
分布式架構(gòu)演進(jìn)總結(jié)
二、背景說明
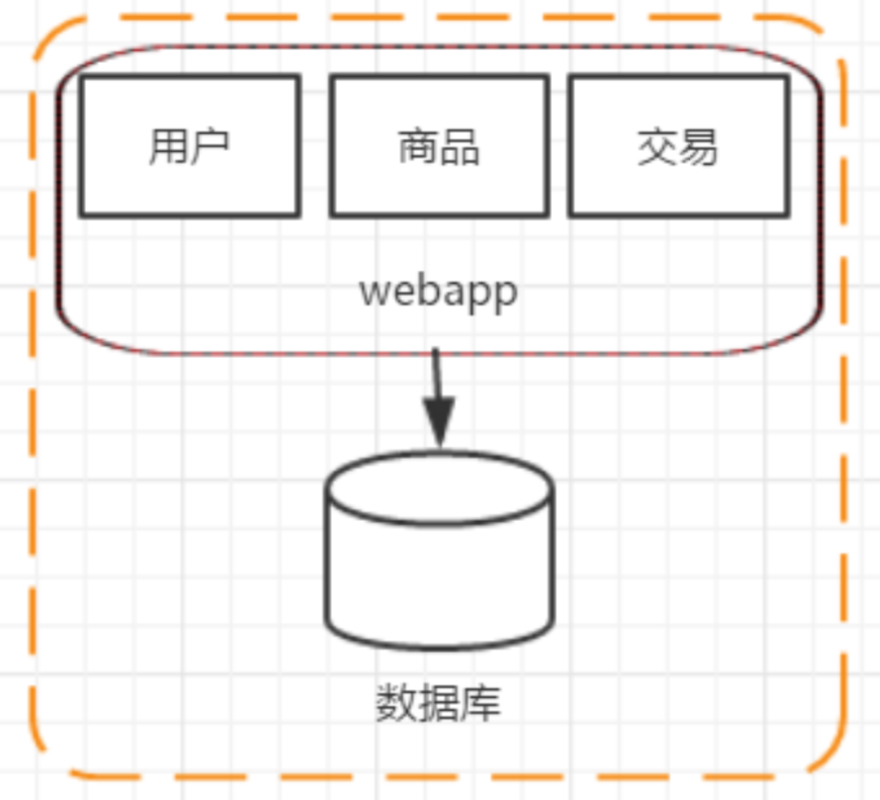
用戶模塊:用戶注冊和管理。 商品模塊:商品展示和管理。 交易模塊:創(chuàng)建交易及支付結(jié)算。
三、階段一:單應(yīng)用架構(gòu)
