
全鏈路監(jiān)控:方案概述與比較
網(wǎng)上難得的一篇關于『全鏈路』的好文,隨便可以了解一下 Google 的 Dapper。分布式跟蹤系統(tǒng)作為基礎設施,不會限制『使用線程池等會池化復用線程的組件』,并期望對業(yè)務邏輯盡可能的透明。從技術能力上講,「全鏈路壓測」 與 「分布式跟蹤系統(tǒng)」 是一樣的,即鏈路打標。
對了,這里作者沒有深入對比 skywalking ,個人推薦 skywalking 。
?
一、問題背景
隨著微服務架構(gòu)的流行,「服務按照不同的維度進行拆分」,一次請求往往需要涉及到多個服務。「互聯(lián)網(wǎng)應用構(gòu)建在不同的軟件模塊集上」,這些軟件模塊,「有可能是由不同的團隊開發(fā)、可能使用不同的編程語言來實現(xiàn)、有可能布在了幾千臺服務器,橫跨多個不同的數(shù)據(jù)中心」。因此,就需要一些可以幫助理解系統(tǒng)行為、用于分析性能問題的工具,以便發(fā)生故障的時候,能夠快速定位和解決問題。
全鏈路監(jiān)控組件就在這樣的問題背景下產(chǎn)生了。最出名的是谷歌公開的論文提到的 Google Dapper。「想要在這個上下文中理解分布式系統(tǒng)的行為,就需要監(jiān)控那些橫跨了不同的應用、不同的服務器之間的關聯(lián)動作。」所以,「在復雜的微服務架構(gòu)系統(tǒng)中,幾乎每一個前端請求都會形成一個復雜的分布式服務調(diào)用鏈路」。一個請求完整調(diào)用鏈可能如下圖所示: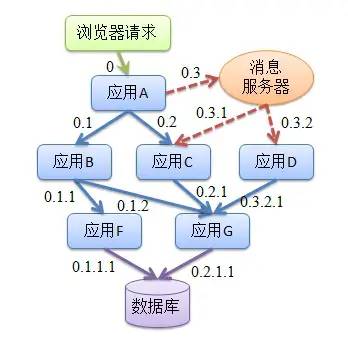
那么在業(yè)務規(guī)模不斷增大、服務不斷增多以及頻繁變更的情況下,面對復雜的調(diào)用鏈路就帶來一系列問題:
??
如何快速發(fā)現(xiàn)問題? 如何判斷故障影響范圍? 如何梳理服務依賴以及依賴的合理性? 如何分析鏈路性能問題以及實時容量規(guī)劃?
「同時我們會關注在請求處理期間各個調(diào)用的各項性能指標」,比如:吞吐量(TPS)、響應時間及錯誤記錄等。
??
吞吐量,根據(jù)拓撲可計算相應組件、平臺、物理設備的實時吞吐量。 響應時間,包括整體調(diào)用的響應時間和各個服務的響應時間等。 錯誤記錄,根據(jù)服務返回統(tǒng)計單位時間異常次數(shù)。
全鏈路性能監(jiān)控 「從整體維度到局部維度展示各項指標」,將跨應用的所有調(diào)用鏈性能信息集中展現(xiàn),可方便度量整體和局部性能,并且方便找到故障產(chǎn)生的源頭,生產(chǎn)上可極大縮短故障排除時間。
「有了全鏈路監(jiān)控工具,我們能夠達到:」
??
請求鏈路追蹤,故障快速定位:可以通過調(diào)用鏈結(jié)合業(yè)務日志快速定位錯誤信息。2.可視化:各個階段耗時,進行性能分析。3.依賴優(yōu)化:各個調(diào)用環(huán)節(jié)的可用性、梳理服務依賴關系以及優(yōu)化。4.數(shù)據(jù)分析,優(yōu)化鏈路:可以得到用戶的行為路徑,匯總分析應用在很多業(yè)務場景。
二、目標要求
如上所述,那么我們選擇全鏈路監(jiān)控組件有哪些目標要求呢?Google Dapper 中也提到了,總結(jié)如下:
1、探針的性能消耗
APM組件服務的影響應該做到足夠小。「服務調(diào)用埋點本身會帶來性能損耗,這就需要調(diào)用跟蹤的低損耗,實際中還會通過配置采樣率的方式,選擇一部分請求去分析請求路徑。」 在一些高度優(yōu)化過的服務,即使一點點損耗也會很容易察覺到,而且有可能迫使在線服務的部署團隊不得不將跟蹤系統(tǒng)關停。
2、代碼的侵入性
「即也作為業(yè)務組件,應當盡可能少入侵或者無入侵其他業(yè)務系統(tǒng),對于使用方透明,減少開發(fā)人員的負擔。」對于應用的程序員來說,是不需要知道有跟蹤系統(tǒng)這回事的。如果一個跟蹤系統(tǒng)想生效,就必須需要依賴應用的開發(fā)者主動配合,那么這個跟蹤系統(tǒng)也太脆弱了,往往由于跟蹤系統(tǒng)在應用中植入代碼的 bug 或疏忽導致應用出問題,這樣才是無法滿足對跟蹤系統(tǒng)“無所不在的部署”這個需求。
3、可擴展性
「一個優(yōu)秀的調(diào)用跟蹤系統(tǒng)必須支持分布式部署,具備良好的可擴展性。能夠支持的組件越多當然越好。」 或者提供便捷的插件開發(fā)API,對于一些沒有監(jiān)控到的組件,應用開發(fā)者也可以自行擴展。
4、數(shù)據(jù)的分析
「數(shù)據(jù)的分析要快 ,分析的維度盡可能多。」 跟蹤系統(tǒng)能提供足夠快的信息反饋,就可以對生產(chǎn)環(huán)境下的異常狀況做出快速反應。「分析的全面,能夠避免二次開發(fā)。」
三、功能模塊
一般的全鏈路監(jiān)控系統(tǒng),大致可分為四大功能模塊:
1、埋點與生成日志
埋點即系統(tǒng)在當前節(jié)點的上下文信息,可以分為 「客戶端埋點、服務端埋點,以及客戶端和服務端雙向型埋點。」 埋點日志通常要包含以下內(nèi)容 traceId、spanId、調(diào)用的開始時間,協(xié)議類型、調(diào)用方ip和端口,請求的服務名、調(diào)用耗時,調(diào)用結(jié)果,異常信息等,同時預留可擴展字段,為下一步擴展做準備;
?「不能造成性能負擔:」 一個價值未被驗證,卻會影響性能的東西,是很難在公司推廣的!因為要寫 log,業(yè)務 QPS 越高,性能影響越重。「通過采樣和異步 log 解決。」
?
