
大型分布式 Web 系統(tǒng)的架構(gòu)演進(jìn)

- 前言 -
用戶模塊:用戶注冊和管理 商品模塊:商品展示和管理 交易模塊:創(chuàng)建交易和管理
- 正文 -
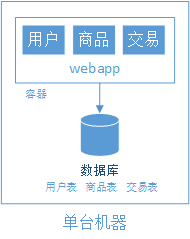
階段二、應(yīng)用服務(wù)器與數(shù)據(jù)庫分離

階段三、應(yīng)用服務(wù)器集群
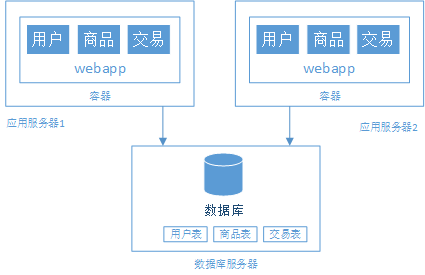
1、負(fù)載均衡的問題
HTTP重定向就是應(yīng)用層的請求轉(zhuǎn)發(fā)。用戶的請求其實已經(jīng)到了HTTP重定向負(fù)載均衡服務(wù)器,服務(wù)器根據(jù)算法要求用戶重定向,用戶收到重定向請求后,再次請求真正的集群
優(yōu)點:簡單易用; 缺點:性能較差。
DNS域名解析負(fù)載均衡就是在用戶請求DNS服務(wù)器,獲取域名對應(yīng)的IP地址時,DNS服務(wù)器直接給出負(fù)載均衡后的服務(wù)器IP。
優(yōu)點:交給DNS,不用我們?nèi)ゾS護(hù)負(fù)載均衡服務(wù)器; 缺點:當(dāng)一個應(yīng)用服務(wù)器掛了,不能及時通知DNS,而且DNS負(fù)載均衡的控制權(quán)在域名服務(wù)商那里,網(wǎng)站無法做更多的改善和更強(qiáng)大的管理。
在用戶的請求到達(dá)反向代理服務(wù)器時(已經(jīng)到達(dá)網(wǎng)站機(jī)房),由反向代理服務(wù)器根據(jù)算法轉(zhuǎn)發(fā)到具體的服務(wù)器。常用的Apache,Nginx都可以充當(dāng)反向代理服務(wù)器。
優(yōu)點:部署簡單; 缺點:代理服務(wù)器可能成為性能的瓶頸,特別是一次上傳大文件。
在請求到達(dá)負(fù)載均衡器后,負(fù)載均衡器通過修改請求的目的IP地址,從而實現(xiàn)請求的轉(zhuǎn)發(fā),做到負(fù)載均衡。
優(yōu)點:性能更好; 缺點:負(fù)載均衡器的寬帶成為瓶頸。
在請求到達(dá)負(fù)載均衡器后,負(fù)載均衡器通過修改請求的MAC地址,從而做到負(fù)載均衡,與IP負(fù)載均衡不一樣的是,當(dāng)請求訪問完服務(wù)器之后,直接返回客戶。而無需再經(jīng)過負(fù)載均衡器。
2、集群調(diào)度轉(zhuǎn)發(fā)算法
顧名思義,輪詢分發(fā)請求。
優(yōu)點:實現(xiàn)簡單 缺點:不考慮每臺服務(wù)器的處理能力
我們給每個服務(wù)器設(shè)置權(quán)值Weight,負(fù)載均衡調(diào)度器根據(jù)權(quán)值調(diào)度服務(wù)器,服務(wù)器被調(diào)用的次數(shù)跟權(quán)值成正比。
