全隨機(jī)的跟玩骰子一樣。
跳表包含一個(gè)表頭,它查找數(shù)據(jù)時(shí),是從上往下,從左往右進(jìn)行查找。現(xiàn)在找出值為37的節(jié)點(diǎn)為例,來對(duì)比說明跳表和普遍的鏈表。
沒有跳表查詢 比如我查詢數(shù)據(jù)37,如果沒有上面的索引時(shí)候路線如下圖: 
有跳表查詢 有跳表查詢37的時(shí)候路線如下圖: 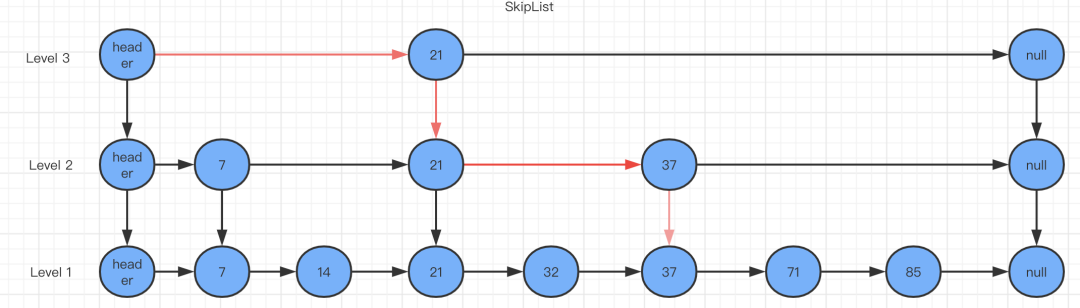 應(yīng)用場(chǎng)景:
應(yīng)用場(chǎng)景:
積分排行榜、時(shí)間排序新聞、延時(shí)隊(duì)列。
1.6、Redis Geo
以前寫過Redis Geo核心原理解析,想看的直接跳轉(zhuǎn)即可。他的核心思想就是將地球近似為球體來看待,然后 GEO利用 GeoHash 將二維的經(jīng)緯度轉(zhuǎn)換成字符串,來實(shí)現(xiàn)位置的劃分跟指定距離的查詢。
1.7、HyperLogLog
HyperLogLog :是一種概率數(shù)據(jù)結(jié)構(gòu),它使用概率算法來統(tǒng)計(jì)集合的近似基數(shù)。而它算法的最本源則是伯努利過程 + 分桶 + 調(diào)和平均數(shù)。具體實(shí)現(xiàn)可看 ?HyperLogLog 講解。
功能:誤差允許范圍內(nèi)做基數(shù)統(tǒng)計(jì) (基數(shù)就是指一個(gè)集合中不同值的個(gè)數(shù)) 的時(shí)候非常有用,每個(gè)HyperLogLog的鍵可以計(jì)算接近2^64不同元素的基數(shù),而大小只需要12KB。錯(cuò)誤率大概在0.81%。所以如果用做 UV 統(tǒng)計(jì)很合適。
HyperLogLog底層 一共分了 2^14 個(gè)桶,也就是 16384 個(gè)桶。每個(gè)(registers)桶中是一個(gè) 6 bit 的數(shù)組,這里有個(gè)騷操作就是一般人可能直接用一個(gè)字節(jié)當(dāng)桶浪費(fèi)2個(gè)bit空間,但是Redis底層只用6個(gè)然后通過前后拼接實(shí)現(xiàn)對(duì)內(nèi)存用到了極致,最終就是 16384*6/8/1024 = 12KB。
1.8、bitmap
BitMap 原本的含義是用一個(gè)比特位來映射某個(gè)元素的狀態(tài)。由于一個(gè)比特位只能表示 0 和 1 兩種狀態(tài),所以 BitMap 能映射的狀態(tài)有限,但是使用比特位的優(yōu)勢(shì)是能大量的節(jié)省內(nèi)存空間。
在 Redis 中BitMap 底層是基于字符串類型實(shí)現(xiàn)的,可以把 Bitmaps 想象成一個(gè)以比特位為單位的數(shù)組,數(shù)組的每個(gè)單元只能存儲(chǔ)0和1,數(shù)組的下標(biāo)在 Bitmaps 中叫做偏移量,BitMap 的 offset 值上限 2^32 - 1。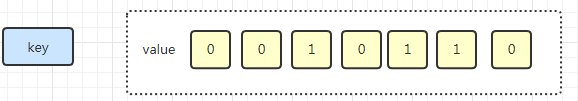
用戶簽到
key = 年份:用戶id ?offset = (今天是一年中的第幾天) % (今年的天數(shù))
統(tǒng)計(jì)活躍用戶
使用日期作為 key,然后用戶 id 為 offset 設(shè)置不同offset為0 1 即可。
PS : Redis 它的通訊協(xié)議是基于TCP的應(yīng)用層協(xié)議 RESP(REdis Serialization Protocol)。
1.9、Bloom Filter
使用布隆過濾器得到的判斷結(jié)果:不存在的一定不存在,存在的不一定存在。
布隆過濾器 原理:
當(dāng)一個(gè)元素被加入集合時(shí),通過K個(gè)散列函數(shù)將這個(gè)元素映射成一個(gè)位數(shù)組中的K個(gè)點(diǎn)(有效降低沖突概率),把它們置為1。檢索時(shí),我們只要看看這些點(diǎn)是不是都是1就知道集合中有沒有它了:如果這些點(diǎn)有任何一個(gè)為0,則被檢元素一定不在;如果都是1,則被檢元素很可能在。這就是布隆過濾器的基本思想。
想玩的話可以用Google的guava包玩耍一番。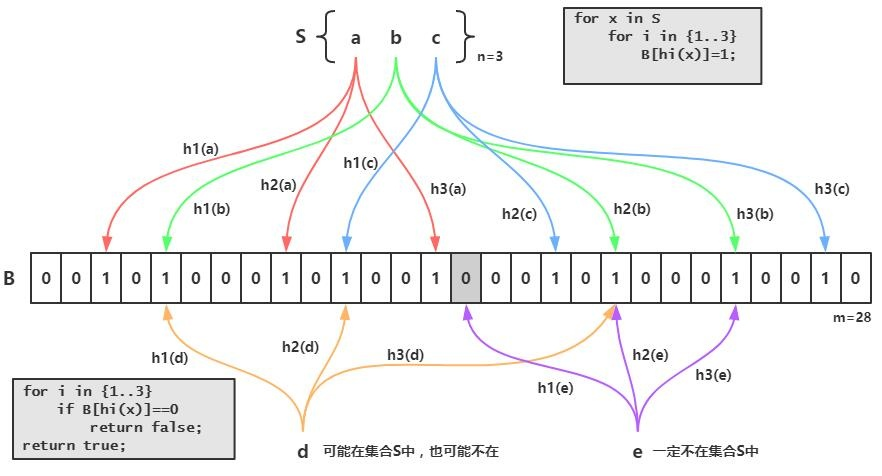
1.10 發(fā)布訂閱
redis提供了發(fā)布、訂閱模式的消息機(jī)制,其中消息訂閱者與發(fā)布者不直接通信,發(fā)布者向指定的頻道(channel)發(fā)布消息,訂閱該頻道的每個(gè)客戶端都可以接收到消息。不過比專業(yè)的MQ(RabbitMQ RocketMQ ActiveMQ Kafka)相比不值一提,這個(gè)功能就算球了。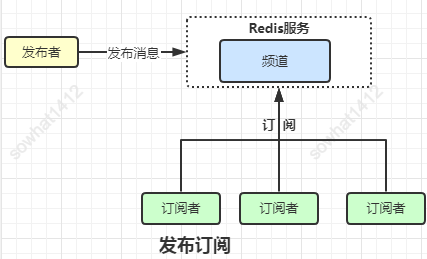
2、持久化
因?yàn)镽edis數(shù)據(jù)在內(nèi)存,斷電既丟,因此持久化到磁盤是必須得有的,Redis提供了RDB跟AOF兩種模式。
2.1、RDB
RDB 持久化機(jī)制,是對(duì) Redis 中的數(shù)據(jù)執(zhí)行周期性的持久化。更適合做冷備。優(yōu)點(diǎn):
1、壓縮后的二進(jìn)制文,適用于備份、全量復(fù)制,用于災(zāi)難恢復(fù)加載RDB恢復(fù)數(shù)據(jù)遠(yuǎn)快于AOF方式,適合大規(guī)模的數(shù)據(jù)恢復(fù)。
