
?CVPR2021最佳學(xué)生論文提名:Less is More

極市導(dǎo)讀
本文介紹的是今年CVPR的最佳學(xué)生論文提名的工作:ClipBert。這篇論文解決了以前工作中對(duì)于視頻-語言任務(wù)訓(xùn)練消耗大、性能不高、多模態(tài)特征提取時(shí)沒有交互等問題。 >>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
【寫在前面】
本文介紹的是今年CVPR的最佳學(xué)生論文提名的工作:ClipBert。這篇論文解決了以前工作中對(duì)于視頻-語言任務(wù)訓(xùn)練消耗大、性能不高、多模態(tài)特征提取時(shí)沒有交互等問題。另外,這是一篇用Image-Text 預(yù)訓(xùn)練的模型去解決Video-Text的任務(wù)。以前的Video-Text任務(wù)大多是對(duì)視頻進(jìn)行Dense采樣,而本文通過預(yù)訓(xùn)練的Image-Text模型,對(duì)視頻進(jìn)行稀疏采樣,只需要很少的幀數(shù),就能超過密集采樣的效果,進(jìn)而提出了本文標(biāo)題中的 “Less is More”。
1. 論文和代碼地址
Less is More: CLIPBERT for Video-and-Language Learning via Sparse Sampling
論文地址:https://arxiv.org/abs/2102.06183
代碼地址:https://github.com/jayleicn/ClipBERT
2. Motivation
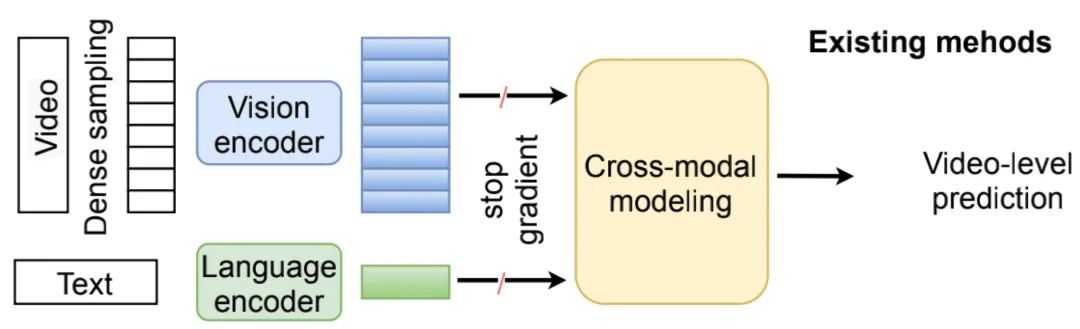
在這篇文章之前,大多數(shù)解決Video-Language任務(wù)的工作的框架圖都是如上圖所示的這樣,對(duì)視頻和語言分別提取特征,然后通過多模態(tài)信息的融合結(jié)構(gòu),將兩個(gè)模態(tài)的信息embedding到一個(gè)共同的空間。
