愛奇藝全鏈路自動化監(jiān)控平臺的探索與實踐
點擊“開發(fā)者技術(shù)前線”,選擇“星標(biāo)?”
讓一部分開發(fā)者看到未來

1
互聯(lián)網(wǎng)技術(shù)普及過程中,數(shù)據(jù)的監(jiān)控對每個公司都很重要。近些年,隨著一些優(yōu)秀監(jiān)控工具(比如Zabbix、Graphite、Prometheus)的成熟,每個公司都會搭建自己的監(jiān)控體系,來分析整體業(yè)務(wù)流量和應(yīng)對異常報警。但隨著系統(tǒng)復(fù)雜性的提高,微服務(wù)的成熟,監(jiān)控又有了新的問題需要解決,如上下文的鏈路關(guān)系、跨系統(tǒng)的故障定位等相關(guān)問題。
為減輕公司業(yè)務(wù)線資源和開發(fā)的監(jiān)控壓力,愛奇藝技術(shù)產(chǎn)品團隊研發(fā)了一套全鏈路自動化監(jiān)控平臺,可以提供統(tǒng)一的監(jiān)控標(biāo)準(zhǔn)和基礎(chǔ)的監(jiān)控能力,增強故障定位和深度分析能力,提升監(jiān)控準(zhǔn)確性和透明性,本文將基于監(jiān)控一些經(jīng)驗,和大家分享全鏈路自動化監(jiān)控平臺。
2
近些年ELK Stack、Cat、以及Google Dapper等監(jiān)控工具在機器數(shù)據(jù)分析實時日志處理領(lǐng)域,也都在嘗試解決一些新問題,我們對此做了分析,總結(jié)來看,ELK Stack重依賴ES,存儲能力和查詢能力較難擴展。Cat側(cè)重于Java后端。基于Google Dapper的全鏈路監(jiān)控思想相對成熟,但多數(shù)開源實現(xiàn)的介紹缺少深度分析,查詢性能比較差,見下圖:
維度 | ELK Stack | Cat | Pinpoint/SkyWalking |
可視化 | 弱 | 一般 | 一般 |
報表 | 豐富 | 豐富 | 中 |