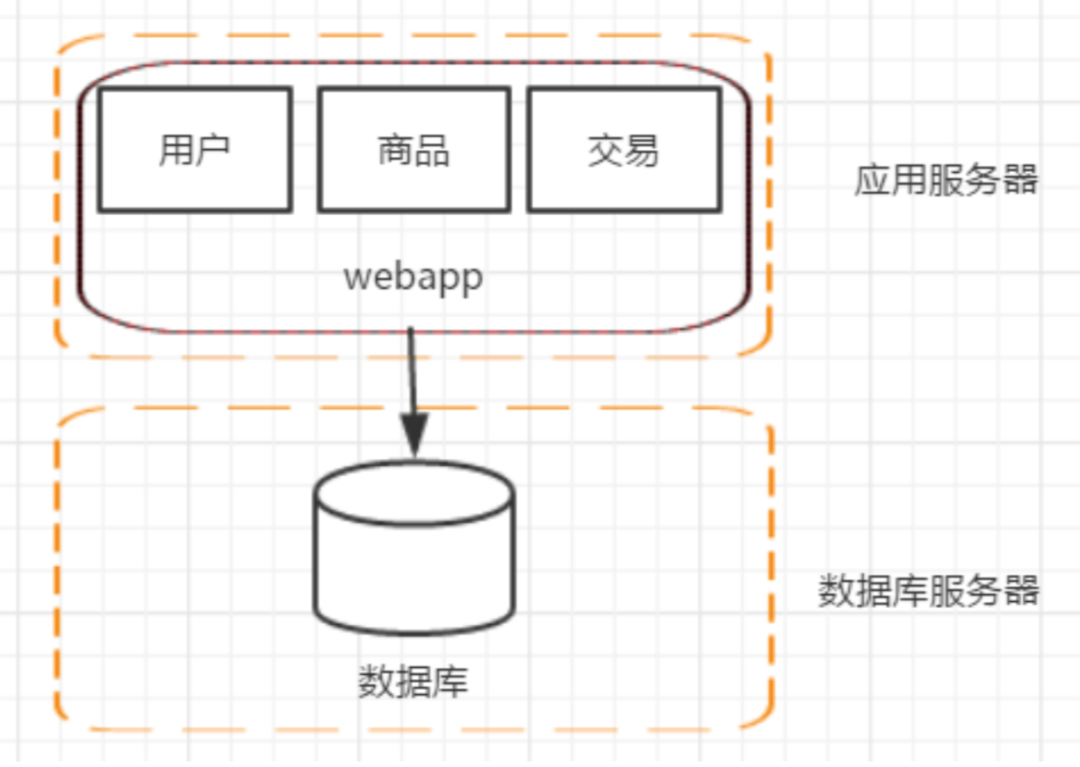
四、階段二:應(yīng)用服務(wù)器和數(shù)據(jù)庫服務(wù)器分離
五、階段三:應(yīng)用服務(wù)器集群
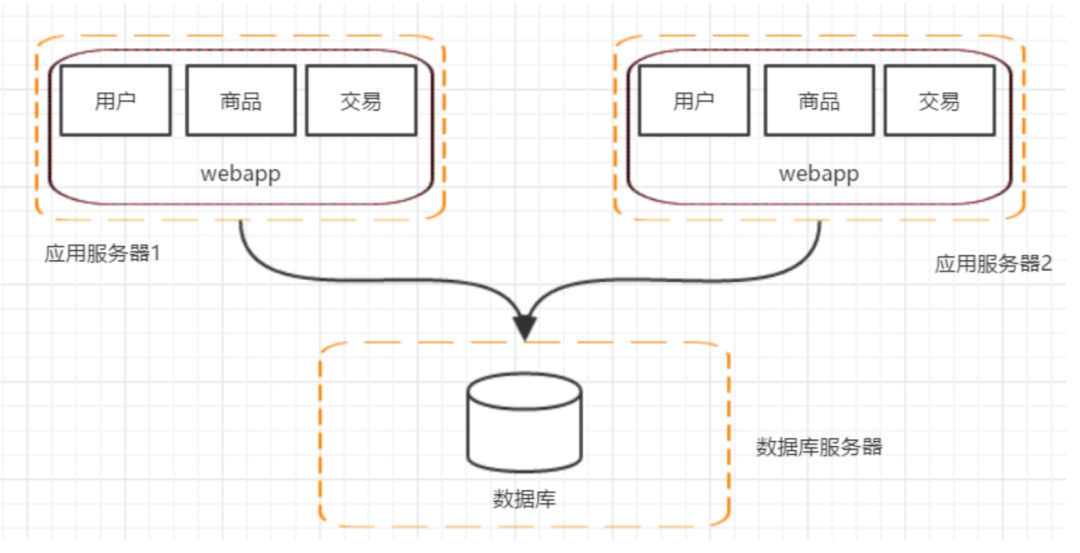