2、收集和存儲日志
主要支持分布式日志采集的方案,同時增加 MQ 作為緩沖;
??
每個機器上有一個 「deamon」 做日志收集,業(yè)務進程把自己的 Trace 發(fā)到 daemon,daemon 把收集 Trace 往上一級發(fā)送; 「多級的 collector」,類似 pub/sub 架構(gòu),可以負載均衡; 對聚合的數(shù)據(jù)進行 「實時分析和離線存儲」; 「離線分析」 需要將同一條調(diào)用鏈的日志匯總在一起;
3、分析和統(tǒng)計調(diào)用鏈路數(shù)據(jù),以及時效性
「調(diào)用鏈跟蹤分析」:把同一 TraceID 的 Span 收集起來,按時間排序就是timeline。把** ParentID 串起來就是調(diào)用棧**。
拋異常或者超時,在日志里打印 TraceID。利用 TraceID 查詢調(diào)用鏈情況,定位問題。
「依賴度量」:
??
「強依賴」:調(diào)用失敗會直接中斷主流程 「高度依賴」:一次鏈路中調(diào)用某個依賴的幾率高 「頻繁依賴」:一次鏈路調(diào)用同一個依賴的次數(shù)多
「離線分析」:按 TraceID 匯總,通過 Span 的 ID 和 ParentID 還原調(diào)用關系,分析鏈路形態(tài)。「實時分析」:對單條日志直接分析,不做匯總,重組。得到當前 QPS,延遲。
4、展現(xiàn)以及決策支持
四、Google Dapper
1、Span
「基本工作單元」,一次鏈路調(diào)用(可以是 RPC,DB 等沒有特定的限制)創(chuàng)建一個 span,通過一個 64 位 ID 標識它,uuid 較為方便,span 中還有其他的數(shù)據(jù),例如描述信息,時間戳,key-value 對的(Annotation)tag 信息,parent_id 等,其中 parent-id 可以表示span調(diào)用鏈路來源。

上圖說明了 span 在一次大的跟蹤過程中是什么樣的。「Dapper 記錄了 span 名稱,以及每個 span 的 ID 和父 ID,以重建在一次追蹤過程中不同 span 之間的關系」。如果一個 span 沒有父 ID 被稱為 root span。所有 span 都掛在一個特定的跟蹤上,也共用一個跟蹤 id。
「Span 數(shù)據(jù)結(jié)構(gòu):」
type Span struct {
TraceID int64 // 用于標示一次完整的請求id
Name string
ID int64 // 當前這次調(diào)用span_id
ParentID int64 // 上層服務的調(diào)用span_id 最上層服務parent_id為null
Annotation []Annotation // 用于標記的時間戳
Debug bool
}
2、Trace
類似于 「樹結(jié)構(gòu)的 Span 集合」,表示一次完整的跟蹤,從請求到服務器開始,服務器返回 response 結(jié)束,跟蹤每次 rpc 調(diào)用的耗時,存在唯一標識 trace_id。比如:你運行的分布式大數(shù)據(jù)存儲一次 Trace 就由你的一次請求組成。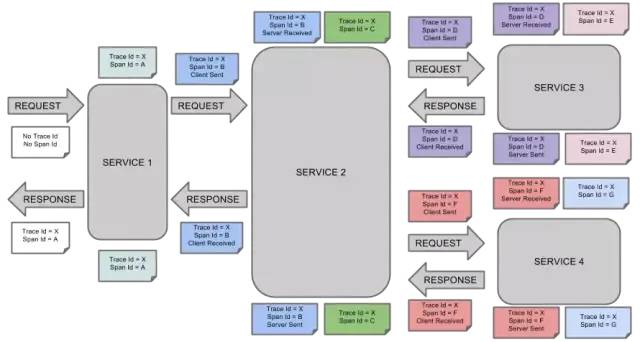
每種顏色的 note 標注了一個 span,一條鏈路通過 TraceId唯一標識,Span 標識發(fā)起的請求信息。「樹節(jié)點是整個架構(gòu)的基本單元,而每一個節(jié)點又是對 span 的引用」。節(jié)點之間的連線表示的 span 和它的父 span 直接的關系。雖然 span 在日志文件中只是簡單的代表 span 的開始和結(jié)束時間,他們在整個樹形結(jié)構(gòu)中卻是相對獨立的。
4、Annotation
「注解,用來記錄請求特定事件相關信息(例如時間),一個 span 中會有多個 annotation 注解描述」。通常包含四個注解信息:
??
