
《安家》熱播,我用Python對(duì)北京房?jī)r(jià)進(jìn)行了分析,結(jié)果……

關(guān)注統(tǒng)計(jì)與數(shù)據(jù)分析實(shí)戰(zhàn),帶你飛
今天,讓我們通過一個(gè)小案例快速了解一下數(shù)據(jù)分析的常規(guī)流程。
分析流程解析
分析背景
分析思路與方法
分析過程(及微觀方法)
分析結(jié)論及建議
分析背景
現(xiàn)有一份北京二手房市場(chǎng)近幾年交易情況的數(shù)據(jù)集,我們希望通過對(duì)數(shù)據(jù)集的分析對(duì)北京二手房市場(chǎng)相關(guān)信息有一個(gè)總體了解,能夠?yàn)樵诒本┵I房做出一定的數(shù)據(jù)指導(dǎo)。
字段解析
id:交易編號(hào)
tradeTime:交易時(shí)間
followers:關(guān)注人數(shù)
totalPrice:總價(jià)
price:?jiǎn)蝺r(jià)
square:面積
livingRoom:臥室數(shù)量
drawingRoom:客廳數(shù)量
kitchen:廚房數(shù)量
bathRoom:浴室數(shù)量
floor:樓層
buildingType:建筑類型
buildingStructure:建筑結(jié)構(gòu)
ladderRatio:梯戶比
elevator:有無電梯
fiveYearsProperty:是否滿五年
subway:有無地鐵
disrict:所在區(qū)域
communityAverage:小區(qū)均價(jià)
分析思路與方法
接下來,讓我們根據(jù)以上數(shù)據(jù)集的維度,整理分析思路,看看哪些信息對(duì)我們?cè)诒本┵I房比較有幫助!
首先,需要了解“價(jià)格”信息,例如:
市場(chǎng)近幾年的整體價(jià)格趨勢(shì)是什么情況?
房源在不同價(jià)格區(qū)間的大致分布狀態(tài)是什么樣子的?
然后,可以看看“交易數(shù)量與熱度”,例如:
通過不同時(shí)間的交易數(shù)量可以大致判斷有沒有明顯的交易淡旺季?
通過關(guān)注人數(shù)可以了解哪些房源比較受歡迎,然后觀察一下他們的價(jià)格及其他特征。
針對(duì)以上我們準(zhǔn)備了解的信息,本次分析主要會(huì)使用描述性統(tǒng)計(jì)方法,然后對(duì)分析結(jié)果進(jìn)行可視化展示。
常用分析方法解析
描述型分析:
最常見的分析方法,旨在告訴分析師“發(fā)生了什么”,提供了重要指標(biāo)和業(yè)務(wù)的衡量方法,利用可視化工具,能夠有效地增強(qiáng)描述型分析所提供的信息
診斷型分析:
通過評(píng)估描述型數(shù)據(jù),診斷分析工具能夠讓分析師深入分析數(shù)據(jù),鉆取到數(shù)據(jù)核心,并診斷出“為什么會(huì)發(fā)生”
預(yù)測(cè)型分析:
通過預(yù)測(cè)模型,使用各種變量來進(jìn)行預(yù)測(cè),數(shù)據(jù)成員的多樣化與預(yù)測(cè)結(jié)果密切相關(guān),通過預(yù)測(cè)型分析可以知道“可能會(huì)發(fā)生什么”
指令型分析:
指令分析不單獨(dú)使用,基于以上三種分析方法的完成,是在分析師已經(jīng)了解“發(fā)生了什么”,“為什么會(huì)發(fā)生”以及“可能會(huì)發(fā)生什么”之后,通過分析來幫助業(yè)務(wù)決定“需要做些什么”
分析過程(及微觀方法)
數(shù)據(jù)導(dǎo)入及整體信息查看:
首先,導(dǎo)入我們的“數(shù)分三劍客”,
import pandas as pdimport numpy as npimport matplotlib as plt
載入數(shù)據(jù),

我們看到,給出了數(shù)據(jù)類型警告,方便起見,將以上幾個(gè)字段全部定義為str,在處理過程中根據(jù)需要再進(jìn)行修改,
df?=?pd.read_csv('./test_data/beijing_houst_price.csv',dtype={'id':'str',?'tradeTime':'str','livingRoom':'str','drawingRoom':'str','bathRoom':'str'})查看一下數(shù)據(jù)的整體信息,
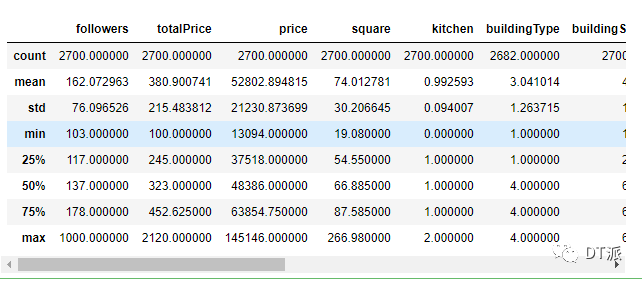
df.shapedf.head(10)df.describe()df.count()
大約32萬條數(shù)據(jù),19個(gè)字段