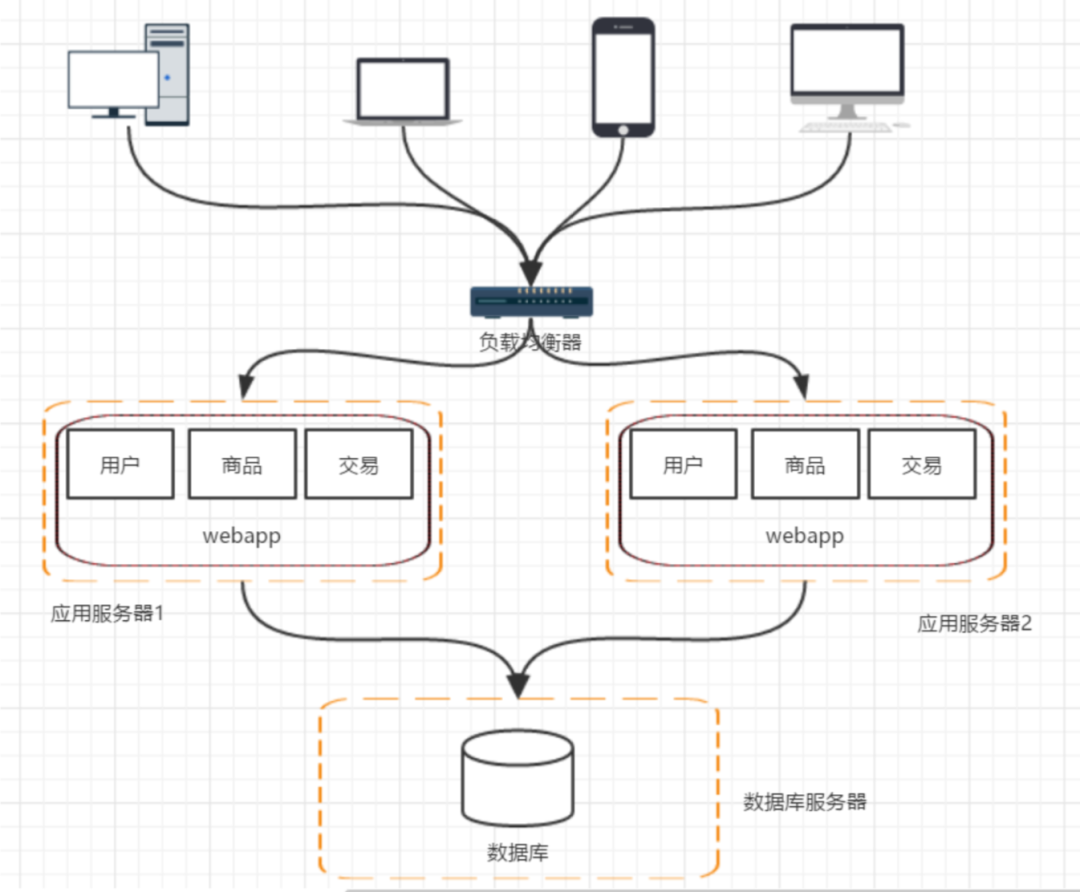
用戶請求交由誰來轉(zhuǎn)發(fā)到具體的應(yīng)用服務(wù)器上(誰來負(fù)責(zé)負(fù)載均衡) 