2、如果業(yè)務(wù)對(duì)數(shù)據(jù)完整性和一致性要求不高,RDB是很好的選擇。數(shù)據(jù)恢復(fù)比AOF快。
缺點(diǎn):
1、RDB是周期間隔性的快照文件,數(shù)據(jù)的完整性和一致性不高,因?yàn)镽DB可能在最后一次備份時(shí)宕機(jī)了。
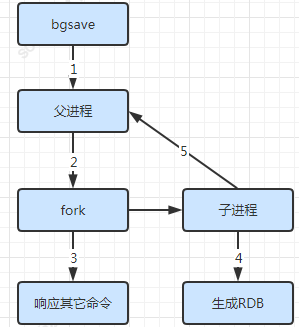
2、備份時(shí)占用內(nèi)存,因?yàn)镽edis 在備份時(shí)會(huì)獨(dú)立fork一個(gè)子進(jìn)程,將數(shù)據(jù)寫入到一個(gè)臨時(shí)文件(此時(shí)內(nèi)存中的數(shù)據(jù)是原來的兩倍哦),最后再將臨時(shí)文件替換之前的備份文件。所以要考慮到大概兩倍的數(shù)據(jù)膨脹性。
注意手動(dòng)觸發(fā)及COW:
1、
SAVE直接調(diào)用 rdbSave ,阻塞Redis 主進(jìn)程,導(dǎo)致無法提供服務(wù)。2、BGSAVE則 fork 出一個(gè)子進(jìn)程,子進(jìn)程負(fù)責(zé)調(diào)用 rdbSave ,在保存完成后向主進(jìn)程發(fā)送信號(hào)告知完成。在BGSAVE 執(zhí)行期間仍可以繼續(xù)處理客戶端的請(qǐng)求。3、Copy On Write 機(jī)制,備份的是開始那個(gè)時(shí)刻內(nèi)存中的數(shù)據(jù),只復(fù)制被修改內(nèi)存頁數(shù)據(jù),不是全部?jī)?nèi)存數(shù)據(jù)。
4、Copy On Write 時(shí)如果父子進(jìn)程大量寫操作會(huì)導(dǎo)致分頁錯(cuò)誤。
2.2、AOF
AOF 機(jī)制對(duì)每條寫入命令作為日志,以 append-only 的模式寫入一個(gè)日志文件中,因?yàn)檫@個(gè)模式是只追加的方式,所以沒有任何磁盤尋址的開銷,所以很快,有點(diǎn)像 Mysql 中的binlog。AOF更適合做熱備。
優(yōu)點(diǎn):
AOF是一秒一次去通過一個(gè)后臺(tái)的線程fsync操作,數(shù)據(jù)丟失不用怕。
缺點(diǎn):
1、對(duì)于相同數(shù)量的數(shù)據(jù)集而言,AOF文件通常要大于RDB文件。RDB 在恢復(fù)大數(shù)據(jù)集時(shí)的速度比 AOF 的恢復(fù)速度要快。
2、根據(jù)同步策略的不同,AOF在運(yùn)行效率上往往會(huì)慢于RDB。總之,每秒同步策略的效率是比較高的。
AOF整個(gè)流程分兩步:第一步是命令的實(shí)時(shí)寫入,不同級(jí)別可能有1秒數(shù)據(jù)損失。命令先追加到aof_buf然后再同步到AO磁盤,如果實(shí)時(shí)寫入磁盤會(huì)帶來非常高的磁盤IO,影響整體性能。
第二步是對(duì)aof文件的重寫,目的是為了減少AOF文件的大小,可以自動(dòng)觸發(fā)或者手動(dòng)觸發(fā)(BGREWRITEAOF),是Fork出子進(jìn)程操作,期間Redis服務(wù)仍可用。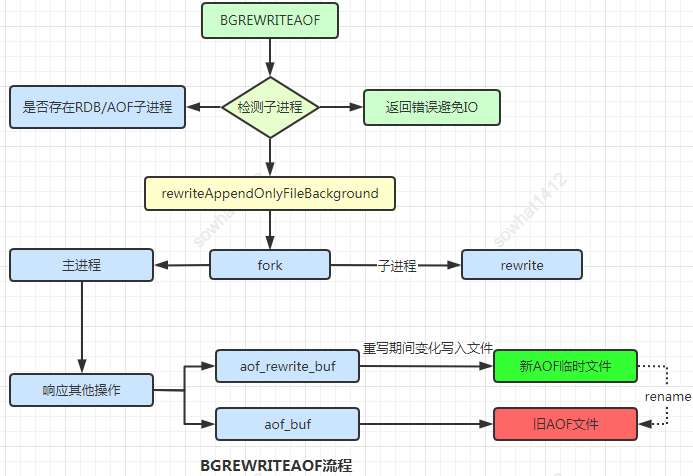
1、在重寫期間,由于主進(jìn)程依然在響應(yīng)命令,為了保證最終備份的完整性;它
依然會(huì)寫入舊的AOF中,如果重寫失敗,能夠保證數(shù)據(jù)不丟失。2、為了把重寫期間響應(yīng)的寫入信息也寫入到新的文件中,因此也會(huì)
為子進(jìn)程保留一個(gè)buf,防止新寫的file丟失數(shù)據(jù)。3、重寫是直接把
當(dāng)前內(nèi)存的數(shù)據(jù)生成對(duì)應(yīng)命令,并不需要讀取老的AOF文件進(jìn)行分析、命令合并。4、無論是 RDB 還是 AOF 都是先寫入一個(gè)臨時(shí)文件,然后通過
rename完成文件的替換工作。
關(guān)于Fork的建議:
1、降低fork的頻率,比如可以手動(dòng)來觸發(fā)RDB生成快照、與AOF重寫;
2、控制Redis最大使用內(nèi)存,防止fork耗時(shí)過長(zhǎng);
3、配置牛逼點(diǎn),合理配置Linux的內(nèi)存分配策略,避免因?yàn)槲锢韮?nèi)存不足導(dǎo)致fork失敗。
4、Redis在執(zhí)行
BGSAVE和BGREWRITEAOF命令時(shí),哈希表的負(fù)載因子>=5,而未執(zhí)行這兩個(gè)命令時(shí)>=1。目的是盡量減少寫操作,避免不必要的內(nèi)存寫入操作。5、哈希表的擴(kuò)展因子:哈希表已保存節(jié)點(diǎn)數(shù)量 / 哈希表大小。因子決定了是否擴(kuò)展哈希表。
2.3、恢復(fù)
啟動(dòng)時(shí)會(huì)先檢查AOF(數(shù)據(jù)更完整)文件是否存在,如果不存在就嘗試加載RDB。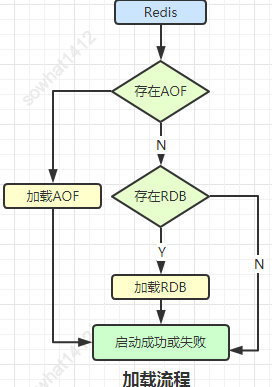
2.4、建議
既然單獨(dú)用RDB會(huì)丟失很多數(shù)據(jù)。單獨(dú)用AOF,數(shù)據(jù)恢復(fù)沒RDB來的快,所以出現(xiàn)問題了第一時(shí)間用RDB恢復(fù),然后AOF做數(shù)據(jù)補(bǔ)全才說王道。