優(yōu)點:考慮了服務(wù)器處理能力的不同
提取用戶IP,根據(jù)散列函數(shù)得出一個key,再根據(jù)靜態(tài)映射表,查處對應(yīng)的value,即目標(biāo)服務(wù)器IP。過目標(biāo)機(jī)器超負(fù)荷,則返回空。
優(yōu)點:實現(xiàn)同一個用戶訪問同一個服務(wù)器。
原理同上,只是現(xiàn)在提取的是目標(biāo)地址的IP來做哈希。
優(yōu)點:實現(xiàn)同一個用戶訪問同一個服務(wù)器。
優(yōu)先把請求轉(zhuǎn)發(fā)給連接數(shù)少的服務(wù)器。
優(yōu)點:使得集群中各個服務(wù)器的負(fù)載更加均勻。
在lc的基礎(chǔ)上,為每臺服務(wù)器加上權(quán)值。算法為:(活動連接數(shù) * 256 + 非活動連接數(shù)) ÷ 權(quán)重,計算出來的值小的服務(wù)器優(yōu)先被選擇。
優(yōu)點:可以根據(jù)服務(wù)器的能力分配請求。
其實sed跟wlc類似,區(qū)別是不考慮非活動連接數(shù)。算法為:(活動連接數(shù) +1 ) * 256 ÷ 權(quán)重,同樣計算出來的值小的服務(wù)器優(yōu)先被選擇。
改進(jìn)的sed算法。我們想一下什么情況下才能“永不排隊”,那就是服務(wù)器的連接數(shù)為0的時候,那么假如有服務(wù)器連接數(shù)為0,均衡器直接把請求轉(zhuǎn)發(fā)給它,無需經(jīng)過sed的計算。
負(fù)載均衡器根據(jù)請求的目的IP地址,找出該IP地址最近被使用的服務(wù)器,把請求轉(zhuǎn)發(fā)之。若該服務(wù)器超載,最采用最少連接數(shù)算法。
負(fù)載均衡器根據(jù)請求的目的IP地址,找出該IP地址最近使用的“服務(wù)器組”,注意,并不是具體某個服務(wù)器,然后采用最少連接數(shù)從該組中挑出具體的某臺服務(wù)器出來,把請求轉(zhuǎn)發(fā)之。若該服務(wù)器超載,那么根據(jù)最少連接數(shù)算法,在集群的非本服務(wù)器組的服務(wù)器中,找出一臺服務(wù)器出來,加入本服務(wù)器組,然后把請求轉(zhuǎn)發(fā)。
3、集群請求返回模式問題
負(fù)載均衡器接收用戶的請求,轉(zhuǎn)發(fā)給具體服務(wù)器,服務(wù)器處理完請求返回給均衡器,均衡器再重新返回給用戶。
負(fù)載均衡器接收用戶的請求,轉(zhuǎn)發(fā)給具體服務(wù)器,服務(wù)器出來玩請求后直接返回給用戶。需要系統(tǒng)支持IP Tunneling協(xié)議,難以跨平臺。
