
如何使用多類型數(shù)據(jù)預(yù)訓(xùn)練多模態(tài)模型?
在訓(xùn)練過程中使用更多數(shù)據(jù)一直是深度學(xué)習(xí)提效的重要方法之一,在多模態(tài)場(chǎng)景也不例外。比如經(jīng)典的CLIP模型,使用了大規(guī)模的網(wǎng)絡(luò)圖文匹配數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,在圖文匹配等任務(wù)上取得非常好的效果。
在此之后對(duì)CLIP多模態(tài)模型的優(yōu)化中,一個(gè)很重要的分支是如何使用更多其他類型的數(shù)據(jù)(例如圖像分類數(shù)據(jù)、看圖說話數(shù)據(jù)等),特別是CVPR 2022、谷歌等近期發(fā)表的工作,都集中在這個(gè)方面。想使用多種類型的數(shù)據(jù),核心是在數(shù)據(jù)或模型結(jié)構(gòu)上實(shí)現(xiàn)多任務(wù)的統(tǒng)一。本文梳理了這個(gè)方向4篇近期最典型的工作,包括2篇CVPR 2022的文章和2篇谷歌的文章。其中涉及的方法包括:多模態(tài)模型結(jié)構(gòu)上的統(tǒng)一、多模態(tài)數(shù)據(jù)格式上的統(tǒng)一、單模態(tài)數(shù)據(jù)引入、多類型數(shù)據(jù)分布差異問題優(yōu)化4種類型。
論文題目:CoCa: Contrastive Captioners are Image-Text Foundation Models
下載地址:https://arxiv.org/pdf/2205.01917.pdf