(1) cs:Client Start,表示客戶端發(fā)起請求 (2) sr:Server Receive,表示服務端收到請求 (3) ss:Server Send,表示服務端完成處理,并將結(jié)果發(fā)送給客戶端 (4) cr:Client Received,表示客戶端獲取到服務端返回信息
「Annotation 數(shù)據(jù)結(jié)構(gòu):」
type Annotation struct {
Timestamp int64
Value string
Host Endpoint
Duration int32
}
5、調(diào)用示例
5.1、請求調(diào)用示例
1.當用戶發(fā)起一個請求時,首先到達前端 A 服務,然后分別對 B 服務和 C 服務進行 RPC 調(diào)用;2.B 服務處理完給 A 做出響應,但是 C 服務還需要和后端的 D 服務和E服務交互之后再返還給 A 服務,最后由 A 服務來響應用戶的請求;
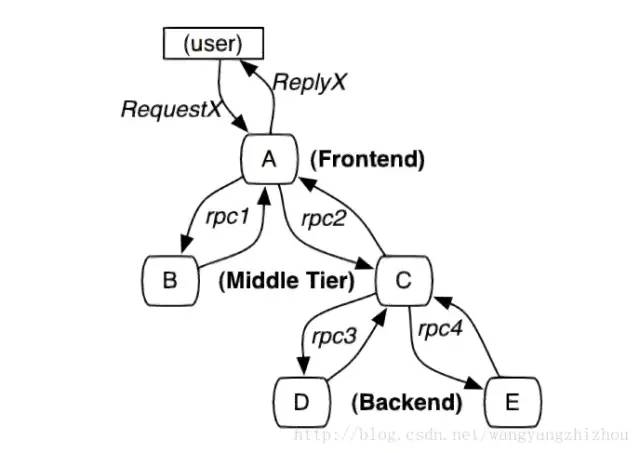
5.2、調(diào)用過程追蹤
**請求到來生成一個全局 TraceID **,通過 TraceID 可以串聯(lián)起整個調(diào)用鏈,一個 TraceID 代表一次請求。 除了 TraceID 外,「還需要 SpanID 用于記錄調(diào)用父子關系」。每個服務會記錄下 parent id 和span id,通過他們可以組織一次完整調(diào)用鏈的父子關系。 一個沒有 parent id 的 span 成為 root span,可以看成調(diào)用鏈入口。 所有這些 ID 可用全局唯一的 64 位整數(shù)表示; 「整個調(diào)用過程中每個請求都要透傳 TraceID 和 SpanID。」 每個服務將該次請求附帶的 TraceID 和附帶的 SpanID 作為 parent id 記錄下,并且將自己生成的 SpanID 也記錄下。 要查看某次完整的調(diào)用則 「只要根據(jù) TraceID 查出所有調(diào)用記錄,然后通過 parent id 和 span id 組織起整個調(diào)用父子關系」。 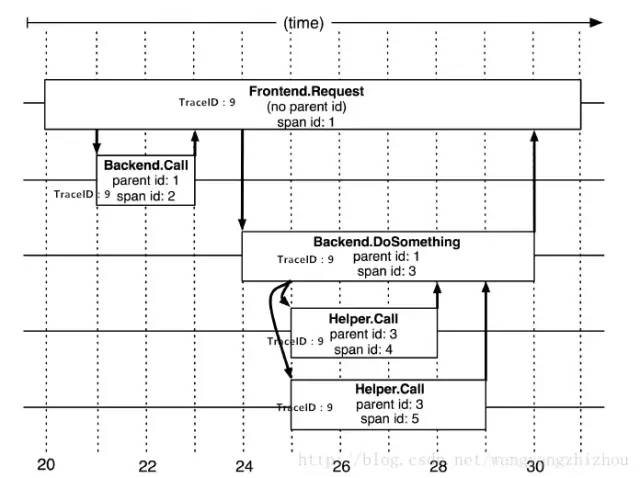
5.3、調(diào)用鏈核心工作
「調(diào)用鏈數(shù)據(jù)生成」,對整個調(diào)用過程的所有應用進行埋點并輸出日志。 「調(diào)用鏈數(shù)據(jù)采集」,對各個應用中的日志數(shù)據(jù)進行采集。 「調(diào)用鏈數(shù)據(jù)存儲及查詢」,對采集到的數(shù)據(jù)進行存儲,由于日志數(shù)據(jù)量一般都很大,不僅要能對其存儲,還需要能提供快速查詢。 「指標運算、存儲及查詢」,對采集到的日志數(shù)據(jù)進行各種指標運算,將運算結(jié)果保存起來。 「告警功能」,提供各種閥值警告功能。
5.4、整體部署架構(gòu)
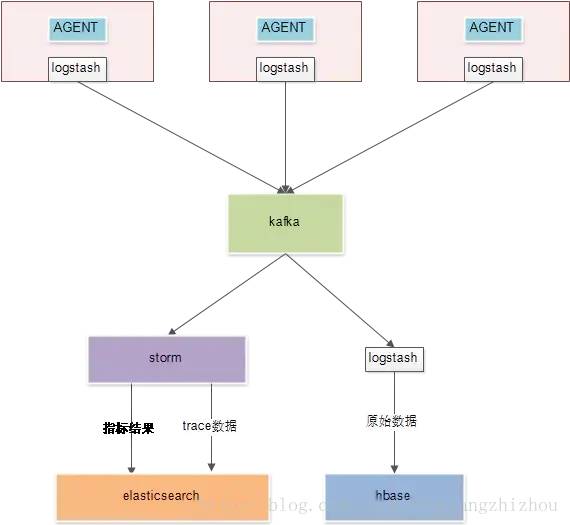
??