查看數(shù)據(jù)前10行,各字段信息如下
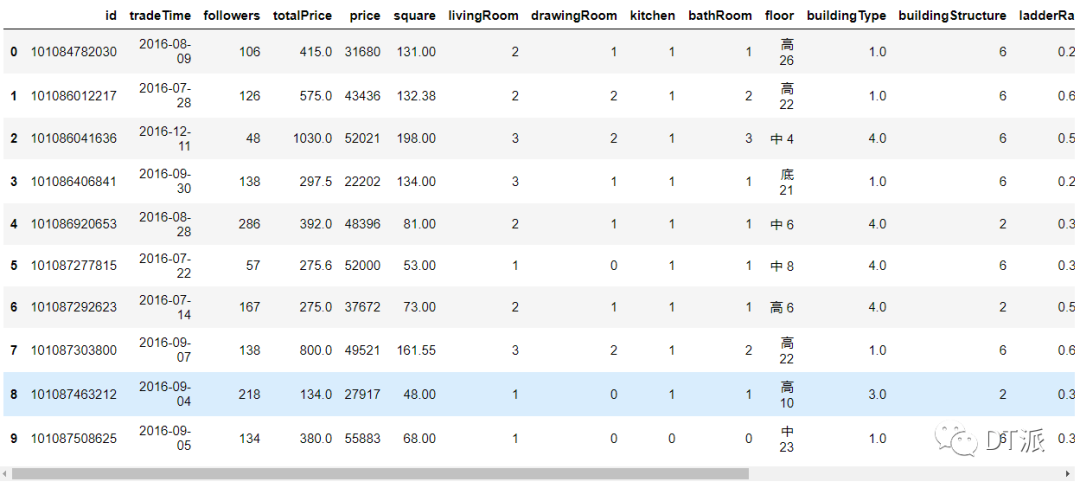
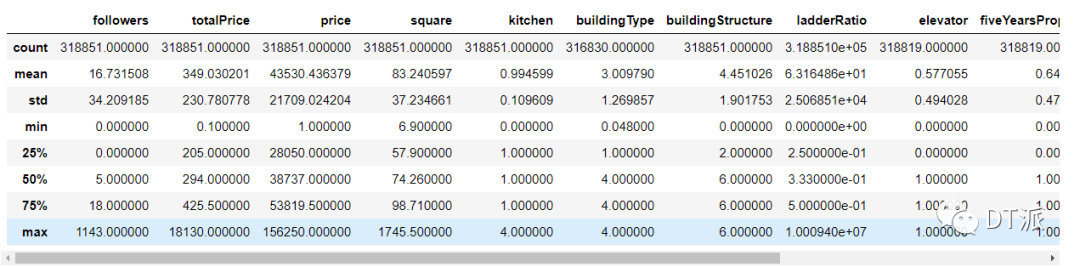
數(shù)值類列的常用統(tǒng)計(jì)值
查看各列非空值數(shù)量

常用統(tǒng)計(jì)值解析
count--計(jì)算每列中非空數(shù)值的數(shù)量
mean--返回每列的平均值
std--返回每列的標(biāo)準(zhǔn)差
min--返回每列的最小值
max--返回每列的最大值
(25%,50%,75%)--統(tǒng)計(jì)學(xué)四分位數(shù),其中50%對(duì)應(yīng)中位數(shù)
數(shù)據(jù)清洗及預(yù)處理:
每個(gè)編號(hào)對(duì)應(yīng)一筆交易,看下是否有重復(fù)數(shù)據(jù),
df[df['id'].duplicated()]
由于是橫跨好幾年的數(shù)據(jù),有些年份可能數(shù)據(jù)會(huì)比較少,先看看每年數(shù)據(jù)的總量,確定一下是否需要?jiǎng)h除數(shù)據(jù)少的年份,我們從時(shí)間維度對(duì)數(shù)據(jù)進(jìn)行一次清洗,使用tradeTime字段,
先將字符串轉(zhuǎn)為日期格式,方便提取
df['tradeTime'] = pd.to_datetime(df['tradeTime'])#?df.dtypes????#?可以查看當(dāng)前的數(shù)據(jù)類型
統(tǒng)計(jì)下每年的數(shù)據(jù)量
df['tradeTime'].dt.year.value_counts()
其中有幾個(gè)年份數(shù)據(jù)量太少,我們?cè)谶@里選擇2012-2017年的數(shù)據(jù)比較合適
df.drop(df[df['tradeTime'].dt.year < 2012].index, inplace=True)df.drop(df[df['tradeTime'].dt.year?>?2017].index,?inplace=True
接下來再看每年的數(shù)據(jù)量