3、Redis為什么那么快
3.1、 基于內(nèi)存實(shí)現(xiàn):
數(shù)據(jù)都存儲(chǔ)在內(nèi)存里,相比磁盤IO操作快百倍,操作速率很快。
3.2、高效的數(shù)據(jù)結(jié)構(gòu):
Redis底層多種數(shù)據(jù)結(jié)構(gòu)支持不同的數(shù)據(jù)類型,比如HyperLogLog它連2個(gè)字節(jié)都不想浪費(fèi)。
3.3、豐富而合理的編碼:
Redis底層提供了 豐富而合理的編碼 ?,五種數(shù)據(jù)類型根據(jù)長(zhǎng)度及元素的個(gè)數(shù)適配不同的編碼格式。
1、String:自動(dòng)存儲(chǔ)int類型,非int類型用raw編碼。
2、List:字符串長(zhǎng)度且元素個(gè)數(shù)小于一定范圍使用 ziplist 編碼,否則轉(zhuǎn)化為 linkedlist 編碼。
3、Hash:hash 對(duì)象保存的鍵值對(duì)內(nèi)的鍵和值字符串長(zhǎng)度小于一定值及鍵值對(duì)。
4、Set:保存元素為整數(shù)及元素個(gè)數(shù)小于一定范圍使用 intset 編碼,任意條件不滿足,則使用 hashtable 編碼。
5、Zset:保存的元素個(gè)數(shù)小于定值且成員長(zhǎng)度小于定值使用 ziplist 編碼,任意條件不滿足,則使用 skiplist 編碼。
3.4、合適的線程模型:
I/O 多路復(fù)用模型同時(shí)監(jiān)聽客戶端連接,多線程是需要上下文切換的,對(duì)于內(nèi)存數(shù)據(jù)庫來說這點(diǎn)很致命。
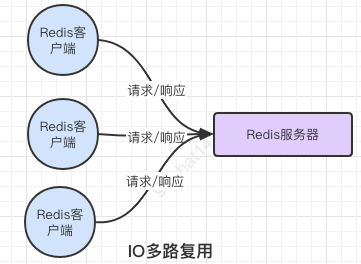
3.5、 Redis6.0后引入多線程提速:
要知道 讀寫網(wǎng)絡(luò)的read/write系統(tǒng)耗時(shí) >> Redis運(yùn)行執(zhí)行耗時(shí),Redis的瓶頸主要在于網(wǎng)絡(luò)的 IO 消耗, 優(yōu)化主要有兩個(gè)方向:
1、提高網(wǎng)絡(luò) IO 性能,典型的實(shí)現(xiàn)比如使用 DPDK 來替代內(nèi)核網(wǎng)絡(luò)棧的方式?
2、使用多線程充分利用多核,典型的實(shí)現(xiàn)比如 Memcached。
協(xié)議棧優(yōu)化的這種方式跟 Redis 關(guān)系不大,支持多線程是一種最有效最便捷的操作方式。所以Redis支持多線程主要就是兩個(gè)原因:
1、可以充分利用服務(wù)器 CPU 資源,目前主線程只能利用一個(gè)核
2、多線程任務(wù)可以分?jǐn)?Redis 同步 IO 讀寫負(fù)荷
關(guān)于多線程須知:
Redis 6.0 版本 默認(rèn)多線程是關(guān)閉的 io-threads-do-reads no Redis 6.0 版本 開啟多線程后 線程數(shù)也要 謹(jǐn)慎設(shè)置。 多線程可以使得性能翻倍,但是多線程只是用來處理網(wǎng)絡(luò)數(shù)據(jù)的讀寫和協(xié)議解析,執(zhí)行命令仍然是單線程順序執(zhí)行。
4、常見問題
4.1、緩存雪崩
 雪崩定義:
雪崩定義:
Redis中大批量key在同一時(shí)間同時(shí)失效導(dǎo)致所有請(qǐng)求都打到了MySQL。而MySQL扛不住導(dǎo)致大面積崩塌。
雪崩解決方案:
1、緩存數(shù)據(jù)的過期時(shí)間加上個(gè)隨機(jī)值,防止同一時(shí)間大量數(shù)據(jù)過期現(xiàn)象發(fā)生。
2、如果緩存數(shù)據(jù)庫是分布式部署,將熱點(diǎn)數(shù)據(jù)均勻分布在不同搞得緩存數(shù)據(jù)庫中。
3、設(shè)置熱點(diǎn)數(shù)據(jù)永遠(yuǎn)不過期。
4.2、緩存穿透
穿透定義:
緩存穿透 是 指緩存和數(shù)據(jù)庫中
都沒有的數(shù)據(jù),比如ID默認(rèn)>0,黑客一直 請(qǐng)求ID= -12的數(shù)據(jù)那么就會(huì)導(dǎo)致數(shù)據(jù)庫壓力過大,嚴(yán)重會(huì)擊垮數(shù)據(jù)庫。
穿透解決方案:
1、后端接口層增加 用戶鑒權(quán)校驗(yàn),參數(shù)做校驗(yàn)等。
2、單個(gè)IP每秒訪問次數(shù)超過閾值直接拉黑IP,關(guān)進(jìn)小黑屋1天,在獲取IP代理池的時(shí)候我就被拉黑過。
3、從緩存取不到的數(shù)據(jù),在數(shù)據(jù)庫中也沒有取到,這時(shí)也可以將key-value對(duì)寫為key-null 失效時(shí)間可以為15秒防止惡意攻擊。
4、用Redis提供的 ?Bloom Filter 特性也OK。
4.3、緩存擊穿

擊穿定義:
現(xiàn)象:大并發(fā)集中對(duì)這一個(gè)熱點(diǎn)key進(jìn)行訪問,當(dāng)這個(gè)Key在失效的瞬間,持續(xù)的大并發(fā)就穿破緩存,直接請(qǐng)求數(shù)據(jù)庫。
擊穿解決:
設(shè)置熱點(diǎn)數(shù)據(jù)永遠(yuǎn)不過期 加上互斥鎖也能搞定了
4.4、雙寫一致性
雙寫:緩存跟數(shù)據(jù)庫均更新數(shù)據(jù),如何保證數(shù)據(jù)一致性?