通過 AGENT 生成調(diào)用鏈日志。 通過 logstash 采集日志到 kafka。 kafka 負責提供數(shù)據(jù)給下游消費。 storm 計算匯聚指標結(jié)果并落到 es。 「storm 抽取 trace 數(shù)據(jù)并落到 es,這是為了提供比較復雜的查詢」 。比如通過時間維度查詢調(diào)用鏈,可以很快查詢出所有符合的 traceID,「根據(jù)這些 traceID 再去 Hbase 查數(shù)據(jù)就快了」。 logstash 將 kafka 原始數(shù)據(jù)拉取到 hbase中。「hbase 的 rowkey 為 traceID,根據(jù) traceID 查詢是很快的」。
5.5、AGENT 無侵入部署
通過 AGENT 代理無侵入式部署,將性能測量與業(yè)務邏輯完全分離,可以測量任意類的任意方法的執(zhí)行時間,這種方式大大提高了采集效率,并且減少運維成本。
「根據(jù)服務跨度主要分為兩大類 AGENT」:
??
「服務內(nèi) AGENT」,這種方式是通過 Java 的 agent 機制,對服務內(nèi)部的方法調(diào)用層次信息進行數(shù)據(jù)收集,如方法調(diào)用耗時、入?yún)ⅰ⒊鰠⒌刃畔ⅰ?/section> 「跨服務 AGENT」,這種情況需要對主流 RPC 框架以插件形式提供無縫支持。并通過提供標準數(shù)據(jù)規(guī)范以適應自定義RPC框架:- Dubbo 支持;- Rest 支持;- 自定義 RPC 支持;
5.6、調(diào)用鏈監(jiān)控好處
「準確掌握生產(chǎn)一線應用部署情況;」 從調(diào)用鏈全流程性能角度,「識別對關鍵調(diào)用鏈,并進行優(yōu)化;」 「提供可追溯的性能數(shù)據(jù)」,量化 IT 運維部門業(yè)務價值; 「快速定位代碼性能問題」,協(xié)助開發(fā)人員持續(xù)性的優(yōu)化代碼; 「協(xié)助開發(fā)人員進行白盒測試」,縮短系統(tǒng)上線穩(wěn)定期;
五、方案比較
市面上的全鏈路監(jiān)控理論模型大多都是借鑒 Google Dapper 論文,本文重點關注以下三種 APM 組件:
Zipkin:由 Twitter 公司開源,開放源代碼分布式的跟蹤系統(tǒng),用于收集服務的定時數(shù)據(jù),以解決微服務架構(gòu)中的延遲問題,包括:數(shù)據(jù)的收集、存儲、查找和展現(xiàn)。 Pinpoint:一款對 Java 編寫的大規(guī)模分布式系統(tǒng)的 APM 工具,由韓國人開源的分布式跟蹤組件。 Skywalking:國產(chǎn)的優(yōu)秀 APM 組件,是一個對 JAVA 分布式應用程序集群的業(yè)務運行情況進行追蹤、告警和分析的系統(tǒng)。
「以上三種全鏈路監(jiān)控方案需要對比的項提煉出來:」
「探針的性能」主要是 agent 對服務的吞吐量、CPU 和內(nèi)存的影響。微服務的規(guī)模和動態(tài)性使得數(shù)據(jù)收集的成本大幅度提高。 「collector的可擴展性」能夠水平擴展以便支持大規(guī)模服務器集群。 「全面的調(diào)用鏈路數(shù)據(jù)分析」提供代碼級別的可見性以便輕松定位失敗點和瓶頸。 「對于開發(fā)透明,容易開關」添加新功能而無需修改代碼,容易啟用或者禁用。 「完整的調(diào)用鏈應用拓撲」自動檢測應用拓撲,幫助你搞清楚應用的架構(gòu)
1、探針的性能
比較關注探針的性能,畢竟 APM 定位還是工具,如果啟用了鏈路監(jiān)控組建后,直接導致吞吐量降低過半,那也是不能接受的。對 skywalking、zipkin、pinpoint 進行了壓測,并與基線(未使用探針)的情況進行了對比。
選用了一個常見的基于 Spring 的應用程序,他包含 Spring Boot, Spring MVC,redis 客戶端,mysql。監(jiān)控這個應用程序,每個trace,探針會抓取5個 span(1 Tomcat, 1 SpringMVC, 2 Jedis, 1 Mysql)。這邊基本和 skywalkingtest 的測試應用差不多。
