
Go 常見錯(cuò)誤集錦 | 字符串底層原理及常見錯(cuò)誤
大家好,我是 Go 學(xué)堂的漁夫子。
string 是 Go 語言的基礎(chǔ)類型,在實(shí)際項(xiàng)目中針對(duì)字符串的各種操作使用頻率也較高。本文就介紹一下在使用 string 時(shí)容易犯的一些錯(cuò)誤以及如何避免。
01 字符串的一些基本概念
首先我們看下字符串的基本的數(shù)據(jù)結(jié)構(gòu):
type?stringStruct?struct?{
????str?unsafe.Pointer
????len?int
}
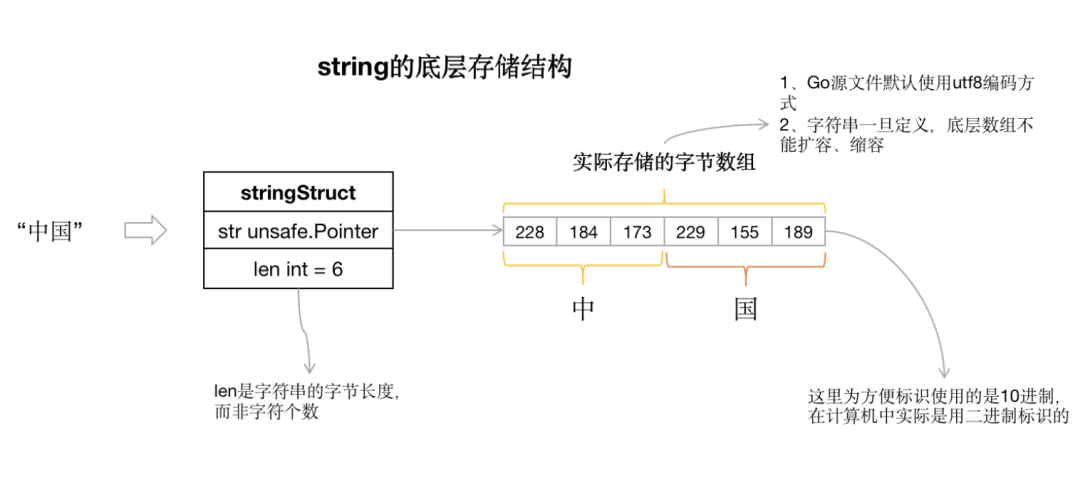
由字符串的數(shù)據(jù)結(jié)構(gòu)可知,字符串只包含兩個(gè)成員:
stringStruct.str:一個(gè)指向底層數(shù)據(jù)的指針 stringStruct.len:字符串的字節(jié)長度,非字符個(gè)數(shù)。假設(shè),我們定義了一個(gè)字符串 “中國”, 如下:
a?:=?"中國"
因?yàn)?Go 語言對(duì)源代碼默認(rèn)使用 utf-8 編碼方式,utf-8 對(duì)” 中 “使用 3 個(gè)字節(jié),對(duì)應(yīng)的編碼是(我們這里每個(gè)字節(jié)編碼用 10 進(jìn)制表示):228 184 173。同樣 “國” 的 utf-8 編碼是:229 155 189。如下存儲(chǔ)示意圖:
02 rune 是什么
要想理解 rune,就會(huì)涉及到 unicode 字符集和字符編碼的概念以及二者之間的關(guān)系。
