
綜述 | 基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法
點(diǎn)擊左上方藍(lán)字關(guān)注我們

轉(zhuǎn)載自 | 計(jì)算機(jī)視覺(jué)life
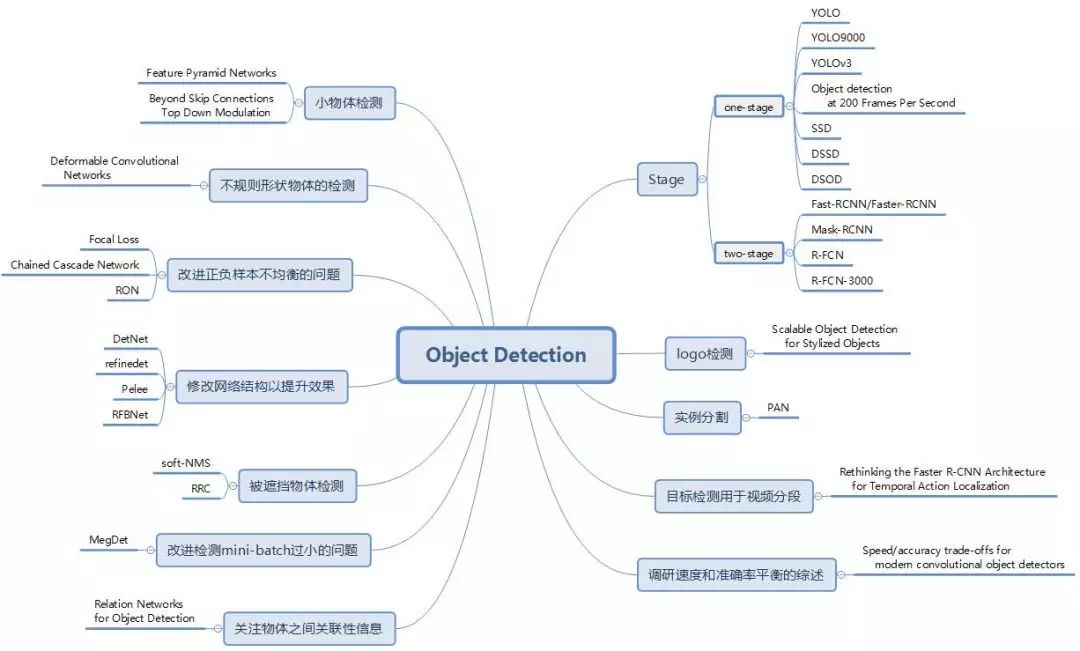
圖1
下文中,我們針對(duì)每篇文章,從論文目標(biāo),即要解決的問(wèn)題,算法核心思想以及算法效果三個(gè)層面進(jìn)行概括。同時(shí),我們也給出了每篇論文的出處,錄用信息以及相關(guān)的開(kāi)源代碼鏈接,其中代碼鏈接以作者實(shí)現(xiàn)和 mxnet 實(shí)現(xiàn)為主。
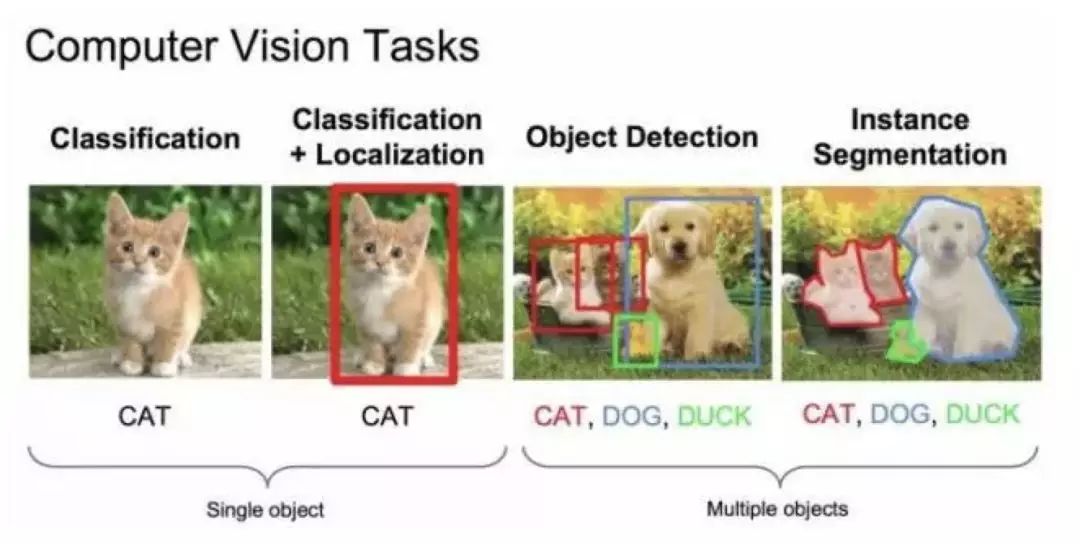
圖2
物體檢測(cè)的任務(wù)是找出圖像或視頻中的感興趣物體,同時(shí)檢測(cè)出它們的位置和大小,是機(jī)器視覺(jué)領(lǐng)域的核心問(wèn)題之一。
物體檢測(cè)過(guò)程中有很多不確定因素,如圖像中物體數(shù)量不確定,物體有不同的外觀、形狀、姿態(tài),加之物體成像時(shí)會(huì)有光照、遮擋等因素的干擾,導(dǎo)致檢測(cè)算法有一定的難度。進(jìn)入深度學(xué)習(xí)時(shí)代以來(lái),物體檢測(cè)發(fā)展主要集中在兩個(gè)方向:two stage 算法如 R-CNN 系列和 one stage 算法如 YOLO、SSD 等。兩者的主要區(qū)別在于 two stage 算法需要先生成 proposal(一個(gè)有可能包含待檢物體的預(yù)選框),然后進(jìn)行細(xì)粒度的物體檢測(cè)。而 one stage 算法會(huì)直接在網(wǎng)絡(luò)中提取特征來(lái)預(yù)測(cè)物體分類和位置。
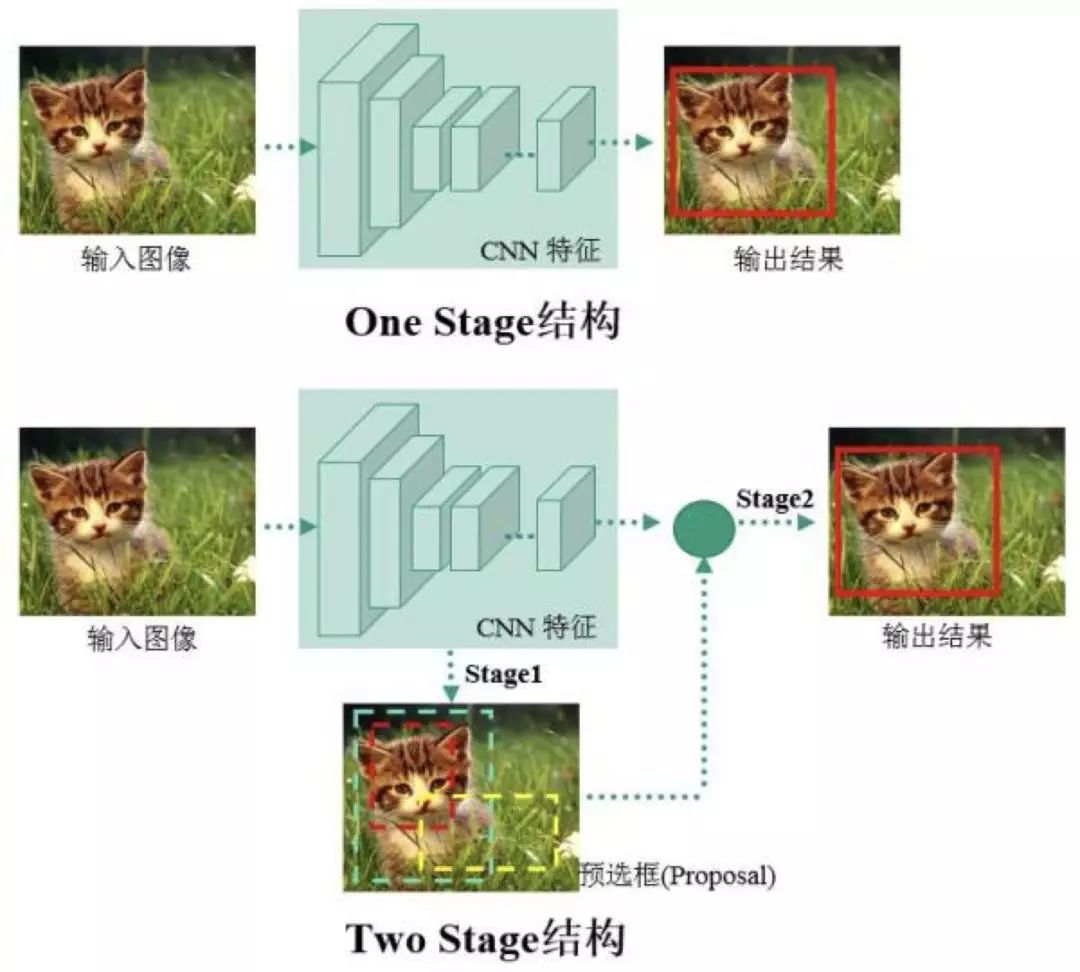
圖3
基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法綜述分為三部分:
Two/One stage 算法改進(jìn)。 這部分將主要總結(jié)在 two/one stage 經(jīng)典網(wǎng)絡(luò)上改進(jìn)的系列論文,包括 Faster R-CNN、YOLO、SSD 等經(jīng)典論文的升級(jí)版本。
解決方案。 這部分我們歸納總結(jié)了目標(biāo)檢測(cè)的常見(jiàn)問(wèn)題和近期論文提出的解決方案。
擴(kuò)展應(yīng)用、綜述。 這部分我們會(huì)介紹檢測(cè)算法的擴(kuò)展和其他綜述類論文。
本綜述分三部分,本文介紹第一部分。
Faster R-CNN 網(wǎng)絡(luò)包括兩個(gè)步驟:1. 使用 RPN(region proposal network) 提取 proposal 信息;2. 使用 R-CNN 對(duì)候選框位置進(jìn)行預(yù)測(cè)和物體類別識(shí)別。本文主要介紹在 Faster R-CNN 基礎(chǔ)上改進(jìn)的幾篇論文:R-FCN、R-FCN3000 和 Mask R-CNN。R-FCN 系列提出了 Position Sensitive(ps) 的概念,提升了檢測(cè)效果。另外需要注明的是,雖然 Mask R-CNN 主要應(yīng)用在分割上,但該論文和 Faster R-CNN 一脈相承,而且論文提出了 RoI Align 的思想,對(duì)物體檢測(cè)回歸框的精度提升有一定效果,故本篇綜述也介紹了這篇論文。
論文鏈接:arxiv.org/abs/1605.06409
開(kāi)源代碼:github.com/daijifeng001/R-FCN
錄用信息:CVPR2017
Faster R-CNN 是首個(gè)利用 CNN 來(lái)完成 proposals 的預(yù)測(cè)的,之后的很多目標(biāo)檢測(cè)網(wǎng)絡(luò)都是借助了 Faster R-CNN 的思想。而 Faster R-CNN 系列的網(wǎng)絡(luò)都可以分成 2 個(gè)部分:
Fully Convolutional subnetwork before RoI Layer
RoI-wise subnetwork
第 1 部分就是直接用普通分類網(wǎng)絡(luò)的卷積層來(lái)提取共享特征,后接一個(gè) RoI Pooling Layer 在第 1 部分的最后一張?zhí)卣鲌D上進(jìn)行提取針對(duì)各個(gè) RoIs 的特征圖,最后將所有 RoIs 的特征圖都交由第 2 部分來(lái)處理(分類和回歸)。第二部分通常由全連接層組層,最后接 2 個(gè)并行的 loss 函數(shù):Softmax 和 smoothL1,分別用來(lái)對(duì)每一個(gè) RoI 進(jìn)行分類和回歸。由此得到每個(gè) RoI 的類別和歸回結(jié)果。其中第 1 部分的基礎(chǔ)分類網(wǎng)絡(luò)計(jì)算是所有 RoIs 共享的,只需要進(jìn)行一次前向計(jì)算即可得到所有 RoIs 所對(duì)應(yīng)的特征圖。
第 2 部分的 RoI-wise subnetwork 不是所有 RoIs 共享的,這一部分的作用就是給每個(gè) RoI 進(jìn)行分類和回歸。在模型進(jìn)行預(yù)測(cè)時(shí)基礎(chǔ)網(wǎng)絡(luò)不能有效感知位置信息,因?yàn)槌R?jiàn)的 CNN 結(jié)構(gòu)是根據(jù)分類任務(wù)進(jìn)行設(shè)計(jì)的,并沒(méi)有針對(duì)性的保留圖片中物體的位置信息。而第 2 部分的全連階層更是一種對(duì)于位置信息非常不友好的網(wǎng)絡(luò)結(jié)構(gòu)。由于檢測(cè)任務(wù)中物體的位置信息是一個(gè)很重要的特征,R-FCN 通過(guò)提出的位置敏感分?jǐn)?shù)圖(position sensitive score maps)來(lái)增強(qiáng)網(wǎng)絡(luò)對(duì)于位置信息的表達(dá)能力,提高檢測(cè)效果。
position-sensitive score map