模擬了三種并發(fā)用戶:500,750,1000。使用 jmeter 測試,每個線程發(fā)送 30 個請求,設置思考時間為 10ms。使用的采樣率為1,即100%,這邊與生產(chǎn)可能有差別。pinpoint 默認的采樣率為 20,即 50%,通過設置 agent 的配置文件改為 100%。zipkin 默認也是1。組合起來,一共有 12 種。下面看下匯總表:
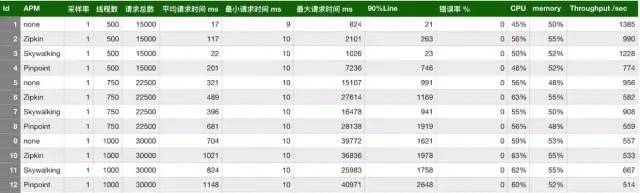
從上表可以看出,在三種鏈路監(jiān)控組件中,「skywalking 的探針對吞吐量的影響最小,zipkin 的吞吐量居中。pinpoint 的探針對吞吐量的影響較為明顯,在 500 并發(fā)用戶時,測試服務的吞吐量從 1385 降低到 774,影響很大」。然后再看下 CPU 和memory 的影響,在內(nèi)部服務器進行的壓測,對 CPU 和 memory 的影響都差不多在 10 %之內(nèi)。
2、collector 的可擴展性
collecto r的可擴展性,使得能夠水平擴展以便支持大規(guī)模服務器集群。
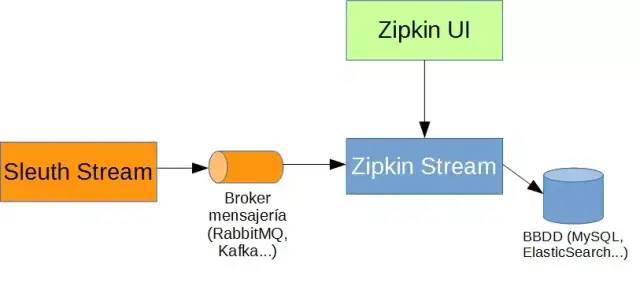
「zipkin」開發(fā)zipkin-Server(其實就是提供的開箱即用包),zipkin-agent 與 zipkin-Server 通過 http 或者 mq 進行通信,「http 通信會對正常的訪問造成影響,所以還是推薦基于 mq 異步方式通信」,zipkin-Server 通過訂閱具體的 topic 進行消費。這個當然是可以擴展的,「多個 zipkin-Server 實例進行異步消費 mq 中的監(jiān)控信息」。
「skywalking」skywalking 的 collector 支持兩種部署方式:「單機和集群模式。collector 與 agent 之間的通信使用了 gRPC」。
「pinpoint」同樣,pinpoint 也是支持集群和單機部署的。「pinpoint agent 通過 thrift 通信框架,發(fā)送鏈路信息到 collector」。
3、 全面的調(diào)用鏈路數(shù)據(jù)分析
全面的調(diào)用鏈路數(shù)據(jù)分析,提供代碼級別的可見性以便輕松定位失敗點和瓶頸。
zipkin 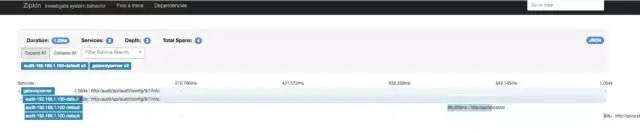 「zipkin 的鏈路監(jiān)控粒度相對沒有那么細」,從上圖可以看到調(diào)用鏈中具體到接口級別,再進一步的調(diào)用信息并未涉及。
「zipkin 的鏈路監(jiān)控粒度相對沒有那么細」,從上圖可以看到調(diào)用鏈中具體到接口級別,再進一步的調(diào)用信息并未涉及。skywalking「skywalking 還支持 20 +的中間件、框架、類庫,比如:主流的 dubbo、Okhttp,還有 DB 和消息中間件」。上圖 skywalking鏈路調(diào)用分析截取的比較簡單,網(wǎng)關調(diào)用 user 服務,「由于支持眾多的中間件,所以 skywalking 鏈路調(diào)用分析比 zipkin 完備些」。 
pinpoint 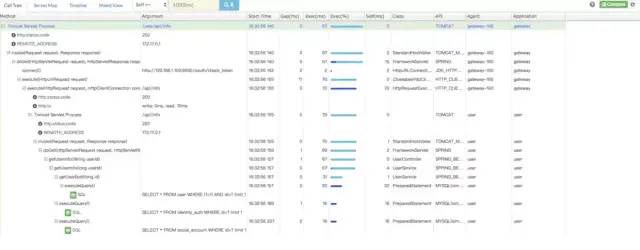 pinpoint 應該是這三種 APM 組件中,「數(shù)據(jù)分析最為完備的組件」。提供代碼級別的可見性以便輕松定位失敗點和瓶頸,上圖可以看到對于執(zhí)行的 sql 語句,都進行了記錄。還可以配置報警規(guī)則等,設置每個應用對應的負責人,根據(jù)配置的規(guī)則報警,支持的中間件和框架也比較完備。
pinpoint 應該是這三種 APM 組件中,「數(shù)據(jù)分析最為完備的組件」。提供代碼級別的可見性以便輕松定位失敗點和瓶頸,上圖可以看到對于執(zhí)行的 sql 語句,都進行了記錄。還可以配置報警規(guī)則等,設置每個應用對應的負責人,根據(jù)配置的規(guī)則報警,支持的中間件和框架也比較完備。
4、 對于開發(fā)透明,容易開關