指標(biāo) | 無 | 有 | 無 |
拓撲 | 無 | 簡單依賴圖 | 好 |
埋點 | Logstash/Beats | 侵入 | 無侵入,字節(jié)碼增強 |
大查詢 | 弱 | 弱 | 弱 |
社區(qū) | 好,有中文 | 好,文檔豐富 | 一般,文檔缺,無中文 |
案例 | 很多公司 | 攜程、點評、陸金所、獵聘網(wǎng) | 暫無 |
源頭 | ELK | aBay CAL | Google Dapper |
另一方面看,隨著微服務(wù)的成熟,實時監(jiān)控更加重要,Prometheus等基礎(chǔ)監(jiān)控解決了基本指標(biāo)和報警問題,部分全鏈路監(jiān)控的實現(xiàn)解決鏈路追蹤的問題,但兩者各司其職,是互相的補充,卻未融成統(tǒng)一的全鏈路監(jiān)控平臺。
基于對這些工具的分析,我們以現(xiàn)有的基礎(chǔ)監(jiān)控和日志采集為基礎(chǔ),融合Google Dapper思想,形成了統(tǒng)一的全鏈路自動化監(jiān)控平臺,并且可靈活快速接入公司的其他業(yè)務(wù)。對Google Dapper的改造,我們加入了緩存和離線處理的部分,大大提升了查詢性能;加入了深度分析部分,能夠自動診斷用戶具體的報障;在改造鏈路UI展示的基礎(chǔ)上,加入了監(jiān)控指標(biāo),在看服務(wù)鏈路的同時能看到監(jiān)控指標(biāo),體驗升級并更易發(fā)現(xiàn)性能瓶頸,可指導(dǎo)資源伸縮、可看到容量預(yù)警。
下面我們總結(jié)出全鏈路監(jiān)控的四部分:鏈路采集、指標(biāo)采集、日志采集、深度分析,并在全鏈路監(jiān)控平臺中一一落地。
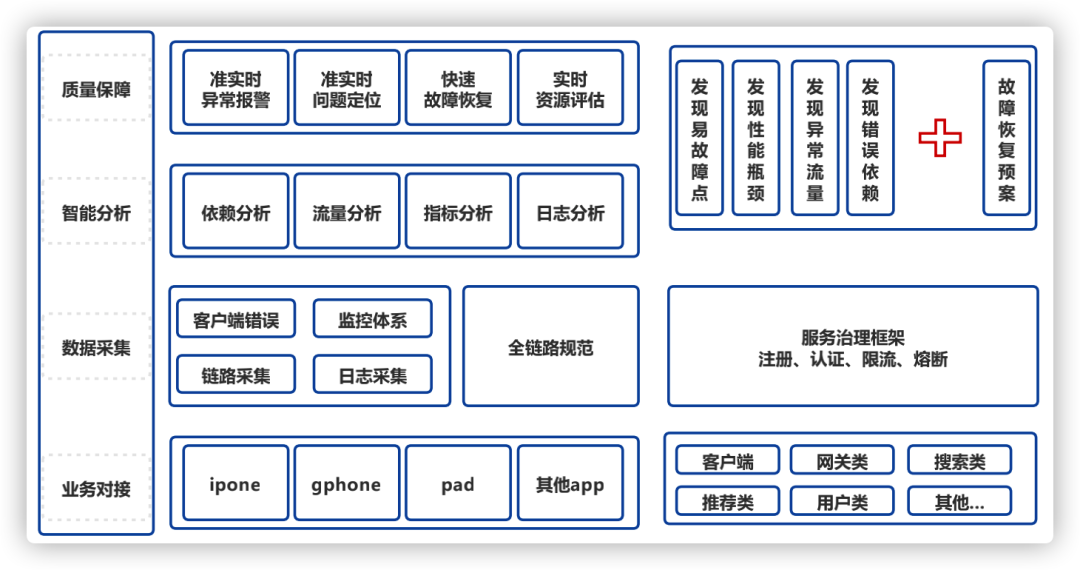
圖1整體實踐
3
總體概覽
鏈路采集包括調(diào)用鏈和服務(wù)拓撲,是全鏈路分析的串聯(lián)器。
