
用Python對某婭偷逃稅進行微博輿情分析~
↑?關(guān)注 + 星標(biāo)?,每天學(xué)Python新技能
后臺回復(fù)【大禮包】送你Python自學(xué)大禮包
前天某婭因偷逃稅被罰了13.41億元,此消息一出,可是在網(wǎng)上激起了千層浪,網(wǎng)友們直接炸鍋了。志斌也很感慨,這輩子掙的錢不知道有沒有人家交的罰款的零頭多。
所以志斌爬取了這條微博下的數(shù)據(jù),進行了一個簡單的輿情分析!
01
分析頁面
因為從移動端來對微博進行爬取較為方便,所以我們此次選擇從移動端來對微博進行爬取。
平時我們都是在這個地方輸入關(guān)鍵字,來對微博內(nèi)容進行搜索。

我通過在開發(fā)者模式下對這個頁面觀察發(fā)現(xiàn),它每次對關(guān)鍵字發(fā)起請求后,就會返回一個XHR響應(yīng)。
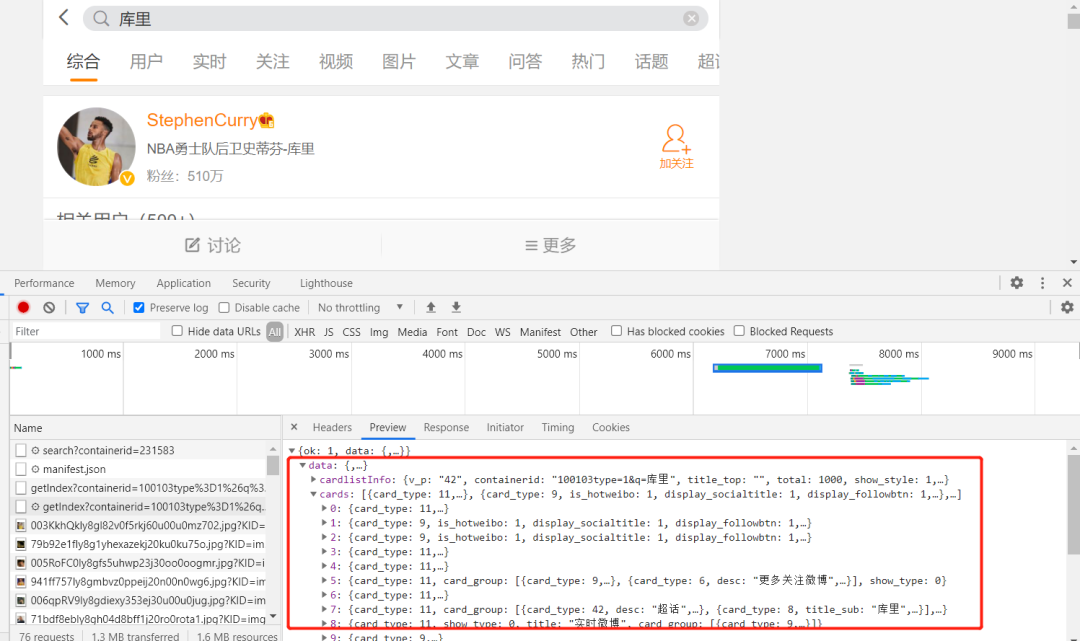
我們現(xiàn)在已經(jīng)找到數(shù)據(jù)真實存在的頁面了,那就可以進行爬蟲的常規(guī)操作了。
02
數(shù)據(jù)采集
在上面我們已經(jīng)找到了數(shù)據(jù)存儲的真實網(wǎng)頁,現(xiàn)在我們只需對該網(wǎng)頁發(fā)起請求,然后提取數(shù)據(jù)即可。
01
?發(fā)送請求
通過對請求頭進行觀察,我們不難構(gòu)造出請求代碼。
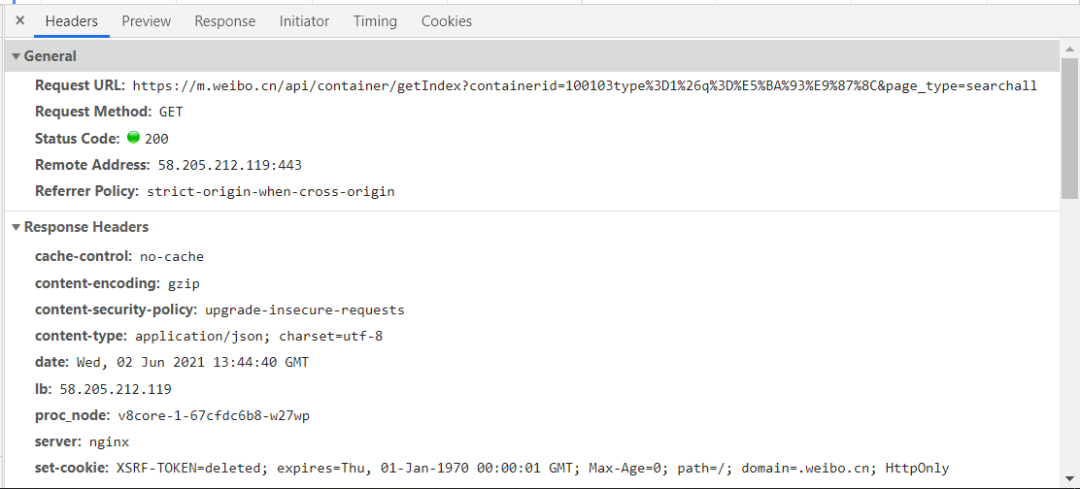
構(gòu)造代碼如下:
key = input("請輸入爬取關(guān)鍵字:")
for page in range(1,10):
params = (
('containerid', f'100103type=1&q={key}'),
('page_type', 'searchall'),
('page', str(page)),
)
response = requests.get('https://m.weibo.cn/api/container/getIndex', headers=headers, params=params)
02
?解析響應(yīng)
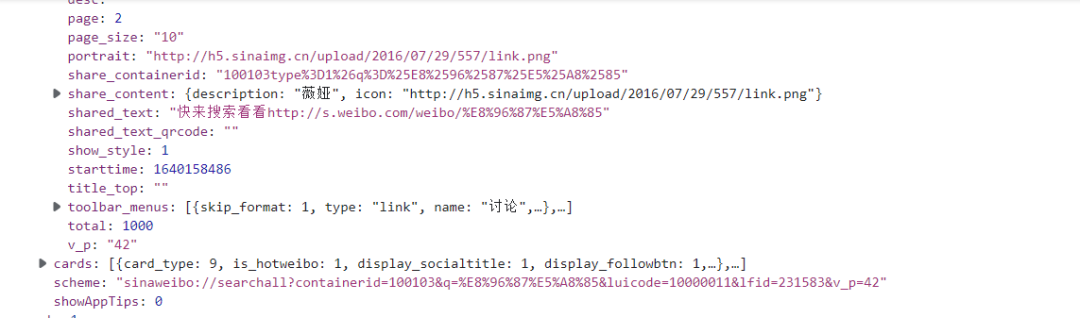