CoCa將解決圖像或多模態(tài)問題的模型概括成3種經(jīng)典結(jié)構(gòu),分別是single-encoder model、dual-encoder model、encoder-decoder model。Single-encoder model指的是基礎(chǔ)的圖像分類模型,dual-encoder model指的是類似CLIP的雙塔圖文匹配模型,encoder-decoder model指的是用于看圖說話任務(wù)的生成式模型。三種類型的模型結(jié)構(gòu)對(duì)比如下圖。
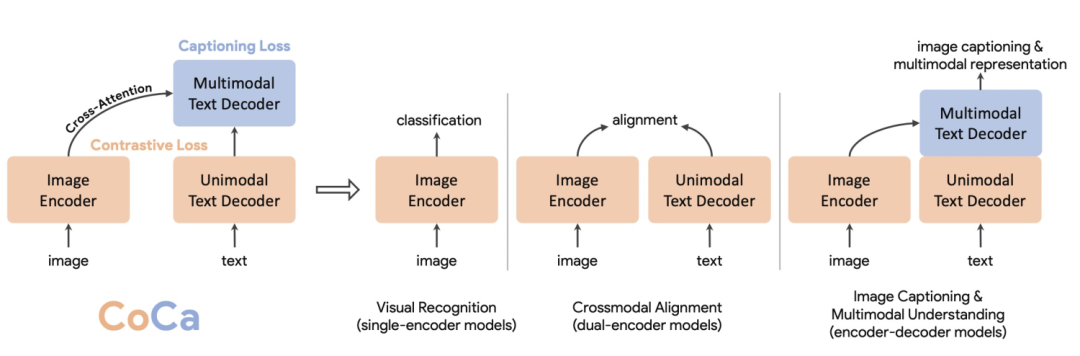
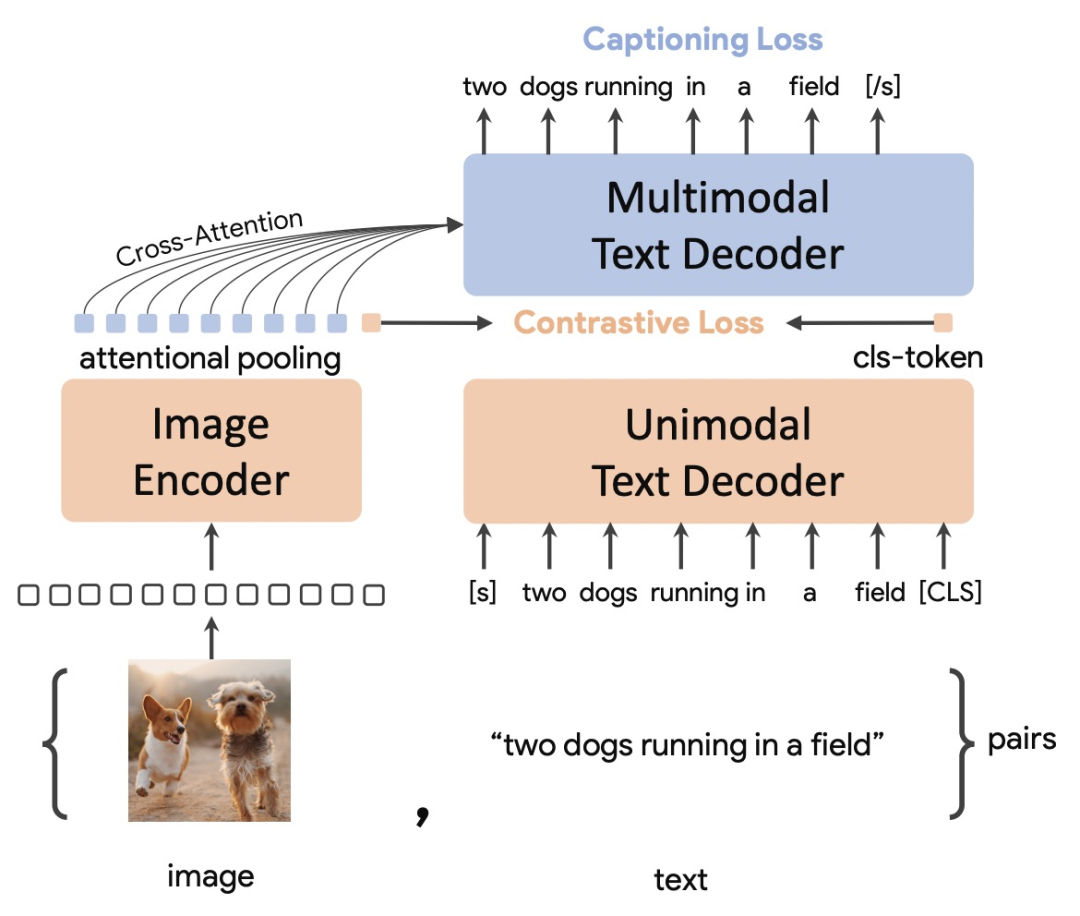
CoCa希望將三種類型的模型結(jié)構(gòu)進(jìn)行統(tǒng)一,這樣模型可以同時(shí)使用3種類型的數(shù)據(jù)訓(xùn)練,獲取更多維度的信息,也可以實(shí)現(xiàn)3種類型模型結(jié)構(gòu)的優(yōu)勢(shì)互補(bǔ)。CoCa的整體結(jié)構(gòu)包括3個(gè)部分:一個(gè)encoder(Image Encoder)和兩個(gè)decoder(Unimodal Text Decoder、Multimodal Text Decoder)。Image Encoder采用一個(gè)圖像模型,例如ViT等。Unimodal Text Decoder在這里起到CLIP中text encoder的作用,是一個(gè)不和圖像側(cè)信息交互的文本解碼器。Unimodal Text Decoder和Image Encoder之間沒有cross attention,實(shí)際上是一個(gè)單向語言模型。最后,Multimodal Text Decoder在單模態(tài)文本decoder之上,和圖像encoder進(jìn)行交互,生成圖像和文本交互信息,并解碼還原對(duì)應(yīng)文本。注意兩個(gè)文本decoder都是單向的,防止信息泄露。