指標(biāo)采集整合到服務(wù)鏈路上,使全鏈路具備基礎(chǔ)監(jiān)控能力。
日志采集的數(shù)據(jù)源,也是全鏈路分析的數(shù)據(jù)源。
深度分析包括離線、在線模塊,滿足全鏈路的問題定位需求。
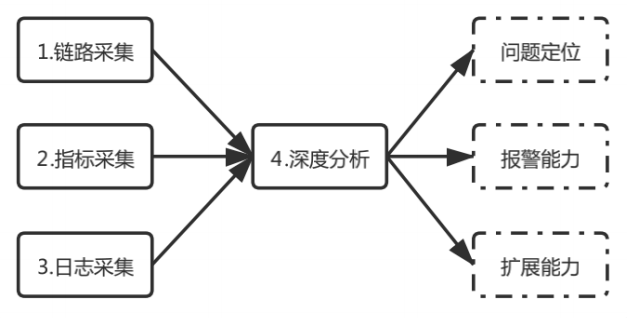
圖2全鏈路分析流程
鏈路采集
? ?鏈路采集,分為調(diào)用關(guān)系鏈和服務(wù)拓撲兩部分:
調(diào)用關(guān)系鏈:兩個系統(tǒng)之間的調(diào)用,稱之為Span,每個Span會記錄服務(wù)信息和上下文信息。串聯(lián)Span關(guān)系的字段是Trace id,是每個請求產(chǎn)生的唯一算法值。調(diào)用鏈?zhǔn)怯啥鄠€Span組成的有向無環(huán)圖(DAG),表示了一次請求的完整處理過程。圖中的每一個節(jié)點代表的是一個Span,圖中的邊表示的是不同服務(wù)(或服務(wù)內(nèi)部)的調(diào)用關(guān)系。通過深度分析Span,我們就能得到每個請求的調(diào)用鏈。 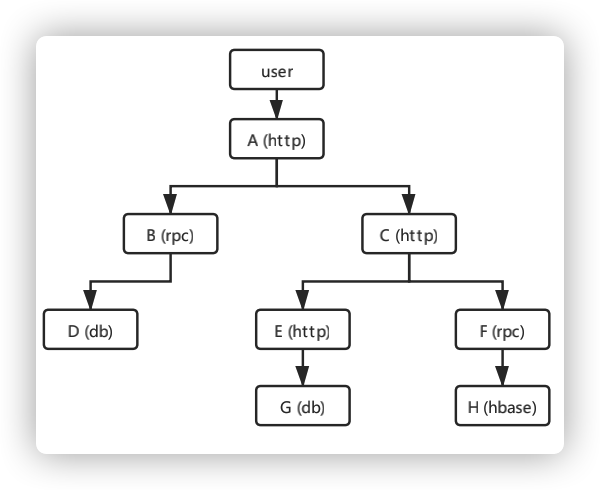
圖3 有向無環(huán)圖DAG
????????① 代碼侵入模式
????????按照規(guī)范,在相關(guān)組件手動埋點投遞。
????????② 無侵入模式(保證應(yīng)用級的透明)
????????支持Java、Go、Lua等Agent,原理采用探針技術(shù),對客戶端應(yīng)用程序沒有任何代碼入侵,使用方便易于對接。
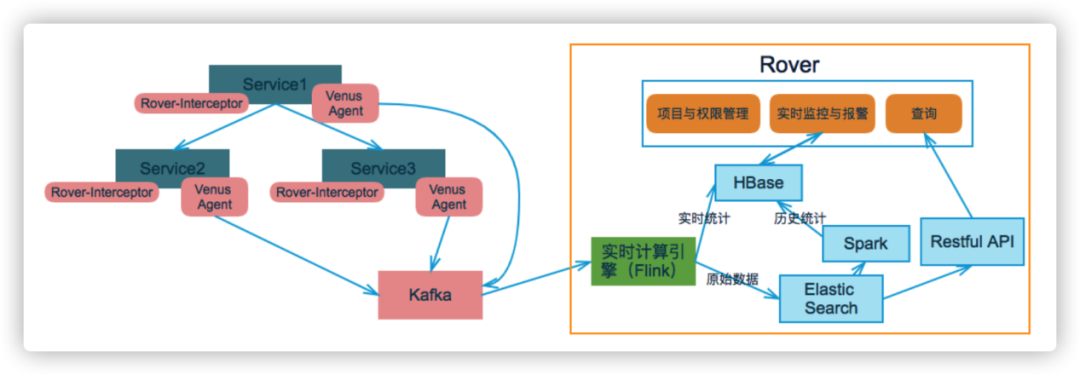
圖4 鏈路采集架構(gòu)圖
我們的設(shè)計
1)鏈路分析基礎(chǔ)能力:
① 具備調(diào)用鏈檢索能力,有具體到接口級別的Trace鏈路,可根據(jù)Trace id來查看調(diào)用關(guān)系。? ?