從上面我們觀察發(fā)現(xiàn)這個數(shù)據(jù)可以轉(zhuǎn)化成字典來進行爬取,但是經(jīng)過我實際測試發(fā)現(xiàn),用正則來提取是最為簡單方便的,所以這里展示的是正則提取的方式,有興趣的讀者可以嘗試用字典方式來提取數(shù)據(jù)。代碼如下:
r = response.text
title = re.findall('"page_title":"(.*?)"',r)
comments_count = re.findall('"comments_count":(.*?),',r)
attitudes_count = re.findall('"attitudes_count":(.*?),',r)
for i in range(len(title)):
print(eval(f"'{title[i]}'"),comments_count[i],attitudes_count[i])
03
?存儲數(shù)據(jù)
數(shù)據(jù)已經(jīng)解析好了,我們直接存儲就可以了,這里我是將數(shù)據(jù)存儲到csv文件中,代碼如下:
for i in range(len(title)):
try:
with open(f'{key}.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow([eval(f"'{title[i]}'"),comments_count[i],attitudes_count[i],reposts_count[i],created_at[i].split()[-1],created_at[i].split()[1],created_at[i].split()[2],created_at[i].split()[0],created_at[i].split()[3]])
except:
pass
03
數(shù)據(jù)清洗
數(shù)據(jù)采集完后,需要對其進行清洗,使其達到分析要求才可以進行可視化分析。
01
?導(dǎo)入數(shù)據(jù)
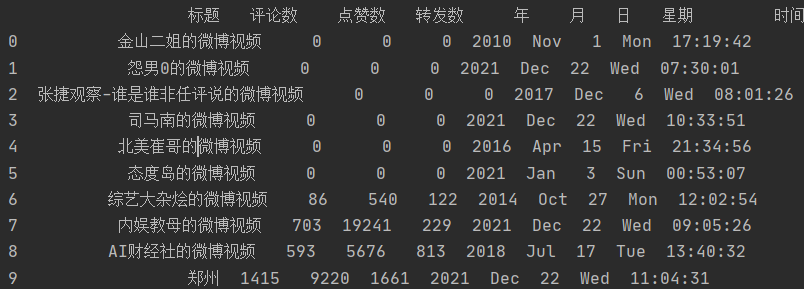