用戶如果每次訪問到的服務(wù)器不一樣,那么如何維護(hù) session,達(dá)到session共享的目的。
六、階段四:數(shù)據(jù)庫壓力變大,數(shù)據(jù)庫讀寫分離
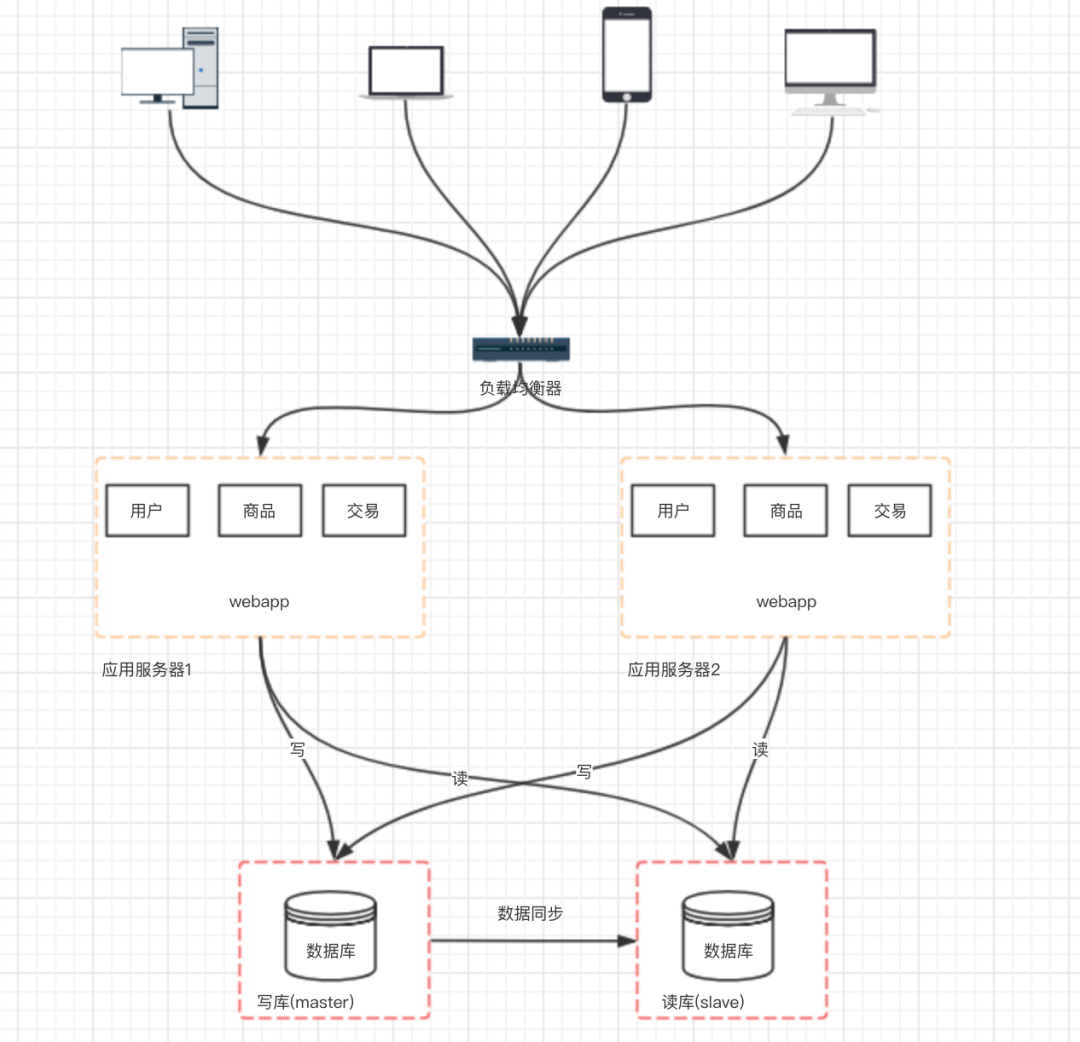
主從數(shù)據(jù)庫之間的數(shù)據(jù)需要同步(可以使用 