② 調(diào)用關(guān)系中包含每個節(jié)點的響應(yīng)時間,請求方法和參數(shù)、以及自定義的Tag等信息,方便查詢和優(yōu)化鏈路。
2)鏈路分析優(yōu)化:
服務(wù)鏈路拓撲?ELK Stack的Kibana沒有服務(wù)拓撲能力。業(yè)界的Skywalking、Zipkin等,具備了服務(wù)拓撲能力但可視化比較弱,功能單一,而且目前看到的全鏈路實現(xiàn),均未加入客戶端節(jié)點。
我們的設(shè)計
包裝了客戶端日志,在鏈路中加上前端節(jié)點;在Skywalking基礎(chǔ)上,升級了UI頁面增強交互和視覺;存儲組件從關(guān)系型數(shù)據(jù)庫改為圖數(shù)據(jù)庫,使得UI有更多的邏輯展示空間和更快的響應(yīng)速度。最終補全整體鏈路,提供更友好的可視化(比如我們支持三層展示:首先業(yè)務(wù)線、業(yè)務(wù)線內(nèi)的服務(wù)、服務(wù)內(nèi)的調(diào)用)。
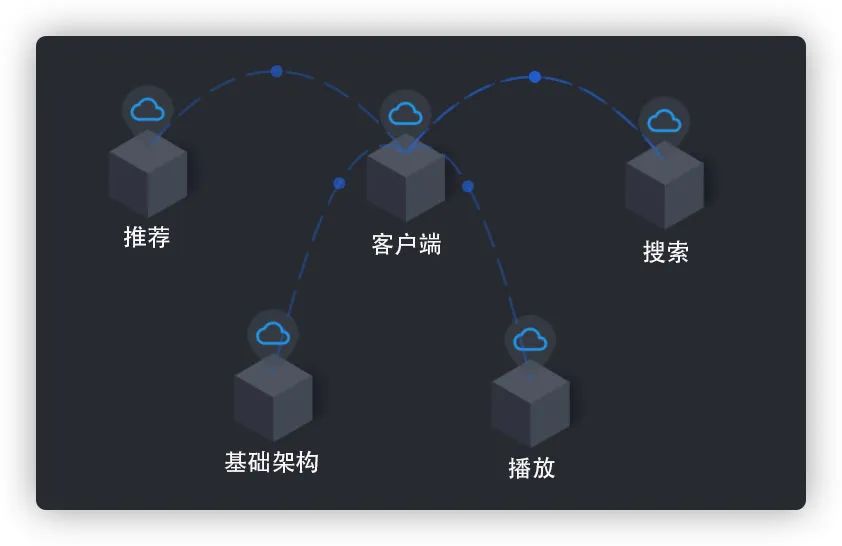 圖5 業(yè)務(wù)線維度?
圖5 業(yè)務(wù)線維度?
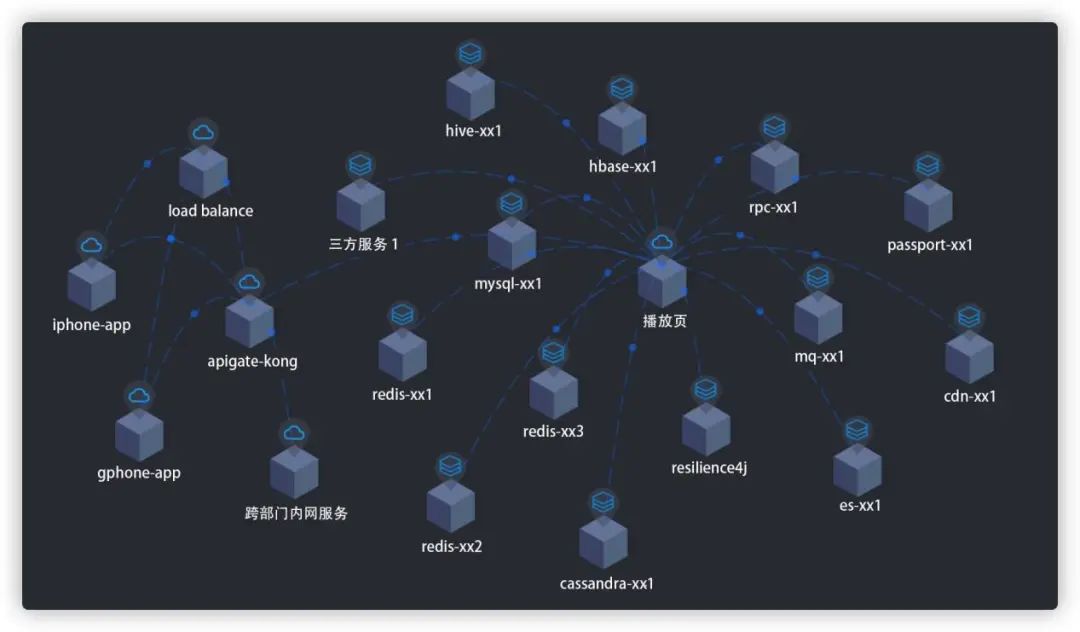 圖6 服務(wù)維度???