同上,但無需IP Tunneling協(xié)議,跨平臺性好,大部分系統(tǒng)都可以支持。
4、集群Session一致性問題
Session sticky就是把同一個用戶在某一個會話中的請求,都分配到固定的某一臺服務(wù)器中,這樣我們就不需要解決跨服務(wù)器的session問題了,常見的算法有ip_hash算法,即上面提到的兩種散列算法。
優(yōu)點:實現(xiàn)簡單; 缺點:應(yīng)用服務(wù)器重啟則session消失。
Session replication就是在集群中復(fù)制session,使得每個服務(wù)器都保存有全部用戶的session數(shù)據(jù)。
優(yōu)點:減輕負(fù)載均衡服務(wù)器的壓力,不需要要實現(xiàn)ip_hasp算法來轉(zhuǎn)發(fā)請求; 缺點:復(fù)制時網(wǎng)絡(luò)帶寬開銷大,訪問量大的話Session占用內(nèi)存大且浪費。
Session數(shù)據(jù)集中存儲就是利用數(shù)據(jù)庫來存儲session數(shù)據(jù),實現(xiàn)了session和應(yīng)用服務(wù)器的解耦。
優(yōu)點:相比Session replication的方案,集群間對于寬帶和內(nèi)存的壓力大幅減少; 缺點:需要維護(hù)存儲Session的數(shù)據(jù)庫。
Cookie base就是把Session存在Cookie中,由瀏覽器來告訴應(yīng)用服務(wù)器我的session是什么,同樣實現(xiàn)了session和應(yīng)用服務(wù)器的解耦。
優(yōu)點:實現(xiàn)簡單,基本免維護(hù)。 缺點:cookie長度限制,安全性低,帶寬消耗。
Nginx目前支持的負(fù)載均衡算法有wrr、sh(支持一致性哈希)、fair(lc)。但Nginx作為均衡器的話,還可以一同作為靜態(tài)資源服務(wù)器。 Keepalived + ipvsadm比較強(qiáng)大,目前支持的算法有:rr、wrr、lc、wlc、lblc、sh、dh Keepalived支持集群模式有:NAT、DR、TUN Nginx本身并沒有提供session同步的解決方案,而Apache則提供了session共享的支持。

階段四、數(shù)據(jù)庫讀寫分離化
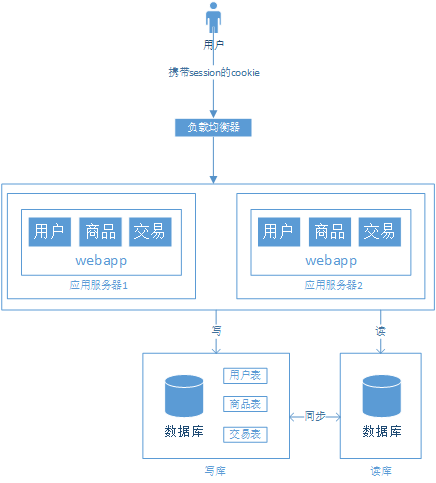
主從數(shù)據(jù)庫之間數(shù)據(jù)同步問題。 應(yīng)用對于數(shù)據(jù)源的選擇問題。