mysql 自帶的 master-slave 方式實(shí)現(xiàn)主從復(fù)制 ) 應(yīng)用中需要根據(jù)業(yè)務(wù)進(jìn)行對應(yīng)數(shù)據(jù)源的選擇( 采用第三方數(shù)據(jù)庫中間件,例如 mycat )
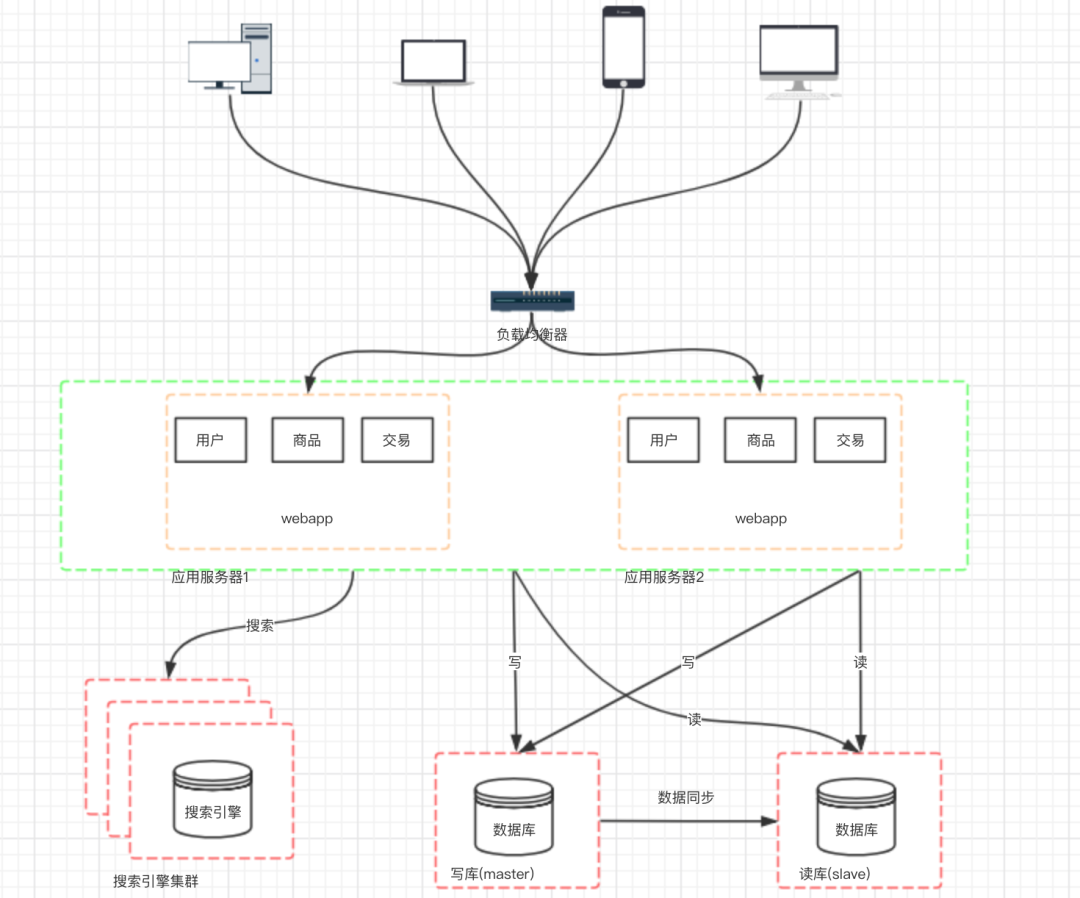
七、階段五:使用搜索引擎緩解讀庫的壓力
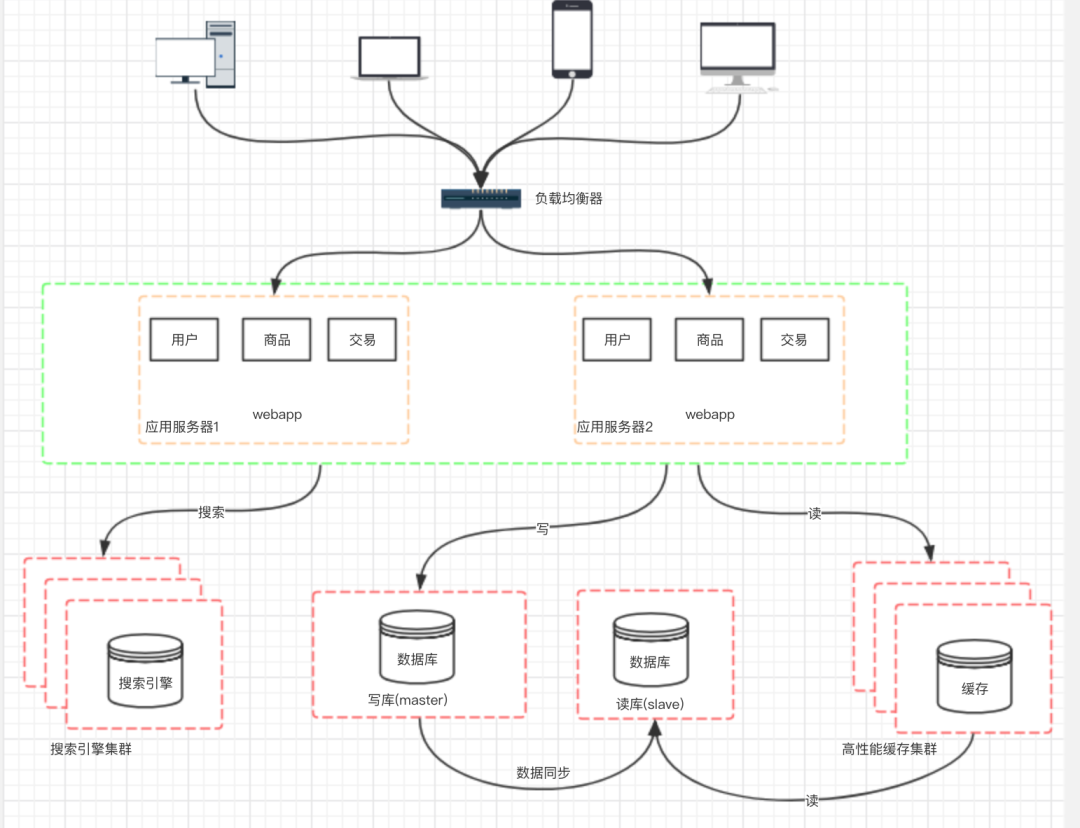
八、階段六:引入緩存機(jī)制緩解數(shù)據(jù)庫的壓力