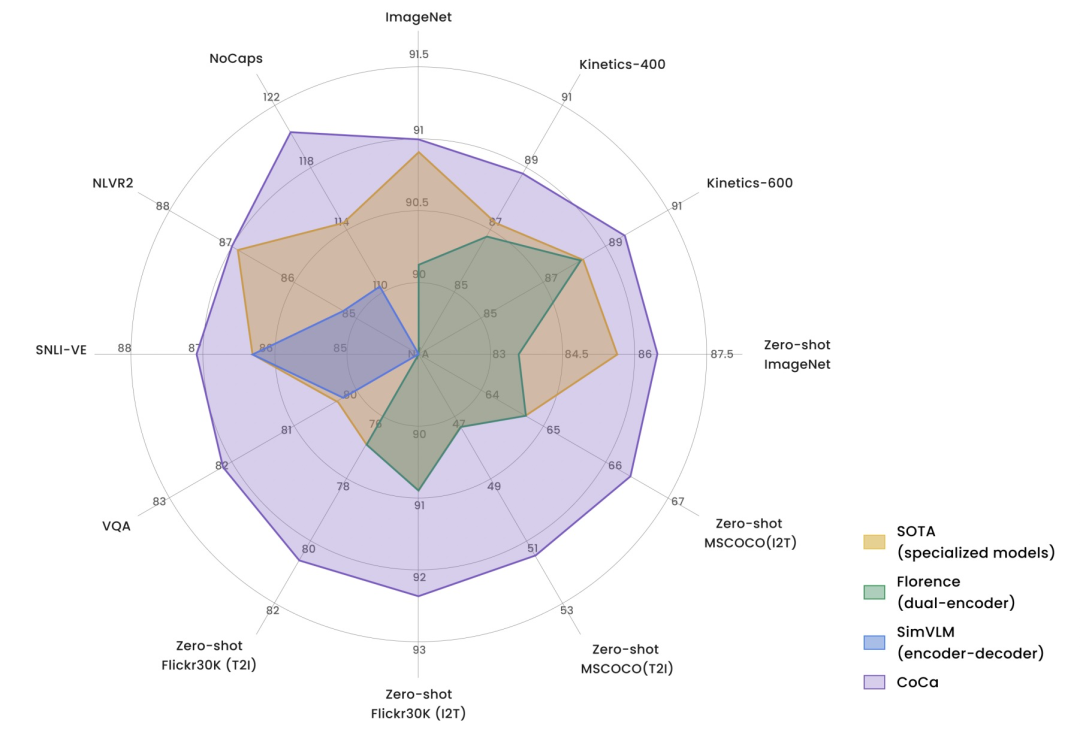
CoCa在多個(gè)任務(wù)上取得非常亮眼的效果。下圖是CoCa和3種類型圖文模型在多個(gè)任務(wù)上的效果對(duì)比,CoCa的優(yōu)勢(shì)非常明顯。多個(gè)任務(wù)和數(shù)據(jù)集上達(dá)到SOTA,在ImageNet上達(dá)到91%的效果。
論文題目:Unified Contrastive Learning in Image-Text-Label Space
下載地址:https://arxiv.org/pdf/2204.03610.pdf
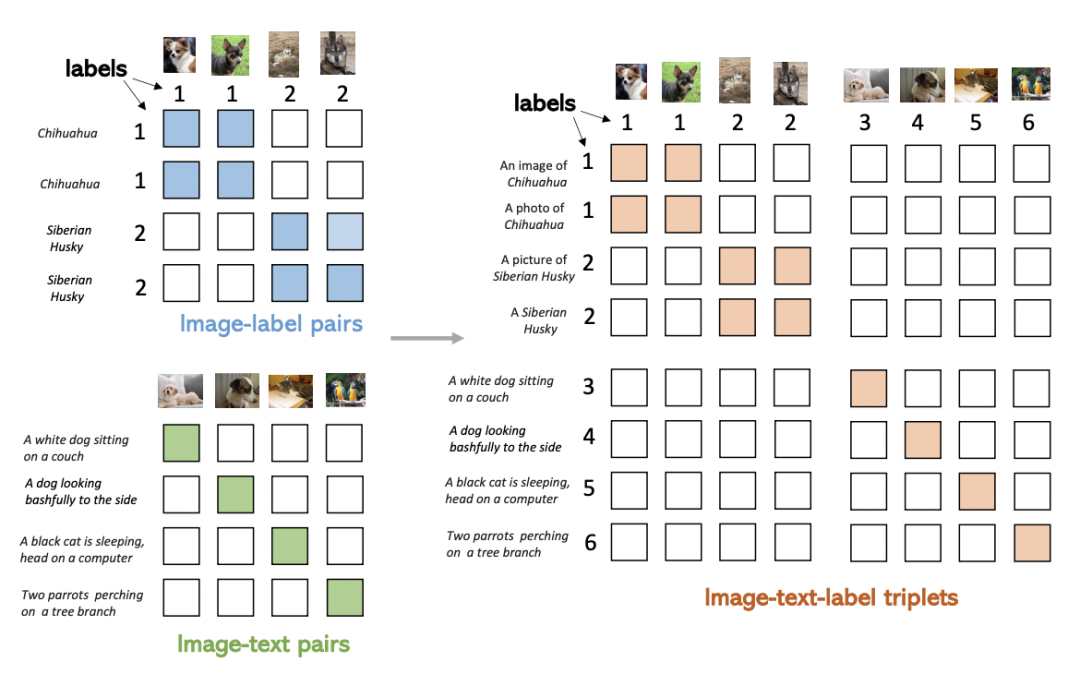
本文提出的方法希望同時(shí)利用圖像、文本、label三者的信息,構(gòu)建一個(gè)統(tǒng)一的對(duì)比學(xué)習(xí)框架,同時(shí)利用兩種訓(xùn)練模式的優(yōu)勢(shì)。下圖反映了兩種訓(xùn)練模式的差異,Image-Label以離散label為目標(biāo),將相同概念的圖像視為一組,完全忽視文本信息;而Image-Text以圖文對(duì)匹配為目標(biāo),每一對(duì)圖文可以視作一個(gè)單獨(dú)的label,文本側(cè)引入豐富的語義信息。

本文的核心方法是在數(shù)據(jù)格式上進(jìn)行統(tǒng)一,以此實(shí)現(xiàn)同時(shí)使用Image-Text和Image-Label數(shù)據(jù)的目標(biāo)。這兩種類型的數(shù)據(jù)可以表示成一個(gè)統(tǒng)一的形式:(圖像,文本,label)三元組。其中,對(duì)于Image-Lable數(shù)據(jù),文本是每個(gè)label對(duì)應(yīng)的類別名稱,label對(duì)應(yīng)的每個(gè)類別的離散標(biāo)簽;對(duì)于Image-Text數(shù)據(jù),文本是每個(gè)圖像的文本描述,label對(duì)于每對(duì)匹配的圖文對(duì)都是不同的。