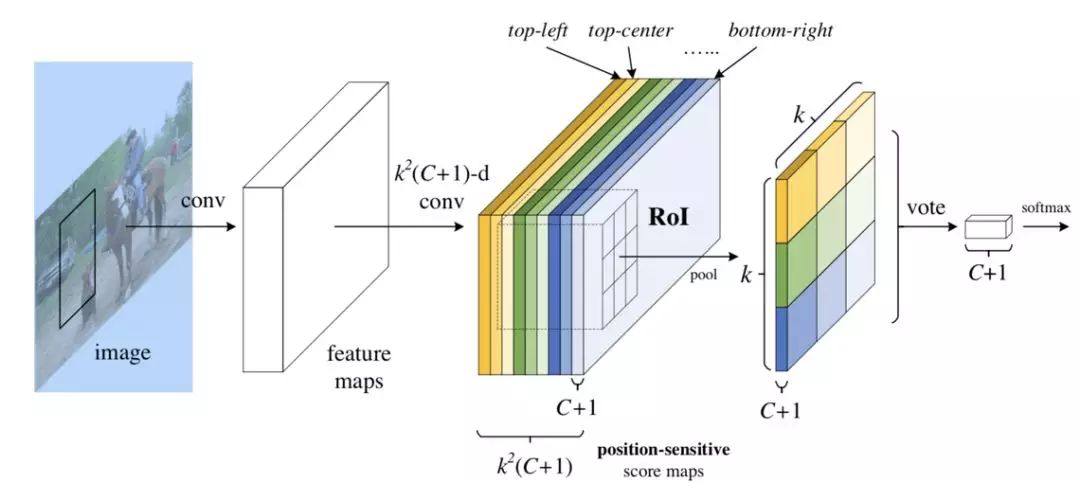
圖4
圖 4 展示的是 R-FCN 的網(wǎng)絡(luò)結(jié)構(gòu)圖,展示了位置敏感得分圖 (position-sensitive score map) 的主要設(shè)計(jì)思想。如果一個(gè) RoI 含有一個(gè)類別 c 的物體,則將該 RoI 劃分為 k x k 個(gè)區(qū)域,分別表示該物體的各個(gè)相應(yīng)部位。其每個(gè)相應(yīng)的部位都由特定的特征圖對(duì)其進(jìn)行特征提取。R-FCN 在 、共享卷積層的最后再接上一層卷積層,而該卷積層就是位置敏感得分圖 position-sensitive score map。其通道數(shù) channels=k x k x (C+1)。C 表示物體類別種數(shù)再加上 1 個(gè)背景類別,每個(gè)類別都有 k x k 個(gè) score maps 分別對(duì)應(yīng)每個(gè)類別的不同位置。每個(gè)通道分別負(fù)責(zé)某一類的特定位置的特征提取工作。
Position-sensitive RoI pooling
位置敏感 RoI 池化操作了(Position-sensitive RoI pooling)如下圖所示:
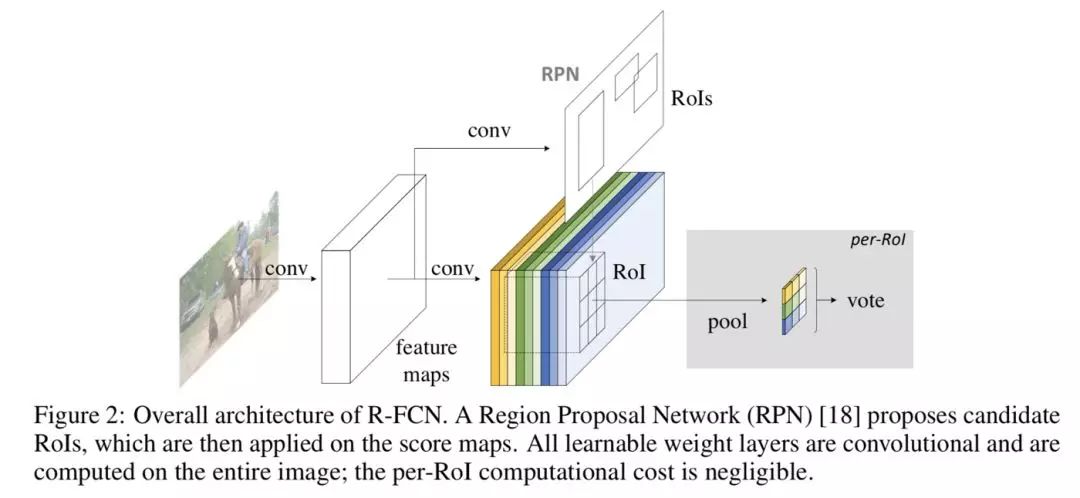
圖5
該操作將每個(gè) RoIs 分為 k x k 個(gè)小塊。之后提取其不同位置的小塊相應(yīng)特征圖上的特征執(zhí)行池化操作,下圖展示了池化操作的計(jì)算方式。
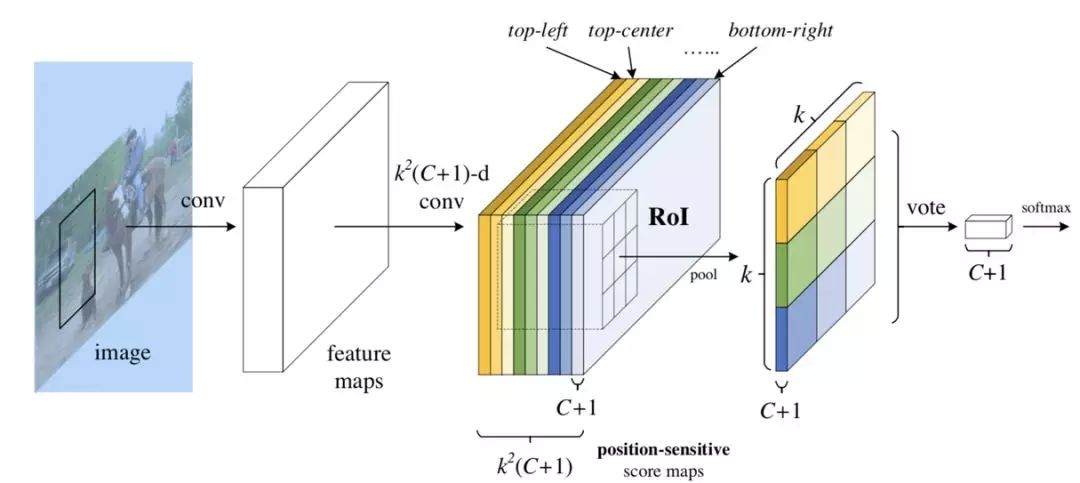
圖6
得到池化后的特征后,每個(gè) RoIs 的特征都包含每個(gè)類別各個(gè)位置上的特征信息。對(duì)于每個(gè)單獨(dú)類別來(lái)講,將不同位置的特征信息相加即可得到特征圖對(duì)于該類別的響應(yīng),后面即可對(duì)該特征進(jìn)行相應(yīng)的分類。
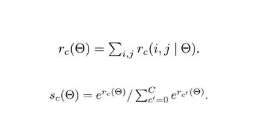
position-sensitive regression
在位置框回歸階段仿照分類的思路,將特征通道數(shù)組合為 4 x k x k 的形式,其中每個(gè)小塊的位置都對(duì)應(yīng)了相應(yīng)的通道對(duì)其進(jìn)行位置回歸的特征提取。最后將不同小塊位置的四個(gè)回歸值融合之后即可得到位置回歸的響應(yīng),進(jìn)行后續(xù)的位置回歸工作。
position-sensitive score map 高響應(yīng)值區(qū)域
在訓(xùn)練的過(guò)程中,當(dāng) RoIs 包涵物體屬于某類別時(shí),損失函數(shù)即會(huì)使得該 RoIs 不同區(qū)域塊所對(duì)應(yīng)的響應(yīng)通道相應(yīng)位置的特征響應(yīng)盡可能的大,下圖展示了這一過(guò)程,可以明顯的看出不同位置的特征圖都只對(duì)目標(biāo)相應(yīng)位置的區(qū)域有明顯的響應(yīng),其特征提取能力是對(duì)位置敏感的。

圖 7
使用如上的損失函數(shù),對(duì)于任意一個(gè) RoI,計(jì)算它的 Softmax 損失,和當(dāng)其不屬于背景時(shí)的回歸損失。因?yàn)槊總€(gè) RoI 都被指定屬于某一個(gè) GT box 或者屬于背景,即先讓 GT box 選擇與其 IoU 最大的那個(gè) RoI,再對(duì)剩余 RoI 選擇與 GT box 的 IoU>0.5 的進(jìn)行匹配,而剩下的 RoI 全部為背景類別。當(dāng) RoI 有了 label 后 loss 就可以計(jì)算出來(lái)。這里唯一不同的就是為了減少計(jì)算量,作者將所有 RoIs 的 loss 值都計(jì)算出來(lái)后,對(duì)其進(jìn)行排序,并只對(duì)最大的 128 個(gè)損失值對(duì)應(yīng)的 RoIs 進(jìn)行反向傳播操作,其它的則忽略。并且訓(xùn)練策略也是采用的 Faster R-CNN 中的 4-step alternating training 進(jìn)行訓(xùn)練。在測(cè)試的時(shí)候,為了減少 RoIs 的數(shù)量,作者在 RPN 提取階段就將 RPN 提取的大約 2W 個(gè) proposals 進(jìn)行過(guò)濾:
去除超過(guò)圖像邊界的 proposals
使用基于類別概率且閾值 IoU=0.3 的 NMS 過(guò)濾
按照類別概率選擇 top-N 個(gè) proposals
在測(cè)試的時(shí)候,一般只剩下 300 個(gè) RoIs。并且在 R-FCN 的輸出 300 個(gè)預(yù)測(cè)框之后,仍然要對(duì)其使用 NMS 去除冗余的預(yù)測(cè)框。

圖 8
圖 8 比較了 Faster-R-CNN 和 R-FCN 的 mAP 值和監(jiān)測(cè)速度,采用的基礎(chǔ)網(wǎng)絡(luò)為 ResNet-101,測(cè)評(píng)顯卡為 Tesla K40。
論文鏈接:arxiv.org/abs/1712.01802
開(kāi)源代碼:/
錄用信息:/
YOLO9000 將檢測(cè)數(shù)據(jù)集和分類數(shù)據(jù)集合并訓(xùn)練檢測(cè)模型,但 r-fcn-3000 僅采用具有輔助候選框信息的 ImageNet 數(shù)據(jù)集訓(xùn)練檢測(cè)分類器。
如果使用包含標(biāo)注輔助信息(候選框)的大規(guī)模分類數(shù)據(jù)集,如 ImageNet 數(shù)據(jù)集,進(jìn)行物體檢測(cè)模型訓(xùn)練,然后將其應(yīng)用于實(shí)際場(chǎng)景時(shí),檢測(cè)效果會(huì)是怎樣呢?how would an object detector perform on "detection"datasets if it were trained on classification datasets with bounding-box supervision?