unicode 字符集是對(duì)世界上多種語言字符的通用編碼,也叫萬國碼。在 unicode 字符集中,每一個(gè)字符都有一個(gè)對(duì)應(yīng)的編號(hào),我們稱這個(gè)編號(hào)為 code point,而 Go 中的rune 類型就代表一個(gè)字符的 code point。
字符集只是將每個(gè)字符給了一個(gè)唯一的編碼而已。而要想在計(jì)算機(jī)中進(jìn)行存儲(chǔ),則必須要通過特定的編碼轉(zhuǎn)換成對(duì)應(yīng)的二進(jìn)制才行。所以就有了像 ASCII、UTF-8、UTF-16 等這樣的編碼方式。而在 Go 中默認(rèn)是使用 UTF-8 字符編碼進(jìn)行編碼的。所有 unicode 字符集合和字符編碼之間的關(guān)系如下圖所示:
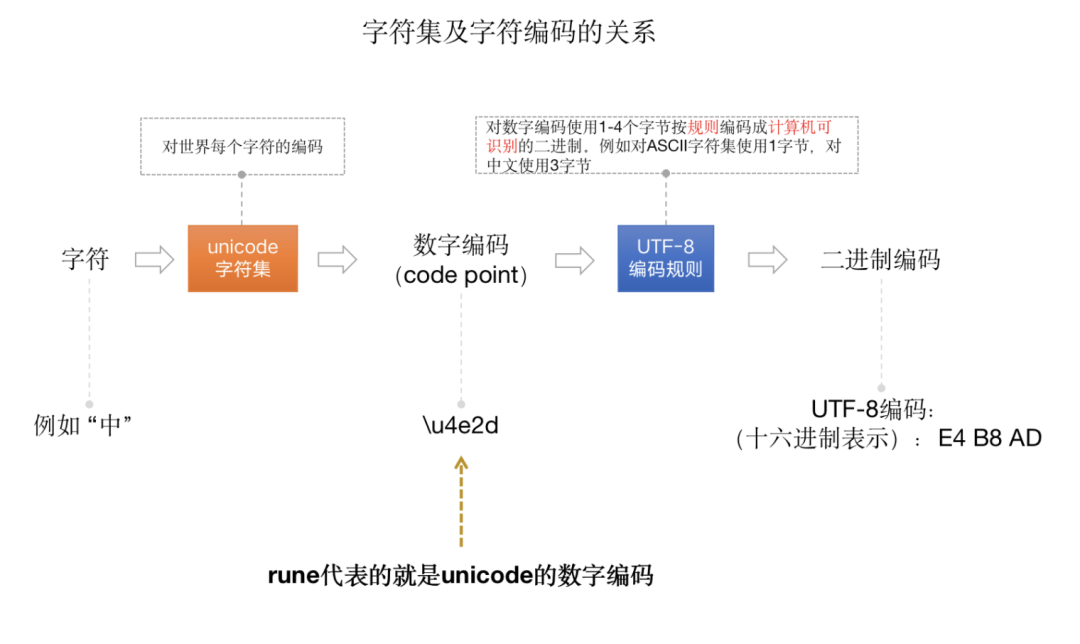
我們知道,UTF-8 字符編碼是一種變長字節(jié)的編碼方式,用 1 到 4 個(gè)字節(jié)對(duì)字符進(jìn)行編碼,即最多 4 個(gè)字節(jié),按位表示就是 32 位。所以,在 Go 的源碼中,我們會(huì)看到對(duì) rune 的定義是 int32 的別名:
//?rune?is?an?alias?for?int32?and?is?equivalent?to?int32?in?all?ways.?It?is
//?used,?by?convention,?to?distinguish?character?values?from?integer?values.