這樣的結(jié)構(gòu)具有兩個(gè)方面的問題:
1) Disconnection in tasks/domains:缺少了任務(wù)之間的聯(lián)系,比如在動(dòng)作識(shí)別任務(wù)中提取的特征,并不一定使用于下游任務(wù)(比如:Video Captioning),由于存在任務(wù)之間的gap,這樣的特征提取方式會(huì)有導(dǎo)致sub-optimal的問題。
2) Disconnection in multimodal features:缺少了特征之間的聯(lián)系,兩個(gè)特征提取分支在提取特征過程中沒有進(jìn)行交互,導(dǎo)致視覺和語言信息并沒有得到充分聯(lián)系。
除此之外,在提取視頻特征的時(shí)候,由于相比于圖片特征,視頻會(huì)多一個(gè)時(shí)間維度,因此提取視頻特征是非常耗時(shí)、并且計(jì)算量是非常大的。

基于以上的問題,本文提出了CLIPBERT,一個(gè)端到端的視頻-語言學(xué)習(xí)框架(結(jié)構(gòu)如上圖)。相比于以前的框架,本文主要有下面幾個(gè)方面的不同:
1)以前的方法是對(duì)原始視頻以dense的方式提取特征,非常耗時(shí)、耗計(jì)算量。但是眾所周知,視頻中大多數(shù)的幀其實(shí)都是非常相似的,對(duì)這些相似的幀進(jìn)行特征提取確實(shí)比較浪費(fèi)(而且就算提取了信息,模型也不一定能夠?qū)W習(xí)到,如果模型的學(xué)習(xí)能力不夠,過多的冗余信息反而會(huì)起到反作用)。因此,本文對(duì)視頻采用稀疏采樣,只采用很少的幾張圖片。
2)如果對(duì)這些采樣的clip拼接后同時(shí)計(jì)算,這就相當(dāng)于又多了一個(gè)維度,就會(huì)增加計(jì)算的負(fù)擔(dān)。因此本文是對(duì)每一個(gè)clip分別計(jì)算后,然后再將計(jì)算結(jié)果融合,來減少計(jì)算量和顯存使用,從而來實(shí)現(xiàn)端到端的視頻-語言任務(wù)。