r-fcn-3000 是對(duì) r-fcn 的改進(jìn)。上文提到,r-fcn 的 ps 卷積核是 per class 的,假設(shè)有 C 個(gè)物體類別,有 K*K 個(gè) ps 核,那么 ps 卷積層輸出 K*K*C 個(gè)通道,導(dǎo)致檢測(cè)的運(yùn)算復(fù)雜度很高,尤其當(dāng)要檢測(cè)的目標(biāo)物體類別數(shù)較大時(shí),檢測(cè)速度會(huì)很慢,難以滿足實(shí)際應(yīng)用需求。
為解決以上速度問(wèn)題,r-fcn-3000 提出,將 ps 卷積核作用在超類上,每個(gè)超類包含多個(gè)物體類別,假設(shè)超類個(gè)數(shù)為 SC,那么 ps 卷積層輸出K*KSC 個(gè)通道。由于 SC 遠(yuǎn)遠(yuǎn)小于 C,因此可大大降低運(yùn)算復(fù)雜度。特別地,論文提出,當(dāng)只使用一個(gè)超類時(shí),檢測(cè)效果依然不錯(cuò)。算法網(wǎng)絡(luò)結(jié)構(gòu)如下:
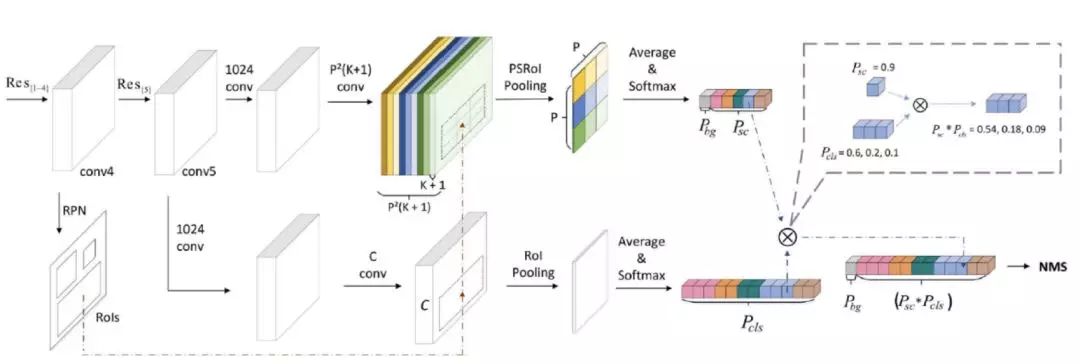
圖 9
上圖可以看出,與 r-fcn 類似,r-fcn-3000 也使用 RPN 網(wǎng)絡(luò)生成候選框(上圖中虛線回路);相比 r-fcn,r-fcn-3000 的網(wǎng)絡(luò)結(jié)構(gòu)做了如下改進(jìn):
r-fcn-3000 包含超類(上圖中上半部分)和具體類(上圖中下半部分)兩個(gè)卷積分支。
超類卷積分支用于檢測(cè)超類物體,包含分類(超類檢測(cè))和回歸(候選框位置改進(jìn))兩個(gè)子分支;注意上圖中沒(méi)有畫(huà)出用于候選框位置改進(jìn)的 bounding-box 回歸子分支;回歸分支是類別無(wú)關(guān)的,即只確定是否是物體。
具體類卷積分支用于分類物體的具體類別概率,包含兩個(gè)普通 CNN 卷積層。
最終的物體檢測(cè)輸出概率由超類卷積分支得到的超類類概率分別乘以具體類卷積分支輸出的具體類別概率得到。引入超類和具體類兩個(gè)卷積分支實(shí)現(xiàn)了“物體檢測(cè)”和“物體分類”的解耦合。超類卷積分支使得網(wǎng)絡(luò)可以檢測(cè)出物體是否存在,由于使用了超類,而不是真實(shí)物體類別,大大降低了運(yùn)算操作數(shù)。保證了檢測(cè)速度;具體類分支不檢測(cè)物體位置,只分類具體物體類別。
超類生成方式:對(duì)某個(gè)類別 j 的所有樣本圖像,提取 ResNet-101 最后一層 2018 維特征向量,對(duì)所有特征項(xiàng)向量求均值,作為該類別的特征表示。得到所有類別的特征表示進(jìn)行 K-means 聚類,確定超類。
在 imagenet 數(shù)據(jù)集上,檢測(cè) mAP 值達(dá)到了 34.9%。使用 nvidia p6000 GPU,對(duì)于 375x500 圖像,檢測(cè)速度可以達(dá)到每秒 30 張。在這種速度下,r-fcn-3000 號(hào)稱它的檢測(cè)準(zhǔn)確率高于 YOLO 18%。
此外,論文實(shí)驗(yàn)表明,r-fcn-3000 進(jìn)行物體檢測(cè)時(shí)具有較強(qiáng)的通用性,當(dāng)使用足夠多的類別進(jìn)行訓(xùn)練時(shí),對(duì)未知類別的物體檢測(cè)時(shí),仍能檢測(cè)出該物體位置。如下圖:

圖 10
在訓(xùn)練類別將近 3000 時(shí),不使用目標(biāo)物體進(jìn)行訓(xùn)練達(dá)到的通用預(yù)測(cè) mAP 為 30.7%,只比使用目標(biāo)物體進(jìn)行訓(xùn)練達(dá)到的 mAP 值低 0.3%。
論文鏈接:
arxiv.org/abs/1703.06870
開(kāi)源代碼:
github.com/TuSimple/mx-maskrcnn
錄用信息:CVPR2017
解決 RoIPooling 在 Pooling 過(guò)程中對(duì) RoI 區(qū)域產(chǎn)生形變,且位置信息提取不精確的問(wèn)題。
通過(guò)改進(jìn) Faster R-CNN 結(jié)構(gòu)完成分割任務(wù)。
LaneNet模型 使用 RoIAlign 代替 RoIPooling,得到更好的定位效果。
在 Faster R-CNN 基礎(chǔ)上加上 mask 分支,增加相應(yīng) loss,完成像素級(jí)分割任務(wù)。
Mask R-CNN 是基于 Faster R-CNN 的基礎(chǔ)上演進(jìn)改良而來(lái),不同于 Faster R-CNN,Mask R-CNN 可以精確到像素級(jí)輸出,完成分割任務(wù)。此外他們的輸出也有所不同。Faster R-CNN 輸出為種類標(biāo)簽和 box 坐標(biāo),而 Mask R-CNN 則會(huì)增加一個(gè)輸出,即物體掩膜 (object mask)。
Mask R-CNN 結(jié)構(gòu)如下圖:
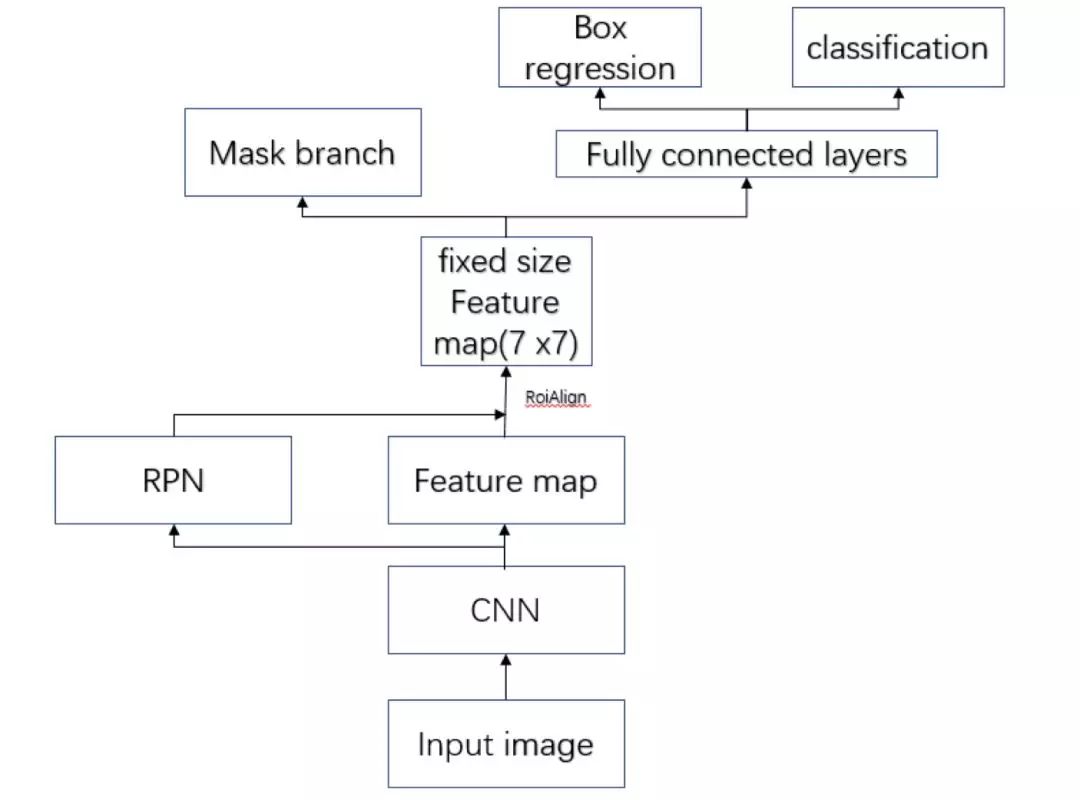
圖 11
Mask R-CNN 采用和 Faster R-CNN 相同的兩個(gè)階段,具有相同的第一層 (即 RPN),第二階段,除了預(yù)測(cè)種類和 bbox 回歸,并且并行的對(duì)每個(gè) RoI 預(yù)測(cè)了對(duì)應(yīng)的二值掩膜 (binary mask)。
RoIAlign
Faster R-CNN 采用的 RoIPooling,這樣的操作可能導(dǎo)致 feature map 在原圖的對(duì)應(yīng)位置與真實(shí)位置有所偏差。如下圖:

圖 12
而通過(guò)引入 RoIAlign 很大程度上解決了僅通過(guò) Pooling 直接采樣帶來(lái)的 Misalignment 對(duì)齊問(wèn)題。
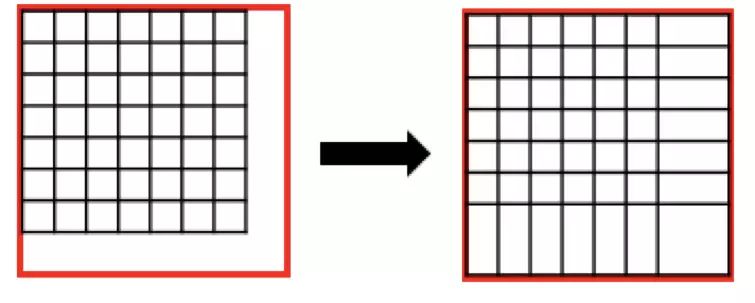
圖 13:RoIPooling
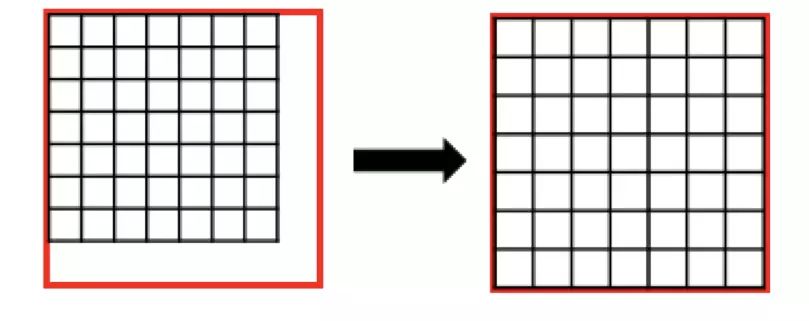