type?rune?=?int32
好,有了以上基礎(chǔ)知識(shí),我們來看看在使用 string 過程中有哪些需要注意的地方。
03 strings.TrimRight 和 strings.TrimSuffix 的區(qū)別
strings.TrimRight 函數(shù)
該函數(shù)的定義如下:
func?TrimRight(s,?cutset?string)?string
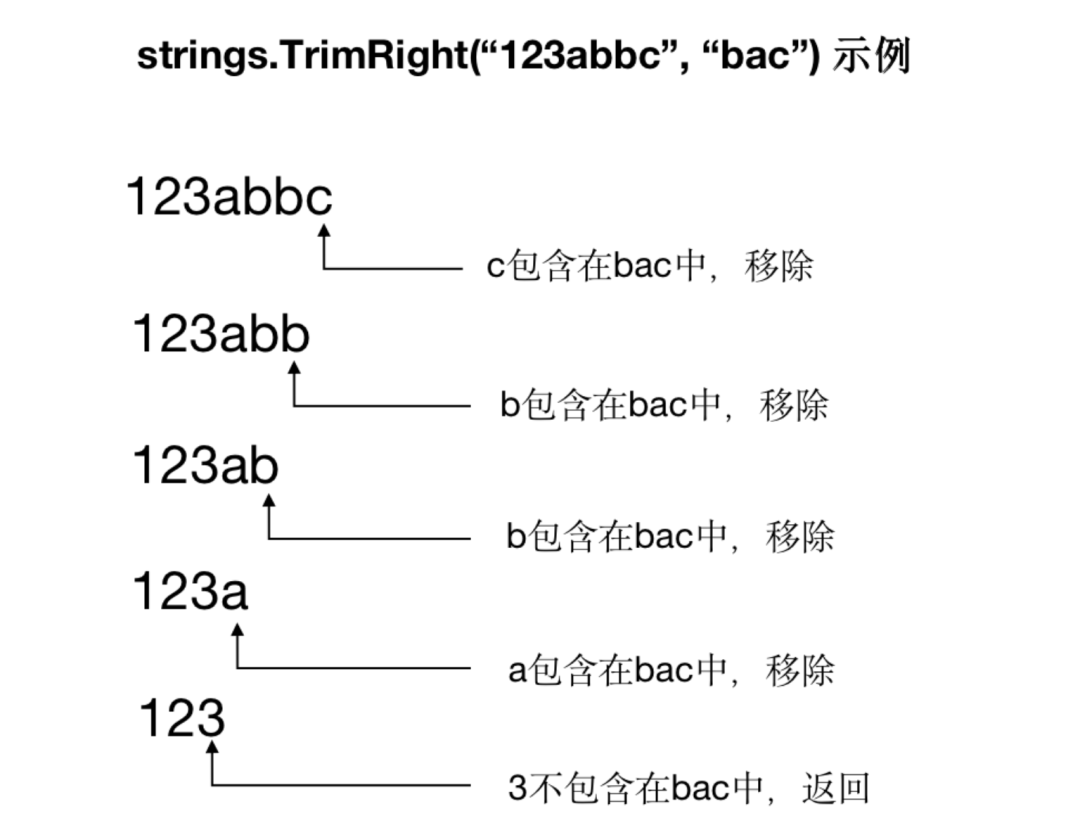
該函數(shù)的功能是:從 s 字符串的末尾依次查找每一個(gè)字符,如果該字符包含在 cutset 中,則被移除,直到遇到第一個(gè)不在 cutset 中的字符。例如:
fmt.Println(strings.TrimRight("123abbc",?"bac"))
執(zhí)行示例代碼,會(huì)將字符串末尾的 abbc 都去除掉,打印出"123"。執(zhí)行邏輯如下:
strings.TrimSuffix 函數(shù)
該函數(shù)是將字符串指定的后綴字符串移除。定義如下:
func?TrimSuffix(s,?suffix?string)?string
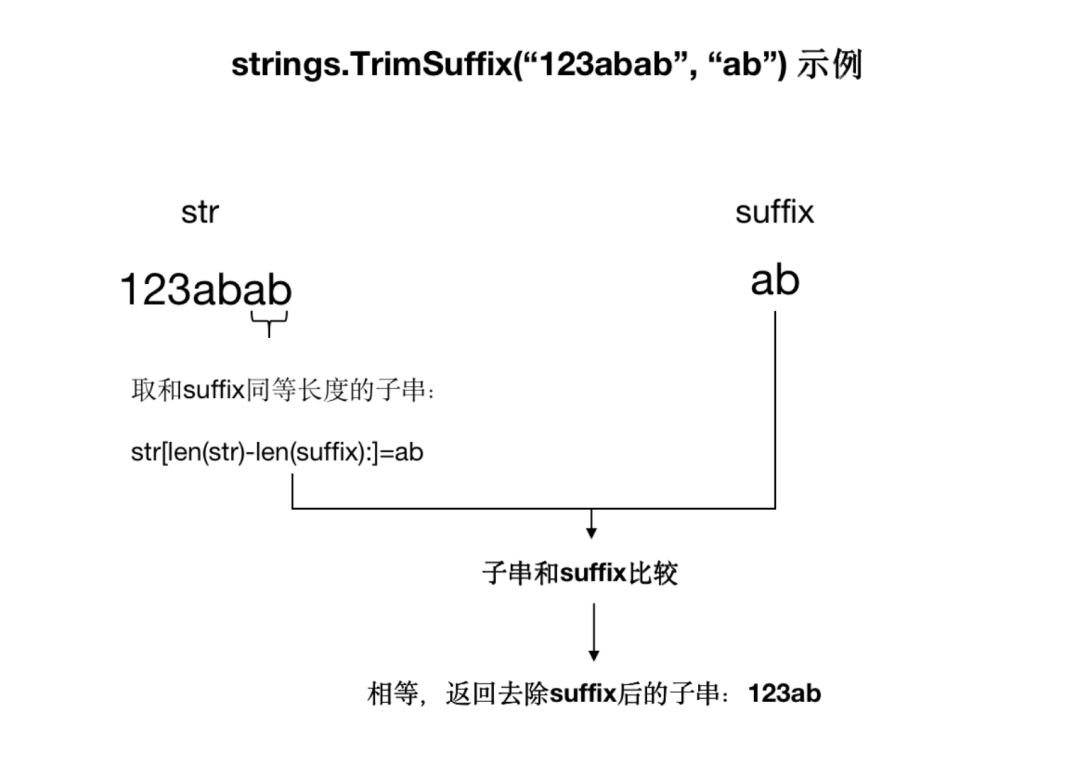