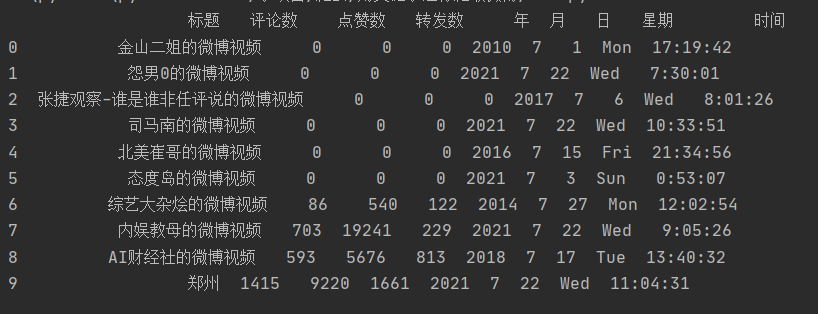
用pandas讀取爬取后的數(shù)據(jù)并預(yù)覽。
import pandas as pd
df = pd.read_csv('薇婭.csv',encoding='gbk')
print(df.head(10))
02
?日期轉(zhuǎn)換
我們發(fā)現(xiàn),月份中的數(shù)據(jù)是英文縮寫,我們需要將其轉(zhuǎn)化成數(shù)字,代碼如下:
c = []
for i in list(df['月']):
if i == 'Nov':
c.append(11)
elif i == 'Dec':
c.append(12)
elif i == 'Apr':
c.append(4)
elif i == 'Jan':
c.append(1)
elif i == 'Oct':
c.append(10)
else:
c.append(7)
df['月'] = c
df.to_csv('薇婭.csv',encoding='gbk',index=False)
03
?查看數(shù)據(jù)類型
查看字段類型和缺失值情況,符合分析需要,無需另做處理。
df.info()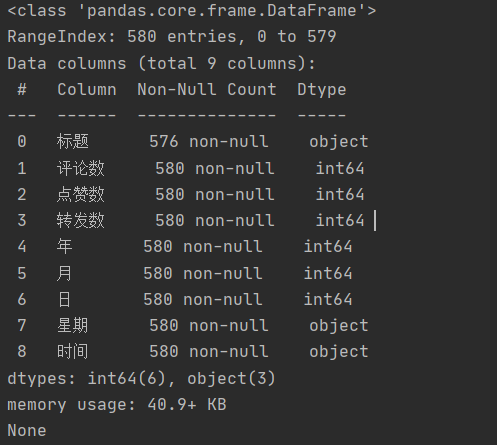
04
可視化分析
我們來對這些數(shù)據(jù)進行可視化分析。
01
?每日微博數(shù)量
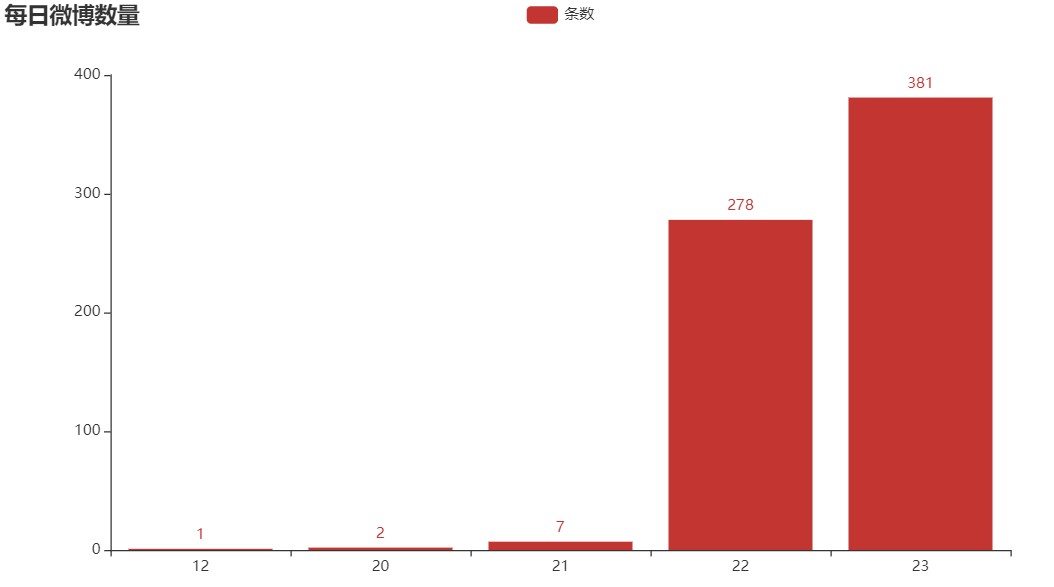
志斌這里只爬取了近100頁的數(shù)據(jù),可能是導(dǎo)致20和21號的微博數(shù)據(jù)較少的原因。
代碼如下:
from pyecharts.charts import Bar
from pyecharts import options as opts
from collections import Counter # 統(tǒng)計詞頻
c=[]
d={}
a = 0
for i in list(df['月']):
if i == 12:
if list(df['日'])[a] not in c:
c.append(list(df['日'])[a])
a+=1
a = 0
for i in c:
d[i]=0