好了,現(xiàn)在我們拿到了合適時(shí)間范圍的數(shù)據(jù)。剛才在查看常用統(tǒng)計(jì)值時(shí),我們看到在totalPrice和price兩個(gè)字段中存在像0.1或者1這樣不正常的值,接下來我們從價(jià)格維度再清洗一次數(shù)據(jù),分別使用totalPrice,price和communityAverage三個(gè)字段,
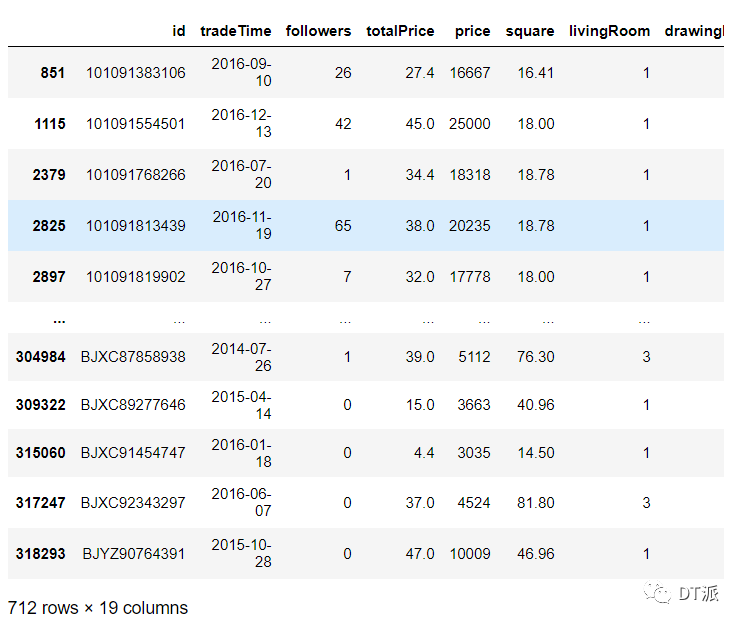
根據(jù)四分位數(shù)的分布范圍,在totalPrice字段中暫取小于50萬和小于100萬這兩個(gè)范圍先分別查看一下各自對(duì)應(yīng)多少條數(shù)據(jù),
df[df['totalPrice'] < 50]df[df['totalPrice'] < 100]
總價(jià)小于50萬
總價(jià)小于100萬
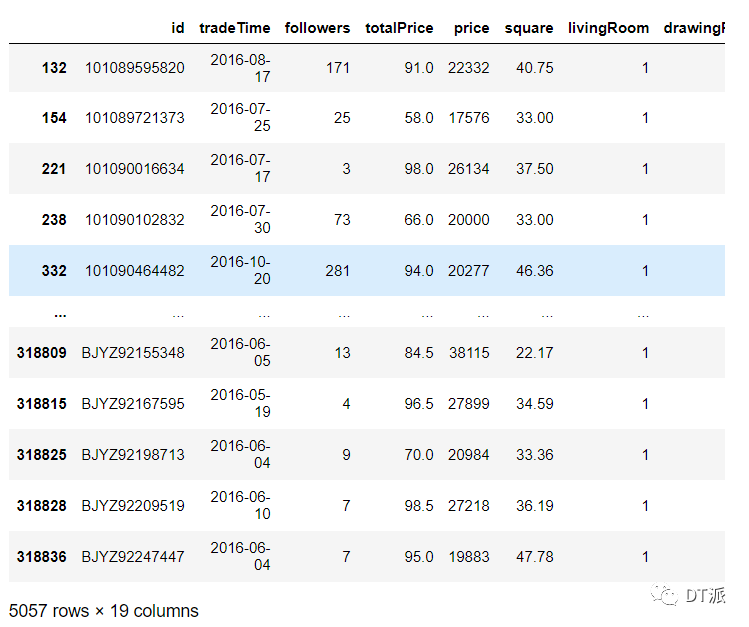
根據(jù)我們剛才清洗后的樣本數(shù)據(jù)量(約31萬),這里可以直接刪除總價(jià)在100萬以下的數(shù)據(jù)了,然后同樣的方法再用price字段進(jìn)行一次清洗,這里選擇刪除單價(jià)在10000以下的數(shù)據(jù),現(xiàn)在我們可以再看一下常用統(tǒng)計(jì)值,
df.drop(df[df['totalPrice'] < 100].index, inplace=True)df.drop(df[df['price'] < 10000].index, inplace=True)