圖6 服務(wù)維度???
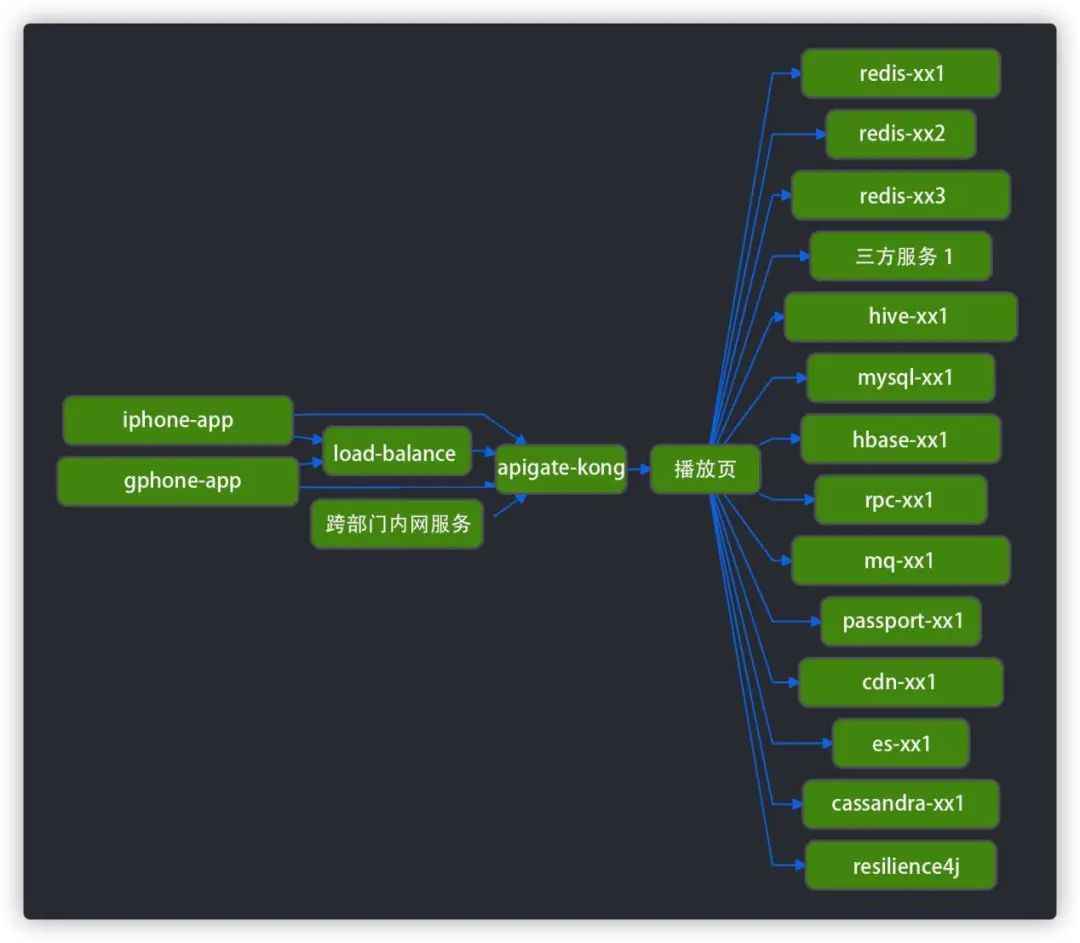 圖7 服務(wù)維度切換視圖??
圖7 服務(wù)維度切換視圖??