圖 14:RoIAlign
RoIPooling 會(huì)對(duì)區(qū)域進(jìn)行拉伸, 導(dǎo)致區(qū)域形變。RoIAlign 可以避免形變問(wèn)題。具體方式是先通過(guò)雙線性插值到 14 x 14,其次進(jìn)行雙線性插值得到藍(lán)點(diǎn)的值,最后再通過(guò) max Pooling 或 average pool 到 7 x 7。
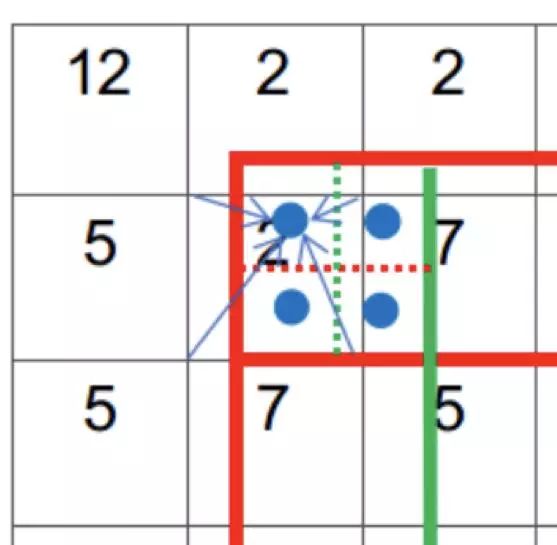
圖 15
多任務(wù)損失函數(shù)
Mask R-CNN 的損失函數(shù)可表示為:


掩膜分支針對(duì)每個(gè) RoI 產(chǎn)生一個(gè) K x M xM 的輸出, 即 K 個(gè) M x M 的二值的掩膜輸出。其中 K 為分類物體的類別數(shù)目。依據(jù)預(yù)測(cè)類別輸出,只輸出該類對(duì)應(yīng)的二值掩膜,掩膜分支的損失計(jì)算如下示意圖:

圖 16
mask branch 預(yù)測(cè) K 個(gè)種類的 M x M 二值掩膜輸出。
依據(jù)種類預(yù)測(cè)分支 (Faster R-CNN 部分) 預(yù)測(cè)結(jié)果:當(dāng)前 RoI 的物體種類為 i。
RoI 的平均二值交叉損失熵(對(duì)每個(gè)像素點(diǎn)應(yīng)用 Sigmoid 函數(shù))即為損失 。
此外作者發(fā)現(xiàn)使用 Sigmoid 優(yōu)于 Softmax ,Sigmoid 可以避免類間競(jìng)爭(zhēng)。
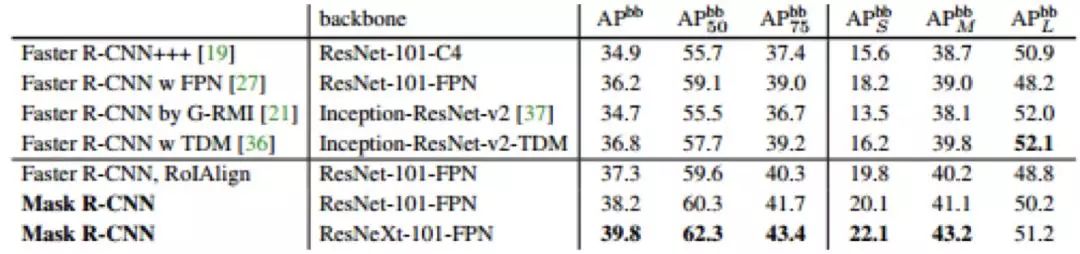
圖 17
體現(xiàn)了在 COCO 數(shù)據(jù)集上的表現(xiàn)效果。
One stage
提到 one stage 算法就必須提到 OverFeat,OverFeat 網(wǎng)絡(luò)將分類、定位、檢測(cè)功能融合在一個(gè)網(wǎng)絡(luò)之中。隨后的 YOLO 和 SSD 網(wǎng)絡(luò),都是很經(jīng)典的 one stage 檢測(cè)算法。
YOLO 論文作者對(duì)原始 YOLO 網(wǎng)絡(luò)進(jìn)行了改進(jìn),提出了 YOLO9000 和 YOLOv3。YOLO9000 號(hào)稱可以做到更好,更快,更強(qiáng)。其創(chuàng)新點(diǎn)還包括用小規(guī)模(指類別)檢測(cè)標(biāo)注數(shù)據(jù)集 + 大規(guī)模分類標(biāo)注數(shù)據(jù)集訓(xùn)練通用物體檢測(cè)模型。YOLOv3 是作者的一個(gè) technical report,主要的工作展示作者在 YOLO9000 上的改進(jìn)。另外本綜述還將介紹新論文 Object detection at 200 Frames Per Second,這篇論文在 YOLO 的基礎(chǔ)上進(jìn)行創(chuàng)新,能在不犧牲太多準(zhǔn)確率的情況下達(dá)到 200FPS(使用 GTX1080)。
SSD 算法是一種直接預(yù)測(cè) bounding box 的坐標(biāo)和類別的 object detection 算法,利用不同分辨率卷積層的 feature map,可以針對(duì)不同 scale 的物體進(jìn)行檢測(cè)。本篇綜述中主要介紹 DSSD(原始作者的改進(jìn)版本)和 DSOD 這兩篇論文。
論文鏈接:
arxiv.org/abs/1612.0824
開(kāi)源代碼:github.com/pjreddie/darknet
github.com/zhreshold/mxnet-yolo(MXNet 實(shí)現(xiàn))
錄用信息:CVPR2017
論文目標(biāo)是要解決包含大規(guī)模物體類別的實(shí)際應(yīng)用場(chǎng)景中的實(shí)時(shí)目標(biāo)檢測(cè)。實(shí)際應(yīng)用場(chǎng)景中,目標(biāo)檢測(cè)應(yīng)滿足兩個(gè)條件:1. 檢測(cè)速度滿足實(shí)際場(chǎng)景需求;2. 覆蓋物體類別滿足實(shí)際場(chǎng)景需求。實(shí)際場(chǎng)景包含很多類別的物體,而這些類別物體的標(biāo)注數(shù)據(jù)很難拿到,本論文提出使用小規(guī)模(指類別)檢測(cè)標(biāo)注數(shù)據(jù)集 + 大規(guī)模分類標(biāo)注數(shù)據(jù)集訓(xùn)練通用物體檢測(cè)模型。
YOLO9000 是在 YOLO 基礎(chǔ)上的改進(jìn),相比 YOLO,YOLO9000 號(hào)稱可以做到更好,更快,更強(qiáng)。下面從這三個(gè)方面介紹 YOLO9000 如何做到這三點(diǎn)。YOLO 相關(guān)的論文解讀可以參考:https://zhuanlan.zhihu.com/p/25236464
準(zhǔn)確率提升。相比 R-CNN 系列,YOLOv1 的召回率和物體位置檢測(cè)率較低,YOLO9000 做了如下七點(diǎn)改進(jìn)對(duì)其進(jìn)行提升。
加入 BN 層。在所有的卷積層后加入 BN 操作,去掉所有 dropout 層。
使用高分辨率訓(xùn)練得到的分類模型 pretrain 檢測(cè)網(wǎng)絡(luò)。YOLOv1 使用 224x224 訓(xùn)練得到的分類模型 pretrain,而 YOLO9000 直接使用 448x448 訓(xùn)練得到的分類模型 pretrain 檢測(cè)網(wǎng)絡(luò)。
使用卷積層預(yù)測(cè) anchor box 位置。YOLOv1 基于輸入圖像的物理空間劃分成 7x7 的網(wǎng)格空間,每個(gè)網(wǎng)格最多對(duì)應(yīng)兩個(gè)候選預(yù)測(cè)框,因此每張圖像最多有 98 個(gè) bounding box,最后接入全連接層預(yù)測(cè)物體框位置。而 YOLO9000 移除全連接層,使用 anchor box 預(yù)測(cè)候選框位置,大大增加了每張圖片的候選框個(gè)數(shù)。這個(gè)改進(jìn)將召回率由 81% 提高到 88%,mAP 由 69.5% 稍微降低到 69.2%。同時(shí),由于去掉了全連接層,YOLO9000 可以支持檢測(cè)時(shí)不同分辨率的圖像輸入。