df.drop(df[df['communityAverage'].isnull()].index, inplace=True)communityAverage最大值和最小值合理,不過有空值,大約只有400條數(shù)據(jù),這里我們直接刪掉(也可以選擇填充),最后再看一下square列,值都在合理的范圍內(nèi),并且也沒有空值,現(xiàn)在,數(shù)據(jù)清洗就已經(jīng)完成了,接下來可以開始分析。
數(shù)據(jù)分析(提取、篩選、匯總、統(tǒng)計(jì)):
我們回到最開始提出的幾個(gè)問題,現(xiàn)在從數(shù)據(jù)中找到它們的答案。
市場(chǎng)近幾年的整體價(jià)格趨勢(shì)是什么情況?
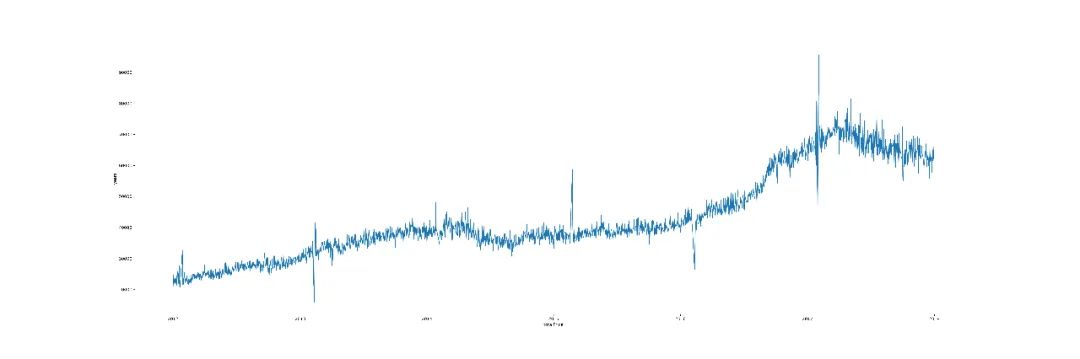
從均價(jià)一般可以看出市場(chǎng)的整體水平,這里我們統(tǒng)計(jì)一下每日所有房源的平均單價(jià),

數(shù)據(jù)可視化展示:

上圖可以看出近幾年北京房?jī)r(jià)的一個(gè)整體上漲趨勢(shì),其中有個(gè)別偏離度較大的極值,可能是房?jī)r(jià)受一些短期因素的影響或者當(dāng)日成交房源的價(jià)格中有偏離度極大的值造成的,這里不用過多考慮。
常用統(tǒng)計(jì)圖說明
線圖:能夠顯示數(shù)據(jù)的趨勢(shì),反映事物的變化情況
散點(diǎn)圖:判斷變量之間是否存在數(shù)量關(guān)聯(lián)趨勢(shì),展示分布規(guī)律
柱狀圖:繪制離散數(shù)據(jù),能夠一眼看出各個(gè)數(shù)據(jù)的大小,比較數(shù)據(jù)之間的差別
直方圖:繪制連續(xù)性的數(shù)據(jù),展示一組或者多組數(shù)據(jù)的分布狀況
餅圖:展示分類數(shù)據(jù)的占比情況
房源在不同價(jià)格區(qū)間的大致分布狀態(tài)是什么樣子?
通過之前對(duì)整體價(jià)格趨勢(shì)的分析,可以看到在有些年份房?jī)r(jià)的漲幅非常明顯,考慮到這一點(diǎn),我們?nèi)绻捶吭磧r(jià)格區(qū)間的分布,最好設(shè)定一個(gè)時(shí)間范圍,這里我們選擇以年為單位分別進(jìn)行統(tǒng)計(jì),下面以成交量最大的2016年為例,其他年份可以按照同樣的方法進(jìn)行類比,取出2016年的所有數(shù)據(jù),我們以總價(jià)的最大值和最小值為整體范圍,按50萬的區(qū)間距離,先畫一個(gè)粗略的直方圖,
可以看到,總價(jià)在2000萬以上的房子幾乎都沒有了,為了更好地表示區(qū)間分布情況,調(diào)整一下取值范圍,在最小值到2000萬的范圍內(nèi)重新統(tǒng)計(jì),