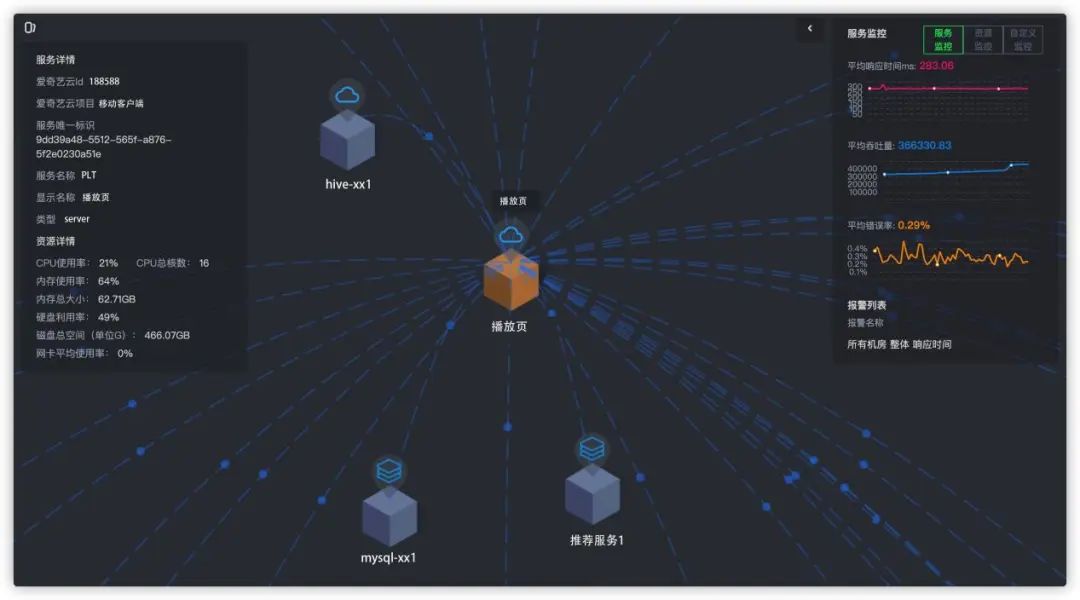
圖8 監(jiān)控指標(biāo)??
指標(biāo)采集
在指標(biāo)采集方面:指標(biāo)采集的技術(shù),如今Graphite、Prometheus配合時序數(shù)據(jù)庫的監(jiān)控體系,都能做到。問題在于每個業(yè)務(wù)線都有自己的一套監(jiān)控,比如同樣計算成功率,因為存儲或者性能等方面的影響,算法有差異(有的是根據(jù)總成功數(shù)/總請求數(shù),有的在每臺機器的每分鐘的成功率聚合的基礎(chǔ)上匯總做算數(shù)平均或者加權(quán)平均)。因此監(jiān)控統(tǒng)一,整體架構(gòu)的數(shù)據(jù)分析才可描述。
我們的設(shè)計
日志采集
在日志采集方面,分為兩個階段:
ELK Stack的日志監(jiān)控階段,采用的是Logstash/Beats+Kafka+ES,優(yōu)點是采集靈活,缺點是ES存儲能力和查詢能力弱。 全鏈路監(jiān)控方面,比如蘑菇街的實現(xiàn),采用的是Logstash+Kafka+ES+Hadoop,優(yōu)點是解決了ES存儲能力問題,缺點是未解決查詢能力問題。
我們的設(shè)計
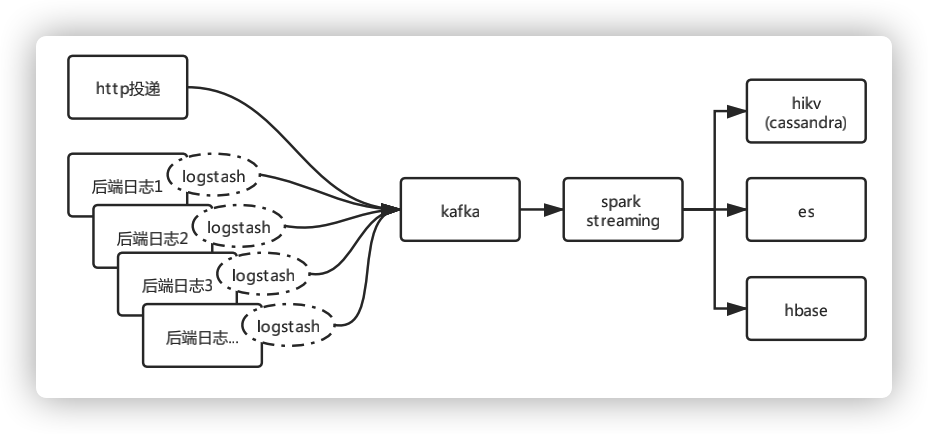
圖9 日志采集流程
深度分析
深度分析在報警方面,普遍的問題,比如OPS、RT、Success Rate、P999,僅能反應(yīng)服務(wù)整體質(zhì)量。但具體到用戶的個人APP問題,傳統(tǒng)方式都是開發(fā)手動排查,需要良好的架構(gòu)技術(shù)和豐富的業(yè)務(wù)經(jīng)驗,排查周期長且結(jié)果模糊。這是業(yè)界存在的痛點。 我們的設(shè)計