kmeans 聚類確定候選框形狀。使用 k-means 對(duì)訓(xùn)練數(shù)據(jù)集中的物體框的分辨率和比例進(jìn)行聚類,確定 anchor box 的形狀。為避免物體大小引起的統(tǒng)計(jì)誤差,YOLO9000 使用 IoU 而不是歐氏距離來(lái)作為距離度量方式。
預(yù)測(cè)“候選框相對(duì)于圖像的內(nèi)部偏移”。以往 RPN 網(wǎng)絡(luò),通過(guò)回歸候選框相對(duì)于當(dāng)前 anchor box 的偏移來(lái)定位候選框的位置,由于偏移相對(duì)于 anchor box 外部,所以取值范圍是不受限的,導(dǎo)致訓(xùn)練的時(shí)候難以收斂。因此 YOLO9000 采用與 YOLO 類似的方式,預(yù)測(cè)候選框相對(duì)于圖像左上角的位置偏移,并將偏移量歸一化到 0-1 區(qū)間,解決了訓(xùn)練難收斂問(wèn)題。
使用更精細(xì)的特征。YOLOv1 提取 13x13 的特征層進(jìn)行后續(xù)物體檢測(cè),對(duì)于小物體的檢測(cè)效果并不友好。為解決這個(gè)問(wèn)題,YOLO9000 將前一層 26x26 的特征與 13x13 層的特征進(jìn)行通道 concatenation。如 26x26x512 的 feature map 被拆分成 13x13x2048,然后同后面的 13x13 特征層進(jìn)行 concatenation。mAP 提升 1%。
多尺度圖像訓(xùn)練。YOLO9000 采用不同分辨率的圖像進(jìn)行模型迭代訓(xùn)練,增強(qiáng)模型對(duì)多尺度圖像的預(yù)測(cè)魯棒性。
YOLOv1 的 basenet 基于 GoogleNet 改進(jìn)得到,計(jì)算復(fù)雜度大概是 VGG16 的 1/4,但在 imagenet 上 224x224 圖像的 top-5 分類準(zhǔn)確率比 vgg16 低 2%。YOLO9000 提出一個(gè)全新的 basenet,號(hào)稱 darknet-19,包含 19 個(gè)卷積層和 5 個(gè) max pooling 層,詳細(xì)網(wǎng)絡(luò)結(jié)構(gòu)見(jiàn)論文,計(jì)算復(fù)雜度比 YOLOv1 進(jìn)一步減少了 34%,imagenet 上 top-5 準(zhǔn)確率提升了 3.2%。
更強(qiáng)是指在滿足實(shí)時(shí)性需求的前提下,能檢測(cè)出的物體類別數(shù)更多,范圍更大。YOLO9000 提出使用詞樹(shù)“wordtree”,將分類數(shù)據(jù)集和檢測(cè)數(shù)據(jù)集合并,進(jìn)行模型訓(xùn)練。反向傳播時(shí),檢測(cè)樣本的訓(xùn)練 loss 用于計(jì)算和更新整個(gè)網(wǎng)絡(luò)的模型參數(shù);而分類樣本的訓(xùn)練 loss 僅用于更新與分類相關(guān)的網(wǎng)絡(luò)層模型參數(shù)。這樣以來(lái),檢測(cè)數(shù)據(jù)集訓(xùn)練網(wǎng)絡(luò)學(xué)到如何檢測(cè)出物體(是否是物體,位置),而分類數(shù)據(jù)集使得網(wǎng)絡(luò)識(shí)別出物體類別。
下圖給出了 YOLOv2 和對(duì)比算法的準(zhǔn)確率和運(yùn)行時(shí)間的綜合性能結(jié)果。可以看出 YOLOv2 在保證準(zhǔn)確率的同時(shí),可以達(dá)到超過(guò) 30fps 的圖像檢測(cè)速度。相比 SSD512 和 Faster R-CNN(使用 ResNet),YOLOv2 在準(zhǔn)確率和運(yùn)行性能上都更勝一籌(圖中左邊第一個(gè)藍(lán)圈)。

圖 18
論文鏈接:arxiv.org/abs/1804.02767
開(kāi)源代碼:github.com/pjreddie/darknet
錄用信息:/
原文是 4 頁(yè) technical report,2018 年 4 月在 arxiv 放出
保證準(zhǔn)確率同時(shí),更快。
YOLOv3 對(duì) YOLO9000 進(jìn)行了改進(jìn),v3 采用的模型比 YOLO9000 更大,進(jìn)一步提高檢測(cè)準(zhǔn)確率,但速度比 YOLO9000 稍慢。相比其他檢測(cè)算法,RetinaNet、SSD、DSSD 等算法,YOLOv3 的綜合性能(準(zhǔn)確率 & 速度)仍然很是最好的。但總的來(lái)說(shuō),文章的改進(jìn)主要還是修修補(bǔ)補(bǔ),換換網(wǎng)絡(luò),沒(méi)有特別的突出創(chuàng)新點(diǎn)。具體改進(jìn)如下:
候選框預(yù)測(cè)時(shí)增加“物體性”的預(yù)測(cè),即增加對(duì)候選框「是否包含物體」的判斷。這條改進(jìn)借鑒 Faster R-CNN 的做法。區(qū)別在于,F(xiàn)aster R-CNN 一個(gè) ground truth 框可能對(duì)應(yīng)多個(gè)檢測(cè)候選框,而 YOLO9000 每個(gè) ground truth object 最多對(duì)應(yīng)到一個(gè)檢測(cè)候選框。那么這會(huì)使得很多候選框?qū)?yīng)不到 ground truth box,這種候選框在訓(xùn)練時(shí)不會(huì)計(jì)算坐標(biāo)或分類誤差,而只會(huì)加入對(duì)“物體性”的檢測(cè)誤差。
多標(biāo)簽分類。每個(gè)候選框可以預(yù)測(cè)多個(gè)分類,使用邏輯歸二分類器進(jìn)行分類。