好了,現(xiàn)在可以明顯地看出來,在2016一整年里,250萬到300萬之間成交的房源數(shù)量是最多的。當(dāng)然,這里價(jià)位區(qū)間的間距可以根據(jù)需要再放大或縮小,其他年份的統(tǒng)計(jì)方法以此類推,就不再贅述了。
判斷一下有沒有明顯的交易淡旺季?
可以通過每個(gè)月的交易數(shù)量來判斷一下交易淡旺季,然后我們把這幾個(gè)年份放在一起進(jìn)行下對(duì)比,看看有沒有比較明顯的規(guī)律。
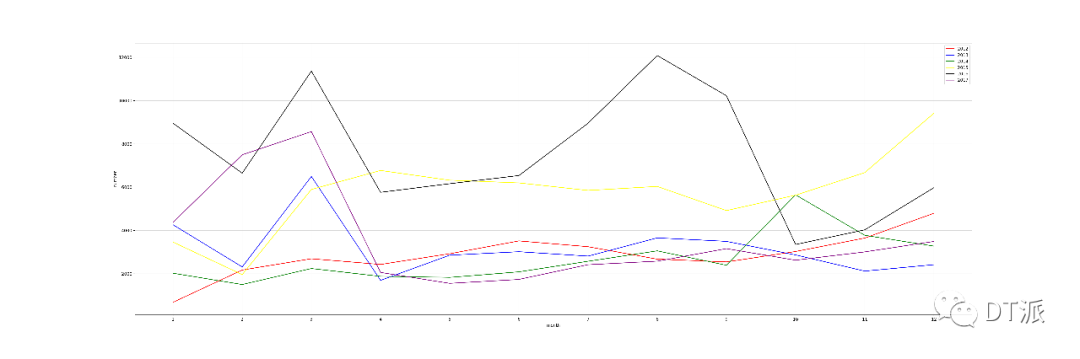
上圖反映了交易量隨月份變化的情況,通過連續(xù)六年的對(duì)比,我們可以看出在大多數(shù)年份,3月左右房子交易會(huì)有一個(gè)小高峰,12月左右,交易量也有明顯上升趨勢(shì)。
哪些房源比較受歡迎,它們有什么特點(diǎn)?
考慮到時(shí)間因素的影響,房子價(jià)格等信息或許有較大變化,為了分析結(jié)果更加精細(xì),我們還是取單一年份分別統(tǒng)計(jì),這里以交易量最大的2016年為例。共有約9萬條數(shù)據(jù),因?yàn)檫€有很多關(guān)注人數(shù)為0的數(shù)據(jù),預(yù)先查看后,這里取關(guān)注人數(shù)最多的前3%的數(shù)據(jù),做一個(gè)樣本集,我們看下這個(gè)樣本集的房源價(jià)格、房子面積等屬性呈現(xiàn)怎樣的特征。
以上房源的關(guān)注人數(shù)都在百人以上,最高達(dá)1000人,我們看下這些房子都有什么特點(diǎn)?

上面兩張圖分別是這些房源的總價(jià)及單價(jià)分布情況,下面兩張圖分別是房源是否滿5年和房源面積的占比情況。可以看出,這些最受歡迎的房源總價(jià)大多在200到300萬之間,有7成左右都是滿5年的,并且面積在30到90平米之間的居多。如果你打算在北京買房,這些房源可以考慮考慮哦。
分析結(jié)論及建議
最后我們來總結(jié)一下,看看數(shù)據(jù)說了些什么。市場(chǎng)的總體價(jià)格趨勢(shì)是持續(xù)上漲,在16年有一個(gè)較大的增幅,17年略有回落;以16年為例,我們看到圍繞200到300萬這個(gè)范圍房源是最多的;通過連續(xù)6年的對(duì)比,在3月和12月附近有較為明顯的交易小高峰;最受歡迎的房源都在200-300萬之間,和全部房源的數(shù)量分布情況十分吻合,并且這些受歡迎的房子多在30到90平米,大多數(shù)都是5年以上的房子。這個(gè)案例就不給大家分析意見了,如果一定說一條,那就是:好好掙錢!!!畢竟這些價(jià)格都已經(jīng)是幾年前的咯。
如果你已經(jīng)看到了這里,非常感謝閱讀,順便收下我的膜拜,哈哈哈!

如果有機(jī)會(huì)在北京買了房,勿相忘哦!
記得點(diǎn)在看,么么噠~