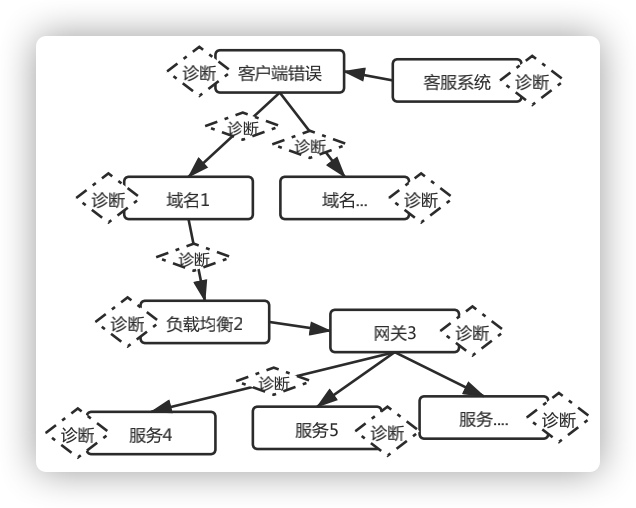
圖10 環(huán)環(huán)相扣的診斷
聚合分析思路
① 對接客戶端錯誤和客服系統(tǒng)用戶反饋,將粒度細到單條記錄作為分析的起點,再根據(jù)鏈路關(guān)系,離線聚合該起點對應(yīng)所有后續(xù)鏈路服務(wù)的日志。其中,我們聚合的索引是Device id,因為有的服務(wù)無法獲得該參數(shù),我們優(yōu)化了Trace id算法(包含Device id)。首先在服務(wù)請求的開始,會全量自動生成Trace id,保證后方服務(wù)都有Trace id,從而后方服務(wù)能從中提取到Device id。
② 所有的節(jié)點日志,進行多維度最優(yōu)診斷,直到發(fā)現(xiàn)錯誤點或遍歷結(jié)束。配合Easy Rule在不同的場景制定專門的診斷策略,靈活可拓展。策略之外,我們有對用戶的行為分析,用來展示用戶在一段時間內(nèi)的請求和行為。

④ 除了時序數(shù)據(jù)庫產(chǎn)生的指標(biāo),我們會將部分需要聚合的指標(biāo)存入Clickhouse,這樣能支持更多維度的實施聚合,對監(jiān)控能力作補充,保證日志采集和深度分析質(zhì)量。
在日志都上報的情況下,該思路覆蓋了常規(guī)開發(fā)操作所能想到的問題。不斷的補充策略會讓深度分析更智能。
4
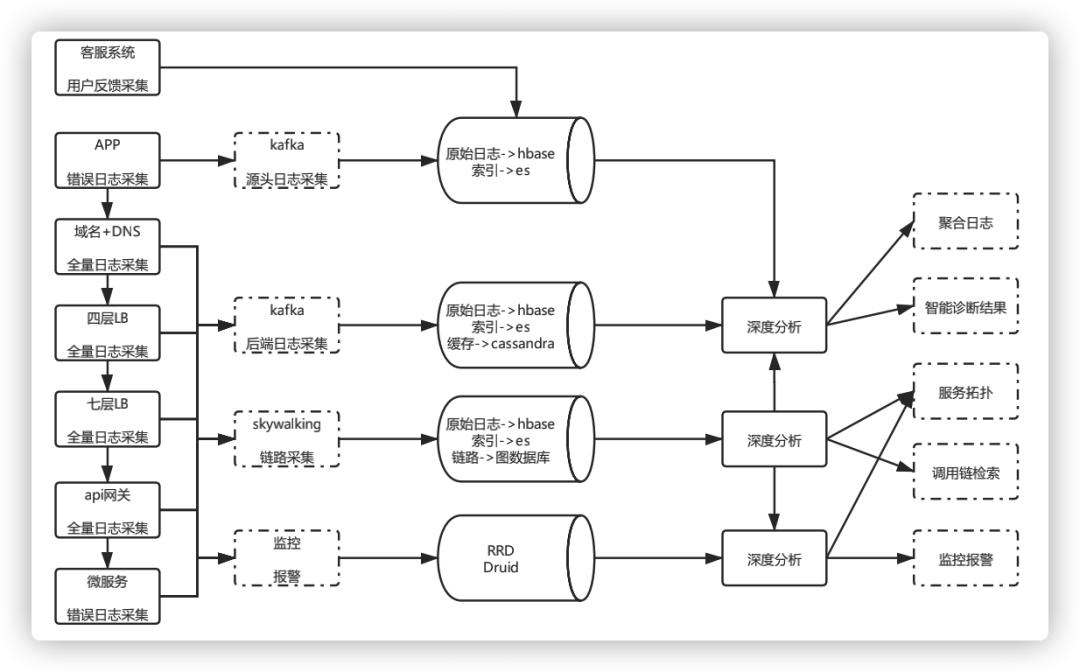 圖11 整體架構(gòu)設(shè)計
圖11 整體架構(gòu)設(shè)計