1、先更新數(shù)據(jù)庫,再更新緩存
安全問題:線程A更新數(shù)據(jù)庫->線程B更新數(shù)據(jù)庫->線程B更新緩存->線程A更新緩存。
導(dǎo)致臟讀。業(yè)務(wù)場(chǎng)景:讀多寫少場(chǎng)景,頻繁更新數(shù)據(jù)庫而緩存根本沒用。更何況如果緩存是疊加計(jì)算后結(jié)果更
浪費(fèi)性能。
2、先刪緩存,再更新數(shù)據(jù)庫
A 請(qǐng)求寫來更新緩存。
B 發(fā)現(xiàn)緩存不在去數(shù)據(jù)查詢舊值后寫入緩存。
A 將數(shù)據(jù)寫入數(shù)據(jù)庫,此時(shí)緩存跟數(shù)據(jù)庫不一致。
因此 FackBook 提出了 ?Cache Aside Pattern
失效:應(yīng)用程序先從cache取數(shù)據(jù),沒有得到,則從數(shù)據(jù)庫中取數(shù)據(jù),成功后,放到緩存中。
命中:應(yīng)用程序從cache中取數(shù)據(jù),取到后返回。
更新:
先把數(shù)據(jù)存到數(shù)據(jù)庫中,成功后,再讓緩存失效。
4.5、腦裂
 腦裂是指因?yàn)榫W(wǎng)絡(luò)原因,導(dǎo)致master節(jié)點(diǎn)、slave節(jié)點(diǎn) 和 sentinel集群處于不用的網(wǎng)絡(luò)分區(qū),此時(shí)因?yàn)閟entinel集群無法感知到master的存在,所以將slave節(jié)點(diǎn)提升為master節(jié)點(diǎn) 此時(shí)存在兩個(gè)不同的master節(jié)點(diǎn)就像一個(gè)大腦分裂成了兩個(gè)。其實(shí)在
腦裂是指因?yàn)榫W(wǎng)絡(luò)原因,導(dǎo)致master節(jié)點(diǎn)、slave節(jié)點(diǎn) 和 sentinel集群處于不用的網(wǎng)絡(luò)分區(qū),此時(shí)因?yàn)閟entinel集群無法感知到master的存在,所以將slave節(jié)點(diǎn)提升為master節(jié)點(diǎn) 此時(shí)存在兩個(gè)不同的master節(jié)點(diǎn)就像一個(gè)大腦分裂成了兩個(gè)。其實(shí)在Hadoop 、Spark集群中都會(huì)出現(xiàn)這樣的情況,只是解決方法不同而已(用ZK配合強(qiáng)制殺死)。
集群腦裂問題中,如果客戶端還在基于原來的master節(jié)點(diǎn)繼續(xù)寫入數(shù)據(jù)那么新的master節(jié)點(diǎn)將無法同步這些數(shù)據(jù),當(dāng)網(wǎng)絡(luò)問題解決后sentinel集群將原先的master節(jié)點(diǎn)降為slave節(jié)點(diǎn),此時(shí)再從新的master中同步數(shù)據(jù)將造成大量的數(shù)據(jù)丟失。
Redis處理方案是redis的配置文件中存在兩個(gè)參數(shù)
min-replicas-to-write?3??表示連接到master的最少slave數(shù)量
min-replicas-max-lag?10??表示slave連接到master的最大延遲時(shí)間
如果連接到master的slave數(shù)量 < 第一個(gè)參數(shù) 且 ping的延遲時(shí)間 <= 第二個(gè)參數(shù)那么master就會(huì)拒絕寫請(qǐng)求,配置了這兩個(gè)參數(shù)后如果發(fā)生了集群腦裂則原先的master節(jié)點(diǎn)接收到客戶端的寫入請(qǐng)求會(huì)拒絕就可以減少數(shù)據(jù)同步之后的數(shù)據(jù)丟失。
4.6、事務(wù)
MySQL?中的事務(wù)還是挺多道道的還要,而在Redis中的事務(wù)只要有如下三步: 關(guān)于事務(wù)具體結(jié)論:
關(guān)于事務(wù)具體結(jié)論:
1、redis事務(wù)就是一次性、順序性、排他性的執(zhí)行一個(gè)隊(duì)列中的一系列命令。 ?
2、Redis事務(wù)沒有隔離級(jí)別的概念:批量操作在發(fā)送 EXEC 命令前被放入隊(duì)列緩存,并不會(huì)被實(shí)際執(zhí)行,也就不存在事務(wù)內(nèi)的查詢要看到事務(wù)里的更新,事務(wù)外查詢不能看到。
3、Redis不保證原子性:Redis中單條命令是原子性執(zhí)行的,但事務(wù)不保證原子性。
4、Redis編譯型錯(cuò)誤事務(wù)中所有代碼均不執(zhí)行,指令使用錯(cuò)誤。運(yùn)行時(shí)異常是錯(cuò)誤命令導(dǎo)致異常,其他命令可正常執(zhí)行。
5、watch指令類似于樂觀鎖,在事務(wù)提交時(shí),如果watch監(jiān)控的多個(gè)KEY中任何KEY的值已經(jīng)被其他客戶端更改,則使用EXEC執(zhí)行事務(wù)時(shí),事務(wù)隊(duì)列將不會(huì)被執(zhí)行。
4.7、正確開發(fā)步驟
上線前:Redis 高可用,主從+哨兵,Redis cluster,避免全盤崩潰。