將兩種數(shù)據(jù)融合到一起,如下圖右側(cè)所示,可以形成一個(gè)矩陣,填充部分為正樣本,其他為負(fù)樣本。Image-Label數(shù)據(jù)中,對(duì)應(yīng)類別的圖文為正樣本;Image-Text中對(duì)角線為正樣本。通過這種方式統(tǒng)一格式后的數(shù)據(jù),可以直接使用原來CLIP中的對(duì)比學(xué)習(xí)方式進(jìn)行訓(xùn)練,實(shí)現(xiàn)了同時(shí)使用多種類型數(shù)據(jù)的目的。
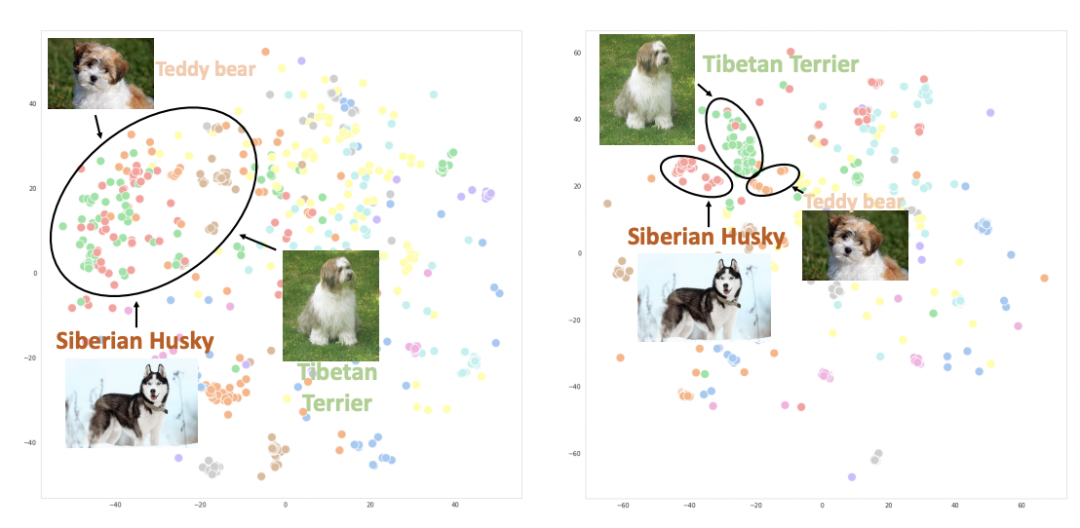
下圖繪制了使用CLIP(左)和UniCL(右)兩種方法訓(xùn)練的圖像embedding的t-sne圖。可以看到,使用CLIP訓(xùn)練的模型,不同類別的圖像表示混在一起;而使用UniCL訓(xùn)練的模型,不同類別的圖像表示能夠比較好的得到區(qū)分。
論文題目:FLAVA: A Foundational Language And Vision Alignment Model
下載地址:https://arxiv.org/pdf/2112.04482.pdf
FLAVA方法的出發(fā)點(diǎn)是,一個(gè)訓(xùn)練的比較好的多模態(tài)模型,不僅在圖文跨模態(tài)任務(wù)上效果好,同時(shí)也能在圖片或文本的單模態(tài)任務(wù)上效果好。因此,FLAVA提出,在訓(xùn)練多模態(tài)模型時(shí),同時(shí)引入圖像領(lǐng)域和NLP領(lǐng)域的單模態(tài)任務(wù),提升單模態(tài)模型的效果,這有助于多模態(tài)模型后續(xù)的訓(xùn)練。