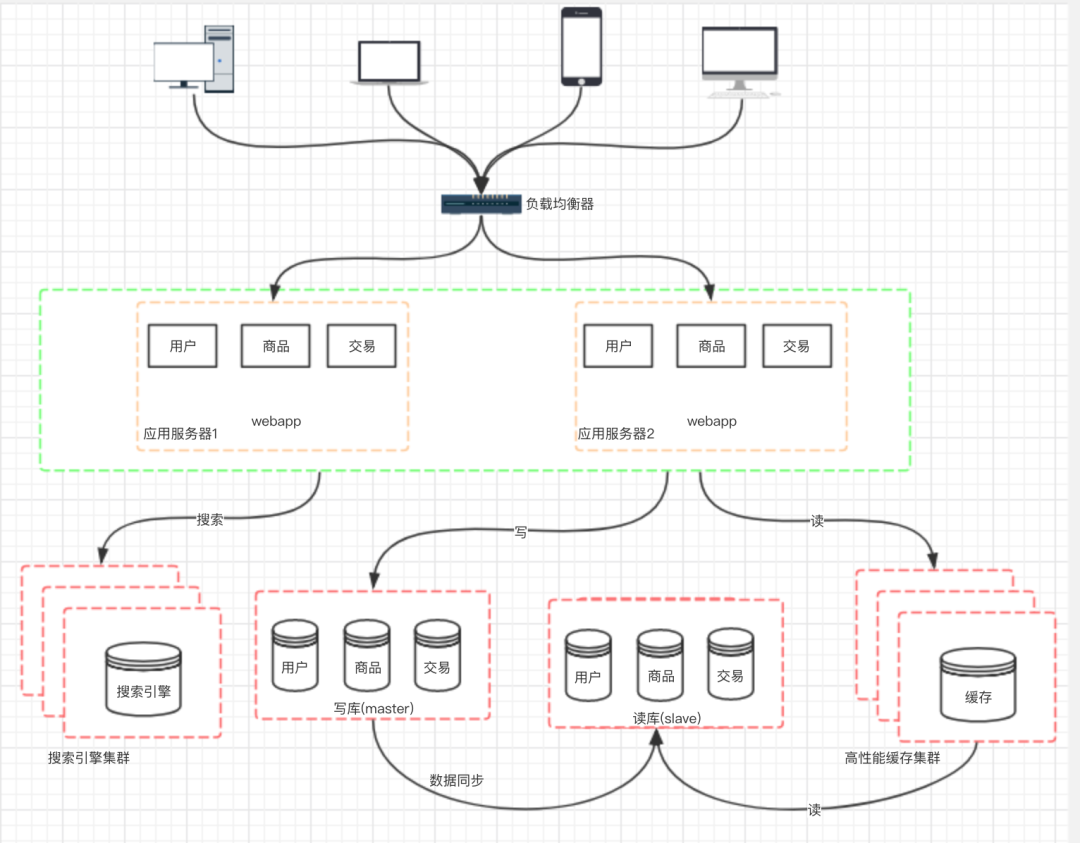
九、階段七:數(shù)據(jù)庫的水平/垂直拆分
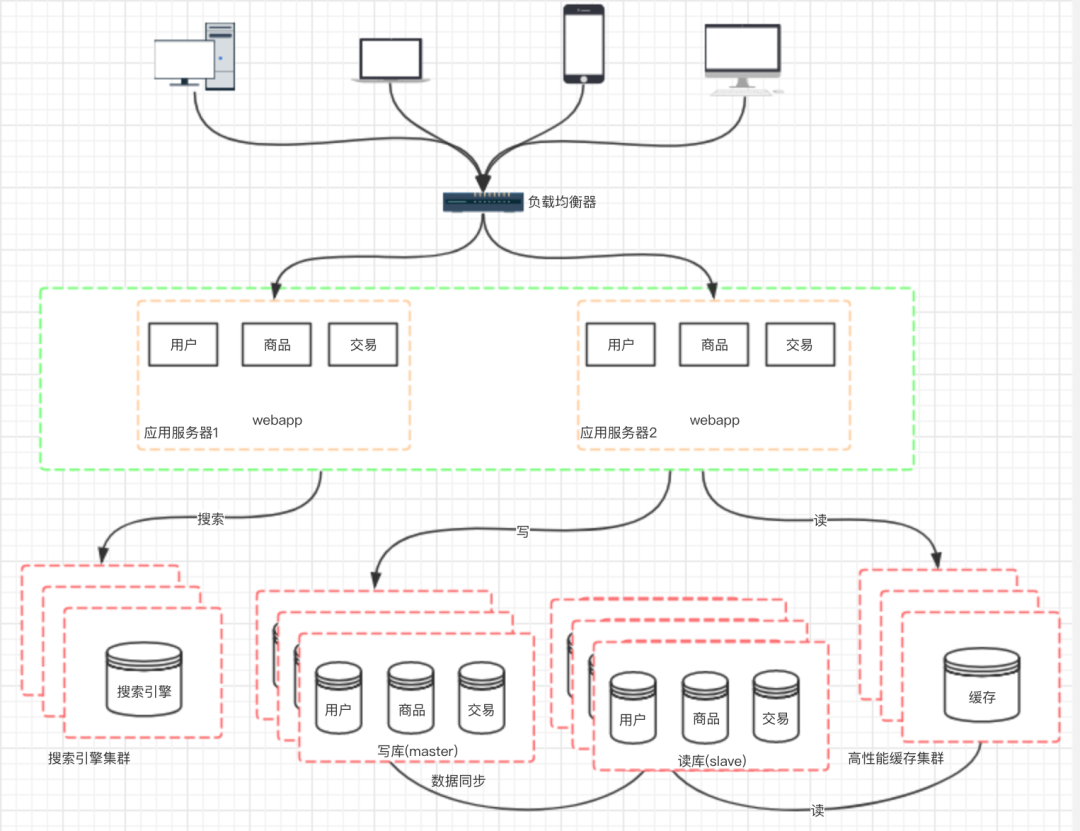
十、階段八:應(yīng)用的拆分