此函數(shù)的實(shí)現(xiàn)原理是,從字符串 s 中截取末尾的長度和 suffix 字符串長度相等的子字符串,然后和 suffix 字符串進(jìn)行比較,如果相等,則將 s 字符串末尾的子字符串移除,如果不等,則返回原來的 s 字符串,該函數(shù)只截取一次。
我們通過如下示例來了解下其執(zhí)行邏輯:
fmt.Println(strings.TrimSuffix("123abab",?"ab"))
我們注意到,該字符串末尾有兩個(gè) ab,但最終只有末尾的一個(gè) ab 被去除掉,保留” 123ab"。執(zhí)行邏輯如下圖所示:
以上的原理同樣適用于 strings.TrimLeft 和 strings.Prefix 的字符串操作函數(shù)。而 strings.Trim 函數(shù)則同時(shí)包含了 strings.TrimLeft 和 strings.TrimRight 的功能。
04 字符串拼接性能問題
拼接字符串是在項(xiàng)目中經(jīng)常使用的一個(gè)場(chǎng)景。然而,拼接字符串時(shí)的性能問題會(huì)常常被忽略。性能問題其本質(zhì)上就是要注意在拼接字符串時(shí)是否會(huì)頻繁的產(chǎn)生內(nèi)存分配以及數(shù)據(jù)拷貝的操作。
我們來看一個(gè)性能較低的拼接字符串的例子:
func?concat(ids?[]string)?string?{
????s?:=?""