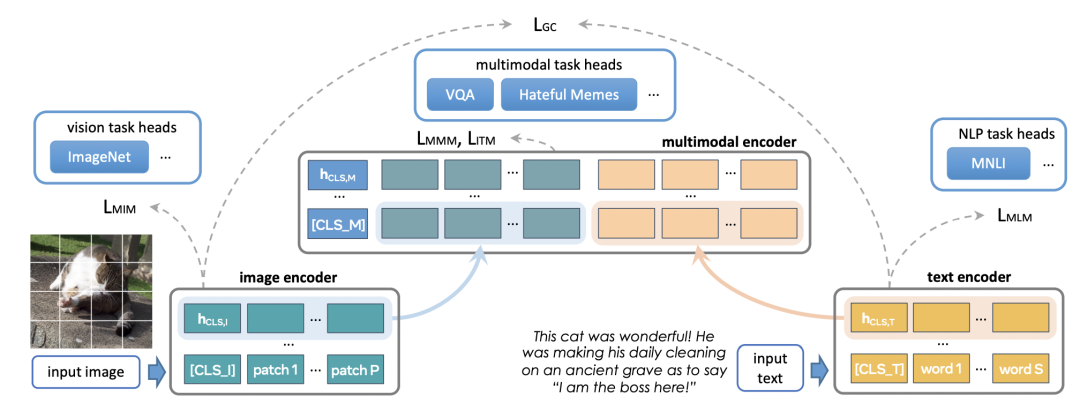
FLAVA的具體模型結(jié)構(gòu)如下圖所示,底層是兩個(gè)獨(dú)立的Image Encoder和Text Encoder,上層使用一個(gè)跨模態(tài)的Multimodal Encoder,實(shí)現(xiàn)圖像側(cè)和文本側(cè)信息的交叉。Multimodal Encoder的輸入是Image Encoder和Text Encoder各自的輸出拼接到一起。預(yù)訓(xùn)練任務(wù)除了CLIP中的圖文對(duì)比學(xué)習(xí)外,新增了下面3種loss:
Masked multimodal modeling (MMM):對(duì)文本中的部分token和圖像中的部分patch進(jìn)行mask,讓模型進(jìn)行預(yù)測(cè),可以視為mask單模態(tài)token的一種擴(kuò)展。
Masked image modeling (MIM):MIM是圖像Encoder內(nèi)部的單模態(tài)優(yōu)化目標(biāo),對(duì)圖像中部分patch進(jìn)行mask,然后使用圖像Encoder進(jìn)行預(yù)測(cè)。
Masked language modeling (MLM):MLM則是BERT中的基礎(chǔ)方法,mask部分token后進(jìn)行還原。
Image-text matching (ITM):圖像和文本的匹配loss,和對(duì)比學(xué)習(xí)loss類似,用于學(xué)習(xí)樣本全局的表示。
在訓(xùn)練過程中,首先使用單模態(tài)任務(wù)(MIM、MLM)進(jìn)行單模態(tài)模型的預(yù)訓(xùn)練,然后再同時(shí)使用單模態(tài)和多模態(tài)任務(wù)繼續(xù)訓(xùn)練。
