
某銀行應用接地氣的容器云平臺是什么樣子?

【作者】
彭尚峰,目前就職銀行企業(yè),深耕云計算領域多年,深度參與銀行PaaS私有云建設與推廣,擁有豐富的容器云平臺設計和落地經(jīng)驗。
張少博,目前就職銀行企業(yè),從事云計算領域技術研究和技術支持工作。對Kubernetes高可用架構、Windows容器、云原生安全等有較深的理解,現(xiàn)致力于Operator的定制化開發(fā)工作。
鄭宇光,目前就職銀行企業(yè),從事云計算領域相關技術研究、工程實施運維與技術支撐工作。任職期間主導完成云計算架構設計,制定容器云安全基線等指導性規(guī)范。

一、銀行容器云平臺建設的需求分析
伴隨著 Docker 容器、Kubernetes、微服務、DevOps 等熱門技術的興起和逐漸成熟,利用云原生(Cloud Native)解決方案為企業(yè)數(shù)字化轉(zhuǎn)型,已成為主流趨勢。云原生解決方案通過使用容器、Kubernetes、微服務等這些新潮且先進的技術,能夠大幅加快軟件的開發(fā)迭代速度,提升應用架構敏捷度,提高 IT 資源的彈性和可用性,幫助企業(yè)客戶加速實現(xiàn)數(shù)字化轉(zhuǎn)型。通過容器技術搭建的云原生 PaaS(Platform-as-a-Service)平臺,可以為企業(yè)提供業(yè)務的核心底層支撐,同時能夠建設、運行、管理業(yè)務應用或系統(tǒng),使企業(yè)能夠節(jié)省底層基礎設施和業(yè)務運行系統(tǒng)搭建、運維的成本,將更多的人員和成本投入到業(yè)務相關的研發(fā)上。
銀行數(shù)字化轉(zhuǎn)型的一大關鍵內(nèi)容就是如何通過利用容器云平臺為應用開發(fā)人員和基礎設施建設運維人員賦能。除了利用容器云平臺帶來容器編排調(diào)度、故障自檢自愈、資源彈性供給等基本能力外,還需要更加關注容器云平臺的穩(wěn)定性、安全性、以及如何融入已有開發(fā)運維體系。
二、銀行容器云平臺的總體架構設計
某銀行容器云平臺定位為以應用為中心的平臺,總體上分為容器云平臺和云管理平臺兩大部分,為跨服務器運行的容器化應用提供一站式完備的分布式應用系統(tǒng)開發(fā)、運行和支撐平臺。平臺內(nèi)提供內(nèi)建負載均衡、強大的故障發(fā)現(xiàn)和自我修復機制、服務滾動升級和在線擴容、可擴展的資源自動調(diào)度機制、多租戶應用支撐、透明的服務注冊、服務發(fā)現(xiàn)、多層安全防護準入機制、多粒度的資源配額管理能力,此外提供完善的管理工具,包括開發(fā)、測試、發(fā)布、運維監(jiān)控。
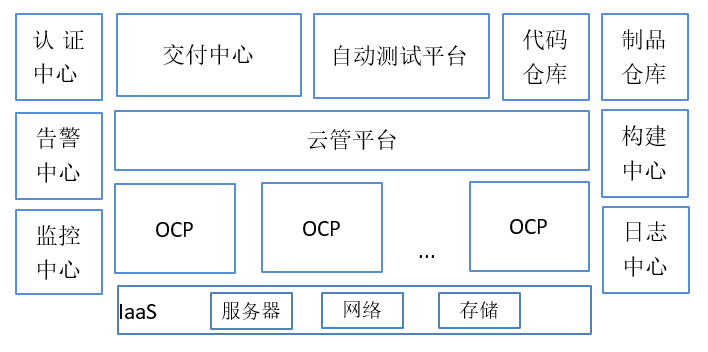
某銀行容器云平臺包含多個 Redhat Openshift Container Platform 集群,并通過云管理平臺統(tǒng)一管理。使用行內(nèi)IaaS提供的基礎資源,通過對接項目管理系統(tǒng)實現(xiàn)自動化的資源分配,通過對接變更管理系統(tǒng)實現(xiàn)變更信息獲取,通過對接行內(nèi)代碼庫和依賴包倉庫來實現(xiàn)代碼的持續(xù)集成和鏡像構建,同時對接行內(nèi)的統(tǒng)一認證、統(tǒng)一日志、監(jiān)控告警和應用管理平臺來實現(xiàn)相應的認證、日志、監(jiān)控和應用變更功能。
Openshift基于英特爾?至強?可擴展處理器、英特爾?傲騰?固態(tài)盤等硬件產(chǎn)品,針對虛擬化、大數(shù)據(jù)和人工智能工作負載進行性能驗證和優(yōu)化,可支持裸機或者虛擬機。英特爾?傲騰?固態(tài)盤在SSD設備加入了新的存儲層,能夠提升存儲層持久化的效率和可靠性。
OpenShift容器云單集群主要由Master管理節(jié)點、Slave計算節(jié)點及其他功能節(jié)點組成,其配置樣例如下:
角色 | 最小數(shù)量 | 單節(jié)點配置 | 資源類型 | 操作系統(tǒng) | 結構 |
控制臺操作機 | 1 | 4C 8G | 虛擬機 | RHEL 7.5 | 單機多用戶 |
Master管理節(jié)點 | 3 | 8C 16G | 虛擬機 | RHEL 7.5 | 奇數(shù),1主多從 |
Master軟負載 | 2 | 4C 8G | 虛擬機 | RHEL 7.5 | 雙機,1主1備 |
路由 | 3 | 8C 16G | 虛擬機 | RHEL 7.5 | 多活 |
路由軟負載 | 2 | 4C 8G | 虛擬機 | RHEL 7.5 | 雙機,1主1備 |
監(jiān)控 | 3 | 8C 32G | 虛擬機 | RHEL 7.5 | 多活 |
日志 | 3 | 8C 32G | 虛擬機 | RHEL 7.5 | 多活 |
鏡像倉庫 | 2 | 8C 16G | 虛擬機 | RHEL 7.5 | 雙活互備 |
鏡像倉庫軟負載 | 2 | 8C 16G | 虛擬機 | RHEL 7.5 | 雙機,1主1備 |
YUM源 | 1 | 4C 8G | 虛擬機 | RHEL 7.5 | 單機 |
文件服務器 | 1 | 4C 8G | 虛擬機 | RHEL 7.5 | 單機 |
DNS服務器 | 2 | 4C 8G | 虛擬機 | RHEL 7.5 | 雙活互備 |
Slave計算節(jié)點 | ≥3 | 32C 64G | 虛擬機/物理機 | RHEL 7.5 | 多活,由Master管理調(diào)度 |
以上是一個經(jīng)典的Openshift容器云集群配置案例,所有節(jié)點均可以采用虛擬機方案,但不同角色節(jié)點對應的資源配置量不同,搭配起來可以充分利用資源,其中計算節(jié)點也可以使用Intel x86物理機,在日常運維過程中,計算節(jié)點擴充頻率最高,其次是路由節(jié)點,是自動化運維的重要管理內(nèi)容。
某銀行隨著容器云平臺的引入,經(jīng)過幾年的蓬勃發(fā)展,平臺規(guī)模日益擴大,當前容器云平臺已建設超過30個集群,容器總數(shù)上萬個。已經(jīng)承載行內(nèi)接近200個應用系統(tǒng),包括使用資源需求龐大的AI平臺系統(tǒng)、“雙11”期間峰值TPS超1.1萬的消息服務系統(tǒng)、日均千萬筆交易的金融交易系統(tǒng)等。
三、容器云平臺運維痛點
隨著容器云平臺建設規(guī)模的增長和使用場景的增多,容器云平臺運維方面逐步顯露出了很多全新的問題與挑戰(zhàn),由于容器技術本身與傳統(tǒng)虛擬機技術存在一定的差別,容器云平臺中使用自治網(wǎng)絡用于容器通信,而且容器的調(diào)度由平臺完成,容器的IP分配等場景無法人為地進行干預,以往針對虛擬機的運維管理經(jīng)驗不能有效覆蓋平臺化的容器場景。以下針對某銀行這幾年在容器云平臺運維方面存在的痛點作一些說明。
(1)資產(chǎn)信息無法有效聚合。某銀行建設容器云的思路是按照網(wǎng)絡分區(qū)部署容器云平臺。一方面考慮平臺規(guī)模可以做到分區(qū)控制,避免超大規(guī)模平臺的出現(xiàn);另一方面依托現(xiàn)有的網(wǎng)絡分區(qū)安全管理制度,有效抑制跨區(qū)帶來的網(wǎng)絡安全問題。最后在每一個網(wǎng)絡區(qū)域部署一套容器云平臺,容器云平臺做到不跨區(qū)。由于行內(nèi)的各應用系統(tǒng)等級保護要求不一樣,需要在各個不同的等保網(wǎng)絡區(qū)獨立部署容器云平臺來承載行內(nèi)應用,容器云平臺數(shù)量在不斷地增加,建設初期對平臺中各項資源收集整合就成為一項繁重的工作,沒有配置管理無法有效做到各平臺資產(chǎn)信息的集中可視化展示,包括平臺內(nèi)節(jié)點數(shù)量、節(jié)點名稱、節(jié)點角色、節(jié)點IP、節(jié)點配置、平臺內(nèi)承載應用等信息。不僅導致周期性統(tǒng)計工作量的上升,而且容器云的資產(chǎn)定義與現(xiàn)有其他平臺對資產(chǎn)的定義標準不統(tǒng)一,不利于其他平臺與容器云平臺整體聯(lián)動,擴展性也不盡如人意。
(2)運維復雜度與平臺規(guī)模呈正相關性。上一點已經(jīng)提到,容器云平臺規(guī)模的擴張不但使資產(chǎn)信息統(tǒng)計工作量上升,而且針對平臺的運維工作量也出現(xiàn)井噴之勢。容器云的運維工作大致可以分為兩類,一類是日常維護工作,包括平臺例行巡檢、平臺容量擴容、安全加固、組件更新、交付應用賬戶及相應的授權等;另一類是應急處置工作,包括故障應急處理、例行應急演練等。當承載容器云平臺的總節(jié)點數(shù)超過一定規(guī)模后,尤其是日常維護工作如果不采用自動化處理會變得非常繁重,與此同時由于運維人員技術水平參差不齊,傳統(tǒng)手工運維往往難以高效執(zhí)行,出錯率也變的很高。
(3)容器云平臺運行監(jiān)控數(shù)據(jù)不完善,不能有效獲取平臺運行狀態(tài),資源管控能力薄弱。容器云平臺對底層服務器進行整合并形成彈性資源池,在沒有一套完整的監(jiān)控體系下,對容器云平臺的狀態(tài)掌握無異于盲人摸象,雖然可以通過原有的虛擬機監(jiān)控方法人工統(tǒng)計容器云平臺的整體負載情況,但實時性和針對性差。
(4)突發(fā)的大量資源交付周期長。在我們的實際工作中會出現(xiàn)某一季度或者某一個業(yè)務條線出現(xiàn)大量上云的應用,現(xiàn)有平臺資源剩余量無法承載的情況。這種情況的發(fā)生雖然跟業(yè)務激增有一定的關系,但更多的問題是在不能實時掌握平臺運行狀態(tài)、不能對資源消耗情況進行追蹤,不能自動化開展高效資源交付。
(5)異常事件跟蹤能力薄弱。這部分能力主要依靠告警和日志查詢功能來實現(xiàn),在建設初期,往往還沒有建立起一套完善的監(jiān)控告警機制來實現(xiàn)及時精確的告警,各個容器云集群的日志沒有做到統(tǒng)一收集,通常是云上應用系統(tǒng)的業(yè)務發(fā)生異常后,才向平臺運維方申請排查,在沒有準確的告警及日志的幫助下無法第一時間定位問題點,排查耗時長且響應不及時。
四、容器云平臺自動化運維的實現(xiàn)
自動化運維是容器云平臺建設中期開始逐步完善的,大概分為五塊內(nèi)容:配置管理、監(jiān)控告警、自動發(fā)布、流程管理、批量執(zhí)行。
配置管理分為兩部分,一是平臺級的配置信息管理,體現(xiàn)在平臺所在區(qū)域、平臺節(jié)點數(shù)量、平臺節(jié)點角色等信息的采集入庫,并通過統(tǒng)一視圖進行展示;二是平臺內(nèi)的應用容器的信息采集入庫,包括應用系統(tǒng)名稱、應用系統(tǒng)容器鏡像版本、應用容器IP地址、應用容器運行環(huán)境等信息。
監(jiān)控告警分為四塊,一是資源監(jiān)控,包括平臺資源總量、己使用量、可分配量;二是系統(tǒng)監(jiān)控,包括節(jié)點級CPU/內(nèi)存/磁盤實際使用率、平臺流量入口業(yè)務請求速率、節(jié)點就緒狀態(tài)等,并通過設置安全閾值在異常時觸發(fā)告警;三是業(yè)務監(jiān)控,包括應用系統(tǒng)數(shù)量統(tǒng)計、運行應用容器數(shù)量、項目資源配額、項目維度容器實際CPU/內(nèi)存使用率、應用容器異常狀態(tài)告警等;四是日志監(jiān)控,主要體現(xiàn)在日志的集中采集分析。CPU資源監(jiān)控需要適應容器環(huán)境的特點,具備靈活性和自動化。
自動發(fā)布針對是云上應用系統(tǒng),通過CICD支持應用的自動發(fā)布及回滾。
流程管理體現(xiàn)在利用工單系統(tǒng)、標準流程實現(xiàn)資源的按期交付,應用投產(chǎn)上線流程標準化。
批量執(zhí)行將繁瑣的平臺巡檢工作、平臺擴容工作利用自動化工具實現(xiàn)批量執(zhí)行,縮短周期,提高整體效率,減少人工成本。
基于容器云平臺本身所帶來的好處以及其高效性、靈活性的特點,某銀行設計了一套針對容器云平臺的自動化運維架構。容器云平臺本身針對應用開發(fā)團隊來說已經(jīng)實現(xiàn)了所測即所投、應用快速發(fā)布、應用健康檢查、應用故障自愈、基于持續(xù)交付系統(tǒng)的自動發(fā)布等能力。自動化運維所做的更多是偏向平臺運維本身,大致內(nèi)容如下。
(1) 建設云管平臺。云管平臺建設的目的在于,一方面納管所有的容器云平臺,通過標準Kubernetes API進行納管,云管平臺中記錄各容器云平臺網(wǎng)絡分區(qū)信息、節(jié)點數(shù)量、應用項目相關信息等并通過統(tǒng)一視圖進行展示,基于這些信息組成一套容器云平臺的CMDB。另一方面提供統(tǒng)一API接口供外部系統(tǒng)調(diào)用,后續(xù)新建設的容器云平臺信息由云管平臺API進行封裝,提高可擴展性。同時實現(xiàn)統(tǒng)一用戶認證、權限集中控制和審計,滿足管理要求。
(2)對接配置管理系統(tǒng)(CMDB)。除了云管平臺自身的CMDB外,行內(nèi)配置管理系統(tǒng)通過云管平臺API遍歷所有容器云平臺的應用系統(tǒng)配置信息并入庫,包括應用系統(tǒng)名稱、應用系統(tǒng)容器鏡像版本、應用容器IP地址、應用容器運行環(huán)境、應用項目組管理成員等信息。通過完善的配置信息管理可以快速定位故障應用的相關屬性。
(3)建立統(tǒng)一用戶體系。云管平臺通過對接行內(nèi)統(tǒng)一用戶平臺實現(xiàn)單點登錄,這樣做的好處是:首先應用項目成員可以完成自行登錄,不需要容器云平臺側進行用戶分配;其次可以實現(xiàn)基于用戶角色的權限綁定并進行操作審計;最后可以基于真實用戶實現(xiàn)和其他平臺之間的聯(lián)動,比如外部的交付平臺。
(4)對接日志中心。在所有容器云平臺的節(jié)點上部署日志采集工具對接行內(nèi)日志中心,通過日志中心實現(xiàn)日志集中查詢分析。
(5)建立監(jiān)控體系。監(jiān)控體系由容器云平臺監(jiān)控系統(tǒng)和行內(nèi)監(jiān)控中心組成。監(jiān)控系統(tǒng)我們采用Prometheus監(jiān)控組件和Grafana監(jiān)控展示組件,對監(jiān)控指標、告警規(guī)則和展示面板進行定制開發(fā),各容器云平臺分別對接行內(nèi)監(jiān)控中心,將結構化監(jiān)控數(shù)據(jù)及告警規(guī)則傳遞至監(jiān)控中心,整體實現(xiàn)了資源監(jiān)控、系統(tǒng)監(jiān)控、業(yè)務監(jiān)控,異常事件短信告警。提升異常事件跟蹤、資源管控能力,并且根據(jù)資源使用率的監(jiān)控可以提前對資源枯竭進行預警,提前完成節(jié)點擴容,縮短資源交付周期。基礎設施資源建議選擇能夠支持開源主流監(jiān)控技術棧的產(chǎn)品,包括CPU、內(nèi)存、磁盤等等,例如英特爾云原生 Telemetry Software Stack 技術支持一系列信息采集、監(jiān)控、展示組件 (Collectd, Prometheus, node-exporter, Grafana)。
(6)批量執(zhí)行工具。平臺巡檢、平臺擴容等操作固化、頻繁的工作采用自研 Ansible ?playbook 結合 Openshift 本身的 Ansible playbook 合并成一個自動化工具,可以實現(xiàn)一鍵化完成平臺巡檢并生成巡檢報告、平臺擴容前針對虛擬機的準備工作、執(zhí)行平臺擴容等內(nèi)容。直接縮短維護時間、降低使用技術門檻,提高運維效率。
(7)流程管理。目前有兩套流程,一個是圍繞應用項目自動發(fā)布的,另一個是應對容器云平臺故障應急的。應用項目自動發(fā)布流程基于DevOps流程,行內(nèi)代碼倉庫、交付中心對接云管平臺,各容器云平臺對接制品倉庫,結合投產(chǎn)工單系統(tǒng)整體實現(xiàn)從源碼到鏡像制品再到自動發(fā)布的應用構建發(fā)布流水線,其中包含代碼基線管理、應用代碼單元測試、應用鏡像制品晉級管理等管理流程,能夠使應用項目組自行完成應用的快速交付。容器云平臺故障應急流程則是通過行內(nèi)監(jiān)控中心派單機制結合行內(nèi)應急故障處置流程來實現(xiàn),監(jiān)控中心會根據(jù)容器云平臺監(jiān)控系統(tǒng)報送的監(jiān)控數(shù)據(jù)和告警規(guī)則來決策故障事件等級并下發(fā)告警短信通知,如果等級過高則觸發(fā)應急故障處理流程,值班人員根據(jù)容器云平臺應急手冊中命中的場景展開應急處置工作。這里需要注意的一個問題就是應急手冊場景要細、操作步驟可靠可行,現(xiàn)有的這套流程提高了容器云平臺應急事件處理的效率,大大縮短了應急響應時間。
五、實現(xiàn)自動化運維帶來的效果及總結
通過基于OpenShift的自動化運維機制,并與行內(nèi)科技管理、配置、應用支持等系統(tǒng)對接,很好地支撐了資源量大、并發(fā)量高的應用場景,同時穩(wěn)定地支持了行內(nèi)重要交易系統(tǒng)的運行。基于容器云平臺的自動化運維主要帶來了如下三方面好處:一是為開發(fā)人員減負、聚焦于業(yè)務功能實現(xiàn)和創(chuàng)新,實現(xiàn)分鐘級的應用快速部署,提升應用研發(fā)和運維效率;二是實現(xiàn)云上應用的全生命周期管理,提供了應用運行全景視圖;三是實現(xiàn)資源按需自動供給、彈性擴容、空閑自動回收,資源使用效率提升三倍以上。
容器云平臺在某銀行的應用已經(jīng)日漸成熟,其作為容器化底座的基礎平臺,今后將為基于Service Mesh的微服務治理平臺、基于Serverless的應用開發(fā)平臺提供有力的保障。

歡迎點擊文末閱讀原文,到社區(qū)提問討論