????for?_,?id?:=?range?ids?{
????????s?+=?id
????}
????return?s
}
這段代碼執(zhí)行邏輯上不會(huì)有任何問題,但是在進(jìn)行 s += id 進(jìn)行拼接時(shí),由于字符串是不可變的,所以每次都會(huì)分配新的內(nèi)存空間,并將兩個(gè)字符串的內(nèi)容拷貝到新的空間去,然后再讓 s 指向新的空間字符串。由于分配的內(nèi)存次數(shù)多,當(dāng)然就會(huì)對(duì)性能造成影響。如下圖所示:
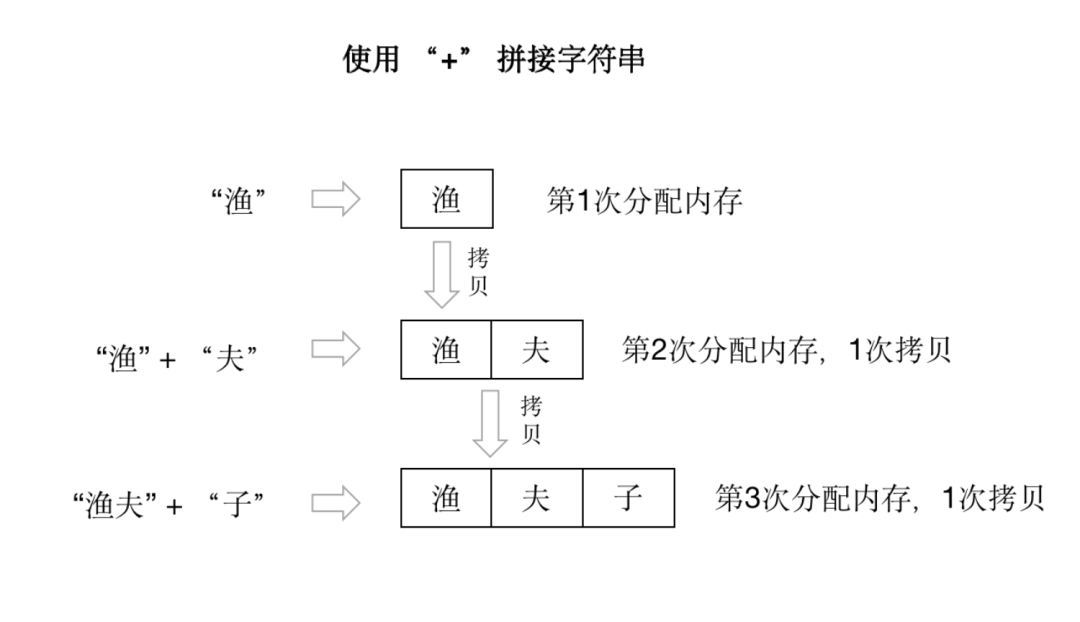
那該如何提高拼接的性能呢?可以通過 strings.Builder 進(jìn)行改進(jìn)。strings.Builder 本質(zhì)上是分配了一個(gè)字節(jié)切片,然后通過 append 的操作,將字符串的字節(jié)依次加入到該字節(jié)切片中。因?yàn)榍衅A(yù)分配空間的特性,可參考切片擴(kuò)容,以有效的減少內(nèi)存分配的次數(shù),以提高性能。
func?concat(ids?[]string)?string?{
????sb?:=?strings.Builder{}?
????for?_,?id?:=?range?ids?{
????????_,?_?=?sb.WriteString(id)?
????}
????return?sb.String()?