另外,本文還有一個(gè)創(chuàng)新點(diǎn)就是用圖片-語言數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練,然后在視頻-語言數(shù)據(jù)上微調(diào),因此本文將圖片-語言數(shù)據(jù)集上學(xué)習(xí)到的信息轉(zhuǎn)換到了視頻-語言這個(gè)下游任務(wù)中,并且效果非常好。
3. 方法
3.1. Previous work
以往的方法對(duì)于視頻-文本任務(wù),往往都是直接對(duì)密集的視頻V和文本S提取特征,每個(gè)視頻V可以被分成N個(gè)clip,因此,以前視頻-文本任務(wù)的模型可以被建模成下面的公式:
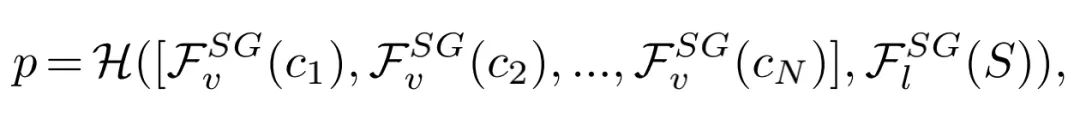
模型的損失函數(shù)為基于預(yù)測(cè)值和Ground Truth 的特定任務(wù)損失函數(shù):
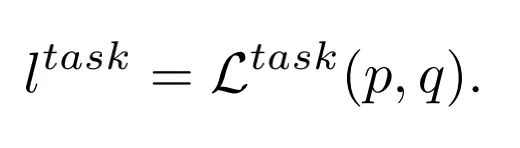
3.2. 隨機(jī)稀疏采樣
為了減少計(jì)算量,作者對(duì)視頻進(jìn)行了稀疏采樣,只采樣了很少的視頻幀數(shù),來表示視頻的信息,因此本文的模型可以用下面的公式表示(第i個(gè)clip的信息可以被表示成):
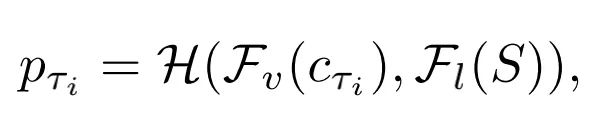
作者對(duì)每一個(gè)clip的特征分別進(jìn)行預(yù)測(cè),然后在將每個(gè)clip的預(yù)測(cè)信息進(jìn)行融合,本文模型的損失函數(shù)如下(G是聚合不同clip信息的函數(shù)):
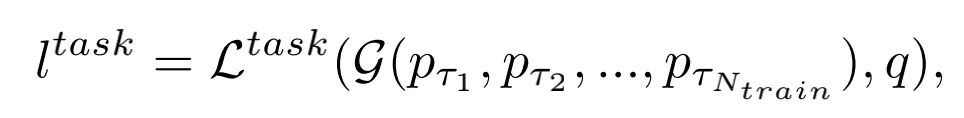