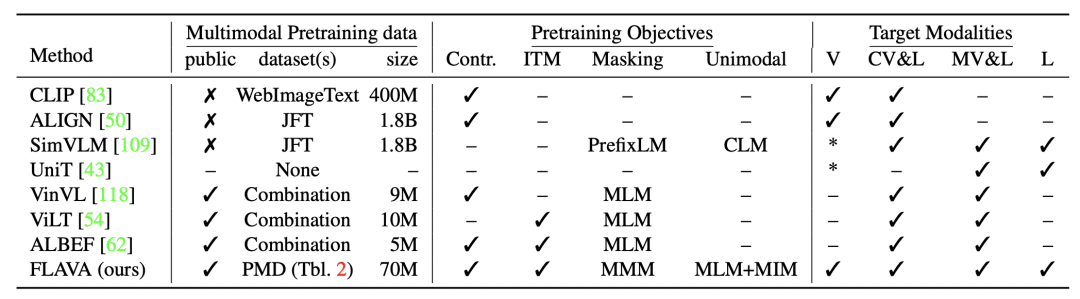
下表對(duì)比了FLAVA和其他多模態(tài)模型在訓(xùn)練數(shù)據(jù)、預(yù)訓(xùn)練任務(wù)和可解決的模態(tài)上的差異。FLAVA使用了多種單模態(tài)數(shù)據(jù),讓模型能夠同時(shí)處理單模態(tài)和多模態(tài)任務(wù)。
論文題目:Prefix Conditioning Unifies Language and Label Supervision
下載地址:https://arxiv.org/pdf/2206.01125.pdf
本文也是希望同時(shí)引入圖像-文本pair數(shù)據(jù),以及圖像的label數(shù)據(jù)。與Unified Contrastive Learning in Image-Text-Label Space這篇文章的思路不同,本文的主要問題點(diǎn)是如何解決兩種類型數(shù)據(jù)在分布上的差異,主要是文本側(cè)的分布差異。對(duì)于圖像的文本描述,一般都是比較長(zhǎng)且內(nèi)容比較多的。而通過Image-Label轉(zhuǎn)換而來的圖像-文本對(duì),文本側(cè)都是比較干凈的類目信息,例如A photo of a cat。兩種數(shù)據(jù)的差異導(dǎo)致多模態(tài)匹配時(shí),需要關(guān)注的信息、圖文兩側(cè)交互的方法也會(huì)有不同。
這篇文章采用了prefix prompt的思路解決兩種類型數(shù)據(jù)文本側(cè)數(shù)據(jù)分布差異大的問題。Prefix prompt原本是用于輕量級(jí)finetune的,在finetune大模型的時(shí)候,加上任務(wù)特定的prompt前綴向量,只finetune這個(gè)前綴向量,原理是利用prompt的思路作為上下文信息影響其他位置元素的表示生成過程。對(duì)prefix prompt感興趣的同學(xué)可以參考這篇文章:NLP Prompt系列——Prompt Engineering方法詳細(xì)梳理。本文在兩種類型的數(shù)據(jù)前面拼接了兩個(gè)不同的prefix向量,分別對(duì)應(yīng)文本描述數(shù)據(jù)和Image-label轉(zhuǎn)換而來的數(shù)據(jù)。在預(yù)訓(xùn)練階段就引入prefix prompt,讓模型在預(yù)訓(xùn)練過程中就能區(qū)分兩種類型的數(shù)據(jù)。
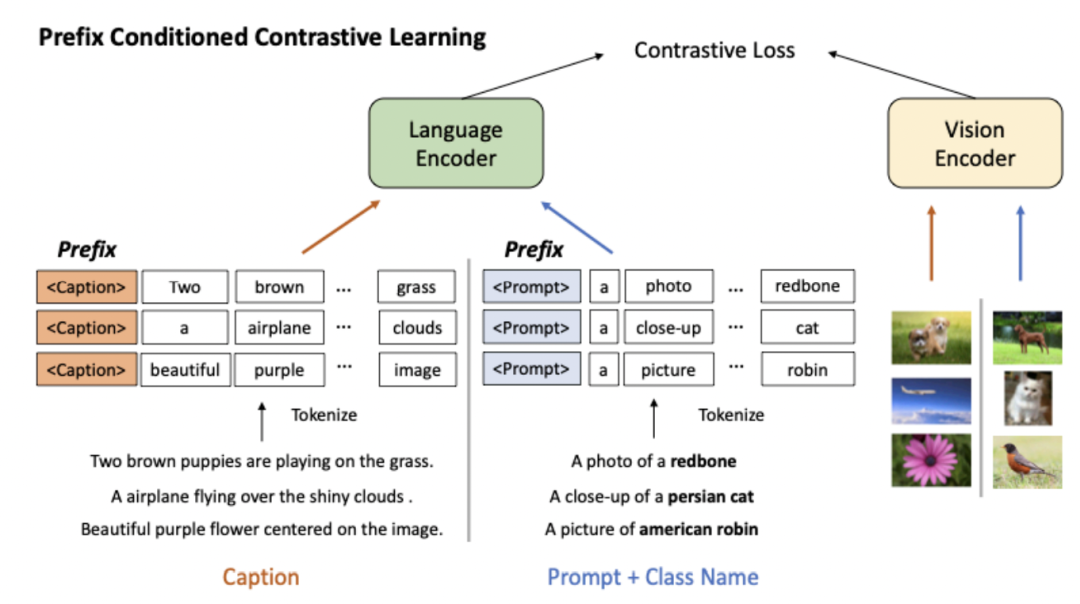
從下面的Attention Map可以看到,對(duì)于不同的prefix prompt和數(shù)據(jù)類型,模型在文本側(cè)的Attention分布有比較明顯的差異,即使其他文本是完全相同的。文本描述(Caption)的prefix prompt對(duì)應(yīng)的attention map,呈現(xiàn)出相對(duì)均勻的分布,對(duì)多個(gè)token都比較關(guān)注;而Image-Label的prefix prompt對(duì)應(yīng)的attention map,則更關(guān)注類目相關(guān)的關(guān)鍵性的幾個(gè)字。這表明模型學(xué)到了如何區(qū)分不同類型的數(shù)據(jù),并將其存儲(chǔ)到prefix prompt的向量中,用來影響整個(gè)句子的表示生成。

本文介紹了多模態(tài)模型優(yōu)化中的引入多種類型數(shù)據(jù)的研究方向。近期的論文中,這類工作表多,是目前業(yè)內(nèi)研究的熱點(diǎn),也是能夠顯著提高多模態(tài)模型效果的方法。