}
我們看下 strings.Builder 的數(shù)據(jù)結(jié)構(gòu):
type?Builder?struct?{
????addr?*Builder?//?of?receiver,?to?detect?copies?by?value
????buf??[]byte
}
由此可見,Builder 的結(jié)構(gòu)體中有一個(gè) buf [] byte,當(dāng)執(zhí)行 sb.WriteString(id) 方法時(shí),實(shí)際上是調(diào)用了 append 的方法,將字符串的每個(gè)字節(jié)都存儲(chǔ)到了字節(jié)切片 buf 中。如下圖所示:
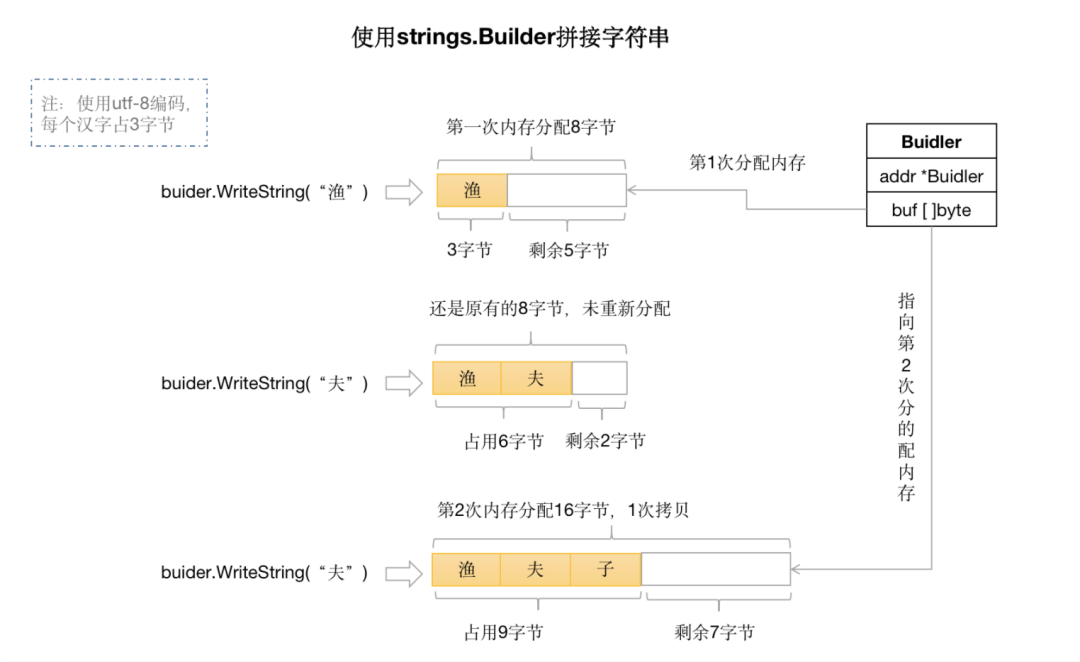
上圖中,第一次分配的內(nèi)存空間是 8 個(gè)字節(jié),這跟 Go 的內(nèi)存管理有關(guān)系,網(wǎng)上有很多相關(guān)文章,這里不再詳細(xì)討論。
如果我們能提前知道要拼接的字符串的長度,我們還可以提前使用Builder 的 Grow 方法來預(yù)分配內(nèi)存,這樣在整個(gè)字符串拼接過程中只需要分配一次內(nèi)存就好了,極大的提高了字符串拼接的性能。如下圖所示及代碼:
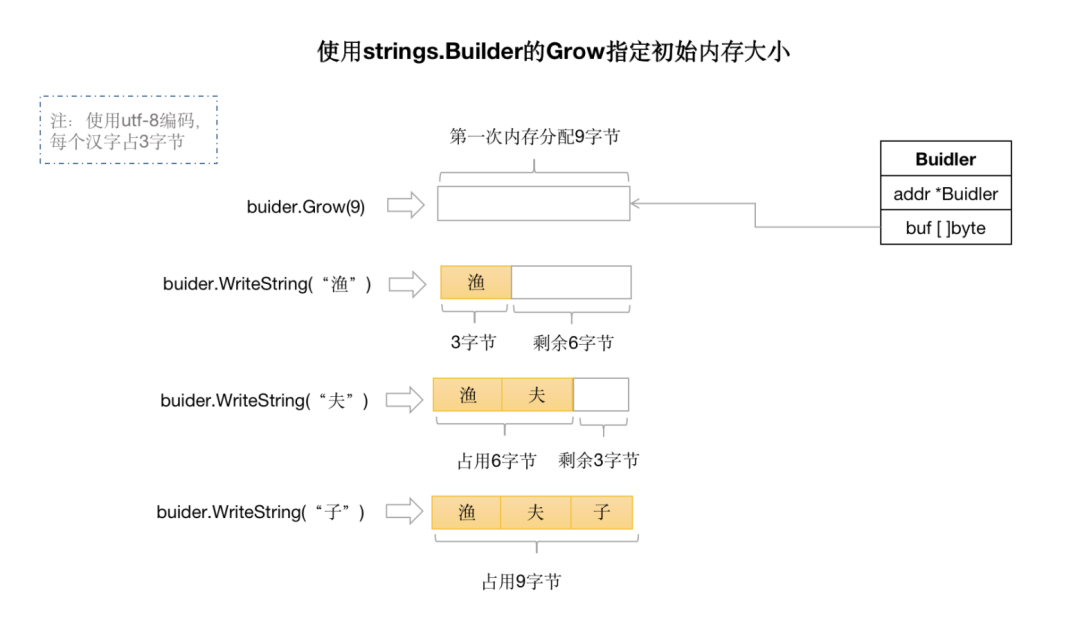
示例代碼:
func?concat(ids?[]string)?string?{
????total?:=?0
????for?i?:=?0;?i?????????total?+=?len(ids[i])
????}
????sb?:=?strings.Builder{}
????sb.Grow(total)?