由于在訓(xùn)練中,同一視頻每次采樣的圖片并不一樣,所以本文使用的稀疏采樣方法也可以被看作是一種數(shù)據(jù)增強(qiáng)。因?yàn)樵谝酝姆椒ㄖ校怯谜麄€(gè)視頻進(jìn)行訓(xùn)練的,全部的視頻信息都暴露在模型中;而隨機(jī)稀疏采樣每次都暴露幾個(gè)clip的信息,并且每次暴露的clip還是不同的,因此就起到了數(shù)據(jù)增強(qiáng)的效果(就像CV中的Random Crop,不采用數(shù)據(jù)增強(qiáng)的話,就將整張圖片暴露給模型;如果使用Random Crop,每次都會(huì)對(duì)圖片進(jìn)行隨機(jī)裁剪,只暴露圖片的一部分信息,并且由于裁剪是隨機(jī)的,所以每次暴露的信息也是不一樣的)。
3.3. 模型結(jié)構(gòu)
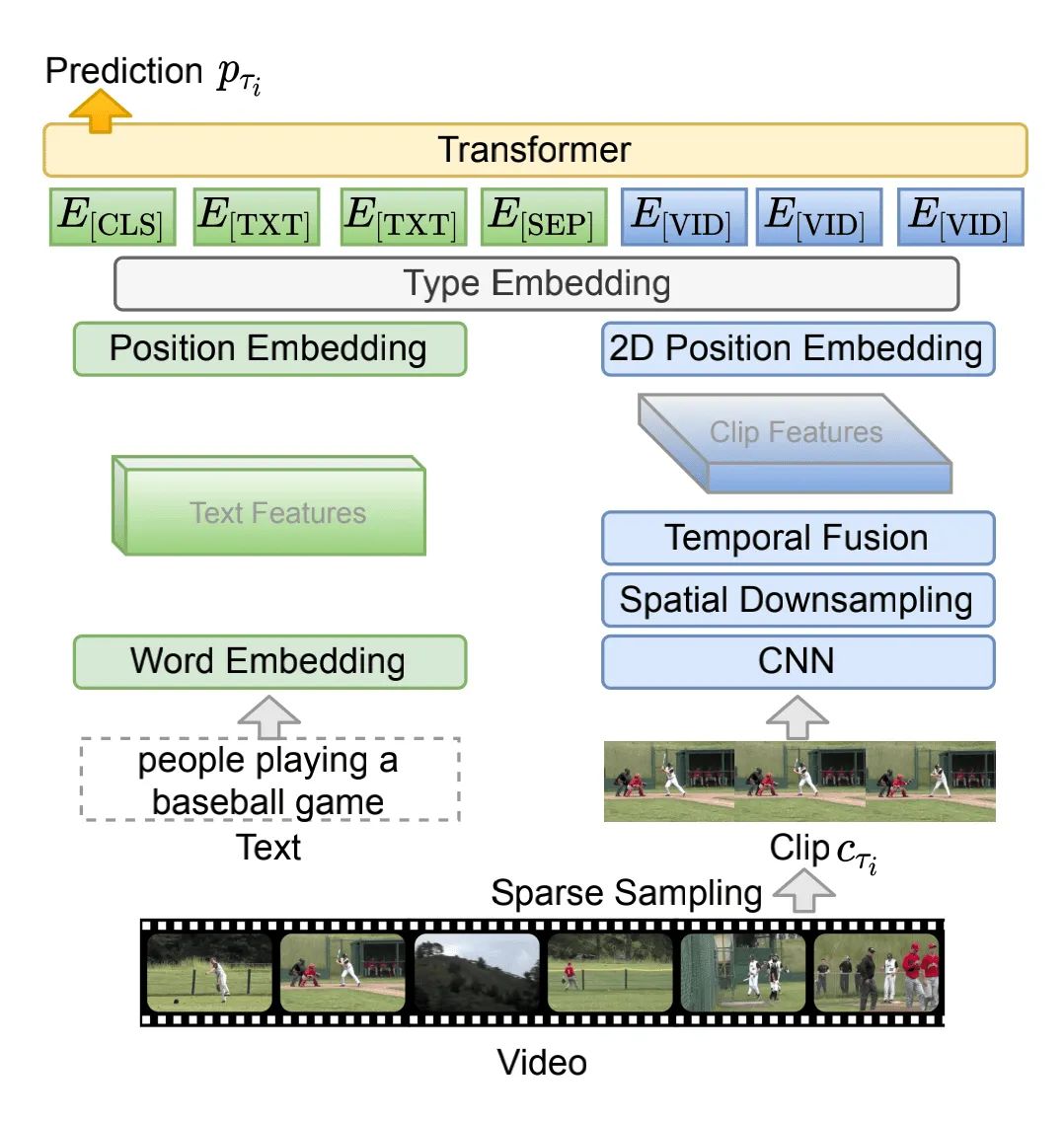
本文的模型結(jié)果如上圖所示:
對(duì)于視覺編碼器,本文采用的是2D CNN結(jié)構(gòu)ResNet-50,因?yàn)橄啾扔?D的CNN結(jié)構(gòu),2D的結(jié)構(gòu)使用的顯存更少、速度更快。
圖中的Spatial Downsampling模塊,作者采用的是2x2的max-pooling。
圖中的Temporl Fusion模塊,本文采用的mean-pooling,來聚合每個(gè)clip中T個(gè)幀的信息,得到clip級(jí)別的特征表示。
然后采用row-wise和column-wise的position embedding來實(shí)現(xiàn)2D的Position Embedding。
對(duì)于語言編碼器,作者采用了一個(gè)work embedding層進(jìn)行本文信息的映射,然后采用position embedding進(jìn)行特征位置的編碼。
接著,作者又加入了一個(gè)type embedding層,對(duì)輸入特征的類型(視覺或語言)進(jìn)行編碼。