上線時(shí):本地 ehcache 緩存 + Hystrix 限流 + 降級(jí),避免MySQL扛不住。上線后:Redis 持久化采用 RDB + AOF 來保證斷點(diǎn)后自動(dòng)從磁盤上加載數(shù)據(jù),快速恢復(fù)緩存數(shù)據(jù)。
5、分布式鎖
日常開發(fā)中我們可以用 synchronized 、Lock ?實(shí)現(xiàn)并發(fā)編程。但是Java中的鎖只能保證在同一個(gè)JVM進(jìn)程內(nèi)中執(zhí)行。如果在分布式集群環(huán)境下用鎖呢?日常一般有兩種選擇方案。
5.1、 Zookeeper實(shí)現(xiàn)分布式鎖
你需要知道一點(diǎn)基本zookeeper知識(shí):
1、持久節(jié)點(diǎn):客戶端斷開連接zk不刪除persistent類型節(jié)點(diǎn) 2、臨時(shí)節(jié)點(diǎn):客戶端斷開連接zk刪除ephemeral類型節(jié)點(diǎn) 3、順序節(jié)點(diǎn):節(jié)點(diǎn)后面會(huì)自動(dòng)生成類似0000001的數(shù)字表示順序 4、節(jié)點(diǎn)變化的通知:客戶端注冊(cè)了監(jiān)聽節(jié)點(diǎn)變化的時(shí)候,會(huì)調(diào)用回調(diào)方法
大致流程如下,其中注意每個(gè)節(jié)點(diǎn)只監(jiān)控它前面那個(gè)節(jié)點(diǎn)狀態(tài),從而避免羊群效應(yīng)。關(guān)于模板代碼百度即可。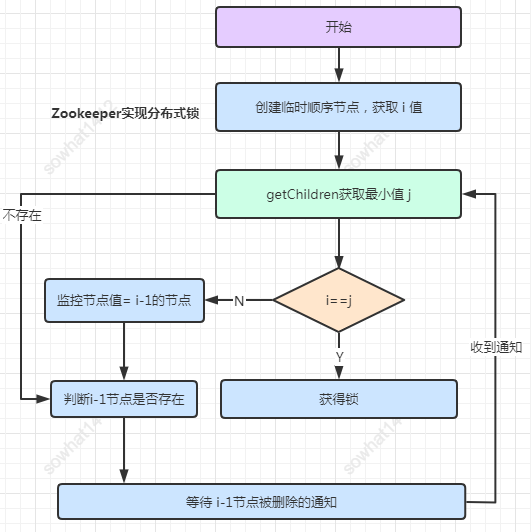 缺點(diǎn):
缺點(diǎn):
頻繁的創(chuàng)建刪除節(jié)點(diǎn),加上注冊(cè)watch事件,對(duì)于zookeeper集群的壓力比較大,性能也比不上Redis實(shí)現(xiàn)的分布式鎖。
5.2、 Redis實(shí)現(xiàn)分布式鎖
本身原理也比較簡(jiǎn)單,Redis 自身就是一個(gè)單線程處理器,具備互斥的特性,通過setNX,exist等命令就可以完成簡(jiǎn)單的分布式鎖,處理好超時(shí)釋放鎖的邏輯即可。
SETNX
SETNX 是SET if Not eXists的簡(jiǎn)寫,日常指令是
SETNX key value,如果 key 不存在則set成功返回 1,如果這個(gè)key已經(jīng)存在了返回0。
SETEX
SETEX key seconds value 表達(dá)的意思是 將值 value 關(guān)聯(lián)到 key ,并將 key 的生存時(shí)間設(shè)為多少秒。如果 key 已經(jīng)存在,setex命令將覆寫舊值。并且 setex是一個(gè)
原子性(atomic)操作。
加鎖:
一般就是用一個(gè)標(biāo)識(shí)唯一性的字符串比如UUID 配合 SETNX 實(shí)現(xiàn)加鎖。
解鎖:
這里用到了LUA腳本,LUA可以保證是原子性的,思路就是判斷一下Key和入?yún)⑹欠裣嗟龋堑脑捑蛣h除,返回成功1,0就是失敗。
缺點(diǎn):
這個(gè)鎖是無法重入的,且自己實(shí)心的話各種邊邊角角都要考慮到,所以了解個(gè)大致思路流程即可,工程化還是用開源工具包就行。
5.3、 Redisson實(shí)現(xiàn)分布式鎖
Redisson 是在Redis基礎(chǔ)上的一個(gè)服務(wù),采用了基于NIO的Netty框架,不僅能作為Redis底層驅(qū)動(dòng)客戶端,還能將原生的RedisHash,List,Set,String,Geo,HyperLogLog等數(shù)據(jù)結(jié)構(gòu)封裝為Java里大家最熟悉的映射(Map),列表(List),集(Set),通用對(duì)象桶(Object Bucket),地理空間對(duì)象桶(Geospatial Bucket),基數(shù)估計(jì)算法(HyperLogLog)等結(jié)構(gòu)。
這里我們只是用到了關(guān)于分布式鎖的幾個(gè)指令,他的大致底層原理: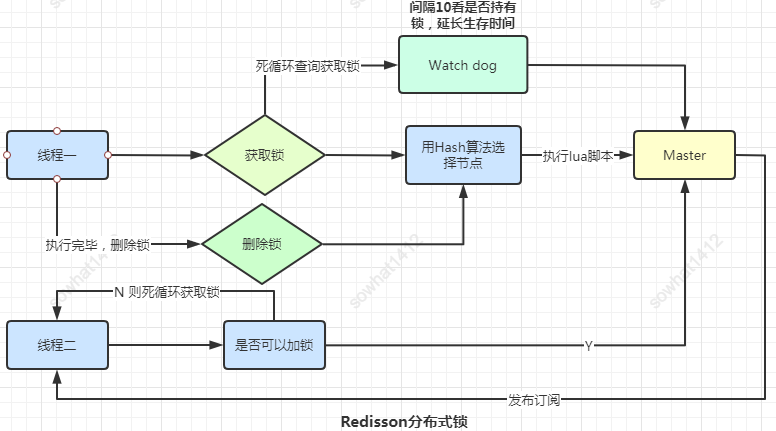
Redisson加鎖解鎖 大致流程圖如下: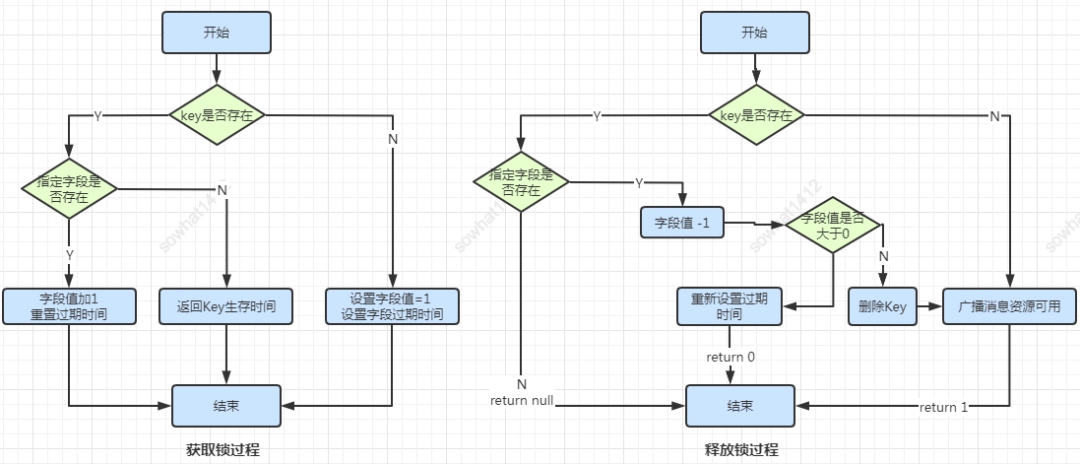
6、Redis 過期策略和內(nèi)存淘汰策略
6.1、Redis的過期策略
Redis中 過期策略 通常有以下三種:
1、定時(shí)過期:
每個(gè)設(shè)置過期時(shí)間的key都需要?jiǎng)?chuàng)建一個(gè)定時(shí)器,到過期時(shí)間就會(huì)立即對(duì)key進(jìn)行清除。該策略可以立即清除過期的數(shù)據(jù),對(duì)內(nèi)存很友好;但是會(huì)占用大量的CPU資源去處理過期的數(shù)據(jù),從而影響緩存的響應(yīng)時(shí)間和吞吐量。
2、惰性過期:
只有當(dāng)訪問一個(gè)key時(shí),才會(huì)判斷該key是否已過期,過期則清除。該策略可以最大化地節(jié)省CPU資源,卻對(duì)內(nèi)存非常不友好。極端情況可能出現(xiàn)大量的過期key沒有再次被訪問,從而不會(huì)被清除,占用大量?jī)?nèi)存。
3、定期過期:
每隔一定的時(shí)間,會(huì)掃描一定數(shù)量的數(shù)據(jù)庫的expires字典中一定數(shù)量的key,并清除其中已過期的key。該策略是前兩者的一個(gè)折中方案。通過調(diào)整定時(shí)掃描的時(shí)間間隔和每次掃描的限定耗時(shí),可以在不同情況下使得CPU和內(nèi)存資源達(dá)到最優(yōu)的平衡效果。
expires字典會(huì)保存所有設(shè)置了過期時(shí)間的key的過期時(shí)間數(shù)據(jù),其中 key 是指向鍵空間中的某個(gè)鍵的指針,value是該鍵的毫秒精度的UNIX時(shí)間戳表示的過期時(shí)間。鍵空間是指該Redis集群中保存的所有鍵。
Redis采用的過期策略:惰性刪除 + 定期刪除。memcached采用的過期策略:惰性刪除。
6.2、6種內(nèi)存淘汰策略
Redis的內(nèi)存淘汰策略是指在Redis的用于緩存的內(nèi)存不足時(shí),怎么處理需要新寫入且需要申請(qǐng)額外空間的數(shù)據(jù)。
1、volatile-lru:從已設(shè)置過期時(shí)間的數(shù)據(jù)集(server.db[i].expires)中挑選最近最少使用的數(shù)據(jù)淘汰?
2、volatile-ttl:從已設(shè)置過期時(shí)間的數(shù)據(jù)集(server.db[i].expires)中挑選將要過期的數(shù)據(jù)淘汰?
3、volatile-random:從已設(shè)置過期時(shí)間的數(shù)據(jù)集(server.db[i].expires)中任意選擇數(shù)據(jù)淘汰?
4、allkeys-lru:從數(shù)據(jù)集(server.db[i].dict)中挑選最近最少使用的數(shù)據(jù)淘汰?
5、allkeys-random:從數(shù)據(jù)集(server.db[i].dict)中任意選擇數(shù)據(jù)淘汰 6、no-enviction(驅(qū)逐):禁止驅(qū)逐數(shù)據(jù),不刪除的意思。
面試常問常考的也就是LRU了,大家熟悉的LinkedHashMap中也實(shí)現(xiàn)了LRU算法的,實(shí)現(xiàn)如下:
class?SelfLRUCache<K,?V>?extends?LinkedHashMap<K,?V>?{
????private?final?int?CACHE_SIZE;
????/**
?????*?傳遞進(jìn)來最多能緩存多少數(shù)據(jù)
?????*?@param?cacheSize?緩存大小
?????*/
????public?SelfLRUCache(int?cacheSize)?{
??// true 表示讓 linkedHashMap 按照訪問順序來進(jìn)行排序,最近訪問的放在頭部,最老訪問的放在尾部。
????????super((int)?Math.ceil(cacheSize?/?0.75)?+?1,?0.75f,?true);
????????CACHE_SIZE?=?cacheSize;
????}
????@Override
????protected?boolean?removeEldestEntry(Map.Entry?eldest) ?{
????????//?當(dāng) map中的數(shù)據(jù)量大于指定的緩存?zhèn)€數(shù)的時(shí)候,就自動(dòng)刪除最老的數(shù)據(jù)。
????????return?size()?>?CACHE_SIZE;
????}
}
6.2、總結(jié)
Redis的內(nèi)存淘汰策略的選取并不會(huì)影響過期的key的處理。內(nèi)存淘汰策略用于處理內(nèi)存不足時(shí)的需要申請(qǐng)額外空間的數(shù)據(jù),過期策略用于處理過期的緩存數(shù)據(jù)。
7、Redis 集群高可用
單機(jī)問題有機(jī)器故障、容量瓶頸、QPS瓶頸。在實(shí)際應(yīng)用中,Redis的多機(jī)部署時(shí)候會(huì)涉及到redis主從復(fù)制、Sentinel哨兵模式、Redis Cluster。
| 模式 | 優(yōu)點(diǎn) | 缺點(diǎn) |
|---|---|---|
| 單機(jī)版 | 架構(gòu)簡(jiǎn)單,部署方便 | 機(jī)器故障、容量瓶頸、QPS瓶頸 |
| 主從復(fù)制 | 高可靠性,讀寫分離 | 故障恢復(fù)復(fù)雜,主庫的寫跟存受單機(jī)限制 |
| Sentinel 哨兵 | 集群部署簡(jiǎn)單,HA | 原理繁瑣,slave存在資源浪費(fèi),不能解決讀寫分離問題 |
| Redis Cluster | 數(shù)據(jù)動(dòng)態(tài)存儲(chǔ)solt,可擴(kuò)展,高可用 | 客戶端動(dòng)態(tài)感知后端變更,批量操作支持查 |
7.1、redis主從復(fù)制
該模式下 具有高可用性且讀寫分離, 會(huì)采用 增量同步 跟 全量同步 兩種機(jī)制。
7.1.1、全量同步
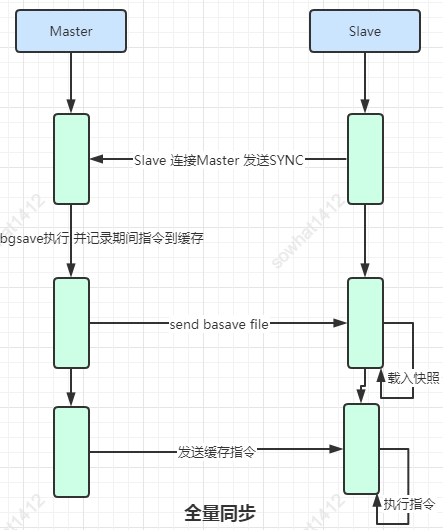 Redis全量復(fù)制一般發(fā)生在Slave初始化階段,這時(shí)Slave需要將Master上的所有數(shù)據(jù)都復(fù)制一份:
Redis全量復(fù)制一般發(fā)生在Slave初始化階段,這時(shí)Slave需要將Master上的所有數(shù)據(jù)都復(fù)制一份:
1、slave連接master,發(fā)送
psync命令。2、master接收到
psync命名后,開始執(zhí)行bgsave命令生成RDB文件并使用緩沖區(qū)記錄此后執(zhí)行的所有寫命令。3、master發(fā)送快照文件到slave,并在發(fā)送期間繼續(xù)記錄被執(zhí)行的寫命令。4、slave收到快照文件后丟棄所有舊數(shù)據(jù),載入收到的快照。
5、master快照發(fā)送完畢后開始向slave發(fā)送緩沖區(qū)中的寫命令。
6、slave完成對(duì)快照的載入,開始接收命令請(qǐng)求,并執(zhí)行來自master緩沖區(qū)的寫命令。
7.1.2、增量同步
也叫指令同步,就是從庫重放在主庫中進(jìn)行的指令。Redis會(huì)把指令存放在一個(gè)環(huán)形隊(duì)列當(dāng)中,因?yàn)閮?nèi)存容量有限,如果備機(jī)一直起不來,不可能把所有的內(nèi)存都去存指令,也就是說,如果備機(jī)一直未同步,指令可能會(huì)被覆蓋掉。
Redis增量復(fù)制是指Slave初始化后開始正常工作時(shí)master發(fā)生的寫操作同步到slave的過程。增量復(fù)制的過程主要是master每執(zhí)行一個(gè)寫命令就會(huì)向slave發(fā)送相同的寫命令。
7.1.3、Redis主從同步策略:
1、
主從剛剛連接的時(shí)候,進(jìn)行全量同步;全同步結(jié)束后,進(jìn)行增量同步。當(dāng)然,如果有需要,slave 在任何時(shí)候都可以發(fā)起全量同步。redis 策略是,無論如何,首先會(huì)嘗試進(jìn)行增量同步,如不成功,要求從機(jī)進(jìn)行全量同步。2、slave在同步master數(shù)據(jù)時(shí)候如果slave丟失連接不用怕,slave在重新連接之后丟失重補(bǔ)。3、一般通過主從來實(shí)現(xiàn)讀寫分離,但是如果master掛掉后如何保證Redis的 HA呢?引入
Sentinel進(jìn)行master的選擇。
7.2、高可用之哨兵模式
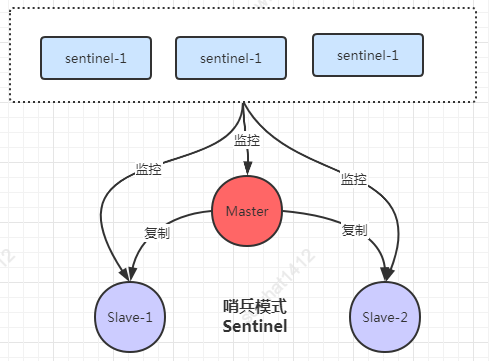
Redis-sentinel ?本身是一個(gè)獨(dú)立運(yùn)行的進(jìn)程,一般sentinel集群 節(jié)點(diǎn)數(shù)至少三個(gè)且奇數(shù)個(gè),它能監(jiān)控多個(gè)master-slave集群,sentinel節(jié)點(diǎn)發(fā)現(xiàn)master宕機(jī)后能進(jìn)行自動(dòng)切換。Sentinel可以監(jiān)視任意多個(gè)主服務(wù)器以及主服務(wù)器屬下的從服務(wù)器,并在被監(jiān)視的主服務(wù)器下線時(shí),自動(dòng)執(zhí)行故障轉(zhuǎn)移操作。這里需注意sentinel也有single-point-of-failure問題。大致羅列下哨兵用途:
集群監(jiān)控:循環(huán)監(jiān)控master跟slave節(jié)點(diǎn)。
消息通知:當(dāng)它發(fā)現(xiàn)有redis實(shí)例有故障的話,就會(huì)發(fā)送消息給管理員?
故障轉(zhuǎn)移:這里分為主觀下線(單獨(dú)一個(gè)哨兵發(fā)現(xiàn)master故障了)。客觀下線(多個(gè)哨兵進(jìn)行抉擇發(fā)現(xiàn)達(dá)到quorum數(shù)時(shí)候開始進(jìn)行切換)。
配置中心:如果發(fā)生了故障轉(zhuǎn)移,它會(huì)通知將master的新地址寫在配置中心告訴客戶端。
7.3、Redis Cluster
RedisCluster是Redis的分布式解決方案,在3.0版本后推出的方案,有效地解決了Redis分布式的需求。
7.3.1、分區(qū)規(guī)則
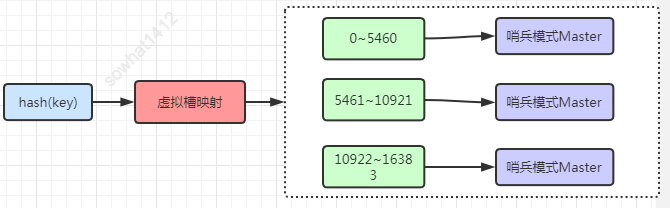 常見的分區(qū)規(guī)則
常見的分區(qū)規(guī)則
節(jié)點(diǎn)取余:hash(key) % N一致性哈希:一致性哈希環(huán)虛擬槽哈希:CRC16[key] & 16383
RedisCluster采用了虛擬槽分區(qū)方式,具題的實(shí)現(xiàn)細(xì)節(jié)如下:
1、采用去中心化的思想,它使用虛擬槽solt分區(qū)覆蓋到所有節(jié)點(diǎn)上,取數(shù)據(jù)一樣的流程,節(jié)點(diǎn)之間使用輕量協(xié)議通信Gossip來減少帶寬占用所以性能很高,?