????for?_,?id?:=?range?ids?{
????????_,?_?=?sb.WriteString(id)
????}
????return?sb.String()
}
strings.Builder 的使用場(chǎng)景一般是在循環(huán)中對(duì)字符串進(jìn)行拼接,如果只是拼接兩個(gè)或少數(shù)幾個(gè)字符串的話,推薦使用 "+"操作符,例如: s := s1 + s2 + s3,該操作并非每個(gè) + 操作符都計(jì)算一次長度,而是會(huì)首先計(jì)算三個(gè)字符串的總長度,然后分配對(duì)應(yīng)的內(nèi)存,再將三個(gè)字符串都拷貝到新申請(qǐng)的內(nèi)存中去。
05 無用字符串的轉(zhuǎn)換
我們?cè)趯?shí)際項(xiàng)目中往往會(huì)遇到這種場(chǎng)景:是選擇字節(jié)切片還是字符串的場(chǎng)景。而大多數(shù)程序員會(huì)傾向于選擇字符串。但是,很多 IO 的操作實(shí)際上是使用字節(jié)切片的。其實(shí),bytes 包中也有很多和 strings 包中相同操作的函數(shù)。
我們看這樣一個(gè)例子:實(shí)現(xiàn)一個(gè) getBytes 函數(shù),該函數(shù)接收一個(gè) io.Reader 參數(shù)作為讀取的數(shù)據(jù)源,然后調(diào)用 sanitize 函數(shù),該函數(shù)的作用是去除字符串內(nèi)容兩端的空白字符。我們看下第一個(gè)實(shí)現(xiàn):
func?getBytes(reader?io.Reader)?([]byte,?error)?{
?b,?err?:=?io.ReadAll(reader)
?if?err?!=?nil?{
?return?nil,?err
?}
?//?Call?sanitize
?return?[]byte(sanitize(string(b))),?nil
}
函數(shù) sanitize 接收一個(gè)字符串類型的參數(shù)的實(shí)現(xiàn):
func?sanitize(s?string)?string?{
?return?strings.TrimSpace(s)
}
這其實(shí)是將字節(jié)切片先轉(zhuǎn)換成了字符串,然后又將字符串轉(zhuǎn)換成字節(jié)切片返回了。其實(shí),在 bytes 包中有同樣的去除空格的函數(shù)bytes.TrimSpace,使用該函數(shù)就避免了對(duì)字節(jié)切片到字符串多余的轉(zhuǎn)換。
func?sanitize(s?[]byte)?[]byte?{
????return?bytes.TrimSpace(s)
}
06 子字符串操作及內(nèi)存泄露
字符串的切分也會(huì)跟切片的切分一樣,可能會(huì)造成內(nèi)存泄露。下面我們看一個(gè)例子:有一個(gè) handleLog 的函數(shù),接收一個(gè) string 類型的參數(shù) log,假設(shè) log 的前 4 個(gè)字節(jié)存儲(chǔ)的是 log 的 message 類型值,我們需要從 log 中提取出 message 類型,并存儲(chǔ)到內(nèi)存中。下面是相關(guān)代碼:
func?(s?store)?handleLog(log?string)?error?{
????if?len(log)?????????return?errors.New("log?is?not?correctly?formatted")
????}
????message?:=?log[:4]
????s.store(message)
????//?Do?something
}
我們使用 log[:4] 的方式提取出了 message,那么該實(shí)現(xiàn)有什么問題嗎?我們假設(shè)參數(shù) log 是一個(gè)包含成千上萬個(gè)字符的字符串。當(dāng)我們使用 log[:4] 操作時(shí),實(shí)際上是返回了一個(gè)字節(jié)切片,該切片的長度是 4,而容量則是 log 字符串的整體長度。那么實(shí)際上我們存儲(chǔ)的 message 不是包含 4 個(gè)字節(jié)的空間,而是整個(gè) log 字符串長度的空間。所以就有可能會(huì)造成內(nèi)存泄露。如下圖所示:
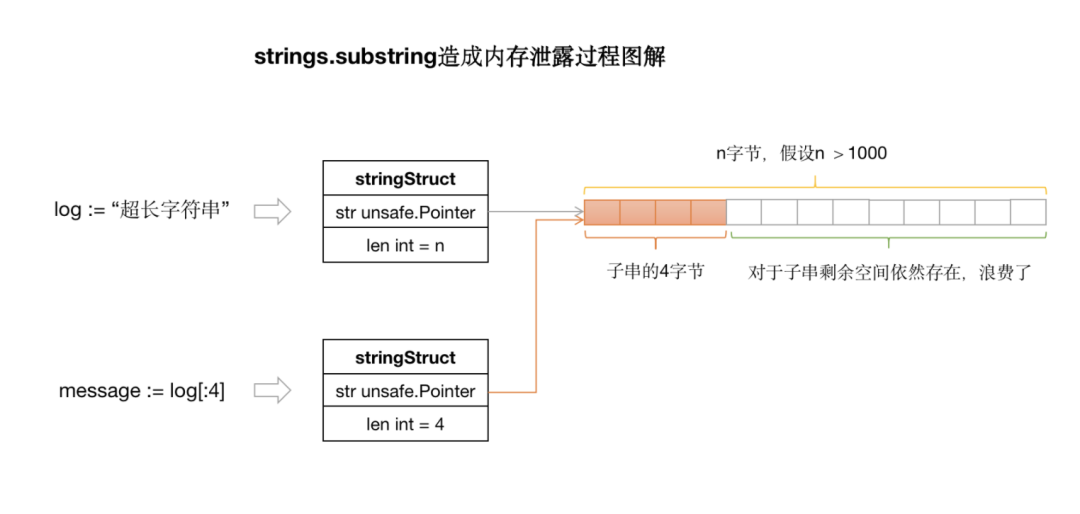
那怎么避免呢?使用拷貝。將 uuid 提取后拷貝到一個(gè)字節(jié)切片中,這時(shí)該字節(jié)切片的長度和容量都是 36。如下:
func?(s?store)?handleLog(log?string)?error?{
?if?len(log)??return?errors.New("log?is?not?correctly?formatted")
?}
?uuid?:=?string([]byte(log[:36]))?
?s.store(uuid)
?//?Do?something
}07 小結(jié)?
字符串是 Go 語言的一種基本類型,在 Go 語言中有自己的特性。字符串本質(zhì)上是一個(gè)具有長度和指向底層數(shù)組的指針的結(jié)構(gòu)體。在 Go 中,字符串是以 utf-8 編碼的字節(jié)序列將每個(gè)字符的 unicode 編碼存儲(chǔ)在指針指向的數(shù)組中的,因此字符串是不可被修改的。在實(shí)際項(xiàng)目中,我們尤其要注意字符串和字節(jié)切片之間的轉(zhuǎn)換以及在字符串拼接時(shí)的性能問題。
想要了解關(guān)于 Go 的更多資訊,還可以通過掃描的方式,進(jìn)群一起探討哦~