
日常Bug排查-讀從庫(kù)沒(méi)有原子性?
前言
日常Bug排查系列都是一些簡(jiǎn)單Bug排查。問(wèn)題雖小,但經(jīng)常遇到,了解這些問(wèn)題,會(huì)讓我們少走點(diǎn)彎路,提升效率。說(shuō)不定有些問(wèn)題你遇到過(guò)哦:)
Bug現(xiàn)場(chǎng)
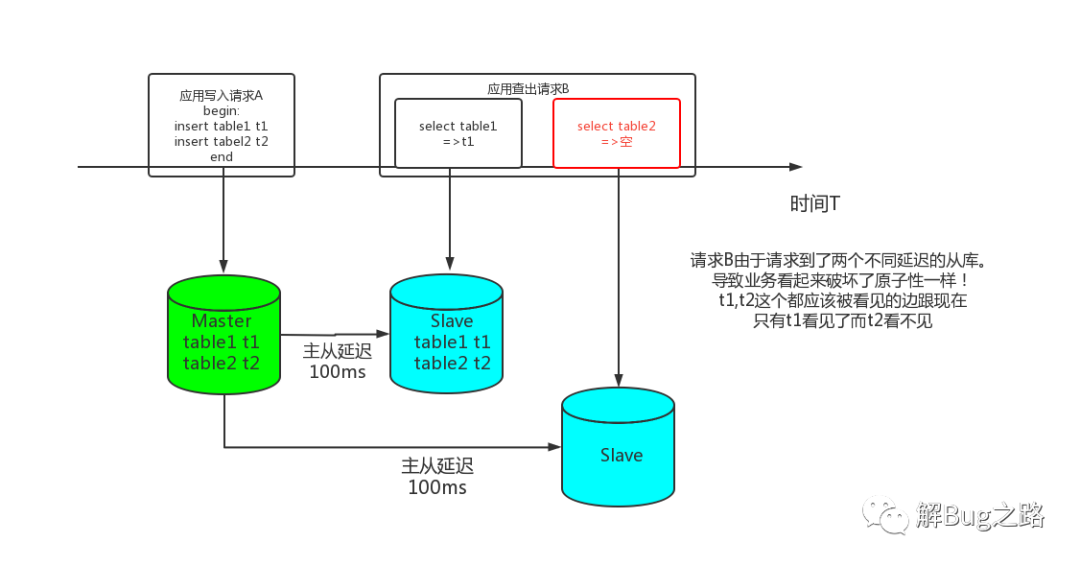
業(yè)務(wù)開(kāi)發(fā)同學(xué)突然問(wèn)了筆者一個(gè)問(wèn)題,從庫(kù)讀會(huì)不會(huì)沒(méi)有原子性?我下意識(shí)的反應(yīng)怎么可能,只要是遵守MySQL主從Replication協(xié)議的原子性至少是能夠保證的。但他們遇到了一個(gè)比較詭異的現(xiàn)象。如下圖所示:

這么一看確實(shí)像從庫(kù)沒(méi)有保證原子性。但這個(gè)明顯有違背筆者的常識(shí),這個(gè)問(wèn)題背后肯定還有其它的因素沒(méi)有挖掘到。
數(shù)據(jù)庫(kù)拓?fù)?/h1>
于是筆者看了看這個(gè)庫(kù)的拓?fù)洌且恢鲀蓮牡慕Y(jié)構(gòu)。如下圖所示:

真相大白
看到這個(gè)拓?fù)涞哪且豢坦P者立馬反應(yīng)過(guò)來(lái),是踩了一個(gè)主從延遲變種的坑。由于請(qǐng)求B的兩條select是不在事務(wù)內(nèi)的,而且都是select。這兩很有可能路由到兩個(gè)不同的從庫(kù),而這兩個(gè)從庫(kù)的主從延遲是不一樣的。例如一個(gè)100ms,一個(gè)200ms。那么落到100ms從庫(kù)的那條sql就會(huì)查到請(qǐng)求A的提交,而200ms從庫(kù)的那條sql查不到。以致與錯(cuò)誤的認(rèn)為從庫(kù)不保證原子性!
應(yīng)該怎么做
遇到這種情況,其實(shí)我們所需要做的只是在某次請(qǐng)求中穩(wěn)定的路由到某個(gè)特定的從庫(kù)上面,這樣就能保證原子性(要么能查到,要么都查不到)。
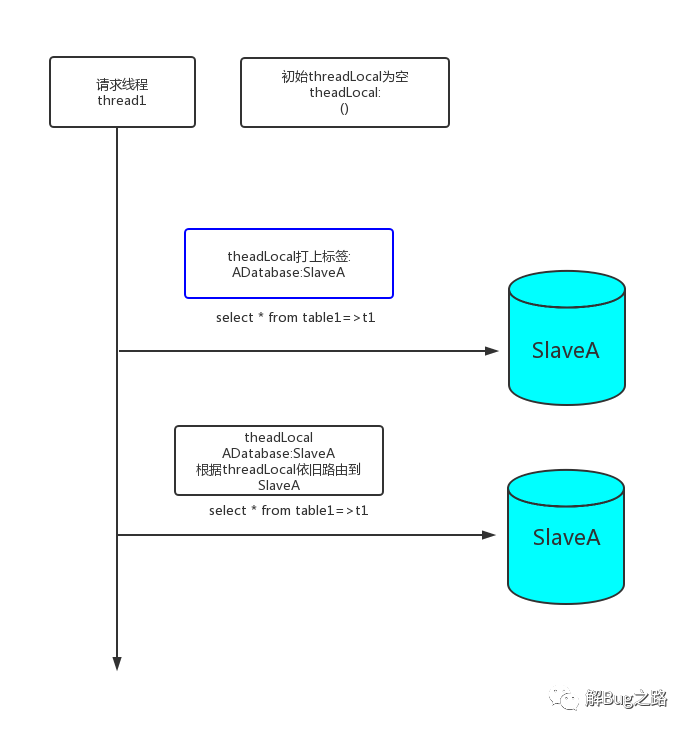
如上圖所示,一般在第一次請(qǐng)求之后,在threadLocal中打上相關(guān)粘性標(biāo)簽(SlaveA),那么在這次線程請(qǐng)求中。后來(lái)的從庫(kù)select都走SlaveA即可。這個(gè)選擇邏輯可以通過(guò)重載數(shù)據(jù)源DataSource的getConnection邏輯來(lái)實(shí)現(xiàn)。
總結(jié)
主從延遲是個(gè)非常常見(jiàn)的問(wèn)題。最常見(jiàn)的是主庫(kù)寫(xiě)入后讀從庫(kù)沒(méi)有相應(yīng)的數(shù)據(jù),當(dāng)然也有本文描述的這種看上去”不符合原子性”的變種。看似違背常識(shí)的背后可能有其它的隱變量(多從庫(kù)不同延遲)。多挖掘一點(diǎn)問(wèn)題現(xiàn)場(chǎng)的上下文信息就很容易揪出問(wèn)題的根因。
公眾號(hào)
關(guān)注筆者公眾號(hào),獲取更多干貨文章: