
阿里數(shù)據(jù)專家:如何有規(guī)范+規(guī)劃的進行數(shù)據(jù)埋點?
本文是前阿里巴巴數(shù)據(jù)分析專家-張騰在infoQ 賬號?analysis-lion
?發(fā)布的一篇原創(chuàng)文章
https://xie.infoq.cn/article/661e01f560c13b028b3e1567a
序
說起數(shù)據(jù)埋點,對于大多數(shù)的數(shù)據(jù)分析師來說并不陌生,并且可能在很多人的認知中,埋點的工作是由產(chǎn)品經(jīng)理來完成的。那么為什么筆者認為數(shù)據(jù)埋點是分析師成長體系中的一環(huán)呢?其核心在于埋點的規(guī)范與規(guī)劃。在筆者任職的多家企業(yè)中,通常產(chǎn)品經(jīng)理設(shè)計埋點是僅考慮自己所負責(zé)的模塊,那么會出現(xiàn)一個常見的問題--數(shù)據(jù)鏈路斷裂,在一些前后端跨模塊統(tǒng)計時數(shù)據(jù)無法有效追蹤或者關(guān)聯(lián)。那么作為分析師,尤其是中臺的分析師,自身存在一定的優(yōu)勢,承接業(yè)務(wù)、產(chǎn)品的需求,對接前后端數(shù)據(jù),可以從總體去規(guī)劃和規(guī)范埋點方案,從而降低埋點成本,減少數(shù)據(jù)鏈路斷裂等問題。
Starting~
什么是埋點?
埋點是數(shù)據(jù)采集的重要方式之一,通過在 app/H5/pc 等終端部署采集 SDK 代碼,來記錄和收集用戶的行為數(shù)據(jù),比如進入頁面、點擊按鈕等,之后數(shù)據(jù)會被收集并傳輸?shù)椒?wù)器存儲。下圖為一個較常見的數(shù)據(jù)流處理流程。

埋點的分類
筆者的經(jīng)驗,埋點其實可以分為客戶端(前端)埋點和服務(wù)端(后端)埋點,可能一些小伙伴對前后概念不是很清楚,這里簡單概括一下,客戶端就是用戶端,就是使用服務(wù),而服務(wù)端則是為用戶端提供服務(wù)。客戶端埋點和服務(wù)端埋點核心都是為了采集數(shù)據(jù),但是相較于客戶端埋點,服務(wù)端的本質(zhì)決定了其能夠?qū)崟r采集數(shù)據(jù),不存在延遲上報,數(shù)據(jù)更準(zhǔn)確;同時服務(wù)端埋點支持與用戶身份信息和行為附帶屬性信息整合;并且服務(wù)端埋點更新時不需要隨發(fā)版才生效。
不過需要注意的是,大多情況埋點時不會將服務(wù)端埋點獨立出來,而是混合在客戶端中,等用戶端和服務(wù)器的交互返回結(jié)果之后,將結(jié)果進行上報。

埋點的技術(shù)方案
埋點的技術(shù)方案目前來看基本可以分為三大類:代碼埋點、可視化埋點、無埋點(也成為全埋點),其中代碼埋點是目前的主流埋點技術(shù)方案。
代碼埋點
代碼埋點實際上就是將采集的 SDK 集成在終端,用戶在使用客戶端時,只要觸發(fā)了需要統(tǒng)計的事件,SDK 就會將數(shù)據(jù)傳到后端服務(wù)器上。
優(yōu)勢:自定義屬性、行為,控制精準(zhǔn),想要統(tǒng)計什么用戶行為數(shù)據(jù)都可以獲取到
劣勢:埋點成本較大,需要 RD 才能完成;更新成本較高,需要隨客戶端發(fā)版才能生效;
可視化埋點
除了 RD 開發(fā)集成采集的 SDK 外,不需要額外的開發(fā)量,業(yè)務(wù)人員直接在可視化分析平臺上,直接設(shè)置需要采集的行為,配置后自動采集用戶行為數(shù)據(jù);流程上是把核心代碼、配置和資源做拆分,用過網(wǎng)絡(luò)更新配置和資源從而實現(xiàn)采集代碼下發(fā);其原理參考了 VS 等一系列 IDE 的做法,用交互的手段代替代碼編寫,從而大幅縮減工作量和溝通成本,同時降低出錯幾率。
優(yōu)勢:很好的解決了代碼埋點的人工成本和發(fā)版更新的代駕;有業(yè)務(wù)人員直接操作、無需開發(fā)支持
劣勢:覆蓋的功能有限,企業(yè)個性化 SDK 開發(fā)難度較高;
無埋點
無埋點也成為全埋點,就是 SDK 采集用戶所有的行為數(shù)據(jù),并全部上報,不要 RD 添加額外的代碼;業(yè)務(wù)方通過后臺管理對關(guān)注的行為數(shù)據(jù)進行圈選。
優(yōu)勢:全量采集數(shù)據(jù),無需 RD 開發(fā),減少溝通成本,支持先上報數(shù)據(jù)后埋點
劣勢:全量采集數(shù)據(jù),數(shù)據(jù)傳輸和服務(wù)器壓力較大;企業(yè)個性化 SDK 開發(fā)難度大;
埋點框架
筆者認為埋點也是一門藝術(shù),埋點的框架就是從大量埋點方案中抽象出來的規(guī)則或方法。本文以阿里的埋點框架 SPM 為例,定義 A,B,C,D,E 分別代表站點、頁面、區(qū)塊、具體位置、隨機生成的字符串,通過組合的形式來確定唯一的用戶行為。優(yōu)勢就是將埋點結(jié)構(gòu)化,并且每個元素都可以獨立管理及復(fù)用。以天貓首頁部分頁面為例,通過點擊跳轉(zhuǎn)可以區(qū)分此圖內(nèi)有 3 個模塊。
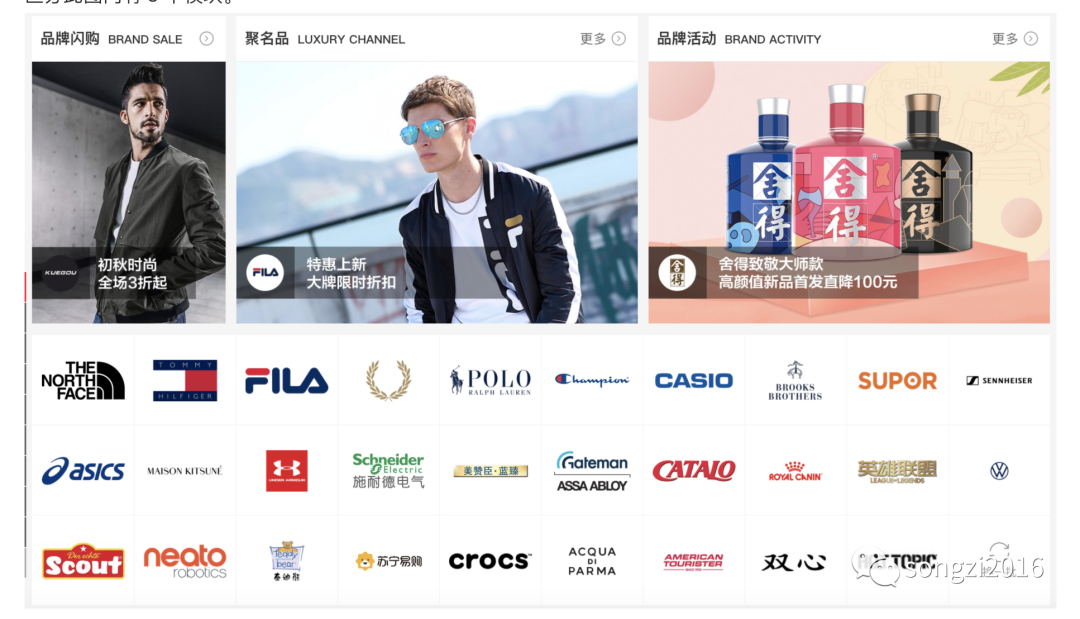
點擊 fila 圖標(biāo),可以看到鏈接中 spm 部分為 875.7931836/B.2016073.3.1c9c4265IitEmy,根據(jù)框架結(jié)構(gòu)帶入可以了結(jié)其信息和對應(yīng)關(guān)系
https://fila.tmall.com/shop/view_shop.htm?spm=875.7931836/B.2016073.3.1c9c4265IitEmy&user_number_id=676606897&pvid=38336a1a-9b06-4951-a7d8-410faf8fe4dc&pos=3&brandId=3224828&acm=09042.1003.1.1200415&scm=1007.13029.131809.100200300000000復(fù)制代碼
埋點規(guī)范
正所謂無規(guī)矩不成方圓,哪怕你有了一個合理的埋點框架,但是沒有制定和遵守規(guī)范,隨著埋點的不斷迭代,數(shù)據(jù)處理的復(fù)雜度會隨時間推移不斷的增加。
在介紹規(guī)范之前,我們先了解一下埋點采集的日志數(shù)據(jù)類型和結(jié)構(gòu)。
日志數(shù)據(jù)
通常對于埋點采集的數(shù)據(jù)我們成為日志數(shù)據(jù),此部分主要介紹日志數(shù)據(jù)的事件和日志數(shù)據(jù)的結(jié)構(gòu)。
以客戶端采集的數(shù)據(jù)為例,按照用戶行為的不同,我們定義為不同的事件(event),其中常見的基礎(chǔ)事件包括不限于啟動、頁面訪問、曝光、點擊、性能,針對于不同產(chǎn)品會有一些特定的事件比如播放類產(chǎn)品需要定一個播放事件等。
日志的數(shù)據(jù)結(jié)構(gòu)主要由公共參數(shù)和拓展參數(shù)構(gòu)成。公共參數(shù)表示不同事件都可以具備和擁有的信息,例如用戶 id 類(guid,user_id 等)、地域信息、設(shè)備、事件基礎(chǔ)信息(事件類型、會話 id 等);拓展參數(shù)是不同事件特有的信息,比如頁面訪問時間的訪問時長、播放事件的播放次數(shù)、用戶啟動事件的登錄狀態(tài)等,拓展參數(shù)大多以 json 形式存在,好處是數(shù)據(jù)倉的日志層可以減少字段拓展造成的改動,缺點是可能存在數(shù)據(jù)整理成本較高,尤其是 json 嵌套下。
下圖為筆者參與的埋點方案設(shè)計。
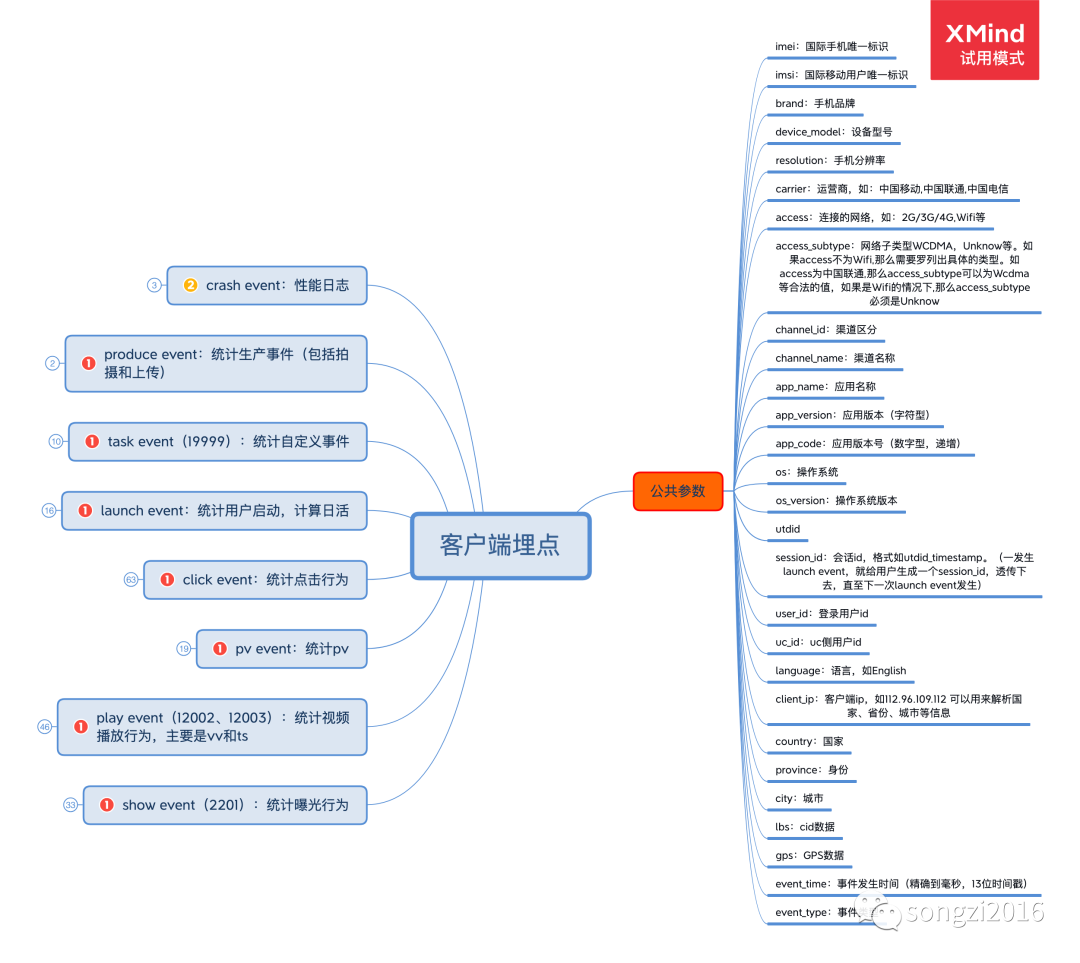
敲黑板,要注意客戶端埋點和服務(wù)端埋點的區(qū)別,以及數(shù)據(jù)透傳與記錄。例如紅包、折扣券、推薦內(nèi)容由服務(wù)端記錄及提供,客戶端可以選擇性記錄用來分析及關(guān)聯(lián)相應(yīng)的明細信息。
規(guī)范
了解日志數(shù)據(jù)基礎(chǔ)信息后,我們就要制定的相應(yīng)的規(guī)范來確保埋點的準(zhǔn)確和穩(wěn)定性。
首先,如果采用的是結(jié)構(gòu)化的埋點框架,對于站點、頁面、區(qū)塊的管理都是獨立,統(tǒng)一管理減少唯一 id 代表的信息冗余;
其次,劃分事件類型,對事件類型的定義進行統(tǒng)一,如:頁面訪問事件為 pv 或者 pageload;制定參數(shù)命名的規(guī)范,如點擊 click,提交 submit;
再次,對于不同事件觸發(fā)和上報的邏輯的規(guī)范,什么事件需要實時上報,什么事件可以延遲上報,特定行為的上報邏輯應(yīng)該如何設(shè)計,比如:卡片的曝光,可以設(shè)計成卡片面積超過 60%,曝光時長超過 1 秒,這 樣既可以保證用戶看到大部分的內(nèi)容,同時避免快速切換或者滑動頁面造成的虛假曝光統(tǒng)計;
最后,我們需要制定統(tǒng)一標(biāo)準(zhǔn)的埋點文檔。

如何做埋點?
上文介紹為了什么是埋點,埋點的分類、技術(shù)方案、框架和規(guī)范,那么從數(shù)據(jù)分析師的角色出發(fā),如何去做埋點呢?官方話術(shù):了解業(yè)務(wù)、產(chǎn)品設(shè)計方案及交互、明確分析的目標(biāo)。
思路
做埋點的前提是遵循 4W1H 的思路:
WHO:誰?表征用來描述用戶的 id 類信息;
WHEN:時間,會話創(chuàng)建的時間、事件發(fā)生時間、事件上報時間、視頻播放時間、推薦資源請求時間等;
WHAT:描述事件內(nèi)容,比如:播放事件,從什么入口進來,播放了什么內(nèi)容,播放的時長是多久等;
WHERE:表示位置類信息,如城市、區(qū)域、GPS、IP 信息等;
HOW:路徑及方式,從那個頁面,那個模塊跳轉(zhuǎn)而來,在什么網(wǎng)絡(luò)環(huán)境下;
流程
以分析師作為第一視角的埋點流程大致如下:
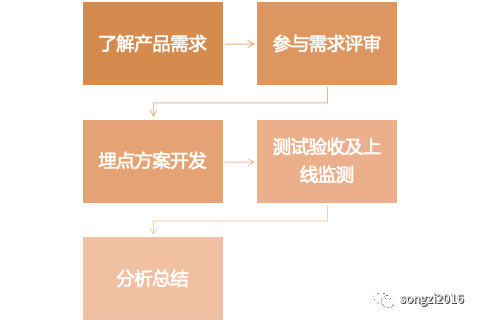
了解產(chǎn)品需求
對于每次產(chǎn)品迭代,作為分析師應(yīng)該深入的去了解產(chǎn)品迭代的背景、面向的用戶和業(yè)務(wù)邏輯, 數(shù)據(jù)的角度去思考如何通過數(shù)據(jù)證明,從而思考埋點如何設(shè)計。
此過程包含最初的產(chǎn)品需求對接,以及產(chǎn)品內(nèi)部的需求評審,作為分析師應(yīng)該參與其中了解更多的細節(jié)內(nèi)容。對于過審的產(chǎn)品需求,產(chǎn)品應(yīng)提供一下內(nèi)容:產(chǎn)品文檔、交互原型、數(shù)據(jù)指標(biāo)需求,分析師設(shè)計具體的埋點方案及數(shù)據(jù)統(tǒng)計邏輯。
參與需求評審
產(chǎn)品埋點方案設(shè)計完整之后需要和開發(fā)進行評審,主要討論功能或者埋點可實現(xiàn)性及開發(fā)周期相關(guān)工作。
埋點方案開發(fā)
過審后,分析師及產(chǎn)品會頻繁的與開發(fā)進行溝通,跟蹤埋點整體的進度以及解決開發(fā)過程中的問題。分析師可以在此過程中,優(yōu)先構(gòu)建指標(biāo)數(shù)據(jù)統(tǒng)計看板,待測試或者正式上線后,可以同步看到數(shù)據(jù),提升整體產(chǎn)出效率。
測試驗收及上線監(jiān)測
功能開發(fā)后,分析師主要檢查埋點上傳的日志數(shù)據(jù)的準(zhǔn)確性(是否異常值、值錯誤、數(shù)據(jù)重復(fù))、完整性(公共參數(shù)、自定義參數(shù)是否缺失,日志漏傳等)。
埋點測試通過后,需要緊密監(jiān)控發(fā)版后的數(shù)據(jù),通常在此過程中會有一段時間的 AB-test,主要是監(jiān)控埋點數(shù)據(jù)、統(tǒng)計指標(biāo)是否異常,用戶行為數(shù)據(jù)是否出現(xiàn)較大波動。
分析總結(jié)
測試和發(fā)版后數(shù)據(jù)沒有明顯異常的情況下,通常在之后的 1-2 周可以輸出相關(guān)的產(chǎn)品功能迭代的分析報告,主要是同步覆蓋率、使用率、留存活躍及迭代功能使用的相關(guān)數(shù)據(jù)。
寫在最后
埋點是一項相對精細的工作,不僅僅是為了上報數(shù)據(jù),其中事件的定義、行為的已定、日志結(jié)構(gòu)、存儲方式、前后端數(shù)據(jù)交互邏輯、數(shù)據(jù)提取的邏輯都需要考慮其中,需要從更高的全局角度去看待埋點。以免變成埋個點挖個坑,最后坑套坑,無窮盡。
本文闡述的內(nèi)容僅作為個人工作的總結(jié),如有疑問,歡迎與我討論交流。感謝閱讀~