對于開發(fā)透明,容易開關,添加新功能而無需修改代碼,容易啟用或者禁用。我們期望功能可以不修改代碼就工作并希望得到代碼級別的可見性。對于這一點,「Zipkin 使用修改過的類庫和它自己的容器(Finagle)來提供分布式事務跟蹤的功能」。但是,它要求在需要時修改代碼。「skywalking 和 pinpoint 都是基于字節(jié)碼增強的方式,開發(fā)人員不需要修改代碼,并且可以收集到更多精確的數(shù)據(jù)因為有字節(jié)碼中的更多信息。」
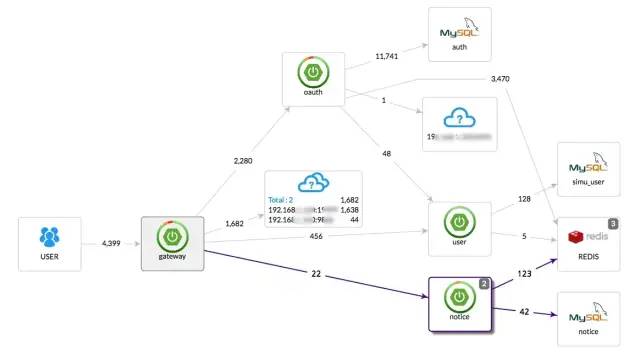
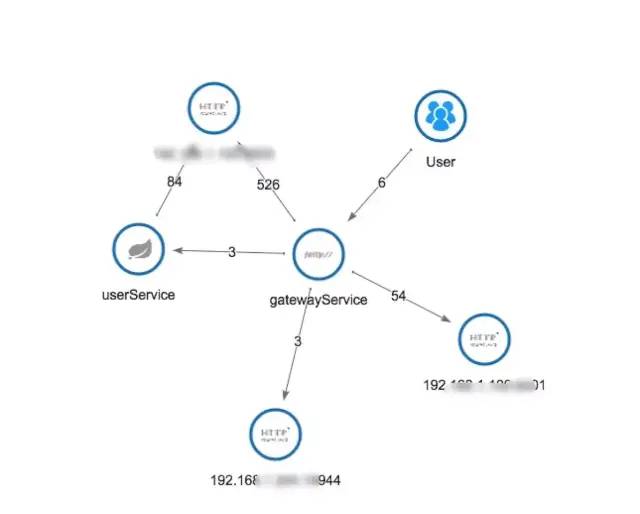
5、完整的調(diào)用鏈應用拓撲
自動檢測應用拓撲,幫助你搞清楚應用的架構(gòu)。

6、 Pinpoint 與 Zipkin 細化比較
6.1、 Pinpoint 與 Zipkin 差異性
「Pinpoint 是一個完整的性能監(jiān)控解決方案」:有從探針、收集器、存儲到 Web 界面等全套體系;「而 Zipkin 只側(cè)重收集器和存儲服務」,雖然也有用戶界面,但其功能與 Pinpoint 不可同日而語。「反而 Zipkin 提供有 Query 接口」,更強大的用戶界面和系統(tǒng)集成能力,可以基于該接口二次開發(fā)實現(xiàn)。 「Zipkin 官方提供有基于 Finagle 框架(Scala 語言)的接口」,而其他框架的接口由社區(qū)貢獻,目前可以支持 Java、Scala、Node、Go、Python、Ruby 和 C# 等主流開發(fā)語言和框架;「但是 Pinpoint 目前只有官方提供的 Java Agent 探針」,其他的都在請求社區(qū)支援中(請參見 #1759 和 #1760)。 Pinpoint 提供有 Java Agent 探針,通過字節(jié)碼注入的方式實現(xiàn)調(diào)用攔截和數(shù)據(jù)收集,「可以做到真正的代碼無侵入,只需要在啟動服務器的時候添加一些參數(shù),就可以完成探針的部署;而 Zipkin 的 Java 接口實現(xiàn) Brave」,只提供了基本的操作 API,如果需要與框架或者項目集成的話,「就需要手動添加配置文件或增加代碼」。 P「inpoint 的后端存儲基于 HBase,而 Zipkin 基于 Cassandra。」
6.2、 Pinpoint 與 Zipkin 相似性
Pinpoint 與 Zipkin 都是基于 Google Dapper 的那篇論文,因此理論基礎大致相同。「兩者都是將服務調(diào)用拆分成若干有級聯(lián)關系的 Span,通過 SpanId 和 ParentSpanId 來進行調(diào)用關系的級聯(lián);最后再將整個調(diào)用鏈流經(jīng)的所有的 Span 匯聚成一個 Trace,報告給服務端的 collector 進行收集和存儲。」
即便在這一點上,Pinpoint 所采用的概念也不完全與那篇論文一致。比如他采用 **TransactionId 來取代 TraceId,而真正的 TraceId 是一個結(jié)構(gòu),里面包含了 TransactionId, SpanId 和 ParentSpanId。**而且 Pinpoint 在 Span 下面又增加了一個 SpanEvent 結(jié)構(gòu),用來記錄一個 Span 內(nèi)部的調(diào)用細節(jié)(比如具體的方法調(diào)用等等),「因此 Pinpoint 默認會比 Zipkin 記錄更多的跟蹤數(shù)據(jù)」。但是理論上并沒有限定 Span 的粒度大小,所以一個服務調(diào)用可以是一個 Span,那么每個服務中的方法調(diào)用也可以是個 Span,這樣的話,「其實 Brave 也可以跟蹤到方法調(diào)用級別,只是具體實現(xiàn)并沒有這樣做而已」。
6.3、 字節(jié)碼注入 vs API 調(diào)用