使用MySQL自帶的Master + Slave的方式實現(xiàn)主從復(fù)制。 采用第三方數(shù)據(jù)庫中間件,例如MyCat。MyCat是從Cobar發(fā)展而來的,而Cobar是阿里開源的數(shù)據(jù)庫中間件,后來停止開發(fā)。MyCat是國內(nèi)比較好的MySql開源數(shù)據(jù)庫分庫分表中間件。
階段五、用搜索引擎緩解讀庫的壓力
搜索引擎具有的優(yōu)點:它能夠大大提高查詢速度和搜索準(zhǔn)確性。
引入搜索引擎的開銷
帶來大量的維護(hù)工作,我們需要自己實現(xiàn)索引的構(gòu)建過程,設(shè)計全量/增加的構(gòu)建方式來應(yīng)對非實時與實時的查詢需求。 需要維護(hù)搜索引擎集群
搜索引擎并不能替代數(shù)據(jù)庫,它解決了某些場景下的精準(zhǔn)、快速、高效的“讀”操作,是否引入搜索引擎,需要綜合考慮整個系統(tǒng)的需求。
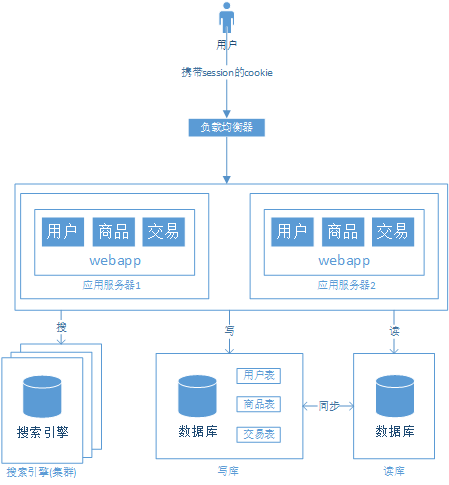
階段六、用緩存緩解讀庫的壓力
- 應(yīng)用層和數(shù)據(jù)庫層的緩存 -
另外,在某些場景下,關(guān)系型數(shù)據(jù)庫并不是很適合,例如我想做一個“每日輸入密碼錯誤次數(shù)限制”的功能,思路大概是在用戶登錄時,如果登錄錯誤,則記錄下該用戶的IP和錯誤次數(shù),那么這個數(shù)據(jù)要放在哪里呢?假如放在內(nèi)存中,那么顯然會占用太大的內(nèi)容;假如放在關(guān)系型數(shù)據(jù)庫中,那么既要建立數(shù)據(jù)庫表,還要簡歷對應(yīng)的Java bean,還要寫SQL等等。而分析一下我們要存儲的數(shù)據(jù),無非就是類似{ip:errorNumber}這樣的key:value數(shù)據(jù)。對于這種數(shù)據(jù),我們可以用NOSQL數(shù)據(jù)庫來代替?zhèn)鹘y(tǒng)的關(guān)系型數(shù)據(jù)庫。
頁面緩存
優(yōu)點:減輕數(shù)據(jù)庫的壓力, 大幅度提高訪問速度; 缺點:需要維護(hù)緩存服務(wù)器,提高了編碼的復(fù)雜性。
緩存集群的調(diào)度算法不同與上面提到的應(yīng)用服務(wù)器和數(shù)據(jù)庫。最好采用一致性哈希算,這樣才能提高命中率。

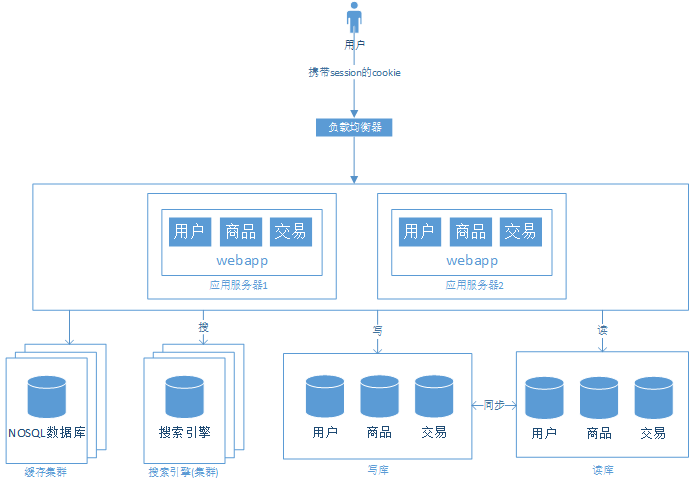
階段七、數(shù)據(jù)庫水平拆分與垂直拆分
- 數(shù)據(jù)垂直拆分 -
解決了原來把所有業(yè)務(wù)放在一個數(shù)據(jù)庫中的壓力問題; 可以根據(jù)業(yè)務(wù)的特點進(jìn)行更多的優(yōu)化。
需要維護(hù)多個數(shù)據(jù)庫的狀態(tài)一致性和數(shù)據(jù)同步。