2、自動(dòng)實(shí)現(xiàn)負(fù)載均衡與高可用,自動(dòng)實(shí)現(xiàn)failover并且支持動(dòng)態(tài)擴(kuò)展,官方已經(jīng)玩到可以1000個(gè)節(jié)點(diǎn) 實(shí)現(xiàn)的復(fù)雜度低。
3、每個(gè)Master也需要配置主從,并且內(nèi)部也是采用哨兵模式,如果有半數(shù)節(jié)點(diǎn)發(fā)現(xiàn)某個(gè)異常節(jié)點(diǎn)會(huì)共同決定更改異常節(jié)點(diǎn)的狀態(tài)。
4、如果集群中的master沒有slave節(jié)點(diǎn),則master掛掉后整個(gè)集群就會(huì)進(jìn)入fail狀態(tài),因?yàn)榧旱膕lot映射不完整。如果集群超過半數(shù)以上的master掛掉,集群都會(huì)進(jìn)入fail狀態(tài)。
5、官方推薦 集群部署至少要3臺(tái)以上的master節(jié)點(diǎn)。
8、Redis 限流
經(jīng)常乘坐北京西二旗地鐵或者在北京西站乘坐的時(shí)候經(jīng)常會(huì)遇到一種情況就是如果人很多,地鐵的工作人員拿個(gè)小牌前面一檔讓你等會(huì)兒再檢票,這就是實(shí)際生活應(yīng)對(duì)人流量巨大的措施。
在開發(fā)高并發(fā)系統(tǒng)時(shí),有三把利器用來保護(hù)系統(tǒng):緩存、降級(jí)和限流。那么何為限流呢?顧名思義,限流就是限制流量,就像你寬帶包了1個(gè)G的流量,用完了就沒了。通過限流,我們可以很好地控制系統(tǒng)的qps,從而達(dá)到保護(hù)系統(tǒng)的目的。
1、基于Redis的setnx、zset
1.2、setnx
比如我們需要在10秒內(nèi)限定20個(gè)請(qǐng)求,那么我們?cè)趕etnx的時(shí)候可以設(shè)置過期時(shí)間10,當(dāng)請(qǐng)求的setnx數(shù)量達(dá)到20時(shí)候即達(dá)到了限流效果。
缺點(diǎn):比如當(dāng)統(tǒng)計(jì)1-10秒的時(shí)候,無法統(tǒng)計(jì)2-11秒之內(nèi),如果需要統(tǒng)計(jì)N秒內(nèi)的M個(gè)請(qǐng)求,那么我們的Redis中需要保持N個(gè)key等等問題。
1.3、zset
其實(shí)限流涉及的最主要的就是滑動(dòng)窗口,上面也提到1-10怎么變成2-11。其實(shí)也就是起始值和末端值都各+1即可。我們可以將請(qǐng)求打造成一個(gè)zset數(shù)組,當(dāng)每一次請(qǐng)求進(jìn)來的時(shí)候,value保持唯一,可以用UUID生成,而score可以用當(dāng)前時(shí)間戳表示,因?yàn)閟core我們可以用來計(jì)算當(dāng)前時(shí)間戳之內(nèi)有多少的請(qǐng)求數(shù)量。而zset數(shù)據(jù)結(jié)構(gòu)也提供了range方法讓我們可以很輕易的獲取到2個(gè)時(shí)間戳內(nèi)有多少請(qǐng)求,
缺點(diǎn):就是zset的數(shù)據(jù)結(jié)構(gòu)會(huì)越來越大。
2、漏桶算法
漏桶算法思路:把水比作是請(qǐng)求,漏桶比作是系統(tǒng)處理能力極限,水先進(jìn)入到漏桶里,漏桶里的水按一定速率流出,當(dāng)流出的速率小于流入的速率時(shí),由于漏桶容量有限,后續(xù)進(jìn)入的水直接溢出(拒絕請(qǐng)求),以此實(shí)現(xiàn)限流。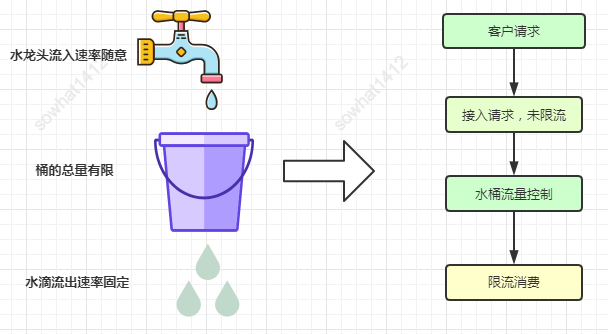
3、令牌桶算法
令牌桶算法的原理:可以理解成醫(yī)院的掛號(hào)看病,只有拿到號(hào)以后才可以進(jìn)行診病。
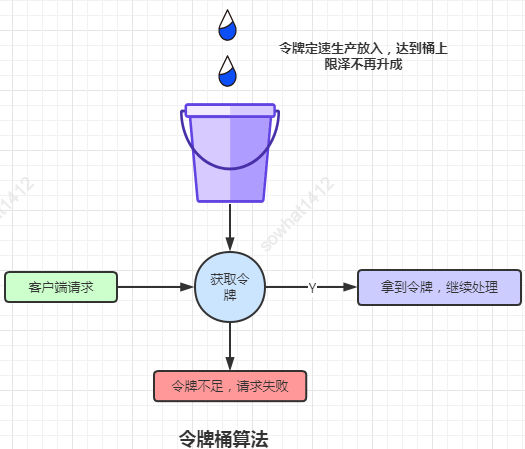 細(xì)節(jié)流程大致:
細(xì)節(jié)流程大致:
1、所有的請(qǐng)求在處理之前都需要拿到一個(gè)可用的令牌才會(huì)被處理。
2、根據(jù)限流大小,設(shè)置按照一定的速率往桶里添加令牌。
3、設(shè)置桶最大可容納值,當(dāng)桶滿時(shí)新添加的令牌就被丟棄或者拒絕。
4、請(qǐng)求達(dá)到后首先要獲取令牌桶中的令牌,拿著令牌才可以進(jìn)行其他的業(yè)務(wù)邏輯,處理完業(yè)務(wù)邏輯之后,將令牌直接刪除。
5、令牌桶有最低限額,當(dāng)桶中的令牌達(dá)到最低限額的時(shí)候,請(qǐng)求處理完之后將不會(huì)刪除令牌,以此保證足夠的限流。
工程化:
1、自定義注解、aop、Redis + Lua 實(shí)現(xiàn)限流。
2、推薦 guava 的RateLimiter實(shí)現(xiàn)。
9、常見知識(shí)點(diǎn)
字符串模糊查詢時(shí)用 Keys可能導(dǎo)致線程阻塞,盡量用scan指令進(jìn)行無阻塞的取出數(shù)據(jù)然后去重下即可。多個(gè)操作的情況下記得用 pipeLine把所有的命令一次發(fā)過去,避免頻繁的發(fā)送、接收帶來的網(wǎng)絡(luò)開銷,提升性能。bigkeys可以掃描redis中的大key,底層是使用scan命令去遍歷所有的鍵,對(duì)每個(gè)鍵根據(jù)其類型執(zhí)行STRLEN、LLEN、SCARD、HLEN、ZCARD這些命令獲取其長(zhǎng)度或者元素個(gè)數(shù)。缺陷是線上試用并且個(gè)數(shù)多不一定空間大, 線上應(yīng)用記得開啟Redis慢查詢?nèi)罩九叮舅悸犯鶰ySQL類似。 Redis中因?yàn)閮?nèi)存分配策略跟增刪數(shù)據(jù)是會(huì)導(dǎo)致 內(nèi)存碎片,你可以重啟服務(wù)也可以執(zhí)行activedefrag yes進(jìn)行內(nèi)存重新整理來解決此問題。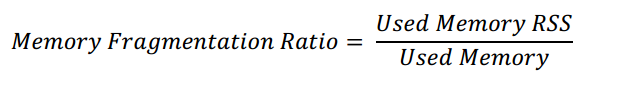
1、Ratio >1 表明有內(nèi)存碎片,越大表明越多嚴(yán)重。
2、Ratio?< 1 表明正在使用虛擬內(nèi)存,虛擬內(nèi)存其實(shí)就是硬盤,性能比內(nèi)存低得多,這是應(yīng)該增強(qiáng)機(jī)器的內(nèi)存以提高性能。
3、一般來說,mem_fragmentation_ratio的數(shù)值在1 ~ 1.5之間是比較健康的

往期推薦

線程池的7種創(chuàng)建方式,強(qiáng)烈推薦你用它...

Redis的自白:我為什么在單線程的這條路上越走越遠(yuǎn)?

Redis 6.0 正式版終于發(fā)布了!除了多線程還有什么新功能?