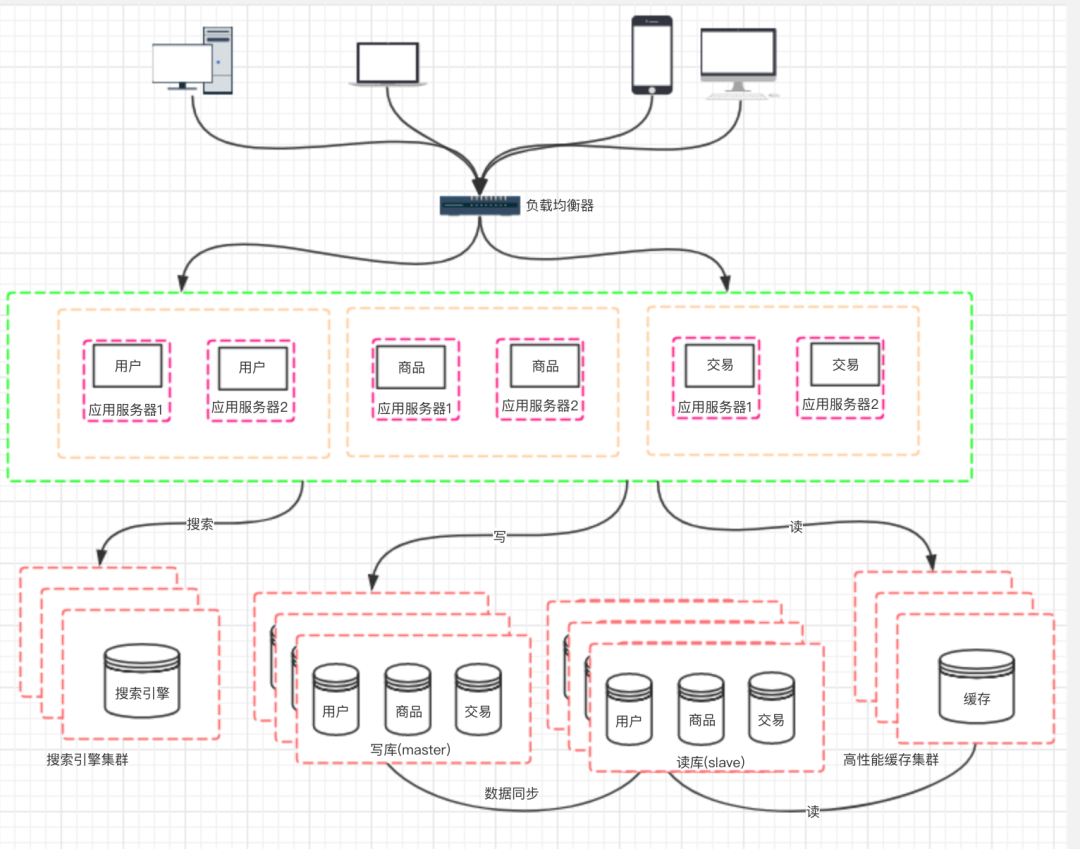
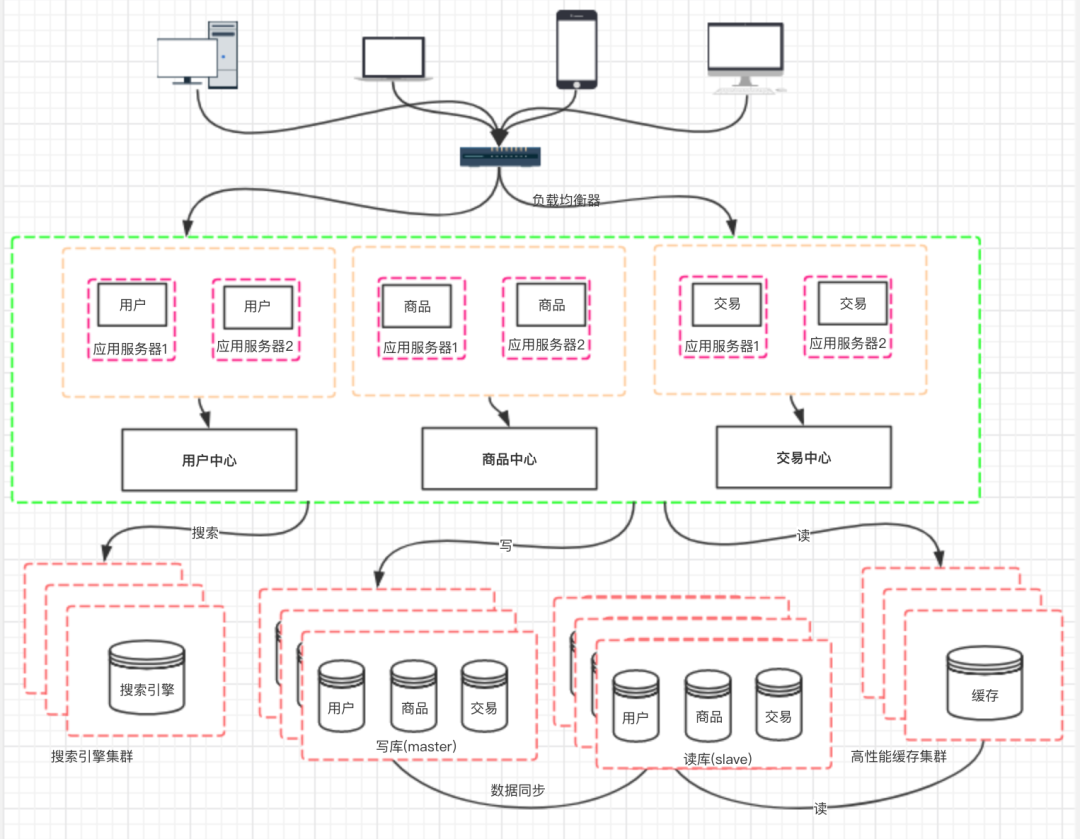
原文來自:https://www.cnblogs.com/logsharing/p/13037372.html
作者:在途中#
評論
圖片
表情