需要考慮原來跨業(yè)務(wù)的事務(wù); 跨數(shù)據(jù)庫的Join。
應(yīng)該在應(yīng)用層盡量避免跨數(shù)據(jù)庫的分布式事務(wù),如果非要跨數(shù)據(jù)庫,盡量在代碼中控制。 通過第三方中間件來解決,如上面提到的MyCat,MyCat提供了豐富的跨庫Join方案,詳情可參考MyCat官方文檔。
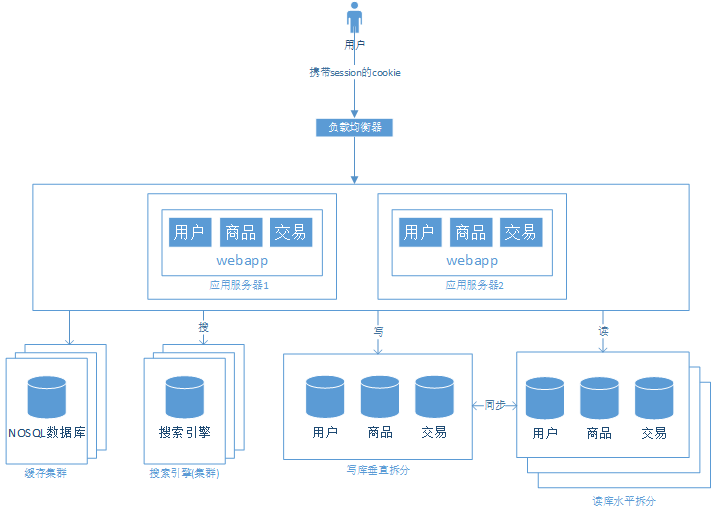
- 數(shù)據(jù)水平拆分 -
如果能克服以上問題,那么我們將能夠很好地對數(shù)據(jù)量及寫入量增長的情況。
訪問用戶信息的應(yīng)用系統(tǒng)需要解決SQL路由的問題,因為現(xiàn)在用戶信息分在了兩個數(shù)據(jù)庫中,需要在進(jìn)行數(shù)據(jù)操作時了解需要操作的數(shù)據(jù)在哪里。 主鍵 的處理也變得不同,例如原來自增字段,現(xiàn)在不能簡單地繼續(xù)使用。 如果需要分頁查詢,那就更加麻煩。
我們還是可以通過可以解決第三方中間件,如MyCat。MyCat可以通過SQL解析模塊對我們的SQL進(jìn)行解析,再根據(jù)我們的配置,把請求轉(zhuǎn)發(fā)到具體的某個數(shù)據(jù)庫。我們可以通過UUID保證唯一或自定義ID方案來解決。 MyCat也提供了豐富的分頁查詢方案,比如先從每個數(shù)據(jù)庫做分頁查詢,再合并數(shù)據(jù)做一次分頁查詢等等。
階段八、應(yīng)用的拆分
按微服務(wù)拆分應(yīng)用
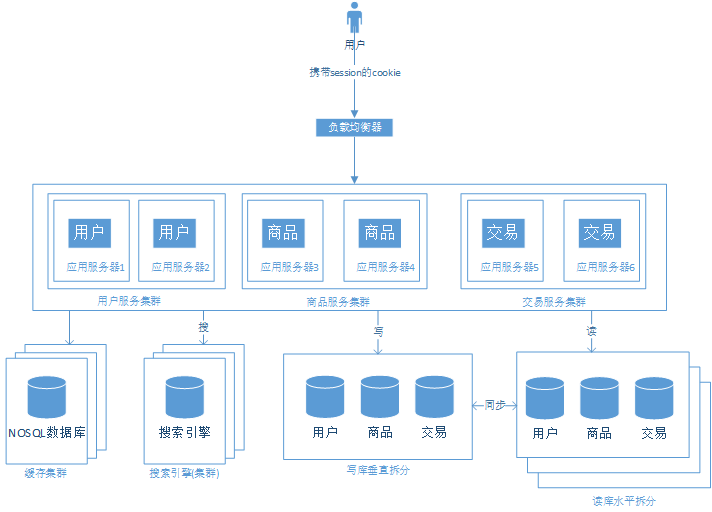
這樣拆分后,可能會有一些相同的代碼,如用戶相關(guān)的代碼,商品和交易都需要用戶信息,所以在兩個系統(tǒng)中都保留差不多的操作用戶信息的代碼。如何保證這些代碼可以復(fù)用是一個需要解決的問題。
通過走服務(wù)化SOA的路線來解決頻繁公共的服務(wù)。
走SOA服務(wù)化治理道路
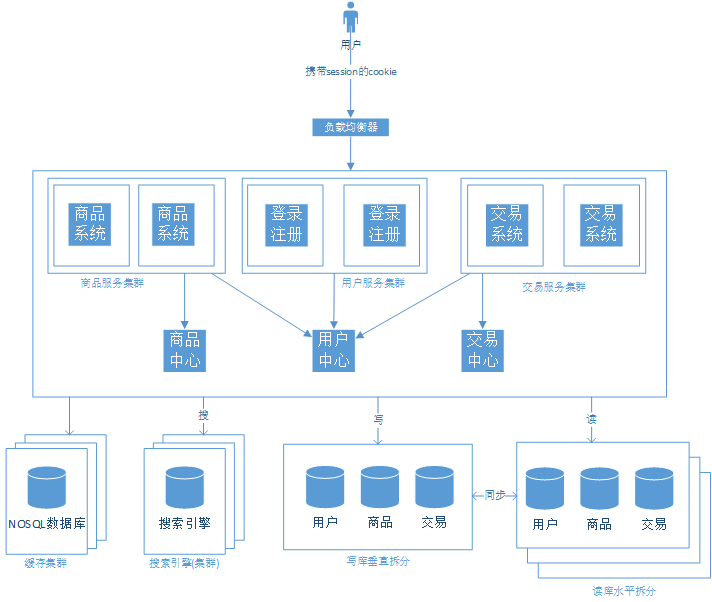
相同的代碼不會散落在不同的應(yīng)用中了,這些實現(xiàn)放在了各個服務(wù)中心,使代碼得到更好的維護(hù)。 我們把對數(shù)據(jù)庫的交互業(yè)務(wù)放在了各個服務(wù)中心,讓前端的Web應(yīng)用更注重與瀏覽器交互的工作。
如何進(jìn)行遠(yuǎn)程的服務(wù)調(diào)用?
可以通過下面的引入消息中間件來解決。
階段九、引入消息中間件

- 總結(jié) -
作者:xiaojiaqi
來源:github.com/xiaojiaqi/10billionhongbao

評論
圖片
表情