多尺度預(yù)測(cè)。借鑒 FPN 思想,在 3 個(gè)尺度上進(jìn)行預(yù)測(cè),每個(gè)尺度對(duì)應(yīng) 3 個(gè)候選框,每個(gè)候選框輸出“位置偏移”,是否包含物體以及分類結(jié)果。YOLOv3 對(duì)小物體的檢測(cè)效果比 YOLO9000 有提升,但是對(duì)中大物體的檢測(cè)準(zhǔn)確率卻有降低。文章沒(méi)給出具體原因。
提出新的 basenet。YOLOv3 采用一個(gè) 53 層卷積的網(wǎng)絡(luò)結(jié)構(gòu),號(hào)稱 darknet-53,網(wǎng)絡(luò)設(shè)計(jì)只采用 3x3,1x1 的卷積層,借鑒了 ResNet 的殘差網(wǎng)絡(luò)思想。該 basenet 在 ImageNet 上對(duì) 256x256 的 Top-5 分類準(zhǔn)確率為 93.5,與 ResNet-152 相同,Top-1 準(zhǔn)確率為 77.2%,只比 ResNet-152 低 0.4%。與此同時(shí),darknet-53 的計(jì)算復(fù)雜度僅為 ResNet-152 的 75%, 實(shí)際檢測(cè)速度(FPS)是 ResNet-152 的 2 倍。
除以上改進(jìn)外,YOLOv3 還做了一些其他嘗試,但效果都不理想。具體見(jiàn)論文,此處不列出。
對(duì) 320x320 的輸入圖像,YOLOv3 在保證檢測(cè)準(zhǔn)確率與 SSD 一致(mAP=28.2)的前提下,處理每張圖像的時(shí)間為 22ms,比 SSD 快 3 倍。
值得注意的是,論文提出的 darknet-53,是一個(gè)比 ResNet152 綜合性能更好的分類網(wǎng)絡(luò)。
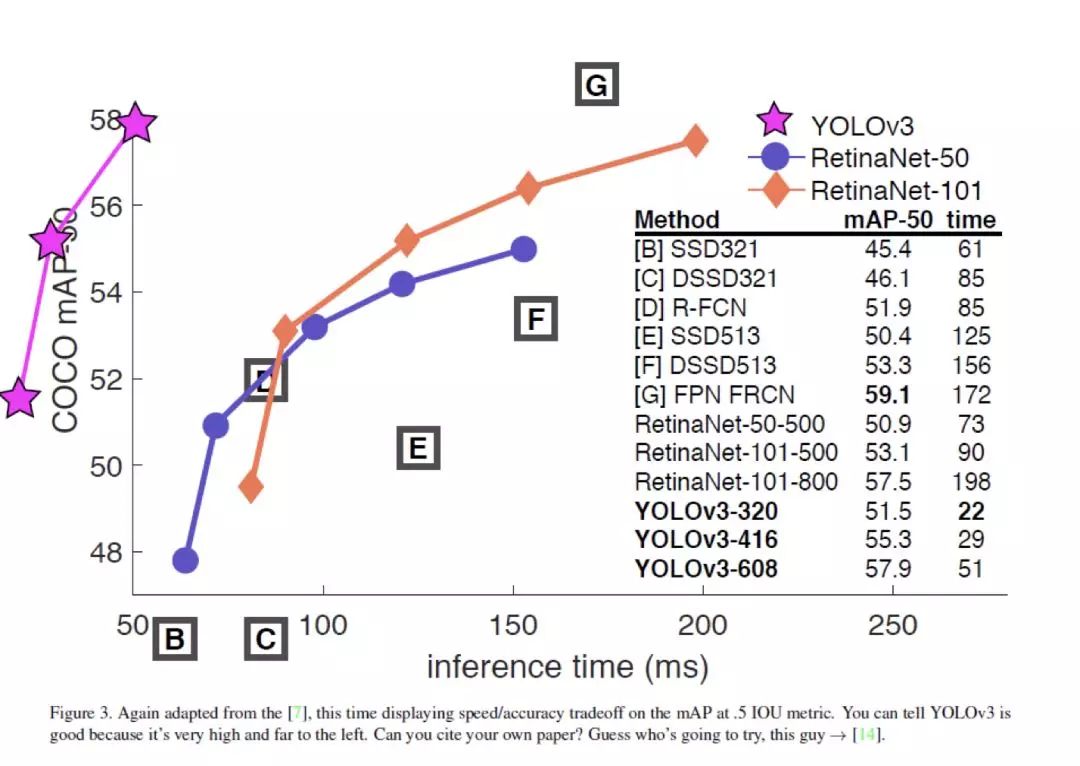
圖 19
論文鏈接:arxiv.org/abs/1805.06361
開(kāi)源代碼:/
錄用信息:/
為了解決檢測(cè)算法計(jì)算復(fù)雜度過(guò)高、內(nèi)存占用過(guò)大的問(wèn)題,本文提出了一種快而有效的方法,能夠在保持高檢測(cè)率的同時(shí),達(dá)到每秒 200 幀的檢測(cè)速度。
為了實(shí)現(xiàn)又快又強(qiáng)的檢測(cè)目標(biāo),本文從三個(gè)方面提出了創(chuàng)新:網(wǎng)絡(luò)結(jié)構(gòu)、損失函數(shù)以及訓(xùn)練數(shù)據(jù)。在網(wǎng)絡(luò)結(jié)構(gòu)中,作者選擇了一種深而窄的網(wǎng)絡(luò)結(jié)構(gòu),并探討了不同特征融合方式帶來(lái)的影響。在損失函數(shù)設(shè)計(jì)中,作者提出了蒸餾損失函數(shù)以及 FM-NMS 方法以適應(yīng) one-stage 算法的改進(jìn)。最后,作者在訓(xùn)練時(shí)同時(shí)使用了已標(biāo)注數(shù)據(jù)和未標(biāo)注數(shù)據(jù)。下面具體介紹下本文在這三方面的創(chuàng)新工作。
一般來(lái)說(shuō),網(wǎng)絡(luò)越深越寬,效果也會(huì)越好,但同時(shí)計(jì)算量和參數(shù)量也會(huì)隨之增加。為了平衡算法的效果與速度,作者采用了一個(gè)深而窄的網(wǎng)絡(luò)結(jié)構(gòu)。示意圖如下:
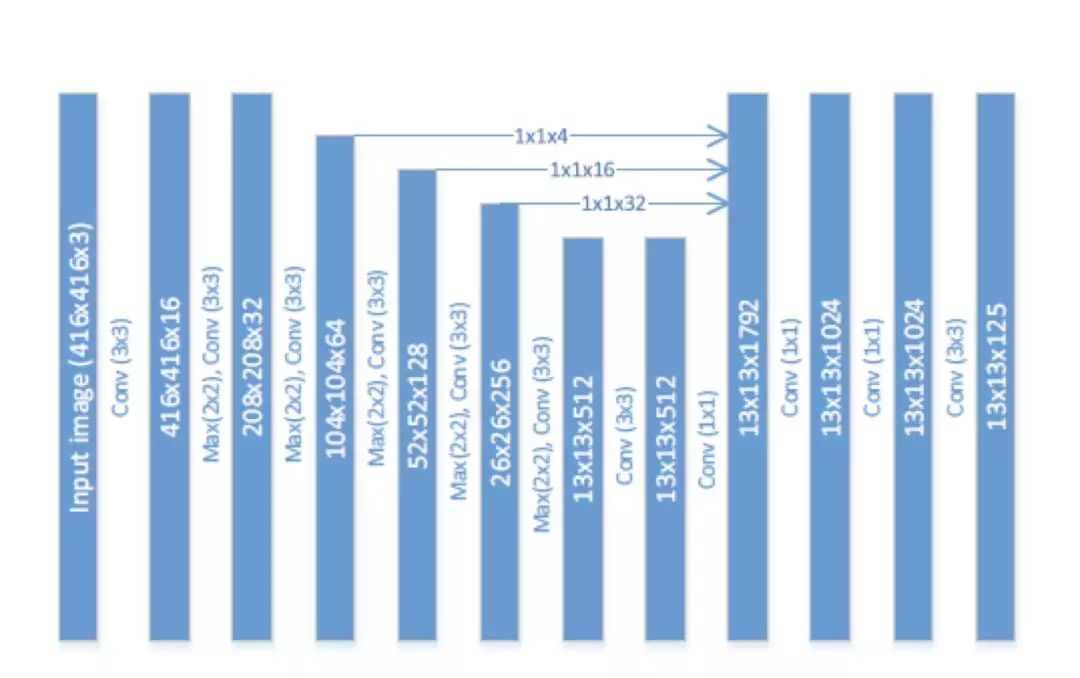
圖 20
說(shuō)明一下,本文的 baseline 算法是 Tiny-Yolo(Yolo 9000 的加速版)。
為了實(shí)現(xiàn)更窄,作者將卷積的通道數(shù)做了縮減,從 Yolo 算法的 1024 縮減為了 512;為了實(shí)現(xiàn)更寬,作者在最后添加了 3 個(gè) 1*1 的卷積層。為了加深理解,建議讀者結(jié)合 Yolo 的網(wǎng)絡(luò)結(jié)構(gòu)圖,對(duì)比查看。
從上圖中,我們還可以看出,作者采用了特征融合的方式,將前幾層提取的特征融合到了后面層的特征圖中。在融合的過(guò)程中,作者并沒(méi)有采取對(duì)大尺寸特征圖做 max pooling 然后與小尺寸特征圖做融合的方式,而是采用了 stacking 方法,即先將大尺寸特征圖進(jìn)行 resize 然后再和小尺寸特征圖做融合。具體到上圖中,對(duì) 104*104*64 的特征圖用卷積核數(shù)量為 4,大小為 1*1 的卷積層進(jìn)行壓縮,得到 104*104*4 的特征圖,然后做 resize 得到 13
13*256 的輸出。
蒸餾算法是模型壓縮領(lǐng)域的一個(gè)分支。簡(jiǎn)單來(lái)說(shuō),蒸餾算法是用一個(gè)復(fù)雜網(wǎng)絡(luò)(teacher network)學(xué)到的東西去輔助訓(xùn)練一個(gè)簡(jiǎn)單網(wǎng)絡(luò)(student network)。但直接將蒸餾算法應(yīng)用于 one stage 的 Yolo 算法還存在著一些困難。
困難 1 是對(duì)于 two stage 算法,在第一階段就會(huì)去除很多背景 RoI,送入檢測(cè)網(wǎng)絡(luò)的 RoI 相對(duì)較少,并且大部分包含 object;而 one stage 算法,輸出中包含大量背景 RoI。如果直接對(duì)輸出進(jìn)行學(xué)習(xí),會(huì)導(dǎo)致網(wǎng)絡(luò)過(guò)于關(guān)注背景,而忽視了前景。
鑒于此,本文作者提出 objectness scaled distillation,主要考慮了 teacher network 中輸出的 objectness 對(duì)損失函數(shù)的影響。作者認(rèn)為只有 objectness 比較大的才應(yīng)該對(duì)損失函數(shù)有貢獻(xiàn)。
為了更好地理解作者的思路,我們先回顧一下 Yolo 算法的損失函數(shù),如下所示:


困難 2 是對(duì)于檢測(cè)算法來(lái)說(shuō),如果不做 NMS,直接將 teacher network 的預(yù)測(cè) RoI 輸出給 student network,會(huì)因?yàn)槟承?box 有很多的相關(guān)預(yù)測(cè) RoI 而導(dǎo)致這些 box 容易過(guò)擬合。
鑒于此,本文作者提出 FM-NMS。取 3*3 區(qū)域內(nèi)的相鄰 grid cell,對(duì)這 9 個(gè) grid cell 中預(yù)測(cè)相同類別的 bbox 按照 objectness 進(jìn)行排序,只選擇得分最高的那個(gè) bbox 傳給 student network。2 個(gè) grid cell 做 FM-NMS 的示意圖如下:
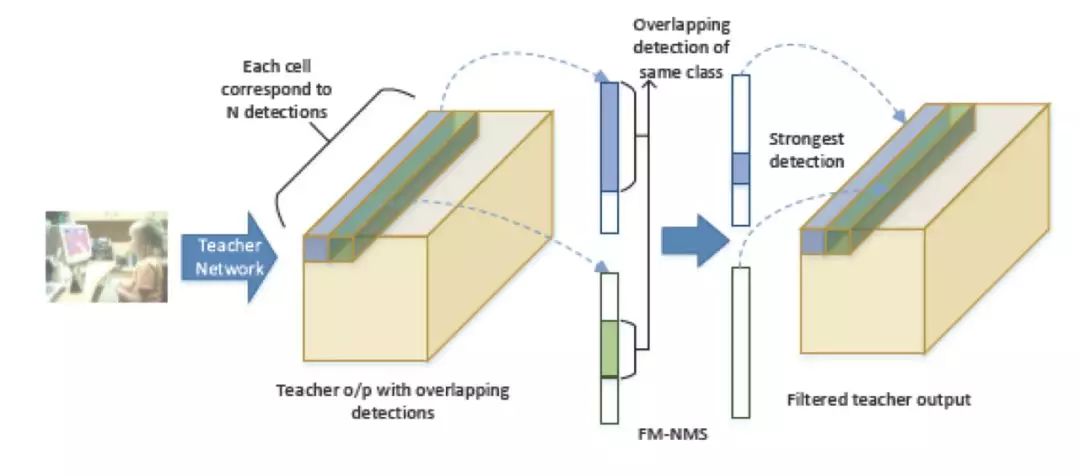
圖 21
鑒于作者使用了蒸餾算法,在訓(xùn)練時(shí),可以非常方便地使用已標(biāo)注數(shù)據(jù)和未標(biāo)注數(shù)據(jù)。如果有標(biāo)注數(shù)據(jù),就使用完整的蒸餾損失函數(shù)。如果沒(méi)有標(biāo)注數(shù)據(jù),就只使用蒸餾損失函數(shù)的 distillation loss 部分。
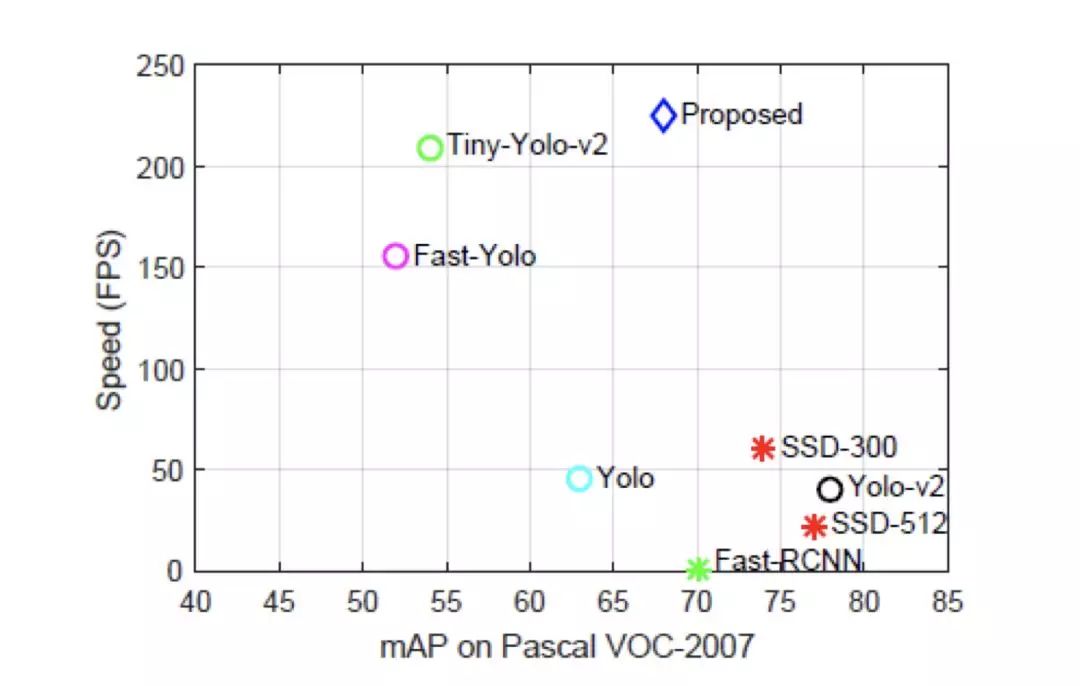
圖 22
論文鏈接:arxiv.org/abs/1701.06659
開(kāi)源代碼:github.com/MTCloudVision/mxnet-dssd(綜述筆者實(shí)現(xiàn)版本)
錄用信息:/
大小物體通吃。使用 Top-Down 網(wǎng)絡(luò)結(jié)構(gòu),解決小物體檢測(cè)的問(wèn)題。DSSD 論文的詳細(xì)解讀可以參見(jiàn):https://zhuanlan.zhihu.com/p/33036037
DSSD 與 FPN 類似,都是基于 Top-Down 結(jié)構(gòu)解決小物體檢測(cè),不同的是,如 FPN 的網(wǎng)絡(luò)結(jié)構(gòu)只是針對(duì) ResNet 做了優(yōu)化,文章中也沒(méi)有提及過(guò)更換其他的基礎(chǔ)網(wǎng)絡(luò)的實(shí)驗(yàn)結(jié)果,普適度不夠。DSSD 作者提出一種通用的 Top-Down 的融合方法,使用 vgg 和 ResNet 網(wǎng)絡(luò)將高層的語(yǔ)義信息融入到低層網(wǎng)絡(luò)的特征信息中,豐富預(yù)測(cè)回歸位置框和分類任務(wù)輸入的多尺度特征圖,以此來(lái)提高檢測(cè)精度。
筆者認(rèn)為,雖然 Top-Down 結(jié)構(gòu)也許有效,但畢竟 DSSD 比 FPN 放出時(shí)間更晚一些,且在網(wǎng)絡(luò)結(jié)構(gòu)上這并沒(méi)有太大創(chuàng)新,也許這就是本文未被會(huì)議收錄的原因之一。
DSSD 是基于 SSD 的改進(jìn),引入了 Top-Down 結(jié)構(gòu)。下文分別從這兩方面出發(fā),介紹 DSSD 思想。
DSSD 相對(duì)于 SSD 算法的改進(jìn)點(diǎn),總結(jié)如下:
提出基于 Top-Down 的網(wǎng)絡(luò)結(jié)構(gòu),用反卷積代替?zhèn)鹘y(tǒng)的雙線性插值上采樣。
在預(yù)測(cè)階段引入殘差單元,優(yōu)化候選框回歸和分類任務(wù)輸入的特征圖。
采用兩階段訓(xùn)練方法。
DSSD 的網(wǎng)絡(luò)結(jié)構(gòu)與 SSD 對(duì)比如下圖所示,以輸入圖像尺寸為為例,圖中的上半部分為 SSD-ResNet101 的網(wǎng)絡(luò)結(jié)構(gòu),conv3_x 層和 conv5_x 層為原來(lái)的 ResNet101 中的卷積層,后面的五層是 SSD 擴(kuò)展卷積層,原來(lái)的 SSD 算法是將這七層的特征圖直接輸入到預(yù)測(cè)階段做框的回歸任務(wù)和分類任務(wù)。DSSD 是將這七層特征圖拿出六層(去掉尺寸為的特征圖)輸入到反卷積模型里,輸出修正的特征圖金字塔,形成一個(gè)由特征圖組成的沙漏結(jié)構(gòu)。最后經(jīng)預(yù)測(cè)模塊輸入給框回歸任務(wù)和分類任務(wù)做預(yù)測(cè)。
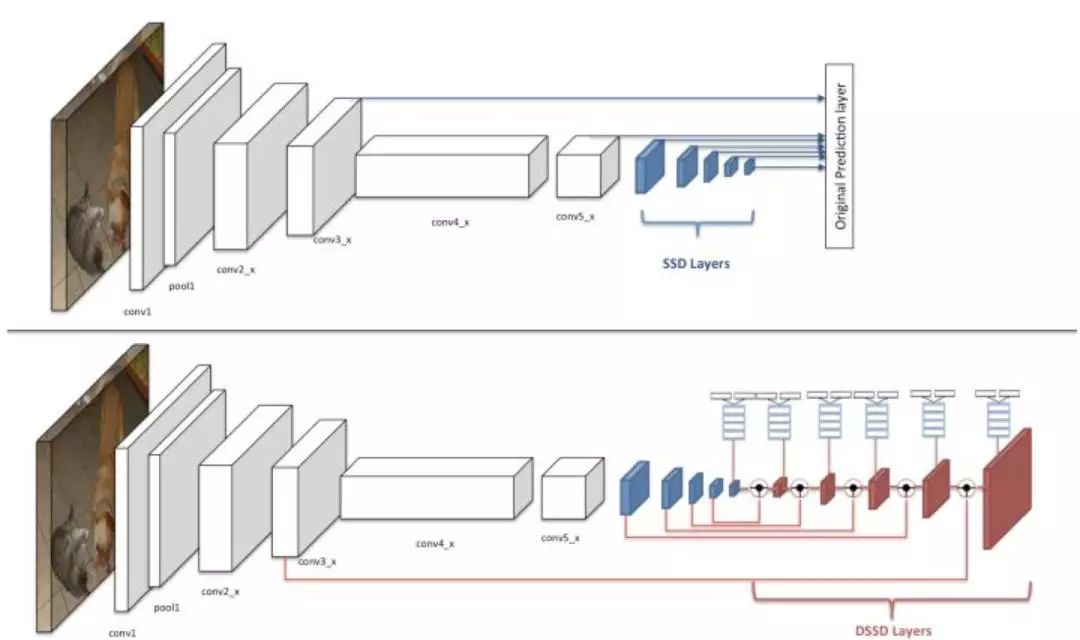
圖 23
DSSD 中的 D,即反卷積模型,指的是 DSSD 中高層特征和低層特征的融合模塊,其基本結(jié)構(gòu)如下圖所示:
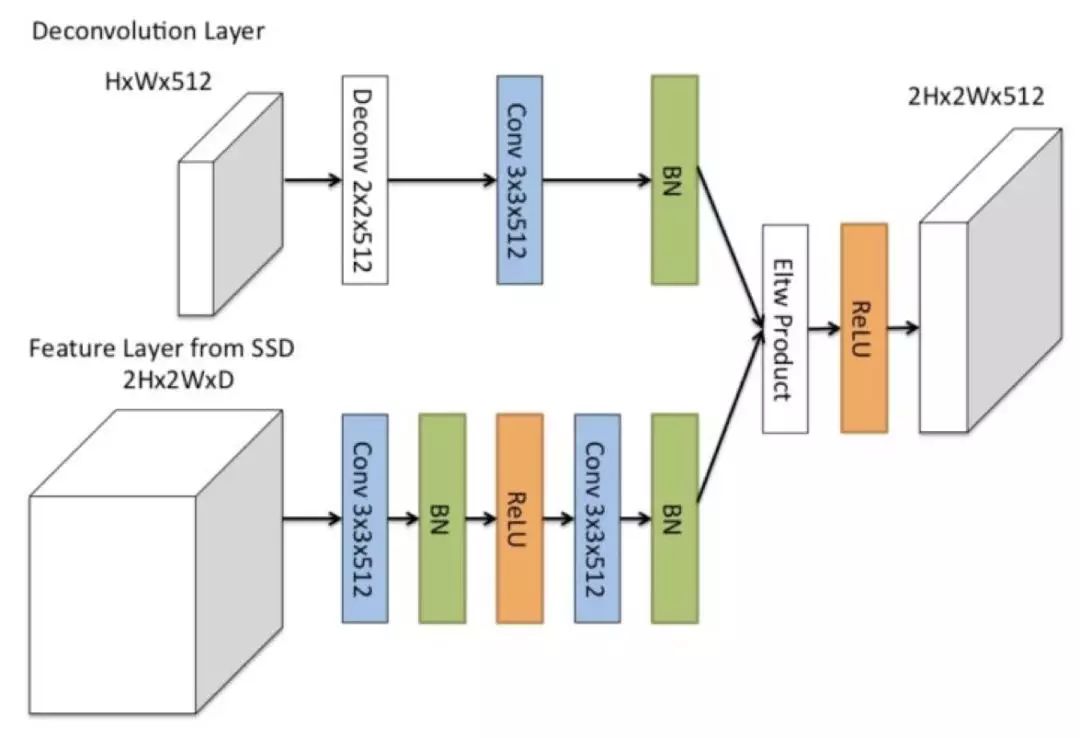
圖 24
同樣是采用 Top-Down 方式,DSSD 與 FPN 和 TDM(這兩篇論文將在本論述后文中詳細(xì)介紹)的網(wǎng)絡(luò)結(jié)構(gòu)區(qū)別如下圖。可以看出,TDM 使用的是 concat 操作,讓淺層和深層的特征圖疊在一起。DSSD 使用的是 Eltw Product(也叫 broadcast mul)操作,將淺層和深層的特征圖在對(duì)應(yīng)的信道上做乘法運(yùn)算。FPN 使用的是 Eltw Sum(也叫 broadcast add)操作,將淺層和深層的特征圖在對(duì)應(yīng)的信道上做加法運(yùn)算。

圖 25
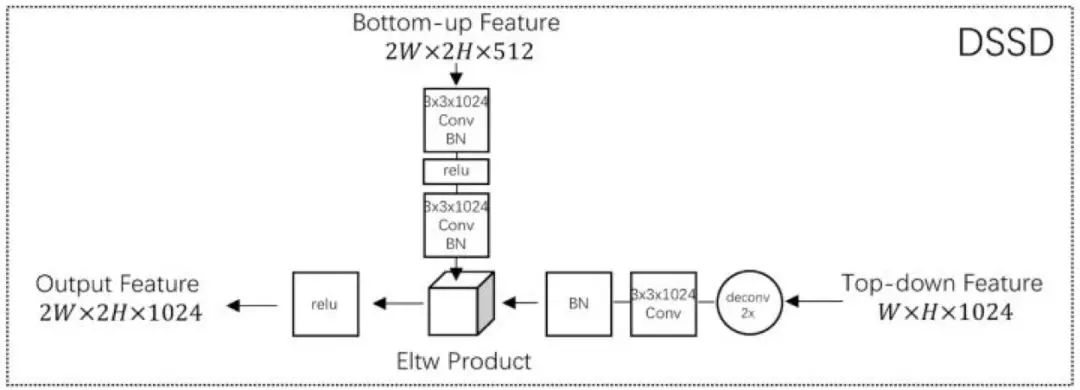
圖 26

圖 27
DSSD 當(dāng)輸入為 513x513 的時(shí)候在 VOC2007 數(shù)據(jù)集賞達(dá)到了 80.0%mAP。更詳細(xì)的實(shí)驗(yàn)復(fù)現(xiàn)和結(jié)果對(duì)比見(jiàn):https://zhuanlan.zhihu.com/p/33036037
論文鏈接:arxiv.org/abs/1708.0124
開(kāi)源代碼:github.com/szq0214/DSOD
錄用信息:ICCV2017
從零開(kāi)始訓(xùn)練檢測(cè)網(wǎng)絡(luò)。DSOD 旨在解決以下兩個(gè)問(wèn)題:
是否可以從零開(kāi)始訓(xùn)練檢測(cè)模型?