Pinpoint 實現(xiàn)了基于字節(jié)碼注入的 Java Agent 探針,而 Zipkin 的 Brave 框架僅僅提供了應用層面的 API,但是細想問題遠不那么簡單。「字節(jié)碼注入是一種簡單粗暴的解決方案,理論上來說無論任何方法調(diào)用,都可以通過注入代碼的方式實現(xiàn)攔截,也就是說沒有實現(xiàn)不了的,只有不會實現(xiàn)的」。但 Brave 則不同,「其提供的應用層面的 API 還需要框架底層驅(qū)動的支持,才能實現(xiàn)攔截」。比如,MySQL 的 JDBC 驅(qū)動,就提供有注入 interceptor 的方法,因此只需要實現(xiàn) StatementInterceptor 接口,并在 Connection String 中進行配置,就可以很簡單的實現(xiàn)相關攔截;而與此相對的,低版本的 MongoDB 的驅(qū)動或者是 Spring Data MongoDB 的實現(xiàn)就沒有如此接口,想要實現(xiàn)攔截查詢語句的功能,就比較困難。
因此在這一點上,Brave 是硬傷,無論使用字節(jié)碼注入多么困難,但至少也是可以實現(xiàn)的,但是 Brave 卻有無從下手的可能,而且是否可以注入,能夠多大程度上注入,更多的取決于框架的 API 而不是自身的能力。
6.4、 難度及成本
經(jīng)過簡單閱讀 Pinpoint 和 Brave 插件的代碼,可以發(fā)現(xiàn)兩者的實現(xiàn)難度有天壤之別。「在都沒有任何開發(fā)文檔支撐的前提下,Brave 比 Pinpoint 更容易上手」。Brave 的代碼量很少,核心功能都集中在 brave-core 這個模塊下,一個中等水平的開發(fā)人員,可以在一天之內(nèi)讀懂其內(nèi)容,并且能對 API 的結(jié)構(gòu)有非常清晰的認識。
Pinpoint 的代碼封裝也是非常好的,尤其是針對字節(jié)碼注入的上層 API 的封裝非常出色,但是這依然要求閱讀人員對字節(jié)碼注入多少有一些了解,雖然其用于注入代碼的核心 API 并不多,但要想了解透徹,恐怕還得深入 Agent 的相關代碼,比如很難一目了然的理解 addInterceptor 和 addScopedInterceptor 的區(qū)別,而這兩個方法就是位于 Agent 的有關類型中。
「因為 Brave 的注入需要依賴底層框架提供相關接口,因此并不需要對框架有一個全面的了解,只需要知道能在什么地方注入,能夠在注入的時候取得什么數(shù)據(jù)就可以了。」 就像上面的例子,我們根本不需要知道 MySQL 的 JDBC Driver 是如何實現(xiàn)的也可以做到攔截 SQL 的能力。但是 Pinpoint 就不然,因為 Pinpoint 幾乎可以在任何地方注入任何代碼,這需要開發(fā)人員對所需注入的庫的代碼實現(xiàn)有非常深入的了解,通過查看其 MySQL 和 Http Client 插件的實現(xiàn)就可以洞察這一點,當然這也從另外一個層面說明 Pinpoint 的能力確實可以非常強大,而且其默認實現(xiàn)的很多插件已經(jīng)做到了非常細粒度的攔截。
「針對底層框架沒有公開 API 的時候,其實 Brave 也并不完全無計可施,我們可以采取 AOP 的方式,一樣能夠?qū)⑾嚓P攔截注入到指定的代碼中,而且顯然 AOP 的應用要比字節(jié)碼注入簡單很多。」
以上這些直接關系到實現(xiàn)一個監(jiān)控的成本,在 Pinpoint 的官方技術文檔中,給出了一個參考數(shù)據(jù)。**如果對一個系統(tǒng)集成的話,那么用于開發(fā) Pinpoint 插件的成本是 100,將此插件集成入系統(tǒng)的成本是 0;但對于 Brave,插件開發(fā)的成本只有 20,而集成成本是 10。**從這一點上可以看出官方給出的成本參考數(shù)據(jù)是 5:1。但是官方又強調(diào)了,如果有 10 個系統(tǒng)需要集成的話,那么總成本就是 10 * 10 + 20 = 120,就超出了 Pinpoint 的開發(fā)成本 100,而且需要集成的服務越多,這個差距就越大。
6.5、 通用性和擴展性
很顯然,這一點上 Pinpoint 完全處于劣勢,從社區(qū)所開發(fā)出來的集成接口就可見一斑。
Pinpoint 的數(shù)據(jù)接口缺乏文檔,而且也不太標準(參考論壇討論帖),需要閱讀很多代碼才可能實現(xiàn)一個自己的探針(比如 Node 的或者 PHP 的)。而且團隊為了性能考慮使用了 Thrift 作為數(shù)據(jù)傳輸協(xié)議標準,比起 HTTP 和 JSON 而言難度增加了不少。