for i in list(df['月']):
if i == 12:
d[list(df['日'])[a]]+=1
a += 1
columns = []
data = []
for k,v in d.items():
columns.append(k)
data.append(v)
bar = (
Bar()
.add_xaxis(columns)
.add_yaxis("條數(shù)", data)
.set_global_opts(title_opts=opts.TitleOpts(title="每日微博數(shù)量"))
)
bar.render("詞頻.html")
02
?評論點贊top10
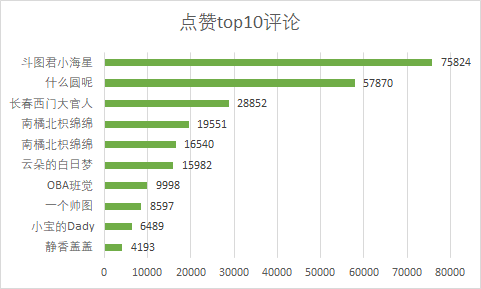
我們發(fā)現(xiàn)斗圖君小海星這個用戶所發(fā)表的評論點贊數(shù)最多,有7.5w+,下面讓我們看看它的評論是什么,竟然讓用戶這么喜歡。
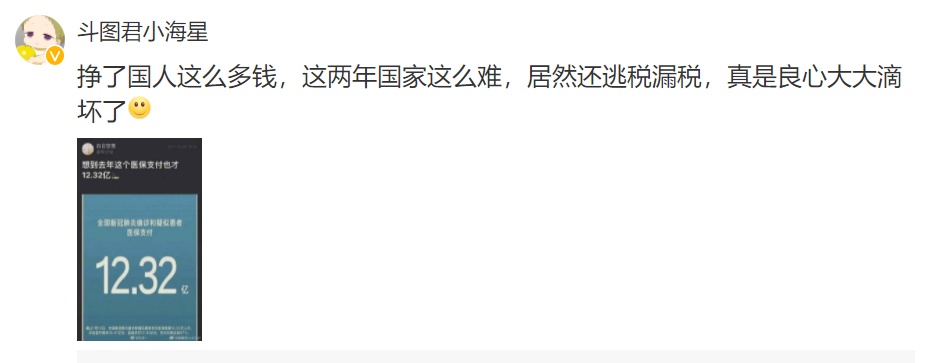
點贊這么多可能是發(fā)的時間早,位置比較靠前,另一個原因可能是內(nèi)容符合大家的心聲。
03
?評論時間分布
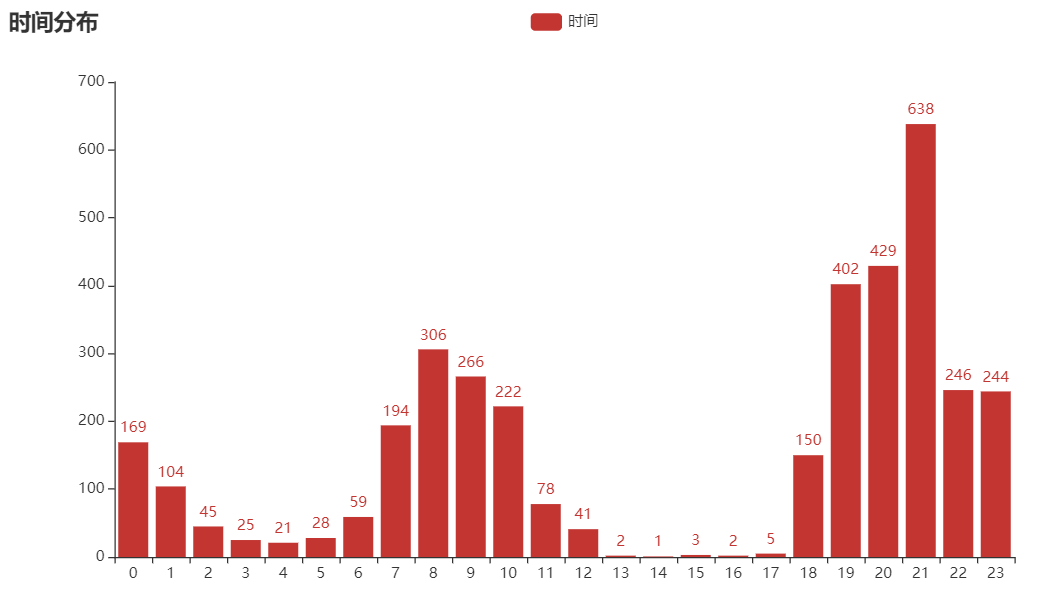
對所有評論發(fā)布時間進行分析,我們發(fā)現(xiàn)21點發(fā)表的評論數(shù)量最多,當(dāng)時上到熱搜榜的時候差不多也是這個時間,看來上不上熱搜榜對微博的影響還是很大的。
代碼如下:
import pandas as pd
df = pd.read_csv('weiya.csv',encoding='gbk')
c=[]
d={}
a = 0
for i in list(df['時']):
if i not in c:
c.append(i)
a = 0
for i in c:
d[i]=0
for i in list(df['時']):
d[i]+=1
print(d)
from collections import Counter # 統(tǒng)計詞頻
from pyecharts.charts import Bar
from pyecharts import options as opts
columns = []
