
基于深度連續(xù)融合的多傳感器三維目標檢測
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

單眼視覺系統(tǒng)以低成本高性能實現(xiàn)令人滿意的效果,但無法提供可靠的3D幾何信息。雙目攝像機可以提供3D幾何信息,但是它們的計算成本很高,并且無法在高遮擋和無紋理的環(huán)境中可靠地工作。另外,該系統(tǒng)在復雜的照明條件下魯棒性較低,這限制了其全天候能力。激光雷達不受光照條件的影響,可以提供高精度的3D幾何信息。但是它的分辨率和刷新率很低,而且成本很高。
Camera-Lidar融合提高了性能和可靠性并降低了成本,但這并不容易。首先,相機通過將現(xiàn)實世界投影到相機平面上來記錄信息,而點云以原始坐標的形式存儲幾何信息。此外,就數(shù)據(jù)結構和類型而言,點云是不規(guī)則,無序和連續(xù)的,而圖像是規(guī)則,有序和離散的。這導致圖像和點云處理算法的巨大差異。
參考文獻中 [1] 提出了一種新穎的3D目標檢測器,它可以利用激光雷達和攝像機進行非常精確的定位。為了實現(xiàn)這一目標,他們設計了一種端到端的可學習架構,該架構利用連續(xù)卷積融合不同分辨率級別的圖像和LIDAR特征圖。這使我們能夠設計基于多個傳感器的新穎,可靠,高效的端到端可學習3D對象檢測器。
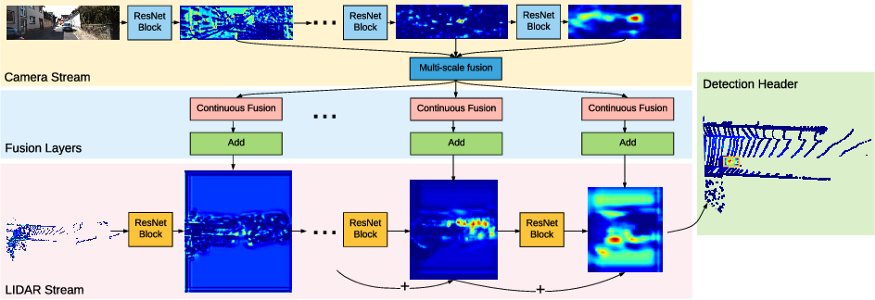
總體架構包括兩個流,其中一個流從LIDAR鳥瞰圖(BEV)提取圖像特征,另一流從LIDAR鳥瞰圖(BEV)提取特征,它們設計了一個連續(xù)融合層以橋接兩側(cè)的多個中間層,從而執(zhí)行多傳感器融合在多個尺度上。
首先,使用ResNet18分別提取圖像流和點云流(BEV)中的特征,然后對圖像特征執(zhí)行多尺度融合,并使用連續(xù)融合層將多尺度圖像特征融合到圖像的四個殘差組中。
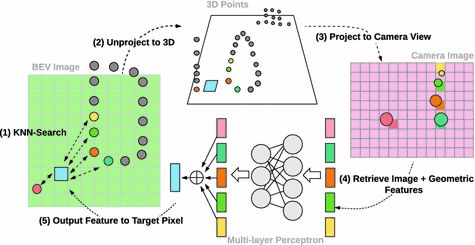
給定輸入的攝像機圖像特征圖和一組LIDAR點,連續(xù)融合層的目標是創(chuàng)建一個密集的BEV特征圖,其中每個離散像素都包含從攝像機圖像生成的特征。對于密集地圖中的每個目標像素,使用歐幾里得距離找到其在2D BEV平面上最接近的K個LIDAR點,然后反向投影到3D空間,然后將這k個點投影到相機視圖中,并找到與每個點,然后利用MLP融合來自這K個最近點的信息,以在目標像素處插值未觀察到的特征。
對于每個目標像素,MLP通過對其所有鄰居的MLP輸出求和來輸出D_o維輸出特征。也就是說:
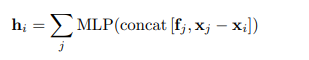
其中fj是點j的輸入圖像特征,xj-xi是從相鄰點j到目標i的3D偏移,而concat(·)是多個向量的串聯(lián)。然后,通過元素逐級求和將MLP的輸出功能與前一層的BEV功能進行組合,以融合多傳感器信息。
他們使用簡單的檢測頭來提高實時效率。在最終的BEV層上計算一個1×1卷積層以生成檢測輸出。在每個輸出位置,他們使用兩個具有固定大小和兩個方向的錨,分別為0和π/ 2弧度。
每個錨點的輸出包括每個像素類的置信度及其關聯(lián)的框的中心位置,大小和方向。接下來是非最大抑制(NMS)層,基于輸出映射生成最終對象框。損失函數(shù)定義為分類損失和回歸損失之和。
參考文獻 [1] 在KITTI和TOR4D數(shù)據(jù)集上評估了其多傳感器3D目標檢測方法。在KITTI數(shù)據(jù)集上,與3D目標檢測和BEV目標檢測中的現(xiàn)有高級方法進行了比較,并進行了模型簡化測試,并比較了不同的模型設計。在TOR4D數(shù)據(jù)集上,此方法在長距離(> 60m)檢測中特別有效,這在自動駕駛的定時和目標檢測系統(tǒng)中起著重要作用。
對于BEV檢測,此模型比中度AP測得的所有其他方法要好。對于3D檢測,此模型排名第三,但在簡單子集中具有最佳AP。在保持高檢測精度的同時,該模型可以實時高效運行。檢測器以大于每秒15幀的速度運行,這比其他基于LIDAR和基于融合的方法要快得多。
[1] Ming Liang, Bin Yang , Shenlong Wang , and Raquel Urtasun .Deep Continuous Fusion for Multi-Sensor 3D Object Detection
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~