目前在打通客戶端和后臺鏈路的基礎(chǔ)上,兼容不同系統(tǒng)架構(gòu)和后臺服務(wù)實現(xiàn),各個流程自動化,單條業(yè)務(wù)線采集OPS高峰在每秒幾十萬,Hikv數(shù)據(jù)量在幾T(壓縮后平均數(shù)據(jù)長度不到1k),ES每小時數(shù)據(jù)量在幾百G左右(總量看保存多少小時),Hbase一天落地日志量幾十T。鏈路、指標(biāo)、日志采集和深度分析均達到準(zhǔn)時。
① 統(tǒng)一的指標(biāo)監(jiān)控
② 豐富的報警機制
③ 報警的根因定位
④ 資源的擴容分析
⑤ 日志的自動分析
⑥ 跨機房的調(diào)用檢測
5
自愛奇藝全鏈路自動化監(jiān)控平臺上線以來,填補移動端在鏈路監(jiān)控上的空白,擴大了可監(jiān)控的范圍,提高了問題定位效率,從鏈路的角度保障移動端的整體服務(wù)質(zhì)量。通過統(tǒng)一技術(shù)規(guī)范,目前全鏈路是公司微服務(wù)參考架構(gòu)的一部分。通過自動識別依賴關(guān)系,使鏈路可視化,能夠分鐘級的聚合指標(biāo)和報警,及時發(fā)現(xiàn)故障點和其中的依賴。通過基于規(guī)則引擎的自動化分析,解決錯誤日志存儲時間短導(dǎo)致無法定位的問題,錯誤日志查找效率提升50%以上,提高了客訴響應(yīng)速度。并且調(diào)用鏈路的分析,精準(zhǔn)輔助發(fā)現(xiàn)鏈路性能瓶頸進行優(yōu)化,提升整體架構(gòu)質(zhì)量。
未來,我們會在當(dāng)前基礎(chǔ)上,加入全鏈路壓測(普通壓測基本是單系統(tǒng)壓測)的功能,使系統(tǒng)具備線上壓測和模擬壓測的能力,提前感知系統(tǒng)負載能力,使系統(tǒng)的資源伸縮智能化,以應(yīng)對假期或者熱劇等突發(fā)流量。

掃碼助手小姐姐微信,進群大廠內(nèi)推&大佬技術(shù)交流