data = []
for k,v in d.items():
columns.append(k)
data.append(v)
bar = (
Bar()
.add_xaxis(columns)
.add_yaxis("時間", data)
.set_global_opts(title_opts=opts.TitleOpts(title="時間分布"))
)
bar.render("詞頻.html")
04
?詞云圖

通過詞云圖我們可以看出,關(guān)鍵詞偷逃漏稅非常多,符合主題,其次是注銷、封殺和坐牢,看來大家對于違法的行為還是很仇恨的。
代碼如下:
from imageio import imread
import jieba
from wordcloud import WordCloud, STOPWORDS
with open("weiya.txt",encoding='utf-8') as f:
job_title_1 = f.read()
with open('停用詞表.txt','r',encoding='utf-8') as f:
stop_word = f.read()
word = jieba.cut(job_title_1)
words = []
for i in list(word):
if i not in stop_word:
words.append(i)
contents_list_job_title = " ".join(words)
wc = WordCloud(stopwords=STOPWORDS.add("一個"), collocations=False,
background_color="white",
font_path=r"K:\蘇新詩柳楷簡.ttf",
width=400, height=300, random_state=42,
mask=imread('xin.jpg', pilmode="RGB")
)
wc.generate(contents_list_job_title)
wc.to_file("推薦語.png")
05
小結(jié)
1. 網(wǎng)紅和明星作為公眾人物更要做好表率,不能享受名利的同時還干著違法的行為。
2. 本文僅供學(xué)習(xí)參考,不做它用。
推薦閱讀