6.6、 社區(qū)支持
這一點也不必多說,Zipkin 由 Twitter 開發(fā),可以算得上是明星團隊,而 Naver 的團隊只是一個默默無聞的小團隊(從 #1759 的討論中可以看出)。雖然說這個項目在短期內(nèi)不太可能消失或停止更新,但畢竟不如前者用起來更加放心。而且沒有更多社區(qū)開發(fā)出來的插件,「讓 Pinpoint 只依靠團隊自身的力量完成諸多框架的集成實屬困難,而且他們目前的工作重點依然是在提升性能和穩(wěn)定性上。」
6.7、 其他
Pinpoint 在實現(xiàn)之初就考慮到了性能問題,www.naver.com 網(wǎng)站的后端某些服務每天要處理超過 200 億次的請求,因此他們會選擇 Thrift 的二進制變長編碼格式、而且使用 UDP 作為傳輸鏈路,同時在傳遞常量的時候也盡量使用數(shù)據(jù)參考字典,傳遞一個數(shù)字而不是直接傳遞字符串等等。這些優(yōu)化也增加了系統(tǒng)的復雜度:包括使用 Thrift 接口的難度、UDP 數(shù)據(jù)傳輸?shù)膯栴}、以及數(shù)據(jù)常量字典的注冊問題等等。
相比之下,Zipkin 使用熟悉的 Restful 接口加 JSON,幾乎沒有任何學習成本和集成難度,只要知道數(shù)據(jù)傳輸結(jié)構(gòu),就可以輕易的為一個新的框架開發(fā)出相應的接口。
另外 「Pinpoint 缺乏針對請求的采樣能力,顯然在大流量的生產(chǎn)環(huán)境下,不太可能將所有的請求全部記錄,這就要求對請求進行采樣,以決定什么樣的請求是我需要記錄的」。Pinpoint 和 Brave 都支持采樣百分比,也就是百分之多少的請求會被記錄下來。但是,「除此之外 Brave 還提供了 Sampler 接口,可以自定義采樣策略」,尤其是當進行 A/B 測試的時候,這樣的功能就非常有意義了。
6.8、 總結(jié)
從短期目標來看,Pinpoint 確實具有壓倒性的優(yōu)勢:「無需對項目代碼進行任何改動就可以部署探針、追蹤數(shù)據(jù)細粒化到方法調(diào)用級別、功能強大的用戶界面以及幾乎比較全面的 Java 框架支持」。但是長遠來看,學習 Pinpoint 的開發(fā)接口,以及未來為不同的框架實現(xiàn)接口的成本都還是個未知數(shù)。「相反,掌握 Brave 就相對容易,而且 Zipkin 的社區(qū)更加強大,更有可能在未來開發(fā)出更多的接口」。在最壞的情況下,我們也可以自己通過 AOP 的方式添加適合于我們自己的監(jiān)控代碼,而并不需要引入太多的新技術和新概念。而且在未來業(yè)務發(fā)生變化的時候,Pinpoint 官方提供的報表是否能滿足要求也不好說,增加新的報表也會帶來不可以預測的工作難度和工作量。
六、Tracing 和 Monitor 區(qū)別
「Monitor 可分為系統(tǒng)監(jiān)控和應用監(jiān)控」。系統(tǒng)監(jiān)控比如CPU,內(nèi)存,網(wǎng)絡,磁盤等等整體的系統(tǒng)負載的數(shù)據(jù),細化可具體到各進程的相關數(shù)據(jù)。這一類信息是直接可以從系統(tǒng)中得到的。「應用監(jiān)控需要應用提供支持,暴露了相應的數(shù)據(jù)」。比如應用內(nèi)部請求的 QPS,請求處理的延時,請求處理的error數(shù),消息隊列的隊列長度,崩潰情況,進程垃圾回收信息等等。「Monitor主要目標是發(fā)現(xiàn)異常,及時報警。」
「Tracing的基礎和核心都是調(diào)用鏈。」 相關的 metric 大多都是圍繞調(diào)用鏈分析得到的。「Tracing主要目標是系統(tǒng)分析。提前找到問題比出現(xiàn)問題后再去解決更好。」Tracing 和應用級的 Monitor 技術棧上有很多共同點。都有數(shù)據(jù)的采集,分析,存儲和展式。只是具體收集的數(shù)據(jù)維度不同,分析過程不一樣。
原文地址:https://juejin.cn/post/6844903560732213261
推薦閱讀:
華為內(nèi)網(wǎng)最火的文章:什么是內(nèi)卷?