如果可以從零訓(xùn)練,什么樣的設(shè)計(jì)會(huì)讓網(wǎng)絡(luò)結(jié)果更好?
DSOD 是第一個(gè)不使用圖像分類預(yù)訓(xùn)練模型進(jìn)行物體檢測(cè)訓(xùn)練初始化的檢測(cè)算法。此外,DSOD 網(wǎng)絡(luò)參數(shù)只有 SSD 的 1/2,F(xiàn)aster R-CNN 的 1/10。
現(xiàn)有的物體檢測(cè)算法如 Faster R-CNN、YOLO、SSD 需要使用在大規(guī)模分類數(shù)據(jù)集上訓(xùn)練得到的分類模型進(jìn)行 backbone 網(wǎng)絡(luò)初始化。比如使用 ImageNet 分類模型。這樣做的優(yōu)勢(shì)在于:1. 可以使用現(xiàn)有的模型,訓(xùn)練較快;2. 由于分類任務(wù)已經(jīng)在百萬(wàn)級(jí)的圖像上進(jìn)行過(guò)訓(xùn)練,所以再用做檢測(cè)需要的圖片數(shù)量會(huì)相對(duì)較少。
但其缺點(diǎn)也很明顯:1. 很多檢測(cè)網(wǎng)絡(luò)都是分類網(wǎng)絡(luò)改的。圖像分類網(wǎng)絡(luò)一般都較大,檢測(cè)任務(wù)可能不需要這樣的網(wǎng)絡(luò)。2. 分類和檢測(cè)的策略不同,可能其最佳收斂區(qū)域也不一樣。3. 分類任務(wù)一般都是 RGB 圖像訓(xùn)練的,但檢測(cè)有可能會(huì)使用深度圖像、醫(yī)療圖像等其他類型的圖像。導(dǎo)致圖像空間不匹配。
為解決以上問(wèn)題,DSOD 提出從零開(kāi)始訓(xùn)練檢測(cè)模型。
DSOD 網(wǎng)絡(luò)由 backbone sub-network 和 front-end sub-network 構(gòu)成,Backbone 的作用在于提取特征信息,F(xiàn)ront-end 網(wǎng)絡(luò)是檢測(cè)模塊,通過(guò)對(duì)多層信息的融合用于物體檢測(cè)。
基礎(chǔ)網(wǎng)絡(luò) Backbone sub-network 部分,是一個(gè) DenseNets 的變種, 由一個(gè) stem block, 四個(gè) dense blocks, 兩個(gè) transition layers , 兩個(gè) transition w/o pooling layers 構(gòu)成, 用來(lái)提取特征。如下圖所示:

圖 28
Stem block 中作者沒(méi)有使用 DenseNet 的 7*7 卷積,而是使用了兩個(gè) 3*3 的卷積(這點(diǎn)和 Inception-V3 的改進(jìn)很像)。作者指出這種設(shè)計(jì)可以減少?gòu)脑紙D像的信息損失,對(duì)檢測(cè)任務(wù)更有利。其他的模塊和 Densenet 很類似。作者使用了詳細(xì)的實(shí)驗(yàn)證明了基礎(chǔ)網(wǎng)絡(luò)的設(shè)計(jì)部分的規(guī)則,如 Densenet 的過(guò)渡層 transition layer 通道數(shù)不減少、Bottleneck 結(jié)構(gòu)的通道更多、使用 stem block 而非 7*7 卷積對(duì)最終的識(shí)別率都是有提升的。
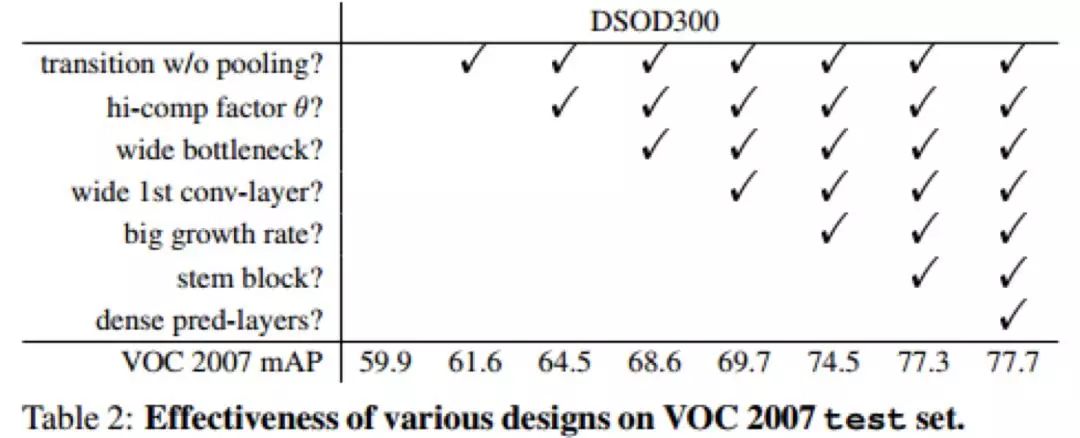
圖 29
經(jīng)過(guò)基礎(chǔ)特征提取后,檢測(cè)的網(wǎng)絡(luò) Front-end sub-network 有兩種實(shí)現(xiàn)方式:Plain Connection 和 Dense Connection。其中 Plain Connection 就是 SSD 的特征融合方法。注意虛框中的是 Bottlenet 結(jié)構(gòu),即使用 1*1 的卷積先降維然后再接 3*3 的卷積。
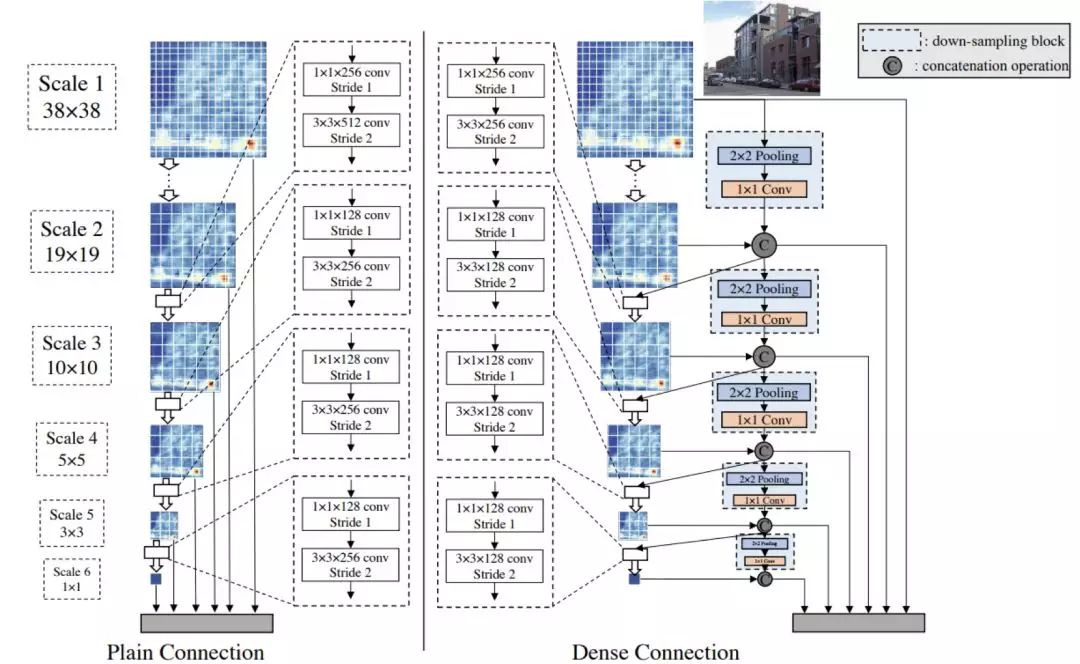
圖 30
筆者認(rèn)為 Dense Connection 結(jié)構(gòu)就是 DSOD 的主要?jiǎng)?chuàng)新點(diǎn),這部分也很巧妙的采用了 densenet 的思想,一半的 Feature map 由前一個(gè) scale 學(xué)到,剩下的一半是直接 down-sampling 的高層特征。

圖 31
以第一個(gè)鏈接結(jié)構(gòu)為例,該結(jié)構(gòu)的輸入一半為上一層的降采樣的 Feature Map,其中通道的改變由 1*1 的卷積完成。另一半為這個(gè)尺度學(xué)習(xí)到的 feature。經(jīng)過(guò) Concat 后的輸出是三個(gè)部分:1. 經(jīng)過(guò) 1*1 卷積和 3*3 卷積作為下一層的輸入;2. 直接降采樣并修改通道作為下一層的輸入;3. 輸入這一層的 feature 到最后的檢測(cè)任務(wù)。
DSOD 的檢測(cè)速度 (17.4fps) 比 SSD、YOLO2 略差,但在模型準(zhǔn)確率和模型大小方面卻更勝一籌,最小的網(wǎng)絡(luò)只有 5.9M,同時(shí) mAP 也能達(dá) 73.6%。作者在實(shí)驗(yàn)部分還使用了 pre-trained model 初始化 DSOD,結(jié)果反而沒(méi)有從零開(kāi)始訓(xùn)練效果好, 未來(lái)可能去探究一下。
END
整理不易,點(diǎn)贊三連↓