最后,只需要讓這些視覺和語言特征進(jìn)入一個(gè)12層的Transformer中進(jìn)行訓(xùn)練即可。
4. 實(shí)驗(yàn)
4.1. Image Size
為了確定最合適的輸入圖片的大小,作者首先在Image Size上做了實(shí)驗(yàn):
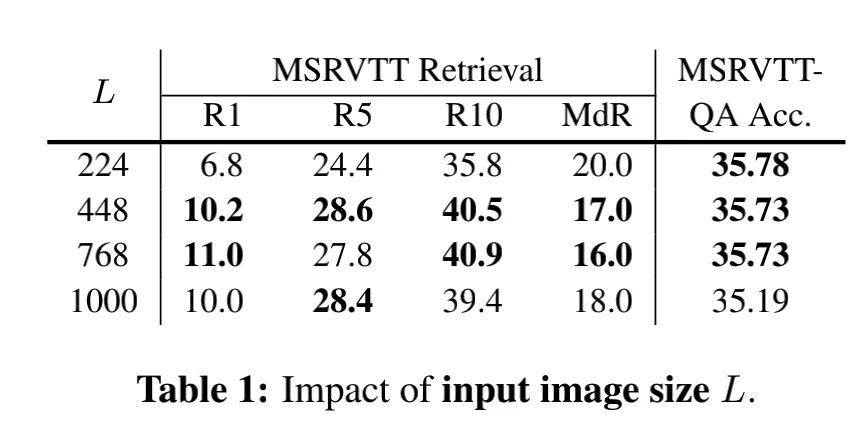
從圖中可以看出,圖片大小從224→448的過程中,性能提高顯著;但將448的圖片繼續(xù)放大,性能提升就不太顯著了,甚至部分指標(biāo)已經(jīng)開始下降了。
4.2. 幀信息的聚合
實(shí)驗(yàn)中,每個(gè)clip采樣了T幀,為了探究如何對(duì)這些幀的信息進(jìn)行聚合,獲得clip級(jí)別的特征表示,作者嘗試了以下方法:
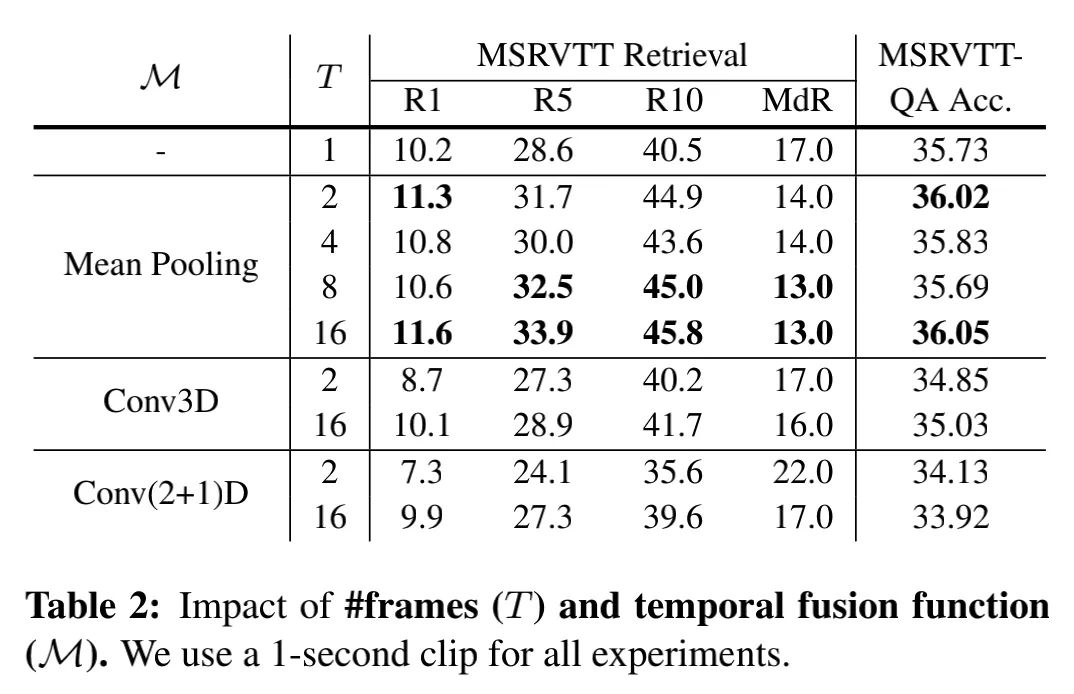
可以看出,Conv3D和Conv(2+1)D的方法明顯沒有Mean Pooling好。
4.3. 測(cè)試時(shí)的clip數(shù)量
為了探究測(cè)試時(shí)采用多少clip的信息合適,作者進(jìn)行了下面的實(shí)驗(yàn):

可以看出,clip≤4,隨著clip的增加,性能顯著提升;clip>4,隨著clip的增加,性能提升不顯著。此外,每個(gè)clip采樣兩幀明顯比采樣一幀的效果好。
4.4. 訓(xùn)練時(shí)的clip數(shù)量
為了探究訓(xùn)練時(shí)采用多少clip的信息合適,作者進(jìn)行了下面的實(shí)驗(yàn):
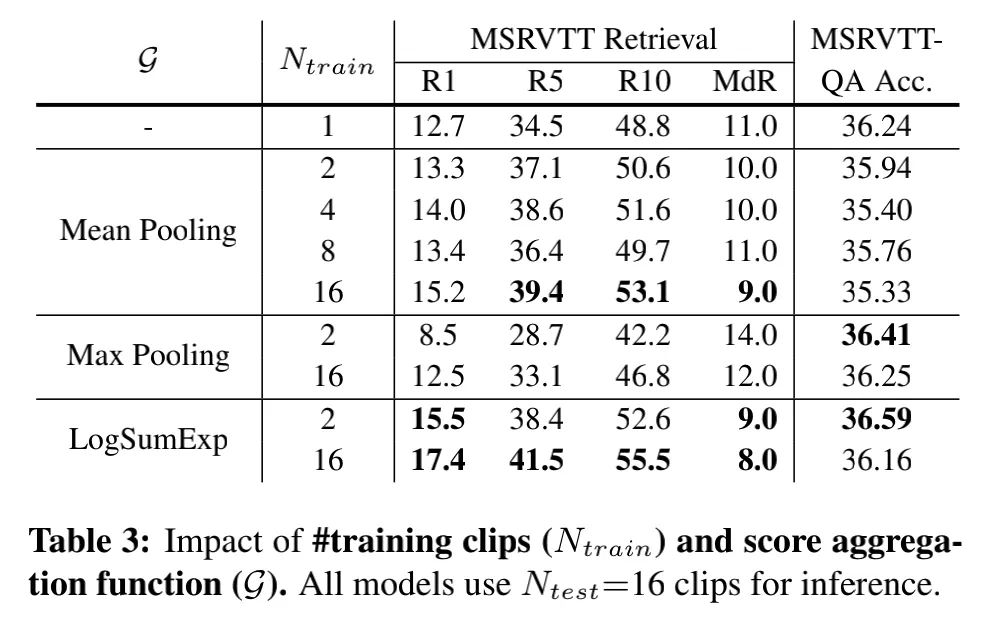
總體上來說,訓(xùn)練時(shí)clip數(shù)量從1→2時(shí),效益最顯著。比如在LogSumExp函數(shù)下,clip從1增加到2,R1高了2.8%;clip從2增加到16,R1高了1.9%。
4.5. 稀疏隨機(jī)采樣 vs.密集均勻采樣.
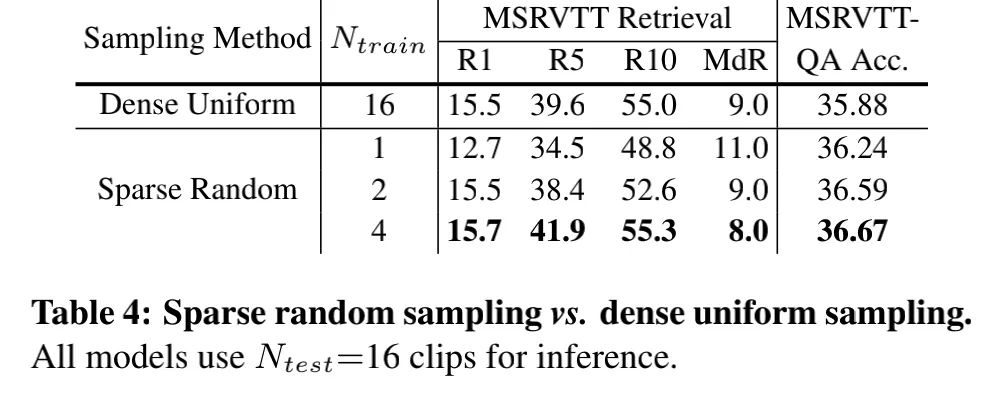
可以看出采用4幀的隨機(jī)采樣,就比16幀的均勻采樣要好。(因?yàn)殡S機(jī)采樣有了隨機(jī)性,就有數(shù)據(jù)增強(qiáng)的效果)
4.6. 相比于SOTA
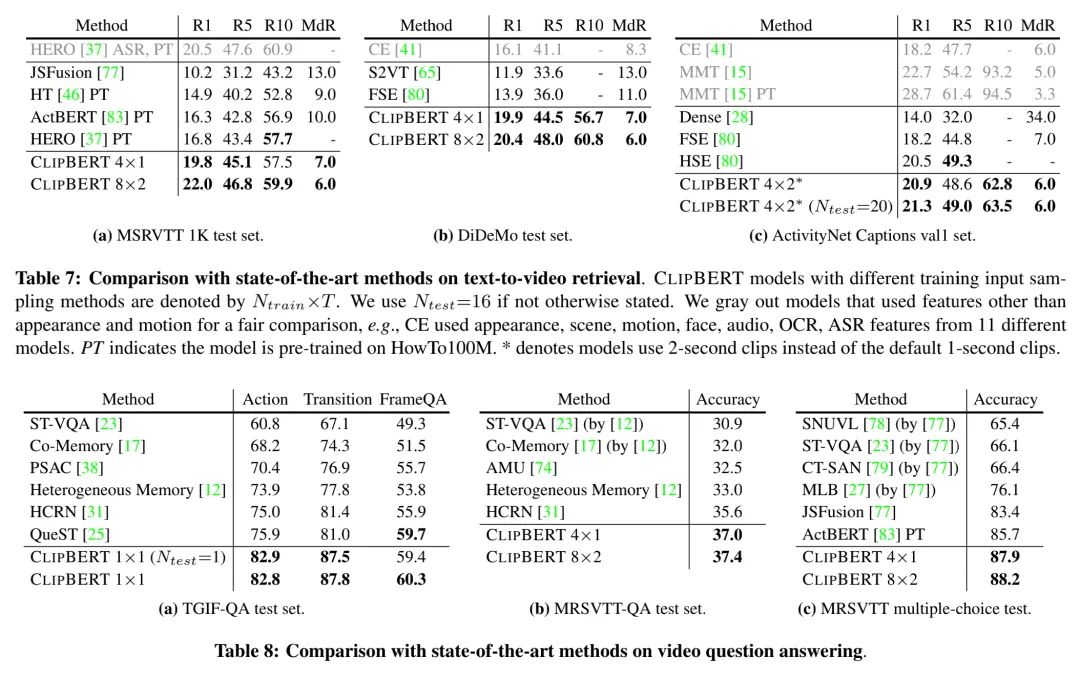
在多個(gè)視頻-語言任務(wù)上,本文提出方法的性能能夠大大超過以往的SOTA模型,證明了本文方法的有效性。
5. 總結(jié)
本文提出了一個(gè)端到端的視頻-語言訓(xùn)練框架,只采樣了視頻中的部分信息,就能超過以前密集采樣的方法,證明了“l(fā)ess is more”思想的有效性。另外,本文的方法在多個(gè)數(shù)據(jù)集、多個(gè)任務(wù)上都遠(yuǎn)遠(yuǎn)超過以前的SOTA方法。
本文亮點(diǎn)總結(jié)
如果覺得有用,就請(qǐng)分享到朋友圈吧!
公眾號(hào)后臺(tái)回復(fù)“CVPR21檢測(cè)”獲取CVPR2021目標(biāo)檢測(cè)論文下載~

# 極市原創(chuàng)作者激勵(lì)計(jì)劃 #
